基于序列到序列模型的观点核心信息抽取
2022-11-05罗雨蒙林煜明
罗雨蒙, 林煜明
(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004)
人根据句子中的观点核心信息能得出其想要表达的主要思想、情感。随着在线评论数据爆炸式地增长,靠人工方法去阅读并提取其中的观点核心信息,以判断商品是否值得购买是十分困难的。近几年,越来越多的研究者对于如何自动地从评论语句中获取观点核心信息展开了广泛地研究。
从句子中提取出观点核心信息是基于方面的情感分析(aspect-based sentiment analysis,简称ABSA)[1]的一项基础任务。该任务旨在从评论句中成对抽取出方面项和观点项(pair-wise aspect and opinion terms extraction,简称PAOTE),方面项描述评论人对什么目标/方面表达了观点,观点项指评论人用什么的词表达观点。例如,在评论句子“这款手机外观好看,续航久,我很喜欢。”中,“外观”和“续航”为方面项(或称观点目标),“好看”和“久”分别为方面项相对应的观点项,〈外观,好看〉和〈续航,久〉为方面-观点项对。
目前相关技术是把从评论句子中提取出的方面-观点项对当作抽取任务来做,其中包含大量词性、语法、规则等复杂的标签,或者是枚举出所有不同跨度的词,会产生大量的负样本。本文将方面-观点项对的抽取任务转换为方面-观点项对的生成任务,提出一种基于Seq2Seq(sequence-to-sequence)模型[2]的端到端生成框架来成对生成方面-观点项对,无需复杂的标注或者大量的负样本。采用大型预训练模型BART[3]的编码器和解码器作为Seq2Seq模型的编码器和解码器,在解码时结合指针机制生成方面-观点项对序列。
1 相关工作
相对于粗粒度(如文档级、句子等)的情感分析,细粒度的情感分析能够提供更准确和深入的用户观点信息。方面项和观点项的成对抽取是细粒度的情感分析任务的一项子任务。
早期的方面项和观点项的联合抽取主要采用基于规则的方法[4-6],这类方法的抽取效果主要依赖于人工预定义的规则或句法模板。随着深度学习技术的发展,深度神经网络常被用于联合抽取方面词和观点词,如基于递归神经网络的方法[7]、多任务学习[8]、注意力网络[9]和图学习[10]等。一些研究者将规则和神经网络模型结合,实现方面词和观点词的联合抽取。Dai等[11]在标注样本的依赖解析结果上自动挖掘抽取规则,将这些规则作为弱监督标注样本,并结合少量人工标注样本训练BiLSTM-CRF模型抽取方面词和观点词。Wu等[12]将一阶逻辑规则整合到深度神经网络中,使模型能根据这些规则纠正错误的预测结果。
上述方法虽然能实现方面项和观点项的抽取,但却忽略了方面项与观点项之间的对应关系。为了解决该问题,Chen等[13]提出一个双通道递归网络分别抽取方面词和观点词,并通过一个同步单元维持通道的同步性实现观点词对抽取。Pereg等[14]通过语法敏感的自注意力机制将外部的语法信息整合到BERT[15]中,并利用外部知识和BERT 内在知识的融合实现跨领域方面词和观点词对抽取。Li等[16]设计一种多跳双记忆交互机制来捕获方面词和观点词的潜在关系。上述工作将抽取看作序列标注问题,这种方法通常由于标签组合爆炸导致搜索空间过大,并且难以处理一个句子中方面词和观点词间一对多和多对多的情况。为此,Zhang等[17]提出了一个基于跨度的多任务框架来同时提取方面项及其对应的观点项。他们受到之前研究[18-19]的激励,提出的框架首先使用基本编码器学习单词级表示,然后列举输入句子中所有可能的跨度。通过共享生成的跨度表示,可以在跨度边界和类标签的监督下提取方面项和观点项。同时,成对关系可以通过计算跨度-跨度对应来识别。因其未能捕获重叠的方面-观点对结构之间的底层共享交互,Wu等[20]提出了一种基于span图的联合PAOTE模型,并在此基础上提出了一种边缘增强的句法图卷积网络(ESGCN),该网络可以同时对语法依赖边和相应的标签进行编码,以增强方面和观点术语的提取和配对。Wu等[21]还通过结合丰富的句法知识来增强方面-观点成对抽取。
本研究将方面-观点项对的抽取任务转换为方面-观点项对的生成任务,提出一种基于Seq2Seq模型的端到端生成框架来直接成对生成方面-观点项对,无需大量的标注样本进行训练,也不会产生大量的负样本,提升了模型的训练效率。
2 所提方法
首先对生成式的方面-观点项的成对抽取任务进行定义,然后介绍所提方法,采用BART模型和指针机制相结合的方式来生成方面-观点词对的序列表示。
2.1 问题定义
给定一个长度为N的输入句子X={x1,x2,…,xN},本文的任务是提取所有的方面-观点项对Y={as1,ae1,os1,oe1,p,…,asi,aei,osi,oei,p},其中:as,ae分别表示方面项开始的索引和方面项结束的索引;os,oe分别表示观点项开始的索引和观点项结束的索引;p表示方面-观点词对之间的间隔标记。一个评论句子中可能包含多对方面-观点项对。
由于本文以生成式的方式表述PAOTE任务,可以将目标函数看成
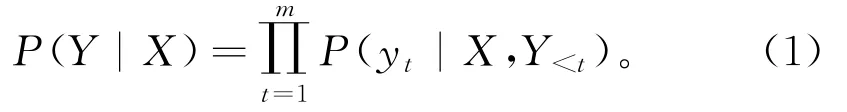
其中:X为输入句子;Y为目标句;m为目标句的长度;当t为0时,y0表示“句子开始”的控制标记。
2.2 基于Seq2Seq的观点核心信息抽取框架
将方面-观点项对的抽取任务转换为文本生成任务,在基于Seq2Seq模型上结合指针机制来生成成对的方面-观点项对,并采用大型预训练模型BART的编码器和解码器作为Seq2Seq模型的编码器和解码器,模型结构如图1所示。该模型主要由三大部分组成:seq2seq的编码器、解码器以及指针机制。其中编码器模块接收文本输入,将文本的所有信息处理成向量传递给解码器模块;解码器模块结合全文的信息和上一时间步的输出,再通过指针机制得到下一时间步的输入文本的位置索引的概率分布,选取得分最高的索引作为下一时间步的输出。

图1 模型结构
2.2.1 编码器
编码器在预训练阶段能很好地结合上下文的信息。BART模型是一个结合双向编码和自回归的大型预训练模型,其主要采用了2种策略。首先使用任意噪声来破坏原文本,然后让模型学习重构原文本,使用掩码替换文本段,从而破坏文本。再用双向编码器编码被破坏的文本,然后再使用自回归解码器计算原始文本的似然值。因此该模型更加适合于生成任务。将句子开头标记〈s〉和句子结束标记〈/s〉分别添加在X的开头和结尾。
在编码器部分,首先将句子X输入进编码器编码成向量

其中:E∈RN×D;N为句子长度;D为隐藏层维度。
因为指针机制是完全依赖输入序列,将其中得分最高的位置索引作为输出,所以本文直接将方面-观点词对之间的间隔标记PAOTE添加在句子后面,以便指针机制做选择。随后得到位置信息向量E1,将向量E与E1进行拼接成E2;将E2进行多头自注意力计算,最后得到每个词与句子所有信息的向量E3。
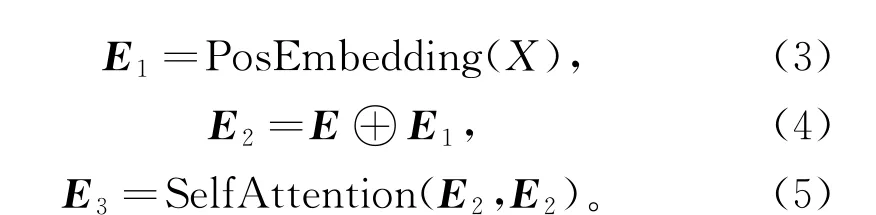
其中,⊕表示向量的拼接。编码器将所得到的词向量E3传给解码器。
2.2.2 解码器
解码器中含有掩码矩阵,遮挡了下文,更适用于生成任务,其每层都与编码器最后隐藏层做一次交叉注意力操作,使其能在每个时间步都能获得不同时刻的侧重信息。为了得到每个时间步输入文本的位置索引概率分布Pt=P(yt|X,Y<t),在解码器部分,首先将向量E3和当前所生成的文本信息处理成向量,再通过解码器解码得到最后的隐藏状态

其中,[;]表示向量在第一维进行连接。
指针机制主要实现输出序列完全源自于输入序列。注意力计算出下一时间步输入序列每个元素的概率,输入序列产生的最大权重的位置索引作为编码器的输出。隐藏状态ht和包含所有信息的向量E3通过指针机制,得到输入序列中每个元素的概率分布

随后选取概率最高的位置索引作为下一时间步输出。
2.3 模型的训练
在训练阶段,采用教师强制法,该方法多用于机器翻译、文本摘要等深度语言模型的训练阶段。该方法不使用上一时间步的输出来作为下一时间步的输出,而是直接使用目标序列中对应的上一项作为下一时间步的输入。如输入句为:“〈s〉Great performance and quality.〈/s〉PAOTE”,目标句为:“〈s〉performance great PAOTE quality great PAOTE”,
将“〈s〉”输入模型,让模型生成下一个单词,假设它生成了“the”,但是本文期望它生成“performance”,教师强制法就是在计算了误差之后,丢弃“the”这个输出,直接将“performance”作为下一时间步的输入,以此类推。此方法可以有效解决缓慢收敛和不稳定的问题。
使用负对数似然损失法,损失函数
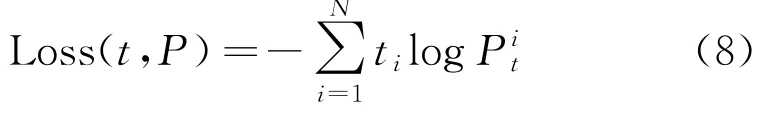
其中,t、P分别表示真实值和预测值。在最后的推理过程中,本文使用自回归的方式生成目标序列。
3 实验
3.1 数据集
在4个公开的ABSA 数据集上评估该模型,其包含餐馆和笔记本2种不同类型的数据。该数据集是由Fan等[22]标注,14lap和14res来源于Semeval 2014 Task 4,15res来源于Semeval 2015 Task 12,16res来源于Semeval 2016 Task 5。如表1所示,其中列举了不同数据集中的评论句数量和方面-观点词对的数量。

表1 数据集
3.2 实验设置
采用BART-Large模型,在所有实验中,BARTLarge的编码器和解码器各有12层,与BERT-Large和RoBERTa-Large模型的transformer层数相同。模型未使用任何其他嵌入,且在优化过程中对BART模型进行了微调。在所有的数据集上采用召回率R、精确率P和F1值3个指标来对模型进行评估。使用倾斜三角学习率预热。实验均在NVIDIA Tesla V100显卡(显存容量16 GiB,显存带宽900 Gbit/s,CUDA核心5120)上进行,使用的超参数详情如表2所示。

表2 超参数
3.3 基线模型
1)GTS-BERT(Wu等[23]):一种基于网格标注的方法提取方面-观点词对模型。
2)Span Mlt[17]:一种基于跨度的多任务学习模型,对方面-观点词对进行成对的抽取。
3)Dual-MRC[24]:一种采用机器阅读理解(machine reading comprehension,简称MRC)方式,由2个MRC组成的联合训练框架,用于解决方面和观点术语的提取和配对问题。
4)ESGCN[21]:一种结合丰富的句法知识来增强方面-观点成对抽取的模型。
3.4 实验结果与分析
本模型与其他基线模型在4个数据集上的实验结果比较如表3所示。

表3 实验结果
从实验结果来看,本模型在14lap、15res、16res这3个数据集上的表现均优于其他基线模型,尤其是在15res数据集上的性能比最佳的基线模型提升了3.74%,在14res数据集上的表现也比大部分基线模型优异。
在不进行任何标注、不产生大量负样本的情况下,采用简单的Seq2Seq模型,端到端地解决了方面-观点词对提取的问题,性能也得到了显著的提升。与ESGCN模型相比,结果在3个数据集上均表现优异,证明BART模型已经习得一定的句法知识,还能提供更多的有效信息。
针对在14res数据集上效果不佳的问题,可简单地使用评论句中包含方面-观点词对的数量来断定句子的复杂程度。根据分析,14res数据集中含有3对及以上对方面-观点词对的评论句数量占比较大,训练集中占23.88%,而其他数据集中只有14%左右。14res数据集中存在多种复杂情况,如一对多、多对一、观点项出现在方面项之前以及一些人脑也难以判断的情况。本模型在这些复杂的评论句中无法很好地处理方面词和观点词、方面词和方面词与观点词和观点词之间的相互依赖关系,导致在复杂的评论句中无法正确地提取所有的方面-观点词对。
3.5 学习率与束搜索
研究不同的学习率和束宽是否对模型性能有影响。首先研究不同学习率对模型的影响,在16res数据集上对于每个大小不同束宽,采用不同的学习率进行实验,结果如图2所示,显示不同的学习率对模型的性能影响较大。在束宽大小不同的情况下,学习率为2×10-5时,性能是最佳的。

图2 学习率
由于本文的框架是基于生成的,随后研究在预测阶段,束宽是否会影响模型性能。束搜索是一种常用的搜索算法,束宽为k表示选取当前概率最大的k个词作为候选输出序列。结果如图3所示,显示束搜索对模型性能的影响较小。
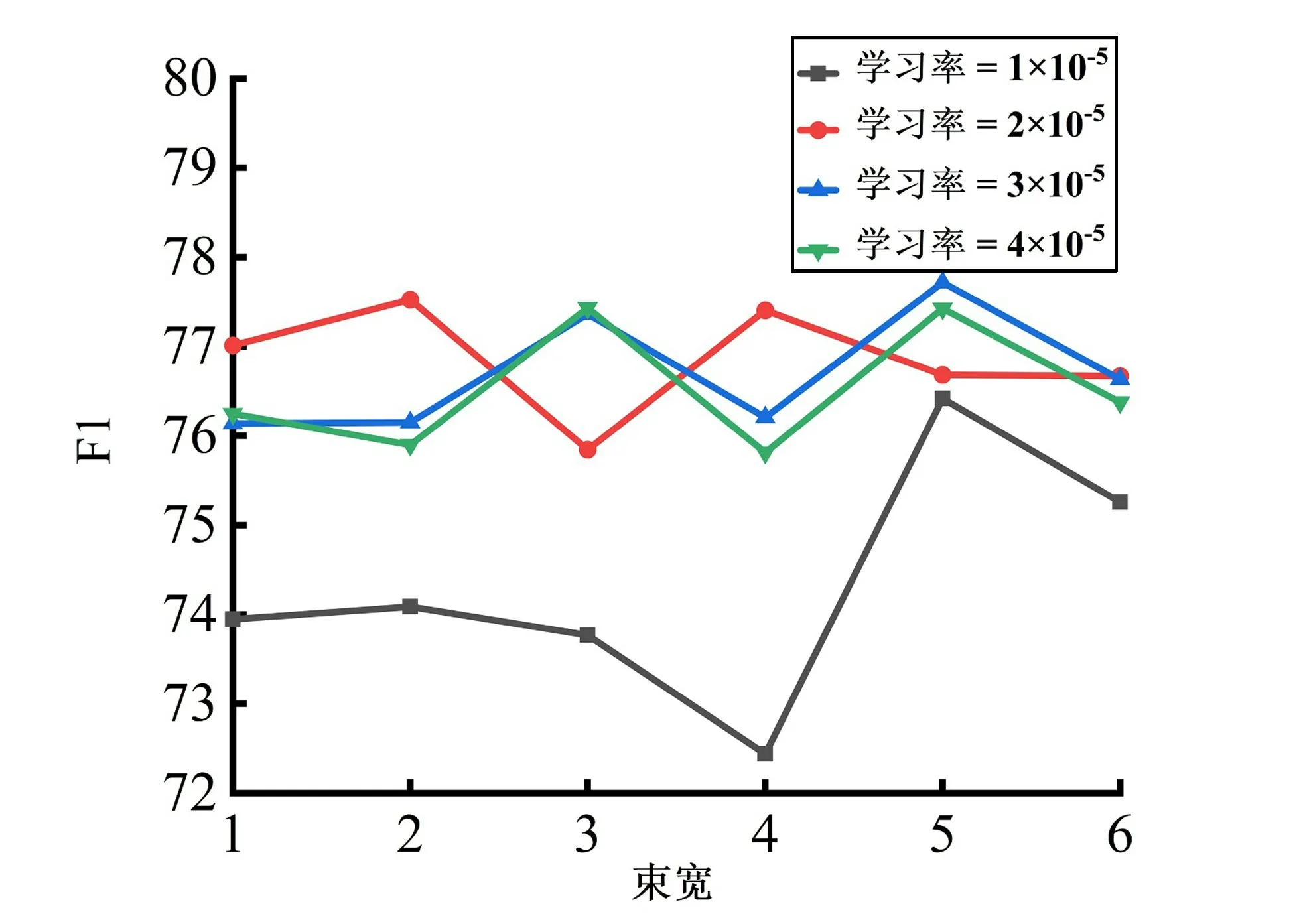
图3 束搜索
4 结束语
将方面-观点项对的抽取任务转换为文本生成任务,采用一个带有指针机制的Seq2Seq模型来成对生成方面-观点项对,无需复杂的标注或生成大量的负样本,使解决方面-观点项对抽取问题的方式更接近人类的逻辑和习惯。根据Seq2Seq模型的特点,采用大型预训练模型BART 的编码器和解码器作为Seq2Seq模型的编码器和解码器,在解码时采用指针机制生成方面-观点词对序列。实验结果表明,本模型在14lap、15res、16res这3个数据集上均优于其他的模型。针对在超长且情况复杂的评论句中含有多对方面-观点项对的提取效果不佳的问题,将会是下一步研究的重点。
