基于轻量化SSD算法的行人目标检测
2022-10-25钱雯倩
钱雯倩,王 军
(苏州科技大学,江苏 苏州 210332)
1 引言
随着智能机器人技术的发展,机器人所发挥的作用不可估量,目标人物跟随也成为其需要具备的重要功能之一。建筑物内部结构复杂,不确定因素非常多,如地面障碍物以及行人遮挡等,这对于人物跟随机器人自主导航任务增加了困难。常用的障碍物检测方法有激光雷达传感器、超声波传感器检测、红外传感器检测和计算机视觉检测等。计算机视觉检测相比于其它障碍物检测方法具有成本低、能够有效利用环境中的颜色与纹理信息等优点,所以目标检测是实现机器人跟随目标人物任务的关键技术。
目标检测被广泛应用于视频监控系统和其它领域。目标检测是用于给图像或视频中存在的目标定位的主要技术之一。目标检测的任务主要使用机器学习和深度学习的方法来检测准确的目标。人类通过看图像或视频来检测物体,如何让计算机实现精确的目标检测是现阶段研究的热点问题之一。
近年来,卷积神经网络在图片分类和目标检测领域取得了巨大的成功。常用的目标检测算法大概可以分为三种:第一种是传统的目标算法,首先采用滑动窗口,并且设置不同大小,进行区域选择,然后利用SIFT、HOG等进行特征提取,最后将特征送入如SVM、Adaboost等分类器进行分类,实现目标检测。这种方法在复杂场景下的检测精度较差;第二种是候选区域/窗结合深度学习分类(通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN等),其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度较低;第三种是基于深度学习的回归方法,如YOLO、SSD、DenseBox等方法,以及最近出现的结合RNN算法的RRC detection,结合DPM的Deformable CNN等,通过深层卷积结构自动学习图像的高阶特征,从而生成更加精确可靠的检测结果。
在目标检测与嵌入式设备结合的过程中,在真实场景中人群密度不一致导致重复检测,目标检测模型太大,是需要解决的主要问题。基于此,本文提出基于SSD的轻量化检测算法。1)减少筛选区域候选框以及选用自适应极大值抑制方法排除重叠检测框,在人群密度不一致的情况下,提高了检测的精度和速度。2)通过使用MobilenetV2网络代替传统的VGG网络进行特征提取,减少模型规模。
2 相关工作
2.1 SSD检测算法
针对传统目标识别中的问题,基于深度学习的目标识别检测方法被提出,Ross Girshick等人于2014年提出R-CNN算法,这是首个将深度学习成功应用于目标识别检测上的算法,Ross Girshick等人又于2015年提出Fast R-CNN,只对图像进行一次特征图像提取,但是这种方法生成候选框还是会耗费大量时间。同年,Ren等人提出了Faster R-CNN算法,改进生成候选框方法,利用区域建议网络RPN(Region Proposal Network)生成候选框,比之前的方法快了将近200倍。2015年,Joseph Redmon等人提出了基于单个神经网络的目标检测算法YOLO,这种方法检测速度快,能够满足实时检测的要求,但是对小目标以及遮挡程度高的物体检测能力低,精度也比Faster R-CNN低。
SSD于2016年被Liu等人提出,是经典的单阶段目标检测模型之一。它的精度可以媲美Faster R-CNN双阶段目标检测方法,但速度却比之间的检测算法更快,达到了59FPS。SSD集合了Faster R-CNN的anchor机制以及YOLO的回归思想。
传统的SSD网络结构采用VGG16作为基础模型,其框架结构如图1所示,在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测,是一种多尺度特征地图目标检测算法。SSD算法利用不同尺度的特征映射来检测不同大小的目标,并在后续的金字塔结构中为不同的特征映射选择不同尺度的候选框。

图1 SSD网络框架
2.2 SSD损失函数
在SSD目标检测算法中,如其它检测方法一样使用多任务的损失函数,其损失函数定义为位置误差(locatization loss,loc)与置信度误差(confidence loss,conf)的加权和。
其损失函数为

(1)
其中,是候选框的正样本数量;为类别置信度预测值;为候选框的所对应边界框的位置预测值;为真实预测框的位置参数。
(,)为区域候选框在多类别置信度c上的softmax损失,其公式为

(2)


(3)
式(2)中分为两个部分,一部分为正样本()的损失,即除背景外被分类为某种类别的损失,另一部分为负样本()的损失,即被识别为背景的损失。
(,,)为位置回归函数,其公式为
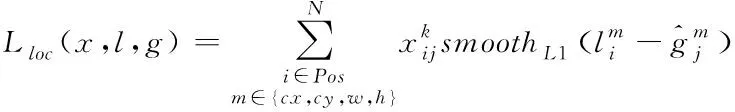
(4)

(5)

(6)
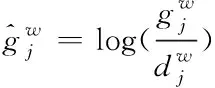
(7)

(8)
其中,(,)为补偿后的候选框的中心,(,)为候选框的宽和高。
3 改进的SSD算法
3.1 SSD区域候选框
SSD的区域候选框借鉴了Faster R-CNN中锚点(anchor)的理念,每个单元设置了尺度或者长宽比不相同的区域候选框,预测得到的真实框是以这些区域候选框为基准的,在一定程度上减少了训练难度。一般情况下,每个预测单元会设置多个区域候选框,其尺度和长宽比存在差异,然后根据每个候选框内预测的各类目标的概率以及区域候选框的位置偏移量对每个区域候选框进行置信度打分,最后经过非极大值抑制NMS(Non Maximum Suppression)找出最有可能出现目标物的框,根据对应的偏移量来调整候选框最后的位置以及形状,得到最终检测框。区域候选框定义如下式

(9)

本实验中,由于人的行为特征、生理特征可能出现行为姿态各异的情况,所以对区域候选框进行了尺寸上的设置。宽高比为2或3的候选框不符合实际情况,所以排除这两个宽高比的区域候选框,此时每个单元格内就只有4个区域候选框。本文在不同层的特征图上设置了不同的区域候选框,覆盖住不同层上原图上的不同大小的人或物体,这样能够更加准确的对目标候选框进行回归,减少运算量及时间。
3.2 改进模型
传统SSD算法使用VGG网络,其网络模型参数较多,且特征提取等操作需要GPU的强大算力做支撑,虽然其精度和速度都已经达到了目前众多目标检测算法中较为可观的程度,但是应用在没有强大GPU的移动设备的嵌入式系统中,SSD算法还需要进行改进,由此,本文选择MobileNetV2轻量化网络代替原本的VGG网络。
MobileNet网络就是对卷积操作进行轻量化处理,使用深度可分卷积(depthwise separable convolution)来减少模型的参数量。其处理方式是将标准卷积分为深度卷积(dephwise convolution)和点卷积(pointwise convolution)两个过程。深度可分卷积虽然大幅降低了计算量,但是在实际训练时会出现很多训练失败的卷积核,所以在输出特征图时,它的维度也很小,它的特征图在通过ReLU激活函数后会产生信息丢失。
MobileNetV2应用了如图2所示的倒残差网络结构减少信息丢失。它首先对输入的特征图用1×1的卷积核进行升维处理,扩展数据中的通道数量,然后再用3×3的普通卷积进行特征提取,最后用1×1的卷积核进行降维,自动选择有用的特征,减少参数数量。在倒残差网络中为了解决ReLU函数会丢失信息的情况,就只对高维的特征图使用ReLU函数,对低维的特征图使用线性激活函数。由于本文是将识别算法应用于移动设备的嵌入式系统中,所以用ReLU6代替ReLU函数,ReLU6能够增强模型的稳定性,整个结构中,特征图在一系列处理后其大小维度都不会改变,所以能够单独使用在任意卷积网络中,实现网络轻量化。

图2 倒残差网络结构图
其中,经过第一个1×1卷积后使用ReLU6激活函数,经过3×3卷积后,使用ReLU6激活函数,最后降维得到的特征图使用线性激活函数。
MobileNetV2网络应用在SSD中如图3,此方法结合了MobileNetV2网络对模型计算量减少的优点以及SSD算法本身对目标检测速度块以及精确度高的优点,使得这个新的目标检测模型在移动设备的嵌入式设备中得到高效率以及高精度的效果。这个模型使用了以MobileNetV2为特征提取网络,SSD多尺度检测方法来进行对不同大小物体的检测,使用了五种不同尺度的特征图,分别为19×19、10×10、5×5、3×3、1×1,这五个尺度特征图生成不同大小比例的候选框进行预测回归,最后通过NMS去除无用候选框,得到最终结果。

图3 MobileNetV2网络应用于SSD算法的模型结构图
3.3 自适应非极大值抑制方法-Adaptive NMS
根据画面目标识别出来的多个候选框出现重叠时,通过候选框的IOU值,排除其它重叠框,留下极大值的候选框。针对公共场所内,人流量密集稀疏程度带来目标检测效率低,容易出现人物重叠等问题,本文使用了一种判断目标密集和稀疏情况的自适应非极大值抑制方法(Adaptive NMS),它在soft-NMS基础上加了一个目标密度预测,其公式如下:

(10)
:=max(,)
(11)

(12)
其中函数是一个的函数,会随着的变化来增大减小分数,即当与的值大于时,=1-或者=(-),为-中的抑制阈值,是的目标密度。该方法将抑制策略法分为三类情况讨论:
第一种是当相邻的框远离目标时,使用;第二种,当位于密集区域时,则使用-,会被保留;第三种,当位于稀疏区域时,=(是一个更高的阈值)。
该方法相较于NMS与soft-NMS,其对于不同行人密度情况下,能够自动改变阈值大小,其效率更高。
4 实验与结果分析
4.1 实验环境
本文算法的具体实验使用的是深度学习框架PyTorch,实验环境为Ubuntu16.04操作系统,使用NVIDIA 1080Ti图像处理器(GPU)运算。本文使用Caltech行人数据集进行训练和评估。该数据集大约拍摄10个小时,分辨率为640×480,标注了大约250000帧,其中约120000帧图像包含行人,350000个矩形框,2300个行人。本文选取Caltech数据集中set00-set05中的2000帧图像作为训练集。将训练好的网络在VOC2007的数据集上进行测试。
4.2 评价标准
由于应用的侧重点不同,目标检测算法的评估标准也有很多,本文使用精度检测,检测效率和模型大小对本文模型进行评估。采用mAP(mean average precision)来评估模型在行人目标检测上性能的好坏,使用每秒检测帧数FPS(frames per second)来评估检测效率,使用MB(MByte)来评估模型的大小。通过实验证明测试模型的各个性能。
4.3 实验结果与分析
为了验证本文算法的有效性,在真实场景中进行检测实验。实验结果如图4所示,在复杂的室内场景中,能够对行人进行精确的检测,不会出现重复检测导致检测框重叠的情况。

图4 行人检测
1)本节通过改变输入图像的尺度,评估检测精度,检测效率和模型的大小。如表1所示,改变输入图像的尺度对检测精度,检测效率的影响几乎没有;而提高输入图像的分辨率可以有效的提高网络的检测精度,其原因是因为随着分辨率的增加,行人目标在图像中的尺寸也随之增加,提高了网络的检测精度。
2)为了与现在其它流行的目标检测网络做对比,证实实验方法的有效性。本节在VOC2007测试数据集上对模型进行评估。其中Tiny SSD和Tiny YOLO是目前最流行的两种轻量级目标检测网络。

表1 不同输入尺度下的网络实验结果
实验对比结果如表2所示。本文所提出的网络结构SSD+MobileNetV2相比于传统的目标检测方法,在模型大小方面明显优于这两种方法,更能适用于嵌入式的系统中。目标检测的进度方面达到了71.8%,明显优于Tiny YOLO和Tiny SSD这这种轻量化的网络模型,在模型大小上,本文提出的算法小于Tiny YOLO,Tiny SSD算法虽然模型参数更小,但是检测精度方面较低。权衡目标检测的评估标准,本文提出的网络结构SSD+MobileNetV2的性能最好。

表2 不同检测网络精度模型对比
5 结论
本文针对嵌入式场景内的行人检测的遮挡,存在障碍物和人流密度不同的问题,提出了一种基于SSD的目标检测算法,实现了基于深度学习的轻量化目标检测模型。以MobileNetV2为基础的网络,实现了网络模型的轻量化。通过引入自适应极大值抑制方法,针对场景中不同行人密度,自动改变阈值大小,其网络的检测效率更高。
实验表明本文提出的轻量化行人检测网络在Caltech数据集上的训练结果在各项评估指标中表现更为优秀,与其它的轻量化网络模型相比,在检测的精确性都更加优秀。在未来的工作中将会在嵌入式的机器人方面进行进一步的实时测试。
