基于LSTM-SVM 模型的恶意软件检测方法
2022-10-25张雪芹朱唯一朱世楠
赵 敏, 张雪芹, 朱唯一, 朱世楠
(华东理工大学信息科学与工程学院,上海 200237)
安卓(Android)系统因其开放性成为了恶意软件最易滋生的平台。许多恶意软件会诱导用户安装木马,或者通过申请过多或不当的权限来获取相关信息,实现其搜集用户隐私的目的[1]。为了避免或减少恶意软件带来的损害,对恶意软件实现高精度的检测具有重要意义。Android 系统恶意软件的检测技术主要分为静态检测[2]和动态检测[3]。静态检测是指在不执行应用软件的情况下判断其是否是恶意的;动态检测是指在执行Android 应用软件时收集系统调用、网络流量、用户交互等信息来判断其是否是恶意的。静态检测能够在安装前发现恶意软件,实现有效预防。本文针对静态检测方法开展研究,提高检测准确度。
近年来,机器学习和深度学习[4-6]技术在Android恶意软件的静态检测中得到了应用。Fcizollah 等[7]为了评估意图信息作为识别恶意软件特征的有效性,提出了AndroDialysis 系统。该系统提取了意图特征,采用贝叶斯网络结合简单估计算法和LAGDHillCilmber 搜索算法进行恶意软件的检测,在1 846 个良性应用和5 560 个恶意软件组成的数据集上达到了91%的检测精度,误报率和漏检率均为9%。Li 等[8]为了应对Android 恶意软件数量的快速增长,提出了一种基于权限使用分析的恶意软件检测系统(SigPID),提取权限特征后通过负比率权限排序、基于支持度的权限排序和关联规则权限挖掘3 个级别的剪枝来识别最重要的权限,以有效区分良性应用和恶意应用;采用Functional Tree 模型,在各有5 494 个良性应用和恶意应用的数据集上达到了95.63%的检测精度,误报率为2.36%,漏检率为6.38%。Alotaibi[9]提出了MalResLSTM 框架用于恶意软件识别。该框架提取硬件组件、请求权限、应用程序组件、意图和可疑应用程序接口调用等8 组静态特征组成特征向量,利用ResLSTM 网络进行恶意软件的检测,在Drbin 数据集(包含123 453 个良性应用和5 560 个恶意软件)上的检测精度达到了99%,误报率为0.36%,漏检率为9%。Xu 等[10]提出了DeepRefiner 网络用于Android 恶意软件的检测。该网络是一个基于深度学习的双层网络,第1 层采用多层感知器,通过xml 文件中的权限、组件等信息将样本分为良性、恶意以及不确定3 类;第2 层采用LSTM 网络,通过字节码信息对第1 层网络中分类为不确定的样本再次检测。在62 915 个恶意软件和47 525 个良性应用组成的数据集上检测精度达到97.74%,误报率为2.54%,漏检率为2.04%。孙志强等[11]针对传统Android 恶意软件检测方法检测率低的问题,提出了一种基于深度收缩降噪自编码网络(Deep Contractive Denoising Autoencoder Network, DCDAN)的Android 恶意软件检测方法,对深度自编码网络的输入数据添加噪声,同时加入雅克比矩阵作为惩罚项,结合贪婪算法和反向传播算法进行训练,通过权限、软硬件、组件和敏感API 等7 类信息进行检测,在各2 500 个良性和恶意样本的数据集上检测精度达到97.8%,误报率为1.6%,漏检率为2.8%。
由此可见,权限、组件、意图和API 特征在恶意软件的检测上是有效的。机器学习方法,特别是深度学习方法能够有效发现特征中隐含的非线性关系,提升检测效果。因此,本文采用维度较低的API 特征训练SVM 网络模型;采用维度较高的XML 特征训练LSTM 网络模型。为了进一步提高Android 恶意软件的检测精度,提出了一种基于多特征多模型的检测方法,主要创新点为:(1)提出了一种API 特征的选取方法,降低对恶意样本的漏检率,提高检测精度。(2)基于API 特征和XML 特征,提出了LSTM-SVM 并联检测模型,结合概率差融合算法,对恶意软件进行检测,在保证漏检率的条件下,降低误报率,提高检测精度。
1 恶意软件特征选择
Android 应用程序的原文件是扩展名为.apk 的压缩文件,经过apktool 来反编译APK 原文件,可获取AndroidManifest.xml 和smali 两类文件。Android-Manifest.xml 文件是应用程序的清单文件,描述了全局的数据,为应用程序的运行提供了说明,从中提取所包含的信息可作为一类检测特征。smali 是Android虚拟机Dalvik 的反汇编语言,每一个smali 文件都对应一个Java 类,其中包含了所有的函数信息。每个应用软件都需要一组Android API 来实现其主要目标和功能,因此应用软件中使用的API 列表代表了应用程序的特点[12]。研究发现,恶意软件与良性软件在某些API 的调用上有很大差异[13],从smali 文件中提取API 调用可作为一类检测特征。
1.1 XML 特征及其特征列表构建
AndroidManifest.xml 文件中包含了应用程序所需要的权限(Permission)、组件(Component)、意图(Intent)、软硬件、资源等信息,其中恶意软件和良性软件在权限、组件和意图的使用种类上有较大差异[14],可以选取这几类信息作为检测特征。
Android 系统提供了一个基于Permission 的访问控制机制,使得应用程序的操作行为和敏感数据的访问被严格控制。为了完成一定的行为操作,应用程序必须向Android 系统申请一些对应的系统权限,因此,系统权限的使用能够暗示一个Android 应用的行为信息。Component 是Android 应用的基本模块,包括Activity、Service、Broadcast Receiver 和Content Provider。其中,Activity 提供一个开发人员可以定义的虚拟用户接口;Service 提供可以执行的后台处理;Broadcast Receiver 提供接收其他应用程序信息的通道;Content Provider 提供数据库接口,用来和其他应用程序分享数据。Intent 可以用来开启组件或者向其他组件传送一些重要数据,它暗示了组件间的交互信息。Intent 有Data、Extras、Action 和Category 4 个重要属性,其中,Data 和Extras 主要用于存放或传递数据,如电话、邮箱、网址等;Action 代表系统中已经定义了的一系列常用动作;Category 用于指定Action 被执行的环境。由于每个应用软件所需的数据都不相同,前两者无法判断应用软件的良、恶意;后两者在一定程度上可以反映应用程序的动作,且具有固定取值,因此可以用来判断应用软件的良、恶意[7]。
本文提取Permission、Component、Intent 信息作为检测特征,称为XML 特征。为了构建检测模型,对训练数据集中的多个Android 软件分别提取XML特征,合并后构建XML 特征列表。表1 示出了XML特征列表中的部分特征。

表1 XML 特征示例Table1 Examples of XML features
1.2 API 特征及其特征列表构建
smali 文件中以“invoke-”开头表示函数调用,可以从中寻找API 及相关信息。API 代表了应用程序的特点,在一定程度上能够区分良性和恶意应用。API 特征有onCreate、getCacheDir、setFillType、createFromParcel 等。本文提出根据smali 文件分析API 调用情况,构建API 特征列表。
为构建检测模型,对训练数据集中的多个Android 应用软件分别提取API 特征,API 特征列表构建方法如下:
(1)提取良性应用软件中的API;
(2)分别统计各API 被多少个良性应用软件调用过,按照调用次数从大到小进行排序,得到一个初始的良性API 列表;
(3)提取恶意应用软件中的API,进行同样的操作,得到一个初始的恶意API 列表;
(4)分别取两个列表中包含前n个API 的子列表,可以认为经过排序操作后选取的两个子列表在一定程度上代表了良性软件和恶意软件的API 调用分布;
(5)将两个子列表合并,删除重复的API(使每个API 名称在列表中仅出现一次),构成API 特征列表。
API 特征列表构建流程如图1 所示。

图1 API 特征列表构建Fig.1 Construction of API feature list
1.3 特征向量化
每个APK 原文件都可以获得XML 和API 两组特征。使用apktool 工具对训练集中的每个Android恶意软件的APK 原文件进行反编译,获取每个APK原文件对应的AndroidManifest.xml 文件和smali 文件。其次,将xml 文档表示成树,通过标签提取检测所需要的Permission、Component 和Intent 特征,并构成XML 特征列表;对smali 文件中通过判断每行的前7 个字符是否是“invoke-”找到相应位置,提取API 调用特征,通过分析API 调用情况构成API 特征列表。
对训练集和测试集中的每个Android 软件,反编译后提取XML 特征和API 特征,对照XML 特征列表和API 特征列表,根据各特征出现与否量化为1 和0,构造出每个软件的特征向量,用于模型训练和检测。
2 LSTM-SVM 并联检测模型
2.1 LSTM-SVM 检测框架
从Android 应用软件中可以提取出多种静态特征,不同的特征其中隐含的信息也不同。简单的级联合并会使特征维度过高,增加检测模型训练负担,同时还会形成特征冗余,影响检测效果。本文提出构建LSTM-SVM 并联检测模型,考虑恶意软件运行的时序性、特征维度等,对XML 长特征采用LSTM建模,对API 特征采用SVM 建模[15],最终根据模型预测概率差确定检测结果。基于LSTM-SVM 模型的Android 恶意软件检测框架如图2 所示。
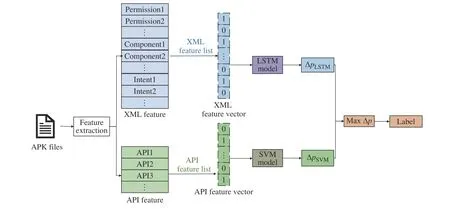
图2 基于LSTM-SVM 的恶意软件检测框架Fig.2 Malware detection framework based on LSTM-SVM
2.2 基于SVM 的异常检测模型
SVM 的本质是一种二分类算法,通过求取能使两类样本以最大间隔分开的超平面建立分类模型。考虑到恶意样本数量较少,API 特征维数较高,而SVM 在小样本、高维度的情况下仍具有较强的分类能力和泛化能力,可以在一定程度上克服“维度灾难”和“过学习”的问题[16],本文采用SVM 构建基于API 特征的异常检测模型。
对于给定的样本数据(x1,y1),(x2,y2), ,(xN,yN),X2 Rd,y2 f+1,−1g,N为样本数,d为输入维数,x为提取的API 特征向量,y为类标签,如果y的值为1,表示对应的样本为良性;如果y的值为-1,表示对应的样本为恶意。根据SVM 理论,对于待分类样本存在一个超平面,使得两类样本完全分开,该超平面为
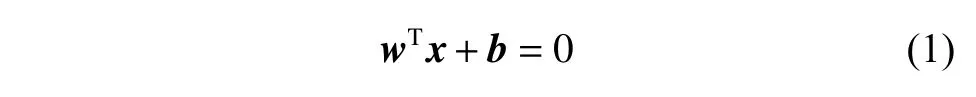
其中:w表示法向量,决定了超平面的方向;b表示偏移量,决定了超平面与原点之间的距离。
求解超平面可以看成如下二次规划问题求解:
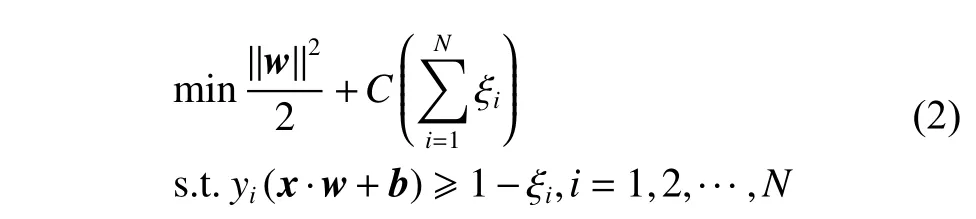
其中:C为惩罚因子,控制对错分样本的惩罚程度;ξi为松弛变量,每个样本都有一个对应的松弛变量,表征该样本不满足约束的程度。
求解式(2)可转化为求解其对偶问题:
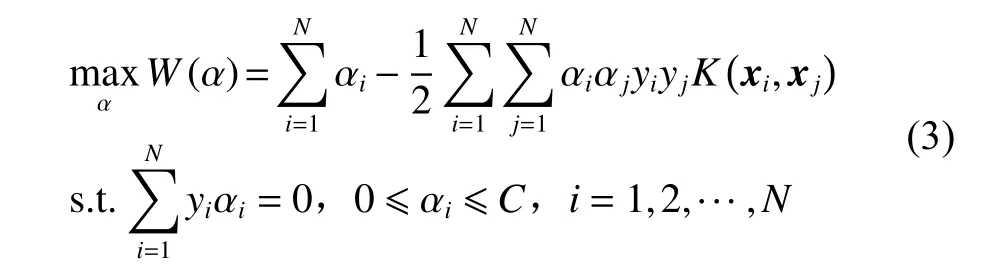
其中: αi为拉格朗日乘子,对应于 αi>0 的向量称为
K�xi,xj)=φ(xi)Tφ�xj)支持向量; 为核函数,常用的核函数有线性核函数、多项式核函数、高斯核函数等,不同的核函数将形成不同的算法。决策函数为
其中, S gn(x) 代表符号函数,当x<0 时,返回值为-1;当x>0 时,返回值为1;当x=0 时,返回值为0;αi*表示最优拉格朗日乘子;b*表示最优偏置。
2.3 基于LSTM-SVM 网络的异常检测模型
长短期记忆(LSTM)网络[17]是为了克服递归神经网络(Recurrent Neural Network, RNN)中梯度消失和梯度爆炸问题而提出的一种深度学习方法,通常应用在具有时间序列的分类问题中。它可以通过基于时间序列的记忆门学习长期依赖关系,模拟多个输入变量的问题,因此常用于时间序列检测。此外,由于LSTM 网络能够有效保留长序列数据中对最终判定结果有益的历史信息,因此,对于挖掘数据之间的关联关系也表现出了良好的效果。考虑到XML特征描述了应用软件的运行特性,其中存在着时序关系,本文采用LSTM 构建基于XML 长特征的异常检测模型。
LSTM 添加了记忆单元专门用于保存历史信息,记忆单元的结构如图3 所示。每个记忆单元含有3 个输入:来自原始输入序列中当前时刻t传入模型的所有有用数据xt、到t-1 时刻模型记录的历史状态ct-1和所有有用的隐藏信息ht-1。每一个记忆单元的输出包括当前时刻记录的所有有用信息ht和当前状态ct。

图3 LSTM 单元标准结构Fig.3 LSTM unit standard construction
为了寻找历史信息中的有效内容,输入数据要通过3 个门:遗忘门(f)、输入门(i)、输出门(o)。遗忘门负责判断是否丢弃历史信息,它的输入是历史隐藏信息ht-1以及当前序列节点信息xt,使用Sigmoid 函数输出一个0 到1 之间的值,表示是否遗忘历史单元状态模式的信息,1 表示保留历史信息,0 表示遗忘历史信息。遗忘门的计算如式(5)所示:

其中:W表示神经单元中的权重矩阵;下标f 表示遗忘门;下标x 表示当前节点信息;下标h 表示历史隐藏信息(即Wfx表示遗忘门当前节点信息的权重矩阵;Wfh表示遗忘门历史隐藏信息的权重矩阵);b为对应权重偏置; σ 表示Sigmoid 函数。
同理可得输入门和输出门对应的计算公式,如式(6)和式(7)所示:

候选状态gt和当前状态st决定了在当前单元中可以保留哪些新的信息到下一个神经元。
最终根据传输信息的状态确定输出值,以tanh 函数处理当前单元状态,并与输出门相乘得到当前单元的隐藏信息ht,再传递给下一个单元。

2.4 概率差融合算法
实际上恶意软件检测的本质是二分类,对应的样本标签为正(1)或负(-1),正标签对应良性应用,负标签对应恶意软件。在进行二分类时,LSTM 和SVM 检测模型输出的是样本属于正、负标签的概率值,并取较大概率值对应的标签为分类结果,即:
其中: l abel 表示得到的样本标签;pbenign表示输入数据属于正标签(即良性应用)的概率;pmalicious表示输入数据属于负标签(即恶意软件)的概率。概率差为

通常,两个概率之间的差值越大,可认为模型得到的分类结果越可靠。
在LSTM-SVM 并联检测模型中,当两个检测模型给出的分类结果不同时,认为概率差较大的检测模型给出的预测结果更为可靠,即

其中: ΔpLSTM为LSTM 模型给出的输入数据的概率差; ΔpSVM为SVM 模型给出的输入数据的概率差;labelLSTM为LSTM 模型给出的分类结果; l abelSVM为SVM 模型给出的分类结果。
2.5 算法描述
基于LSTM-SVM 模型的Android 恶意软件检测算法描述如下:
输入:APK 文件
输出:样本分类标签
(1) apktool 反编译训练样本,获得xml 文件和smali 文件
(2) 从AndroidManifest.xml 文件中提取XML特征,从smali 文件中提取API 特征,分别构建特征列表
(3) 对应特征列表将XML 特征和API 特征映射为0 或1 组成的特征向量
(4) 基于XML 特征训练LSTM 检测模型,基于API 特征训练SVM 检测模型
(5) 反编译测试样本,提取XML 特征和API特征,对应特征列表得到XML 和API 特征向量
(6) 测试样本的XML 特征向量送入训练好的LSTM 模型,API 特征向量送入训练好的SVM 模型,得到对应标签及概率
(7) If labelLSTM= labelSVM
(8) 最终分类标签label=labelLSTM=labelSVM
(9) End
(10) If labelLSTM≠ labelSVMΔpLSTM>ΔpSVM
(11) If 概率差
(12) 最终分类标签label=labelLSTM
(13) Else
(14) 最终分类标签label=labelSVM
(15) End
(16) End
3 实验部分
实验的硬件环境为Intel Core i5-9300H CPU 2.40 GHz, 8 GB RAM, 软 件 环 境 为Windows10,python3.7,apktool。
3.1 实验数据
实验采用CICAndMal2017[18]数据集,其中包含了1 700 个良性软件和426 个恶意软件。该数据集的良性样本多于恶意样本,符合现实世界中良性软件多于恶意软件的状况。实验时,对数据集按照训练集、验证集和测试集分别为60%、20%和20%进行随机划分,各部分数量如表2 所示。在构建各特征序列时,都只使用训练集中的样本,以保证测试集中的样本对于检测都是未知软件。

表2 数据集划分Table2 Data set partition
表3 示出了API 和XML 两类特征的数量。可以看到,API 特征维度为2 253,维度较高;XML 特征中的3 类特征合并后维度达23 893,属于高维特征。

表3 特征类别及其数量Table3 Category and quantity of features
3.2 评价指标
表4 列出了4 个基本评价指标。其中,N(Negative)代表标签为恶意软件;P(Positive)代表标签为良性软件;TN 代表真实标签是N、模型分类为N 的软件数量;FN 代表真实标签是P、模型分类为N 的软件数量;TP 代表真实标签是P、模型分类为P 的软件数量;FP 代表真实标签是N、模型分类为P 的软件数量。

表4 基本评价指标Table4 Basic evaluation index
基于4 个基本指标,定义以下评估指标:
准确率(ACC):被正确识别出来的恶意软件和良性软件个数在样本总数中的占比。

良性检测率(TPR):被正确识别出来的良性软件个数在所有良性软件个数中的占比。

漏检率(FPR):被错误识别为良性的恶意软件个数在所有恶意软件个数中的占比。

3.3 实验结果及分析
实验中,LSTM 模型的神经元数量为256,采用的优化器为adam,学习率为0.001,使用的损失函数为sparse_categorical_crossentropy,SVM 模型的惩罚因子C=0.1。
3.3.1 XML 特征实验 为了验证XML 特征的有效性,XML特征中包含了Permission、Component和Intent 3 类特征,采用LSTM 模型,对比单独使用3 类特征和XML 特征的分类结果,如图4 所示。
由图4 可知,采用XML 特征的ACC 为96.48%,高于3 类特征单独使用时的94.13%、94.13%和92.48%;采用XML 特征的FPR 为6.98%,明显低于3 类特征单独使用时的18.6%、17.44%和31.4%,这是因为各分特征都只描述了程序应用清单的一个方面,单独使用时不能刻画特征间的内在联系,使得准确率较低、漏检率较高。可见,使用XML 特征比单独使用Permission、Component 和Intent 3 类特征更有效。

图 4 3 类特征和XML 特征检测结果比较Fig. 4 Comparison of detection results of three types of features and XML features
3.3.2 API 特征子列表长度对比实验 每个应用软件所用到的API 数量不同,多的甚至达到上万个,但并不是所有的API 调用对恶意软件的检测都是有效的,所选取的API 序列也不是越长越好,选取的序列过长会使得无用信息增加,称为冗余特征。为了在API 特征原始列表中选取合适的子列表长度n,采用SVM 模型进行检测,实验结果如表5 所示。
从表5 中可以看出,虽然TPR 随着API 子列表长度(n)的增加而变大,但是FPR 在API 子列表长度达到2 000 时取得最小,更长的子列表对恶意软件的识别没有更大的作用,因此API 子列表长度取2 000是合理的。

表5 不同API 特征子列表长度检测结果对比Table5 Comparison of detection results of different API feature sublist lengths
3.3.3 特征融合方式对比实验 实验采用LSTM 检测模型,对比使用XML 特征、XML 特征与API 特征向量级联(XML+API)、XML 特征与API 特征向量并联(XML-API)时的分类结果。这里,XML 特征与API特征向量并联指对两种特征分别采用LSTM 建模,输出结果采用概率差融合算法判断。实验结果如表6 所示。
从表6 中可以看出,在XML 特征的基础上引入API 特征,ACC 和TPR 都有所提高,但在级联模式下,FPR 最大,这意味着有更多的恶意软件被漏检。而XML 特征与API 特征并联使用,在不增加漏检率的条件下提升了ACC 和TPR。可见,将XML 特征与API 特征采用并联方式建模是合理有效的。

表6 不同特征融合方式检测结果比较Table6 Comparison of detection results of different feature fusion methods
3.3.4 基于XML 特征的不同算法模型对比实验 为了验证基于XML 特征的LSTM 检测模型的有效性,实验基于XML 特征,对比了LSTM 模型、SVM 模型、RF(Random Forest)模型、MLP(Multi_Layer Perceptron)模型、CNN(Convolutional Neural Networks)模型的实验结果,如表7 所示。
从表7 中可以看出,对于XML 特征,几个模型的TPR 相差不大,RF 模型和CNN 模型的TPR 略高于LSTM 模型,但LSTM 模型的FPR 指标最低,即漏检率最低。因此,基于XML 特征选择LSTM 模型是有效的。

表7 基于XML 特征的不同模型检测结果比较Table7 Comparison of detection results of different models based on XML features
3.3.5 基于API 特征的不同算法模型对比实验 为了验证基于API 特征的SVM 检测模型的有效性,实验基于API 特征,对比了上述几种不同模型的检测结果,以及SVM模型采用线性核(Linear)、高斯核(RBF)和多项式核(Poly)的检测结果,如表8 所示。
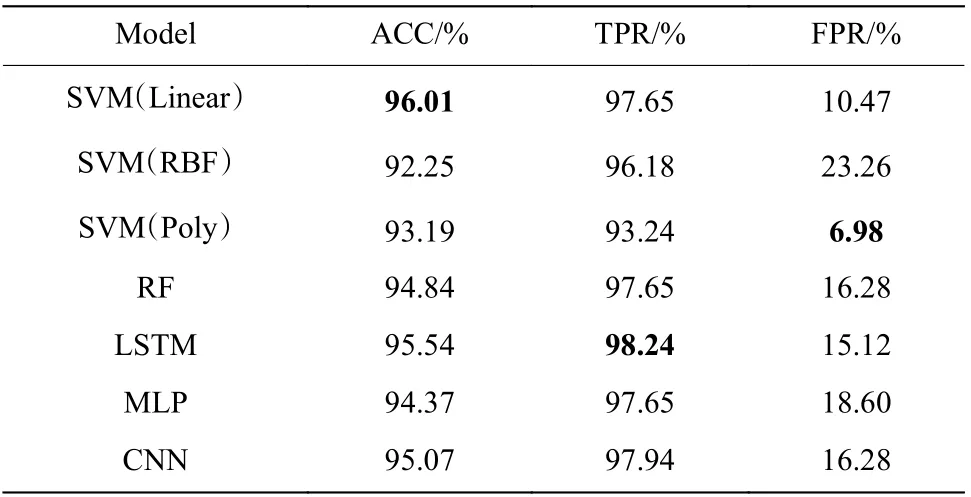
表8 基于API 特征的不同模型检测结果比较Table8 Comparison of detection results of different models based on API features
从表8 看出,采用LSTM 模型的TPR 最高,但FPR 也偏高;使用SVM(Poly)模型的FPR 最低,但ACC 和TPR 也偏低。SVM(Linear)模型的ACC 和TPR 较高,FPR 较低,整体性能好于其他模型。因此,对于API 特征,后续采用SVM(Linear)模型。
3.3.6 并联模型对比实验 为了验证LSTM-SVM 并联模型的有效性,以基于XML 特征的LSTM 模型作为基础对比模型(Baseline),分别将基于API 特征的SVM 模型、RF 模型、LSTM 模型、MLP 模型、CNN模型与基础模型进行并联,采用概率差融合算法给出检测结果,如表9 所示。
从表9 中可以看出,采用并联检测模型可以有效提升检测精度。同时,相较于其他并联模型,本文的LSTM-SVM 模型具有最高的ACC 和TPR,分别为98.12%和99.41%,具有最低的FPR,为6.98%,模型具有最佳性能。
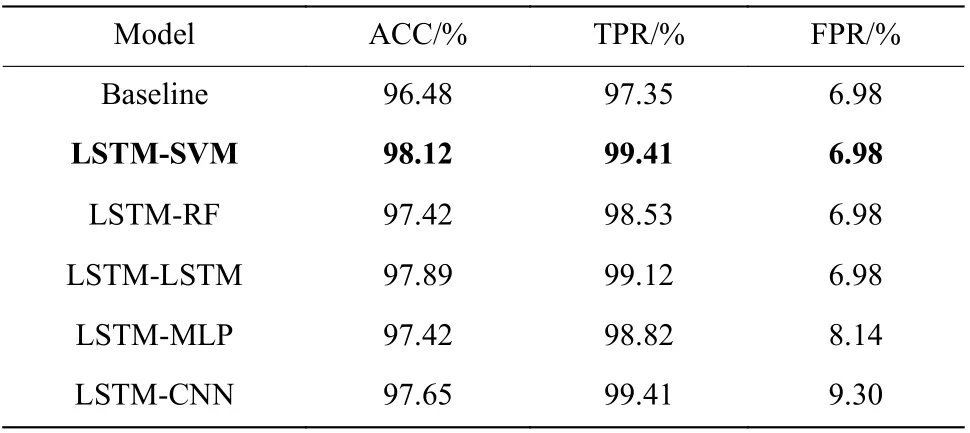
表9 并联模型的对比实验结果Table9 Comparison of parallel models experiments
4 结束语
提出了一种基于LSTM-SVM 模型的Android 恶意软件检测方法。从Android 恶意软件反编译后获得的AndroidManifest.xml 文件中提取Permission、Component、Intent 信息组成XML 特征列表,从smali文件提取API 特征,并通过分析API 调用情况构建API 特征列表;基于XML 特征构建了LSTM 异常检测模型,基于API 特征构建了SVM 异常检测模型,两个模型采用并联模式,基于概率差融合算法给出检测结果。实验结果表明,与单特征单模型、多特征单模型、多特征级联模型相比,基于多特征多模型的LSTM-SVM 模型检测方法具有更高的检测精度。未来考虑进一步在虚拟机或沙箱环境中运行恶意软件获取动态特征,从静态和动态两个方面描述恶意行为,进一步提高Android 恶意软件检测效果。
