基于特征提取和胶囊网络的人脸表情识别
2022-11-05黄小刚黄润才王桂江马诗语
黄小刚,黄润才,王桂江,马诗语
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
随着计算机技术的发展,人脸检测技术已经广泛应用于生活各领域中,如日常锁定和支付等,用来提高安全性。面部表情图像的获取正不断增多,如何进行表情情感分析、实现人机情感交互也就随即成为了当下的研究热点。
表情识别的过程可分为3个部分:图像采集与图像预处理、表情的特征提取、表情的分类。其中,人脸表情识别过程中又以表情特征提取为重点。在传统的人脸表情识别当中,有许多优秀的特征提取算法:局部二值模式(LBP)、方向梯度直方图(HOG)、Gabor小 波 变 换、活 动 外 观 模 型(AAM)等。其中,局部二值模式由于其特征提取方式简洁明了,提取效果较好,受到众多学者青睐,因此衍生出了许多变体:CS-LBP、CLBP、CSLOP等。在特征提取当中,文献[8]使用LBP的变体,能更好地处理像素边缘的特征。文献[9]提取了LBP纹理特征以及用HOG算法提取眼睛、眉毛区域、连同嘴部区域的边缘信息,并对这3个区域进行不同权值的融合。文献[10]使用了一种活动外观模型与Gabor小波变换融合的方法。上述特征提取方法都具有一定的局限性,识别的稳定性也欠佳,研究学界逐渐掀起了对深度学习的研究热潮。
近年来硬件技术取得了较大的突破,深度学习也随之得到迅猛发展,许多学者开始把深度学习方法应用于表情识别当中。文献[13]使用了改进的AlexNet网络进行表情识别,文献[14]构造表情局部特征融合的卷积网络模型。2017年,Sara等人提出了胶囊网络,使用胶囊单元存储信息,并使用独特的动态路由机制传递传输胶囊信息,该网络不仅能够检测到特征,还能检测到特征的空间、大小、位置等信息,具有可观发展前景。文献[16]验证了胶囊网络相比卷积神经网络在表情识别上具有更强的鲁棒性。文献[17]使用了胶囊网络和卷积网络的结合,同时加入大量的卷积操作和层注意力机制,实验结果表明该网络稳健性强,但是也存在着网络结构冗余、网络收敛很慢、训练时间很长的问题。
本文把传统的特征提取方法与深度学习胶囊网络相结合,提取了图像的局部二值模式特征,与原图通道合并,形成双通道输入,送入胶囊网络,形成一种多通道输入胶囊网络。残卷积网络(ResNet)具有收敛速度快,能避免梯度弥散的优点,本文又在双通道输入的基础上添加残差网络形成多通道输入增强胶囊网络模型。通过局部二值模式、ResNet提取复杂低层特征,送入胶囊网络分类,在CK+数据集和RAF-DB数据集上的实验结果表明2种特征增强能充分发挥胶囊网络的效果,获取了更具表达能力的特征。
1 基本原理
1.1 局部二值模式
纹理信息对于图像的模式分析非常重要,局部二值模式(LBP)是一种简单而高效的纹理描述方法。局部二值模式是能够获得中心像素和相邻像素之间差异的二进制模式。具体通过用中心值对每个像素的3×3邻域进行阈值化并将结果作为二进制数来标记图像的像素,中心点像素的LBP编码如式(1)、(2)所示:
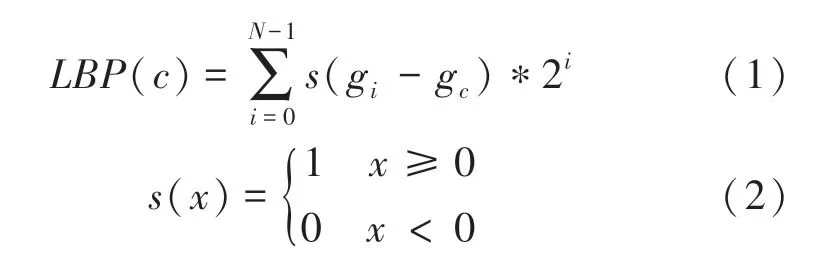
其中,g表示中心像素的灰度值;是涉及邻域像素的总数;g(0,1,,1)是以为中心的邻域像素的灰度值。中心像素及邻域半径为1的3×3的像素如图1所示。

图1 3*3像素点Fig.1 Pixels of 3*3
1.2 胶囊网络
胶囊网络(CapsNet)以胶囊作为基本神经元存储信息,不同于卷积神经网络标量输入、标量输出的传递形式,胶囊网络是一个向量输入、向量输出的形式。胶囊是一个向量,具有多个值,包含更多图像实体的信息,不仅可以表示是否存在特征,还可以表示特征之间的关系,输出综合这些信息,使用向量的模长表示实体存在的概率。用于Mnist手写数字识别的胶囊网络结构如图2所示。
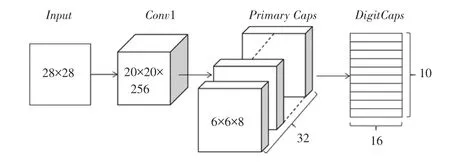
图2 胶囊网络结构Fig.2 Capsule network structures
胶囊网络由输入层()、卷积层(1)、主胶囊层()、数字胶囊层()组成。输入层即输入2828大小的灰度图。1就是普通的卷积层,使用256个步长为1的99卷积核,为激活函数,用于提取图像的低层特征,得到2020256的特征图。
主胶囊层开始使用胶囊单元存储信息,该过程可以看作是普通卷积层的纵向扩展,使用了8组、32个步长为2的99卷积核,把特征图进行三维拼接,得到6*6*32、即1024个胶囊,每个胶囊是一个长度为8的向量。对胶囊进行归一化,使用非线性压缩函数,对胶囊进行压缩,确保长度在01之间,压缩函数如式(7)所示:
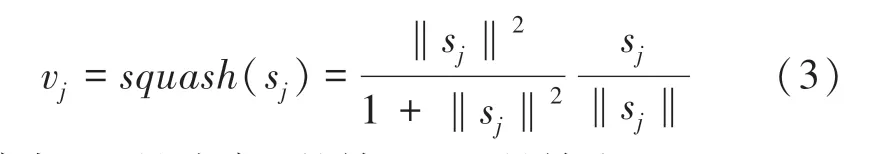
其中,s是胶囊的输入,v是输出。
数字胶囊层的输出是10个维数为16的向量,每个向量的模长代表该类的预测概率。层采用的是动态路由机制,进行3次动态路由迭代。动态路由的过程原理如图3所示。参数更新公式的数学表述可写为:
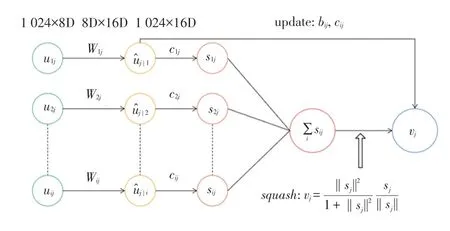
图3 动态路由过程Fig.3 Dynamic routing process
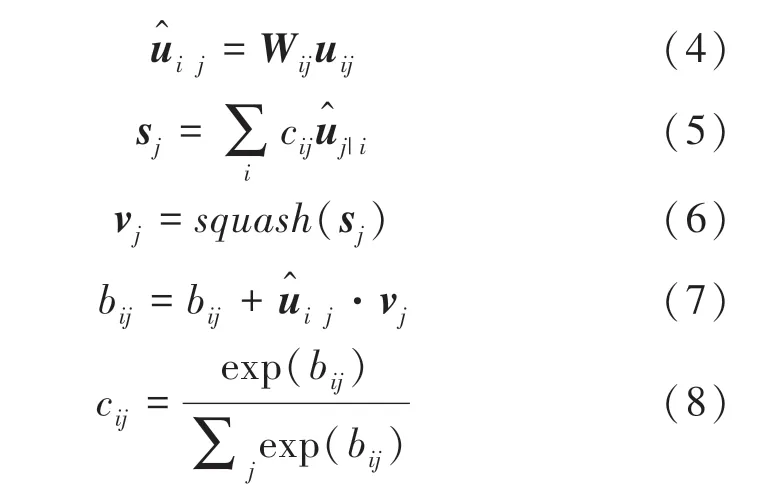
其中,∈(1,2,…,1024),∈(1,2,…,10),这是由于主胶囊层共有1024个胶囊,数字胶囊层输出类别有10类;u是主胶囊层输出的1024个向量;W是权重矩阵;^是预测向量,表示当前向量条件下预测为类别的概率。式(5)中,s是上一层预测向量^乘以胶囊间耦合系数c的加权和;式(6)是压缩函数,式(7)、式(8)用来迭代更新耦合系数b,c。
胶囊网络采用的是边际损失函数,如式(9)所示:
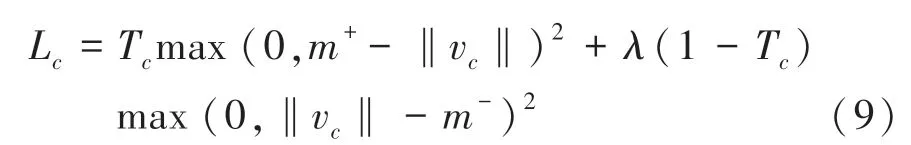
其中,T表示类是否存在:存在为1,不存在为0;m取值为0.9,惩罚假阳性,当类存在预测不存在时会使损失函数很大;m取值为0.1,惩罚假阴性,当类不存在预测存在时会使损失函数很大;取值为0.5,调整假阴性的权重。
2 实验框架
2.1 整体框架
本文提出的基于特征提取与胶囊网络的表情识别算法实现流程如图4所示。图4中,首先对图片进行预处理操作,使用Harr级联器进行人脸检测,获取人脸部分图片,尺寸归一化为48×48、像素归一化为0~1之间。对图片进行数据增强,数据增强操作包括图片的旋转、平移、错切获取更多的训练样本。提取图像LBP纹理特征,提取图像ResNet18特征,送入胶囊网络分类训练,验证模型准确率。
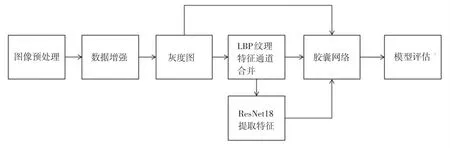
图4 识别算法流程图Fig.4 Flow chart of recognition algorithms
2.2 多通道输入胶囊网络
多通道输入胶囊网络使用LBP算子提取图像的纹理特征,灰度图和其纹理特征如图5所示。将纹理特征图与灰度图进行通道合并的多通道输入胶囊网络结构如图6所示。该网络共进行2组实验。第一组实验输入只使用灰度图作为对照实验,用于验证是否提取纹理特征的多通道输入胶囊网络相比单一的胶囊网络具有更好的识别效果,第二组实验输入为灰度图-LBP特征图。2组实验输入分别送入胶囊网络的1卷积层,得到的40×40×32的特征图,接着输入到主胶囊层中,特征图从标量变为矢量,得到特征长度为8的1024(16*16*4)个向量,最后送入到数字胶囊层,通过动态路由算法迭代3次得到预测结果为16×8的向量,8表示表情的类别(RAF-DB数据集为7类表情,预测结果为16×7,这里的16表示向量的长度,包含了预测该类别的特征信息)。网络各层详细编码参数见表1。

表1 特征提取的胶囊网络结构参数Tab.1 Structural parameters of capsule network based on feature extraction
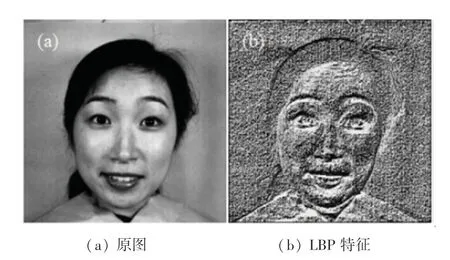
图5 特征图Fig.5 Feature map

图6 多通道输入胶囊网络Fig.6 Multi-channel input capsule network
从图6和表1可以看出,该网络2组实验使用2组不同的特征作为输入进行训练,由于原图尺寸为48×48,对主胶囊层的卷积核个数进行了调整,使得输出仍为1024个维度为8的向量,主胶囊层和数字胶囊层的胶囊维数并没有改变,数字胶囊层输出尺寸16×8为CK+数据集,16×7为RAF-DB数据集输出,后续不再做重复说明。
2.3 多通道输入增强胶囊网络
多通道输入增强胶囊网络结构如图7所示。在输入图像为灰度图和LBP特征图基础上,再使用泛化能力强的ResNet18网络对胶囊网络进行增强。ResNet18网 络 由1个层,4个 残 差 模 块组成,该结构使用了大量的3×3的卷积核,为了满足主胶囊1024个8维向量的输出,对网络卷积核个数步长进行了相应的调整改进。输入图像经过ResNet18得到6×6×256特征图,送入主胶囊层,ResNet18网络可以提取丰富特征,主胶囊层对特征进行整理,把标量变为向量,得到1024个维度为8的向量。主胶囊层的胶囊送入数字胶囊层通过动态路由迭代3次得到最终分类结果,数字胶囊层的胶囊维数为16。网络各层详细编码参数见表2。
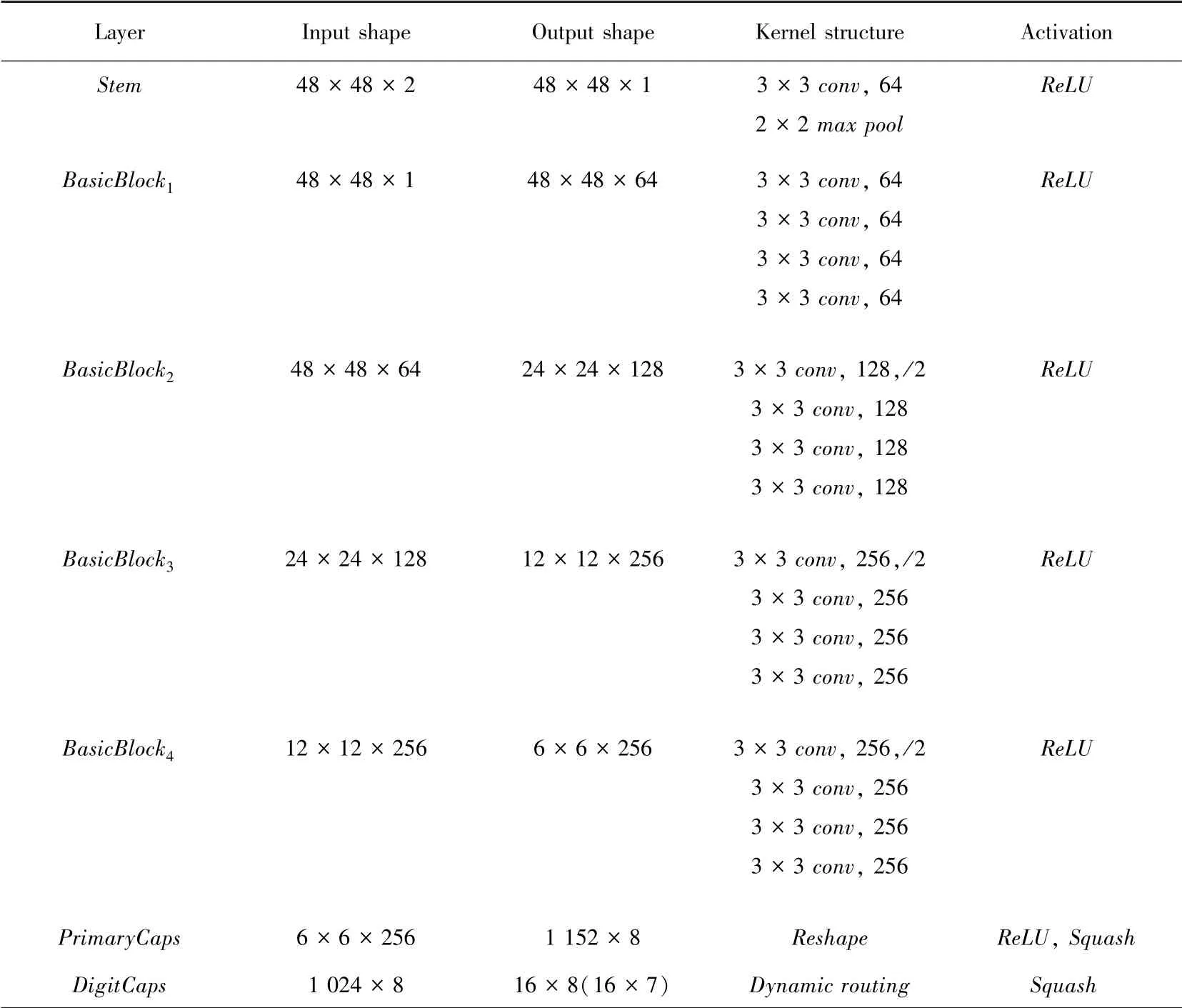
表2 增强胶囊网络结构参数Tab.2 Enhanced capsule network structure parameters
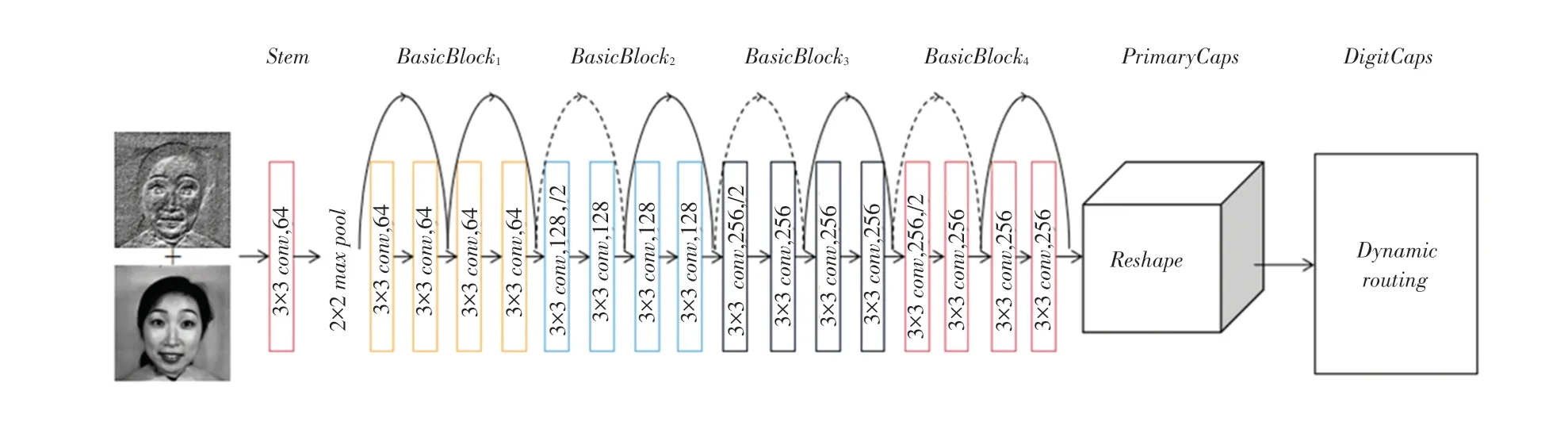
图7 多通道输入增强胶囊网络Fig.7 Multi-channel input enhanced capsule network
3 实验结果与分析
实验程序运行在Window10操作系统上,使用GeForce GTX3060 GPU,仿真环境使用Tensorflow2.6的深度学习框架。
本文采用CK+和RAF-DB数据集进行实验。CK+数据集是实验环境下表情序列,在表情序列中选取了1085张基本图片,这些图片中有7类基本表情,分别是:生气、厌恶、害怕、开心、伤心、惊讶、轻蔑。由于样本较少,添加了对应的中立表情,总共8种表情。对这些图片进行数据增强得到更多的数据集,其中70%的图片用于训练,30%的图片用于测试。RAF-DB数据集是自然环境下的表情图片,包含7类基本表情,训练集图片有12271张,测试集图片有3068张。
2个数据集分别进行3组实验。第一组实验为基准实验,直接用灰度图送入胶囊网络进行训练,称为CapsNet。第二组实验为纹理特征的多通道输入胶囊网络实验,称为LBP-CapsNet。第三组实验是基于纹理特征和深度残差网络的多通道输入增强胶囊网络,称为ResNet-CapsNet。
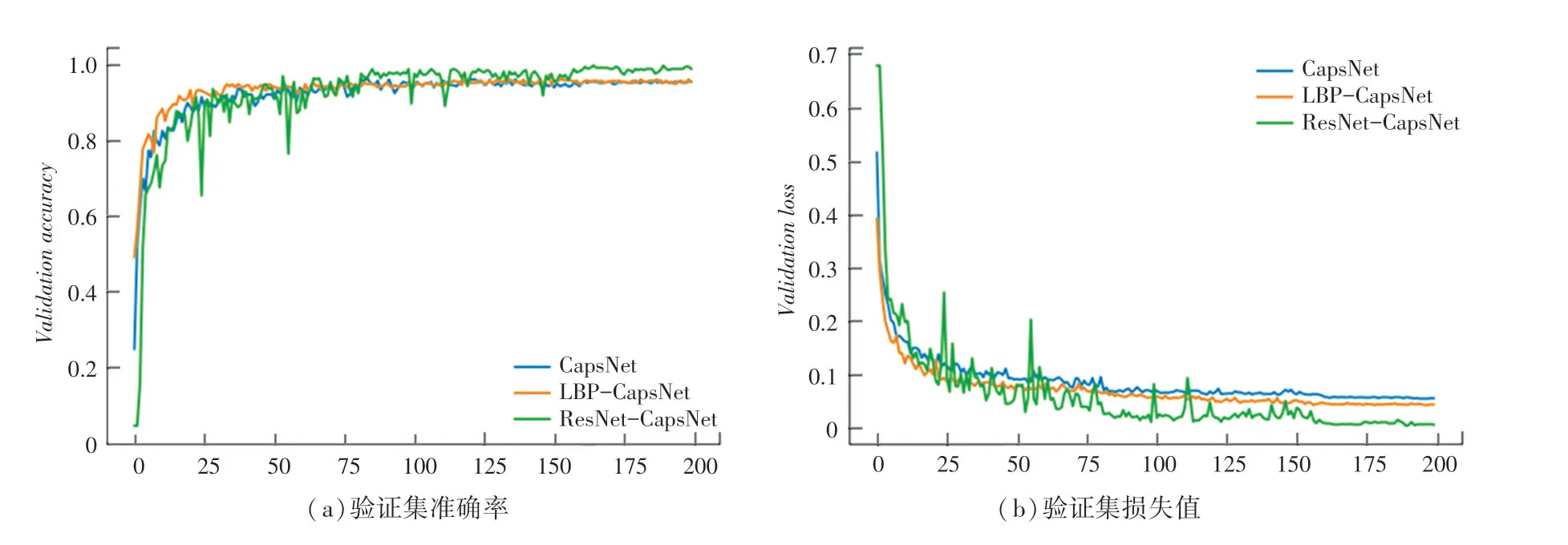
实验中,使用优化器进行梯度下降,总共迭代200次,批大小为30。前80次迭代学习率为0.01,80~160次迭代学习率为0.005,160次后迭代学习率为0.001,CK+数据集3组对照实验的验证集训练曲线如图8所示,RAF-DB数据集3组对照实验的验证集训练曲线如图9所示。
根据图8、图9可以看出,相比于只使用胶囊网络CapsNet实验,多通道输入胶囊网络LBPCapsNet损失值较小,准确率相比于CapsNet实验有所提高。加入ResNet网络提取特征后的多通道输入增强型胶囊网络ResNet-CapsNet的初始损失值较大、准确率较低,这是由于添加ResNet网络,使网络结构变得更为复杂,随着网络不断训练迭代,学习的特征越来越多,网络损失值变小,准确率明显高于CapsNet。
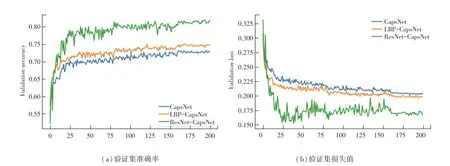
图9 RAF-DB训练曲线Fig.9 RAF-DB training curve
CK+和RAF-DB数据集的3组实验最终准确率见表3。本文提出的多通道输入胶囊网络和多通道输入增强胶囊网络方法相比于只使用胶囊网络在2个数据集上准确率有明显提高,其中多通道输入增强胶囊网络在CK+和RDF-DB数据集准确率分别达到99.69%、82.02%。表4和表5分别列举了其他表情识别算法在CK+和RAF-DB数据集上的准确率。分析可知,本文算法在表情识别方面具有很好的表现,准确率有明显的提升。

表3 本文方法准确率比较Tab.3 Recognition rate comparison of the proposed method

表4 CK+的不同算法的准确率比较Tab.4 Recognition rate comparison of different algorithms on CK+
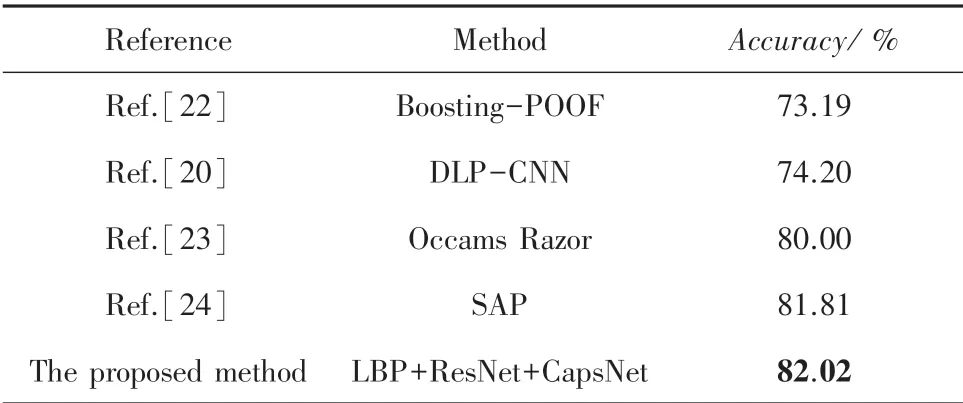
表5 RAF-DB的不同算法的准确率比较Tab.5 Recognition rate comparison of different algorithms on RAF-DB
4 结束语
本文提出了多通道输入胶囊网络和多通道输入增强胶囊网络表情识别方法,2种方法的本质都是通过充分提取低层特征,增强了胶囊网络提取特征的能力,得到了能够充分表示表情的特征的信息。在CK+和RAF-DB数据集上,本文的方法与其他论文方法对比可知,准确率有明显提高。本文算法只提取了图像的纹理特征作为低层特征,而几何特征也是人脸表情的重要特征,后续可以进一步加入几何特征进行实验。胶囊网络仍有较大发展潜力,许多细分方向仍有待深入挖掘,比如胶囊维数、动态路由迭代次数、函数等等对网络的影响。结合纹理特征、几何特征、深度学习这些方法,使用更多复杂场景的人脸图片进行验证以提高识别率是下一步的研究方向。
