S2-Net: Self-Supervision Guided Feature Representation Learning for Cross-Modality Images
2022-10-26ShashaMeiYongMaXiaoguangMeiJunHuangandFanFan
Shasha Mei, Yong Ma, Xiaoguang Mei, Jun Huang, and Fan Fan
Dear Editor,
This letter focuses on combining the respective advantages of cross-modality images which can compensate for the lack of information in the single modality. Meanwhile, due to the great appearance differences between cross-modality image pairs, it often fails to make the feature representations of correspondences as close as possible. In this letter, we design a cross-modality feature representation learning network, S2-Net, which is based on the recently successful detect-and-describe pipeline, originally proposed for visible images but adapted to work with cross-modality image pairs. Extensive experiments show that our elegant formulation of combined optimization of supervised and self-supervised learning outperforms state-of-the-arts on three cross-modal datasets.
Establishing the local correspondences between two images, as a primary task, is the premise of various visual applications, including target recognition, visual navigation, image stitching, 3D reconstruction and visual localization [1]. The conventional matching methods are based on the handcrafted local feature descriptors [2]–[4] to make the representation of two matched features as similar as possible and as discriminant as possible from that of unmatched ones.Over the recent years, the deep learning-based methods have achieved significant progress in general visual tasks, and have also been introduced into the field of image matching. The current approaches are mostly based on a two-stage pipeline that first completes the extraction of keypoints and then encodes the patches centered on the keypoints into descriptors, thus referred to as the detectthen-describe methods. In the field of cross-modality image matching, the detect-then-describe methods have been widely used with a manual detector to detect and an adapted deep learning network to perform description [5]. For example, a cross-spectral local descriptor, Q-Net [6], uses a quadruplet network to map input image patches from two different spectral bands to a common Euclidean space. SFc-Net [7] adopts the Harris corner detector for candidate feature point detection and then gets correspondences by a Siamese CNN.
Despite this apparent success, it is an inevitable disadvantage of this paradigm that the global spatial information is discarded during the description process, which happens to be essential for crossmodality images. In contrast to it, the detect-and-describe framework for visible images uses a network to simultaneously perform feature point extraction and descriptor construction [8], [9]. This approach postpones the detection process without missing high-level information of images. Additionally, the detection stage is tightly coupled with the description so as to detect pixels with locally unique descriptors that are better for matching. Undoubtedly, it is promising to introduce the framework into cross-modality image matching, however, challenges come up due to the huge heterogeneity. To be specific, it is difficult to optimize the model for cross-modality images with extreme geometric and radiometric variances.
Self-supervised learning (SSL), which helps the model obtain easy invariance with augmented data, is one of the most popular techniques in natural language processing and computer vision. As for local feature representation learning, the well-known Superpoint [10]proposed a novel Homographic Adaptation procedure, which is a form of self-supervision, to tackle the ill-posed problem of keypoint extraction. Nevertheless, the SSL technics have not been introduced into cross-modality scenario, while current methods are devoted to obtaining supervised signals from labeled data instead. Since the learning becomes harder for cross-modality images due to the serious radiometric variances, it is desirable to introduce SSL into this task. In fact, among the challenges faced by cross-modality descriptors, excluding inter-modal invariance, other necessities including geometric invariance as well as robustness to noise and grayscale variations can be well-addressed by SSL.
In this work, we explore the possibility of using SSL, based on the recent success of the detect-and-describe methods, but adapted to work with cross-modality image pairs. Although the cross-modality images are heterogeneous and quite different in appearance, they still have some similar semantic information, such as the shape, structure,and topological relationship. The detect-and-describe methods retains the global spatial information which is rather crucial for our task. As for the optimization problem, we provide an effective solution for the application of the detect-and-describe methods to the cross-modality domain. More precisely, we propose our novel architecture of joint training with supervised and self-supervised learning, termed S2-Net,which takes full advantage of SSL to improve matching performance without extra labeled data, as illustrated in Fig. 1. Self-supervision simulates the feature representation learning of images in the same modalities. Since the task of training image representations of the same modality is relatively easier compared to different modalities,self-supervision plays a guiding role in the training process. Also, we design a loss function that combines both supervised and self-supervised learning and optimally balances the guidance of the two optimization methods. To the best of our knowledge, S2-Net is the first algorithm that introduces the SSL technique into cross-modality feature representation, and sufficient experiments have demonstrated the great effectiveness of our work.
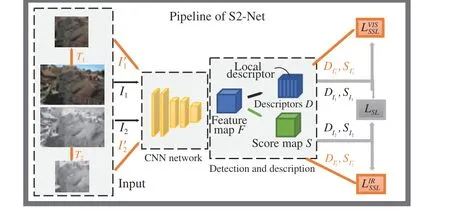
Fig. 1. Our proposed S2-Net for cross-modality images.
Method: In this section, our proposed technique of self-supervision-guided optimization will be explained in detail.
1) Framework of self-supervision guided optimization: We propose S2-Net, a general framework aims to make the detect-anddescribe methods suitable for cross-modality image matching. To train the basic framework, relevant constraints for single modality images are proposed. However, the lack of strong supervision in these constraints, e.g., which point should be the key point, always troubles the training. Moreover, it is common knowledge that the difference between pairs in the same modality is much smaller than cross modalities. To this end, it is promising to introduce the monomodality self-supervised learning to guide the cross-modality training. As illustrated in Fig. 1, based on the basic framework, the other two branches with augmented cross-modality images for self-supervised learning are introduced for joint training. It should be noted that our approach only changes the training process that the original pair of images inside a batch becomes three pairs, which is equivalent to tripling the batch size, so the training time also becomes three times the original, but the testing time remains the same.

Experiments: In order to demonstrate the effectiveness of our proposed approach, we selected D2-Net [8] and R2D2 [9], two classic detect-and-describe methods for visible images, and two handcrafted descriptors of scale-invariant feature transform (SIFT) [3] and radiation-variation insensitive feature transform (RIFT) [4] to compare the performance of our self-supervision on these methods. To better evaluate the performance on cross-modality images, we also compared CMM-Net [11], which designed a novel network for feature representations of thermal infrared and visible images.

2) Experimental datasets: The matching of thermal infrared (TIR)and visible images is a typical cross-modality problem, so we perform our experiments on RoadScene dataset [12], which is comprised of 221 aligned thermal infrared and visible images. This dataset was split in a testing dataset with 43 image pairs from different scenes and a training dataset from the remaining 178 pairs. We also perform our experiments on a public registered RGB-NIR scene dataset [13], which consists of 477 pairs in 9 scenes captured in RGB and near-infrared (NIR). We randomly select 171 pairs for testing (19 per scene) and train on the rest. In addition, we conduct experiments on OS dataset, which is a high-resolution dataset of co-registered optical and SAR patch-pairs [14]. And we select training set from 512×512 pairs for training (2011 pairs) and testing set from 512×512 pairs for testing (424 pairs).
3) Evaluation metrics and comparison results: Three evaluation metrics, number of correspondences in the extracted points (NC),number of correct matches (NCM) and the correctly matched ratio(CMR) are used to evaluate the different methods quantitatively. NC indicates the repeatability of extracted interest points and NCM is crucial for the image registration. CMR is computed as
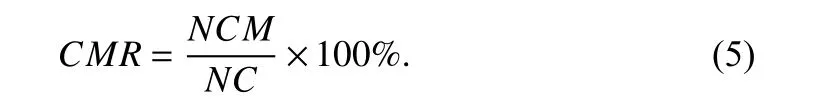
In the testing process, we vary the number of points extracted from both images, which is denoted asK, and record the evaluation results on each method. Specifically, we setK=1024,K=2048 andK=4096. The results obtained are listed in Tables 1-4.
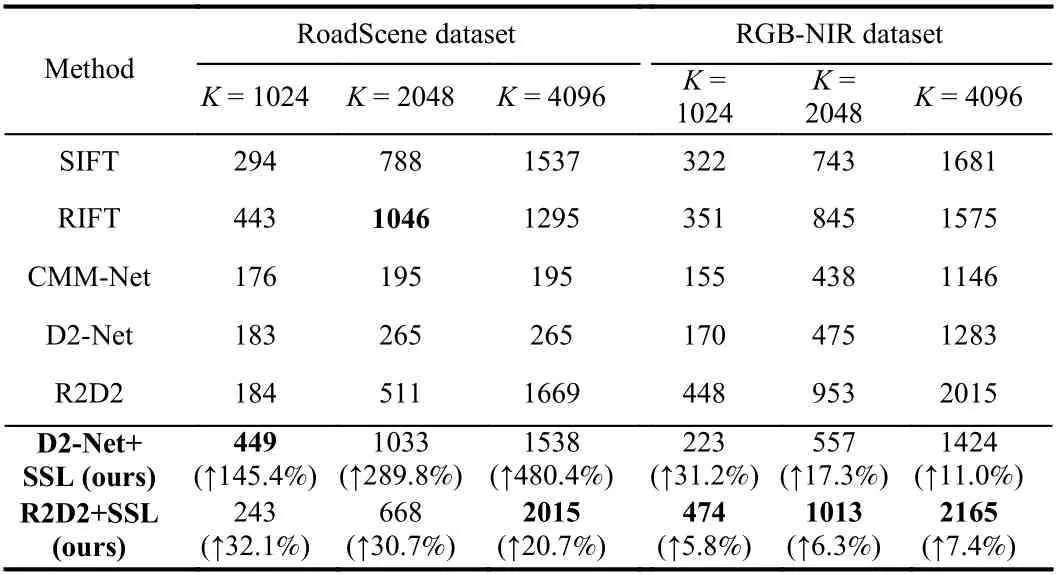
Table 1.Number of Correspondences in the Extracted Points on the Two Datasets
Combining the three evaluation metrics, it can be seen that on RoadScene dataset, D2-Net with SSL achieves the best performance,and R2D2 with SSL ranks second. The SIFT algorithm, performs the worst of all since it requires texture details that differ across modalities. It should be specially noted that the original R2D2 achieves fairly good results among the compared methods, nevertheless, we improve it quite a bit. This is due to the fact that the original R2D2 algorithm takes repeatability and reliability into account in its loss,which is not available in D2-Net. So, with SSL, the performance of D2-Net has been extremely boosted. The relevant visualization results are shown in the first column of Fig. 2. As for optical and SAR images, the R2D2 and D2-Net algorithms are not able to obtaincorrectly matched pairs, and therefore the results of them are not presented in Table 4. The multi-modal descriptor, RIFT, performs well among the comparison algorithms. Nevertheless, our method achieves the best results as shown in the third column of Fig. 2 and in Table 4.
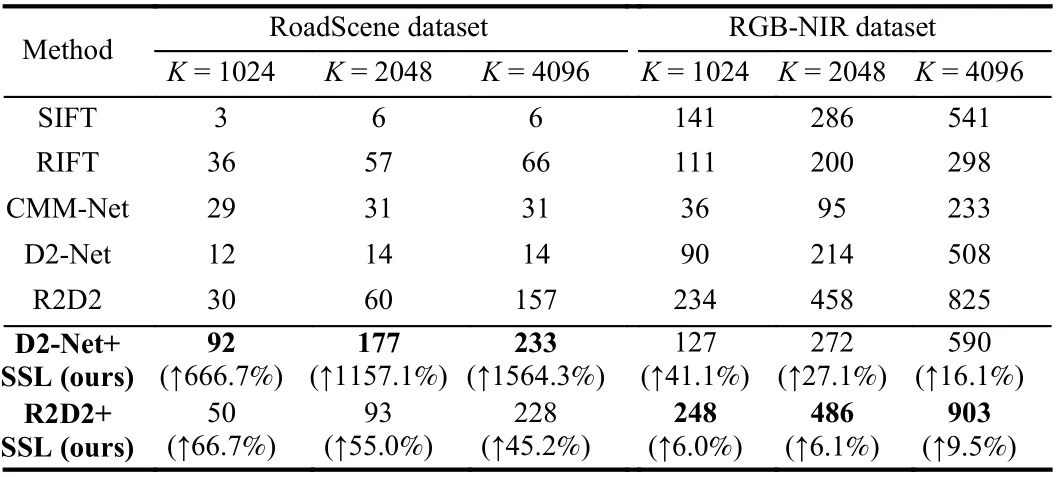
Table 2.Number of Points Correctly Matched on the Two Datasets
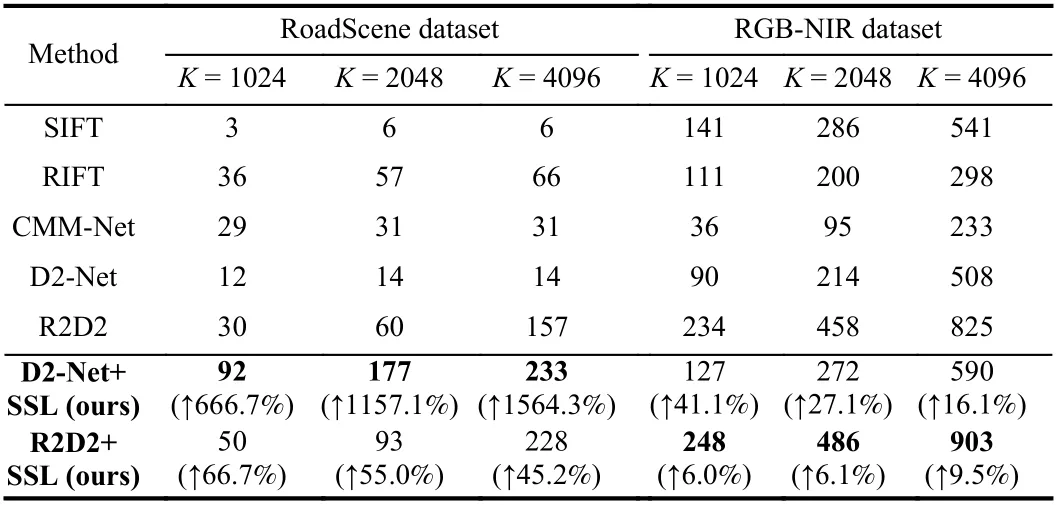
Table 3.Ratio of Correct Matches on the Two Datasets

Table 4.Three Evaluation Metrics on OS Dataset

Fig. 2. Experimental results of S2-Net and the state-of-the-art image matching methods for the three datasets.
And on RGB-NIR dataset, since the difference between visible and thermal infrared images is much more significant than that with nearinfrared images, SSL does not improve the performance of the original method as much as on the RoadScene dataset. And it is reasonable that SIFT achieves a good accuracy. However, the performance of R2D2 with SSL ranks best above all methods, as depicted in the middle column of Fig. 2. The guiding effect of self-supervision in the training process is rather beneficial when learning modality-invariant feature representations.
Conclusion: In this article, we propose S2-Net, which introduces the self-supervised learning in the training learn the modality-invariant feature representation. After performing experiments on three datasets, it can be demonstrated that our strategy significantly improves the networks’ capability of feature representation for crossmodality images, including the detection and description.
Acknowledgments: This work was supported by the National Natural Science Foundation of China (NSFC) (62003247, 62075169,62061160370).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Survey of Output Feedback Robust MPC for Linear Parameter Varying Systems
- Evaluation of the Effect of Multiparticle on Lithium-Ion Battery Performance Using an Electrochemical Model
- Geometric-Spectral Reconstruction Learning for Multi-Source Open-Set Classification With Hyperspectral and LiDAR Data
- Push-Sum Based Algorithm for Constrained Convex Optimization Problem and Its Potential Application in Smart Grid
- A Domain-Guided Model for Facial Cartoonlization
- A Trust Assessment-Based Distributed Localization Algorithm for Sensor Networks Under Deception Attacks