阶层符码差异、学业成绩与教育再生产
2022-10-28吴永源
吴永源 ,沈 红
(1.华中科技大学教育科学研究院,湖北武汉430074;2.南方科技大学高等教育研究中心,广东深圳518000)
一、问题的提出
教育公平是社会公平的关键调节器,也是实现其他社会公平的重要渠道。《中国教育现代化2035》提出要提升义务教育均等化水平,推进城乡义务教育均衡发展[1],以求从教育机会和办学条件上促进教育公平。但在教育过程和结果方面则主要集中于对学生学业成绩的关注[2]。学业成绩作为现有教育体系内实现向上流动的“通行证”,具有溢出“分数”层面的更多意涵,即人们更关注的是其对社会结构位置的决定作用,这也使得学业成绩成为观察教育再生产问题的重要窗口。因此,不同阶层群体不可避免地会以极大的热情投入到教育的竞技之中。国内外已有研究针对不同阶层学生的学业成绩差异进行了丰富的讨论,田丰[3]、马洪杰[4]、赵宁宁[5]、孙志军[6]、赵必华[7]、沃曼(Wößmann)[8]等诸多学者基于不同数据库的实证研究均发现优势阶层学生的学业成绩表现高于弱势阶层学生,且语言类学科的差距更大[9]。可以说已有研究总体上形成“优势阶层学生的学业成绩更好”的共识。而在解释为何不同阶层学生存在学业成绩差异时,学者们提出了不同的观点。多数学者认为优势阶层学生的成绩领先主要得利于更高的家庭收入带来的教育投入[5],父母更高的受教育水平带来的文化浸染[6],更多的时间投入[10],更频繁的家校互动[3],以及所在学校拥有更优质的师资队伍[11]等,有学者通过进一步的比较研究发现家庭文化资本与教师质量发挥着更为关键的作用[9]。这些研究大部分可以归纳到布迪厄“带有学业成分的再生产”的理论范畴内,即社会结构与心理结构相联结的过程[12]1。但这不免给人一种资源占有与学业成绩之间直接且粗暴挂钩的印象,导致相关研究容易陷入了绝对的“结构决定论”的魔咒之中,而实际上从资源占有到学业成绩的获得之间充满着复杂性和不确定性。学者们正在努力揭开这一“黑箱”,如对于以家庭投入型和学校投入型为主的教育生产函数类型进行不断发展和细化[13]。西方民族志关于教育不平等的研究不断呼吁把学校教育过程带回来,并逐渐发展出四种不同路径:学校分类的社会建构、课程知识的社会组织、学校教育的适应以及学生文化的意义建构[14]。其中,伯恩斯坦(Bernstein)提出的“符码理论”(Code Theory)及其后续将“符码理论”延伸到学校课程上,逐渐发展出解释学校教育及知识形式(form of knowledge)与社会再生产深层关系的“课程符码”(curriculum code)理论,连接了“家庭背景-学校教育-课程知识”的整个过程。他将语言符码、课程符码与阶级结构和社会控制机制相互联结的努力,有效拓展了阶层、学业成绩与教育再生产的研究视域。伯恩斯坦的研究提供了一个全新的观察视角,他认为不同阶层在社会化的过程中对语言符码类型的掌握是有差异的,优势阶层倾向于掌握“精致型符码”(elaborated code),而弱势阶层接触更多的是“限制型符码”(restricted code)[15]。此外,他还通过“分类”(classification)和“架构”(framing)两个概念将理论触角延伸到学校教育过程中的课程知识上,为进一步关注学业成绩内部的学科异质性以及不同学科之间在知识结构特征、语言表达方式等上的差异[16]提供了理论基础。总的来说,已有研究对符码理论的实证应用很少,更多是对理论观点的介绍[17],即使稍有涉及也很少做深入的分析[5]。因此,与已有研究不同的是,本文不仅关注不同阶层之间存在的语言符码差异对学业成绩的影响,还将进一步利用混合研究方法探讨阶层之间的语言符码和学科之间的课程符码的匹配情况对学业成绩的影响。
二、理论基础与研究假设
围绕着教育再生产问题的学术争论产生了丰富的理论观点。总的来看,教育再生产的理论体系经历了从“强再生产”向“弱再生产”发展的过程。强再生产理论认为“教育系统在某种程度上通过其自身内部的社会关系与劳动场所的社会关系之间的对应,再生资本主义劳动的社会分工”[18]。但其对教育系统与社会系统的关系过于简单的理解也是其被人诟病之处,这不可避免地影响了其解释力度。而弱再生产理论起始于强再生理论的终结之处,试图发展出一种把文化、阶层与学校教育的逻辑联结起来的解释体系[19]。其代表人物之一——伯恩斯坦从社会语言学出发探讨学校的文化传承,并发展出解释学校教育与社会再生产深层关系的“符码理论”。
(一)语言符码与学业成绩
伯恩斯坦所提出的“符码理论”关注的是不同文化背景的阶层语言构成习惯和使用规则,包括了社会因素对语言构建的影响,以及语言在社会构建方面所展示的功能,即社会因素影响个体语言特征形成的同时,语言特征也会影响社会资源的分布。他认为语言能够高效地进行阶级区分[20],这里的“语言”内涵明显溢出了索绪尔(Sausure)基于社会心理学的语言符号学的关注范畴,更像是一种习惯、一种规则,甚至是一种权力[21]。伯恩斯坦重点关注不同阶层所使用的语言的语法元素,并将语言形式凝练为语言符码,即“精致型符码”(elaborated code)和“限制型符码”(restricted code)[22]。前者指个体的句式及词汇都有较多变化,并且个体更能够抽离所谈论的事情和交代前因后果,而后者则缺乏变化,带有更多的命令式和情绪性词句,语言表达相对墨守成规[23]。伯恩斯坦认为不同阶层在掌握的符码上是有差异的,中产阶级身处具有流动性及成员异质性的社会环境,语言表达的意义更具有普遍性,更容易掌握的是“精致型符码”。而工人阶级身处缺乏流动性、成员同质性高的社会环境,语言表达的意义更具有特殊性,更多接触的是“限制型符码”。
语言符码上的差异导致工人阶级子女在取得教育成就时可能面临更多的困难。已有研究发现儿童在早期生活中形成的不同符码是影响他们后期学习成就的重要因素[24]。这可能是因为学校本身就是符码和意识形态的重要生产场[25],在学校场域中“任何教学行为客观上都是一种符号暴力”,即优势阶层通过对于学校知识传授的有效控制实现宰制关系的合法化,并赋予自身符号力量(symbolic force)[26]49。而教师作为“半支配阶层和半知识分子”是主流文化的合法代理人[27],其所使用的课堂教学语言也具有进行知识控制、分配的潜在功能[28]。教师对学生的期待会影响到师生互动中的言行特征,例如在与中上阶层家庭的学生互动时,教师所使用的合法性语言①明显高于来自劳工阶层家庭的学生[29-30],这使得弱势阶层的学生在受教育过程中在“语言”上被区别对待。而学校教育正是通过用“标准的”“合法化的”语言讲授知识,并通过考试结果来强化标准化语言和思维的意义[21],这可能使得教学过程从知识的获取转变成为符号的获取。最终,两种语言形式衍生的感知取向(perceptual orderings)导致阶层教育成就的差异[16],也即不同阶层之间的符码差异间接地转换成学业成绩的差异。
由此提出假设一:
优势阶层子女更容易适应学校教育中的语言符码,使得优势阶层的学业总成绩显著高于弱势阶层。
(二)课程符码与学业成绩
伯恩斯坦对“符码理论”的研究并未停下脚步。20世纪60年代中后期,他开始将“符码”概念从日常语言领域延伸到学校知识范畴,逐渐形成“课程符码理论”,旨在探讨学校知识传授的深层原则,以求更具体地反映学校内部教学活动与社会权力及秩序的关系[16]。只有深入到学校具体课程内部的知识构成,才能够探究社会权力与控制原则的传导过程。因为学校知识并非中立的价值无涉,往往隐含着对“谁的知识最有价值”的价值判断。亦如阿普尔(Apple)所言,要了解学校教育与社会权力的关系,就必须深入研究学校传授的知识以探讨打造学校知识的文化分配与吸收过程[31]。伯恩斯坦的这一转变将“符码”概念的讨论范围扩展到不同学科和课程层面上,使该理论更加深入学校教育过程,也将我们对语言符码与学业成绩关系的关注进一步细化到语言符码与课程符码的匹配情况对学生学业成绩的影响层面上。
具体来说,“课程符码理论”把学校教育知识的组织原则分为“分类”和“架构”两个面向(见表1)。“分类”是指课程中不同知识领域及学科之间界线的开放程度。其中,“强分类”主要指课程科目之间的界线明确牢固、关系壁垒分明;反之便是“弱分类”。而“架构”界定教学传授活动的权力关系,调控施教者与受教者对教授内容、进度、先后顺序及评核标准的控制权。其中,“强架构”主要指对教学内容、顺序和考核标准的既定限制较多,且和生活世界联系较弱;反之便是“弱架构”。伯恩斯坦从这两个概念出发,将学校的学科课程分为“集合型课程”(collection type course)和“整合型课程”(integrated type course)。

表1 分类、架构与课程属性
“集合型课程”的知识从表层结构出发逐渐向深层结构转变,知识的不确定处——“秩序”与“无序”及“知”与“不知”的交汇处——一直要到教育系统的后期(例如研究生阶段)才出现。在这之前,学校传授的知识都被认定是明确绝对的,而数学②的课程结构则明显属于“强分类、强架构”的“集合型课程”。其知识之间的关系是线性的和客观的,如勾股定理中公式的可推导性和确定性。知识的发展与生活世界的联系也相对独立,更多的是一种确定的、有序的知识。而对于无序的、未知的知识探索则通常需要到很高的教育阶段,例如对于各种根据不完全资讯下的“数学猜想”的探索。“整合型课程”的知识则突破了学科之间的鸿沟,知识的不确定性从一开始便出现。在教学内容、教学法、评估标准等方面都相对宽松,更加鼓励学生的批判性思考[26]83。而语文的课程结构则更类似于“弱分类、弱架构”的“整合型课程”,语文与生活世界的联系更加频繁和紧密,知识之间的关系是发散的和主观的。例如语文写作更强调的是主观的意义建构[32],这种意义的建构和知识的不确定性在教育阶段的早期便开始出现,也更鼓励学生的发散思维和创造性。
由此可见,两种不同的课程具有特色鲜明的课程符码,这也说明了深入分析学生不同学科学业成绩的重要性。此外,不同阶层群体间的语言符码差异与其生活环境和行为有着紧密的联系。具体来看,中产阶级从事符号生产(symbolic production),其工作和生活的时空区隔和安排较开放且有弹性,处理的人事较复杂且具有较高的含糊性。因此,他们更倾向于使用“弱分类、弱架构”的方式教育子女。而工人阶级则彻底地参与到产品的生产流程中,生产活动中每一个环节之间环环相扣,生产的地点、时间、速度和工序等受到整体流程的制约,因此工人阶级更倾向于使用“强分类、强架构”的方式教育孩子。拉鲁(Lareau)等人的研究佐证了这一观点,优势阶层的工作强调理性思维和自主管理,因而注重培养子女在复杂的社会中理性思考和独立自主的能力,强调沟通的双向互动,是一种“协作培养”的方式。而工人阶级家长在工作过程中意识到顺从和规矩的重要性,而教养子女重视对权威的服从,多采用指令为主的单向互动[33]。
不同的培养方式塑造了不同的语言符码,并在不同学科上产生影响(见图1)。相较于语言缺乏变化且表达较为墨守成规的“限制型符码”而言,“精致型符码”强调的是语言表达的逻辑性和自主性,语言的句式和词汇都有较多的变化,这种语言特征可能在强调知识的不确定性、主观性、创造性的“整合型课程”中更有发挥的空间。正如有学者认为,“弱分类、弱架构”的高考符码与优势阶层掌握“弱分类、弱架构”教育所需的资源之间存在紧密的切合性[34]。这可能使其子女在“整合型课程”中更容易占据优势。但诸如数学的“集合型课程”更强调的是知识之间关系的确定性和客观性,本身并不要求语言表达的多元化,这与优势阶层的“精致型符码”的吻合度并不高,反而可能与“限制型符码”吻合度更高。但需要注意的是,这并不意味着优势阶层在“集合型课程”中就会处于劣势,因为为避免子女们在公开的竞争性升学中处于不利地位,优势阶层最终还是会利用其资源优势加强“集合型课程”的训练[26]84-85。

图1 阶层、符码与课程的关系传递示意图
由此提出假设二:
相对于弱势阶层,优势阶层学生在语文成绩上优势明显,但在数学成绩上两者则差异不大。
三、研究设计
(一)样本选择
本文所使用的数据为中国人民大学数据与调查中心的中国教育追踪调查(China Education Panel Survey,CEPS)的基线调查数据。该调查利用多阶段概率与规模成比例(PPS)抽样方法,从全国随机抽取28 个县级单位、112 所学校、438 个班级的 19487 名学生。此外还提供了包括学生、教师、家长和学校的配套数据,数据质量较高且在国内得到了广泛的使用。本文选择七年级学生作为分析对象,在数据处理过程中删除存在缺失值的样本③,最终进入本文分析的样本为来自213 个班级④的5421 位学生。此外,为进一步探讨阶层的语言符码与不同学科的课程符码的对应过程,本文还对6名初中语、数、英教师进行访谈,以收集质性资料。我国基础教育内容的同质性相对较强,这为访谈对象的选择提供了便利,对6位教师各自进行了40—60 分钟的访谈,基本上便达到了内容饱和。量化研究主要回答由理论推演而来的研究假设,即掌握不同符码类型的学生是否在学业成绩及各科成绩上有显著差异;质性研究主要回答阶层的语言符码和不同学科的课程符码对应过程。
(二)变量说明
本文选择七年级学生2013—2014 年期中考试的语、数、英三科成绩和学业总成绩⑤作为因变量,由于不同地区、学校的试卷总分和难度有所不同,对学业成绩按学校分别进行标准化处理。此外,已有研究发现性别、民族、独生、流动、留守、住校、班级排名、班级规模、班级学生农业户口比例、班级学生住校比例、班主任年龄等变量会影响学生学业成绩,因此这些均加入控制变量。不同阶层的划分是一个有争议的难题,参考已有研究[35-37],本文操作化地将农业户口群体定义为弱势阶层,非农业户口群体定义为优势阶层,同时还通过家庭社会经济地位对估计结果加以稳健性检验。相关统计信息如表2所示。

表2 相关变量基本情况
(三)模型设定
在研究中通常需要通过控制诸多其他变量以进一步理清阶层差异对学生发展的影响。但由于中国教育追踪调查(CEPS)在班级、学生层面上存在明显的嵌套情况,这种嵌套情况的存在使得传统线性回归模型中的个体间相互独立的假设很难满足,从而导致在估计阶层差异对学生发展的影响时出现偏误[38]。而多层线性模型(Hierarchical Linear Model,HLM)在处理嵌套数据时能够将多层结构数据的总变异分为组内和组间两个不同层次,并在不同层次上引入相应的自变量以解释组内变异和组间变异。因此多层线性模型能够有效区分层次变量与扰动项的相关信息,以提高个体估计效应的准确性。考虑到CEPS 在每个学校中只抽取2 个班级,这并不符合HLM 对于样本容量的最低要求,因此本文不考虑构建学校、班级和学生的三层线性模型。借鉴已有研究[39],本文建立班级和学生的两层线性模型,分析不同阶层学生的语言符码与课程符码的匹配情况对学生学业成绩的影响。
1.零模型
零模型不含任何解释变量,公式如下:

其中因变量Yij表示j 班学生i 的学业成绩,β0j是截距,表示j班学生的平均学业成绩水平,rij表示j班级i同学与班级平均学业成绩的差距,方差为σ2;γ00是全样本学校的平均学业成绩,μoj表示各班级平均成绩与全体样本平均成绩的差距,方差为τ00。零模型的目的在于计算跨级相关系数ICC(Inter-class correlation),ICC=τ00/(σ2+τ00),即考察模型总变异中有多大程度上是由班级层面的差异造成的,是判断是否使用HLM 的关键系数。
2.随机效应模型
在零模型的基础上,引入学生层面的相关预测变量Zij,建立随机效应协方差模型,班级层面不引入任何预测变量,允许第一层截距和斜率在组间随机变异,公式表示如下:

3.非随机变动斜率模型
在第一层和第二层引入学生层面和班级层面的预测变量,考察在控制了学生和班级层面的变量后,不同阶层学生的学业成绩差异。公式表示如下:
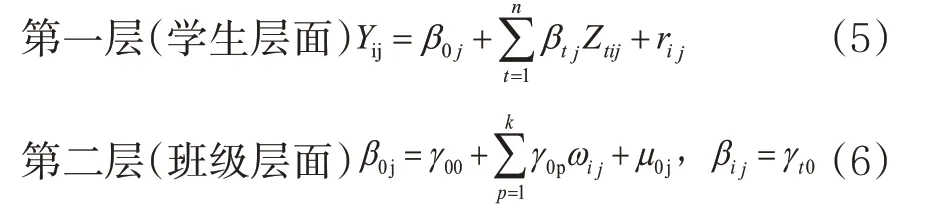
四、实证结果
(一)学业总成绩的阶层差异
如表3所示,在传统OLS回归模型(3)中分别控制学生层面和班级层面变量后,发现优势阶层的学生学业总成绩明显高于弱势阶层2.07 个标准分(p〈0.01)。但由于CEPS 的数据是学生与班级相互嵌套的数据结构,在模型(3)中将班级层面的变量直接分解到学生层面的回归模型中将会影响估计结果⑥。因此需要使用多层线性模型进行分析以校正违背独立性前提假设的错误。检验发现,σ2=538.41,τ00=37.40,计算可得学业总成绩在班级间的跨级相关系数ICC=0.065〉0.059,说明学生的成绩差异有6.5%是来自班级间的差异,这可能是由不同班级之间在资源分配、学习氛围等上的差异所致。在随机效应模型(1)中只纳入学生层面变量,发现优势阶层学生的学业总成绩有2.32个标准分的领先(p〈0.01)。此后,在非随机变动斜率模型(2)中纳入学生和班级变量后,学业总成绩的优势上升到2.42 个标准分(p〈0.01),说明在考虑了班级层面的影响因素后,优势阶层子女的学业优势更明显。从回归结果来看,传统OLS 回归低估了优势阶层在学业总成绩上的领先优势(2.07〈2.32〈2.42),三个不同模型结果均显示优势阶层子女在学业总成绩上明显高于弱势阶层子女。由此,假设一得到了验证。
(二)语文、数学成绩的阶层差异
优势阶层在学业场域中具有优势地位几乎成为一种共识。但知识社会学对于知识结构与社会结构相互连接的关注拓宽了人们对于学业成绩与阶层的理解。扬(Young)[40]强调了控制与知识的内在联系,伯恩斯坦则更加具体地论述了知识的分类与架构。这为我们了解不同类型知识在不同阶层上的分布差异打开了一扇新的窗户。那么,优势阶层在知识分类与架构不同的学科上依旧有显著的优势吗?如表3所示,模型(4)控制了学生层面变量,发现优势阶层的语文成绩显著高出弱势阶层0.84 个标准分(p〈0.01);而完全模型(5)中同时纳入学生层面和班级层面变量后,其语文成绩的优势扩大了,显著高于弱势阶层0.91个标准分(p〈0.01),传统OLS回归则低估了这一影响,只有0.61 个标准分(p〈0.01)。但有趣的是,优势阶层在语文学科上的领先地位并没有延续到数学学科上。在模型(7)—(9)中,多层线性模型和传统OLS 回归的结果显示,优势阶层的数学成绩分别高出弱势阶层0.43(p〉0.05)、0.32(p〉0.05)、0.46(p〉0.05)个标准分,均未通过显著性水平检验。以上结果说明,优势阶层在语文学科的学习和应用上处于领先地位,但在数学学科上没有优势。由此,假设二得到了验证。
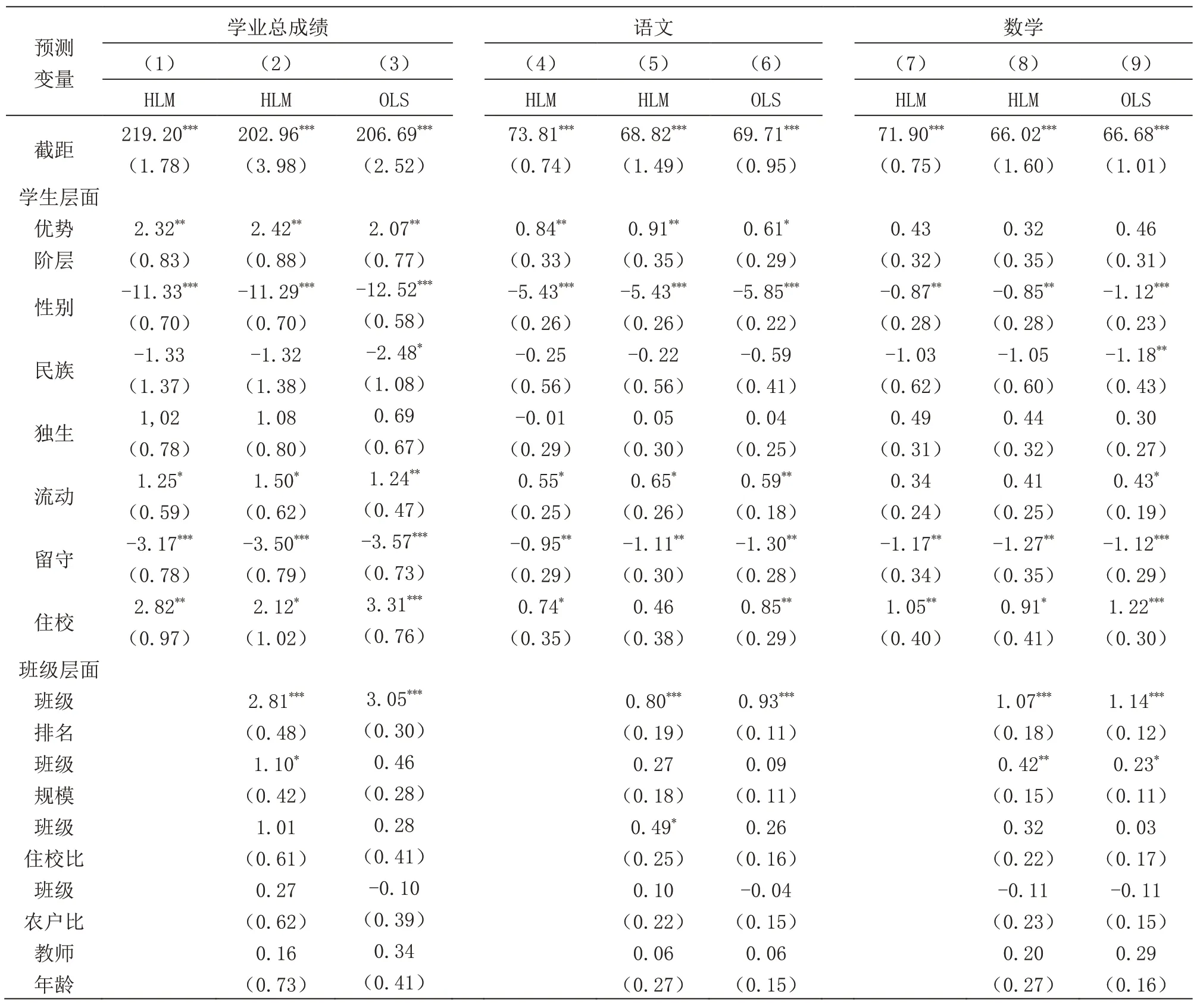
表3 阶层与学业成绩的HLM和OLS估计结果
(三)稳健性检验
为检验研究结论的稳健性,本文将分别从阶层定义和学业成绩两个角度重新寻找替代变量。在阶层定义上,虽然我国户籍制度在生活、教育等方面导致的城乡二元分割,使得以户籍差异为操作化手段分析不同阶层在学业成绩上的差异表现具有一定的合理性,但将社会群体简单地一分为二也不可避免会造成理解的偏差。学者们同样批评了伯恩斯坦在“阶层”概念上仅使用“工人阶级”和“中产阶级”的处理过于简单和模糊[20]。因此本文将以由家庭收入、父母受教育程度和父母职业通过主成分分析合成的家庭社会经济地位进行稳健性检验。在学业成绩上,英语作为基础教育阶段三大主要科目之一具有举足轻重的地位,且语文和英语同属于语言类的学科,都依赖于环境的长期影响和积累,在课程属性上都更倾向于“整合型课程”,两者具有明显的共性,但作为第二语言的英语,学生学习和使用程度都属于初期阶段,在语言逻辑的理解、知识迁移的应用等方面又弱于语文学科。因此以英语代替语文检验假设二,既可行,也必要。
1.家庭社会经济地位与成绩差异
如表4所示,无论是多层线性模型还是传统OLS都显示:学生家庭经济地位越高,其学业总成绩越高。具体来看,多层线性模型(1)(2)中,在控制了学生层面变量后,学生的家庭社会经济得分每提高1个单位,学生的学业总成绩显著提高1.12个标准分(p〈0.01),而当加入班级层面变量后,这种效应下降到了1.00 个标准分(p〈0.05),传统OLS 回归也低估其影响效应,仅为0.82个标准分(p〈0.01)。从学科差异来看,以多层线性模型的完全模型(5)(8)为例,家庭社会经济地位得分每提高1个单位,学生的语文成绩显著提高0.37个标准分(p〈0.05),而数学成绩只能提高0.23个标准分(p〉0.05)且不显著。以上结果说明家庭社会经济地位对学生学业总成绩具有显著的预测作用,同时这种预测作用存在学科差异,更适用于语文学科,而不适用于数学学科。
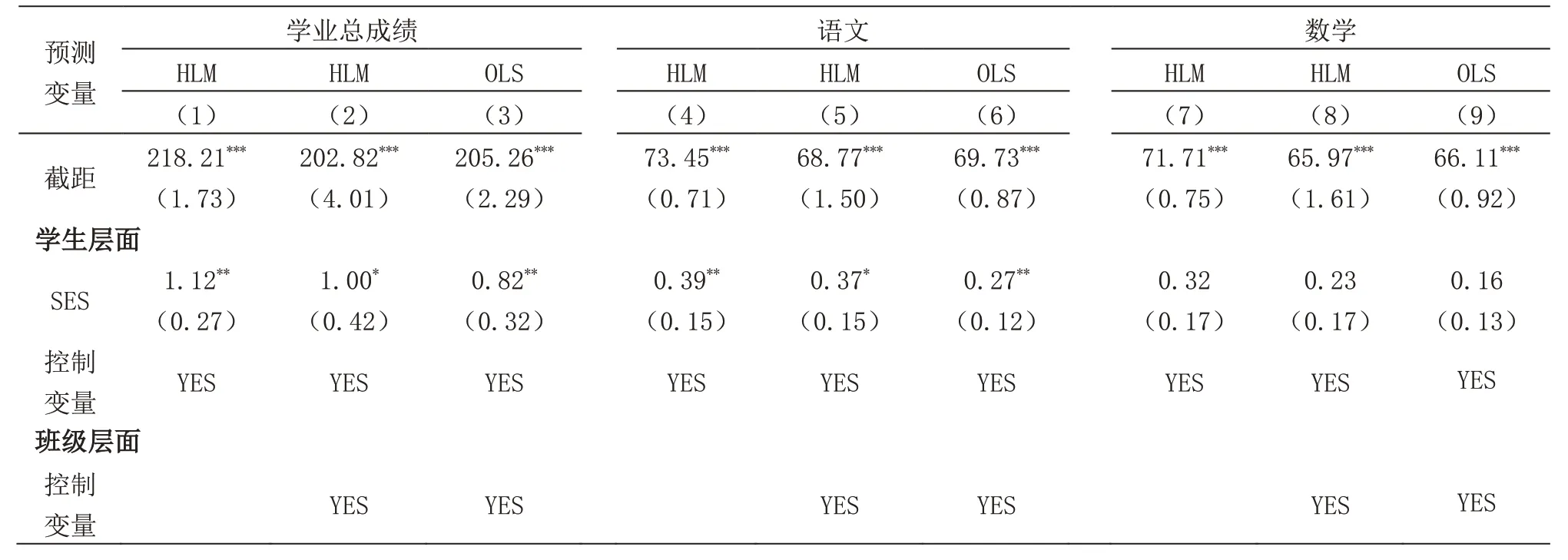
表4 阶层与学业成绩的HLM和OLS估计结果
2.英语成绩的阶层差异
不同阶层在“集合型课程”和“整合型课程”上的差异是否稳健?以英语学科代替语文学科进行检验发现,优势阶层不仅在语文学科上有显著的优势,并且其英语成绩在三个分析模型中分别高出弱势阶层1.03 个标准分(p〈0.01)、1.14 个标准分(p〈0.01)和0.94个标准分(p〈0.01)(见表5)。以上结果说明优势阶层在“整合型课程”上的优势是显著且稳定的,但在“集合型课程”上没有显著的优势。

表5 阶层与英语、数学成绩的HLM和OLS估计结果
五、结论与讨论
本文基于中国教育追踪调查(CEPS)基线数据和质性访谈资料,从阶层之间的语言符码差异以及语言符码和课程符码的关系角度出发,分析了不同阶层学生学业总成绩及不同学科成绩上的差异及成因。
(一)优势阶层的学业总成绩显著高于弱势群体
在我国这种“竞争式流动”的教育体制内,学生在正式进入社会之前长时间处于单一的教育竞争序列之中,这充分凸显了学业成绩在教育场域中的“硬通货”地位,进而加剧了优势阶层对决定社会空间结构再生产的教学机构的竞争。正如布迪厄所言,“随着企业的延续(通常从第二代起)和规模的扩大,求助于学业上某种形式的神化,哪怕是最基本的神化,倾向于成为越来越广泛,越来越迫切的需要”[12]526。在这种需求的推动下,优势阶层竭尽所能地参与到子代的学业之中。李斯莉(Todd Risley)和哈特(Betty Hart)[41]的研究表明,在“专业人士”家庭中,其父母平均每小时使用2153 个单词;在“工薪阶层”中,其父母平均每小时用1251 个单词;而在“福利救助”家庭中,其父母平均每小时仅使用616 个。不仅如此,这种参与更隐蔽地体现在优势阶层儿童在日常生活中潜移默化地实现对主流文化与语言符码的掌握和运用上。正如伯恩斯坦所认为的,在语言的构成和使用方式中潜藏着关乎身份的内在区别,其映射的是主体本身所处的某一阶层的思维习惯,而这种习惯是在早期学习过程中就形成的,在与环境的交汇中不断地普及和强化成一种特殊的类型,从而创造个性化的特殊意义形式[42]。紧接着这种带有文化意义的符码通过教育手段参与了社会阶级的构建过程。例如在“食物分类”的试验中,中产阶级儿童对于“猪肉”的分类,首先想到的是“这是动物类”,而多数劳动阶级儿童则首先回应“这是爸爸爱吃的”。显然前者的思维方式更接近老师的标准答案[21],而这些因素使得优势阶层子女更容易获得学业成功。除此之外,在正式教育中也体现在对优质教育资源的排他性争夺[43],例如通过购买学区房获得重点学校入学机会[44-45]。在非正式教育中则体现在影子教育上,城市家庭每年平均在子女教育上的支出占家庭子女支出的76.1%,占家庭总支出的35.1%,占家庭总收入的30.1%,比例远高于农村家庭[46]。影子教育资源的占有差异进而导致“夏季失落”(Summer Loss)现象,即优势阶层和弱势阶层学生在暑假期间的学业表现差距会拉大,开学之后才有所缓解。
(二)优势阶层在语文、英语成绩上优势明显,但在数学成绩上没有显著优势
优势阶层“带有学业成分的再生产”也并非一种“赢者通杀”的结局,学科知识在传播、表达上的特色与阶层的教养方式、语言符码等的不同使得学业成绩的阶层差异有了更大的理解空间。对于诸如语文和英语的“整合型课程”来说,其知识的不确定性更强,导致在教学内容、教学方法和评估标准上都更加的主观和灵活。正如一位老师所言,“语文就是一种人生经历和感悟,我们说一种叫作一朝顿悟,就是说积累到一定量的时候,你看得懂。语文本身就是人的经历,都是一个人的思想和人生经历的精华所在。而相对其他科目来说,是一种语言学,积累性会更强,基础性会更强。”(C-1)另一位老师还提到,“语文的很多学科实践不像理科一样有个绝对的评判标准和是非曲直,所以开放性程度还是比较高的。比如关于阅读材料的理解、关于口语交际、写作的构思等等,这些没有必要也不可能去预设具体内容和评判标准。所以就是在大的课程标准下进行最大程度的开放。”(C-2)以高考作文为例,近年来的高考作文均非常强调书面语言的交际语境,无论是发言稿的撰写还是漫画材料的理解等都是在为学生搭建与特定接受群体展开思想碰撞、信息互动的交流平台。但由于语言文字运用与学生的思维、审美、文化等方面有着紧密的关系,使得高考作文提供的“交流平台”难免与弱势群体文化背景产生隔阂,特别是“当这种语言背景具有许多脱离学生文化经验的意义时,问题就更加复杂了”[47]。例如2016 年全国II 卷的作文“从课堂有效教学、课外大量阅读、社会生活实践谈谈如何提升语文素养”,构建了对语文素养提升的“课内教学-课外阅读”和“学习-实践”的话语语境。“语文学科是个体日常实践的工具,日常实践常是语文存在的场域,情感的表现、语用的适切等都需要在实践中慢慢培养起来。”(C-2)但现实生活中,弱势群体在课外阅读与社会实践上往往本身就处于相对边缘的地位,使得这种“慢慢培养”更是困难重重。例如,“电子阅读与纸质阅读哪个更好这个问题,对于农村学生来说,能接触到的知识面就那么一点点,所以他能提取的观点不多;而对于城市的人来说,本身这两个观点的争论就非常多,接触得比较多,能够提取的观点自然而然就比较准确,也会比较多。”(C-1)
此外正如拉鲁所发现的,在教养方式上优势阶层家庭更多采用“协作式”的双向互动,注重子女的语言表达与独立思考,而工人阶级更多采用“命令式”的单向互动,强调的是规矩和顺从。这更体现在日常交流的内容之中。“在平时交流说话和讨论的内容上,对于农村的家庭来说,他(们)讨论的一般是一日三餐或者生活状况,比如说今天赚了多少钱,更多停留在生活的层面;而城市等比较好的地方,还会涉及比如说国家大事,或者人与人之间的交流。”(C-1)而在家庭内部的交流形式上,另一位老师分享道:“家长之间交流的形式上,在城市的环境中语言形式更加丰富,而对农村学生来说,由于没有接触到这样的环境,他想不到替代的语言,永远都是很匮乏的那几个字……而且语言表达形式城市更多是讲普通话,农村更多是方言,有地域性的特点,从而导致交流的形式、方式都会比较单一单调,城市会比较复杂。”(C-3)这种“单一的”“有地域性的特点”的语言风格就是“限制性符码”,而“形式更加丰富”“复杂”的语言风格便是“精致型符码”。这种教养方式的差异最终导致不同阶层学生在语文写作中的不同表现:“(农村学生)平时如果过于表述别人的观点,那么在语文写作中就不敢说,别人没有告诉我这个观点是什么,即使心里有话也不敢说。而对于经常表达观点的人,只要能够自圆其说,他就敢去表达。如果敢于表达自己的观点,那观点之后的理由可能不是很完善,(那么)在表达第二次的时候,他就要把这几个漏洞补掉,逐渐形成自己的一条观点线和证据线,那这样自然而然就会越来越完整。”(C-1)可见,语文学科的特殊性注定了其与现实生活世界保持着紧密的联系,更加注重平时的积累和体验,而优势阶层的生活方式、教养方式以及所形成的语言符码等与语文学科的特征更为吻合,使得其能够获得语文成绩的更大收益。
语文学科是“符号暴力”更适合生长的温床,知识的不确定性,使得学业礼仪建构过程中,所有持有称号的人成了学业神化过程的神圣群体。如德·梅雷骑士所说“亲身实践德行的方式,方式本身就是各种各样的德行”[48]。从法律上来说,就是使他们成为某种社会品德或者某种能力的合法垄断者[12]205。英语作为主要外语科目,在初中阶段涉及的还是相对基础的知识内容。“英语学科的知识从中学到大学是一种螺旋式上升的结构。中学阶段主要考察的是综合语言的应用能力和一些比较基础的语法知识。”(E-1)但同样作为一种语言,在英语写作中和语文知识又有着紧密的联系。“现在的英语写作更强调整合性。以前可能就是要求你写个“my friend”或者“my favorite animal”这样的简单话题,但现在比如提供了三个话题的内容,你要懂得综合运用这些素材,需要学生去整合和提炼素材和观点。而语文不好的学生虽然有的同学作文的整体要点都写到,但是要点之间的衔接和过渡是比较不清楚的。所以学生在写作时,有时候语法没有问题,但是读起来就是很奇怪。”(E-1)虽然优势阶层的家庭也很少能够提供全英文的语言环境,但其所掌握的“符号暴力”依旧发挥着作用。
而数学学科知识之间的线性关系更强,在学习的早期阶段知识的确定性强,在教学内容和评估标准上也更客观和固定。“数学说白了就是分析数量之间的关系,而这种关系是非常严谨的,要素之间的关系也是环环相扣,是一种严格的推理,所以在考试的时候经常出现一个小符号的错误就导致整道大题的失分。另外一个显著的特点就是数学的抽象性。例如三角函数、二次函数等等,其实我们在实际生活中很少说用这样的函数去解决什么具体的生活问题,这更多是数学本身的话语。”(M-1)这种相对确定和封闭的学科知识特征和优势阶层开放、多元的生活状态并没有像语文学科那样切合。“数学知识不像语文那样追求个性化和多元化。无论你用哪种语言,英语也好,中文也罢,全世界的数学公式基本上就在那里,不变的,通用的。”(M-1)这种知识类型的特征也使得诸如数学的“集合型课程”更难被优势阶层所垄断。可见,由于数学课程中所涵盖的知识具有很强的确定性和独立性,使得数学成绩相对独立于学生的家庭背景状况。已有研究梳理了近30 年来关于家庭背景与学生数学成绩之间关系,发现两者之间呈现的线性关系较弱(r=0.202)[49],且不同地区、不同年龄和不同样本中两者之间的系数都有差异[50-52]。此外,参加数学课外补习可以给家庭社会经济地位较低的学生带来更大的成绩收益,起到促进教育结果公平的作用[53],说明即使家庭处境不利,学生仍有机会获得较好的数学成绩。
(三)进一步的讨论
再生产理论不仅与流动理论观点相左,其内部之间也存在诸多不同。但无论是以金蒂斯(Gintis)等人为代表的强再生产观点强调教育与社会结构的“符应原则”,还是布迪厄的教育弱再生产观点强调的“文化惯习”,都较少涉及“投入”与“产出”之间的学校教育过程,而即便伯恩斯坦提出了“语言符码”与“课程符码”,亦没有明确凸显两者之间的匹配情况在再生产过程中的作用。本文尝试思考阶层之间“语言符码”和学科之间“课程符码”的匹配情况,实证分析了不同阶层学生在不同学科上的学业成绩差异情况,揭示了教育再生产过程的不同情况。准确地说,“符码理论”在解释再生产的实现途径上更多是通过诸如语文、英语等“整合型课程”得以实现,而在如数学这样的“集合型课程”上则显得并不顺畅,可能是因为文化资本的作用是有条件的,只有在考核与评价体系主观化、非标准化的情况下才有效[54]。可见,“符码理论”在解释教育再生产时并没有体现出绝对的结构主义,而是一种含蓄的结构主义。总的来说,只有当语言符码与课程符码达成匹配时,教育再生产的通道才会被打开。可以说,知识特征与阶层特征的匹配是教育再生产理论得以有效运转的关键,课程符码与阶层符码之间的“匹配程度”成了教育再生产的调节器。因此,对教育再生产理论的理解不能只停留在资源的“投入-产出”模式,应该进一步认识到是资源“投入-匹配-产出”的模式。
本文的不足主要体现在:第一,在现有数据条件下,文章中关于“课程符码”的讨论只能局限在语文、数学和英语范围内进行,缺乏更多学科角度和更细致的证据来进行稳健性验证;第二,虽然本文证实符码理论对不同学科学业成绩的阶层差异具有较好的解释力,但不同社会环境的文化差异和中文世界语言环境的复杂性使得继续开展更加严谨和开拓的实证探索依旧很有必要。
注释
①合法性语言:对学生课堂回答结果的肯定、否定的知识性反馈。
②前期对一线教师的访谈中发现,例如政治、历史、地理、物理、化学、生物等学科均有不少与数学学科特征相近之处,均在一定程度上体现了“集合型课程”的特征,而英语与语文的学科特征也在一定程度上重合。但CEPS数据并不提供除语数英三科之外的学科成绩,导致本文无法通过相关学科的互证以进一步增强结论的稳健性。
③因为多层线性模型分析过程中不允许存在缺失值,所以删除了所有存在缺失值的样本。经检验,删除存在缺失值前后的样本在学校、班级、性别、户籍等各维度上的分布均差异不大。
④分别以C 代表受访的语文教师,M 代表数学教师,E 代表英语教师。
⑤学业总成绩为学生的语文、数学和英语经过标准化的分数之和。
⑥需要说明的是,传统计量方法在分析嵌套数据时容易犯以下错误:一是将班级特征分解到个体变量,但由于同一班级的学生彼此之间不独立,受到相同的教学环境、教学方法等的影响,这违背了传统统计的独立性假设;二是将个体特征集中到班级层面上,这种做法遗漏了宝贵的个体之间的差异。
