基于智能网关的网络防御模型设计
2022-11-03叶勇健
叶勇健
(厦门华天涉外职业技术学院,福建 厦门 361102)
0 引言
随着互联网规模的发展和壮大,复杂多样的网络攻击行为日益增多,基于网络攻击阻断策略的研究越来越重要。20世纪90年代,美国加州大学戴维斯分校提出了分布式入侵检测系统(DIDS),分布式入侵检测系统主要是在主机方部署网络监视器,以获得该主机的网络信息,再将信息发送到分布式入侵检测系统的网络中心节点进行处理[1-2]。法国MIRADOR项目提出了网络恶意行为的协同识别模型(CRIM),可以通过协调识别的方法主动发现网络攻击行为[3]。日本也很早开始了网络检测认证工作,日本信息化推进机构(IPA)提出了利用移动通信代理技术获得网络流量信息的自动采集[4]。1996年,美国得克萨斯A&M大学提出了智能网格入侵检测系统(CSM),在网格环境主机端(或“上”)部署该系统,采用资源调度算法降低报警数量,确保网络资源使用的负载均衡,属于一个完整的网络攻击阻断系统。美国负责研发军用科技的行政机构提出了EMERALD项目,该项目属于构建大型分布式入侵检测系统[5-6]。
以上研究提出的主要是基于分布式入侵检测系统防御策略,通过对网络报警的实时监测,降低报警重复率和无效率,通过分析报警信息发现网络入侵行为,寻找有效的解决方案。这种方式需要在网络中部署专门域,按照人为设定的模式防御网络入侵行为,实现对网络资源的管理[7-8]。但是,在一体化智能网络结构下,该方法难以实现有效的网络防御功能,因此,提出了基于指数加权移动平均值(EWMA)的攻击阻断权值计算模型,以实现在最接近攻击源的网络节点对网络攻击行为进行有效阻断。
1 基于EWMA的网关阻断权值计算方法
在一体化智能网络下,网关的阻断权值计算要保证网关符合攻击阻断策略的执行条件。主要参数包括:网络带宽F;实时网络流量f;网关与攻击源之间的距离d;时间t;负载参数E。负载参数E是根据实时网络监测情况得到网络负载量,基于指数加权移动平均值(EWMA)算法对网络负载情况进行计算如下:
EWMA(t)=λY(t)+(1-λ)EWMA(t-1)
(1)
+(1-a)EWNA(t-1)
(2)
E=En/n
(3)
a=2/(n+1)
(4)
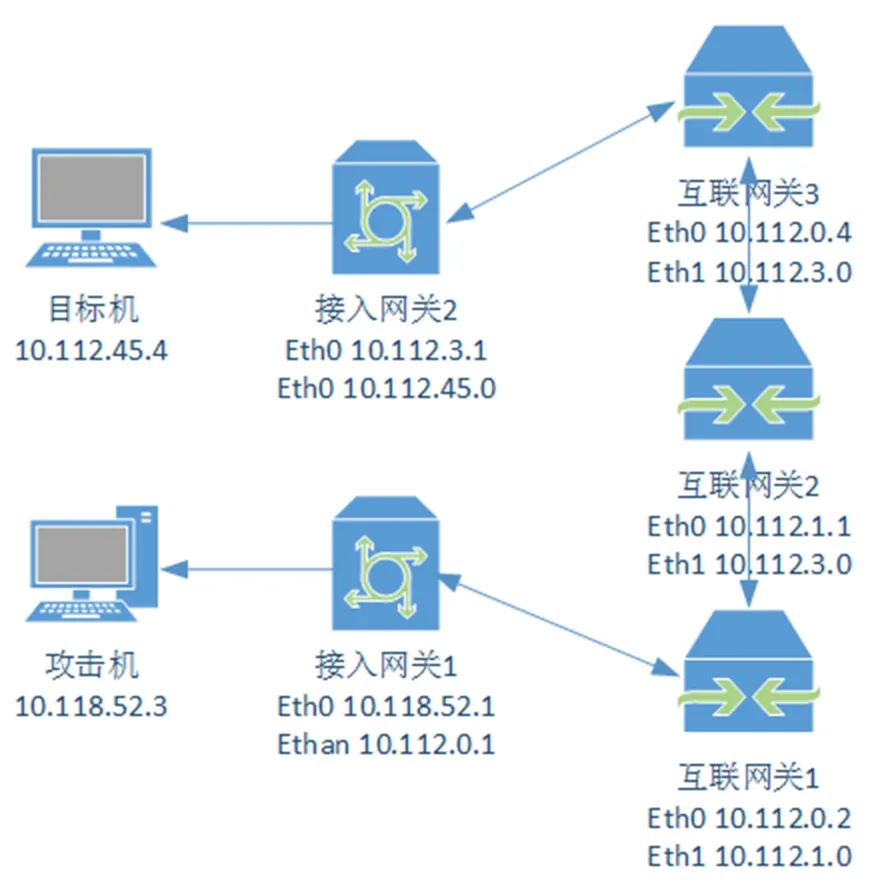
网关性能测量值用Y(t)表示,CPU采集时长用n表示,历史测量值得到的权重系数为a(0 Ni=Ei/CPUNi (5) 通过公式(5)能够获得网关负载情况,如果经过判断后可以下达策略指令,则将该网关汇总到可以执行指令的网关集合中,接着对网关下发指令的权重进行计算并选择网关。主要根据网关到攻击源的距离和网络流量情况计算网关权重。 由于过滤规则会影响网关实际流量,因此,网关与攻击源的距离越近,网关流量越小,给予的权重越高[9-10]。如果网关自身流量较高,再给予较多的过滤规则,则会进一步降低网关性能,网关的权重比计算如下: (6) 公式(6)中,计算得到的网关的权重比值为R,网关的权重系数为k,网关在t时刻的流量用Ft表示,网络攻击源流量经历多个网关到被攻击的距离用D表示。网关的权重比要按照实际的网关流量判定得出,如果获得的网关权重值越小,则其更适合执行网络攻击阻断策略指令。 基于网络攻击拓扑树的攻击阻断权值计算方法需要用到两种数据结构,一是String数据结构,网络防御系统会收集String数据结构类型的网络攻击路径集合,以“,”在字符串中进行间隔,将“,”作为分隔的节点,再将每个网络攻击路径进行还原处理,得到真实的String数据结构类型组,对其进行遍历,Hash Map 对Tree Node数据结构类型中的根节点进行设置,标记为root,同时将其距离变量设置为0,通过Hash Map遍历计算,得到对应的Hash Set值,新建一个Tree Node类型数据结构,把Hash Set值中存储的String数据结构类型数据存储到Tree Node中,此时,将距离变量“+1”,赋值给Tree Node变量,IP值赋值给String数据结构变量,再将新建的已经赋值给对应子节点的Tree Node变量节点存储到Stack栈,再读取Stack栈数据并遍历全部节点。重复以上直到Stack栈中没有数据为止,该过程完成了对网络攻击拓扑树的还原,以及网关到攻击源距离的计算。 只有设置多个网关参数值,才能够对网关负载进行计算。创建一个Hash Map遍历,利用Connection变量与数据库建立连接,选定目标时刻t,获取网关在该时刻之前时间内全部历史测量结果。此时,Hash Map网络攻击路径的源节点的键代表时间,遍历值为该时间的网络流量信息。设置一个全局变量,表示采集时间长度,标记为n;设置一个double类型变量,代表历史测量值权重,标记为k=2/n+1,完成一次计算循环,则将k计算k/2;变量Yt是从Hash Map遍历中获取的数据,表示测量值;采取递归方式,根据公式(2)计算结果,每一次的结果与下一次递归计算结果相加。递归计算的参数包括Hash Map遍历数据、递减后的网关权重系数k、测量时间t、当参数k的数值为0时,代表递归结束,返回0,此时数据对结果影响程度最小。再根据公式(3),获得最终的负载参数E。 根据公式(6)获得节点的攻击阻断权值,创建一个double数据结构类型的变量代表网关攻击阻断权值计算中攻击距离以及网关负载的占比,记作kn,其默认值设为0.5。通过Tree Node数据结构中对网关节点距离的计算,得到网关节点距离变量,表示在网络攻击路径中,网关与攻击源之间的距离,将得到的值通过公式(6)计算得到攻击阻断权值的最终结果,将结果赋值给变量R,得到该网络节点在此次网络攻击阻断中的阻断权值。 该实验主要验证了在网关的网络攻击阻断权值计算中,攻击距离和网关负载占比对计算结果的影响。采用的是纵向比较模式,在设置了不同的攻击距离和网关负载占比情况下,得到的网关攻击阻断权值结果,与预先设置的数值之间的实际差距,以得到最优的攻击距离和网关负载占比。实验网络拓扑结构图如图1所示,攻击源的网络攻击流量通过网关接入了一体化智能主干网络,在不同的互联网网关中进行攻击流量的转发,最终完成了一次完整的网络攻击。由于网关包含了两张网卡,所以显示为两个IP地址,IP地址是该实验自行设置的网络地址。 图1 实验网络拓扑结构图 实验步骤为:构建网络拓扑结构图,设置一个网关路由表;对攻击主机和被攻击主机的IP和路由表进行设置,实现攻击主机与被攻击机的网络通信;在攻击主机上安装网络恶意攻击软件,将攻击目标IP设置为被攻击主机的IP地址,并进行分布式拒绝服务攻击(DDos);更改系统程序,设置多个网关负载k值,对被攻击主机发起多次网络攻击,获得网络攻击阻断权值计算结果。 在完成实验需要的网络拓扑结构图之后,采用虚拟机的方式搭建了接入网关和互联网网关之间的通道。表1为设置的网关路由表,同时包括了网络拓扑图中的各个网关地址、攻击主机和被攻击主机的IP地址。目标地址是攻击流量需要到达的被攻击主机的IP地址,当网关转发攻击流量并达到目标地址时,网关地址为下一个攻击目标的IP地址。 表2给出了不同k值的实验结果,攻击阻断策略下发网关的个数,以及各个网关的流量总和的乘积用以判断攻击阻断的效果。对于攻击阻断 表1 网关路由表 表2 网关的攻击阻断权值计算性能对比 效果实际情况看,如果各个网关的总流量越低,同时阻断策略下发对网关影响越小,攻击阻断的效果越佳。网络攻击流量的值可以通过安装的网络攻击软件进行控制,实验将网络攻击流量设置为1 000MB,通过创建定时的网络流量采集脚本,对网关流量进行实时采集存储,用于实验分析。通过设置专门的网关负载计算脚本,对网关负载进行计算并实时记录,用于计算网络攻击过程中,网关负载的平均值。为了提高实验的有效性和可靠性,保证不同环境下测试结果的准确性,增加了网关负载测试,其值无限接近各个网关的最高网关负载情况,保证阻断权值计算过程中因子取值的可靠性。由表2可以看出,当网关负载因子在0.5~0.6之间,发生网络攻击时,使用网关阻断权值计算方法能够提高阻断效果。 实验结果显示,在接近网络攻击源的攻击阻断方法中,攻击距离和网关负载的占比,对于网络攻击阻断权值的计算结果影响较大。通过对网络负载占比变量k值的改变,采用纵向对比的方式,对计算结果进行比较,分析攻击阻断算法的实际效果。最终获得了当网络负载占比k值在0.5~0.6之间,采用攻击阻断算法获得的阻断效果最好。 实验主要验证历史加权因子变化在网关负载计算中的影响。为此,采用了两种网关负载计算方式,用于计算网络攻击阻断权值。采用加权因子在攻击阻断权值中的计算方法,与历史加权因子在攻击阻断权值中的计算方法进行横向对比,对攻击阻断算法计算结果的有效性和实际阻断效果进行验证,以判断采用历史加权因子对攻击阻断权值计算影响是否具有有效性。 实验步骤为:配置好攻击主机和被攻击主机的路由表,部署网关;开启安装在网关的网关流量采集脚本,每间隔0.1秒记录并存储网关流量信息;配置每秒执行一次任务的定时脚本,通过开启两种网关负载计算方式,将计算结果记录并存储到系统中;对攻击主机的网络攻击流量进行调试,增加或减少攻击主机数量,形成网络流量较大的攻击模式;分析数据得到实验结果。通过对网关流量的实时采集,得到网关流量波动图如图2所示。 图2 网关流量波动图 表3 固定因子与呈指数递减因子计算方式对比 如表3所示,给出了针对网关流量波动图进行负载计算的最终结果。采用网关负载因子中间值及网关负载因子呈指数递减的两种方式,分别计算得到网关负载。根据结果可以看出,当网络流量处于比较稳定的状态时,两种因子的网关负载计算结果相近,且比较准确。但是,当网络流量在某一时间段内出现了较大波动时,采用固定因子得到的计算结果偏离较大;相反,历史数据加权计算得到的网关负载结果更贴近真实情况。 由该实验可以得出,在网络流量比较稳定时,固定历史因子进行网络负载计算得到的结果具有良好的可靠性。当网络流量出现较大波动,且网络连接状况不够稳定时,采用固定历史因子的方式不能够准确计算网络负载,加权历史因子方法计算的网络负载结果可以预测网络波动的情况,能够对网关负载情况做出准确判断。因此,加权历史因子网关负载计算方式更适用于攻击阻断算法。 提出了基于指数加权移动平均值(EWMA)的攻击阻断权值计算模型,给出了攻击阻断权值的计算方法,针对网络攻击拓扑结构分析了影响攻击阻断权值计算结果的因素,分别是网关与攻击源距离、网关负载两个因素。通过基于指数加权移动平均值(EWMA)的攻击阻断权值计算模型实现了对阻断权值的计算。最后,通过实验对该模型的有效性和可行性进行验证,采用网关负载因子中间值和网关负载因子呈指数递减的方式进一步讨论了不同权重因子对计算结果的影响。实验表明,该模型计算方法可以充分满足网关阻断权值计算的现实需求。2 网络攻击阻断权值计算模型构建
2.1 攻击拓扑树计算方法
2.2 计算安全网关负载
3 实验与结果验证
3.1 网关负载与攻击源距离影响因子验证


3.2 历史加权因子影响验证


4 结论
