一种基于差分隐私保护的skyline 查询方法
2022-11-03张丽平金飞虎郝忠孝
张丽平 ,杨 玉 ,金飞虎 ,李 松 ,郝忠孝 ,2
(1. 哈尔滨理工大学计算机科学与技术学院,黑龙江 哈尔滨 150080;2. 哈尔滨工业大学计算机科学与技术学院,黑龙江 哈尔滨 150001)
Skyline 查询是解决计算机多目标优化问题的一类重要方法,由Borzony 等[1]提出,目前在位置导航、数据挖掘和推荐算法中具有越来越广泛的应用[2-5]. 尽管skyline 查询机制从理论上讲能够保证隐私,但在实践中,攻击者通过重复攻击仍然可以获得个人信息[6]. 因此,需要进一步研究该机制中防止重复攻击的问题. skyline 查询的结果为没有被其他任何点支配的对象,也正是因为这一特性,用户的隐私容易泄露[7]. 为进行数据的隐私保护,Dwork[8]提出了一种基于差分隐私保护的方法,通过对数据进行一般的统计分析,为隐私保护提供定量的评估技术,从而实现差分隐私保护的功能. 文献[9]提出了一种操作方便、定量准确的方法,可以在执行独立的差异私有机制的过程中跟踪累积的隐私损失. 文献[10]提出了一种基于环境中整体迹线和已发布迹线之间相互联系的方法,该方法可以在给定查询约束的情况下将迹线隐私泄漏的几率最小化. 文献[11]提出了一种设置线性查询数量上限的方法,该方法能够找到最优的线性查询. 基于差分隐私的查询机制有两种,分别是拉普拉斯机制[12]和指数机制[13],基于差分隐私的数据挖掘方法广泛应用于频繁模式挖掘[14]、MapReduce 大数据分析查询[15]、智能权重截取算法[16]和智能电网[17].
为了解决差分隐私保护机制中重复攻击会泄露用户隐私的问题,国内外研究人员提出了许多解决方法. 文献[18]为解决二维多媒体数据不均匀和精度降低的问题,提出了一种基于标准偏差圆半径的差分隐私噪声动态分配算法. 文献[19]使用传统搜索未涵盖的属性关联来调查新的隐私威胁,通过配置差异隐私的噪声参数来减轻周期滑动推理攻击对差分隐私的影响. 文献[20]通过对样本数据进行训练,获得一个对抗性网络数据模型,将噪声数据添加到真实数据集中,可以在高斯分布下实现不同等级的隐私保护. 文献[21]提出了一种用于位置数据隐私的隐私保护方法,该方法可满足不同的隐私约束. 但是,目前这些方法都无法满足skyline 查询中隐私保护的要求,并且无法动态设定隐私预算值以实现不同等级的隐私保护级别. 文献[22]提出了一种设定查询上限的高效方法,通过计算准确性的期望值与可用于补偿个人的预算值之间的平均值来确定计算查询上限. 文献[23]提出了一种基于环境中整体迹线和已发布迹线之间的相互联系的方法,通过计算整体位置迹线的隐私度量值来确定接下来最优的位置迹线方案,该方法可以在给定查询约束的情况下将迹线隐私泄漏几率最小化. 文献[24]提出了一种设置线性查询数量上限的方法,通过找到最优的线性查询,设置查询数量的上限,使得最优的线性查询也无法泄露过多的隐私. 但是仍然无法在分级查询中动态改变隐私预算值的同时对查询次数的上限进行调整.因此,文献[25]提出了一种有效且可保护隐私的在线医疗基础诊断框架,在该框架内通过skyline 查询,用户可以准确访问在线医疗诊断服务,而无需泄露他们的医疗数据.
综上所述,针对传统skyline 查询方法无法有效地解决用户隐私泄露的问题,提出了一种基于差分隐私保护的skyline 查询方法. 本文的主要贡献包括3 个方面:
1) 为提高skyline 查询的效率,提出最优主导页的概念. 最优主导页能够针对skyline 查询结果的分页特性,确定查询范围的数据隐私保护等级. 针对skyline 查询的特性提出页敏感度的概念,页敏感度能够满足ε-差分隐私.
2) 为解决因噪音导致有效查询结果的范围无法量化的问题,引进置信区间和置信率的概念;为解决不同信任等级的用户查询结果相同会泄露数据隐私的问题,提出一种基于置信率的隐私预算值调节方法,对不同的信任等级的用户设定不同的隐私预算值,实现数据的分级保护.
3) 为解决攻击次数过多导致用户隐私泄露的问题,提出调整隐私预算和置信率,限制查询次数的策略,从而保护隐私数据.
1 基本定义
定义1全局敏感度[12]. 设有函数f:T→Rd,T为输入数据集,输出为d维实数向量. 对于T的任意邻近数据集Ta,函数f的全局敏感度GSf= max{T,Ta} ||f(T) -f(Ta) ||1,其中,||f(T) -f(Ta) ||1是f(T) 和f(Ta) 之间的1-阶范数距离,表示相差的个数,这里个数只能为1,若 ||f(T)-f(Ta) ||1=1,表示相差一个.
函数的全局敏感度由函数本身决定,不同的函数会有不同的全局敏感度. 一些函数具有较小的全局敏感度,因此,只需加入少量噪声即可掩盖因一个记录被删除对查询结果所产生的影响,从而实现差分隐私保护. 但是仍然无法满足某些需求,例如求平均值和中位数等函数,则具有较大的全局敏感度. 此时,敏感度可能是一个很大的值,无法满足隐私保护的要求. 为解决该问题,进一步提出了页敏感度的概念.
定义2页敏感度. 设有函数f:T→Rd,T为一个输入数据集,输出为d维实数向量,对于输入数据集T和任意的邻近数据集Ta,LSf(T) = max{Ta}×||f(T) -f(Ta) ||1,称为函数f在数据集T上的页敏感度.
为进一步调节页敏感度,合理设置隐私预算的值,引入了基于差异化拉普拉斯分布的置信区间和置信率的概念. 置信区间和置信率与隐私预算有关,隐私预算的大小决定隐私保护的效果,如果所添加的噪声是有效的,则一次查询无法获得用户的隐私.但是,如果攻击者进行多次重复攻击,并且噪声分布符合拉普拉斯分布,实际结果就会在某一个区间. 为进一步量化该区间范围,给出置信区间的定义如定义3 所示.
定义3置信区间. 符合拉普拉斯分布的噪声在某一个区间范围内,如果用 φ 代表置信区间的一半长度,则 [ -φ,φ] 为置信区间[24].
由拉普拉斯分布知置信区间是对称的,则可以推断出被攻击数据的私有数据,并且可以通过累计函数计算攻击的成功率A(T),实际结果为
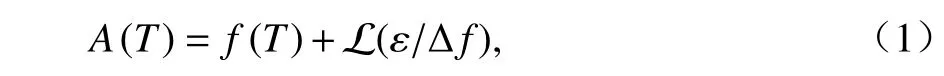
式中:ε为隐私预算值; Δf为全局敏感度; L(·) 为拉普拉斯变换.
L(ε/Δf) 的置信区间为[ μ-φ, μ+φ] ,其中,μ为位置参数,是相对于参数 φ 对称的未知参数. 为量化计算结果在置信区间的概率,进一步给出了置信率的概念,如定义4 所示.
定义4置信率.f(T)的查询结果落在置信区间[μ-φ, μ+φ]的概率为置信率,则置信率通过累计函数计算为[24]
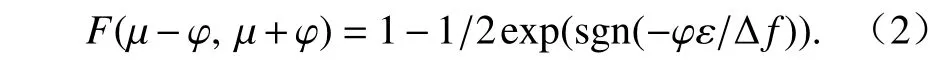
根据置信率进一步量化隐私预算值ε的上界,设p为隐私泄露的概率,则

隐私预算值上界可以限制隐私预算值的大小,并且与置信率相关. 查询结果有两种可能性,分别是查询结果落在置信区间和查询结果不落在置信区间,两种结果互斥. 设攻击者进行查询的总次数为C,在置信区间内的查询结果次数为m,m为大于0 的整数,则攻击成功的概率为
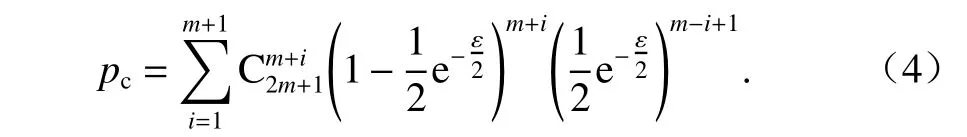
因此,若对攻击者的成功率进行限制,使其不大于某个阈值,则能够确定隐私预算的取值范围. 隐私预算ε的选择与查询的页敏感度LSf(T)、攻击者的总查询次数C、置信区间 [ -φ, φ] 和攻击成功率pc有关,隐私预算取值范围的计算如式(5)所示.
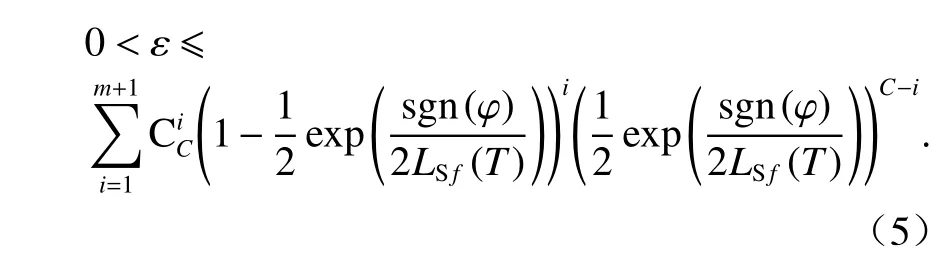
理想的情况下,成功的事件和不成功的事件互斥,ε的值接近1/2 时,则成功率近似为50%. 假设置信区间为 [ 1/2-ω,1/2+ω] ,其中,ω为用户设定的成功率参数,取决于数据的隐私性和能够承受攻击的上限. 当查询结果在置信区间的成功率大于1/2 时,可对页敏感度进行调整,即降低页敏感度,增加隐私保护等级,因此,置信区间成功率可以控制在用户设定的 [ 1/2-ω,1/2+ω] 区间内.
最后,为对skyline 的查询结果进行优化,给出最优主导页的概念如定义5 所示.
定义5最优主导页. 根据支配页将skyline 查询的输入数据集T分为h个子数据集Tsub1,Tsub2, … ,Tsubh,在一次具体查询中,如果查询数据集为部分子数据集Tsubk,Tsubk+1, … ,Tsubk+z,其中k和z为正整数且0 <k+z≤h,则该查询的最优主导页为Tsubk.
2 基于差分隐私保护的skyline 查询方法
skyline 查询结果通常是隐私数据,故用户的隐私更容易泄露. 为保护用户隐私,提出了基于差分隐私保护的skyline 查询方法,所提方法的主要思想为:根据查询对象的范围确定查询的最优主导页,从而确定页敏感度;根据查询者的查询范围、查询次数评估查询者的信任等级,限制查询次数;根据页敏感度和信任等级进一步确定隐私预算,给出查询结果.
2.1 最优主导页的计算方法
最优主导页是指在一次skyline 查询范围中,隐私最容易被泄露的某一页查询结果. 最优主导页的计算过程为:首先,通过skyline 查询获得查询结果,将隐私最容易被泄露的某一页查询结果确定为最优主导页;其次,遍历数据集并实时更新查询结果;后续依据查询范围的改变再动态更新最优主导页. 如图1 所示,图中,Pt、Oy分别为第t页、第y个对象.
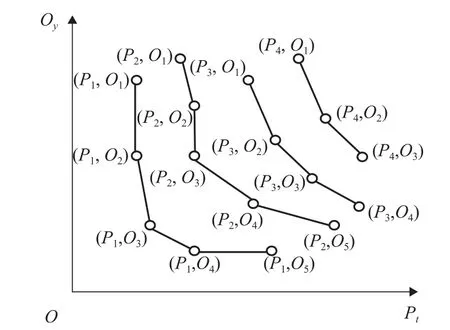
图1 skyline 分页查询示例Fig. 1 skyline paged query
首先,利用skyline 分页查询对所有的数据点进行分页,查到每一页所有不被支配的数据点,每一页为一个隐私泄露等级的子数据集.
第一页的第一个对象记为(P1,O1),第一页的对象子数据集为{(P1,O1), (P1,O2), (P1,O3), (P1,O4),(P1,O5)},以此类推,每一页查询结果如表1 所示.

表1 skyline 分页查询结果Tab. 1 Skyline paged query results
根据所有对象的属性向量计算第i(i= 1, 2, …)页skyline 查询结果,第1 页为首次查询确定的最优主导页,每一次查询的最优主导页都代表最容易泄露当前数据隐私的子数据集.
2.2 页敏感度的计算方法
在skyline 查询过程中,局部敏感度计算的过程比较复杂,全局敏感度无法对子集进行分类保护;查询次数和查询结果的隐私泄露程度具有正相关性,页敏感度能够调节两者相关性的大小.
基于差分隐私保护的查询通过添加噪音干扰查询结果,从而保护用户隐私. 查询机制有两种,分别是拉普拉斯机制和指数机制,其中拉普拉斯机制是一种噪音干扰机制,噪音是一种满足拉普拉斯分布(Laplace distribution)的函数. 基于拉普拉斯机制的skyline 查询的页敏感度为LSf(T)时,满足ε-差分隐私.
基于以上论述,所提计算页敏感度算法 (page sensitivity calculation algorithm,PSC_A)的主要思想为:首先,在预处理阶段通过skyline 查询结果初步确定第一次查询的最优主导页,并计算页敏感度;其次,在每次查询时遍历数据集,将当前计算的页数与最优主导页进行比较,更新最优主导页,最终,输出页敏感度的值. PSC_A 如算法1 所示.
算法1PSC_A /*页敏感度计算算法*/
输入:数据集T.
输出:页敏感度LSf(T).
1) 执行skyline 查询,通过skyline 查询结果初步确定第一次查询的最优主导页;
2) 对skyline 查询数据集T进行遍历,计算每一个对象的页数;
3) 将当前计算的页数与最优主导页进行比较;
4) 如果当前数据对象的页数小于最优主导页,则更新最优主导页;
5) 计算当前最优主导页的页敏感度LSf(T);
6) 返回页敏感度LSf(T).
2.3 基于置信率的隐私预算值调节方法
针对不同的隐私泄露等级的子数据集,为了差异性地保护隐私,利用基于拉普拉斯分布的差分隐私保护机制保护数据隐私. 传统的隐私保护方法可以通过引入随机性增加干扰,达到对隐私的有效保护. 设x为查询参数变量,Nnoise是服从某种随机分布的噪声,则f(x) =Ccount(x) +Nnoise,其中,Ccount(x)为针对x的统计函数. 在传统的差分隐私保护方法中,无法对输出的结果进行特定的处理,针对skyline 分页查询结果集中的数据隐私保护等级不同的问题,为进一步对不同隐私等级的数据进行分级调节,提出基于置信率的隐私预算值调节方法.
利用拉普拉斯机制执行ε-差分隐私保护,将满足拉普拉斯分布的随机噪声添加到查询结果中,拉普拉斯机制满足
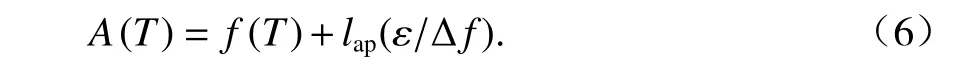
拉普拉斯噪声计算公式为
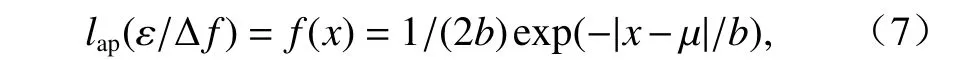
式中:b> 0 为尺度参数.
设b=ε/ Δf, μ = 0,则
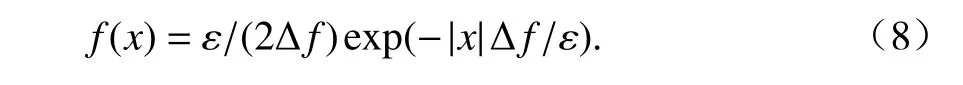
对于任意绝对值变量,累计函数为
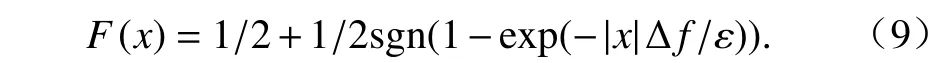
添加的噪声大小与隐私预算值ε和 Δf密切相关,ε的取值越小,隐私保护效果越好,但是数据的有效性越低;ε的取值越大,数据的隐私保护则效果越差,但是数据的有效性越高. 基于以上论述分析,所提出的基于置信率的隐私预算值调节算法(privacy budget adjustment algorithm for confidence rate,PBAACR_A)如算法2 所示.
算法2PBAACR_A /*隐私预算值调节算法*/
输入:查询数据集T, 置信区间[1/2-ω,1/2+ω],查询次数C.
输出:隐私预算值.
1) 调用PSC_A 算法计算页敏感度;
2) 针对置信区间 [ 1/2-ω,1/2+ω] ,利用页敏感度和式(2)计算置信率;
3) 利用式(3)计算隐私预算值;
4) 基于拉普拉斯机制执行ε-差分隐私,利用拉普拉斯噪声计算公式(式(7))将满足拉普拉斯分布的随机噪声添加到查询结果中;
5) 对置信区间 [ 1/2-ω,1/2+ω] 的隐私预算值进行判断,如果满足该置信区间的置信率要求,则输出隐私预算值;否则,隐私预算值设置为0.
2.4 基于差分隐私保护的skyline 查询算法
基于页敏感度计算和隐私预算值调节方法,针对skyline 查询的次数过多导致用户隐私可能泄露的情况,可采取限制用户查询次数的策略加大隐私保护力度. 在置信区间为 [ 1/2-ω,1/2+ω] 的情况下可根据隐私预算值和全局敏感度计算出置信率. 查询结果满足ε-差分隐私的查询次数上限设为c,当查询次数达到c时,需要对用户信任等级和隐私参数重新计算,再利用PBAACR_A算法对隐私预算值进行调节,最终得到满足隐私保护要求的skyline查询结果.
进一步给出基于差分隐私保护的skyline 查询算法(skyline query algorithm for differential privacy protection,SQADP_A ),该算法首先计算隐私预算值;其次,基于隐私预算值更新查询次数上限;对每次查询结果进行判断;查询完成后再计算页敏感度;最后,利用拉普拉斯机制添加噪音,输出skyline 查询结果. SQADP_A 如算法3 所示.
算法3SQADP_A /*基于差分隐私保护的skyline 查询算法*/
输入:查询数据集T,置信区间 [ 1/2-ω,1/2+ω] ,查询总次数C,满足ε-差分隐私的查询次数最大值c.
输出:skyline 查询结果.
1) 调用PBAACR_A 算法得出隐私预算值;
2) 判断隐私预算值,若隐私预算值为0,则更新查询次数上限,重新计算隐私预算值;若隐私预算值不为0,则增加查询次数;
3) 基于置信区间 [ 1/2-ω,1/2+ω] 计算置信率;
4) 遍历查询数据集T中的所有子数据集;
5) 针对相邻子数据集进行skyline 查询,得到查询结果集;
6) 计算页敏感度;
7) 利用拉普拉斯机制,根据隐私预算值和页敏感度对查询结果集添加噪音;
8) 发布skyline 查询结果.
3 实验评估
3.1 实验环境
为更好地保护隐私,本实验加入人工合成的人名、性别和年龄等信息. 人名为随机生成的3 个汉字,性别为男或者女,年龄为0 ~ 100 周岁的整数,符合正态分布. 实验环境为Microsoft Windows 10,Core (TM) i7- 3537U CPU@ 2.00 GHz (2 501 MHz)处理器,4 GB 内存. 假设人名、性别和年龄均为隐私数据,本实验分析skyline 查询的效率、查询结果的可靠性以及查询结果的隐私泄露程度.
为构造对比算法,对文献[20]所提算法和文献[21]所提算法的关键步骤进行适当的修改. 在文献[20]所提算法进行剪枝之前增加了最优主导页的计算,并将敏感度更改为页敏感度,简称为OGWP (optimizing GAN obfuscator with pruning)算法;在文献[21]所提算法进行信息熵的计算之前增加最优主导页的计算,并将敏感度的计算更改为动态调节敏感度,简称为FOQIL (find the optimal quantization interval length)算法. 本节将本文所提SQADP_A 算法与OGWP 算法、FOQIL 算法进行对比实验,验证所提算法的可行性和有效性.
3.2 实验结果分析
实验1本实验主要对比3 种算法的数据规模对算法执行时间的影响. 图2 展示了数据集对象数量从64 kB 增长到1 024 kB 时3 种算法的查询效率对比结果,分别分析数据规模的不同对CPU 运行时间的影响. 由于剪枝算法能够剪掉一部分无效对象,且最优主导页是动态更新的,所以3 种算法在数据规模较小的时候相差不大,但是随着数据规模的增加,FOQIL 算法需要额外处理的数据量较多,因此,对很多无效的对象进行最优主导页和信息熵的计算量也增加,查询效率相对较低. 梯度修剪策略由于没有涉及到大量的复杂计算,而是基于高斯分布针对不同场景进行差异化剪枝,因此,OGWP 算法效率较高.
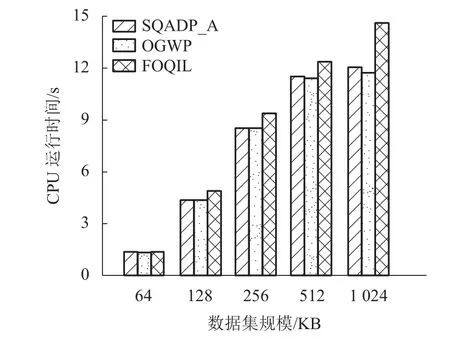
图2 数据规模对查询效率的影响Fig. 2 Effect of data size on query efficiency
实验2本实验主要评估数据规模对查询结果可靠性的影响. SQADP_A 算法依据剪枝规则和存在概率排序规则进行查询. 实验中数据项泄露数为结果集中隐私数据数量,因变量为数据集的规模,在5 个不同规模的数据集上进行查询. 如图3 所示,因为每次skyline 查询的结果输出后,才作为计算页敏感度的剪枝结果,所以SQADP_A 算法的输出结果集的无效数据最少. 与SQADP_A 算法相比,FOQIL 算法的查询结果隐私项较少,隐私保护等级较高,但是由于涉及到大量的计算,查询效率较低.OGWP 算法输出结果的隐私数据数量高于FOQIL算法和SQADP_A 算法,隐私保护效果最差. 因此,由实验结果可知:如果不考虑查询时间的影响,FOQIL 算法和SQADP_A 算法更能保护用户隐私.此外,虽然FOQIL 算法和SQADP_A 算法的隐私保护等级相差不大,但是,SQADP_A 算法的查询速度更快. 因此,随着数据规模的增加,SQADP_A 算法能在查询速度较快的情况下增强查询结果的隐私保护.
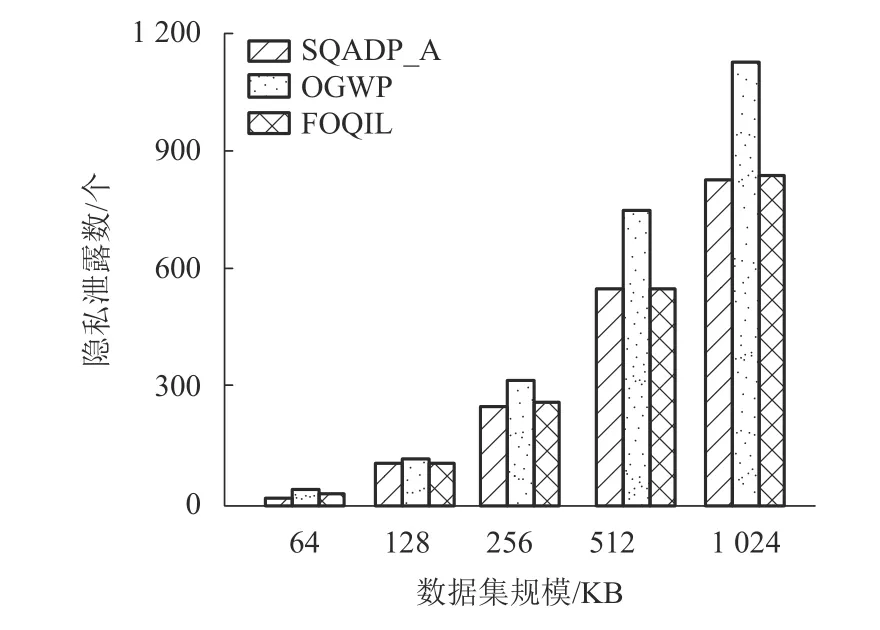
图3 数据规模对查询结果可靠性的影响Fig. 3 Effect of data size on the reliability of query results
实验3本实验评估了隐私预算值调节策略和梯度修剪策略对算法输出结果集的隐私泄露程度的影响. 实验中采用控制变量法保证隐私预算值计算的策略不同,结果如 图4 所示. 由图4 可知:两种查询算法在skyline查询过程中采用不同的策略,其查询结果集中的有效的隐私泄露数具有显著差异;隐私预算值调节策略更适应于对skyline 查询隐私保护要求较高的场所,skyline 查询的查询结果为没有被其他任何点支配的对象,关于skyline 查询的查询结果通常是隐私数据,因此,这种方式可以用较小的时间代价换取隐私保护等级的增加;而梯度修剪策略虽然具有较快的查询速度,但是隐私泄露程度随着数据规模的增加而快速增加. 故如果对skyline查询结果的隐私保护有较高要求则可以采用隐私预算值调节策略,对查询速度有较高要求则可以采用梯度修剪策略.
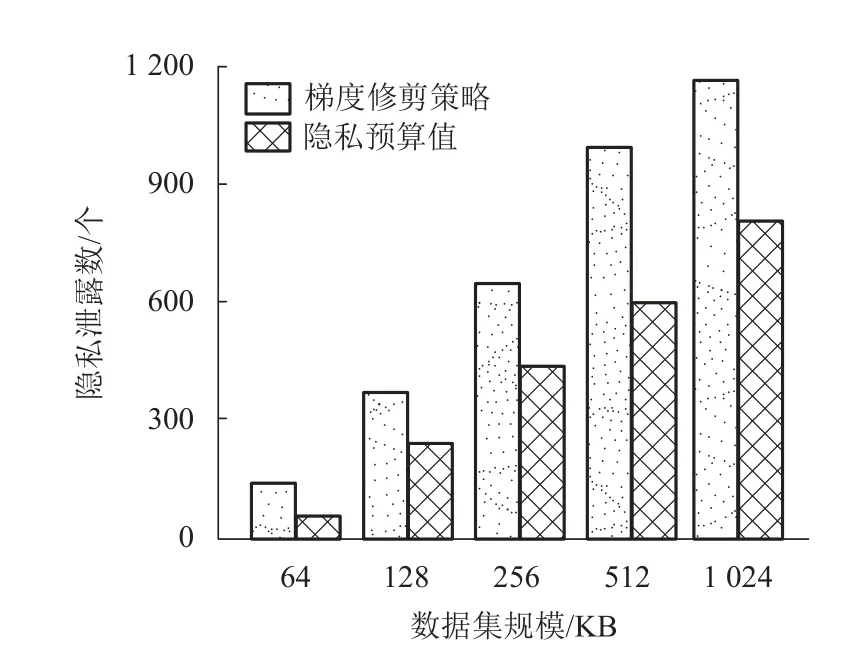
图4 两种策略对查询结果隐私泄露程度的影响Fig. 4 Effect of two strategies on the degree of privacy disclosure of query results
实验4本实验评估了3 种算法中的隐私预算值设定对skyline 查询结果集中隐私泄露程度的影响,数据规模为256 kB,隐私预算值分别设为10.0、5.0、0.8、0.5、0.4,实验结果如图5 所示. 由实验结果可知:隐私预算值设定较低的情况下3 种算法的隐私泄露程度没有明显的区别,3 种算法在隐私预算设定为0.4 时的隐私泄露的差距较小,但是随着隐私预算值设定值的增加,SQADP_A 算法的隐私泄露程度逐渐收敛,并且在隐私预算值较小(小于5.0)的情况下,SQADP_A 算法的隐私保护效果最好. 隐私预算设定值为10.0 时,OGWP 算法的隐私泄露程度较高,随着隐私预算值的增加,FOQIL 算法的隐私保护效果有降低的趋势.
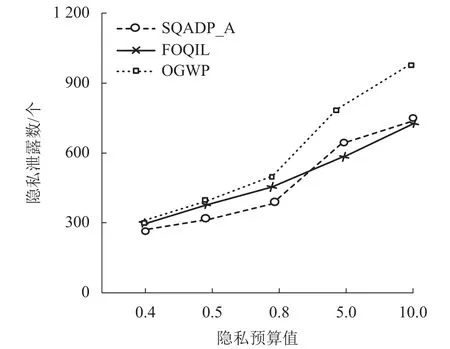
图5 隐私预算值对隐私泄露程度的影响Fig. 5 Effect of privacy budget value on privacy disclosure
实验5本实验评估了3 种算法中的隐私预算值设定对skyline 查询结果集中准确率的影响,实验结果如图6 所示. 由图6 可知:隐私预算值设定较低的情况下,OGWP 算法的查询准确率最低;随着隐私预算值的增加,OGWP 算法的隐私保护效果变差,OGWP 算法的查询准确率却有所提高. 在隐私预算值设定较低的情况下,SQADP_A 算法的查询准确率最高,当隐私预算设定为0.8 以内时其查询准确率没有明显的变化,当隐私预算值设定大于0.8 时,查询准确率有明显变高的趋势. FOQIL 算法在隐私预算设定较低的时候也有较高的准确率,隐私预算值设定为0.8 以内时,准确率变化依旧不明显,甚至有降低的趋势;当隐私预算的值大于0.8 后准确率逐渐增加. 由实验可知:在skyline 查询结果中,SQADP_A 算法的准确率相对最高.

图6 隐私预算值对skyline 查询结果集中准确率的影响Fig. 6 Effect of privacy budget value on the accuracy of skyline query result set
4 结 论
skyline 查询的隐私保护问题受到越来越广泛的关注,差分隐私能够有效地保护skyline 查询结果中不同子结果页的隐私. 本文研究了基于差分隐私保护的skyline 查询方法,提出了有效的页敏感度计算方法和隐私预算值调节策略. 页敏感度的计算能够有效地适用于skyline 查询方法,基于置信率和置信区间的隐私预算值调节策略确保了数据对象的有效性. 最后给出了基于拉普拉斯机制进行查询结果隐私保护的SQADP_A 算法. 通过实验表明:所提方法能减少skyline 查询结果的隐私泄露数量,为用户提供有效的隐私保护. 未来将深入研究不确定高维skyline 查询过程中的数据隐私问题,使得在执行多次查询时,查询结果不仅能保证数据的有效性,也能保证数据的隐私性.
