基于深度学习的MOBA类游戏胜率预测模型的研究
2022-11-05刘凯
刘 凯
(东北大学 计算机科学与工程学院,沈阳 110169)
0 引言
电子竞技行业飞速发展,近年来推出的MOBA类游戏正是当下最热门的竞技类游戏之一。在该类游戏中,参赛双方的阵容选择、比赛中双方队伍的经济差与经验差都对比赛的胜负起着决定性作用。根据阵容与比赛中的实时信息来预测比赛双方的胜率已然成为该领域的研究热点方向,其结果不仅可以为选手提供英雄选择参考,也有助于游戏开发者改善游戏平衡性,相关技术还可以用于团队竞技类体育赛事的预测。
目前,研究人员对MOBA类游戏的胜率预测问题进行了大量的研究和工作,早期大部分研究都是基于游戏比赛的历史数据,采用朴素贝叶斯、决策树、逻辑回归等传统机器学习的方法来解决游戏的胜率预测问题。Kinkade等人用逻辑回归与随机森林的方法,在Dota2游戏中分别根据阵容与完整的赛后数据预测比赛的结果。Wang等人使用逻辑回归、支持向量机、随机森林的方法,将不同英雄在历史比赛中的金币、经验、击杀等特征作为特征输入,预测Dota2游戏的比赛结果。Wang等人利用朴素贝叶斯的方法,根据比赛双方所选阵容来预测Dota2游戏的比赛结果,虽然在训练集上取得了85.33%的准确率,但在测试集上只有58.99%的准确率,过拟合现象较为严重。Song等人使用逐步回归的方法,根据阵容预测Dota2比赛的结果,取得了解决61%的预测准确率。Lin使用梯度提升树与逻辑回归模型,根据赛前数据对比赛结果进行预测,但由于没有运用比赛的实时数据,导致预测准确率较低。Cleghern等人使用自回归模型与统计模型预测Dota2中英雄的血量变化,并取得了较优的效果。
随着深度学习技术的发展,不少学者将神经网络应用到预测模型中。Silva等人建立RNN模型,对英雄联盟比赛进行实时预测,使用0~5 min的数据与20~25 min的数据分别预测比赛结果,各自取得了63.91%与83.54%的准确率。Grutzik等人使用传统神经网络建立模型,利用比赛时的玩家信息和英雄信息预测Dota2游戏的比赛结果,取得了较高的准确率。许晨波提出改进的双向LSTM神经网络用于预测Dota2游戏的比赛结果,并实现了阵容推荐功能。Yang等人将英雄信息、玩家信息的特征作为模型的输入,实现了Dota2的赛前胜率预测,在没有加入比赛实时数据的情况下,最高时取得了71.49%的预测准确率。在加入比赛的实时数据后,最高时则取得了93.73%的预测准确率。Hodge等人进行了Dota2的实时预测研究,并提出了一套电子竞技获胜预测研究的评估标准。Yang等人提出了一种时间序列模型TSSTN,用于解决王者荣耀的胜率预测问题。李康维等人提出了一种序列到序列的模型,预测MOBA类游戏的趋势发展情况。
上述研究虽然取得了较好的效果,但依旧存在一定的不足。例如:在MOBA类游戏的实时预测问题中,没有充分考虑不同时间点对结果的影响大小。受到文献[7]的启发,本文首先采用基于统计与Word2Vec的方法提取比赛双方的阵容特征,并结合比赛中的实时信息作为模型输入。模型结构上,采用2层LSTM模型,同时引入注意力机制,预测比赛的最终结果。本文的主要贡献与创新点如下:
(1)提出引入注意力机制的双层LSTM模型,通过双层LSTM模型提取实时比赛中不同时间节点的特征数值;通过引入注意力机制为不同时间节点的特征数值赋予权重。
(2)采用统计与Word2Vec的方法提取比赛阵容的特征作为网络输入信息,提高模型的预测准确率与泛化能力。
(3)在真实的比赛数据集上进行实验,得到的预测结果优于其他模型。
1 特征介绍
本节将对模型的输入特征做详尽阐述。在MOBA类游戏中,阵容的好坏在一定程度上决定了比赛的发展趋势,合理的阵容是赢得比赛的基础,但由于玩家水平、玩家在比赛中的发挥不同,导致较差的阵容也有可能在比赛中取得较大优势,所以研究中将比赛双方的阵容特征与比赛双方实时的数据作为模型的输入。阵容的好坏可以由阵容中英雄的配合能力、英雄个人能力、对敌方阵容的克制强度、阵容合理度来衡量;比赛的实时数据包含英雄击杀数、小兵击杀数、防御塔摧毁数量等,但以上实时数据最终都会转化为经济与经验,所以比赛双方实时的经济与经验数据可以反映不同时间点比赛双方的实力差距。研究中给出的模型输入特征见表1。下面将系统论述模型中各输入特征的计算方式。
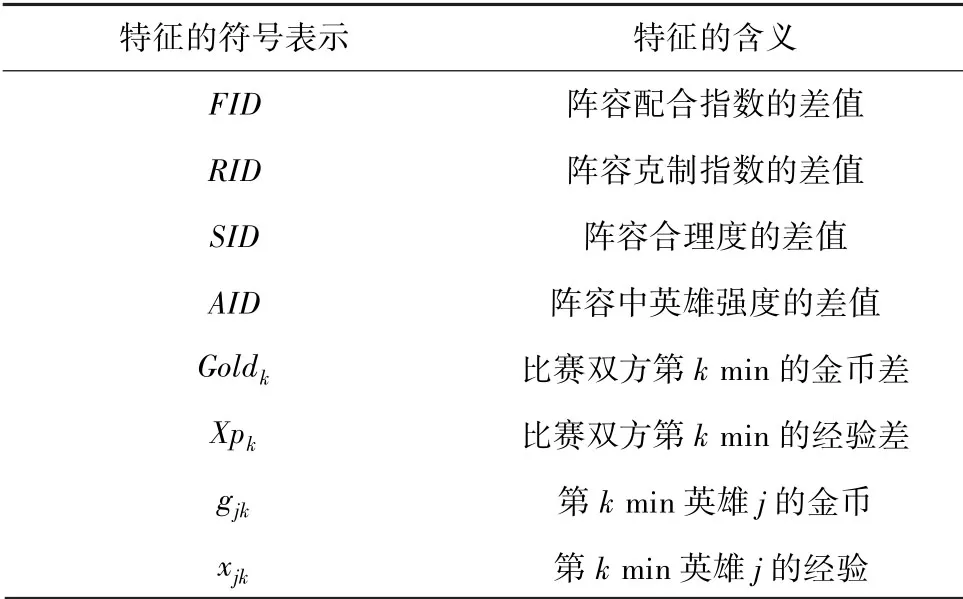
表1 模型的输入特征列表Tab.1 List of input features for the model
1.1 英雄的平均胜率
部分英雄出场率很高,在团队取得优势时作用大,但是在团队处于劣势时就很难发挥作用,或者英雄的容错率太低,一旦玩家发挥失误,就会陷入劣势。故英雄的出场次数不能完全反映英雄的强弱。所以引入英雄的平均胜率(average)作为英雄的特征之一。average的公式如下:
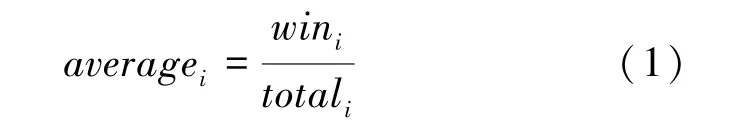
其中,win表示英雄获胜的场次,total表示英雄出现的总场次。
1.2 英雄间的配合关系
不同英雄之间的技能或者购买的装备之间存在着不同的配合关系,可以强化彼此的实力。配合关系会在数场比赛中反映出来,当2个配合关系强的英雄出现时,可以认为此时的胜率会比英雄单个出场时要高,于是文中引用配合指数(cooperate)来量化英雄间的配合关系。cooperate的公式如下:

其中,Y表示英雄与英雄属于同一阵容时的获胜的场次;N表示英雄与英雄属于同一阵容的总场次。配合指数越高,说明2个英雄的配合关系越强,当配合关系小于05时,说明2个英雄存在着冲突,会影响彼此发挥。英雄间的配合关系矩阵如图1所示。

图1 配合关系可视化图Fig.1 Visual diagram of mating relationship
图1的横、纵坐标均用于表示英雄的。 不同英雄之间的配合关系越强,则英雄的配合指数在图1中的颜色越接近红色,反之接近绿色。由于比赛中大部分英雄不会出现在同一队伍中,故图1中横轴的大部分区域颜色一致。
1.3 英雄的克制关系
以最低成本、例如一个小技能,来影响敌方英雄的发育、对线、出装思路、后期输出环境等,都能算作克制。Dota2中的克制关系表现得十分明显。当克制关系强的2个英雄对阵时,胜率会出现不平衡的情况。于是通过克制指数(restrain)来量化2个英雄的克制关系。克制指数公式如下:
其中,W表示英雄,对阵时,获胜的场次;A表示英雄、对阵的总场次。克制指数越高,说明2个英雄的克制关系越强,当克制指数大于05时,说明英雄克制英雄。当克制指数小于05时,说明英雄被英雄所克制。英雄间的克制关系矩阵如图2所示。
图2的横、纵坐标均用于表示英雄的。 不同英雄之间的克制关系越强,则英雄的克制指数在图2中的颜色越接近红色,反之接近绿色。由图2可见,英雄与英雄之间的克制关系差距较为明显:比如4号英雄对7号英雄的克制指数为0.47,但对103号英雄的克制指数高达0.62。

图2 克制关系可视化图Fig.2 Visual diagram of restraint relationship
1.4 阵容的合理度
MOBA游戏的一个阵容由5个英雄构成,一个好的阵容应该同时包含核心、辅助、控制、灵敏等类型的英雄,由于玩家选择英雄时的主观性,可能导致阵容里缺少某些类型的英雄,或者重复选用相同类型的英雄,导致阵容不合理。为了解决该问题,本文引入了阵容合理度的概念。通过自然语言处理的方法,可以把英雄的名称转化为词向量,以词向量表示英雄。由于skip-gram模型能够根据句子中的某一个单词预测其上下文,故本节采用Word2Vec中的skip-gram模型来训练词向量。在训练后要求类型越相似的英雄,对应的词向量之间的相关性更高。于是可以用词向量之间的相关性来衡量英雄属于同一类别的概率。例如丽娜(Lina)和凤凰(Phoenix)都属于远程类型、辅助,转化为词向量后2个英雄对应的词向量的相似度应该是高的。研究中把每个阵容作为一个句子来当成输入,通过训练2 w个句子后得到不同英雄的词向量,并通过PCA方法将训练后的词向量进行降维,再运用k-means的方法将降维后英雄的词向量进行聚类,这里将英雄分为5类。不同类别的英雄在绘图中会用不同颜色进行表示。英雄的词向量可视化展示如图3所示。
由图3可以看出,类型相似的英雄,在图3上的位置比较接近,相似度高。如Monkey_King(齐天大圣)与Lone Drui(德鲁伊)都属于核心位,在图3上位置十分接近。通过Word2Vec工具,可以获得2个英雄间的相似度。本文通过的数值来衡量阵容的合理度,的数学定义公式如下:
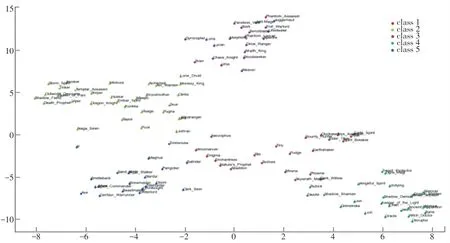
图3 英雄向量可视化图Fig.3 Heros vector visualization diagram

其中,S表示同一阵容中,英雄与英雄的相似度,表示同一阵容中英雄的个数。suitable的值越大,表明阵容中类似的英雄越多,阵容越不合理;suitable的值越小,表明阵容中存在的英雄种类越多,阵容更合理。
1.5 队伍的配合指数差值
研究中将选定的英雄进行编号,当英雄的编号0,时,认为英雄处于阵容;当英雄的编号,2*时,认为英雄处于阵容。进而推得,队伍的配合指数差值公式如下:
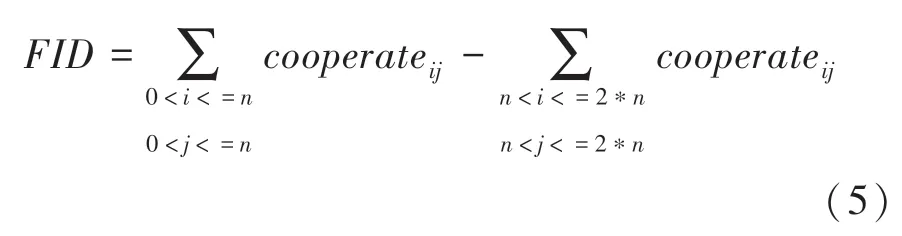
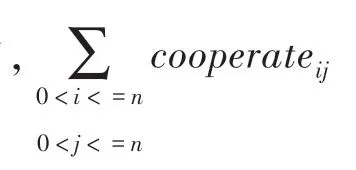
1.6 阵容间的克制指数差值
研究中将选定的英雄进行编号,当英雄的编号0,时,可认为英雄处于阵容;当英雄的编号,2*时,可认为英雄处于阵容。如此一来,双方阵容的克制指数差值公式如下:

的值衡量了比赛双方阵容间的克制指数的大小,越大,表示阵容对阵容的克制能力越大,反之则越小。例如阵容中包含{,,,,}这5名英雄,阵容中包含{,,,,}这5名 英 雄。 将restrain、restrain、…、restrain的值进行累加,得到的值。若大于0,说明阵容对阵容的克制关系较强,若小于0,则说明阵容对阵容的克制关系较强。
1.7 阵容合理度的差值
研究中将选定的英雄进行编号,当英雄的编号0,时,认为英雄处于阵容;当英雄的编号,2*时,认为英雄处于阵容。则阵容合理度的差值公式如下:
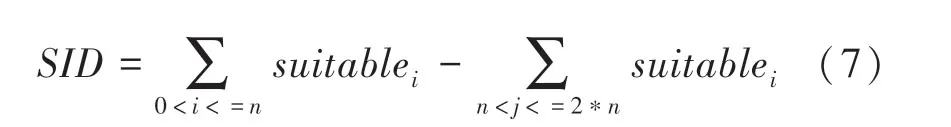
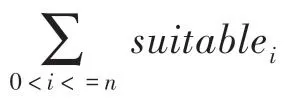
1.8 队伍中英雄能力强弱的差值
研究中将选定的英雄进行编号,当英雄的编号0,时,认为英雄处于阵容;当英雄的编号,2*时,认为英雄处于阵容。则队伍中英雄能力强弱的差值的公式如下:


1.9 比赛中的实时信息
比赛中的双方队伍的经济差与经验差体现了不同时刻双方的实力差距。设比赛双方共有2*个英雄,则比赛中的实时数据向量()表示如下:
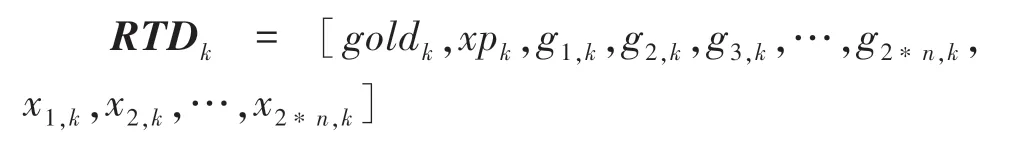
其中,gold表示比赛进行到第min时比赛双方的队伍经济差;xp表示比赛进行到第min时比赛双方的队伍经验差;G表示英雄在比赛进行到第min时获得的金币数值;x表示英雄在比赛进行到第min时获得的经验数值。
2 实时胜率预测模型
对于给定2支队伍{,…,a}和{,…,b},其中a和b分别表示2队中所选英雄,根据比赛进行过程中的信息预测,比赛队伍和的获胜概率分别为P和P,且有P+P=1。
在MOBA类游戏中,游戏的胜负不仅与比赛双方阵容有关,还与比赛过程中比赛双方的英雄击杀、防御塔摧毁、野怪击杀等实时数据相关。由于比赛局势每一个时刻都在变化,仅凭游戏进行中单个时刻的数据很难预测比赛的结果,因此应该将比赛双方的阵容信息以及比赛过程中不同时刻的信息作为预测依据,展开比赛结果的预测。本节提出的引入注意力机制的双层LSTM模型以比赛双方的阵容信息、不同时间的比赛信息作为模型输入,运用LSTM结点处理时序信息,作为模型的编码阶段,同时引入注意力机制来计算不同时刻的信息对结果的影响权重,并加入全连接层作为过渡层;作为解码阶段,在输出层采用函数作为激活函数,输出比赛双方的获胜概率。
2.1 模型结构介绍
在本文的实时胜率预测模型中,模型的输入是一个时间序列,因此用LSTM层作为输入层,LSTM层返回每一个时间步的结果、即{,,…,h},此后将{,,…,h}作为第二层LSTM的输入,再将第二层LSTM的输出作为注意力层、即层的输入,由此来得到不同时间步对结果的影响大小,最后将层的计算结果经过层,转化为一维向量,另将层的输出经过层后,采用函数进行归一化,并将模型的输出结果转化为概率的形式,得到模型的输出结果,模型结构如图4所示。
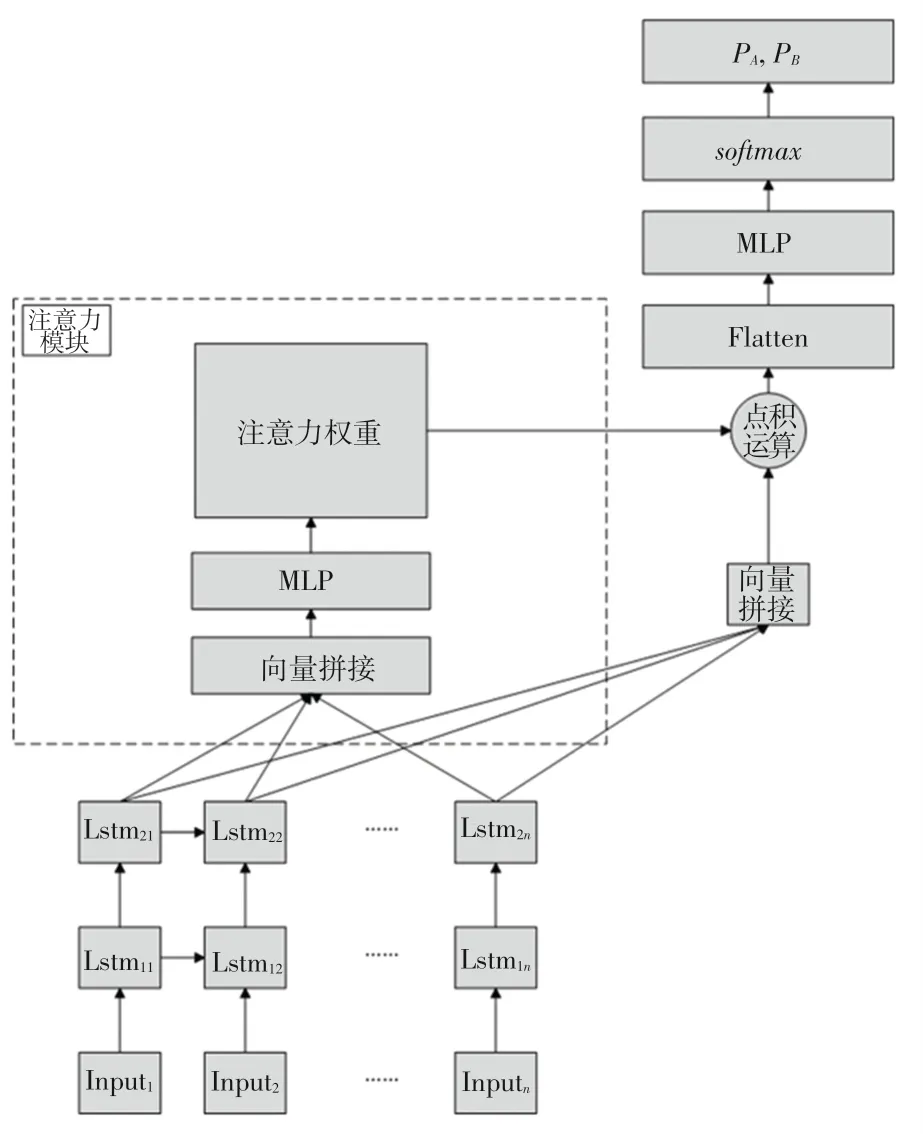
图4 实时胜率预测模型结构图Fig.4 Structure diagram of the real-time winning rate prediction model
2.2 模型的输入与输出
2.2.1 模型输入介绍
模型的输入为前min的比赛双方的实时经验、金币、阵容信息,模型输入的形式化定义如下:
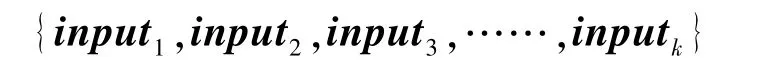
其中,input(1≤≤)表示比赛第min时比赛双方的实时经验、金币、阵容信息。
设比赛双方共有2*个英雄,向量input形式化定义如下:
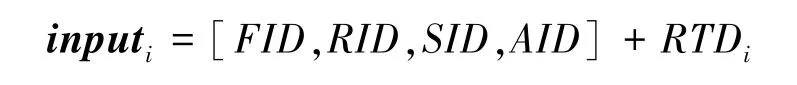
其中,“+”表示向量的连接。
2.2.2 模型输出介绍
由于胜率预测是一个二分类问题,故模型的输出是一个1*2的一维向量,其形式化的定义为:[P,P]。 其中,P表示队伍的胜率,P表示队伍的胜率。当P>P时,认为队伍获胜;当P<P时,认为队伍获胜;P=P时,则认为队伍、的胜率相等。
3 实验结果与分析
3.1 数据集
本文的数据来源于opendota网站,在该网站上可以获取到每场比赛的详细数据,包括双方阵容、比赛持续时间、英雄、比赛双方每分钟的金币与经验等。仿真时,从该网站上获取了2019年1月1日至2019年12月31日的2.5 w场职业比赛数据。每场比赛数据至少包含以下信息:天辉、夜魇阵容所选英雄信息;获胜方;比赛时长;比赛开始后双方每一分钟的经济与经验;每分钟发生的英雄击杀事件。
3.2 数据预处理
获取的数据需要进行筛选,通过对每场比赛时间的判断,时间小于20 min的比赛,可以认为是因为特殊原因提前结束的比赛,将这些数据剔除掉,以防干扰特征的准确性。将所有数据按6∶2∶2的比例划分为训练集、验证集、测试集,且数据在输入到模型前均进行归一化处理。
3.3 测评指标
实时胜率预测模型的效果由预测准确率()来评估,的公式如下:
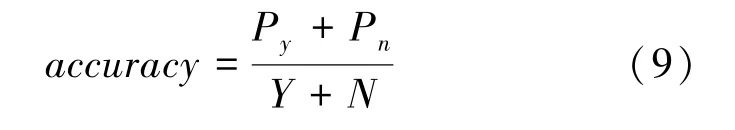
其中,P表示队伍比赛获胜、且预测结果也为获胜的次数;P表示队伍比赛获胜、且预测结果也为获胜的次数;表示队伍比赛获胜的次数;表示队伍比赛获胜的次数。预测准确率的值越高,说明模型效果越好。
3.4 实验结果与分析
为了验证模型与不同输入特征的效果,本节进行2组消融实验。第一组消融实验分析了不同特征对实验结果的影响;第二组消融实验分析了不同模型结构对实验结果的影响。
(1)消融实验一。在{,,,,}集合中5个特征的基础上,分别舍弃不同特征,再将剩余特征作为引入注意力机制的双层LSTM模型的输入,对比实验效果见表2。

表2 选择不同输入特征的实验效果对比表Tab.2 Comparison table of experimental effects of choosing different input features
由表2可见,当选择{克制指数差值、配合指数差值、英雄强弱、阵容合理度、前15 min的比赛的实时数据}中所有特征作为模型输入时,模型的预测准确率为71.8%,当减少某一特征时,对比选择所有特征作为输入的实验结果,模型的预测准确率均有所下降。其中,当减少前15 min的比赛的实时数据这一特征时,模型的预测准确率只有61.2%。说明在上述所有特征中,前15 min比赛的实时数据对结果的影响是最大的。综上可知,本文选择的所有特征,都对模型最后的预测结果有所贡献。
(2)消融实验二。将所有特征:{克制指数差值、配合指数差值、英雄强弱、阵容合理度、前15 min的比赛的实时数据},分别作为引入注意力机制的双层LSTM模型、双层LSTM模型、多层感知机、随机森林模型的输入,对比在相同输入特征下,不同模型中的效果。各模型实验效果对比见表3。

表3 不同模型的实验效果对比表Tab.3 Comparison table of experimental effects of different models
由表3可知,相对其他模型,引入注意力机制的双层LSTM模型的预测准确率最高,为71.8%。
4 结束语
针对比赛实时预测问题,本文采用引入注意力机制的双层LSTM模型模型,该模型以比赛中的经验、金币及阵容信息作为模型输入,预测比赛的最终结果,在比赛进行到第15 min时,预测准确率为71.8%。较传统方法相比,预测准确率提高了1.5%以上,得到了较优的效果。在MOBA类游戏中,选手的水平同样影响着比赛的胜负,而本文暂未考虑选手的因素,在未来的研究中,可以弥补这一不足,从而进一步提升模型预测结果的准确性。
