Ceph存储系统中节点的容错选择算法
2022-11-05夏亚楠
夏亚楠, 王 勇
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
随着信息化的普及,各行各业每天产生的数据量都在以指数级的速度快速增长,预计到2025年,全球数据量相较2016年将增加10倍[1]。传统的存储模式已经无法应对海量数据的存储需求,而分布式存储系统通过廉价的商用硬件较好地解决了这一问题,目前投入商业使用的有OpenStack Swift、Amazon EBS、Ceph等[2]。其中,Ceph因具有可扩展性、高性能、统一存储以及适用范围广的优势,被广泛应用于当前主流的软硬平台。
作为分布式对象存储典型代表,Ceph 最初由Weil等开发提出,十多年间已经有超过100家公司(机构)研究与使用Ceph,其中包括欧洲原子能研究组织、Yahoo、阿里巴巴等。同时由于不同的应用场景对存储系统的关注点不同,吸引许多学者开展了一系列针对Ceph性能优化的研究,主要包括读写性能优化、节点工作负载优化、存储数据分布的优化等方面。为了提高Ceph中数据的读写性能,Zhan等[3]针对librados库方法,应用2种多线程算法来优化读写性能,使得大文件的下载速度和小文件的上传、下载速度得到了提升;Ceph节点工作负载方面,Sevilla等[4]设计了可编程元数据存储系统,将策略和迁移机制分离,可以满足用户不同需求时节点负载均衡;在存储节点选择方面,SHA 等[5]根据Ceph的架构和MapReduce的特性,提出了一种混合整数线性规划方法来选择最优的存储节点,解决了Ceph存储系统中应用MapReduce算法配合CRUSH 算法进行节点选择时系统性能较差的问题。但是这些对Ceph集群数据存储位置选择策略和工作负载的研究并未考虑节点间的网络状态信息。
SDN作为一种新的网络模型,解决了传统的网络状态测量方法存在的网络配置复杂且资源消耗较大的问题[6]。目前SDN在网络状态信息测量方面的研究有:Harewood-Gill等[7]针对现有网络方法无法应对Qos要求指数增长的问题,提出利用SDN 综合考虑时延和带宽的Q-Routing算法来选择最佳路径,该算法与K-Shortest Path算法相比具有更快的路径计算速度;Okwuibe等[8]在边缘云环境下提出一种基于SDN的资源管理模型,该模型对内存、带宽等资源进行集中管理,并自动计算不同条件下的最佳资源分配方案,根据预定义的约束动态调整分配的资源,降低了系统的部署成本;王勇等[9]设计出一种SDN与Ceph结合的架构,利用SDN 获取的信息选择性能最优OSD 的方式,显著提升了Ceph的读性能。这些工作为在Ceph中获取网络状态信息来进行节点选择提供了有力依据。
虽然国内外学者在Ceph性能优化和利用SDN优化网络存储方面取得了很多成果,但较少有研究从利用SDN获取的网络信息来增强系统容错性的角度优化Ceph性能[10]。因此,考虑Ceph集群中节点的负载状况,结合SDN中集中控制思想,给出一种提升集群故障节点修复性能的节点容错选择(fault-tolerant node selection based on Ceph,简称FTNSC)算法。
1 Ceph数据修复过程及问题描述
Ceph的三副本模式提供了良好的容错性,使得在出现磁盘故障、服务器宕机等故障时不会出现数据丢失,但在故障发生后仍需对丢失的副本数据进行修复,以保证数据的高可靠性[11]。按照是否能够依靠日志进行修复,Ceph中存在2种修复方式:Recovery和Backfill[12]。考虑受损副本能够通过日志进行修复的Recovery过程。根据受损副本存在的位置不同,Recovery有2种修复的方式,当降级对象在Primary PG上时,Primary PG所在主OSD会通过Pull方式从其他的副本拉取待修复对象的权威版本至本地完成修复;当其他副本存在降级对象时,Primary PG所在主OSD 会通过Push方式主动将待修复对象的权威版本推送到目标副本,由副本完成修复[13]。最后当数据修复工作完成后,副本中的数据恢复一致。若数据放置节点的负载较高或节点间网络状态较差,将会影响数据修复过程的修复时延。
Ceph中数据的映射过程如图1所示,从图1可知,Ceph将数据映射到OSD上主要分为3步:1)将文件切分为同等大小的多个对象,每个对象获得唯一的ID,记为oid。2)利用哈希函数对每个oid进行哈希运算,得到的结果与mask(mask=PGs-1)值按位进行与操作,生成PG的编号pgid。3)通过crush算法将PG映射到OSD中。此过程运算如式(1)所示。
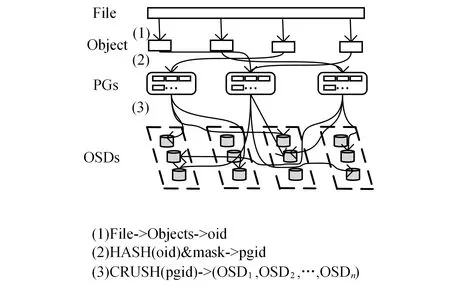
图1 数据映射过程

其中:CRUSH_Map表示保存集群拓扑状态等信息的映射表;CRUSH_Rule表示副本的容错规则,最终得到存放三副本的3个OSD,其中编号最小的为Primary OSD(主OSD),剩余的为Replica OSD(次OSD)。在CRUSH 算法中,CRUSH Maps作为记录存储集群的层级结构与副本映射以及节点权重的参数,将存储容量作为权重决策的唯一因素,却未考虑节点负载和网络状态对于集群的影响,这会导致节点负载过高或网络性能很差的节点仍会被选为存储节点,影响集群的整体性能。
根据对Ceph发生故障时的数据修复过程和节点的选择算法分析发现,虽然Ceph的节点选择策略能够将数据均匀地分布在集群中的同时,也保证了集群的稳定性和灵活性,但是由于CRUSH 过程将节点的剩余存储容量作为数据映射过程中选择主次OSD的唯一决定因素,当有节点发生故障时较高的节点负载和副本之间较差的网络状态会导致节点的修复时延较长,后续故障会导致更高的数据丢失概率。针对上述问题,综合考虑异构节点的性能和副本之间的网络状态,建立优化Ceph系统性能的存储节点选择模型,以期在节点发生故障时能够尽快地完成数据修复,减少发生数据损坏的风险。
2 Ceph分布式存储系统的节点容错选择算法
在具有N个OSD节点的Ceph集群中,每个节点最多可存放一份数据副本,将副本数设为3,则Ceph中的节点容错选择问题可总结为选择合适的放置数据副本的OSD集合,使得节点出现故障时,最小化节点的数据修复时延。根据对节点容错选择方法的定义,按两阶段分别对主、次OSD进行选择。
2.1 副本放置问题建模
将节点故障后的修复时延定义为2部分:节点处理时延和数据传输时延,具体模型构建流程如图2所示。
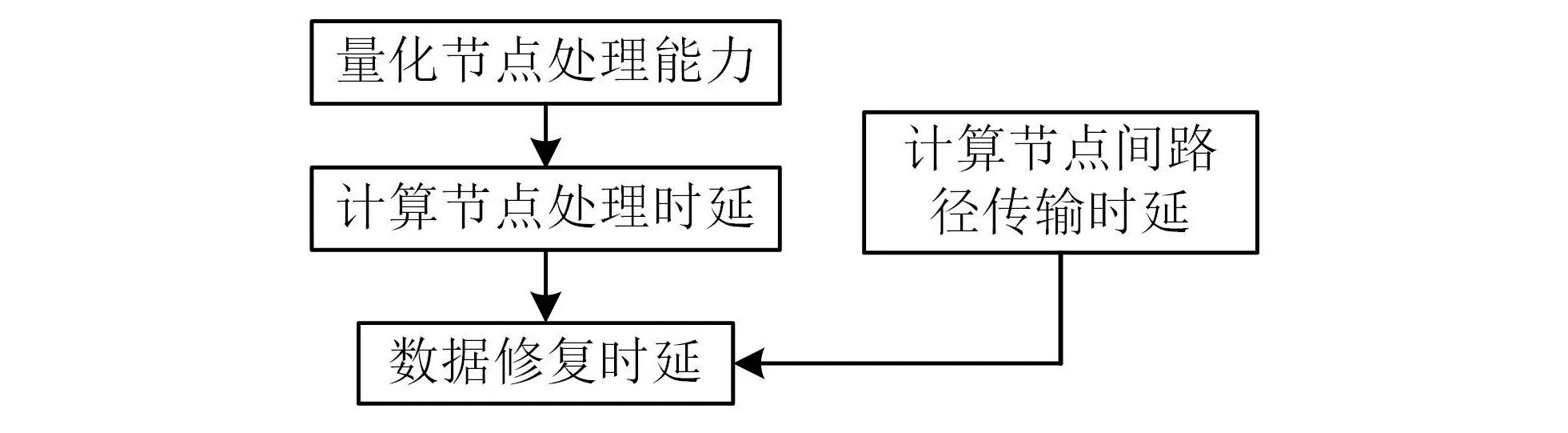
图2 模型构建流程
对于节点的处理时延,考虑节点异构对于节点数据处理能力的影响,采用齐凤林等[14]对节点处理能力的定义。考虑影响节点处理能力的因素有CPU性能、IO速率、内存及芯片,分别用f1,f2,f3,f4来表示,并为这些影响因素分配相应的权重w1,w2,w3,w4,则节点i的处理能力可表示为p=1

假设节点Ni需要处理的数据量为D,能力转化系数为∂,则节点Ni对数据的处理时延为

对于数据的传输时延,参考秦华等[15]对传输时延的定义,将传输路径上各段链路的传输时延之和作为端到端的传输时延,设E(Ni,Nj)为节点Ni与Nj之间的传输路径,b为路径带宽,则节点Ni与Nj之间的传输时延为

在对失效节点的数据进行修复时,若是主OSD故障,则需要从次OSD拉取需要修复的数据到本地;若次OSD发生故障,则需主OSD 主动将数据Push到次OSD,整个数据修复时间包括源节点和目的节点的处理时间以及数据的传输时间:
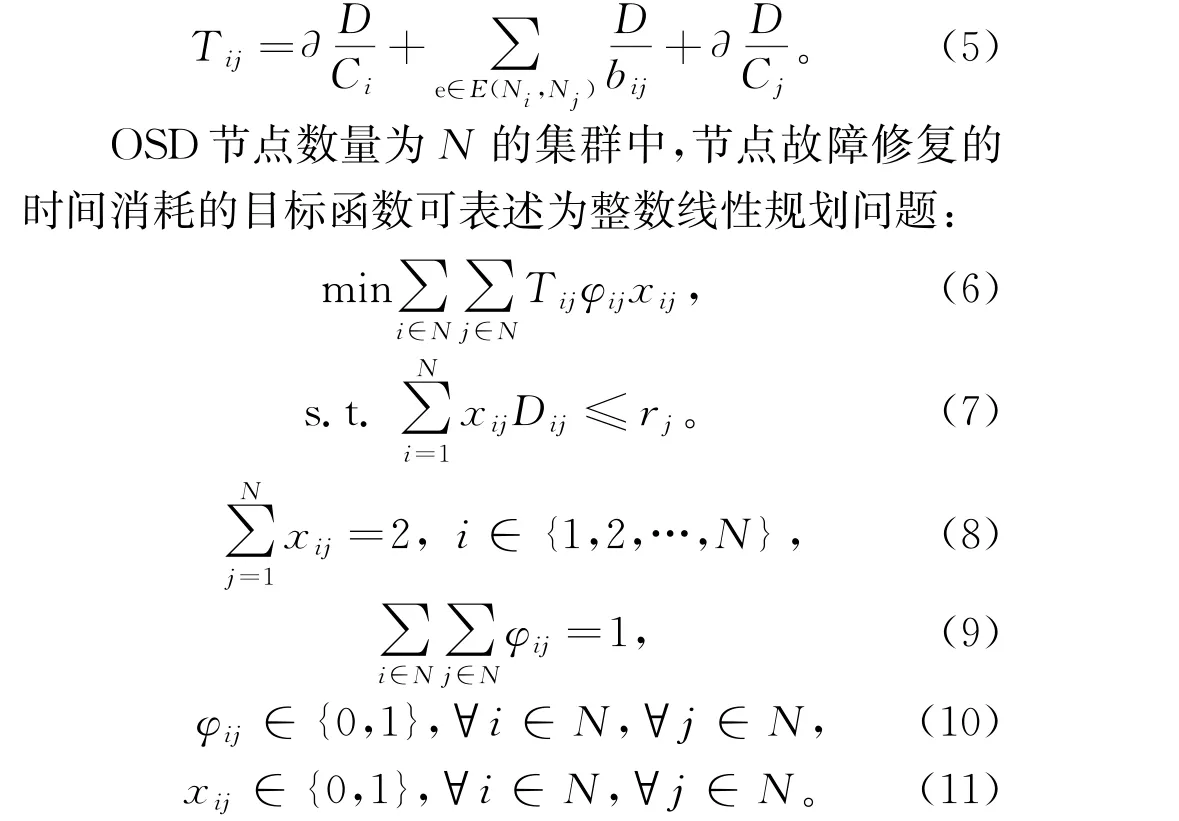
其中,约束条件(7)中rj表示节点j的剩余容量,Dij表示从节点i传输到节点j的数据量,式(7)确保放置副本内容资源请求不超过节点的剩余容量。约束条件(8)表示共有2个节点为节点i的数据提供副本访问,即保证每份数据的三副本存储。式(9)表示只考虑单点故障即一次修复操作只修复一个失效节点。式(10)中,φij为二进制决策变量,当φij值为1时,表示节点i将修复数据发往节点j,对节点j进行故障修复,当φij值为0时则反之。式(11)中,xij表示副本放置的决策,xij=1时,表示节点j为节点i提供副本访问,当xij值为0时,表示节点j为节点i提供副本访问。
2.2 基于多属性决策的主OSD选择
根据Ceph数据映射过程可知,在Ceph的节点选择中仅仅以节点的剩余存储容量作为节点被选择的权重因子。对此在考虑节点剩余容量的基础上增加节点CPU、IO、芯片3个指标作为节点选择的权重因素,使用基于理想解的副本选择方法确定出具有最优处理性能的节点,作为副本数据存放的主OSD。
逼近理想解排序法(technique for order preference by similarity to ideal solution, 简称TOPSIS)是一种有效的多属性决策方案,该方法从归一化的原始数据矩阵中构造出决策问题的正理想解和负理想解,通过计算各方案与正、负理想解的距离作为评价方案的准则[16]。主OSD选择算法设计如下:
步骤1:决策矩阵构造及其归一化
设基于多属性决策的主OSD 问题中有m个节点,得到节点方案集P={P1,P2,…,Pm},每个节点有4个属性指标,构成节点属性集A={A1,A2,A3,A4},决策矩阵构造如下:

步骤2:构造加权决策矩阵
OSD节点的CPU、I/O、内存及芯片对节点处理能力的影响是不同的,对于相对重要的属性如I/O分配较大的权重因子,每个属性分配的具体权重Wj通过实验的方式获取[17]。得到加权决策矩阵

其中,Z+表示加权决策矩阵的正理想解,由集群中所有候选节点上每种属性的最大值构成;Z-表示加权决策矩阵的负理想解,由集群中所有候选节点上每种属性的最小值构成。
步骤4:计算每个候选节点到正负理想解的距离


2.3 基于人工蜂群算法的次OSD选择
FTNSC算法在2.2节得到的节点性能最优的主OSD基础上,考虑节点性能以及与主OSD之间的网络状态对数据修复时延的影响,计算出不同候选节点的适应度值,通过人工蜂群算法选择出合适的次OSD节点。
人工蜂群(artificial bee colony,简称ABC)算法是一种模拟蜂群寻找蜜源过程的群体智能优化算法,具有结构简单、控制参数较少及鲁棒性强等特点。人工蜂群中的蜜蜂分为3种:雇佣蜂、跟随蜂和侦查蜂。3种蜜蜂通过分工协作开采蜜源,并通过蜜源的标记与不断分享更新位置寻找最优蜜源,即问题的最优解[18]。其中,蜜源的位置对应优化问题的一个可行解,蜜源的蜜量对应适应度值。算法步骤如下:
1)解的构造和编码:基本的ABC算法适用于连续型论域,并不适用于本节点选择问题的整数编码方式,因此将其进行离散化处理。假设集群中共有N个OSD节点,主OSD 的数据需要选择2个次OSD进行放置,则解的构造如式(20)所示。
xi={x1i,x2i},xji∈[xjmin,xjmax],i=1,2,…,N。(20)
其中:xi为第i个蜜源,即第i个节点选择方案;xji表示第j个次OSD 选择为编号为i的节点存储数据;xjmax、xjmin分别代表集群中OSD节点编号的上限和下限。如编码{3,17},表示第一个次OSD节点选择集群中id=3的节点,第二个次OSD 选择集群中id=3的节点。

3)确定适应度函数值:对于每个初始解,根据式(22)计算其适应度值,判断蜜源的优劣。

设选择出来的最佳主OSD节点编号为bm,则基于人工蜂群算法的次OSD选择算法的适应度函数表示选取具有节点处理性能以及与节点bm之间网络状态最好的节点作为次OSD,来减少发生故障时数据的修复时延。

5)跟随蜂阶段:雇佣蜂完成邻域搜索后,跟随蜂接收到雇佣蜂分享的信息后进行进一步开采,通过轮盘赌算法按式(25)计算的概率选择蜜源,蜜源的适应度值越大,被跟随蜂选择的概率越大。
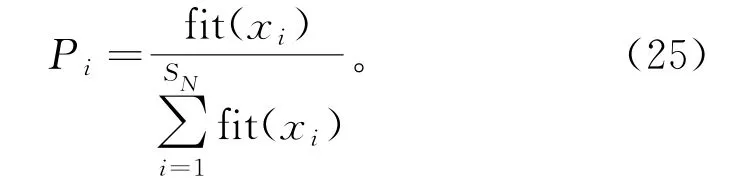
6)侦查蜂阶段:设定蜜源的开采上限为l次,若蜜源经过l次迭代后适应度值仍无变化,则为了防止陷入局部最优,将此蜜源淘汰,用式(21)产生的新蜜源替换。
迭代完成后,将适应度值最大的蜜源作为最优解,得到存放副本的2个次OSD节点,算法结束。
3 实验设置与性能评估
为评估FTNSC算法的性能,在Mininet[19]网络模拟器上模拟和构建Ceph集群拓扑,并在SDN 控制器Ryu[20]上部署FTNSC算法。仿真实验环境为:Intel Core i5-4210,操作系统为VMware Ubuntu 14.0,4 GiB 内存,Mininet版本为2.3.0,Ryu 4.34以及1.3版本的Openflow协议。
将拓扑中存储节点的个数设为24,节点中的数据采取三副本法则进行设置,网络拓扑采用无向完全图。模拟实验场景中的异构存储节点的处理能力服从文献[8],各异构节点性能参数及其取值范围为{CPU,[1,90]}, {I/O,[21,265]},{内存,[0.3,76]}, {芯片,[0.5,23]},对应的权重分别为30%,40%,20%,10%,节点能力转化系数∂为0.3。设置集群网络拓扑中各链路的可用带宽随机均匀分布在50~100 Mbit/s,默认链路(Vi,Vj)与(Vj,Vi)相互独立且大小相等。
Ceph集群中的失效节点的数据修复考虑2种情况:首先是降级对象发生在主OSD 节点,此时主OSD通过Pull方式从2个次OSD上拉取缺少的数据;当次OSD 存在降级对象时,主OSD 通过Push方式主动将缺失数据推送到相应的副本,本实验中随机设定故障节点来模拟Ceph集群中单节点失效的修复过程。算法分为2 个阶段,第一个阶段为主OSD的选择过程,通过SDN 获取异构节点的CPU、IO、内存以及芯片4个指标,并将其作为节点选择的权重因素,使用基于理想解的副本选择方法确定出具有最优处理性能的节点。第二个阶段在第一阶段选择出主OSD基础上,考虑节点性能以及其与主OSD之间的网络状态对数据修复时延的影响,计算出不同候选节点的适应度值,通过人工蜂群算法选择出合适的次OSD节点。算法中涉及的参数如表1所示。
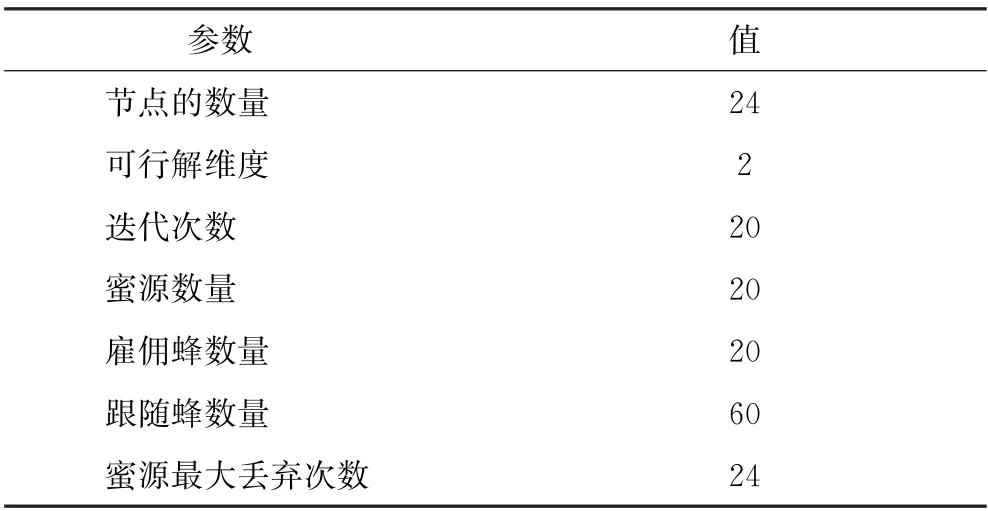
表1 算法参数取值
将FTNSC 算法与Ceph 云存储系统原生的CRUSH 算法以及NSMBD 算法[8]进行对比实验。其中,CRUSH 算法作为Ceph云存储系统数据映射过程的经典算法,将存储节点按剩余存储容量进行排序,选择存储容量性能最优的3个节点。NSMBD是一种有效的针对小文件的Ceph存储系统节点选择方法,其利用SDN获取集群中的网络带宽性能,并用逼近理想解排序法选择出性能最优的3个节点来存放数据副本,以提高读写操作的吞吐量和响应时间。实验测试数据修复时延,从所选节点的CPU、IO、内存、芯片角度对比3种算法的性能,每组实验测试5次,取平均值作为实验结果。
3.1 节点故障的数据修复时延
为了测试3种不同算法对于不同大小数据修复对象的修复时延的性能,如图3所示,实验中制定了50、100、150、200、250、300 MiB 6种对象的工作量,比较Ceph原有的CRUSH 算法、NSMBD算法和本算法在不同修复数据对象时,完成故障节点数据修复的时间。

图3 数据修复时延
从图3可看出,对于6种不同规模的修复数据,FTNSC算法均拥有最优修复时延,且对于200 MiB以下的小规模修复数据有明显提升,当修复数据的规模大于200 MiB时,数据修复时延的提升较小。由于CRUSH 算法选择集群中剩余容量性能较优的节点存储数据,但在节点发生失效而进行数据修复时,仍无法避免较差的网络性能和节点其他性能的影响,导致修复时延较大。随着修复数据量增大,上述缺陷得到一定程度的改善,但CRUSH 算法的修复时延在3种算法中仍最长。在不同的修复数据规模场景下,FTNSC算法的数据修复时延较CRUSH 算法减少了2%~29.7%,较NSMBD 算法减少了1.8%~18.4%,这是由于在实验场景中引用了存储节点处理能力的异构和拓扑网络状况,为副本数据选择性能最优的节点进行存储。
3.2 三副本节点性能
图4为在修复数据大小为150 MiB,异构节点的能力转化系数为0.3时,FTNSC算法、NSMBD算法和CRUSH 算法所选OSD节点的CPU、IO、内存及芯片性能情况。

图4 节点性能
在节点的CPU、IO、芯片性能中,FTNSC算法所选主OSD的性能明显优于CRUSH 算法和NSMBD算法,这是由于FTNSC算法不仅考虑了集群节点的4种资源指标,还分别考虑了各个资源指标的权重情况,降低了所选节点某项资源指标性能较差的可能。对于次OSD,FTNSC算法在CPU 性能和IO速率上表现较好,但在内存和芯片性能上提升并不明显。Ceph存储系统中的2种数据修复都依靠主OSD通过Pull或Push方式从次OSD中选取一个节点获取或发送失效数据,因此相对次OSD而言,主OSD在失效节点修复过程中具有更加重要的作用。在内存方面,CRUSH 算法性能优于FTNSC 算法,这是由于CRUSH 算法以内存作为节点选择的唯一标准。综合4种指标,FTNSC算法所选节点的性能优于另外2种算法,使得在发生节点失效时,节点具有更高的处理能力,从而减少数据修复的时延。
4 结束语
针对云存储系统中大量使用廉价商用硬件引起的频繁的节点失效问题,提出了一种Ceph存储系统中FTNSC算法,通过优化副本放置的节点位置来减少节点失效时的数据修复时延。首先利用软件定义网络技术,获得实时的网络状态和节点负载信息,并将其作为节点选择方法的数据支撑;然后通过建立综合考虑节点负载信息的多属性决策数学模型确定主存储节点位置;最后通过人工蜂群算法,根据与主存储节点之间的网络状态以及节点性能得到最优次存储节点。实验结果表明,FTNSC可以提高所选节点性能,同时减少数据的修复时延,降低集群中数据丢失的风险,从而提高整个存储系统的可靠性。下一阶段将考虑将FTNSC算法应用到开源Ceph云存储平台上,产生实际价值。同时可以在SDN监控的消耗问题上做进一步的研究,讨论测量过程中对Ryu控制器的性能和交换机的带宽资源的消耗。
