基于多任务训练的用户登入语音识别模型仿真
2022-10-25江官星
江官星,付 悦
(南昌航空大学科技学院,江西 南昌 332020)
1 引言
语音交流已经成为当下较为流行的沟通方式,语音化服务目前已经广泛应用于智能家居系统、电话拨号、智能查询服务等领域。语音识别任务是将语音信号输入语音特征识别模型并完成语音的训练分类,依据一定标准输出所需信息。在智能家居用户登录语音识别中,通常存在语音信号噪声干扰大、语音信号波动较大问题时,语音识别技术的适应性仍不够理想。
因此用户登入语音识别也逐渐成为相关学者的重点研究课题。如于重重等人研究了基于动态BLSTM的语音识别方法。该方法通过端到端语音识别模型实现识别,但其模型构建过程过于复杂,导致语音识别效率低;李业良等人提出了基于混合式注意力机制的语音识别方法,该方法通过平均池化识别语音特征,但该方法存在泛化误差,直接影响语音识别效果。
为解决以上方法存在的弊端,将多任务训练方法应用在语音识别中,提出基于多任务训练的用户登入语音识别模型,提高任务学习效果和用户登入语音识别的效率。多任务训练是结合多个任务目标共同建模训练学习的方法,能够增强模型的泛化性能,即对多个任务的目标一起联合建模并训练。
2 基于多任务训练的用户登入语音识别模型
2.1 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)具备较好的网络数据处理能力,在语音识别方面发挥重要作用。针对连续语音信号识别,通过构建输出全反馈模型实现识别,RNN网络结构包括输出层与输入层,RNN训练过程中将I层引入输入层,可解决语音数据量导致的训练样本长度过长以及初始反馈不及时引起训练样本的误差等问题。设置I层各神经元与输出恒定为1的神经元彼此相连,则输出值等于两个神经元相连权值。通过权值可纠正误差向量,提高该网络训练性能。
选取时间的反向传播算法设定为RNN网络训练算法,该算法依据时间将网络展开为拥有共享权值的网络,为得出L层初始反馈信号需要添加I层实现,针对输入输出序列的长度为N,RNN网络训练图见图1。
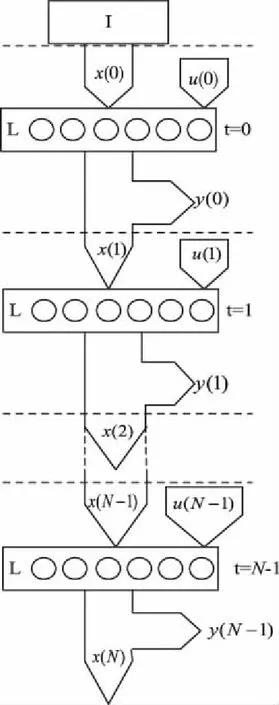
图1 RNN网络训练图
由图1可知,RNN网络训练流程如下:
Step 1:设置第一个输入为(0),层输出的初始状态用(0)描述,通过向前传播求解出(1)与(0)。
Step 2:设置反馈向量为(),将其作为前时刻状态输出,当>0,当前时刻的输入为(),通过向前传播求解出输出向量()与(+1)。训练公式如式(1)~式(2)所示
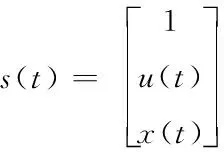
(1)
(+1)=(())
(2)

为得到最后1帧信号输入=-1,需要循环每个时间值输出。
Step 3:最后1个时间输出误差向量用(-1)描述,为计算(-1)需要比较目标函数取值与输出目标值,把误差反传到(-1),其过程如式(3)所示
(-1)=
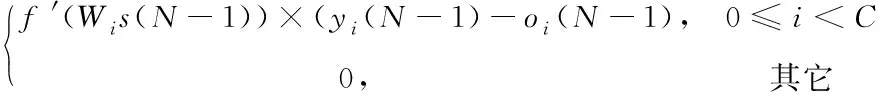
(3)
式中:()为目标值,为待识别种类用。
Step 4:针对全部0≤≤-2,为求解输出向量()误差向量,需要与目标输出进行比较,同时加载+1反向传播,再通过反向传播求解()误差向量,其过程如式(4)所示
()=
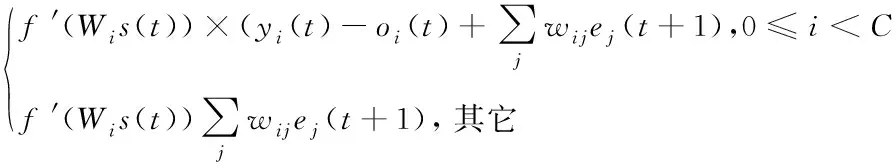
(4)
Step 5:当时刻为零时,将误差层反向传播至层,其过程如式(5)所示
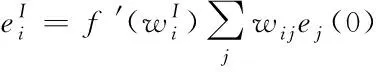
(5)
Step 6:为求解目标函数对权值梯度,通过累加全部时间值,再更新权值,其过程如式(6)~式(7)所示

(6)
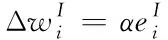
(7)
2.2 多任务学习
为提高神经网络泛化性能,通过将多任务学习()应用在神经网络中,采用共享并行训练多任务完成多任务学习,通过共享隐层学习的方式获取更多共享特征,并挖掘相关任务的隐含特性。
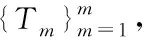

(8)
式中:内的一列为模型向量,模型参数矩阵即为多任务模型参数。
2.3 基于MTL-RNN的语音识别
构建基于MTL-RNN的语音识别模型,通过RNN处理用户登入连贯语音信息,融合多任务学习结构,通过用户身份、情感和性别识别实现语音分类,该算法流程见图2。

图2 MTL-RNN算法流程
由图2可知,语音输入后进行数据预处理并提取特征。该操作先通过检测器过滤测试语音内无用静音数据;然后分帧处理语音信号,语音信号的帧叠和帧长分别是256点、512节点;再将各帧与汉明窗相乘,同时进行傅立叶变换,为求解13阶梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)利用mel滤波器组实现求解;最后得出MFCC特征帧能量、13维MFCC的1、2阶差分。在共享层包括3层RNN,依据时间先后,输入MFCC特征向量,并均匀分布各层节点。第3层接收前2层输出数据后转换为输入至由3个全连接层构成属性依赖层中,并将结果发送至softmax输出层,得出3个任务的分类识别结果。在训练过程中,需要将神经网络中分批输入训练集进行训练,求解计算损失函数,并通过优化器对该函数优化,在网络权重更新前提下,进行下步训练。
损失函数为交叉熵函数,总损失函数如式(9)所示
=++
(9)
式中:损失函数包括性别识别用loss描述;说话人识别用loss描述。权重系数分别用χ、δ、γ描述;语音情感识别用loss描述;通过式(9)计算得出式(10)

(10)
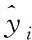
算法测试过程与训练过程流程一致。
3 实验分析
仿真数据为TIMIT声学-音素连续语音语料库的数据集,实验数据集包括650名说话人,其中每个人说10个句子。在数据集内测试集与训练集的比例3:7。
为了验证本文模型的识别性能,选取音素识别错误率作为评价指标,因错误率与识别率呈反比关系。实验设置:学习率为0.01、隐含层节点数量为130个、epoch的数量为19、批量处理次数分别是17次和34次时,测试本文模型的识别错误率,结果见图3,图中epoch指全部训练样本训练一次的过程。

图3 本文模型在不同批量处理次数时的识别错误率
由图3可知,在批量处理次数是17时,两个实验数据集识别错误率曲线呈平稳态势,且识别错误率在0.4上下浮动;而在批量处理次数是34时,两个实验数据集在epoch为15时,识别错误率开始出现波动,说明在批量处理次数为17时,本文模型语音识别效果最好。
考虑错误率受学习率因素的影响,实验设置:批量处理次数是17、隐含层节点数量是110个、epoch数量是19时,测试本文模型在不同学习率下的识别错误率,结果见图4。
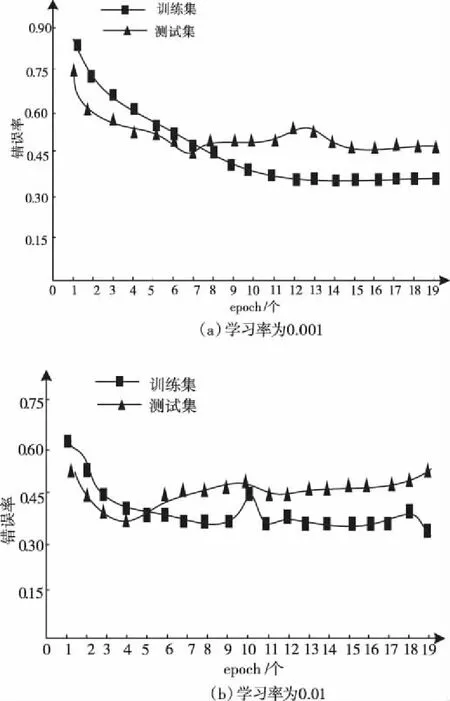
图4 学习率对错误率的影响
由图4可知,当学习率为0.01时,本文模型识别错误率较高,且存在显著波动,说明学习率对模型识别错误率影响表现为:损失变化随学习率高低影响较大,学习率越低,两个实验数据集错误率曲线越趋于稳定态势。
考虑错误率受隐含层节点的影响,实验设置:批处理数量为34个、学习率为0.01,epoch的数量为15,在隐含层节点分别为130个、260个时,测试本文模型的识别错误率,见图5。
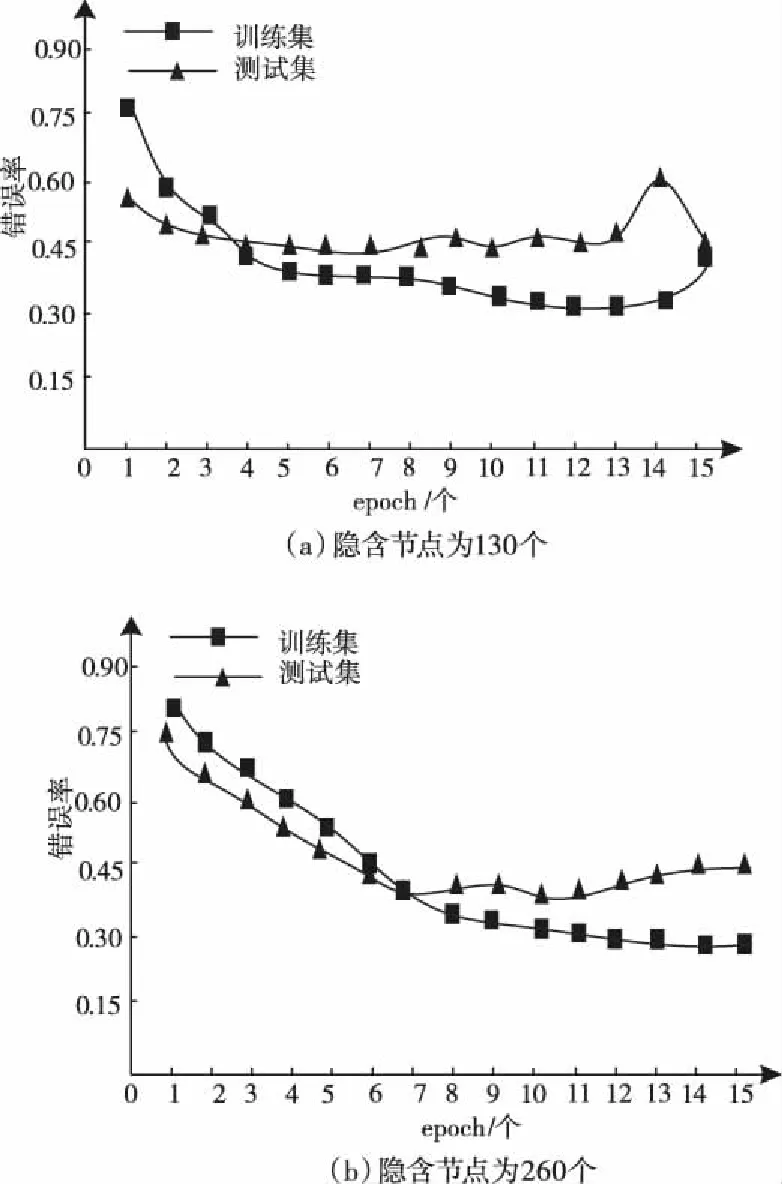
图5 隐含层节点数量对识别错误率的影响
由图5可知,隐含层节点数量是130时,两个实验数据集的错误率差别较大,其中因过拟合导致训练集错误率不高,在隐含层节点数量是260时,两个实验数据集的错误率差别不大,收敛性能较好。因此隐含节点数量为260时模型的识别效果较好。
在实验数据集中选取4个数据集作为4个任务,并且任务间存在关联性。将其中数据集1作为主要任务,剩余3个为辅助任务。实验权重系数初始值分别为0.6,0.2,0.2时进行网络训练,调整权重值进行测试,得出本文模型最佳权重系数χ、δ、γ的值分别为0.5,0.16,0.34。
在不同训练集下,得出本文模型的损失函数值和迭代次数关系图,如图6所示。
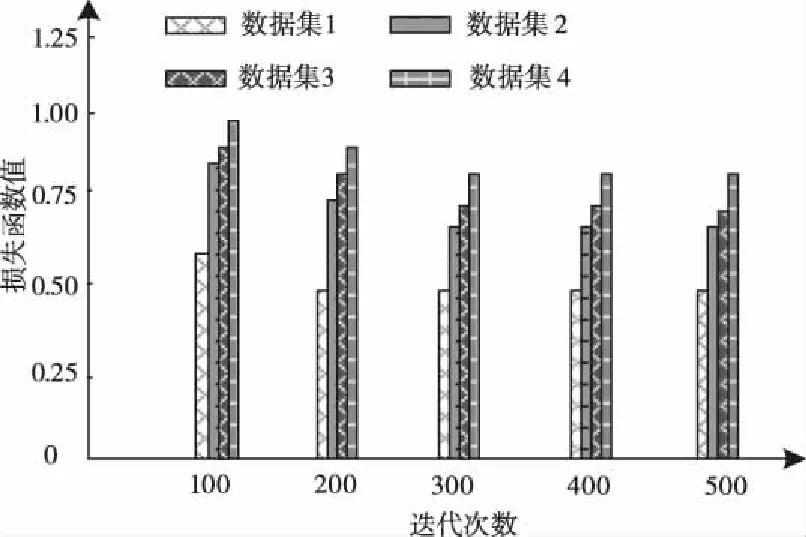
图6 本文模型的损失函数-迭代关系
由图6可知,因数据集1为多任务中的主要任务,本文模型在迭代次数200次就达到收敛,且损失函数值较低,而其余3个数据集作为辅助任务在迭代次数300次均达到收敛,说明本文模型的训练能力和应用性较强,可快速实现多任务分类的语音识别。
为了评价本文模型在用户登入语音情感识别中的应用的性能,将非加权平均召回率UAR作为评价指标,UAR求解如式(11)所示。

(11)
其中:召回率用描述;正类数用描述;类别数用描述;负类数用描述。
将数据集1中设置语言种类识别是辅助任务,情感维度属性的A与B识别设置为主任务,其中A代表登入用户开心情感语音,B代表登入用户悲伤情感语音,在没有引入多任务学习之前的任务A的平均识别UAR值为55%,任务B的平均识别UAR值为63%,通过仿真测试得出本文模型的UAR值,如表1所示。
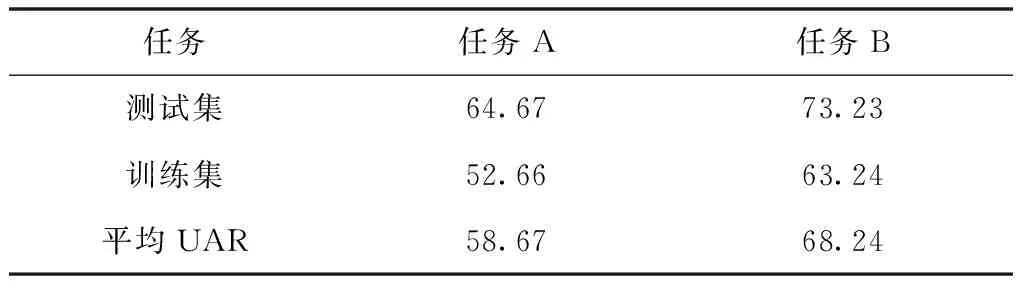
表1 本文模型的UAR值(%)
通过分析表1可知,本文模型对任务A的平均识别UAR值为68.24%;任务B的平均识别UAR值为58.67%,相比没有引入多任务学习的任务A、B平均UAR值分别提高3.67%、5.24%。因此,引入多任务学习的本文模型可增强语音情感识别的泛化能力,提高情感识别精度。
4 结论
针对以往用户登入语音识别方法局限性,导致对多语言的识别效果不佳等问题,研究基于多任务训练的用户登入语音识别模型。通过将循环神经网络与多任务学习算法相结合构建多任务训练的用户登入语音识别模型,增强识别泛化能力。通过仿真可知,当学习率为0.001,批量处理次数是17,epoch数量为19个,隐含层节点数量为260时,两个实验数据集的收敛性能优良,识别错误率曲线比较平稳,说明本文模型可提高语音识别正确率。
因本人时间与精力有限,文中仍有不足,希望在以后的实践中逐步完善,下一步有待改进的方向如下:
1)本文仿真中所使用的数据集,均经过降噪处理后的语音数据,但现实中语音数据都会掺杂着少许噪音,因此本文模型应添加一些先进的方法,例如小波降噪方法在语音识别之前进行降噪工作,提高本文模型的实际应用效果与识别精度。
2)在用户登入语音识别中语种的识别也比较重要,本文研究并未涉及,以后会加强对语音信道对语种识别影响方面的研究,扩大本文模型研究范围。
3)将本文模型应用在语音识别系统中,通过识别系统的开发,进一步提高用户登入语音识别效率,有利于用户登入的管理工作顺利进行。
4)提高与本文模型相匹配的模型,语音信号波动比较大,在语音信号分析中对特征提取方面不太理想,因此在本文模型的基础上加入与之匹配语音信号分析的模型,能够更好地提高户登入语音识别的效果。
