基于核主元分析与核密度估计的非线性过程故障监测与识别①
2022-11-07郑天标肖应旺
郑天标,肖应旺
(广东技术师范大学 自动化学院,广州 510665)
近年来,关于多元统计过程的监控策略可谓百花齐放,早期由于主成分分析方法(principal components analysis,PCA)拥有良好的降维能力被普遍应用,但由于PCA 不适用于非线性系统,Schölkopf 等人[1]提出了核主元分析法(kernel principal components analysis,KPCA),KPCA 通过非线性映射函数将原始输入空间映射到高维特征空间,然后再利用特征空间中映射数据点的内积就可解决非线性问题.吴天昊等人[2]将KPCA 引入核电厂设备在线监控领域中,使监测手段提供更为早期的预报警.吕宁等人[3]提出一种改进的多向核主元分析故障诊断模型,使得非线性主元能够在高维特征空间中被快速提取.吴洪艳等人[4]提出了基于小波的KPCA 故障监测方法,降低了KPCA 计算的复杂性,缩短了计算时间.霍特林的T2统计量和Q统计量(也称平方预测误差,squared prediction error,SPE)是PCA 与KPCA 在过程监控中常用的两个统计量指标.T2统计量用于监控模型空间的变化,而Q统计量用于监控剩余空间的变化.然而,T2和Q统计量仅适用于高斯分布过程的监控.借鉴文献[5-8]提出的算法,本文采用核密度估计(kernel density estimation,KDE)方法推导核主元分析的控制限; 然后,比较了基于高斯分布统计量控制限的KPCA 和KPCA-KDE 在田纳西伊斯曼(TE)过程中的故障检测性能.结果表明,基于KPCA-KDE 的监测方法比基于高斯假设的KPCA 具有更好的性能.
1 基于KPCA-KDE 的过程监控
1.1 KPCA 算法
给定m个训练样本Xk∈Rn,k=1,2,···,m,由非线性映射可以映射到高维特征空间.特征空间中的协方差矩阵为:
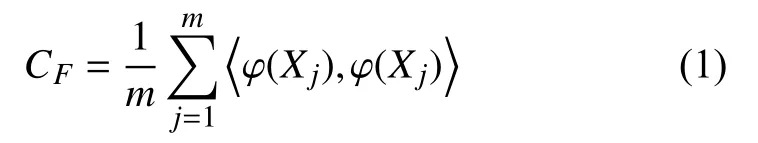

其中,λ是CF的特征值,满足λ ≥0,a∈RF是对应的特征向量(a≠0).特征向量可表示为映射数据点的线性组合如下:
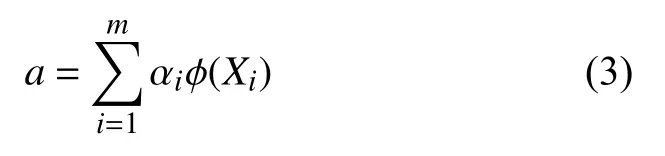
用φ(X)两边同时左乘式(2):
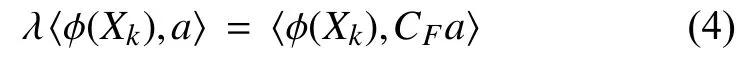
将式(1)、式(3)代入式(4),得:
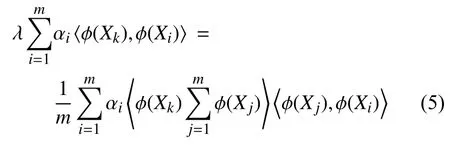
不直接对式(1)中CF的进行特征值分解并找到特征值和主成分,而采用核技巧,定义一个m×m的核矩阵,如式(6):
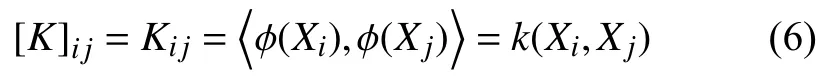
对于所有i,j=1,···,m引入核函数的形式k(x,y)=(φ(x),φ(y))在式(5)使内积的计算〈φ(xi),φ(xi)〉在特征空间中作为输入数据的函数.在特征空间中不需要进行非线性映射和计算内积.对于核矩阵,将式(5)重写为:
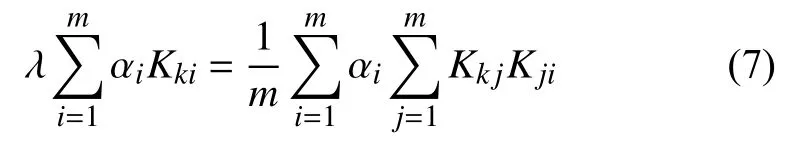
注意,k=1,···,m,因此,式(7)可以表示为:

式(8)等价于特征值问题:

更进一步,核矩阵可以表示为式(10):
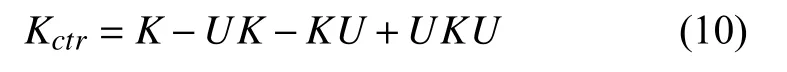
其中,U是一个m×m矩阵,其中每个元素都等于1/m.Kctr的特征值分解相当于 ℜF中的PCA.本质上相当于解决式(9)中的特征值问题,它产生特征向量为α1,α2,···,αm,相应的特征值为λ1≥λ2≥···≥λm.
由于核矩阵Kctr是对称的,故导出的主元是标准正交的,即:
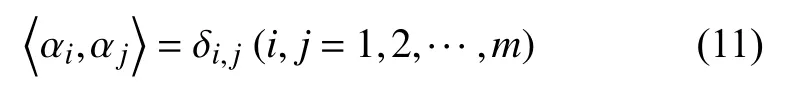
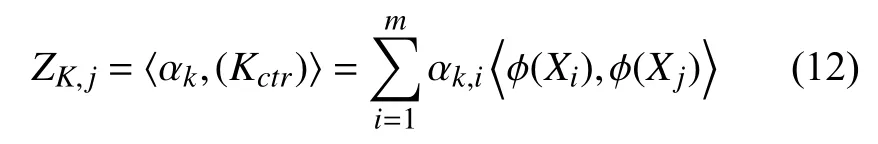
应用内核技巧,这可以表示为:
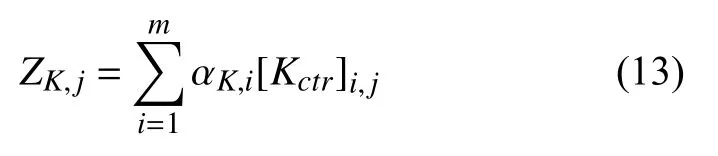
1.2 故障检测指标
特征空间中第j个样本的霍特林的T2,其KPCA故障检测表达式为:

其中,Zi,j,i=1,···,q表示第j个样本的主元得分,q为保留主元的数量,Ω-1表示保留主元对应的特征值矩阵的逆.从T2的分布可估计其控制极限.如果所有采样都是高斯分布的,那么F 分布的控制限对应于一个显著性水平 α,T2,可以表示为:

其中,Fq,m-q,α为显著性水平 α对应的自由度为条件下的F 分布临界值.Choi 等人[9]还提出了对Q统计量的简化计算.对于第j个样本:
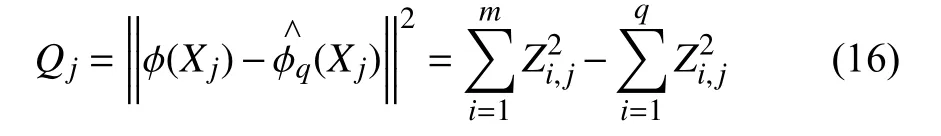
如果所有分数都是正态分布,Q统计量在100(1-α)%置信水平的控制极限可以推导如下:
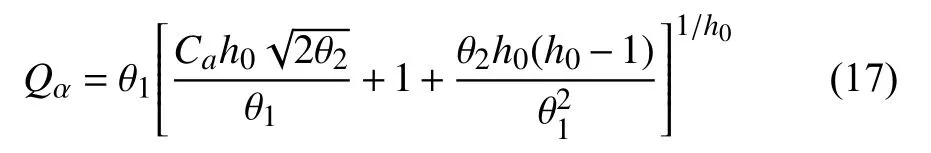
1.3 核密度估计
KDE 是从一组随机样本中使用合适的平滑概率密度函数对数据集进行拟合的过程.它被广泛应用于概率密度函数(probability density functions,PDFS)的估计,特别是单变量的随机数据[10-13].尽管这些统计特征的过程是多变量的,因为两者都是单变量的,所以KDE可应用于T2和Q统计.给定一个随机变量y,从其m个样本中获得它的概率密度函数g(y),yj,j=1,···,m如下:
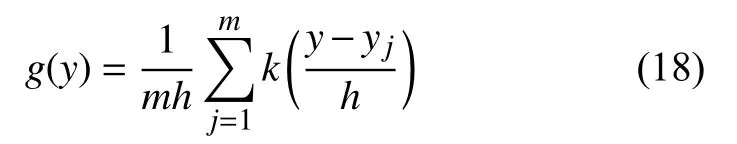
其中,k为核函数,h为带宽或平滑参数.基于Cheng 等人[14]提出的选择带宽的最佳方法,本文在连续范围内对密度函数积分得到概率.因此,假设PDF 在指定的显著水平上,y小于c的概率为:
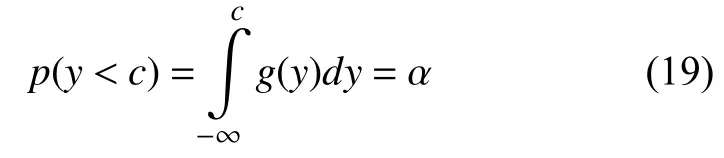
T2Q
因此,监测统计量(和 )的控制限可由各自的概率密度函数估算值计算:
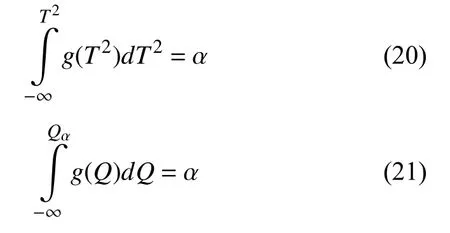
1.4 在线监测
对于一个以均值为中心的观测样本,使用训练例子计算相应的核向量Xj,j=1,···,m如下:

然后将测试核向量标准化,如式(23)所示:
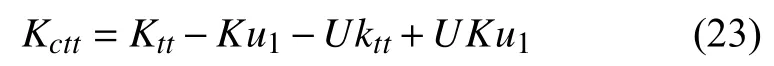
u1=1/m[1,···,1]T∈ℜm.计算相应的得分向量(核主元)Ztt:
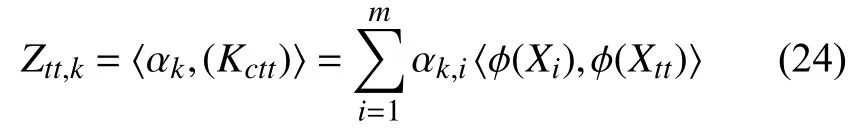
也可写成:
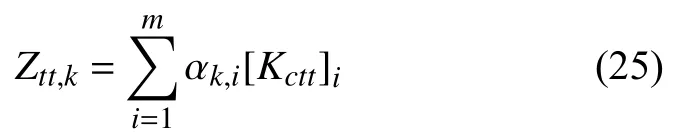
用向量形式表示为:

其中,A=[α1,···,αm].
2 KPCA-KDE 故障监测算法过程
2.1 离线监控模型的建立
TR1.获取正常运行条件下的数据(NOC),使用数据集中代表不同变量的列的均值和标准差对数据进行规范化;
TR2.决定内核函数的类型并确定内核参数;
TR3.构造NOC 数据的核矩阵并将其中心化;
TR4.获得特征值及其对应的特征向量,并将其按降序排列;
TR5.使用式(11)对特征向量进行正交化;
TR6.使用式(13)得到非线性得分向量;
TR7.根据核化NOC 数据,利用式(14)和式(16)计算监控性能指标(T2和Q);
TR8.用式(20)、式(21)确定T2和Q的控制限值.
2.2 在线监控模型的建立
TT1.获取测试样本Xtt并使用离线步骤1 中的均值和标准差进行规范化;
TT2.用式(22)获得样本的核向量;
TT3.据式(23)对核向量进行中心化;
TT4.据式(25)求出测试样本的主元值;
TT5.将测试样本的T2和Q与模型建立阶段得到的各自控制极限进行比较;
TT6.如果T2和Q都小于它们的监控统计数据,则过程处于控制之中.如果T2或Q超过控制限度,则过程失控,进行故障识别,识别故障的来源.基于核主元分析与核密度估计的非线性过程故障监测与识别流程图见图1.
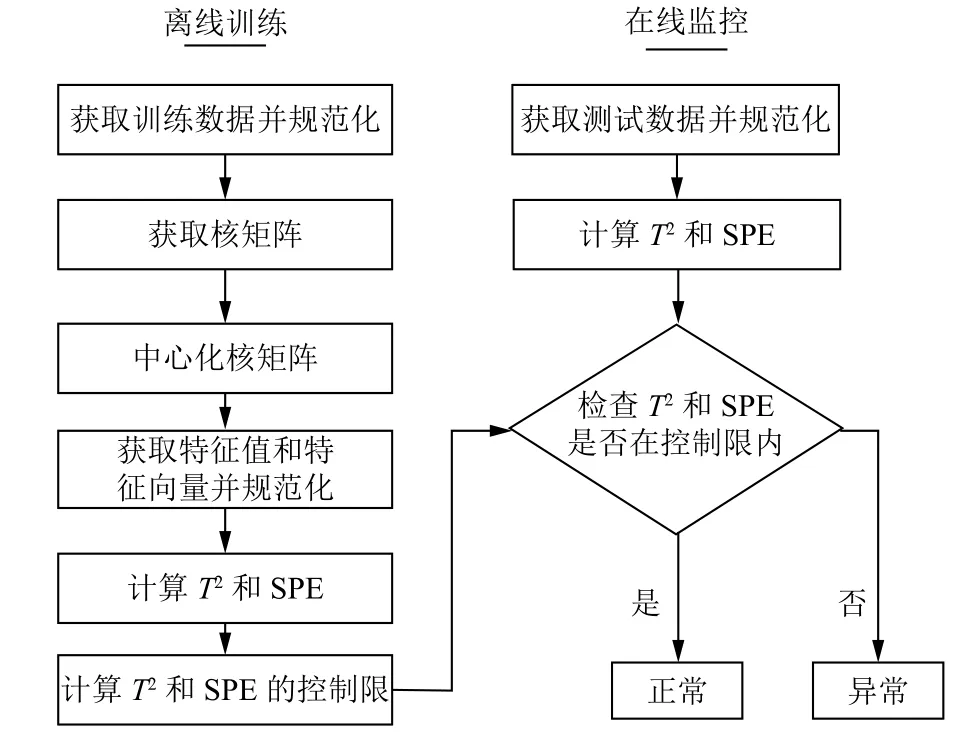
图1 基于KPCA-KDE 的故障监测流程图
2.3 故障变量识别
在检测到故障之后,重要的是要识别与故障关联最紧密的变量,以便于确定故障发生的原因.
贡献图是一种常用的故障识别方法,它显示了各变量对故障区域的高统计指标值的贡献.然而,由于转换后的过程变量与原始过程变量之间存在非线性关系,基于非线性PCA 的故障识别不像线性主成分分析那样简单.
在本文中,使用Petzold 等人[15]提出的敏感性分析原理识别故障变量.该方法基于Deng 等人[16]研究的方法,计算因参数变化而引起系统输出变化的变化率.给定一个测试数据向量Xi∈ℜn,第i个变量对监测指标的贡献定义为:
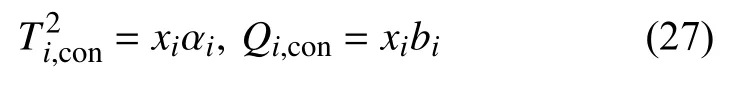
其中,ai=∂T2/∂xi,bi=∂Q/∂xi.
在使用多元统计方法的故障识别中,一种获得变量贡献的有效方法,即通过对定义T2和Q的函数在参考故障瞬间进行阶跃微分得到偏导数的方法来识别故障[17].
3 应用程序
3.1 田纳西伊斯曼过程
TE 过程是基于真实工业过程的模拟[18],具有较强的非线性和动态特性,Chiang 等人[19]把它用作评价和比较过程监控的基准过程.该过程由分离器、压缩机、反应器、汽提器和冷凝器5 个关键部件和编码为A 到H 的8 个部件组成,共采样960 个,变量53 个,其中连续变量22 个,3 个成分分析器采样的成分测量值19 个,TE 过程中的操纵变量为12 个.采样每隔3 分钟进行一次,而每个故障在采样数160 处引入.McAvoy等人[20]阐述了干扰和基线操作的信息工艺条件.
T2Q
由于 和 数据具有互补性,因此联合使用它们进行故障检测.由于可检测到的过程变化并不总是同时发生在模型空间和剩余空间中,故当任一监控统计数据检测到故障时,即检测到故障.
3.2 计算监控性能指标
由于从化学过程获得的测量通常是有噪声的,统计量可能会随机地超过其控制限.这相当于在没有实际发生故障的情况下统计量可能超过控制限,即虚假警报.换句话说,一个统计量可能会超过它的控制限一次,但是如果没有出现故障,在随后的监控中,统计量可能不会总是保持在它的控制限之上.相反,如果在连续的测量中统计量保持在其控制限以上,则可能发生故障.van Sprang 等人[21]使用故障检测规则解决了假警报的问题.检测规则也为比较不同的监测方法提供了统一的依据.在本文中,当一个统计量在至少两个连续监控中超过其控制限时,即认为发生了故障.所有实验在使用基于此准则的数据进行测试时,都记录了一个零的误报率的数据来用于评估不同技术的监视性能.性能监控基于3 个指标: 故障检出率(fault detection rate,FDR)、误报率(false alarm rate,FAR)和检测延迟(detection delay,DD).故障检出率是正确识别的故障样本的百分比:

其中,nfc为正确识别的故障样本数,ntf为故障样本总数.FAR是指在工厂正常运行期间,正常样本中被确定为故障(或异常)的百分比:
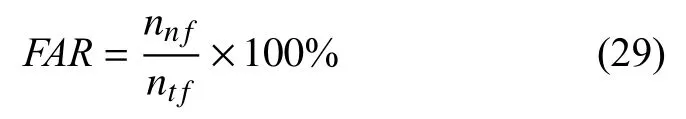
其中,nnf表示被识别为故障的正常样本的数量,ntf为正常样本的总数量.检测延迟为检测到引入故障之前经过的时间.
3.3 应用结果
使用TE 流程的故障11 显示了基于KPCA 的故障检测.故障11 是反应堆冷却水入口温度的随机变化,图2 显示了故障的监控图.实线代表监测指标,红线和绿线分别代表基于高斯分布和基于KDE 的99%置信水平的控制限值.在T2控制图中,基于KDE 的控制限值都低于基于高斯分布的控制限值.即与基于高斯分布的控制限相比,监测指标超出基于KDE 的控制限的程度更大.意味着使用基于KDE 的KPCA 技术的控制限比使用基于高斯分布的控制限具有更高的监控性能.
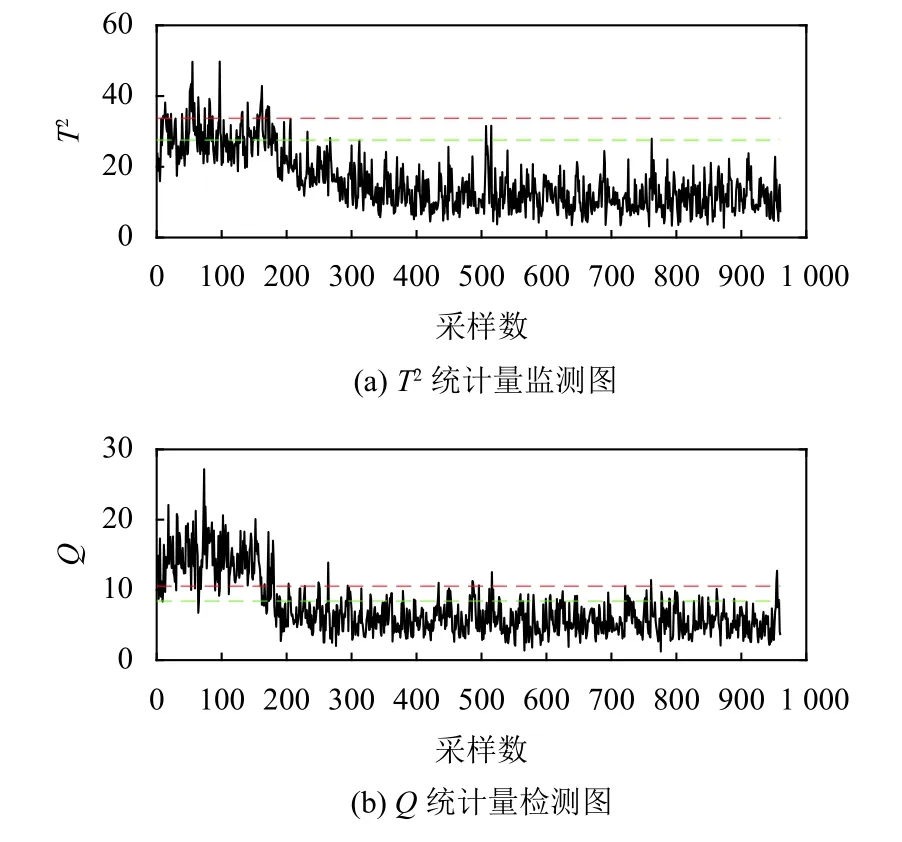
图2 故障11 的监视图
图3 显示了故障14 在ω=40时KPCA 和KPCAKDE 的监视图表.该故障表现为反应堆冷却水阀卡死,大多数统计过程监测方法都能很容易地检测出该故障.在ω=40时,KPCA 和KPCA-KDE 结果一样,在ω=10时,KPCA 记录的误报率为8.13%,而KPCA-KDE 的仍为零.此外,当保留25 个主元个数时,KPCA 记录的误报率也同样高.相反,KPCA-KDE 方法仍然没有记录任何假警报.通过研究KPCA 和KPCA-KDE 所有20 个故障的检出率,结果表明,与相应的基于高斯分布的方法进行比较,KDE 具有较高的故障检出率; 此外,基于KDE 的检测延迟等于或低于其他方法.这意味着基于KDE 控制限的方法比基于高斯分布的同类方法更早地检测出故障.因此,相对于使用基于高斯假设的控制限,将基于KDE 的控制限方法与基于KPCA 的故障检测方法相结合,可提供更好的监控效果.
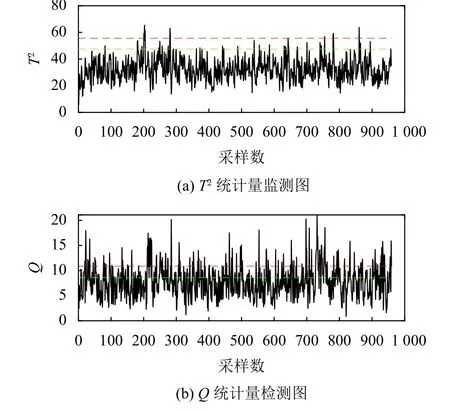
图3 ω=40故障14 基于KPCA 的监视图
以故障11 为例,显示了基于KPCA-KDE 的故障识别.故障11 的出现引起反应堆冷却水流量的变化,从而导致反应堆温度波动.在图4 中所示的样本300处,基于T2和Q的贡献图均正确识别了两个故障变量.变量9 是反应堆温度,变量32 对应于反应堆冷却水流速.尽管控制回路有可能在经过较长时间后补偿反应堆温度的变化,但是通过贡献图可以正确识别出在引入故障后早期受影响的两个变量的波动.
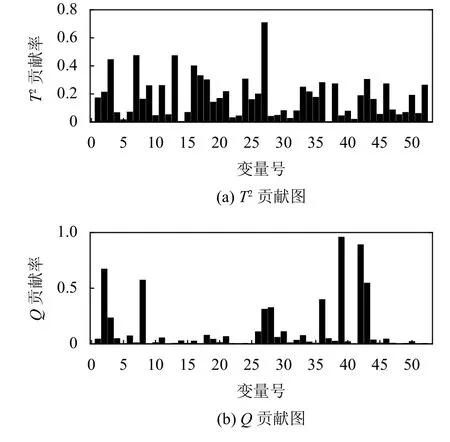
图4 故障11 的贡献图
为了测试KPCA-KDE 技术的性能,通过改变两个参数进行故障检测: 带宽和保留的主元数量.表1 显示,当保留25 个主元时,KPCA 记录的FAR 值也同样高.相反,KPCA-KDE 方法仍然没有记录任何假报警.因此,除了提供更高的FDR 和更早的检测外,KPCAKDE 比基于高斯假设的KPCA 方法监控性能更好,当故障及早发现时,操作人员将有更多的时间找出故障的根本原因,以便采取补救措施.其次,虽然有方法可获得开发过程监控模型的最优设计参数,但不能保证最优值一直使用.造成这种情况的原因可能是人员缺乏经验,以及对流程本身缺乏了解.因此,监控方法性能越好,就更利于过程监控.
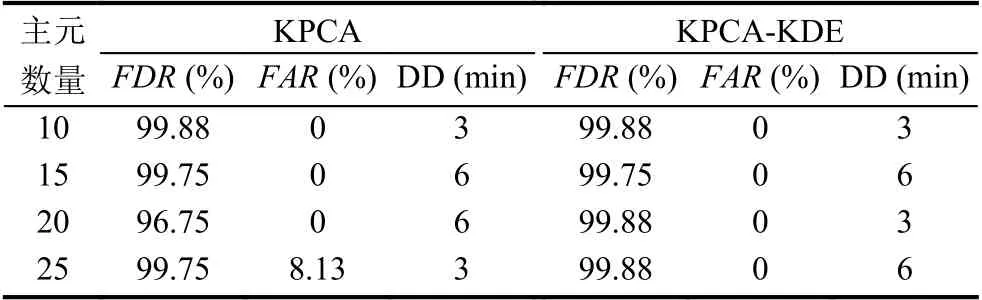
表1 在保留不同数量主元时的监测结果
4 结论与展望
本文研究了基于KPCA-KDE 技术的非线性过程故障检测与识别.在这种方法中,用于构建控制图的控制限是直接从监测指标的概率密度函数得到的,而不是基于高斯分布的控制限.将该方法应用于田纳西伊斯曼过程,并与基于高斯假设的核主成分分析方法进行了性能比较.结果表明,基于KPCA-KDE 比基于高斯分布的KPCA 检测到的故障更多、更早.研究还表明,基于KDE 的控制限比基于高斯假设的控制限更符合监测统计量的实际分布,因此具有更好的监控性能.接下来的研究工作是设计更优化的方法,既在复杂的环境中更能迅速准确的检测出故障,此外,将KPCAKDE 结合自适应算法也是一个有价值的研究方向.
