基于图数据库的阅读行为知识图谱构建研究
2022-10-24陈光仪陈义明吴小慧
陈光仪,陈义明,吴小慧
(湖南农业大学信息与智能科学技术学院,长沙 410128)
0 引言
语义网络作为人工智能的重要应用领域之一,可以给用户提供一个更加准确、更加智能的知识获取环境。而知识图谱是实现语义网络的技术基础,是通向语义网络环境的鲜明道路。在智慧学习的大环境下,叠加近年来新冠疫情的防控需求,在线阅读已越来越多地成为广大读者的首选阅读方式。如果能够有效获取读者的阅读行为并构建对应的知识图谱,对于图书馆而言,可以及时了解其在阅读过程中的实际需求,继而进行针对性的阅读指导并为读者推荐个性化的阅读内容;对于出版商而言,可以及时调整、改进电子出版物的内容编排及后续再版工作,以更好地适应目标读者群体的实际需求。因而,此项研究工作对于进一步提升读者的阅读学习效果,完善图书馆的智慧化阅读服务,推动促进全社会形成良好的智慧学习环境大有裨益。
1 知识图谱构建技术
构建知识图谱有自顶向下和自底向上两种方式。前者通常是指基于百科类网站等高质量的结构化数据源,从中提取本体和模式信息后再加入到知识库中,因而适用于那些内容明确、关系清晰的领域知识图谱构建;而后者是指通过借助特定的技术手段从公开采集的数据中提取模式信息,选择其中置信度较高的新模式,经人工审核后再加入到知识库中。目前大部分知识图谱的构建都采用自底向上的方式,其层次架构按照知识获取的过程可分为信息抽取、知识融合和知识加工。
信息抽取是指从多源异构的数据源中提取出实体、属性以及实体之间的关系,在此基础上形成本体化的知识表达,它是知识图谱构建技术的关键。早期信息抽取主要是基于预定规则的抽取技术,工作量庞大且仅适用于特定的专业领域,后来人们开始尝试使用统计机器学习的方法,通过标注部分数据得到训练集,在此基础上再使用均方根误差算法(root mean squared error,RMSE)或多项式回归算法(polynomial regression,PR)等有监督学习算法识别命名实体。
从开放领域中抽取信息所得到的结果,可能具有较高的数据冗余度且包含大量错误内容,数据内在的层次性和逻辑性也缺失严重,这就需要通过有效的知识融合技术来清洗并整合数据,主要工作包括实体对齐和知识合并等。
经过融合处理后,所得到的数据、信息或事实表达还必须经过进一步的知识加工才能形成最终结构化、网络化的知识体系。此过程中涉及的主要技术包括本体构建、知识推理和质量评估。
上述层次架构可用图1所示的模型来表示。
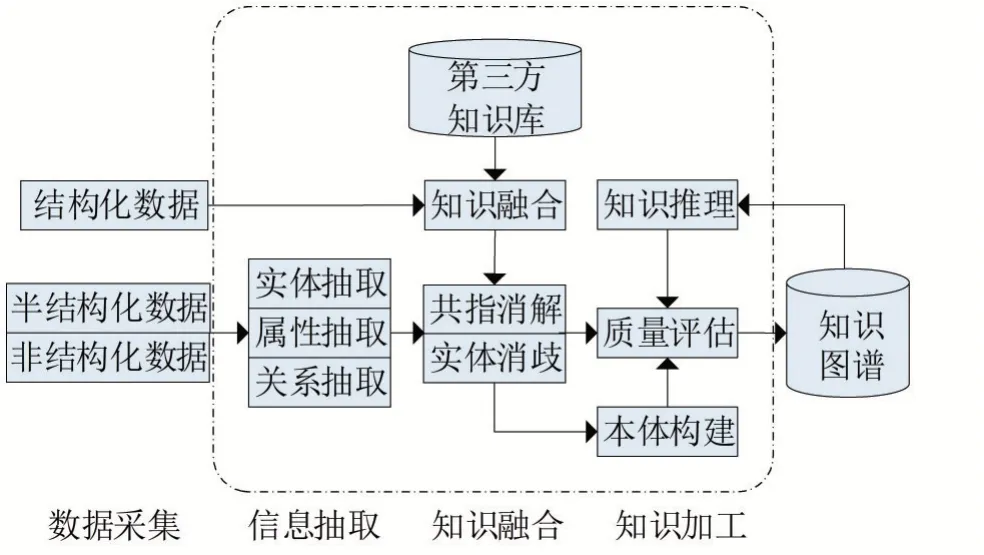
图1 自底向上构建知识图谱的层次架构
2 阅读行为知识图谱构建
就本文所研究的读者阅读行为知识图谱构建而言,采用自底向上的方法更为合适。这种方法将知识图谱的构建过程分为四步:知识获取、知识表示、知识存储和知识可视化错误!未找到引用源。。
结合项目的实际需求,本文设计出阅读行为知识图谱构建系统的实现流程如下:首先从存档的电子出版物中抽取出读者的阅读行为数据,然后对数据进行清洗并进行格式调整,再将数据加载到图数据库中,创建知识节点及节点之间的关系以得到完整的知识图谱,最后使用图数据库操纵语言对知识进行查询推理,并将结果可视化地呈现在页面上。完整流程如图2所示。

图2 阅读行为知识图谱构建流程
2.1 知识获取
构建知识图谱的首要任务是获取知识。从各种类型的数据源中提取出实体(概念)、属性以及实体之间的相互关系,在此基础上形成本体化的知识表达。
本文构建阅读行为知识图谱所需的数据主要来源于读者在阅读过程中所生成的各种标注和注释信息,这是一种简明且方便获取的、用以了解读者阅读行为的数据。读者在阅读电子出版物的过程中,会随手在文档中添加一些附注、标记和注释信息,这些信息真实准确地反映了读者个人的阅读习惯,及其对所阅读内容的认识、理解和掌握程度。为保证数据来源的随机性和真实性,本文收集整理了数十位学生读者在阅读不同类型电子出版物后所形成的文档材料,编写程序自动提取出其中所包含的读者阅读行为数据。部分原始数据如图3所示。

图3 阅读行为原始数据局部
2.2 知识表示
自动提取的原始数据中往往会包含一些信息噪音。因而本文设计了专门的数据清
洗程序以去除其中的噪音,然后再将数据格式化为知识表示的形式。具体过程为:
(1)首次清洗。构造如下正则表达式,对抽取的数据进行完整清洗,去除价值密度低的数据,保留重要的标记注释文本、生成时间和创建位置等内容。
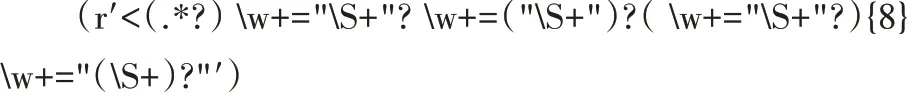
(2)再次清洗。将元组转换为列表数据,构造正则表达式,采用循环扫描的方式对数据进行再次清洗。其中的少部分数据可能发生错置现象,需要抽取相应数据并重载至正确位置。
(3)格式化数据。构造正则表达式,整理清洗后的数据,对它们进行适当的切分和合并,最后将所有数据格式化为知识表示的形式。
2.3 知识存储
关系型数据库在结构化数据的存储和处理方面拥有绝对优势,但对知识存储及语义检索的支持却不够友好。而以图论为基础的图数据库在这些方面却恰好拥有与生俱来的长处,尤其在保持数据语义及处理复杂关系等方面,图数据库明显优于关系型数据库。目前在学术研究和商业领域,主要的图数据库产品包括ArangoDB、FlockDB和Neo4j等。根 据DBEngine排名,其中最为活跃的当属开源产品Neo4j,它不仅支持严格的事务处理,还提供强大的图搜索能力和极好的横向扩展能力。
本文通过编写程序,实现了将格式化后的读者阅读行为数据自动加载到Neo4j图数据库中的功能。程序能根据格式化数据的结构创建相应节点,添加属性并标注关系,自动完成知识图谱的存储和构建。
2.4 知识可视化
Neo4j数据库支持强大的图操纵语言Cypher,可以快捷高效地实现知识图谱的查询和推理。在配置好所需模块后,调用浏览器打开图数据库,输入相应Cypher命令便能查询所需内容并将结果可视化呈现在页面上。本文所创建的读者阅读行为知识图谱的部分查询结果如图4所示。

图4 读者阅读行为知识图谱局部
3 结语
本文介绍了读者阅读行为知识图谱的完整构建过程,设计并实现了一个自动化的开放知识图谱构建系统。测试结果表明:本文所得成果能正确高效地实现对读者阅读行为数据的自动提取、清洗、筛选和格式化,并能在此基础上将融合后的数据表达为知识再存储到图数据库中。后续研究工作重点在于:一方面对获取的阅读行为数据和读者阅读习惯、阅读情感之间的关联性进行深入研究;另一方面对如何将所构建的知识图谱用于帮助图书馆提供更好的智慧阅读服务进行分析。作者将从这两个方面着手,扎实开展后期的理论研究和实践创新工作,以期取得更有价值的成果,为推动全社会形成良好的智慧学习环境添砖加瓦。
