BBR拥塞控制算法延迟及带宽探测优化
2022-10-18黄宏平朱小勇王志远
黄宏平,朱小勇,王志远
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190; 2.中国科学院大学,北京 100049)
0 引 言
1986年10月,因特网第一次经历的“拥塞崩溃”促使拥塞控制算法诞生[1]。随着互联网的迅速发展,各类服务、应用对网络性能的要求越来越高。拥塞控制算法被不断改进,新型拥塞控制算法不断地涌现,如Remy[2]、PCC[3]、Copa[4]等,这些拥塞控制算法为解决网络拥塞提供了全新的视角。一般来说,拥塞控制算法有2个关键的衡量指标,即带宽利用率与公平性。高带宽利用率意味着所有的流能够充分利用链路带宽,但是要避免链路过载而导致网络瘫痪。同时,尽可能地保证各个流之间带宽分配公平,拥塞控制算法应该具有良好的收敛性。谷歌在2016年提出了基于链路容量的BBR拥塞控制算法[5],与传统的基于丢包的拥塞控制算法不同,该算法在保证高带宽利用率的同时,能够保持较低的RTT(Round Trip Time),且算法具备很强的抗丢包能力。BBR通过主动探测链路可用带宽和最小链路传输时延(RTTmin),来充分利用链路可用带宽的同时,减少在瓶颈链路排队的数据包,并保证良好的公平性。根据网络反馈的数据包到达速率和测得的RTTmin,计算得到链路的带宽时延积(Bandwidth Delay Product, BDP),BBR输出2个拥塞控制关键参数:数据包发送速率(pacing_rate)和拥塞窗口(congestion window, cwnd),pacing_rate决定BBR发送数据的速率,cwnd决定BBR能够发送多少数据。此外,BBR对丢包不敏感,其最大抗丢包率达到20%,即丢包“崖点”[6]。
图1揭示了BBR与基于丢包的拥塞控制算法工作方式的根本区别[5]。该图显示了TCP流经过瓶颈链路时RTT、吞吐量与inflight的关系。inflight为正在链路中传输的数据量大小,即所有己发送的但未被确认的数据量。
当inflight刚好大于链路BDP时(图1中A点),瓶颈链路带宽得到充分利用,且此时几乎不产生数据包排队,排队延迟为0或者接近于0,该点被文献[7]证明为最优操作点,此时吞吐量达到瓶颈链路带宽,RTT接近链路固有时延。而在A点的左边,inflight数据低于BDP,瓶颈链路带宽没有被完全利用,可用带宽被浪费。随着inflight数据的增加,到达数据的速率超过瓶颈链路的转发速率,传输速率保持不变,超发的数据会被缓存在中间转发设备的缓冲区或被中间转发设备丢弃。瓶颈链路处的数据包队列越长,数据包排队延迟将越大,该过程在图1中表现为带宽限制。
基于丢包的拥塞控制算法以丢包作为链路拥塞的信号,在丢包之前不断增加拥塞窗口大小,直至出现丢包才减小拥塞窗口。基于丢包的拥塞控制算法操作点为图1中的B点,该点不但容易产生丢包,且会产生不必要的数据包排队延迟,缓冲区膨胀(Buffer Bloat)问题最严重[8]。
BBR试图将传输过程控制在最优操作点A,即获得最大带宽利用率的同时尽可能减少数据包排队延迟。Jaffe[9]证明不存在一个分布式的算法使得传输过程收敛到最优操作点A。BBR采取了一个折中的办法来近似收敛到点A。BBR采用一个状态机,如图2所示,在探测带宽和探测RTT这2个状态之间来回切换从而测得最大可用带宽BWmax和最小链路传播时延RTTmin,两者的乘积即为BDP,从而控制传输过程近似收敛到最优点。
BBR的基本流程如图2所示,算法首先进入START_UP阶段,该阶段以一个初始速率迅速增长到较为公平的可用带宽,然后算法进入DRAIN阶段,在该阶段BBR以START_UP阶段速率的倒数发送数据包,其目的在于排空START_UP阶段超发的数据包。当网络中的数据包数量小于等于BDP时,BBR退出DRAIN阶段,进入PROBE_BW阶段。BBR大部分时间都处在PROBE_BW阶段,在该阶段,BBR以速率增益数组[1.25,0.75,1,1,1,1,1,1]完成带宽的探测和算法的公平收敛,pacing_gain取值为1.25或0.75使得速率增加1/4,随后将超发的数据包排空。pacing_gain取值为1使得带宽保持不变,以保证算法的收敛。此外,BBR如果10 s内没有探测到更小的RTT将进入PROBE_RTT状态,该阶段将拥塞窗口设置为4个发送方最大段大小以排空网络链路重新测得RTTmin。
网络一旦产生拥塞,将可能造成丢包和高延迟。丢包会触发TCP重传,进而降低网络的有效吞吐量。高延迟同样会带来严重问题,首先,许多应用程序如AR/VR、在线游戏、远程系统管理、视频会议等对延迟及其波动性均有较高要求[10]。延迟如果过大,甚至网页浏览QoE也将急剧下降。受应用限制的流的带宽通常较小,如果拥塞控制不能保持较低的延迟,这些数据流在传输过程中也将持续存在高延迟,带宽较小的流吞吐量被挤占[11]。
实验发现,无论是单条还是多条BBR流,均存在较大的延迟,且延迟、带宽波动均较大。其次,BBR在带宽探测上还存在着一些问题,如在较小RTT环境下性能不佳,应对带宽改变不够及时等问题。本文对以上问题进行详细分析,并给出相应的解决方案。
1 相关工作
BBR拥塞控制算法已被广泛地研究与评估,文献[12]搭建了物理测试环境,对高带宽环境下的BBR进行理论分析和实验测试。该文献证明了多个BBR流对可用带宽的估计总和总是趋向于超过瓶颈带宽,使得多个BBR流共享同一个瓶颈带宽环境时将收敛到Kleinrock最优操作点的右侧,多个BBR流通常产生1~1.5倍RTT的排队延迟。该现象的产生源于BBR带宽探测时,为保证流的收敛性,不同BBR流尽可能选择在不同的时间探测链路带宽;探测带宽时使用最大过滤带宽窗口(BWmax-filter)得到的传输速率作为发送速率,最大瓶颈带宽(Max-BtlBW)即时采集,而Max-BtlBW的衰减是随着时间缓慢进行的,该机制是保证多个BBR流能够公平收敛的关键[13]。
此外,BBR存在严重的RTT不公平性问题,文献[14]建立了带宽动力学模型,证明了当RTT比率超过2时,BBR流之间将发生严重的带宽不公平。文献[15]通过调整发送速率增益系数的方式来改进RTT公平性,并且在一定程度上降低了排队延迟。文献[16]通过调整不同网络状态下的拥塞窗口大小以提高RTT公平性。文献[17]证明了BBR流实际获得带宽增长的增益系数与RTT相关,进而提出了更加公平的增益系数以改进RTT公平性。
在与传统基于丢包的拥塞控制算法混合部署中,BBR存在着较为严重的协议间公平性问题。文献[18]提出了一种BBR拥塞窗口缩放方案,来提高BBR与其他基于丢包的拥塞控制算法间的公平性。谷歌在2019年提出的BBRv2[19]一定程度地缓解了该问题,文献[20]对BBRv1和BBRv2进行了充分的比较与实验评估。
文献[21]评估了主流拥塞控制算法在慢启动阶段的行为,实验评估结果表明BBR在慢启动阶段的表现逊于其他拥塞控制算法。该文献的主要评估指标包括慢启动阶段Inflight数据量、成功发送的数据量、RTT等。
文献[13]对多个BBR流的收敛性进行了理论证明,指出多个BBR流能够最终收敛到同一个公平的带宽得益于BBR的带宽探测机制。进行带宽探测的BBR流,在探测RTT内,传输速率乘以一个大于1的增益系数以探测带宽,在排空RTT内,将传输速率乘以增益系数的倒数以排空探测RTT期间产生排队的数据包。而收敛的关键在于相比瓶颈带宽占比较大的流,瓶颈带宽占比较小的流能够得到更大的传输速率增长。
针对BBR多流共享瓶颈链路出现严重的排队延迟问题,谷歌在2018年发布了一个补丁[22]试图解决该问题,其改进方案是在带宽探测状态下,要求pacing_gain数组的第2个drain RTT内,inflight数据包小于等于BDP之后才进入下一个探测阶段,来解决之前的固定耗尽时长不足以排空队列的问题,但是NS3最新版本NS-3.35以及最新版本的Linux内核源码均未实现该改进。本文在NS3中应用该改进后,发现排队时长缩短了40%以上。
文献[17]进一步改进了BBR带宽探测阶段发送数据包行为,在第1个pacing阶段(pacing_gain=1.25),当向网络中注入的数据包达到1.25倍BDP后立即退出此阶段,而不必等待一个RTTmin的最小时长,该改进在瓶颈带宽被高估时减少了注入网络的数据包,进而减少排队延迟。通过应用该改进,排队延迟进一步降低了10%左右。该文献还通过更快地退出PROBE_RTT状态显著减少了RTT探测引起的RTT抖动。
文献[23]旨在解决链路容量快速变化的网络场景下,BBR的最大过滤带宽(BWmax-filter)机制带来的高延迟问题。该文献提出了一种自适应的Tobit Kalman带宽过滤器以应对带宽改变,但是该带宽过滤器一定程度降低了BBR的带宽利用率和协议公平性。
文献[11]借鉴了BBR的设计思想,设计了一种以拥塞窗口为主要控制参数的状态机。该算法严格根据BDP调整cwnd大小,相比BBR能够提供更低的延迟,但是代价是一定的带宽利用率损失。
2 BBR排队延迟与带宽探测分析
2.1 排队延迟
在NS-3.35中仿真实验发现,在应用了上述所提到的延迟优化[17,22]后,即使单个BBR流独占瓶颈链路,仍旧存在一定的排队延迟,实验中设置链路传播时延(RTTprop)为60 ms,瓶颈带宽为10 Mbit/s,RTT变化见图3。
从图3可以看出,绝大部分时间RTT在60 ms到80 ms之间剧烈波动,远高于RTTprop(60 ms)。在第10 s之后,RTTmin逐渐增大,超过链路设置的传播时延,在此之后RTTmin进一步增大。本文发现其原因在于BBR的RTTmin有效时间为10 s,当RTTmin过期时,瓶颈链路此时存在较大的排队时延,使得更新的RTTmin偏大进而使得瓶颈链路排队现象进一步加剧,整个过程如图4所示。
对于多路流共享瓶颈带宽的场景,BBR存在更为严重的排队延迟,对比结果见本文实验评估部分。文献[12]从定性的角度分析了BBR在多流共享瓶颈链路时将过载瓶颈链路,进而产生较大的排队延迟。本文从定量的角度对该问题进行分析。
设瓶颈链路带宽为BtlBw,流的总数为N。假设瓶颈链路处的缓冲区大小足够大。第i个流探测的传播时延记为RTTmin_i,由于各个流共享瓶颈缓冲区,所以其排队时延相同,记为D(t)。则往返时延为:
RTTi=RTTmin_i+D(t)
(1)

BtlBw=∑ibwi
(2)
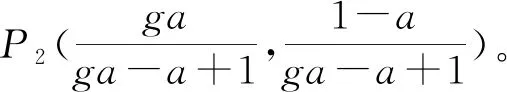


设该平衡状态下2路流的BWmax-filter分别为m1、m2,当2路流的发送速率完全相等时,2路流将达到平衡状态,则m1=m2=m。由于BBR是以BWmax-filter乘以增益系数g的速率发送数据包的,BBR能够保证充分利用链路带宽,则有:
(3)
编写程序对上述带宽探测过程进行模拟,绘制出每次A、B这2个流带宽探测后两者带宽变化散点图、2路流各自的BWmax-filter变化散点图如图6所示。可以观察到,带宽分配起始点P1从直线Y=1-X的任意处开始,经过若干次轮流探测后都将收敛到同一状态。当前实际带宽坐标轮流取值(0.4444,0.5556),2路流BWmax-filter均收敛到0.5556。
在图6中,当流A探测带宽时,A、B这2路流的实际带宽取值分别如L1和L3所示,当流B探测时,A、B这2路流的实际带宽取值分别为L2和L4所示。无论是流A还是流B向上探测,流A的带宽都随着探测次数的增大逐渐减少,流B的带宽会随着探测次数的增大逐渐增大。L1和L4同样是A与B这2路流各自的BWmax-filter变化,可以看出流A的实际发送速率逐渐减小,流B的实际发送速率逐渐增大,在大约第34轮探测后两者收敛到同一值,其值高于理想情况下的公平带宽。
理想情况下有:
(4)
实际发送速率超过瓶颈带宽,在瓶颈链路处产生数据包堆积,进而导致RTTmin估计持续偏大。BBR实际操作点处的带宽和时延两者都大于理想值,导致BBR无法收敛到最优操作点,整个传输过程中持续存在较大排队延迟。
2.2 带宽探测
2.2.1 BBR在RTT较小时性能表现不佳
可以观察到,当RTT较小时,BBR吞吐率曲线在PROBE_RTT阶段后出现带宽崩塌现象。实验链路带宽设置为10 Mbit/s, RTT为8 ms,吞吐率曲线如图7所示。
可以看出,大约在第10 s左右,吞吐率迅速下降。通过进一步对该现象进行分析,发现原因在于PROBE_RTT阶段后,BBR对链路的带宽估计极度偏低,因为在探测RTT阶段,BBR设置拥塞窗口值为4个发送方最大段大小来排空网络链路上的数据包,从而测得RTTprop。画出BBR在整个传输过程中BWmax-filter的变化曲线可进一步验证该分析,如图7中虚线所示。
该曲线在第10 s之后有多次下降过程。其原因在于BBR的BWmax-filter窗口仅在10个RTT内有效,而BBR在PROBE_RTT阶段采集到的带宽样本通常远低于实际链路可用带宽,当RTT较小时,整个PROBE_RTT阶段经历的RTT轮数将大于10,这将导致BBR无法正确估计链路带宽。
2.2.2 对带宽变化敏感性不足
如前所述,BBR通过将pacing_gain设置为一个大于1的增益增大发送速率来探测链路带宽,随后一轮RTT内将pacing_gain设置为增益的倒数排空上一轮产生的数据包队列,接下来6轮RTT内按照网络链路可用带宽发送数据包,这6个平稳状态是BBR带宽能够收敛的关键,保证了BBR的公平性[13]。平稳状态维持时间如果过短,留给其他流探测带宽的时间将会不足。平稳状态维持时间如果过长,BBR将不能及时探测网络链路带宽;平稳阶段过长还会使得BBR收敛时间更长[25]。对于较长RTT的流而言,保持平稳状态的时间将过长,其带宽探测的灵活性与收敛速度均较差。
3 延迟与带宽探测改进
3.1 延迟改进
针对BBR传输过程中排队延迟较高的问题,结合BBR公平收敛的原理,本文提出一种改进算法,该算法的核心思想是限制在外数据包数,并对BBR流进行适当的减窗,在不影响BBR带宽利用率、公平性的条件下,进一步减小BBR的延迟,降低延迟抖动,提升BBR收敛速度。网络链路中的某路流对整体网络参数通常是不可知的,如理想公平分配的带宽大小、流的数目等。该算法动态计算链路BDP来减小拥塞窗口,在保证链路被充分利用的同时,使延迟尽可能减小。算法1详细描述了算法的主要逻辑。
算法1 BBR延迟优化算法。
Set cwnd_gain=1.0;
pacing_gain=[6.0/5, 4.0/5, 1, 1, 1, 1, 1, 1]
For every ack do
queue_delay=RTT_Sample-RTTmin;
If BBR bottleneck bandwidth is stable:
If queue_delay>delaylower_bound:
cumu_shrink_cwnd+=gain_cwnd;
send_cwnd=BDP-Cumulative_shrink_cwnd;
BBR以pacing_rate作为主要控制参数,cwnd_gain被设置为2,在PROBE_BW阶段最高允许2BDP的inflight数据包,其目的是应对ACK延迟和聚合严重的网络传输场景[5]。本文将其减少到1,保证在外数据包数能够充分利用带宽,且能够应对较为严重的ACK延迟场景(如延迟ACK直到每4个数据包回复一个ACK);对于在接收者驱动的传输协议中使用BBR[26],由于并不通过ACK进行带宽估算,也将不受ACK延迟和压缩的影响。将PROBR_BW阶段探测带宽的pacing_gain由5/4减小到6/5以进一步减少BBR探测带宽时超发的数据量,进而降低RTT及其波动性。算法维护一个累积减少拥塞窗口值cumu_shrink_cwnd,该值根据网络链路排队状况进行设置,以达到减少排队时延并加速流的收敛的目的。对每个到达的ACK,算法计算当前排队时延,并根据排队时延计算超发的数据包,在cwnd_pace个RTT期间逐步减少超发数据包。由于各个流共享瓶颈缓冲区,所以其排队时延相同。根据BDP=maxBW·RTTprop,带宽更大的流相比带宽小的流将会减少更多的超发数据包,从而进一步加快流的收敛。减少拥塞窗口需要在网络较为稳定的条件下进行,否则过度地减少拥塞窗口将带来不必要的带宽损失。判断网络是否稳定可计算RTT的方差与平均值的比值,文献[27]测得有线网络中该比值不超过0.3;当BBR退出DRAIN或者处于PROBE_RTT阶段附近测得的延迟通常是较低的,在这些情况下不调整拥塞窗口。设置delaylower_bound的目的在于提高算法的稳定性,保证各个流之间的公平收敛。
3.2 带宽探测
3.2.1 BBR在RTT较小时性能表现不佳
针对根据RTT大小与PROBE_RTT阶段经历的轮数的关系,可以列出关系式:
(5)
其中1轮是用来排空管道使得链路中该流的inflight数据包不超过4个,令round≤10,解得RTT≥22.23 ms时,PROBE_RTT阶段不会使链路估算带宽失效。
针对上述问题,解决该问题的方向大致分为2种。首先,可以更改PROBE_RTT阶段的持续时长,使其在BWmax-filter过期之前结束PROBE_RTT,比如将PROBE_RTT阶段持续的时长改为RTT相关,如3个RTT,但是该方法可能使得BBR流不再同时进入PROBE_RTT状态,进而破坏BBR的收敛性。其次,可以为探测RTT之后的BBR提供一个有效带宽。本文采取的解决思路是将进入PROBE_RTT阶段之前的Max-FilterBW延续到退出PROBE_RTT阶段,继续作为链路带宽估计数据来指导BBR的带宽探测行为。上述思路基于以下假设,即RPOBE_RTT阶段时间较短,仅有200 ms左右,该段时间内链路的可用带宽变化通常较小。
3.2.2 对带宽变化的敏感性改进
针对较长RTT场景BBR对带宽探测敏感性不足的问题,设置一个平稳状态最长保持时间MaxStableDuration来及时退出平稳状态,并转入带宽探测周期进行带宽探测。具体来说,当BBR进入平稳周期时记录平稳周期起始时间,在判断是否要进入下一个平稳周期时,检查平稳周期保持时间是否已经超过MaxStableDuration,如果超过则直接转入带宽探测周期(pacing_gain=1.25),否则按照顺序进入下一个周期。
4 实验评估与分析
本文在NS-3.35仿真平台上对改进BBR进行验证。实验拓扑为经典的哑铃拓扑,其结构如图8所示。节点之间通信采用TCP协议,设置TCP的拥塞控制算法为BBR或改进BBR。
4.1 BBR排队延迟与公平性对比
为了验证改进BBR的性能,本文进行以下几个实验,分别对带宽利用率、RTT、算法公平性、带宽抢占能力进行测试与分析。以下实验设置RTTprop为60 ms,瓶颈带宽为10 Mbit/s, delaylower_bound=10 ms, cwnd_pace=30, ACK延迟计数为2。
图9为2路流同时启动,改进BBR与BBR带宽利用率、延迟的对比结果。可以看出,两者均能够快速收敛到公平带宽,并持续保持在该带宽附近。改进BBR相比BBR具有更为公平的带宽分配,且其带宽波动非常小。BBR延迟在[70,90] ms范围内迅速波动,而改进BBR延迟仅为BBR的延迟波动范围的下限值,为72 ms左右,该值还可以通过调整算法delaylower_bound和cwnd_pace进一步减少,其代价是有一定的带宽波动;改进BBR的延迟波动非常小。
图10为富余带宽抢占能力对比结果。设置第2路流在27 s附近停止传输,观察第1路流对富余带宽的抢占能力。可以看出,改进BBR甚至比BBR能够更快地抢占富余带宽,即使其具有更小的抢占增益系数,其原因是改进BBR在抢占周期的持续时间比BBR更长。抢占带宽前后,改进BBR的带宽与延迟均能够保持较小波动。
图11显示了5路流同时传输时的带宽与时延变化,可以看出,改进BBR在大约3 s左右带宽已基本收敛到公平带宽,而BBR在第42 s左右才收敛,改进BBR收敛速度提升约13倍。改进BBR在多流环境下的带宽与延迟波动仍旧较小,其RTT约为BBR的RTT波动范围的下限值。
4.2 带宽探测改进实验验证
4.2.1 RTT较小时吞吐量对比
图12为链路带宽为10 Mbit/s、RTT=4 ms时的吞吐量变化曲线。BBR在第10 s之后带宽迅速下降至接近于0,而改进BBR仍然能够保持高带宽利用率,改进BBR能够适应更小的RTT环境。如果要将BBR应用到RTT极低的应用场景,还需要修改RTTprop的更新机制,以使得所有流同步进入PROBE_RTT状态。
4.2.2 对带宽变化的敏感性改进
图13显示了BBR与改进BBR在相同链路下吞吐量的变化曲线。实验设置瓶颈链路带宽为10 Mbit/s, RTT=240 ms, MaxStableDuration=400 ms。相同时间内,改进BBR相比BBR带宽向上探测的次数大幅增加,分别为43次和24次。改进BBR能够更加及时地探测到链路带宽增加,进而提高发送速率,及时利用链路富余带宽。
5 结束语
本文对BBR延迟较高的问题进行了详细的分析,进一步给出了解决方案,即通过限制在外数据包数,适时减少拥塞窗口来减少延迟及其波动性。对BBR在较小RTT环境下性能不理想以及带宽探测敏感性不够高的问题给出了解决方案。对于改进BBR应对RTT公平性问题以及与基于丢包的拥塞控制算法混合部署的场景本文并未讨论,这是将来需要进一步研究的内容。
