基于自注意力路由胶囊网络的多音事件检测
2022-10-21李海涛杨树国
李海涛,杨树国
(青岛科技大学 数理学院,山东 青岛 266061)
日常生活中,人们每天都会接触到很多不同的声音,如汽车的鸣笛声、孩子的叫喊声等等,这些声音中包含了丰富的信息,识别生活环境中发生的不同声音事件从而进行不同的处理是非常重要的。声音事件检测(sound events detection,SED)就是检测音频信号中不同的声音事件及其起止时间,为进一步分析和处理声音事件奠定基础。SED在音频监控[1]、城市声音分析[2]、设备监控[3]等诸多领域都有着广泛的应用。
一般来说,SED的任务大致分为两类:单音SED和多音SED。单音SED在任一时刻至多检测出一种声音事件,而多音SED系统可以检测出多个声音事件[4]。从用途上看,因为现实环境中包含多个声源的情况更加多见,所以多音SED应用更为广泛;不同的声音事件往往相互重叠,而从混叠的声音中提取出的特征可能与从单个声音中提取的任何特征都不匹配,导致无法提取出能够有效代表单个声音事件的特征[5],所以多音SED更加困难和复杂,也更具挑战性。
传统的多音事件检测的模型有隐马尔可夫模型[6]和高斯混合模型[7]等。近年来,数据集和计算资源可用性的提高推动了深度学习模型在声音事件检测和分类任务中的应用,包括前馈神经网络(FNN)[8]、卷积神经网络(CNNs)[9]和循环神经网络(RNNs)[10]等。基于CNN和RNN的方法在SED任务中取得了良好的性能,这得益于它们能够学习提取出的音频特征与目标向量之间的非线性关系。特别是在多音SED的情况下,CNN与RNN的结合(CRNN)具有CNN提供的局部位移不变性,并具有RNN层提供的短期和长期时间依赖进行建模的能力,两种体系结构的结合提高了检测性能和效果[4]。
2017年底,HINTON等[11]提出了胶囊网络的概念,它的引入是为了克服CNN的一些局限性,特别是最大池化造成的信息丢失。胶囊可以被认为是一组神经元,它们的输出代表同一实体的不同属性[11]。一层(低层)的胶囊通过变换矩阵对下一层(高层)的胶囊进行姿态预测,然后使用动态路由机制,通过迭代聚类的方法获得耦合系数,并将相关胶囊的信息传递给下一层。
基于胶囊的计算结构与路由机制相结合,胶囊网络可以识别数据特征之间的部分和整体关系,从而能够有效提高网络在重叠目标的检测任务上的表现[11]。从理论上讲,动态路由的引入可在不需要大量数据增强或专用域适应程序的情况下充分训练模型,能够极大地提高模型的泛化能力。文献[12]提出了用于多音事件检测任务的Caps Net,在网络的初始层应用了门控卷积层,并在最后的胶囊层中添加了并行的注意层。该算法在DCASE 2017任务4的弱标注数据集上进行了使用,取得了良好的性能。文献[13]将胶囊网络应用于多音事件检测中,并在三个公开的数据集上进行了评估,结果显示,基于CapsNet的算法不但优于CNN,而且也取得了良好的效果。
然而胶囊网络中的动态路由机制是通过迭代聚类的方法获得耦合系数,这使得网络的训练和推理过程变得缓慢。文献[14]用一种新的非迭代的、高度并行化的路由算法来代替动态路由,称为自注意力路由。本研究以文献[12]提出的CapsNet为基线系统,研究了自注意力路由算法以及多路径基础胶囊层结构对多音事件检测的影响,提出了自注意力路由和多路径基础胶囊层相结合的胶囊网络,并在DCASE 2017 task4数据集上对该模型进行评估。
1 模型与算法
1.1 胶囊网络
胶囊网络的概念是HINTON等[11]在2017年提出的,其主要思想是用向量神经元替代传统的标量神经元。胶囊是一种向量,它的维数与目标的各种性质有关,如位置、大小、方向等,其长度代表了目标的活动概率。胶囊网络主要包含了卷积层、基础胶囊层和数字胶囊层。其结构如图1所示。

图1 胶囊网络结构图Fig.1 Capsule network structure
卷积层主要用来从输入中提取特征,其作用与卷积神经网络中的卷积层类似。低层胶囊通过动态路由机制来确定连接到高层胶囊的权重。动态路由算法的过程如图2所示。

图2 动态路由算法Fig.2 Dynamic routing algorithm
假设低层胶囊为i,高层胶囊为j,则高层胶囊的输出v j可由公式(1)~(3)计算得出:
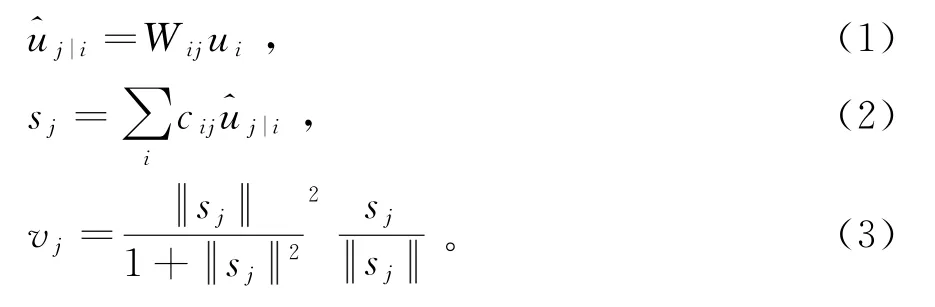
其中u i表示低层胶囊的输出,表示低层胶囊i对高层胶囊j的预测向量,W ij为相应的权重矩阵。将v j的所有预测向量用一组耦合系数c ij进行加权求和,并用一个非线性压缩函数(3)把向量的长度压缩在0到1之间,以表示目标存在的概率。耦合系数c ij由动态路由算法确定:

其中:和v j之间的相似度越高(用内积表示),c ij就会越大。在每次正向传播中,b ij被初始化为0,由方程(4)计算耦合系数c ij的初始值,然后由网络的正向传播计算v j。b ij的值根据公式(5)进行更新,用于更新c ij的值,并通过正向传播修正s j的值,从而改变输出向量v j的值,最后得到一组最优的耦合系数。
1.2 基于自注意力路由的多声音事件检测模型
为了提高胶囊网络的训练速度和推理速度,以及使模型充分利用原始特征中所包含的信息(尤其是时间信息),以进一步提高多声音事件检测的精度,本研究提出了基于自注意力路由的多声音事件检测模型(Mp Caps-att)。该方法使用一种最近提出的非迭代且高度并行的自注意力路由算法和多路径基础胶囊层。
1.2.1 自注意力路由
自注意力路由是文献[14]提出的新型路由方法,具有非迭代且高度并行的特点,因此能大大加快网络的训练速度。自注意力路由过程如下:
首先,对于l层的胶囊u ln∈Rd l(d l代表l层胶囊的维度),通过与权重矩阵相乘,获得对高层胶囊的预测向量,如公式(6)所示:

其中,n l表示l层胶 囊的数量,W ln l,n l+1,d l,d l+1包 含所有的权重矩阵,,n l+1,d l+1包含所有l层胶囊的预测向量,则l+1层胶囊s l+1n由公式(7)计算得出:
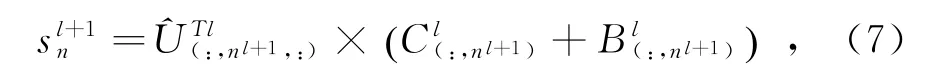
其中,B ln l,n l+1是包含所有权重的对数先验矩阵,C ln l,n l+1是包含自注意力算法产生的所有耦合系数的矩阵。耦合系数通过自注意力张量A ln l,n l,n l+1计算,自注意力张量的计算公式:
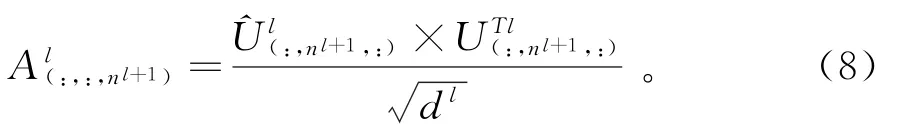
对于上层的每个胶囊n l+1,都含有一个对称矩阵A l:,:,n l+1。耦合系数可通过公式(9)计算得出:

最后将l+1层胶囊的输出s l+1n代入到压缩函数中,将向量的长度压缩到0到1之间,以表示特定目标存在的概率,文献[14]中使用的压缩函数为

1.2.2 多路径基础胶囊层
在声音事件检测任务中,时域信息的重要性比频域信息要高,所以应尽可能多的保留时间信息[4-5,15-16]。因此本研究提出了一种多路径基础胶囊层,如图3所示。
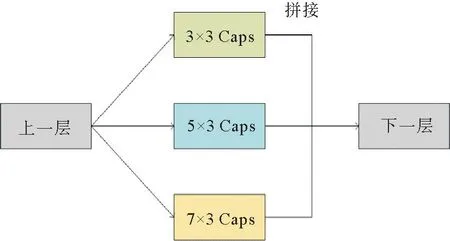
图3 多路径基础胶囊层Fig.3 Multipath primary capsule layer
该结构由三层基础胶囊层组成,且三层基础胶囊层具有不同大小的卷积核。其中两层的卷积核尺寸为非对称的,且在时域上具有更大的卷积尺寸。其中,三层基础胶囊层的卷积核大小分别为(3,3),(5,3),(7,3)。之后将三层基础胶囊层的输出进行拼接,送入高级胶囊层。一般来说,卷积核越大,获得的信息就越多,提取的特征就会更好。因此,在其中的两层基础胶囊层中,使用时域上尺寸更大的非对称卷积核,来获取更多的时间信息。不同的卷积核大小会提取出不同的特征,所以选择不同的卷积核大小就能获得不同分辨率的信息,使得模型能够充分利用特征信息。
1.2.3 基于自注意力路由的胶囊网络模型
本节提出了基于自注意力路由的胶囊网络模型,并用其进行多音事件检测,该模型包括卷积层、胶囊层和全连接层,如图4所示。
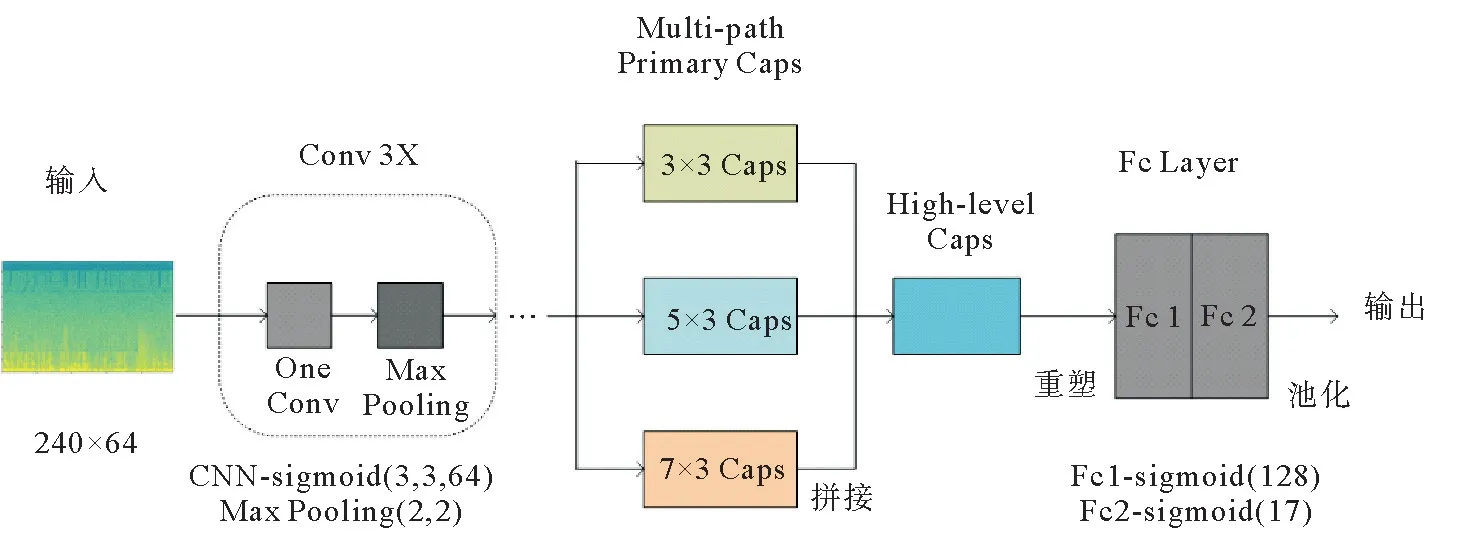
图4 基于自注意力路由的胶囊网络结构Fig.4 Capsule network structure based on self-attention routing
图4中,模型的输入是对数Mel语谱图,是通过将每段音频进行重采样并进行短时傅里叶变换,然后和Mel滤波器组相乘并进行对数运算得出。3层卷积层用来从输入中提取局部特征,并使用最大池化来缩减时域和频域的维度。假设输入的特征向量的形状为T×F,其中,T是样本中所含的帧数,F为输入特征的频点数;卷积层的输出为T′×F′×Q的张量,其中,Q为特征图的数量,T′和F′为经过一系列池化操作后的帧数和频带数。
本研究中使用的胶囊层由多路径基础胶囊层和高级胶囊层组成。多路径基础胶囊层的每个胶囊层是一个含有16通道的卷积层,每个通道由4维胶囊组成。特征被送入基础胶囊层中,经过卷积和squashin g函数压缩后,将三层的输出进行拼接,然后特征压缩成形状为T′×V×U的3维张量,其中,V是从其它维度推断出的,U是胶囊的维度,大小为4;然后将每一帧的胶囊送入高级胶囊层,来计算K个代表声音事件类别的8维高级胶囊,两层胶囊之间使用自注意力路由算法进行计算;最后,将得到形状为T′×K×8的张量。
胶囊层之后是两层全连接层,用来获取声音事件活动的概率。首先将胶囊层的输出重塑成形状为T′×(K×8)的张量,在经过两层全连接层后,张量的形状为T′×K,即T′个帧的每个声音事件的活动概率。由于使用的是弱标注的数据,训练集没有帧级别的标签可用,所以使用聚合函数将输出聚合成音频级的概率,即最后的输出形状为1×K。使用的聚合函数公式如式(11):

其中y i∈[0 ,1]是某个事件类型的帧级预测概率,y l∈[0 ,1]音频级的聚合概率。
2 实验部分
2.1 数据集
本研究提出的方法是基于弱标注数据集的,其中弱标注数据是指只提供音频中的事件类型,而不包含任何的时间信息。本研究使用DCASE 2017任务4提供的弱标记数据集进行评估,此数据集是AudioSet[17]的一个子集,由17个声音事件组成,分为“警告”和“车辆”两类。每段音频的最长持续时间为10 s,并且可能对应于多个可能重叠的声音事件。本工作在这个数据集上评估了2个任务:音频标注和声音事件检测。其中,音频标注旨在预测音频剪辑中包含的声音事件类型,声音事件检测还预测事件的开始时间和结束时间。对于音频标注子任务,使用精确率、召回率和F分数的微平均值来评估模型的性能。对于SED,计算了一个1 s分辨率的基于分段的错误率。
2.2 实验设置
本研究使用对数Mel语谱图作为输入特征。在提取特征之前,将每个音频片段重新采样到16 k Hz。使用64 ms帧长度、20 ms重叠和每帧64个Mel频率单元计算对数Mel特征。对于每个10 s的音频片段,将产生一个240×64的特征向量。
为减少过拟合的发生以及加快收敛的速度,本研究在每个卷积层和初级胶囊层之后使用批标准化。使用Adam优化器进行训练,固定学习率为0.001并且每两个epoch下降为原来的0.9倍。使用二元交叉熵作为损失函数,梯度通过大小为44的mini-batch进行计算。共训练30个epoch。
验证集和评估集具有均衡的事件数,但训练集是不平衡的,这会导致分类的偏差。为了减轻这个问题带来的影响,本研究使用了文献[18]中提出的数据平衡技术,以确保每一个小批量中包含来自每个类的样本数量是相当的。对于本研究提出的系统,音频标注和声音事件检测的阈值分别设置为τ1=0.3和τ2=0.6。
2.3 实验结果
基于上述的弱标注数据集,下面检验前文提出的基于自注意力路由的胶囊网络模型的声音事件检测效果。本研究以文献[12]提出的GCCaps为基线系统,方案一将GCCaps中的动态路由算法更换为自注意力路由(记为GCCaps-att);方案二在GCCaps的基础上使用多路径基础胶囊层(记为GCCaps-mp);对本研究提出的方法进行对比性实验,具体结果见表1和表2。
从表1的结果可以看出,自注意力路由和多路径基础胶囊层的加入能够提高音频标注任务的性能表现,分别比基线系统提高了0.4%和0.9%,而本研究提出的模型的F分数最高,相较于基线系统,提高了1.4%。由表2可知,在声音事件检测子任务中,自注意力路由对于性能的提升更加明显。本研究提出的模型获得了最佳的表现,错误率为0.72。

表1 音频标注子任务的性能结果Table 1 Performance results of audio tagging subtask %

表2 声音事件检测子任务的性能结果Table 2 Performance results of sound event detection subtask
表1和表2表明,本研究提出的自注意力路由和多路径基础胶囊层能够显著提高模型的性能,并且自注意力路由可以加快模型的训练过程,而多路径非对称的卷积结构能够使模型更充分地利用特征信息。
3 结 语
本研究提出了基于自注意力路由的胶囊网络模型,以实现弱标注数据下的多音事件检测。针对传统动态路由算法减缓网络运行速度的问题,采用了一种非迭代的自注意力路由算法,并且提出了一种多路径基础胶囊层结构,其中采用非对称的卷积核用来保留更多的时间信息,同时多路径的结构能够使模型获得不同分辨率的特征,从而使模型能够充分利用特征信息。实验结果也表明,本研究提出的模型具备更好的性能,模型在音频标注子任务上取得了59.5%的F分数,在声音事件检测子任务中错误率仅为0.72。未来的研究需要寻找更加高效的特征提取方法,为模型提取更全面的特征,以及研究最近提出的基于期望最大化算法(EM)的路由变体。
