基于改进的YOLOv3算法研究
2022-10-24李艳武
刘 博,李艳武
(重庆三峡学院电子与信息工程学院,重庆 404100)
0 引言
近年来,随着人工智能技术的发展,这项技术已被应用到无人驾驶、智能家居、智能监控、医疗系统等领域中。类似无人驾驶、智能监控等技术一定需要通过计算机获取图像,再进行后续判断。目标检测技术作为人工智能领域中的重要分支,其目的是让机器能够获取环境中重要的信息图像。目前,目标检测技术分为两类:传统目标检测算法和基于深度学习的目标检测算法。
传统目标检测算法主要包括Haar特征+Adaboost算法等。基于深度学习的目标检测算法主要是利用卷积运算构建卷积神经网络对图像进行特征提取,能够提取到图像更深层的特征和语义信息。基于深度学习的目标检测算法又可分为一阶目标检测算法和二阶目标检测算法。其中一阶目标检测算法包括YOLOv1、SSD、YOLOv2、YOLOv3等。二阶目标检测算法有R-CNN、Fast R-CNN、SPP-Net等。这两大类算法中,一阶目标检测算法速度快,但精度低;二阶目标检测算法则精度高、但速度慢。
为了进一步提升YOLOv3算法的性能,本文将网络中的LeankyReLU函数改成Swish、Mish激活函数,然后采用Giou、Ciou损失函数优化算法的边框回归方式,采用Focal loss优化算法的分类损失,利用K-means算法对数据集进行重新聚类得到新的锚框。训练时采用数据增强方法扩大训练的数据量,通过对图片进行缩放及长和宽的扭曲、色域扭曲、翻转图片等操作,增强网络的鲁棒性。另外采用了冻结网络参数的训练方法,此方法是在网络训练的前一半时间对网络中的特征提取网络部分不进行参数更新,后一半时间才会对整个网络进行参数更新。
1 YOLOv3算法介绍
YOLOv3算法是在YOLOv1和YOLOv2的基础上进行改进的,同样也是一阶目标检测算法,直接生成预测结果。YOLOv3的特征提取网络是将YOLOv2中的Darknet-19与残差结构结合提出的Darknet-53,使得网络能够达到更深的层次。Darknet-53中没有使用池化层而是由1×1和3×3的卷积层组成,通过1×1的卷积压缩网络。同时还加入了BN层,主要是为了缓解网络的过拟合问题。网络的颈部分,借鉴特征金字塔网络结构(FPN)实现三个不同尺度的预测。网络的损失函数有四部分,矩形框中心点损失、预测框宽高损失、置信度损失和类别损失。预测框中心点损失和宽高损失均采用了平方差损失,置信度损失和类别损失则是采用了交叉熵损失计算方式。
2 改进的YOLOv3算法
2.1 激活函数
YOLOv3算法的激活函数为LeakyReLU激活函数,其是在ReLU的基础加入了一个很小的负值,无法为正负输入值提供一致的关系预测。因此针对激活函数,本文采用Swish、Mish激活函数分别对算法进行改进。Swish函数是一种自门控激活函数,定义为:

式中,为一个正值,当很大时,()就接近于1。此时激活函数处于“开”状态,函数值近似于本身,克服了函数饱和的问题;当()接近0时,激活函数处于“关”状态,且函数值近似为0。Mish函数的表达式为:

当→∞时,函数值都不存在饱和的情况;<0时还有轻微的负值,不会导致神经元失活,理论上有更好的梯度流。经过学者们的实验,Mish函数在训练稳定性、平均准确率等方面都有了全面的提升。将上述两个激活函数用在YOLOv3模型上,代替原有激活函数来研究算法的性能,以及三种激活函数的性能差异。
2.2 位置回归损失
在YOLOv3算法中,对目标位置计算回归损失是对中心位置偏移量和框的宽高分别计算损失,且都采用均方差损失。这种回归方式没有把anchor当成一个整体,忽略了其他的影响因素。2016年旷视科技提出了计算真实框和预测框的IOU值作为损失函数,不再对坐标和宽高进行独立预测,而是作为一个整体,使预测结果更加准确。但IOU Loss也有不足之处:一是预测框和真实框之间IOU值为0时,不但无法反映两个框的距离,而且无法进行优化;二是IOU无法精确反映两个框的重合度大小。
2019年,斯坦福大学提出了Giou损失函数,相比于IOU新加入了一个包含真实框和预测框的最小的矩形框C。Giou损失函数公式如下:

Giou同样存在缺点,当真实框和预测框属于包含关系时,Giou就成了,依然无法区分两个框的相对位置。对于垂直方向上的样本,误差很大,基本很难收敛。
针对上述问题,Ciou将Giou中引入的包含预测框和真实框的最小矩形框的面积惩罚项修改成直接计算两个框中心的距离,以此来加速收敛,同时还考虑了Boundingbox的纵横比,进一步提升了回归精度。Ciou损失函数的公式为:
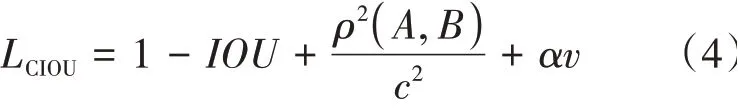


图1 Ciou原理图
针对YOLOv3定位不准确的问题,本文采用Giou、Ciou损失函数作为边框回归损失,研究三种损失计算方式的差异性,同时也研究算法的性能提升。
2.3 分类损失
YOLOv3的分类损失是用交叉熵损失函数来计算的,现改用Focal loss计算分类损失。Focal loss的提出是为了解决一阶目标检测中类别不平衡的问题。主要包含两个方面:一是正负样本不平衡的问题;二是难分类样本和易分类样本不平衡的问题。一张图片中,真实目标的数量远远大于负样本数量,负样本占总损失的大部分,同样易分类样本也占据了样本的大部分,这些样本容易主导模型的优化方向,导致模型分类能力下降。
Focal loss是在交叉熵损失的基础上通过引入和两个参数来控制不同样本的权重,公式如下:
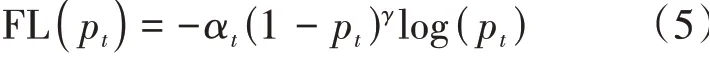
式中α为权重系数,主要用来平衡正负样本的数量比例不均程度;(1-p)为调制系数,通过减少易分类样本的权重来使得模型更加关注于难分类的样本。
2.4 K-means的锚框聚类
在YOLOv3算法中,锚框的大小需要预先设定,而且锚框的设定会直接影响到检测精度。为了能得到一组合理的锚框大小就需要用到K-means聚类算法,其是一种无监督的聚类算法,目的是将相似的框分为一类。使用K-means时,首先获取训练集的标签真实框的大小,然后随机选取个不重复的框,采用IOU指标来对锚框进行聚类。具体流程如下:
(1)在所有真实框中随机挑选个作为簇心;
(2)计算每个真实框与每个簇之间的1-值;
(3)计算每个真实框距离最近的簇心,并分配到最近的簇中;
(4)重新计算每个簇中的簇心;
(5)重复上述操作,直到每个簇中的元素不再改变。
针对YOLOv3算法的多尺度检测特性,需要设置9个锚框大小。首先按照上述步骤得到锚框,然后再引入遗传算法对得到的锚框进行变异,并得到最终的结果为:[17,19],[22,52],[50,39],[47,97],[94,81],[95,164],[225,124],[163,230],[324,254]。
3 实验设置
实验是在Pascal VOC数据集上进行的,采用数据增强以及冻结参数训练,1到50轮冻结特征提取网络参数,不进行权值更新,学习率设置为1e-3,batch_size设置为16;50到100轮不冻结特征提取网络的参数,学习率设置为1e-4,batch_size设置为8。优化器采用Adam,权重衰减设置为5e-4。学习率调整方式为StepLR,调节步长设置为1,调整倍数设置为0.94。实验中首先将LeakyRelu激活函数和原损失函数的YOLOv3算法作为基础实验,研究激活函数Mish、Swish和损失函数Giou、Ciou对算法带来的影响,根据对比实验结果找出最优的激活函数和损失函数,再优化算法中的分类损失以及引入经过K-means聚类后的锚框,并得到最终的优化结果。
4 实验结果分析
对于样本分类的情况一共有4种:一是正样本,被分类到正样本的为True Positive,简称TP;二是正样本,被分类到负样本的为False Positive,简称FN;三是负样本,被分类到正样本的为False Positive,简称FP;四是负样本,被分类到负样本的为True Positive,简称TN。评判模型的好坏有两个常见的指标,精确率()和召回率()。利用精确率和召回率可以画出Precision-Recall曲线。P-R曲线下的面积即为平均精确度(),简称AP。值越大,其分类效果越好。是对多个类别的求平均值。
表1为改变了激活函数和损失函数得到的优化结果。在采用相同损失函数的情况下,激活函数为Swish和Mish时,算法的损失都下降了0.1左右,激活函数为Swish时,算法精度有小幅度的提升,当使用Mish函数时,算法的精度能提升0.6%左右,明显优于Swish函数。将Giou和Ciou作为边框回归函数可以降低平均2.76的损失,对于损失的优化明显,且Giou和Ciou对损失的优化程度都是一样的,对于精度而言,Giou能够提升0.2%左右,Ciou能够提升0.6%左右。最终在使用Ciou和Mish的情况下能够达到78.67%,提升了1.2%。
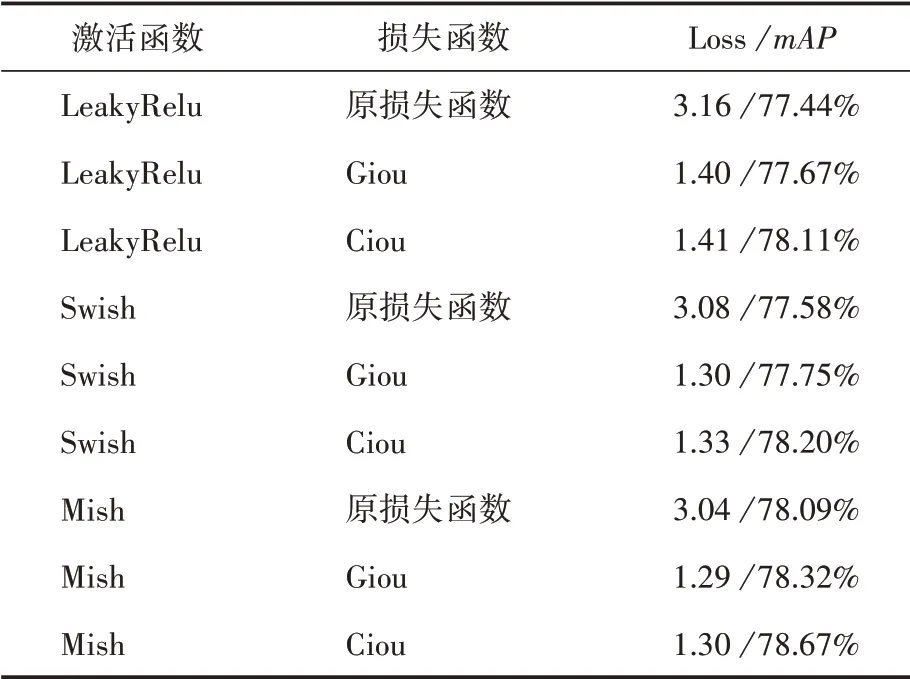
表1 改变激活函数和损失函数的实验结果
表2为采用经过-means聚类后的锚框的结果,本文一共做了两组对比实验,从两组数据可以看出,使用针对数据集合理的锚框会对算法的精度带来一定的提升。

表2 使用K-means聚类锚框结果
表3为融入Focal loss之后的实验结果,融入Focal loss能给算法带来0.92%的精度提升,提升比较明显,可见Focal loss对于解决样本不平衡问题的有效性。

表3 使用Focal loss实验结果
5 结语
本文针对YOLOv3模型精度不够的问题展开了研究,首先是研究激活函数和损失函数,分别采用Swish和Mish函数对激活函数进行改进,模型的精度获得了不错的提升,同时也体现这两种激活函数的性能差异。损失函数中的边框损失函数采用了Giou和Ciou分别进行优化,使得模型能够对目标进行更好的定位。为了解决训练过程中样本的不平衡的问题,还使用了Focal loss函数来优化分类损失,并采用K-means算法重新对训练集的锚框进行聚类。在训练时,采用数据增强和冻结特征提取网络的方法,最终在Pascal VOC数据集上的测试结果最高能够达到79.63%,相比于原来的精度提升了2.19%。
