基于改进蚁狮算法的虚拟机放置方法
2022-11-05刘耀鸿
刘耀鸿, 王 勇,2
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学 广西云计算与复杂系统高校重点实验室,广西 桂林 541004)
云计算已经成为信息行业的主要计算模式,它可以根据用户的需求来提供相关的计算资源,用户不需要关注基础设施内部的更新和维护细节[1]。这样提供资源的云服务提供商就与需要计算资源的客户建立了联系,形成了一条供应链,在虚拟化技术的基础上通过虚拟机和物理机的映射关系来满足用户的需求[2]。随着云计算的发展,虚拟化技术成为了人们关注的重点。通过虚拟化技术,可以把软件资源和硬件资源结合起来,在成本开销相对较少的情况下满足用户的计算需求[3]。
云数据中心的能源问题一直是一个至关重要的问题,它对环境和成本会产生直接的影响[4]。能源消耗、二氧化碳等问题在不断产生,使得云数据中心的能源管理面临更大的挑战。对于大型的云数据中心,能源消耗不可忽视。物理机所产生的能源消耗约占总体能源消耗的60%。一台物理机所产生的的能耗主要由其资源上限以及部署在物理机上的虚拟机请求资源的总和所决定[5]。在通常情况下,一台空闲的物理机产生的功耗占它最大功耗的70%[6],因此对云数据中心的物理机功耗进行控制,减少空闲物理机的数量至关重要。Beloglazov等[7]指出好的虚拟机放置策略能有效减少能耗,并且提高QoS。通过优化虚拟机放置策略,可以将虚拟机更多地放置在资源利用率更高的物理机上,同时将空闲虚拟机关闭,能够最大限度地减少活动物理机的数量,从而降低能耗。除此之外,虚拟机放置的不合理会导致剩余资源不均衡,进而产生资源碎片,大量资源碎片的产生则会造成数据中心效率的低下[8]。因此,在虚拟机放置的过程中,充分考虑各台物理机的负载均衡,有助于减少资源碎片,使得数据中心的资源使用更加高效。
Jangiti等[9]提出了一种基于资源比率的PM 选择算法PMNeAR,该算法会根据虚拟机请求CPU 资源与内存资源的比例将该虚拟机放置在剩余CPU和内存比例最接近的物理机上,在减少资源消耗方面相比其他算法有一定的提升效果。Tarafdar等[10]提出了一种能耗和服务质量感知的虚拟机整合算法EQC,通过马尔可夫模型预测出空闲和过载物理机,并对它们进行迁移,旨在保证服务质量的前提下降低数据中心的能耗,该算法在降低能耗、保证服务质量和减少迁移次数方面有一定的效果。Farahnakian等[11]提出了一种UPBFD 算法,并使用k-近邻回归模型对资源使用率进行预测,将过载物理机上的虚拟机进行迁移,该算法在减少能耗、迁移次数和SLA 违反次数上有一定优势。上述近似算法在求解过程中有时间开销小的优点,但是近似算法通常是根据当前状态得到一个最优解,这个解不一定是全局最优解。文献[12-16]采用智能优化算法进行求解,智能优化算法是通过全局搜索来找到可行解。在多目标优化过程中,一般是将多个目标通过线性加权的方式整合成一个优化目标,再通过智能优化算法进行求解。Parvizi等[12]针对能耗、资源利用率、活动物理机数量进行优化,在引入非线性凸优化解后,提出了一种非支配排序遗传算法,在与其他基础算法比较中有一定的提升。蔺凯青等[13]提出了一种基于离散蝙蝠算法的虚拟机放置算法(DBA-VMP),对经典蝙蝠算法进行改进。相比其他几种多目标优化的VMP算法,该算法在保证QoS的前提下在降低能耗和提高资源利用率两方面取得了一定的效果,但是未对QoS做出进一步优化。李双俐等[14]提出了一种基于Memetic的虚拟机放置方法,首先对虚拟机的请求进行分类,然后通过改进的Memetic算法进行求解,除了在降低能耗、提高资源利用率和保证QoS上有一定的提升效果,计算时间开销相比其他智能算法也有一定程度的减小。马小晋等[15]在模拟退火算法的基础上进行改进,提出了一种基于改进模拟退火算法的虚拟机调度方法,针对资源利用率、执行成本和负载均衡这3个目标进行多目标优化。为了避免陷入局部最优,引入了并行的思想,根据执行成本和执行性能生成两组解并进行迭代,最终效果有一定提升。Tang等[16]提出了一种混合遗传算法,它不仅考虑了物理机的能耗,还考虑了通信网络的能耗,相比于普通遗传算法有着更高的性能和效率。以上这些研究大多是针对能耗、资源利用率进行优化。但在虚拟机放置的过程中,不合理的放置造成大量资源碎片的产生也同样会导致能耗较高、资源利用率低下的问题。因此,文献[17-18]主要将资源的负载均衡及资源碎片最小化作为优化目标。Li等[17]提出了一种基于BBO 算法的多目标虚拟机放置算法,针对CPU、内存和带宽资源的负载均衡进行优化,同时考虑物理机之间的负载均衡及单个物理机内部的负载均衡,取得了一定的效果。Ghasemi等[18]提出了一种基于负载均衡的多目标虚拟机放置算法,该算法使用了强化学习的方法,除了关注物理机内部的资源平衡,还关注物理机之间的负载均衡,这样能使资源分布更加均衡的同时减少运行时间。
上述研究中存在一些不足,例如在用启发式算法进行求解时,大多数只考虑了能耗、资源利用率,很少考虑资源碎片的问题,而资源碎片也是虚拟机放置中的一个关键指标,关系着虚拟机整合效果的好坏,且这类算法很容易陷入局部最优解。因此,提出一种基于蚁狮算法的虚拟机放置算法(MALO)。通过对传统蚁狮算法进行调整,使得种群的随机性和多样性大大提升,能有效避免陷入局部最优解。
1 模型设计
1.1 虚拟机放置问题定义
虚拟机放置问题实质上可看作一个多维装箱问题,也是NP hard问题。假设云数据中心有m台虚拟机、n台物理机,虚拟机放置问题也就是通过合理的调度策略将m台虚拟机放置在n台物理机上,且满足一定的约束条件。问题定义如下:
数据中心中m台虚拟机组成一个虚拟机列表V={V1,V2,…,Vm},n台物理机组成一个物理机列表H={h1,h2,…,hn}。规定每台虚拟机请求的资源及物理机的资源包括CPU 和内存2种。第i台虚拟机请求资源为Ri=(ui,wi),其中:ui表示第i台虚拟机请求的CPU 资源;wi表示第i台虚拟机请求的内存资源。数据中心物理机的CPU 资源容量列表为Rcpu={c1,c2,…,cn},其中cj表示第j台物理机的CPU 资源容量。数据中心物理机的内存资源容量列表为Rmem={m1,m2,…,mn},其中mj表示第j台物理机的内存资源容量。并且还需要满足以下约束条件:

其中:i=1,2,…;m,j=1,2,…,n;Xij表示虚拟机Vi是否放在物理机hj上,它有2种取值1和0,1表示虚拟机Vi放在物理机hj上,0表示虚拟机Vi未放在物理机hj上。式(1)表示一台虚拟机最多只能放置在一台物理机上,式(2)和式(3)表示所有虚拟机请求的CPU 和内存资源总量不能超过当前物理机CPU 和内存资源总量。
1.2 能耗模型
当前数据中心的高能耗问题已经引起了足够的重视,如何降低能耗已成为研究者研究的重点问题。假设当前数据中心有m台虚拟机和n台物理机,第i台物理机hi处于满载状态时的功耗为hfull_poweri,当前的CPU 利用率为hcpu_utii。 在通常情况下,可认为物理机的功耗与其CPU 利用率呈正相关关系,能耗模型为:

其中:α表示空闲物理机占满载物理机功耗的百分比,α的范围一般在0.6~0.7,本研究统一取0.7;yi表示第i台物理机是否为活动物理机,它的取值为0或者1,1表示活动物理机,0表示非活动物理机;Etotal表示的是数据中心的总能耗,在完成虚拟机的放置时,默认当前时刻的总功耗值为数据中心所有物理机产生的能耗。
1.3 资源使用率模型
假如当前数据中心有m台虚拟机和n台活动物理机,资源使用率包括CPU 和内存资源的平均资源使用率2种,且在计算时只考虑活动物理机,而不考虑负载为0的物理机。资源使用率模型为


1.4 资源平衡度模型
假设数据中心有m台虚拟机和n台物理机,为了使虚拟机的放置更加均衡,提出了一种基于比值的资源平衡度的模型,当一台物理机的CPU 利用率和内存利用率的比值越接近于1时,则代表这台物理机的资源利用更加均衡。数据中心的资源平衡度模型为
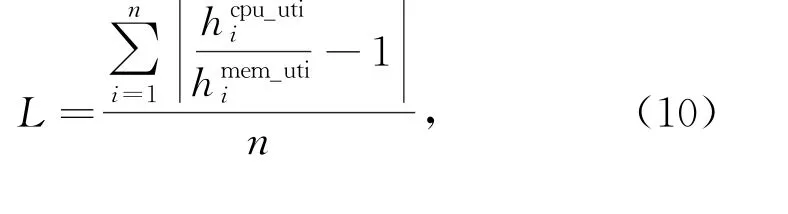
其中:hcpu_utii表示第i台物理机的CPU 利用率;hmem_utii表示第i台物理机的内存利用率。
1.5 资源碎片模型
在当前数据中心,不合理的虚拟机放置策略可能会造成资源碎片的产生,资源碎片即物理机上CPU资源和内存资源不平衡,导致剩余资源无法再满足新的虚拟机请求,随着资源碎片的累积,会造成资源利用率低下及资源的浪费。资源碎片定义为

其中:fcpu表示CPU 资源碎片;fmem表示内存资源碎片;hcpu_remi表示第i台物理机的CPU 剩余量;hmem_remi表示第i台物理机的内存剩余量。yi表示是否满足式(12)和式(14)资源碎片的条件,如果满足yi为1,否则为0。
1.6 虚拟机放置目标函数
一个数据中心的虚拟机是否高效、合理,关键是能否降低能耗、提升资源利用率,并减少资源碎片的产生。低能耗和高资源利用率能使数据中心的成本降低。而虚拟机放置是否平衡同样影响着数据中心的高效性,如果服务器上资源放置不平衡,会导致资源碎片的产生。
根据上述分析,优化目标主要是最小化能耗、资源碎片,最大化资源利用率。虚拟机放置目标函数为

其中:F表示目标函数的适应度函数值,这里先将能耗和资源平衡度进行归一化,再通过加权的方式将多个目标整合成单目标;r表示一个参数,当r值越大,表示能耗占的比重更大,主要考虑降低能耗,反之则表示资源平衡度占的比重更大,主要考虑虚拟机放置更加平衡,减少资源碎片。为了平衡能耗和资源平衡度的影响,将r的值设为0.5,此时能取得更好的放置效果。
2 基于改进蚁狮算法(MALO)的虚拟机放置方法
本质上来说,虚拟机放置问题是一个非线性的优化问题,它产生的解是离散式的,因此不适合用一般的数学方法求解。在大多数情况下,虚拟机放置问题利用启发式算法来求解,如蚁群算法、遗传算法及粒子群算法等。蚁狮优化算法(antlion optimization,简称ALO)具有简单、调节参数少、鲁棒性比较强等优点,在求解一些复杂问题时有一定优势,但也存在不足,主要是易收敛过快,难以跳出局部最优解。因此,为了解决这类问题,需要对ALO 算法的相关步骤进行改进。
蚁狮优化算法的步骤如下:
Step1:初始化算法的参数。种群的大小为N,迭代次数为T,解的维度为dim,解的上界和下界分别为bu,bl。对N个蚂蚁和蚁狮的位置进行随机初始化:
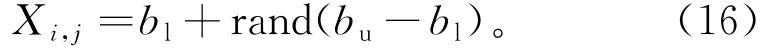
其中:Xi,j表示第i个种群个体的第j维进行初始化,i=1,2,…,N,j=1,2,…,d。将蚂蚁的位置和蚁狮的位置保存在矩阵中,根据目标函数计算出每个个体的适应度,并按适应度进行排序,适应度最优的位置即为精英蚁狮的位置。
Step2:通过轮盘赌策略选择蚁狮,不同位置的蚁狮被选中的概率也不一样,一般来说适应度越好,被选中的概率越大。
Step3:蚂蚁围绕轮盘赌策略选择的蚁狮和精英蚁狮进行随机游走,随机游走的方向和距离由随机函数控制。随着迭代次数的不断增加,蚂蚁随机游走的边界也在不断缩小,越来越接近最优解,边界变化如式(17)所示。最后对蚂蚁的位置进行更新,如式(19)所示。

其中:I随着迭代次数的增加而增大;t为当前迭代次数;T为总迭代次数;W的值由当前迭代次数决定;Ati表示第i个蚂蚁在第t次迭代中的位置;RtA表示由轮盘赌选择的蚁狮在第t次迭代中的位置;RtE表示精英蚁狮在第t次迭代中的位置。
Step4:在蚂蚁位置更新后会计算当前蚂蚁的适应度,若当前蚂蚁的适应度优于当前蚁狮,则蚁狮会捕获蚂蚁,并将蚁狮的位置更新为蚂蚁的位置。
Step5:迭代次数递增,若当前迭代次数达到最大迭代次数,则输出精英蚁狮的位置,即为全局最优解;否则,重复Step2到Step5,直到满足条件为止。
针对ALO算法容易产生的问题,提出了一种改进的蚁狮算法(modified antlion optimization,简称MALO)。算法的主要流程如下:
输入:vmList,pmList
输出:Pos_Elite
T:最大迭代次数;iter:当前迭代次数;N:种群数量;
Pos_Ant:蚂蚁位置;Pos_Antlion:蚁狮位置;
Pos_Elite:精英蚁狮位置;
Step1:按照式(16)初始化N个蚂蚁和蚁狮个体的位置。
Step2:计算每个蚁狮个体的适应度函数值,并按适应度函数值从小到大排序,适应度值最小的个体位置即为Pos_Elite。
Step3:若iter≤T,进行迭代,在迭代过程中边界的变化如式(20)所示,每个蚂蚁个体会围绕轮盘赌策略选择出的蚁狮以及Pos_Elite进行式(22)所示的随机游走。若此时Pos_Ant>bu或者Pos_Ant<bl,则Pos_Ant会按照式(23)进行更新。
Step4:计算Pos_Ant的适应度函数值,若小于Pos_Antlion的适应度函数值,则将Pos_Antlion更新为Pos_Ant。
Step5:若iter=T,则跳转到Step6,否则,iter++,跳转到Step3继续循环。
Step6:此时Pos_Elite即为虚拟机放置的最终方案,输出结果。
2.1 边界自适应调整机制
在传统蚁狮算法中,蚂蚁跟随蚁狮随机游走的边界是不断变化的,随着迭代次数的增加,它的上界和下界不断收缩。但是边界变化的趋势是线性的,即所有蚂蚁个体在游走过程中边界变化趋势完全一致。这种边界变化机制不适用于云环境编码,它可能会破坏种群解的多样性,且易陷入局部最优解,不利于全局寻优。因此,提出了一种边界自适应调整机制,通过改进式(17),使得蚂蚁进行随机游走时解的多样性更加丰富。

其中:r表示当前迭代次数待放置的虚拟机数量和物理机数量的比值;t表示当前迭代次数;T表示总迭代次数;w的大小随着当前迭代次数的变化而变化,当前迭代次数越大,w的值越大;rand表示(0,1)区间的一个随机数。蚂蚁随机游走的边界主要由I来决定,并且与I值呈反比。I的值是随着迭代次数的增加而动态变化的。
2.2 蚂蚁位置更新策略
蚂蚁随机游走的位置根据轮盘赌策略选择出的蚁狮及精英蚁狮的位置确定。在传统蚁狮算法中,蚂蚁最终游走的位置是轮盘赌选择的蚁狮和精英蚁狮位置的中点,这样会造成多数蚂蚁游走的趋势保持一致,破坏了种群的多样性。对蚂蚁随机游走的位置进行改进,使得在迭代的不同时期,蚂蚁游走具有不同的趋势。当迭代次数较少时,蚂蚁偏向轮盘赌选择的蚁狮进行随机游走,而在算法后期,蚂蚁更偏向精英蚁狮进行随机游走。这种策略使蚂蚁的游走更具随机性,也在一定程度上保证了种群的多样性。改进后的蚂蚁位置更新策略为


当蚂蚁完成随机游走后,如果此时蚂蚁的位置大于上界或者小于下界,会将蚂蚁个体移动到边界上,但这样显然不利于种群的多样性,可能会造成一些个体集中在同一位置。因此,对这种情况进行改进,如果蚂蚁个体越界,位置会按式(23)进行更新,保证随机性。

3 仿真实验及分析
用Python语言开发了一个虚拟机放置的仿真平台,该仿真平台可以读取数据、处理数据以及统计性能指标。提出的算法将与FFD 算法[6]、MBFD 算法[6]、BRC算法[19]以及ALO 算法在能耗、资源利用率、资源碎片、活动物理机数量等几个方面进行对比。本实验的环境配置:CPU 为2.2 GHz六核Intel Core i7,内存为16 GiB,操作系统为Mac OS,Python版本为Python 3.7。实验所采用的数据集是BitBrains数据集[20],BitBrains是一家真实的数据中心,并为众多公司提供云计算服务。实验场景选用的是异构的数据中心并选取了CPU 和内存2种指标,数据集的物理机配置如表1所示。

表1 数据中心的物理机配置
实验中,MALO算法的种群数量设置为200,迭代次数为10。待放置的虚拟机数量分别为50,60,70,80,90以及100台。数据中心的物理机数量为60台,且是异构的。随着待放置虚拟机的数量不断增加,使用MALO 算法进行求解时维度也在不断增加,为了保证算法求解的精度尽可能高,实验采用分批放置,即以10台虚拟机为一组进行放置,以此类推。其他对比算法的参数均采用默认配置。分别对比各种算法的能耗、物理机开机数量、CPU 资源利用率、内存资源利用率、CPU 资源碎片以及内存资源碎片这几个指标。
3.1 能耗实验
实验对比了MALO、ALO、BRC、FFD、MBFD五种虚拟机放置算法的能耗情况以及各算法的活跃物理机数量。在对能耗进行统计时,当物理机核心数为24、32、48、64时,物理机对应的峰值功耗分别为0.7、1.0、1.4、2.0 kW。
能耗实验结果如图1所示,MALO 算法能耗优于另外4种算法。当虚拟机数量为50~90时能耗最低,虚拟机数量为100时,MALO与ALO能耗相同。这是因为在数据中心能耗与物理机的开机数量有很强的相关性,活跃物理机的数量越少,能耗一般也越低。但本实验是在异构的数据中心下进行的,因此削弱了这种相关性。MALO 算法在ALO 算法上做了一些改进,有着更好的跳出局部最优解机制,在范围内能搜索到更多解,这样也就使得活跃物理机的数量减少,能耗相比其他几种算法有一定优势。

图1 数据中心总功耗对比
活跃物理机的数量能间接反映能耗高低,通常情况下活跃物理机数量越少,能耗越低,因此降低活跃物理机的数量是解决高能耗问题的关键。图2为这几种算法的活跃物理机数量,可以看出随着待放置虚拟机数量的增加,MALO 算法的活跃物理机数量是最低的,当虚拟机数量为100 时,MALO 算法和ALO算法活跃物理机数量一致。这是因为MALO算法相比ALO 算法有着更好的跳出局部最优解机制,有利于全局寻优。而FFD算法的策略是将虚拟机放置在遍历过程中第一台满足需求的物理机上,MBFD算法是将虚拟机放置在能耗增加最少的物理机上,BRC算法则是基于资源平衡因子和资源浪费得到一个合理的放置方案,这3种算法未尽可能地将多台虚拟机往同一台物理机上放置,从而减少物理机的开机数量。
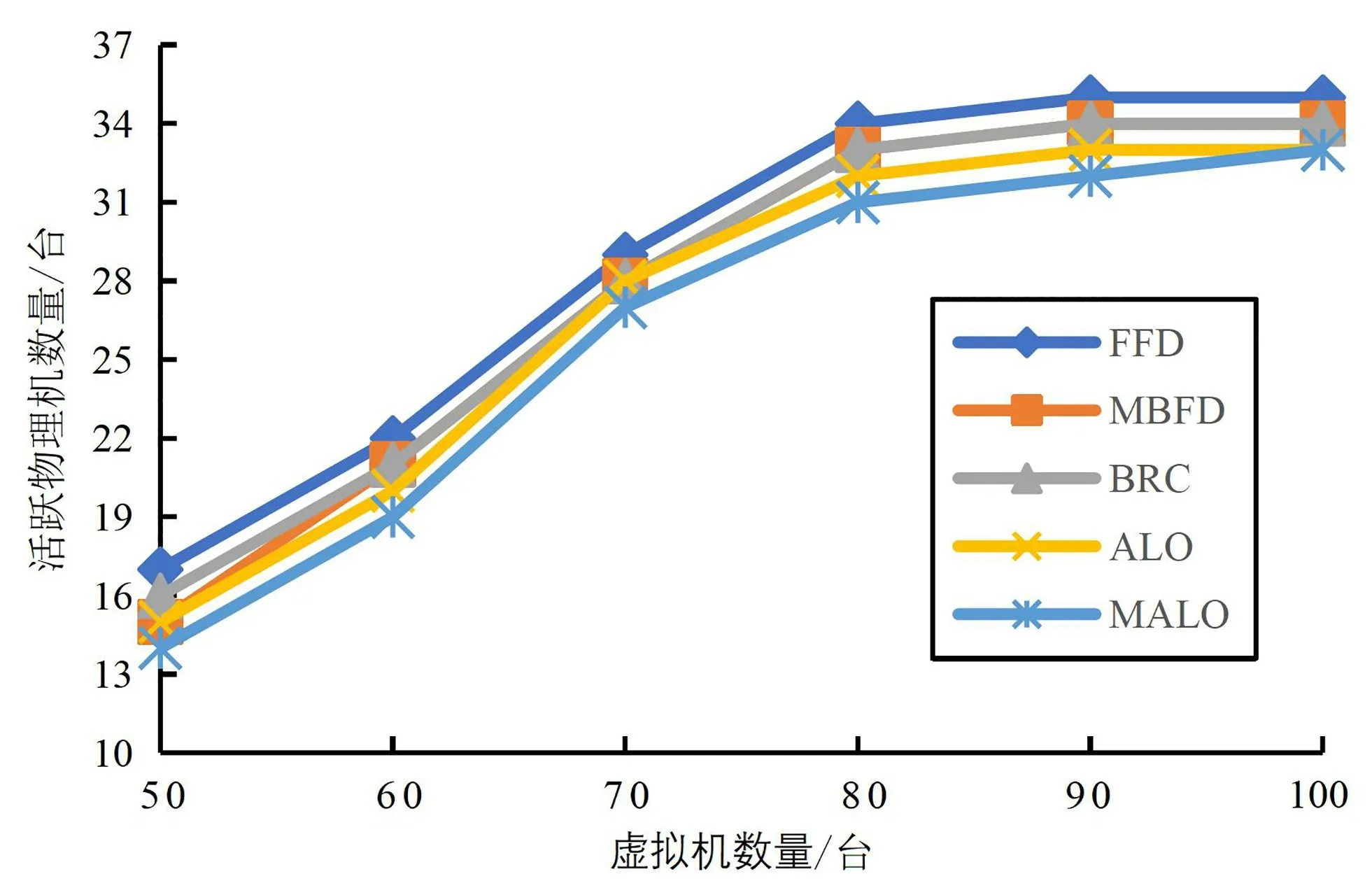
图2 数据中心活跃物理机数量对比
3.2 资源利用率实验
资源利用率是衡量一个数据中心虚拟机放置策略好坏的关键指标,资源利用率越高意味着每台主机的资源利用更加充分,虚拟机放置策略更加合理。图3、图4分别为各算法的CPU、内存利用率的情况,在CPU 利用率方面,在大多数虚拟机规模下MALO 算法都具有比较明显的优势。而在内存利用率方面,当虚拟机规模在60~90时,MALO 算法内存利用率最高;当虚拟机数量为50时,内存利用率低于MBFD算法,当虚拟机数量为100时,内存利用率略低于ALO算法。总的来看,MALO算法在资源利用率上能取得较好的效果,这是因为MALO算法相比ALO算法具有更好的跳出局部最优解机制,能避免陷入局部最优解,而FFD、MBFD 及BRC算法没有尽可能在一台物理机上放置更多的虚拟机,虚拟机放置较分散,活动物理机的数量较多,因此,CPU、内存利用率低于MALO算法。

图3 数据中心CPU利用率对比
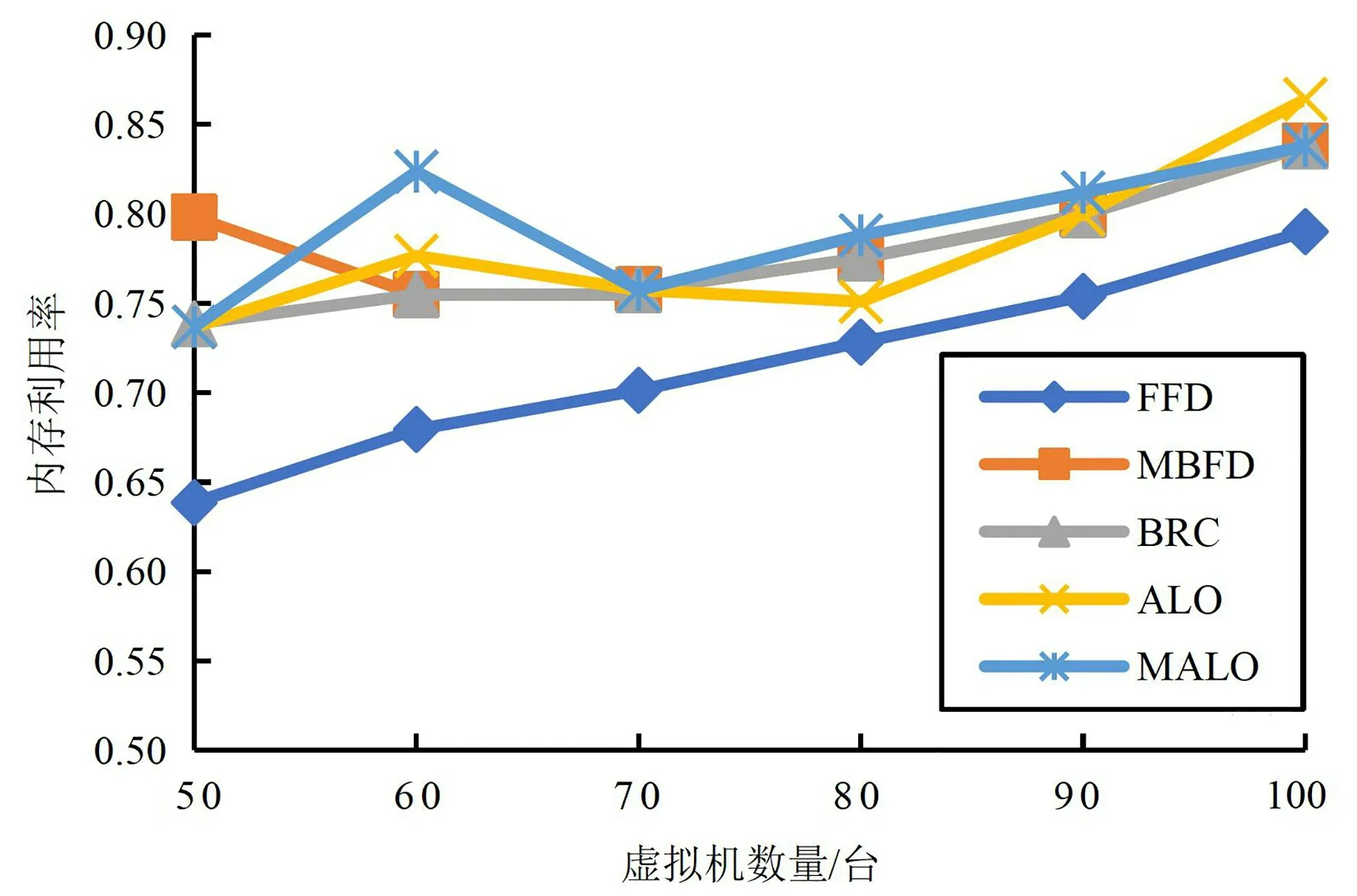
图4 数据中心内存利用率对比
3.3 资源碎片实验
资源碎片是衡量数据中心虚拟机放置是否平衡的一个重要指标。如果一台物理机上的虚拟机放置不平衡,如CPU 资源用完而内存资源还剩很多,就会导致无法再放置新的虚拟机,资源就会被浪费掉,这也是导致物理机资源利用率低下的一个重要原因。因此,通常情况下资源碎片的数量越少,主机负载就越均衡,数据中心的资源利用越高效。通过图5、图6可看出,在CPU 碎片方面,MALO 算法与ALO 算法效果接近,在大多数虚拟机规模下能产生更少的CPU 资源碎片。而在内存碎片方面,MALO 算法在效果上仅次于FFD算法,FFD算法在内存碎片上效果比较明显,主要是因为FFD的放置策略就是在遍历物理机列表的过程中找到首次满足虚拟机资源请求的物理机就进行放置,导致虚拟机放置相对比较分散,这样也就减少了内存资源碎片的产生。综合来看,MALO算法在资源碎片方面总体上能取得一个较好的效果,这是因为MALO 算法在进行放置时考虑了资源平衡度,使得放置后的资源平衡度尽可能小,从而减少放置不平衡情况的发生。

图5 数据中心CPU资源碎片对比

图6 数据中心内存资源碎片对比
4 结束语
提出了一种基于改进蚁狮算法的虚拟机放置方法,针对能耗、资源利用率及资源碎片这3个目标进行优化。在蚁狮算法的基础上,通过在蚂蚁随机游走策略上引入自适应边界变化机制,并且改进蚂蚁随机游走时位置更新策略,使得种群的多样性大大增加,改进后的蚁狮算法有更好的跳出局部最优解机制。将此方法应用在虚拟机放置的场景下,通过与另外4种算法的对比实验可看出,MALO 算法在降低能耗、提高资源利用率的同时,也能在一定程度上减少资源碎片的产生。
在未来的工作中,可考虑结合蚁群算法、粒子群算法等一些智能优化算法的策略,使得算法有更好的跳出局部最优解机制。除此之外,蚁狮算法除了应用在虚拟机放置阶段,还可以应用在虚拟机迁移过程中,最后在真实环境中进一步发挥蚁狮算法的作用,提高云数据中心的效率。
