基于CNN-BiLSTM的滚动轴承变工况故障诊断方法*
2022-11-04董绍江李洋梁天赵兴新胡小林裴雪武朱朋
董绍江,李洋,梁天,赵兴新,胡小林,裴雪武,朱朋
(1.重庆交通大学机电与车辆工程学院 重庆,400074)
(2.重庆长江轴承股份有限公司 重庆,401336)
(3.重庆工业大数据创新中心有限公司 重庆,401000)
引言
轴承作为现代制造业的重要组成部分,其故障诊断意义重大[1]。早期的故障诊断方法大多依赖于专家知识,通过人工手段对原始信号进行特征提取,效率低下,难以处理高速增长的海量数据[2-5]。近年来,深度学习技术在计算机视觉、自然语言处理及语音识别等领域取得了跨越式的发展,一些深度学习方法也被使用到轴承故障诊断领域。
在变工况轴承故障诊断问题上,Li等[6]提出一种改进基于Dempster-Shafer理论的证据融合的集成深度卷积神经网络的算法,将原始时域信号的快速傅里叶变换特征的均方根图输入模型,实现变工况故障诊断。Ding等[7]提出一种基于小波包能量图像和深度卷积网络的能量波动多尺度特征挖掘方法,实现变工况故障诊断。Zhang等[8]提出基于训练干扰的卷积神经网络模型,直接将原始信号输入模型,实现变工况故障诊断。Hao等[9]提出一维卷积长短期记忆网络的多传感器的方法实现变工况故障诊断。
前期相关文献研究成果侧重于强噪声干扰研究或者变工况影响研究,对于变工况和噪声背景的复杂条件下轴承的故障诊断效果不明显。笔者围绕相关问题提出将带有注意力机制、将DropConnect和Dropout混合使用加入到CNN-BiLSTM模型,可以有效地解决这一问题。首先,将轴承时域信号和随机噪声信号输入CNN网络中提取轴承故障特征;其次,经全连接层汇总之后输入带有注意力机制的BiLSTM网络层经过权重分配实现更有效的深层特征提取;最后,通过Softmax层分类器实现滚动轴承故障类别诊断。经试验验证,该方法在变工况和噪声背景下获得了较高的识别精度。
1 CNN-BiLSTM网络模型简介
1.1 卷积神经网络
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。CNN主要由输入层(Input)、卷积层(Conv)、池化层(Pool)、全连接层(FC)和Softmax层5种结构组成。CNN的训练过程由前向传播和反向传播组成,前向传播主要提取输入数据的不同特征,反向传播则主要是优化前向传播的参数,其详细训练过程见文献[10]。
1.2 双向长短时记忆网络
长短时记忆网络(long short-term memory,简称LSTM)是一种循环神经网络结构的变体,能够解决循环神经网络中遇到的梯度爆炸和梯度消失问题[11]。标准LSTM网络结构只有前向传播运算,缺乏前后的逻辑性。双向长短时记忆网络(BiLSTM)是在LSTM的基础上,利用已知时间序列和反向位置序列,通过前向和反向传播双向运算,加深对原序列特征提取,提高模型输出结果的准确性。BiLSTM神经网络最后输出是前向、反向传播的LSTM输出结果之和。BiLSTM网络结构如图1所示。
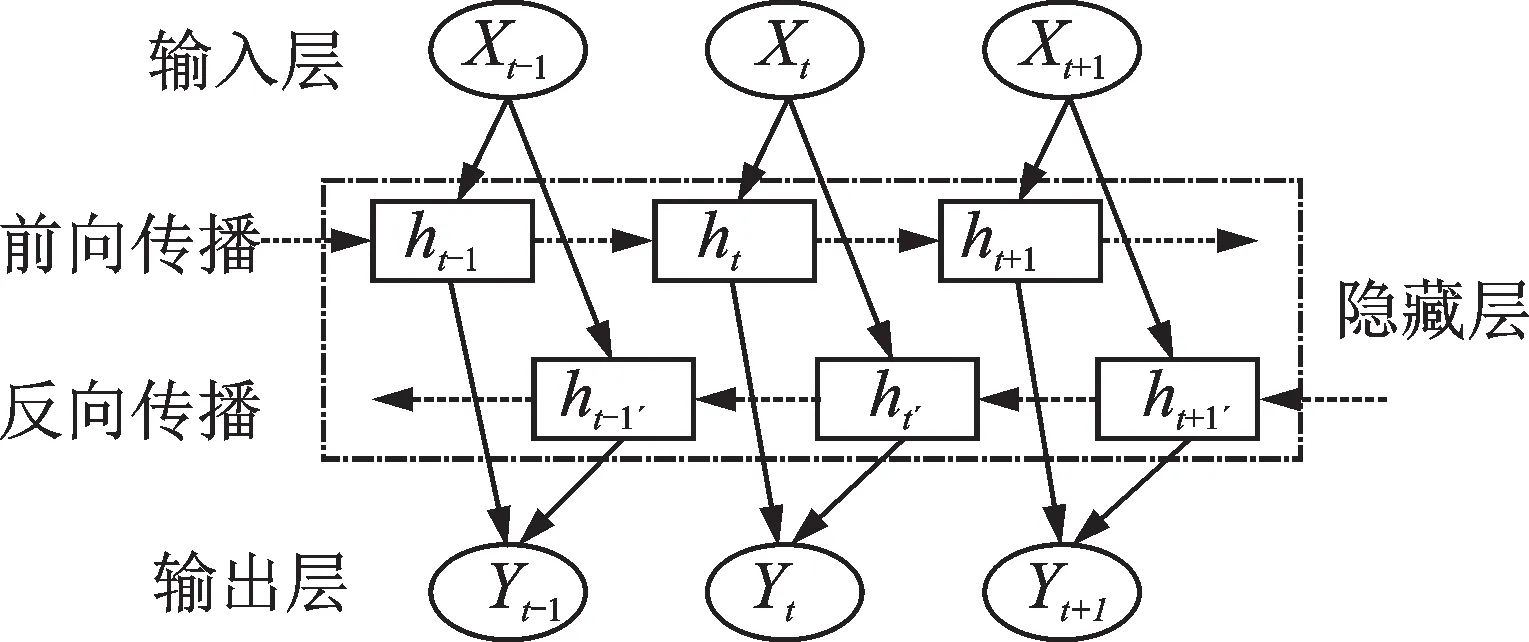
图1 BiLSTM网络结构示意图Fig.1 Schematic diagram of the BiLSTM network structure
2 本研究模型原理及网络结构
2.1 注意力机制原理
在故障诊断领域,对故障进行诊断时通常先需要进行一系列特征提取,以得到故障特征进行诊断。但是在特征提取的过程中,并不是提取到的所有故障特征都有助于故障诊断。为了提高故障诊断的正确率,因此在特征提取时,有必要引入注意力机制对其进行筛选[12]。注意力机制的计算步骤如下。
1)将经过前期网络训练得到的各个故障特征,作为注意力机制层的各输入故障特征yi,即先将输入的故障特征与神经元权重相乘,再加上神经元的偏差;再用双曲正切函数将前面计算得到的值映射到[-1,1]区间,以便于后面计算各个故障特征的权重系数。计算公式为
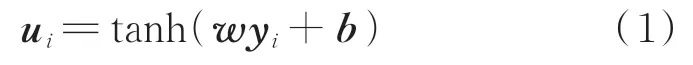
其中:tanh(·)为双曲正切函数,它可以将输入特征映射到[-1,1]区间;w为神经元的权重;b为神经元的偏差。
2)式(2)主要是通过Softmax函数计算出不同故障特征权重以便于后期对输入故障特征中的重要特征进行筛选。经过式(1)计算得到的值,先在经过Softmax函数时可以计算出不同故障特征的权重系数ai,再对其进行归一化处理,得到所有特征注意力权重ai之和为1的概率分布。具体计算公式为
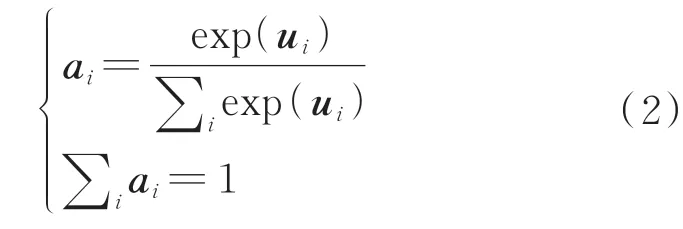
3)式(3)主要是实现重要故障特征的筛选之后的最优故障特征。将各故障特征输入量yi与权重系数ai相乘并求和,得到经过注意力机制优化以后的最终故障特征表达Fc为

由于最终的故障特征经过了权重的重新分配,相较于没有经过注意力机制的故障特征,它反应的是更加重要和关键的故障特征。因此,在原有的训练网络中加入注意力机制层,更有利于提升模型的诊断能力。
2.2 DropConnect和Dropout工 作 原 理
Dropout是一种常用的解决过拟合、提高网络模型泛化能力的方法。Dropout在神经网络的训练过程中,按照一定概率P将一部分中间层单元暂时从网络中丢弃,即把一部分输出置为0,以此避免过拟合,如式(4)所示。DropConnect则是一种通过舍弃一部分输入单元来防止过拟合的方法[13],如式(5)所示。其二者不同之处在于,Dropout一般用于全连接层之后,DropConnect则用于神经网络连接层的权重上,是把一部分输入连接层的权重W单元置为0。二者的网络结构如图2所示。
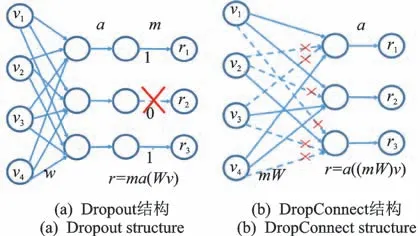
图2 Dropout和DropConnect网络结构Fig.2 Dropout and DropConnect network structure

其中:m为剩余1-P的没有被置为0的概率;a为一个激活函数;W为权重;v为上一层的输出;r为输出,其中m和a(Wv)相乘是对应元素的相乘。
2.3 本研究模型网络结构
本研究所提方法是一种端到端的数据驱动方法,减少了繁杂的人为特征提取过程。该方法在原始信号上加入随机高斯白噪声相当于增加训练样本,不仅可以减弱神经网络的联合适应性,以防止过拟合,还可以增强模型的抗干扰能力[14]。并且在模型的卷积层和全连接层之后,加了可以使得输入数据落入敏感的非线性变换函数区域中的批量归一化(batch normalizatio,简称BN),以防止梯度消失。虽然CNN-BiLSTM模型相较于传统的CNN模型可以提取到更加深层的故障特征,但是为了使网络提取到的特征更有利于故障诊断,笔者引入了注意力机制对深层故障特征进行筛选。为了进一步防止过拟合和提高抗干扰能力,将DropConnect和Dropout混合使用,分别加入到CNN和BiLSTM层模型中。本研究模型主体结构如图3所示,注意力机制的BiLSTM层(A-BiLSTM层)如图4所示。

图3 本研究模型主体结构Fig.3 The main structure of this model

图4 注意力机制的BiLSTM层Fig.4 BiLSTM network layer of attention mechanism
2.4 本研究模型结构参数
本研究模型由4个卷积层和池化层、1个全连接层、1个隐藏层为256的注意力机制的BiLSTM网络层和Softmax层组成。笔者使用反向传播算法和Adam随机优化方法对网络进行训练,迭代轮数为3 000,数据集的训练批处理大小为50,学习率为0.001,DropConnect率为0.5,Dropout率为0.5,激活函数为ReLU,池化类型为最大池化。试验时采用Google的Tensorflow工具箱。各网络层参数如表1所示。
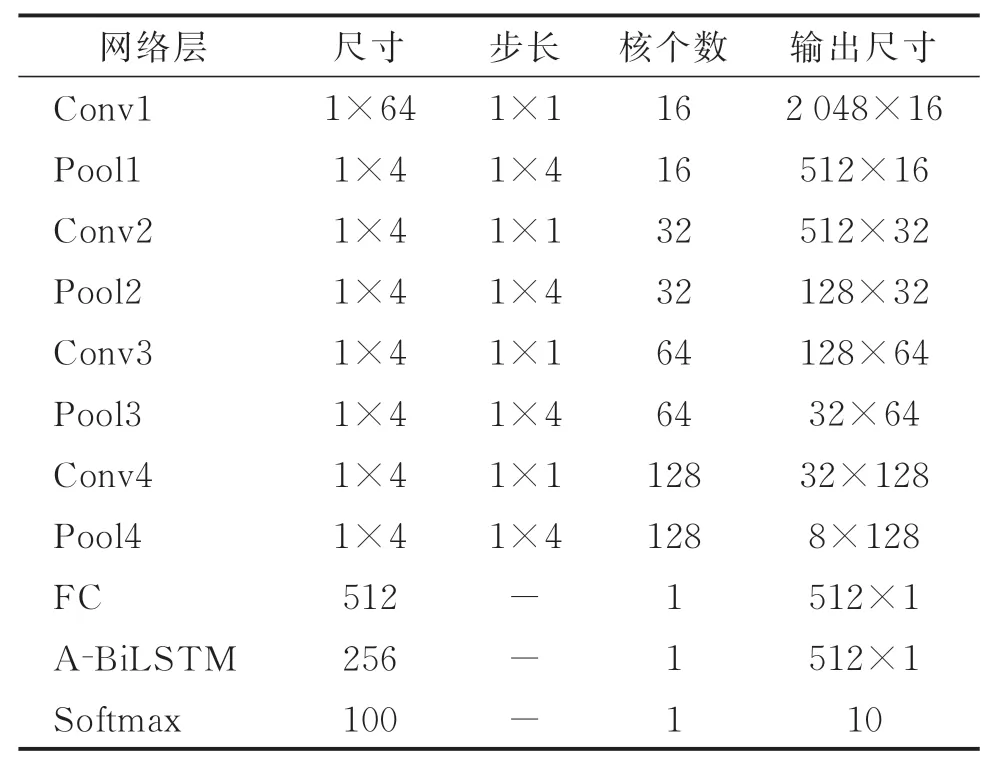
表1 本研究模型各网络层参数Tab.1 The network layer parameters of this model
3 滚动轴承试验验证
3.1 数据选取
3.2 试验模型变量设置
为了消除随机误差对试验结果的影响,本次试验的测试结果为5次的平均值。设置了4个变量,分别是:有无BiLSTM层、有无注意力机制、Dropout添加的位置、有无DropConnect。F1为笔者所提模型:加注意力机制,DropConnect和Dropout混合使用的CNN-BiLSTM模型。F2,F3和F4模型为CNN-BiLSTM模型,F5为传统CNN模型。具体如表2所示。

表2 不同模型的变量设置Tab.2 Variable settings for different models
3.3 试验结果与分析
3.3.1 泛化性和抗噪性试验
试验1:泛化性试验。本研究所提模型主要针对驱动端数据下的轴承故障诊断,本次试验选用4种不同工况数据,也选用风扇端的数据和Mad Net轴承数据来验证笔者所提模型的性能。不同数据集下模型的正确率如表3所示。

表3 不同数据集下模型的正确率Tab.3 Model correct rate under different data sets %
由表3可知:笔者所提模型在驱动端的平均正确率高达99.93%,而文献[7]提出的DCNN模型仅为99.10%;所提模型在驱动端数据和风扇端数据都能达到较高的识别率,但是二者并不相同。造成同一个模型针对不同数据集正确率不同的原因,可能是两者的轴承型号不同、轴承和传感器安装位置不同等因素造成。虽然本研究模型主要是针对驱动端(同类型轴承)不同工况的故障诊断分析,但是在风扇端(其他类型轴承)不同工况下其诊断平均正确率可达100%,在Mad Net轴承数据的10类故障轴承数据试验中,其诊断率也高达100%。通过本次试验可知,本研究模型有较好的泛化能力。
试验2:抗噪性试验。本次试验在选用驱动端的4种不同工况数据测试时,向测试数据集加入高斯白噪声SNR=0 db模拟工业噪声环境,求出各模型平均正确率,其结果如表4和图5所示。

表4 在0 db时不同模型在不同工况下的正确率Tab.4 The correct rate of different models under different working conditions at 0 db %

图5 不同模型的平均正确率Fig.5 The average correct rate of different models
由 表4和图5可以看到,在0 db时,5个模 型在不同工况下诊断能力总存在有高有低的情况,由此说明同一个模型很难在所有的工况下都达到较高的正确率。但是通过分析发现,笔者所提出的F1模型整体性能是最高的,其平均正确率高达98.23%,比F2模型高出0.40%,比F3模型高出2.84%,比F4模型高出4.49%,比F5模型高出5.70%。通过本次试验可以证明,噪声环境下,笔者所提模型有较高的整体抗噪性。
试验3:噪声下的泛化性试验。为了验证笔者所提模型在噪声环境下的泛化性,选用驱动端和风扇端下的4种不同工况的故障数据。本次试验模拟测试数据集在SNR=0 db环境下,笔者所提模型在2种不同轴承上的正确率,其结果如表5所示。
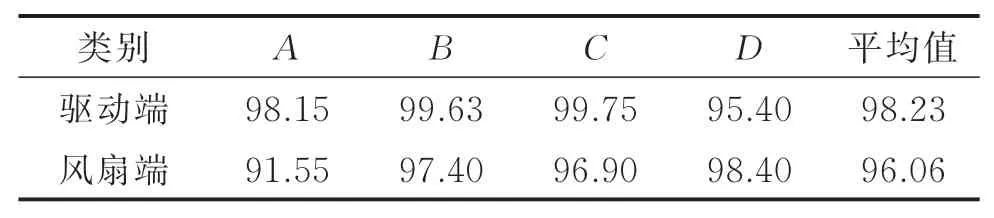
表5 在0 db时不同轴承在4种工况下的正确率Tab.5 The correct rate of different bearings under 4 working conditions at 0 db %
通过表5可知,当SNR为0 db时,驱动端和风扇端在4种不同工况下的正确率都高于90%。驱动端数据在4种不同工况数据的平均故障诊断正确率高达98.23%,风扇端也可以达到96.06%。通过试验可以证明,笔者所提模型在噪声环境下依然有较强的泛化性。
取山羊奶发酵乳5 mL,4℃4000×g离心10 min,取上清液测定抗氧化活性。山羊奶发酵羊乳p H值调至2.0,然后取1 mL接于含9 mL的人工胃酸试管中,充分混匀后37℃保温2 h,沸水浴加热10 min以终止反应。测定消化前后的抗氧化活性。再将其p H调至6.8,以1∶9的体积比加入至人工肠液中,于37℃恒温水浴中模拟消化2 h,沸水浴加热10 min以终止反应,再取样测定其抗氧化。
试验4:Mad Net轴承数据试验。本次试验选取Mad Net轴承数据,测试不同模型在SNR=-2 db环境中的故障诊断能力及各模型的训练时间,其结果如表6所示。

表6 在-2 db时不同模型的正确率和训练时间Tab.6 The correct rate and training time of different models at-2 db
由表6可知,笔者所提模型在强噪声环境下识别Mad Net轴承数据集的正确率达到了94.13%,远高于其他模型。本研究主模型F1是基于F4模型CNN-BiLSTM网络改进的,增加了注意力机制,将DropConnect和Dropout混合使用。在时间仅增加6.88 s的基础上,本研究模型在强噪声环境下的故障诊断能力提升了16.48%,说明了本研究模型在牺牲较短时间的基础上,获得了较高的正确率。
3.3.2 自适应变工况测试
试验1:故障诊断领域常见方法对比试验。自适应变工况测试一直是故障诊断领域的难点,即训练数据集和测试数据集不是同一个工况。本次试验选用驱动端的0,0.75和1.50 kW混合数据训练模型,使用2.25 kW进行测试。主要采用一些故障诊断领域常见的方法,如k最近邻、支持向量机、BP神经网络、文献[7]DCNN模型和文献[9]1DCNNLSTM模型等方法与本研究的方法进行了比较。其正确率如表7所示。

表7 当0,0.75和1.50 kW混合训练2.25 kW测试正确率Tab.7 2.25 kW test correct rate,when 0,0.75 and 1.50 kW mixed training %
通过表7可知,用驱动端的0,0.75和1.50 kW工况下的混合数据训练模型,用2.25 kW进行测试。笔者所提方法正确率高达100%,比一些传统方法和部分深度学习方法的正确率都高,体现出了本研究模型有极高的故障诊断能力。
再选用跟文献[4]多核SSTCA-SVM模型一样的特定变工况类型。1.50 kW训练,0.75 kW测试;1.50和0 kW混 合 训 练,0.75和2.25 kW混 合 测 试;1.50,2.25和0 kW混合训练,0.75 kW测试3种类型试验。其结果如表8所示。
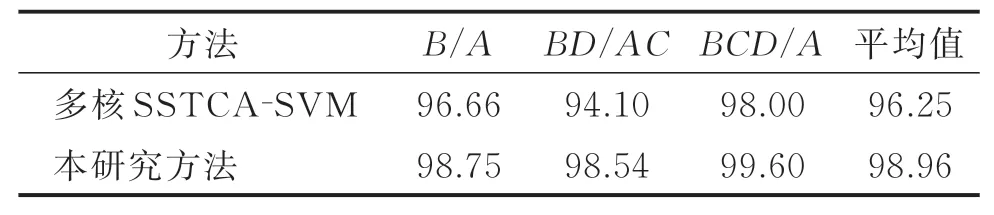
表8 本研究方法与多核SSTCA-SVM对比正确率Tab.8 Comparison of the method in this paper and multi-core SSTCA-SVM correct rate %
由表8可以看出,在以上3种特定变工况类型试验中,笔者所提模型的正确率都高于文献[4]。本研究的平均正确率高达98.96%,比文献[4]高出2.71%。
试验2:变工况下深度学习领域的算法对比试验。接下来主要是与其他论文提出的关于轴承故障诊断的深度学习方法做比较,使用文献[6]IDSCNN模型和文献[8]集成TICNN模型相同的方法做对比试验。选用0.75,1.50和2.25 kW下驱动端轴承数据,仅用一种工况数据训练模型,测试时分别用另一种工况数据测试,其结果如表9所示。

表9 一种工况训练另外一种工况测试的正确率Tab.9 The correct rate of one working condition training and another working condition test %
由表9可知,笔者所提的方法平均正确率高达98.88%,比将原始时域信号作为输入的集成TICNN模型高出2.78%。IDSCNN模型的输入是将原始时域振动信号经过了特征提取,将振动信号的FFT特征的均方根图作为模型输入。由于IDSCNN模型的输入数据是经过复杂的人为特征提取,因此其正确率可以高达98.40%。但是IDSCNN模型相较于本研究直接把原始信号作为模型输入进行变工况下的故障诊断,其平均正确率也比本研究低0.44%。通过跟上述文献中的方法比较,笔者所提模型都取得了较高的精确度。
试验3:不同变工况下的试验。由于轴承实际工作情况下很少出现0 kW的情况,所以接下来的试验不再考虑0 kW的情况下。选用0.75,1.50和2.25 kW的驱动端数据试验。分别采用一种工况数据训练,其余两种工况数据混合测试;用两种工况数据训练,其余一种工况数据测试。其结果如表10和表11所示。

表10 一种工况数据训练两种工况数据混合测试正确率Tab.10 One working condition data training correct rateofmixedtestoftwoworkingconditiondata %

表11 两种工况训练一种测试的正确率Tab.11 The correct rate of the other test for training under two working conditions %
通过试验可知,用一种工况训练,另外两种混合工况测试,本研究模型的平均正确率为98.78%。结合试验2可知,两种工况混合测试比分别测试两种工况的平均正确率98.88%略低。本次试验比试验2低的原因,结合实际情况可推断为当测试数据较为复杂时,其正确率略有下降。
当两种混合工况训练、单一工况测试时,其最低正确率也能高达99%,其平均正确率为99.67%,比用一种工况数据训练模型的平均正确率98.78%高出0.89%。结合实际情况可知,如果能够获取足够多的故障工况训练模型,那么有助于对将会出现的故障进行诊断;当获取的故障工况越少,越难以诊断故障。因此可知,本研究上述试验结果满足实际工作情况。
3.3.3 自适应变工况下噪声测试
由于实际工作中一般难以获得足够多的故障工况数据,因此在故障诊断时会带来一定的挑战。本研究充分考虑实际情况,本次试验选用驱动端轴承在0.75,1.50和2.25 kW下的数据,只研究一种工况数据训练模型,用其他工况数据测试。轴承实际工作时不仅会受到工况变化的影响,也会受到噪声的干扰,因此本小节做自适应变工况下噪声测试。如:0.75 kW训练模型时,诊断过程中分别用1.50 kW,2.25 kW,1.50和2.25 kW混合的3类数据集测试。测试阶段,模拟-4~4 db噪声环境。首先分别用0.75,1.50和2.25 kW训练好3个模 型,然后 依次求出每个模型在每db噪声环境下,3类测试数据集正确率的平均值。如在-4 db环境下的最终值,实际是在3个模型上分别测出3个值,然后对这9个值求其平均。各模型在每db噪声下的正确率及其平均值如表12和图6所示。

表12 一种工况训练其余工况测试的正确率Tab.12 The correct rate of one working condition training and other working condition test %

图6 不同模型在不同噪声下的正确率Fig.6 The correct rate of different models under different noises
由表12和图6可以看到,笔者所提的F1模型在-4~4 db噪声环境中,每db噪声下都高于其他几种模型。F4仅比F5多了一层BiLSTM网络,但在任何噪声环境下F4都比F5高。在-4~4 db下,F4平均正确率为87.45%,比F5高出0.98%。F3是在F4的BiLSTM层中引入了注意力机制,此时F3不仅在任何噪声下都比F4和F5高,而且其最终平均值高达90.00%。由此可见,在网络中引入注意力机制可以使模型在训练时,将更多的注意力放在重要的特征挖掘上,从而极大地提高模型的识别率。
F2与F3,F4及F5相比,F2与F3区别仅在Dropout位 置 不 同。F2在A-BiLSTM中 加Dropout,F3是 在全连接层中加。在SNR为-2时,F2正确率就达到了90.01%。然 而F3,F4和F5均 在90%以下,仅 在SNR大于0时,才达到了90%以上。因此,可以证明将Dropout添加在A-BiLSTM层能够更好地防止随着模型层数的加深而产生过拟合问题。
F1模型与其他模型相比,其最大不同在于将DropConnect和Dropout混合使用。F1主要在F2的全连接层权重上添加了DropConnect=0.5。F1模型在-4~4 db环境下,都高于其他几种模型,在SNR为-4 db时可以达到81.90%,其他模型均不到80%;在-2 db时达到了92.05%;在0 db时高达96.77%;在4 db时更是高达98.77%。在噪声环境下其平均值可以高达94.06%,比没有DropConnect的F2高出了1.30%,比F3高 出4.06%,比F4高出6.61%,比传统CNN模型F5高出7.59%。F1模型同时使用了DropConnect和Dropout,DropConnect通过将CNN网络的一部分输入的数据置为0,以此防止CNN模型训练时的过拟合问题,而Dropout则通过丢弃BiLSTM层的一部分输出数据,防止网络模型层数加深而产生的过拟合问题。因此,通过将DropConnect和Dropout混合使用可以在一定程度上提高模型的整体性能。
综上分析,在用一种工况下的数据训练模型,用其余数据集在-4~4 db环境下测试模型的故障诊断能力。本研究带有注意力机制、DropConnect和Dropout混合使用的CNN-BiLSTM模型具有较强的抗干扰能力,在强噪声环境下,也具有较高的故障诊断能力。
3.3.4 模型结果可视化
本小节主要展示测试过程中各网络层处理故障数据的情况和最后的分类正确率。由于篇幅有限,仅展示SNR为0 db时,用2.25 kW训练模型,用0.75和1.50 kW混合数据集的800个样本的测试情况。图7选用t-随机邻近嵌入(t-distributed stochastic neighbor embedding,简称t-SNE)算法展示了测试样本在各网络层中的特征分布情况。图8通过混淆矩阵的方法展示了测试数据集的最终测试结果,详细地列出了各个类别的分类情况和准确性。

图7 测试样本的特征分布图Fig.7 Feature distribution of test samples

图8 测试结果的正确率Fig.8 The correct rate of test results
通过图7可以看到,测试数据在早期层中是不可分的,随着层数加深,特征变得越来越可分。标签10(正常状态)在Conv2层的时候已经完全被分离开,这表明笔者所提模型有较强的区分故障信号与无故障信号的能力。在带有注意力机制的网络层(A-BiLSTM)中,可以看到不同类别之间区分得更加明显,同类故障之间聚集更加紧凑。通过图8可知,笔者所提方法在SNR为0 db时,针对滚动轴承的大多数故障类别都可以达到100%的诊断能力。仅标签2(滚动体故障0.355 6 mm)和标签3(滚动体故障0.533 4 mm)有少量故障被分类到标签1(滚动体故障0.177 8 mm)上,其二者的错误率分别为0.60%和1.20%,与模型测试输出的98.20%正确率相吻合。
4 结论
1)本研究通过将带有注意力机制、DropConnect和Dropout混合使用加入到CNN-BiLSTM模型中,实现了滚动轴承在变工况的噪声环境下的故障诊断。在选用驱动端和风扇端的两类轴承分别在4种不同工况的故障数据,在测试数据集的SNR为0 db时,驱动端平均故障诊断正确率高达98.23%,风扇端也可以达到96.06%;而且Mad Net轴承数据在-2 db下可以达到94.13%。因此,笔者所提模型在噪声环境中具有较强的泛化性和抗噪性。
2)在自适应测试变工况试验中,选用驱动端的0,0.75和1.50 kW混合训练模型,2.25 kW作为测试时,本研究所提方法高于故障诊断领域常见的方法,正确率高达100%。在用一种工况数据训练模型,分别用另一种工况数据测试时,本研究模型平均正确率高达98.88%,也高于部分文献中使用深度学习的方法。同时,在噪声和变工况的复杂环境中,通过比较不同模型,在-4~4 db噪声下,笔者所提方法正确率高达94.06%,体现了本研究模型的优越性。
3)本研究在CNN-BiLSTM网络中引入有注意力机制,可以帮助网络模型将更多的注意力放在重要特征的提取上;将DropConnect和Dropout混合使用可以分别防止CNN网络和BiLSTM网络在训练过程中的过拟合问题,达到了提升模型故障诊断能力的效果。
