基于可分离结构变换的轻量级Vision Transformer
2022-10-18黄延辉
黄延辉,兰 海,魏 宪
(1.福州大学电气工程与自动化学院,福建 福州 350100;2.中国科学院福建物质结构研究所泉州装备制造研究中心,福建 泉州 362200)
0 引 言
随着AlexNet[1]夺得2012年ImageNet[2]大规模图像识别竞赛(ILSVRC2012)的冠军,卷积神经网络(Convolutional Neural Networks, CNN)也成为计算机视觉领域的研究热点,VGG[3]和ResNet[4]等经典卷积神经网络模型被相继提出,CNN逐渐成为视觉领域的主流网络结构。2020年Vision Transformer[5](ViT)横空出世,这个以Transformer为基本架构的新模型在ImageNet数集上取得了最高的分类精度,此后越来越多的ViT变体被提出,迅速席卷了计算机视觉领域各个下游任务。目前在图像分类[6]、目标检测[7]和图像分割[8]等视觉任务上的最优模型都与Transformer有关。
随着移动设备数量的增长和物联网的普及,深度学习模型越来越需要被部署到一些实时终端设备上,如智能手机、可穿戴医疗设备、自动驾驶汽车和安防监控摄像头等。虽然实验室环境下Transformer结构模型的性能在许多视觉任务上都超越了卷积神经网络,但是如果将其部署到终端设备中则必须解决模型参数量大和推理速度慢的问题。因为这些设备大多不仅要求实时性强,而且自身资源还有限,无法满足快速运行大型模型所需的内存和算力要求。Transformer模型依赖于自注意力机制,一方面因为自注意力机制中大量使用全连接层,这使得多层Transformer模型参数量非常大。另一方面,自注意力机制的计算复杂度相对于序列长度的时间和空间复杂度均是O(n2),当序列长度过大时计算成本难以承受[9]。
在Transformer结构应用到视觉领域之前已有一些工作探索通过降低注意力矩阵计算成本来使得Transformer模型更加高效[10-13]。但这些方法大多没有或者只是略微降低了模型的参数量,并且由于注意力矩阵存在低秩瓶颈[14],许多方法可能会使得模型的表达能力有所损失。
与Transformer模型不同的是,CNN模型的计算大多伴随隐藏层出现,很少有额外的中间计算。所以在CNN模型中参数量的减少也会带来计算成本的降低,这使得CNN压缩算法大多专注于降低模型参数量。模型压缩算法大体上可以分为4类:低秩分解[15]、量化[16]、知识蒸馏[17]、剪枝[18]。剪枝法是研究最广泛、竞争力最强的一类模型压缩算法,它主要通过修剪不重要的权重来压缩模型。但使用剪枝法修剪注意力机制中的全连接层时可能会使特征矩阵Q与特征矩阵K中大量元素为0,使得它们点积生成的注意力矩阵低秩,影响模型的表达能力[14]。
基于以上问题,本文提出一种基于可分离结构变换的轻量级Visual Transformer模型,通过将ViT模型中的全连接层变换为可分离结构(Separable Structured Transformations, SST)来降低参数量,在加速模型的同时尽可能保留模型的精度。本文的主要工作有:
1)提出一种基于克罗内克积分解的可分离结构变换,能够将传统全连接层变换为一种新型全连接结构,使得Transformer结构模型在降低参数量、加速计算的同时避免注意力矩阵低秩从而保证了模型的表达能力。
2)提出一种基于SVD的克罗内克积近似分解法,命名为NKP-SST。使用该法可以将公开的ViT预训练参数分解后加载到ViT-SST上,可以提升模型精度。这为解决Transformer结构模型预训练时间成本高昂的问题提供了一种新的方向。
1 研究现状
1.1 Vision Transformer
在Dosovitskiy等人[5]提出Vision Transformer之前,CNN主导了机器视觉领域。CNN网络依靠权值共享、尺度分离和平移不变性等特性,获得了强大和高效的图像特征提取能力。虽然Transformer结构网络没有像CNN那样直接表现出强大的归纳偏置,但其独特的结构使它可以通过平移不变性来获得归纳偏置。具体来说,标准的Vision Transformer包括以下部分:令牌嵌入、位置嵌入、Transformer编码器和分类头。该模型首先将图片切分为固定尺寸大小的图片块,通过令牌嵌入层将图片块编码,再通过位置嵌入添加位置编码信息,然后将其送入Transformer的编码器中进行特征提取,最后通过分类头输入分类结果。随着对Transformer结构网络的探索,许多基于Transformer结构的模型被提出并有效解决视觉任务。Wu等人[19]则通过结合Transformer和CNN以获得理想的性能。Liu等人[7]提出了Swin Transformer,它采用图片块划分、线性嵌入、金字塔结构和基于窗口的自注意力机制来获得强大的性能。
1.2 Efficient Transformer
借助自注意力机制,Transformer结构在许多领域得到广泛应用。但在注意力计算过程中特征矩阵Q与特征矩阵K的点积会产生一个很大的矩阵用来表示令牌与令牌之间的交互,这使得自注意力运算不可避免地存在穷举和冗余计算。由于自注意力计算时间复杂度是O(n2),当输入序列长度增加时,爆炸式增长的计算量成为了Transformer的瓶颈。为了解决这一问题,研究人员提出了几种新的Transformer架构来改进原有的自注意力机制。这些方法主要分为3类:
第一类方法采用稀疏自注意力,即注意力计算时只能以特定的预定义方式进行有限计算。例如,文献[13,20]利用固定的跨步注意力计算模式来降低计算成本。Kitaev等人[12]提出一种可学习的方法,使用基于哈希的相似性来替换令牌对令牌的交互。
第二类方法采用基于核的方法来直接逼近并生成注意力矩阵。文献[10-11]采用核方法来找到一种相对低秩的结构来减少计算复杂度。而Tay等人[21]提出了综合Transformer,利用多层感知机直接近似自注意力机制的点乘运算。
除此之外,还有一些方法与上述解决方案不同。例如,文献[22]应用一个隐藏状态来使用递归机制连接相邻的令牌。文献[23]使用双系统同时维护长短期记忆以减少计算复杂度。
上述方法都只是试图降低计算成本,没有或者轻微降低了模型的参数量,所以这些模型称为Efficient Transformer[9]。
1.3 模型压缩算法
随着卷积神经网络的发展,计算机视觉任务的精度达到了前所未有的水平。为了进一步提高性能,研究人员设计了更深、更广的网络,但提高准确性往往是有代价的:网络模型参数量和计算量越来越大,超出了许多现实场景中设备的承受能力。为了克服这一问题,研究人员提出了各种类型的神经网络压缩算法。这些方法大体上可以分为4个类别:低秩分解、知识蒸馏、量化和剪枝。
低秩分解算法主要是将使用多个小规模的低秩向量矩阵的张量积去近似大规模的权重矩阵。然而,因为它涉及分解操作,计算代价十分昂贵。另一个问题是因为不同层持有不同的信息,当前的方法只能逐层执行低秩逼近,无法执行全局参数压缩。低秩近似之后,模型还需要较长时间再训练以使原始模型收敛[24]。而Transformer结构模型本身由于缺少归纳偏置而需要在超大数据集上预训练,且训练收敛难度较高[5],这导致低秩分解算法很难在Transformer结构模型上使用。
量化算法则通过减少表示每个权重所需的比特数来压缩原始网络。Gong等人[25]对参数权重值使用K均值找到所有权重值的聚类中心,用聚类中心加偏移量的灵活表示方式来代替传统8位数字的固定表示方法。Vanhoucke等人[26]展示了权值可以在准确率损失极小的同时实现大幅降低参数量。通过上述内容可以看出量化算法主要在模型参数保存阶段使用,所以一般与其他压缩算法组合使用。
知识蒸馏算法[17]将轻量级的学生网络输出分类概率向量与大型教师网络输出分类概率向量的交叉熵损失作为学生网络训练时损失值的一部分,以此来诱导学生网络的训练,实现知识迁移。FitNet[27]则通过让学生模型模仿教师模型的特征图来达到更高的精度。然而基于知识蒸馏的算法通常需要自己设计学生网络,且很难获得有竞争力的结果。
剪枝算法最早通过修剪权值最小的部分参数来达到压缩和加速模型的目的。后来,出现了The Optimal Brain Damage[28]和The Optimal Brain Surgeon[29]方法。这些工作表明,该剪枝算法比根据权值大小进行修剪的剪枝算法具有更高的准确性。而Srinivas等人[30]则探索并发现神经元之间存在冗余,并提出了一种无数据剪枝方法来去除多余的神经元。Transformer结构模型的特征提取模块包含了多头自注意力机制中的3个全连接层Wq、Wk、Wv,当使用剪枝算法进行修剪时会使得该全连接层权值部分变成0,进而使得Q、K、V矩阵也存在大量权值为0,最终导致注意力矩阵低秩,影响模型的表达能力。
2 基于可分离结构变换的ViT-SST
2.1 基于克罗内克积分解的可分离结构
在神经网络中,在单样本输入情况下神经网络全连接层可以表示为:
Y=σ(WX+b)
(1)
式中X表示输入向量,Y表示输出向量,W表示权重矩阵,b表示偏置矩阵,σ(·)为非线性激活函数。假设X∈m×1,Y∈n×1,W∈n×m,b∈n×1,则可以根据公式(2)和公式(3)计算出该全连接层参数量p和浮点计算次数f(floating point operations, FLOPs):
p=(m+1)n
(2)
f=mn
(3)
由此可知,输入向量和输出向量的维度决定了权重矩阵W的大小,进而决定了全连接层的计算量和浮点计算次数。在计算机视觉领域,目前常见的公开数据集图片尺寸最小也有28×28,大的可达224×224及以上。一般来说,全连接层需要将上述图片或提取特征后的特征图展平后作为输入向量X送入全连接层,为了匹配该输入向量维度不得不将参数矩阵的尺寸设置得很大,这就很容易出现网络模型参数量激增的问题。以VGG16为例,ImageNet数据集的图片经过前13层卷积层处理后特征图维度为7×7×512,将其展平后输入向量X∈25088×1,通过参数矩阵W∈25088×4096得到输出向量Y∈4096×1。根据公式(1)可计算出该层全连接层参数量高达1亿多,VGG16网络将近90%的参数在全连接层。
由以上分析可知全连接层参数量大的主要原因是将输入数据拉平变为向量所导致的输入向量维度过大。同时因为注意力矩阵的低秩瓶颈,简单粗暴地修剪注意力机制中的全连接层或者对注意力矩阵采取核逼近或跨步计算等方法有可能影响到模型的表达能力。为了解决这一问题,本文提出一种基于克罗内克积分解的可分离结构。将普通全连接层结构分离转换为2个小规模权值矩阵,即分别从输入矩阵的2个维度去进行权值乘法运算,这样就避免了将输入数据拉平的操作,有效降低了全连接层的参数量,又保留了完整的全连接结构,避免注意力矩阵低秩。
首先,假设参数矩阵W∈n×m,且等于2个小矩阵At和Bt的克罗内克积,即W=Bt⊗At,式中At∈n1×m1,Bt∈n2×m2,n=n1n2,m=m1m2。那么公式(1)就可以写成:
Y=σ((Bt⊗At)X+b)
(4)
将克罗内克积改写为普通点积后可得:
v-1(Y)=σ(At·v-1(X)·Bt+v-1(b))
(5)
其中v-1(·)表示将向量重新塑造维度变为矩阵。上面已经提到,图片数据输入后一般为二维矩阵形式,那么公式(5)可以继续改写为如下形式:
Yt=σ(At·Xt·Bt+bt)
(6)
式中Xt和Yt表示输入、输出矩阵而非输入、输出向量,bt为偏置矩阵,At和Bt为新的参数矩阵。该式即为基于克罗内克积分解的新全连接结构表达式,该变换命名为可分离结构变换。示意图如图1所示。
为了方便比较2种全连接结构的参数量和计算量,下文普通连接层将以FC表示,结构变换后的新全连接层以SST表示。由于偏置参数只是重新塑造了维度并没有减少或增加参数量,参数量计算将不考虑偏置的影响,那么2种全连接层参数之比就可以表示为:
N(SST)/N(FC)=(n1m1+n2m2)/(n1m1n2m2)
=1/n1m1+1/n2m2
(7)
因为n1、n2、m1、m2均远大于1,所以N(SST)/N(FC)结果远小于1,由此可知模型参数量得到了很大幅度的降低,当n1=n2,m1=m2时参数量降低幅度最大。
浮点计算次数之比为:
O(SST)/O(FC)=(n1m1m2+n2m2m1)/n1m1n2m2
=1/n2+1/n1
(8)
因为n2和n1均远大于1,所以O(SST)/O(FC)值远小于1,由此可知模型的浮点计算次数也得到了降低。
2.2 基于SVD分解的模型权值克罗内克积分解法
在深度学习中模型加载预训练参数时需要参数与模型结构完全匹配,缺少或随意修改部分参数都有可能导致预训练模型失去作用。虽然理论上可以将ViT模型的预训练参数进行克罗内克积分解后加载到ViT-SST中,但因为大部分情况下ViT公开预训练模型参数均为多位小数,这使得无法通过传统克罗内克积分解的方法得到有效分解结果。为了得到近似但有效的克罗内克积分解结果,本文引入一种基于Singular Value Decomposition (SVD)分解的克罗内克积分解近似解求法。
接下来以4行4列的W矩阵为例说明该方法。W=B⊗A可以具体写成如下形式:
(9)
求W矩阵的克罗内克积分解后的A矩阵和B矩阵可以转化为最小化φ(A,B)问题,其中:
φ(A,B)=‖W-A⊗B‖F
(10)

(11)
那么公式(10)就可以写成如下形式,式中vec(·)表示将矩阵向量化:
φ(A,B)=‖W-A⊗B‖F
(12)
(13)

2.3 ViT-SST模型结构
ViT-SST网络整体结构如图2(a)所示;Transformer编码器模块结构如图2(b)所示;多头注意力机制结构如图2(c)所示。与传统的ViT相比,本模型将编码器中的MLP层和多头注意力机制中的所有普通全连接层均转换为可分离结构全连接层,这使得模型参数量大幅降低。对于标准的ViT-B/16模型,参数量可以由85.7M降低到0.3M,压缩倍率高达285倍。对于适合小数据集的ViT-Lite模型来说,参数量由3.85M下降至0.21M。
3 实验与分析
3.1 实验设置与数据集
为了验证本文所提网络的性能,以下实验均在常见的公开图片数据集上进行。数据集包括:MNIST[31]、CIFAR-10[32]、CIFAR-100[32]、Caltech101[33]、Caltech256[33]。MNIST数据集由60000张像素为28×28的手写数字图像组成,分为10类。CIFAR-10数据集由60000张32×32的彩色图像组成,分为10类,每类6000张图像。其中有50000张训练图像和10000张测试图像。CIFAR-100数据集由60000张32×32的彩色图像组成,分为100个类,每个类600张图像中有500幅训练图像和100幅测试图像。Caltech101数据集包含101个类别,共9146张图像,每类包含图片数量不同,每个类别约40至800张图像,大多数类别都有大约50张图像,每个图像的大小约为300×200像素,本文在实验中将其图片形状统一变形为224×224。Caltech256共含有256类,每个类别的图片超过80张,其他信息与Caltech101数据集相同。
本次实验代码采用Python语言编写,使用Pytorch深度学习框架,在NVIDIA RTX 2080Ti上训练,并对数据集使用了随机裁剪和随机水平翻转等数据增强方式。ViT需要超大数据集(例如JFT-300M)进行预训练才能获得最好的效果,所有实验(包括对比实验)将全部不进行预训练,以保证实验的公平。
3.2 常用数据集评估
一般来说视觉Transformer模型都包含多个Transformer层,每个Transformer层中在不同位置使用了6层全连接层,分别是Wq、Wk、Wv、Wo、Wfc1、Wfc2。为了便于比较,通过搭配Transformer层数和可分离结构全连接层个数来得到不同大小的模型。ViT-Base-SST是以ViT-Base模型为基础,将模型内全连接层通过可分离结构变换后得到。ViT-Lite-SST则是以ViT-Lite为基础,并且只转换部分全连接层以保证和对比方法参数量大致相同。而ViT-SST则转换了所有全连接层。除此之外,每张图片在序列化前进行了2次卷积操作。
结果如表1所示,其中Params代表模型参数量,MACs代表模型乘加计算次数,是衡量模型计算复杂度的一个指标。Visual Transformer部分是以ViT-Base为基准的传统剪枝算法对比实验结果。

表1 模型图片分类精度、参数量、MACs比较
实验结果显示传统剪枝算法进行修剪后的ViT模型在高压缩倍率下模型精度大幅度下降,几乎失去图像识别功能。这可能是因为当压缩倍率较高时剪枝法使得Wq、Wk、Wv这3个矩阵大部分元素为0,使得注意力矩阵低秩,模型失去了“注意力”。
而在模型ViT-SST中,由于Wq、Wk、Wv这3个特征提取矩阵采用基于克罗内克积分解的可分离结构,全连接层后虽然参数量减少了,但整个参数矩阵仍然完整,注意力矩阵避免了低秩。
本文采用Grad-CAM[36]可视化技术去观察模型在进行图像识别时关注图像的哪些部分。结果如图3所示,发亮部分表示模型所关注的区域。可以看出对比方法中实验结果较好的HYDRA算法修剪后的ViT模型已经很难注意到图像中物体所在位置,而本文提出的模型ViT-SST效果相比较之下更好。
实验结果显示ViT-SST很好地平衡了模型参数量、模型计算量和模型分类精度之间的关系。与模型压缩算法相比,ViT-SST在模型参数量和计算量相同的情况下,图片分类精度大幅度领先;与ResNet34、ResNet50相比,ViT-SST在模型参数量降低为原来的1/100,计算量减少一半的情况下,CIFAR-10和CIFAR-100分类精度均损失小于4.4个百分点,MNIST分类精度差距小于0.2个百分点。
Efficient Transformer部分则以ViT-Lite为基准。在该部分实验中本文对比了性能最为优越的几种高效Transformer结构。为了公平比较,实验将模型参数量提升至和对比方法相同,命名为ViT-Lite-SST。实验结果表明ViT-Lite-SST在参数量不超过对比方法、MACs值几乎相同的情况下各数据集都取得了最高分类精度。此外,实验结果显示ViT-Lite-SST在略微增加计算量的情况下,模型参数量比ResNet34以及ResNet50要更低,分类精度更高。
3.3 NKP-SVD方法评估
本节使用ViT-Base结构进行实验,以下均简称为ViT。实验结果表明,基于SVD分解的克罗内克积近似分解法可以将ViT的预训练参数矩阵经过分解后加载到ViT-SST中。实验结果如表2所示,ViT-SST-NKP表示ViT-SST模型在加载经过NKP-SVD法分解的预训练参数,从表中可以看出模型性能都有所提升,在CIFAR-100上提升得最多。甚至在Caltech101和Caltech256数据集上,模型性能超过了不加载预训练参数的标准ViT。这可能是因为标准ViT参数量过大所以在这些数据集上出现了过拟合问题,而压缩过后的ViT-SST由于参数量更小,模块结构更简单,所以缓解了过拟合问题。
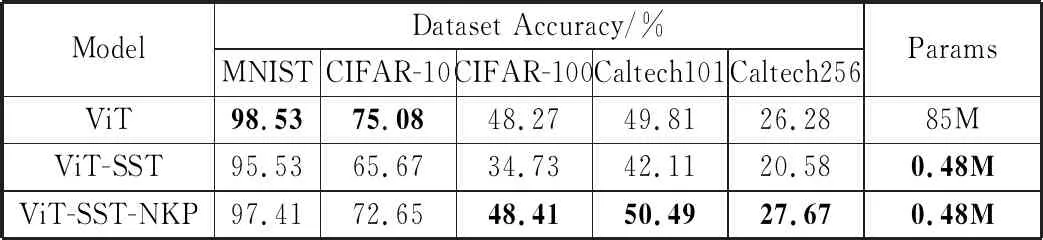
表2 是否使用NKP法加载参数的模型在各数据集精度
模型ViT与模型ViT-SST-NKP在CIFAR-10数据集上训练过程的图片识别精度变化曲线如图4所示,损失值变化曲线如图5所示。ViT模型在训练的第10代到第20代精度几乎不再上升,而损失值反而上升,这是过拟合的表现。而ViT-SST-NKP损失值则一直在缓慢下降,图像识别精度也慢慢上升并趋于平稳,缓解了过拟合的情况,所以最终的识别精度也高于ViT模型。
4 结束语
本文提出了一种基于克罗内克积分解的可分离结构全连接层。通过将普通全连接层转换为可分离结构的全连接层,既降低了模型参数量又避免了注意力矩阵低秩,这使得模型表达能力不因压缩或加速而严重受损。实验结果显示本文提出的方法优于当前模型压缩方法和注意力机制加速方法。同时,为了解决ViT模型预训练参数无法使用且重新预训练代价太大的问题,本文提出了一种基于Singular Value Decomposition(SVD)的参数矩阵克罗内克积近似分解法。该方法可以将公开的ViT模型预训练参数分解后与ViT-SST模型参数尺寸匹配。实验结果表明,该方法可以略微缓解标准ViT模型在小数据集上的过拟合现象,提升了模型分类精度。该方法也为解决Transformer模型预训练难的问题提供了一种解决思路。
