机器学习在心肌梗塞并发症中的预测研究
2022-10-24李先杰
王 蔚,程 君,李先杰,彭 雷
(自贡市第一人民医院信息科,自贡 643000)
0 引言
根据2021年7月发布的《中国心血管健康与疾病报告2020》,我国城乡居民总死亡原因当中,心血管疾病死亡居于首位,高于肿瘤及其他疾病。心肌梗塞(myocardial infarction,MI)作为一种常见的心血管疾病,严重威胁人们的生命健康,从2005年开始,其死亡率呈快速上升趋势。心肌梗塞患者的不同病程,可能不存在并发症或者存在并发症但不会严重威胁生命。与此同时,大约一半的急性和亚急性期心肌梗塞患者有并发症,如心力衰竭、心脏破裂、心房纤颤等,其致死率及致残率仍然较高。因此,提前预测心肌梗塞患者未来可能发生的并发症类型,能够有效辅助临床医务人员实施必要的预防措施,也是降低心肌梗塞患者死亡率的重要途径。
1 相关研究
近年来,大数据、人工智能等技术的快速发展为疾病的诊断和预测提供了强大的技术支持,并表现出较好的应用效果,例如糖尿病早期预测、糖尿病并发症预测、脊柱手术并发症预测、脑肿瘤分类等。
目前,心肌梗塞患者的并发症研究主要集中于评价心肌梗塞并发症与影响因子之间的关系,通过观察影响因子来达到预测心肌梗塞并发症的目的。黄佐贵等采用免疫比浊法测定51例心肌梗塞患者组和40例冠心病对照组的高敏C反应蛋白水平来预测心肌梗塞并发心力衰竭死亡率,实验结果表明高敏C反应蛋白可作为预测心肌梗塞患者一年内总死亡率和心力衰竭死亡率的一项重要指标。宗敏等采用统计学方法中的多因素logistic回归分析来探讨血小板分布宽度对老年人心肌梗塞患者住院期间心力衰竭的预测价值。实验结果表明血小板分布宽度对MI后心衰有独立预测价值,具有较高的敏感性,可作为评价MI后心衰的独立危险因素。Azwari使用机器学习算法中的随机森林模型来预测心肌梗塞患者发生心肌破裂并发症的可能性,该模型以患者的年龄、性别、病死中的心肌梗塞次数、病史中的劳力性心绞痛、高血压等作为模型的输入特征,实验结果表明该模型具有较好的预测效果。由于心肌梗塞的并发症不同,其影响因子也不同,想要利用影响因子来对心肌梗塞并发症的总体分类进行预测,将会变得十分困难。基于此,本文通过患者的既往病史,入院时体征记录以及入院三天的治疗措施来构建多层感知机(multilayer perceptron,MLP)和支持向量机(support vector machine,SVM)两种心肌梗塞并发症预测模型,为临床医务人员早期判别心肌梗塞患者发生并发症提供风险预警。
2 模型与方法
2.1 多层感知机模型
感知机作为神经网络和支持向量机的起源算法,最初用于处理简单的二元分类线性可分问题,即能获得一个将训练数据集正实例点和负实例点完全正确分开的分离超平面,却无法构造非线性可分数据集的超平面。多层感知机,也称为多层神经网络,是在单层神经网络的基础上引入了一个到多个隐藏层,并使用非线性激活函数来克服线性模型的限制,提升非线性数据处理能力,其基本结构如图1所示。
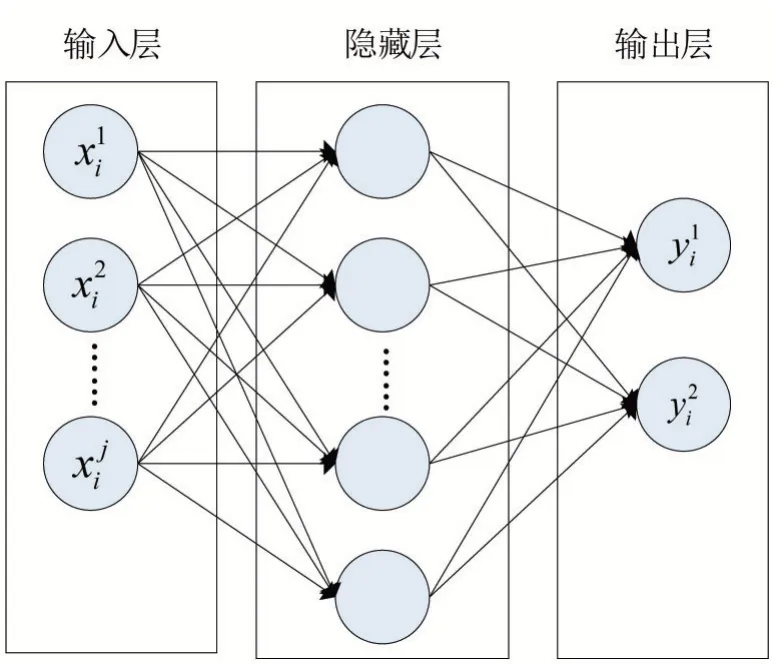
图1 多层感知机模型
由图1可知,MLP是由一个输入层,一个输出层以及若干个隐藏层构成。输入层负责将心肌梗塞患者的个特征作为输入,隐藏层的神经元节点对输入层的输入特征采取加权求和,通过非线性激活函数产生激活响应,使得神经网络可以任意逼近任何非线性函数。在训练过程中,采取向前传播和反向传播算法,不断调整模型权重和偏置参数,从而达到更好的分类效果。
2.2 支持向量机模型
SVM是由输入空间、特征空间和输出空间组成,在特征空间中可能存在多个超平面将数据进行划分,依据结构风险最小化原则,从中寻找间隔最大的分类超平面,其基本结构如图2所示。在真实应用数据集中,很难在现有特征空间中找到一个能够正确划分样本的超平面,因此需要使用核函数将原始的特征空间映射到更高维的特征空间中,使得样本在这个高维的特征空间中线性可分,即可求得最优分类超平面。
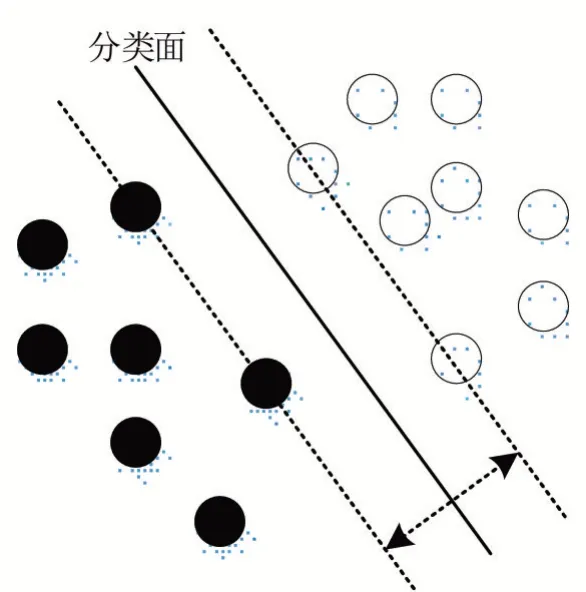
图2 支持向量机模型
2.3 评价指标
为了验证心肌梗塞患者并发症预测模型的有效性,需要对其预测效果进行评价,本文从准确率、召回率、AUC三个维度对模型进行评价。
(1)准确率:心肌梗塞患者发生并发症与不发生并发症的预测准确程度,如表达式(1)所示。

式中,表示正确预测心肌梗塞患者发生并发症的数量,表示正确预测心肌梗塞患者不发生并发症的数量,表示错误预测心肌梗塞患者不发生并发症的数量,表示错误预测心肌梗塞患者发生并发症的数量。
(2)召回率:正确预测心肌梗塞患者发生并发症的数量占样本集中有并发症的比例,如表达式(2)所示。

(3):表示ROC曲线下的面积,用于判断模型的优劣,其值一般介于0.5和1之间,值越大,表明模型的分类效果越好。
3 实验设计与结果分析
3.1 实验数据集
本文使用的数据集来源于加州大学欧文分校的UCI机器学习数据库中的心肌梗塞并发症数据集,总计1700例,数据信息包含患者以往病史(如心肌梗死数量,心绞痛的功能等级、肺结核的既往病史、糖尿病的既往病史等),入院时患者体征(如心电图节律、室颤心电图等),入院三天治疗措施(如药品使用频率),共计111个输入特征向量,11种并发症以及无并发症作为样本标签结果,对每一种并发症建立二分类预测模型。
数据集中含有1700例患者的样本数据,每例样本数据包含111个临床数据点,由于部分记录数据存在数据缺失情况,直接影响数据挖掘的结果。针对数据集中缺失的数据,本文采用最近邻算法进行数据补齐,即首先采用K-means聚类将所有样本进行聚类划分,随后通过划分的种类的均值对各自类中的缺失值进行填补。
心肌梗塞常见于中老年人群,本数据集中心肌梗塞患者的年龄分布如图3所示。从图中可以看出,心肌梗塞患者的年龄多集中于[40,80]之间,平均年龄为61.85岁。

图3 心肌梗塞患者的年龄分布
随着病程的发展,心肌梗塞患者可能没有并发症,也可能会有一种或多种并发症,图4展示了数据集中各并发症的人数分布情况。

图4 心肌梗塞患者的并发症类型分布
由图4可知,心肌梗塞患者最容易面临慢性心力衰竭并发症,与临床实际经验一致。本数据集中各并发症的样本集,有并发症类别的样本数远低于没有并发症类别的样本数,存在数据类别不平衡的问题。基于此,本文对每一种并发症的样本采用随机过采样的方法扩充训练集的数据样本量,达到样本平衡的目的。
3.2 模型参数设置
本模型以数据集的80%作为训练集,以此不断地训练模型,优化模型参数,使得整个模型收敛,然后将剩余的20%作为测试集,评估模型的预测效果。由于心肌梗塞患者可能发生多个并发症的情况,违背多分类输出互斥的原则,故对数据集中的每一种并发症分别建立MLP和SVM模型。经过大量的训练拟合测试后,确定了两种模型的使用参数。
针对MLP,本文构建1个输入层,1个隐藏层,1个输出层的网络结构,其中隐藏层的神经元数量为100,损失函数LogLoss,优化函数Adam,激活函数ReLU。
针对SVM,利用python中sklearn.svm.svc()函数,在核函数系数和惩罚松弛变量为默认值的情况下,分别采用Linear和RBF两种核函数,即Linear_SVM和RBF_SVM进行预测分析比较。
3.3 结果分析
利用MLP、Linear_SVM和RBF_SVM三种模型对数据集中的每一种并发症进行预测,其性能如表1~表3所示。

表1 基于MLP的心肌梗塞并发症预测结果

表3 基于RBF_SVM的心肌梗塞并发症预测结果

表2 基于Linear_SVM的心肌梗塞并发症预测结果
为了进一步比较三种模型在心肌梗塞并发症中的预测性能,对表1~表3中的所有并发症的预测结果取均值,将其作为模型的性能评价指标,结果如表4所示。从表4可以看出,相比于Linear_SVM和RBF_SVM,MLP的准确率最高,召回率和最低,这与原始数据集中的并发症样本数量息息相关,即使扩充样本数量,仍然面临无法准确挖掘出这些并发症与输入特征之间的关联,往往出现过拟合,使得模型的泛化能力较弱。在兼顾准确率、召回率、三种评价指标的情况下,Linear_SVM的整体表现最优,可见在小样本、数据高维的心肌梗塞并发症数据集中,基于Linear核函数的支持向量机表现出更优的模型泛化能力。特别是心房纤颤、三度房室传导阻滞、心肌破裂、心肌梗死后综合征四种并发症均表现出较好的准确率、召回率和AUC,表明该模型对这四种并发症具有较好的拟合能力。

表4 心肌梗塞并发症预测模型性能对比
4 结语
近年来,在医疗领域中利用机器学习算法辅助医务人员完成疾病诊断一直是研究的热点和难点,目前已经广泛应用于心血管疾病、糖尿病、肿瘤、肾病等疾病预测中,并取得了较好的应用效果。在相关应用研究中,研究人员将患者的临床检测数据作为机器学习模型的输入,将疾病的发生风险作为预测输出,有效辅助医务人员提前采取干预措施,减少患病风险,达到早发现、早预防、早治疗的诊疗目的。
目前,研究人员重点关注挖掘诊疗过程的部分特征数据与特定的心肌梗塞并发症之间的关联,忽略了患者诊疗前的病史数据。本文采用公开的真实数据集,根据心肌梗塞患者既往病史,入院时的体征数据以及入院三天的治疗措施,通过机器学习算法中的多层感知机模型和支持向量机模型,建立心肌梗塞患者并发症的预测模型。实验表明基于Linear核函数的支持向量机在本数据集下取得了较好的预测效果,对临床医务人员提早发现心肌梗塞并发症有一定的参考价值。
在心肌梗塞并发症的后续研究中,一方面需要持续优化模型参数,尝试使用更多的分类预测模型,进一步提高模型的预测准确率、召回率、AUC值;另一方面可使用深度学习等方法继续深入分析现有输入特征与心肌梗塞并发症之间的内在联系,对各并发症的影响因子进行重要性排序。
