基于模糊SVM模型的计算机网络入侵识别
2022-11-04张璇
张 璇
(安徽体育运动职业技术学院,安徽 合肥 230051)
0 引言
网络技术的迅速发展,优化了计算机网络体系,为更多网络用户提供了便利条件,很多网络端口支持友情访问,即从当前网络端口可以直接连接另外一个网络端口[1]。除此之外,还有很多新型网络技术。然而这些技术的开发,埋藏着一定的安全风险。目前,一些不法分子攻击网络,篡改用户文件信息、盗取重要信息及个人隐私等,给网络用户带来了较大的损失和不便[2]。网络入侵识别是防御不法分子攻击网络的有效途径之一,由于网络入侵行为较为复杂,很难保证入侵行为的识别精度[3]。从目前掌握的资料来看,大部分入侵识别模型的精度较低,未能有效解决网络安全问题[4-5]。为了弥补以往研究的不足,该文选择模糊SVM模型作为工具展开此方面的研究。
1 模糊SVM模型
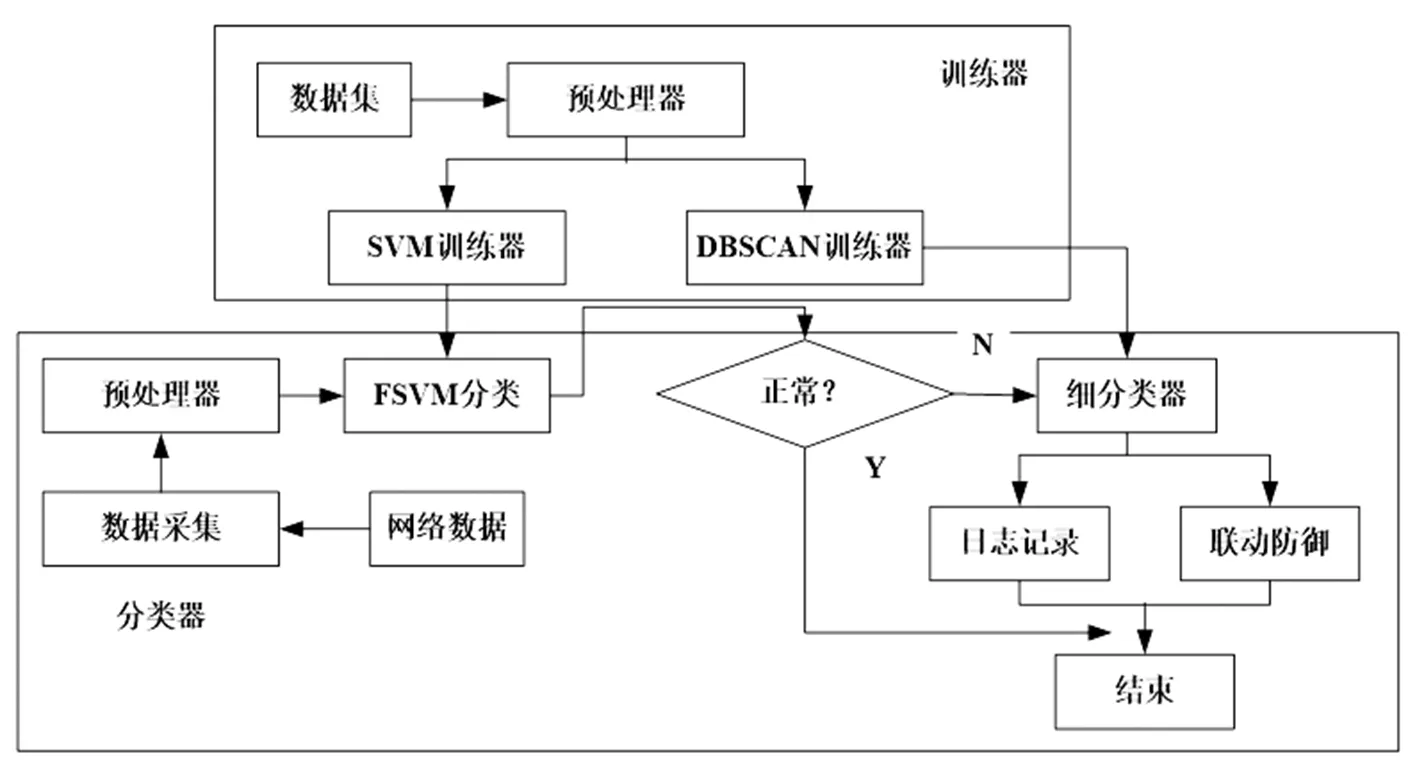
1.1 模糊分类模型的构建
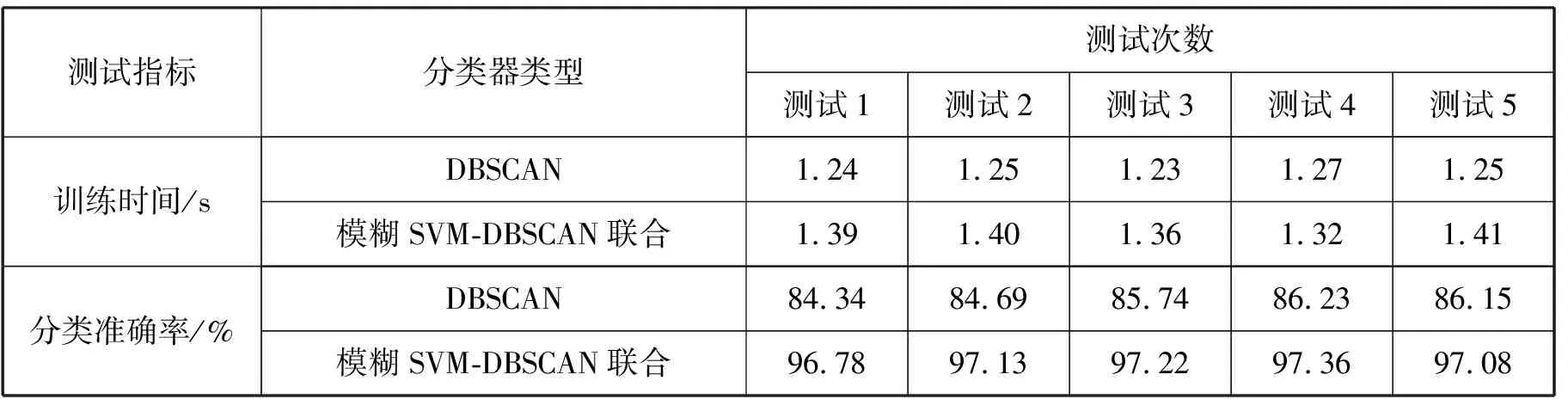
模型引入模糊处理方法,处理噪声、数据孤立点等因素影响问题,从而提高数据分类精准度[6]。另外,模型还采取优化训练SVM参数的方式,针对入侵检测数据采取高精度识别分类。假设样本为i,其标签为li,特征向量为vi,增加函数为fi,用该函数描述隶属度,数值范围0 li[w·λ(vi)+b]-1+μi≥0 (1) 公式(1)中,i的取值范围1,2,…,m;C代表常数,为固定值;μi代表松弛因子。 针对网络入侵检测数据的识别,运用模糊SVM模型转换问题,将问题变为基于数据集训练处理的隶属度函数求解问题。利用SVM训练器、DBSCAN训练处理函数,而后运用分类工具,对网络行为输入进行进一步的识别,判断是否具备入侵行为特性,给出最终判断结果。 模糊分类模型的作业流程。首先需要对数据包进行预处理,而后利用粗分类器,判断当前的数据包中的数据类型。数据分为待处理数据、正常数据,正常数据不需要进行任何处理,待处理数据需要利用细分类器,对数据的类别进行进一步处理[7]。如图1所示为模型作业流程。 图1 模型作业流程 第一步,对数据集中的数据采取预处理,接下来采用两种不同的训练器,对数据进行分类。其中,使用到的训练器有两种,SVM训练器用于初筛,经过该过程处理筛选出感兴趣数据;DBSCAN训练器用于攻击数据类别的划分,是对预处理中表现出攻击特点的数据采取筛选,转入细分类器中,对此部分数据类型进行进一步的分类。第二步,数据类型划分,分别运用FSVM工具、细分类器进行分类。第三步,数据类型判断,对当前数据类型进行判断,如果属于正常数据,则直接结束识别操作。反之,需要将FSVM工具数据结果发送至细分类器中,对此部分数据的类型采取进一步的划分。第四步,对于攻击类型数据,在记录信息的同时,采取联动防御处理。 另外,FSVM工具分类数据对象,除了来自数据集以外,还有一部分直接来自网络数据。利用数据采集工具,从网络中挖掘用户行为数据,而后对此部分数据采取预处理,开启预处理器作业模式,得到初筛结果,此部分结果数据就是FSVM分类作业的数据来源。 为了降低噪声点对入侵数据类型识别的影响,利用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法处理此部分数据,生成聚类后得到的类别数量较为稳定[8]。选取数据集KDD Cup99作为训练数据集,构造4个训练器,对入侵数据类别进行识别。以下为DBSCAN算法应用的核心代码。 输入端:3个输入对象,分别是密度阈值、半径、数据对象集合,记为MinPts、Eps、D。 输出端:聚类,记为C。 DBSCAN( D,Eps,Min Pts) //定义3个输入对象 begin init C = 0; //系统初始化处理。其中,簇数量为 0 for each unvisited point p in D //指针方向的确定 mark p as visited; //标记已访问对象p N=get Neighbours (p,Eps); //按照顺序,对相邻p逐次赋给N if size Of(N)< Min Pts then //设定判断条件,满足该条件时,达到终止循环标准 mark p as noise; //满足上述条件情况下,认为p为噪声,并加以标记 Else //不满足上述判断条件,则执行以下运行语句 C = next cluster; //创建一个新的簇,赋给C Expand Cluster (p,N,C,Eps,Min Pts); // end if end for end 运行上述算法,能够有效识别入侵数据信息中的噪声,对于干扰因素处理有所帮助。 为了扩大识别对象范围,得到更大的数据分类集,在研究方案中引入了Expand Cluster算法,对此算法应用功能的核心程序进行开发,程序如下: Expand Cluster(p,N,C,Eps,Min Pts) //定义5个对象 add p to cluster C; //将p加入集群 C中 for each point p' in N //在N取任意一个 mark p' as visited; //将点p′作为核心点 N'=get Neighbours (p', Eps) ; // 以p′为核心,对N邻域内所有点展开半径检查 if size Of(N')>=Min Pts then //设定判断条件,满足该条件时,达到终止循环标准 N = N + N'; // 满足大于Min Pts条件,则扩展N数目 end if //结束条件判断分析 if p' is not member of any cluster //如果p′不是集群C中的成员,则执行以下程序 add p' to cluster C; // 将 p′加入集群簇C中 end if //结束本轮条件判断 end for //结束本次for循环 end Expand Cluster //结束集群簇扩展 开展实验测试工作之前,需对离散字符型数据采取预处理,而后引入标准处理技术和归一化技术,对此部分数据采取二次处理,经过数据格式转换,得到网络访问行为数据识别对象。其中,实验选取的数据格式为LIBSVM,为SVM模型的运用创造基础条件。 测试以训练时间、分类准确率作为测试指标,利用DBSCAN分类器、模糊SVM-DBSCAN联合分类器识别网络访问行为数据。为了避免单次实验测试得到的结果受某些因素影响降低可靠性,所以开设5组测试实验。其中,每组实验环境和基础环境相同。 分别运用DBSCAN分类器、模糊SVM-DBSCAN联合分类器,进行5次实验,对网络访问行为数据进行类别的划分,从而挖掘入侵行为数据,为网络安全防御工作的开展提供参考依据。表1所示为训练时间与分类准确率测试结果。 表1 训练时间与分类准确率测试结果 表1中统计结果显示,与DBSCAN算法相比,该文提出的模糊SVM-DBSCAN联合算法,虽然耗费的训练时间稍微长一些,但是分类准确率明显提升。例如,测试1中,DBSCAN算法训练时间为1.24s,分类准确率为84.34%,虽然模糊SVM-DBSCAN联合算法训练时间增加了0.15s,但是分类准确率却达到了96.78%。 SVM-DBSCAN双训练器应用下的网络入侵识别模型,配备Expand Cluster算法,能有效提升入侵数据的分类准确率,实现对更多数据类别的识别。实验测试结果显示,该算法应用于多样本数据时,虽然训练时间小幅增加,但分类准确率在96.78%以上,达到网络入侵识别算法改进要求。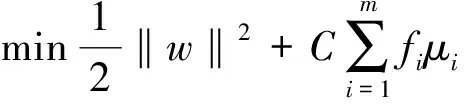
1.2 模型作业流程
2 基于模糊SVM模型的计算机网络入侵识别算法
2.1 DBSCAN算法开发
2.2 Expand Cluster算法开发
3 计算机网络入侵识别实验测试分析
3.1 网络入侵检测数据处理
3.2 测试内容与方法
3.3 测试结果分析
4 结论
