基于BLS-Lasso组合模型的火电厂蒸汽量预测
2022-11-01封之聪祝云高枫
封之聪, 祝云, 高枫
(广西电力系统最优化与节能技术重点实验室(广西大学), 南宁 530004)
火力发电是中国的主要发电方式之一,是由原料焚烧加热水产生水蒸气,产生的蒸汽驱动汽轮机转动,再由汽轮机驱动发电机转动以产生电能。影响火力发电效率的主要因素是锅炉的燃烧效率[1],即燃料燃烧加热水产生水蒸气的过程。蒸汽量的准确测量,对于提升燃烧效率、提高汽轮机的经济稳定运行具有重要的意义。通过建立蒸汽量预测模型,运用该模型模拟锅炉的运行过程,优化运行参数;根据预测模型参数,提高火力发电的整体工艺水平;通过预测结果,实现对能耗的评估,为电厂的运行操作提供可行性建议。
目前直接测量蒸汽量的方法主要是通过流量孔板或喷嘴等标准节流装置,但是使用节流装置容易造成节流损失,从而影响机组的出力[2]。利用传统的弗留格尔公式计算蒸汽流量存在着局限性,如使用弗留格尔公式的前提是通流面积是恒定的,但是在实际生产过程中由于机组负荷的变动或者结垢导致这一假设并不成立,从而造成计算蒸汽流量存在着较大的误差[3]。文献[4]改进了弗留格尔公式,但是依然受到结垢造成通流部分变化的影响,如果结垢存在,需要对误差进行修正,计算过程较为复杂。文献[5]首先利用粗糙集理论选出了影响蒸汽的特征变量,并利用最小二乘支持向量回归算法对蒸汽流量进行了预测,但是该模型较为复杂,训练时间长,不适用于在线监测。文献[6]构建了RBF (radial basis function)神经网络的蒸汽流量软测量方法,取得了较好的预测效果,但该方法存在着全局寻优能力差、训练时间长、容易过拟合等缺点。文献[2]利用混沌搜索策略鲸鱼优化算法(chaos adaptive whale optimization algorithm, CAWOA)优化了并行极限学习机(parallel extreme learning machine, PELM)模型,并构建了基于PELM的蒸汽流量预测模型,成功应用于某台600 MW机组,虽然利用混沌搜索策略摆脱了局部最优的问题,但是在预测精度上却得不到保证。
组合模型可以实现单一模型之间的优势和缺陷互补,优化模型预测效果,提升模型预测精度。文献[7]提出了一种蝙蝠算法(bat algorithm, BA)优化支持向量机(support vector machine, SVM)的短期风速组合预测方法,并通过实例仿真验证了该方法可以有效地提高预测精度,减小误差。文献[8]构建了基于自回归积分滑动平均模型(auto-regressive integrated moving-average model, ARIMA)和卡尔曼滤波(Kalman filter, KF)的船舶系统设备状态参数组合预测模型,实例分析表明组合模型较单一的自回归积分滑动平均模型在预测精度上有了较大提升。
因此,现采用组合预测的方法,把电厂的历史运行数据作为输入变量,分别输入到宽度学习系统(broad learning system, BLS)和Lasso (least absolute shrinkage and selection operator)回归模型中得出预测结果,然后通过最优加权法确定权重系数将得到的结果线性组合,得出最终的蒸汽量预测结果。拟通过组合模型,融合宽度学习系统和Lasso回归模型两个单一模型的优点,在提高模型训练速度的同时,获取精确度更高的蒸汽预测值。
1 数据预处理及特征选择
1.1 基于One-class SVM的数据预处理
在实际采集得到的工业数据当中,由于数据采集设备故障或者是人为操作失误输入,可能存在大量的缺失值以及异常值,这对模型的训练产生了极大的影响,对最终的训练结果起到了很大的干扰作用。因此,在训练模型前需要对所获得的数据进行清洗,以获取更准确的预测值。本文所获得的历史运行数据当中存在着异常值,需要将数据的异常值剔除。如图1所示,正常值和异常值主要通过数值的分布密度进行区分,当待测样本落在密度大的区间为+1 class,反之则为-1 class。图1中,+1 class为正常值,-1 class为异常值。

图1 One-class 分类问题Fig.1 One-class classification problem
对于异常值的检测,Scholkopf等[9]提出了One-class SVM (One-class support vector machines)算法。在数据维度很高或者数据分布情况不明的情况下,利用One-class SVM可以有效地检测出异常值。该方法主要是通过一个超球体对异常值进行划分,在特征空间内求取样本的球形边界,将一类问题转换为二元分类问题。把样本的特征属性向量化,通过核函数映射到高维空间中,分布密度在高维空间内进行划分,由此可以把正常值和异常值进行区分。
现有的核函数有径向基函数RBF (radial basis function)、线性核等。RBF核函数相对于其他核函数来说,具有更宽的收敛域,能够逼近任意的非线性函数,可以寻找数据间复杂的规律特性[10]。因此,采用径向基核函数RBF:

(1)
式(1)中:k(·)为径向基核函数;xi为样本的数据点;yj为核函数的中心;i为第i个数据点;j为第j个核函数的中心;δ为带宽。
(2)
式(2)中:n为样本的数量;l为异常数据到分类超平面的距离;z为分类超平面的法向量;β为松弛变量;c为平滑因子。
构造拉格朗日函数对偶求解z和l,可得到决策函数为
g(x)=sgn[zk(x)]-l
(3)
式(3)中:sgn为阶跃函数。对于任意输入的样本x,当g(x)≥0时,所输入特征向量x属于+1 class,为正常值,反之则为异常值,对于异常值直接剔除。
1.2 基于MIC的特征选择
影响蒸汽量的因素很多,这些因素可分为外部因素和内部因素,外部因素包括燃料特性、环境温度、设备结构特性等,内部因素则包括炉膛温度、炉膛压力、一二次给风量、锅炉给水水量等[11]。外部因素是固定的,可以通过不断调整内部因素来提高锅炉燃烧效率从而产生稳定的蒸汽量。
特征选择影响着模型的拟合程度和预测结果。选取的特征过多,会导致模型的学习能力过强,造成过拟合;选取的特征过少,则会导致模型的学习能力过差,造成欠拟合,预测的精度较低。因此,在训练模型前需要选取对蒸汽影响较大的特征,以获取更精准的预测值。针对影响蒸汽的各特征间的关系是非线性的,本文采用基于最大信息系数(maximal informationcoefficient, MIC)的特征选择方法对特征进行选择。
最大信息系数是由Reshef等[12]提出的,该方法是通过互信息和网格划分来开展计算,可以有效地分析变量与特征之间的关系。定义存在变量H={h1,h2,…,hλ}和K={k1,k2,…,kλ},其中λ=1,2,…,m,m为样本总数,集合D={(h1,k1),(h2,k2),…,(hλ,kλ)}为有限样本对。首先定义划分G把变量H和变量K分别划分为h段和k段,G为h×k的网格。然后在划分的每一种表格内对互信息I(H;K)进行计算,在相同的h×k内有很多种划分网格的方式,选取最大的I(H;K)作为G的互信息。由此可以得到最大互信息
Im(H;K)=max[I(D|G)]
(4)
式(4)中:D|G表示数据D使用G进行划分。在不同划分下计算得到的最大互信息值组成了特征矩阵,特征矩阵I(D)x,y可以定义为

(5)
则最大信息系数为

(6)
式(6)中:B(m)为网格划分h×k的上限值,文献[13]指出当B(m)取m0.6时得到的结果最好。给定一个样本数为M的特征集P={p1,p2,…,pM,e},其中e为类别。定义MIC(pi,pj)为特征pi和类别e间的相关性,MIC(pi,pj)的值越大说明两者的相关性就越强,该特征就越应该保留;反之则说明相关特征pi较弱,需要对其进行删除。对于任意的两个特征pi和pj的冗余性定义为MIC(pi,pj),MIC(pi,pj)越大说明两者的冗余性就越强,可替代性也就越强,需要把其中的一个特征变量进行剔除;反之,当MIC(pi,pj)=0时,说明两者互不影响,都需要保留下来[14]。
2 BLS-Lasso网络的数学模型和预测方法
2.1 宽度学习系统
Chen等[15]提出了宽度学习系统,相对于深度学习等相对复杂的模型,宽度学习系统没有层间耦合,而且不需要使用梯度下降来更新权值,训练时间远优于它们,精度更高、计算消耗的资源更少,更适用于在线监测。文献[16]提出了一种基于宽度学习系统的高效气温空间插值模型,该模型较深度学习和传统空间插值方法具有更好的预测效果和时间损耗,验证了宽度学习系统具有良好的预测性能。
宽度学习系统网络结构图如图2所示,由输入层、特征层、增强层和输出层组成。输入的数据集经过特征分析后,将所提取到的特征进行映射,形成了特征层。特征层的特征节点经过非线性变换后生成增强层,增强层包含着增强节点。特征节点和增强节点都输出到输出层。
由图2可知,BLS的输入层包括Nn组特征映射(每组包括Ng个特征节点)和Nm个增强节点,输入矩阵X是由特征选择出来的特征变量组成,第i组映射特征为

图2 BLS网络结构Fig.2 Network structure of broad learning system
Li=ω(XMhi+λhi),i=1,2,…,n
(7)
式(7)中:ω为映射函数;Mhi为权重矩阵;λhi为偏置项。第j个增强节点Zj是由前n个特征映射组合而成,Zj可表示为
Zj=μ(LMfj+λfj),j=1,2,…,m
(8)
式(8)中:L=[L1,L2,…,LNn];μ为映射函数;Mfj为权重矩阵;λfj为偏置项。将增强节点记作矩阵Z=[Z1,Z2,…,ZNn],最终的BLS模型可表示为
Y=[L1,L2,…,LNn|Z1,Z2,…,ZNn]W
=[L,Z]W
(9)
式(9)中:Y为模型的输出,也就是蒸汽量的预测结果;W为各节点与输出层之间的权重。把特征节点和增强节点所对应的矩阵记作Q=[L,Z]。
在模型训练的过程中,权重矩阵Mhi和Mfj、偏置项λhi和λfj均不发生改变,故只需求解输出权重W。因此,宽度学习系统的求解过程等价于求解线性系统Y=QW的最小二乘解,即

(10)
式(10)中:Q+为矩阵Q的Moore-Penrose广义逆矩阵,也称为伪逆矩阵。由此可见,宽度学习系统的训练无需进行梯度下降,训练耗时短、不易于陷入局部最优[17]。
2.2 Lasso回归模型
Lasso回归模型[18]不仅包含了岭回归的稳定性,最终的训练结果还体现了子集选择的可解释性。Lasso回归模型的核心思想是通过缩小变量集来达到压缩估计,在训练过程中,构造惩罚函数来压缩输入参数的系数,并将某些系数置零,使得整个子集缩小,从而简化该模型摆脱过度拟合,该方法应用在数据预测、数据挖掘领域取得不错的效果。
在一般的多元线性回归模型中,各个数据的观测值一般认为是彼此独立的,模型中存在着大量的变量,变量越多模型就越复杂,训练时就越容易陷入过度拟合。为了排除量纲的干扰,针对模型中存在的m组自变量Xi=(xi1,xi2,…,xim)和因变量Yi,Lasso回归模型对所有自变量做了标准化变换,在误差平方和最小的基础上在目标函数后面加了1范数约束,其表达式可以表示为

(11)
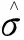
2.3 基于最优加权组合法的组合预测模型
采用最优加权组合的方法[20],把宽度学习系统和Lasso回归模型组合蒸汽量预测模型。该方法在分别采用BLS模型和Lasso回归模型得到各自蒸汽量预测的结果后,确定权重系数将两者进行线性组合,得到最终的预测结果。
首先求取偏差矩阵A,即

(12)
式(12)中:M为样本总数;a1t和a2t分别为BLS模型和Lasso回归模型在t时刻蒸汽量的预测值和真实值的误差。
然后通过拉格朗日乘子法可以求出最优权重,其表达式可以表示为
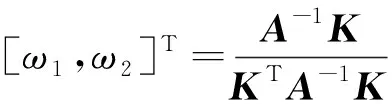
(13)
式(13)中:ω1和ω2分别是BLS模型和Lasso回归模型的权重系数,它们之和为1;K=[1,1]T。
由此可以得到最终的蒸汽量预测模型
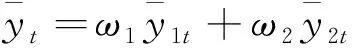
(14)
2.4 组合模型预测流程
组合模型的预测流程图如图3所示,包括以下步骤。

图3 组合模型预测流程图Fig.3 Flow chart of combined model prediction
(1)划分样本数据。把样本数据划分为训练集和测试集,训练集用于训练模型获取参数,测试集用于实际的蒸汽量预测实验。
(2)数据预处理。划分训练集、测试集后,利用One-class SVM算法对样本数据进行异常值检测,对于异常数据直接剔除。
(3)特征选择。采用最大信息系数对样本数据进行特征选择,删除冗余特征变量,形成输入矩阵。
(4)设置超参数。采用网格搜索法获取BLS模型和Lasso回归模型的最优超参数,并用训练集分别对两种模型进行5折交叉验证评估。
(5)模型独立预测。在经过模型训练和参数调优后,把测试集分别输入Lasso回归模型和BLS模型进行独立预测。
(6)组合模型预测。利用最优加权组合法确定权重系数,将Lasso回归模型和BLS模型的预测结果进行线性组合,得到最终的预测结果,并对所得结果进行分析评价。
3 算例分析
3.1 实验数据和平台
本实例引自文献[11],以某火电厂历史运行数据作为实验数据集,该数据集的采样频率为分钟级别。数据集包含2 888个样本数据,训练前按8∶2的比例划分为训练集和测试集。
本文中采用的硬件平台为Intel Core i7-8700 CPU和NVDIA GRID V100D-32Q GPU。软件代码采用Python语言实现,Lasso回归模型调用sklearn库,BLS模型则调用宽度学习包。
3.2 实验评价指标
采用均方误差EMSE和平均绝对误差EMAE作为实验的评价指标,表达式为

(15)
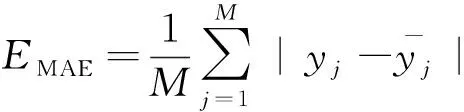
(16)

3.3 超参数设置
超参数的设置影响着BLS模型和Lasso回归模型的训练速度和预测精度,预测前通过设置超参数使模型获取更好的性能。本文采用网格搜索法寻取两种模型的最优超参数,并用5折交叉验证对模型的性能进行评估[21],训练过程中不断优化参数,从而提高模型的泛化能力。
其中,BLS模型的最优超参数为:特征映射Nn为40组,特征节点Ng为10个,增强节点Nm为41个。Lasso回归模型的调参系数h取0.001 5。
3.4 预测结果分析
根据图3预测流程,首先利用One-class SVM算法分别对训练集和测试集进行了异常值的检测,剔除了异常值后,训练集和测试集分别包含2 160、540个正常数据。以特征锅炉压力为例,其异常值检测结果如图4所示,对于偏离密集点的数值直接剔除。

图4 特征锅炉压力异常值处理Fig.4 Treatment of abnormal value of characteristic boiler pressure
剔除异常值后,采用最大信息系数进行特征选择,选取了9个相关性最大的特征,如图5所示,颜色越接近深紫色表示该特征的相关性越高。由图5可以看出,锅炉压力、锅炉温度和燃料给量的相关性最大,相关系数都超过了0.5,其他相关性较大的特征依次是二次风给量、给水水量、一次风给量、过热器温度、炉膛压力、炉膛温度,把这9个特征作为网络模型的输入变量。

图5 相关系数热力图Fig.5 Correlation coefficient thermodynamic diagram
经过数据预处理后,利用BLS模型和Lasso回归模型的组合模型进行蒸汽量预测,并把组合模型的预测结果同真实值、单一模型的预测结果进行了比较,结果如图6所示。由图6可以看出,单一模型的误差较大,LightGBM网络和XGBoost网络在谷值时偏离真实值比较大,BLS模型和Lasso回归模型的变化趋势则滞后于真实值。本文的组合模型更契合蒸汽量的变化趋势,更为接近真实值,预测精度也更高,有效地缓解了单一模型在变化剧烈的峰值和谷值预测偏差较大的问题。
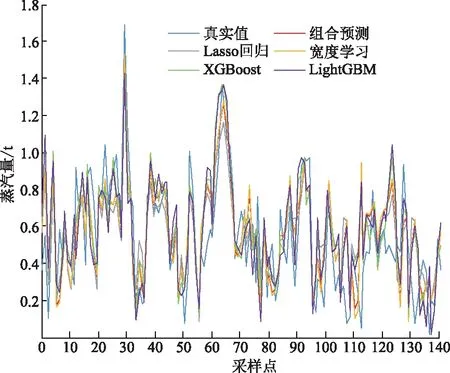
图6 组合模型与单一模型的预测对比Fig.6 Prediction comparison between the first mock exam and the combined model
表1为不同网络模型蒸汽量预测结果的误差对比。可以看出,本文中所提出的BLS-Lasso组合模型相对于单一模型,具有更低的EMSE和EMAE,说明预测结果更接近真实值。

表1 不同预测模型的误差对比Table 1 Error comparison of different prediction models
4 结论
针对传统蒸汽量测量方法精度不高的问题,提出了一种宽度学习系统和Lasso回归模型组合模型的预测方法,与传统方法相比有着以下优势。
(1)利用One-class SVM算法检测样本数据的异常值,一定程度避免了因异常值对预测结果的影响。
(2)采用最大信息系数算法进行特征选择,通过特征选择为模型训练增加了先验知识,避免了模型训练时因特征过多陷入过拟合或者特征过少发生欠拟合,导致预测精度下降。
(3)使用基于BLS-Lasso的组合模型进行预测,不仅提高了模型的训练时间,也保证了预测的精度,适用于在线监测。
(4)该方法泛化能力好,在任意场景都可以使用,有一定的推广价值。
通过建立蒸汽量预测模型,替代了直接测量的方法,减少了直接测量装置所造成的节流损失,提高了机组的出力。与此同时,运用该预测模型实现锅炉运行过程的模拟和验证,实现能耗的评估,优化运行参数,提高汽轮机机组的经济稳定运行,为电厂的操作运行提供可行性建议。本文对蒸汽量只进行了点预测,未来可以把该方法应用到分布预测或者区间预测。此外在特征选择的时候只考虑了蒸汽量与特征的相关性,后续应该增加特征与特征之间的相关性分析。
