超高效液相色谱-四极杆/飞行时间质谱鉴别红葡萄酒的品种和产地
2022-10-17韩静雯李国辉钟其顶王道兵樊双喜刘洋
韩静雯,李国辉,钟其顶,王道兵,樊双喜,刘洋
(中国食品发酵工业研究院有限公司,北京,100015)
葡萄酒是由水、糖、有机酸、酚类和挥发性化合物组成的复杂混合物,GB/T 15037—2006《葡萄酒》中定义葡萄酒为以鲜葡萄或葡萄汁为原料,经全部或部分发酵酿制而成的,含有一定酒精度的发酵酒。自2003年以来,葡萄酒的质量评价以及品种、产地真实性的研究也逐步深入。由于我国对于葡萄酒品种鉴别和原产地认证手段都还不够成熟,缺乏相应的检测方法予以支撑。以次充好虚报品种和产地的葡萄酒产品极大地损害了消费者以及葡萄酒行业的经济利益,因此急需建立我国葡萄酒真实性鉴别的有效手段。
目前用于葡萄酒品种、产地鉴别的主要有稳定同位素技术[1-3]、气相色谱质谱联用技术[4-6],高效液相色谱技术[7]和红外光谱技术[8]等。葡萄酒中物质的组成和数量与气候条件、土壤、葡萄品种等因素息息相关,可利用挥发性成分和元素信息等非靶向或靶向代谢指纹图谱分析判别葡萄酒差异相关的特征性化合物,从而进行不同品种和产地等信息的区分[9-10]。化学计量学的逐步发展使得主成分分析(principal component analysis, PCA)、偏最小二乘判别分析(partial least square-discriminant analysis, PLS-DA)、支持向量机(support ector machine, SM)和随机森林(random forest, RF)等被广泛应用于食品领域进行品种鉴别和产地溯源[11-14]。此外,非目标筛查与多元统计分析相结合可大幅提升对不同地理环境的葡萄酒鉴别的准确率[7]。超高效液相色谱-四极杆飞行时间质谱(ultra-performance liquid chromatography-quadrupole-time-of-flight-mass spectrometry,UPLC-QTOF-MS)技术具有良好的分离能力、分辨率高、检测限低并且能够测定样品成分和物质结构的特性,在葡萄酒的质量和真实性方面有很好的应用前景[11]。本研究以不同品种和产地的国产红葡萄酒为对象,基于UPLC-QTOF-MS进行葡萄酒代谢组学分析,结合化学计量学手段,通过不同预测模型逐步对国产红葡萄酒的品种和产地进行鉴定,通过综合考虑不同模型之间正确率的对比以及各个模型对于异常点的容忍度和过拟合的可能性,选择最优预测模型,为葡萄酒真实性鉴别提供方法支撑。
1 材料与方法
1.1 实验仪器
Agilent 1290-6546超高效液相色谱-四极杆飞行时间质谱仪(配备Dual AJS ESI源),美国Agilent公司。
1.2 实验试剂和样品
甲酸(质谱纯,≥99%),上海麦克林生化科技有限公司;甲醇(质谱纯,99.9%),赛默飞世尔科技有限公司;超纯水,美国Millipore公司。
所选样品均为单一葡萄品种酿造,同时包含不同的品种、产地和年份信息,样品年份范围为2015年—2019年,主要集中在2017年和2018年。样品品种和产地信息如表1、表2所示。
1.3 实验方法
1.3.1 样品的制备
准确量取1 mL红葡萄酒样品与2 mL甲醇置于玻璃管中,涡旋混匀后取2 mL经0.22 μm有机滤膜过滤后置于进样瓶中,以供UPLC-QTOF-MS检测。
质量控制(quality control, QC)样品制备:所有待测样品每个取0.5 mL置于三角瓶中,混合均匀,取混匀后的液体1 mL与2 mL甲醇置于玻璃管中,涡旋混匀后取2 mL经0.22 μm滤膜过滤后置于进样瓶中,以供UPLC-QTOF-MS检测。
1.3.2 试剂配制
流动相A:0.1%(质量分数,下同)甲酸水溶液;流动相B:100%甲醇。
1.3.3 色谱条件
色谱柱:ZORBAX Eclipse Pluse C18(2.1 mm×100 mm,1.8 μm);柱温40 ℃;进样量2 μL;流速0.3 mL/min;梯度洗脱程序见表3。

表3 正模式梯度洗脱程序Table 3 Gradient elution procedure in positie mode
1.3.4 质谱条件
在正模式下进行全扫描检测。
参数设置:毛细管电压3 500 ;干燥气温度300 ℃;干燥气流速6 L/min;雾化气压力241.3 kPa;鞘气温度350 ℃;鞘气流速11 L/min;碎裂电压120 ;质量扫描范围m/z50~1 700;采集速率2 spectra/s;参比离子m/z121.050 873和m/z922.009 798。
1.4 数据处理与统计分析
将在MassHunter Workstation(美国Agilent公司)采集的谱图数据使用Profinder 10.0和Mass Profiler Professional(MPP)进行统计学分析并建立预测模型。
2 结果与分析
2.1 UPLC-QTOF-MS方法
UPLC-QTOF-MS不需要复杂的前处理过程,具有液相色谱中良好的分离机制,被视为代谢指纹图谱分析的有效工具[15],其能够在不需要标准物质的情况下对复杂样品中的化合物成分进行鉴定和分析,具有高分辨率、高灵敏度、高选择性和高精度的优点,能够提供更加精确的相对分子质量和结构信息[16]。本研究对红葡萄酒进行非靶向指纹图谱分析,在没有具体的目标物质的情况下,对液相色谱分离和质谱检测在通用的方法参数基础上加以优化,以获得包含尽可能多的化合物信息的样品数据。方法采用反相高压色谱柱和梯度洗脱使得红葡萄酒样品中不同极性的化合物能够在高水相向高有机相转变过程中有效分离,在流动相水相中添加0.1%的甲酸能够一定程度上帮助物质电离[14],所有的化合物可在16 min内被洗脱,m/z的范围选择50~1 700,仪器在扫描过程中会自动对参比离子进行检测,以此来对样品中检测到的物质进行质量校准。
2.2 提取稳定化合物
图1所示为以正模式扫描的QC样品总离子流色谱图。将获得的QC数据导入Profinder中进行递归特征提取,通过峰高、保留时间和质量进行筛选,共筛选出1 470个特征化合物,在此基础上在MPP中过滤掉变异系数(coefficient of ariation,C)≥20%的不稳定化合物,获得970个C<20%的稳定化合物。样品数据分组导入Profinder并依据获得的稳定化合物进行目标特征提取,获得样品数据的PFA文件。在MPP中将所有数据用中位数对齐,建立预测模型。

图1 质控样品总离子流色谱图Fig.1 Total ion chromatograms of QC samples
2.3 建立预测模型
2.3.1 PCA
PCA技术能够提取分析原始数据中有效的化学信息作为新的主成分变量,有效地降低数据维度,选取方差最大的几个主成分,通过对比不同组别样本间的差异性建立分组模型[17-18]。将经QC数据筛选后的样品数据导入MPP进行PCA,红葡萄酒品种和产地的PCA结果见图2。无论品种还是产地的样本数据都相互交叠、重合程度极大。品种鉴别中3个主成分变量贡献率分别为15.61%、9.81%和8.09%,产地鉴别中3个主成分变量贡献率分别为15.33%、9.45%和7.91%,累计贡献率为32.69%,小于35%,贡献率低。提取的有效数据信息不充分,因此,PCA模型均无法成功区分葡萄酒品种和产地。
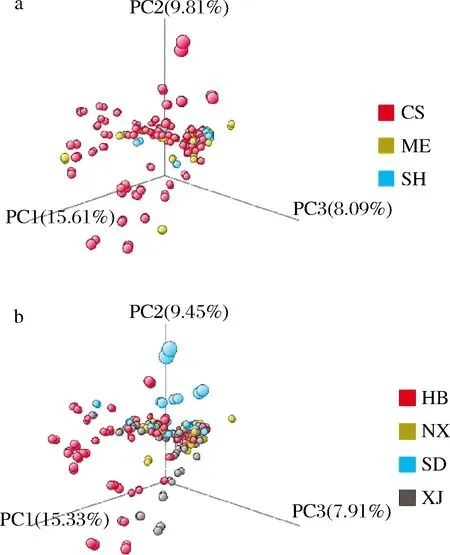
a-品种;b-产地图2 品种和产地的PCA图Fig.2 PCA of ariety and origin
2.3.2 PLS-DA
为了解决PCA模型主成分贡献率低,无法对样品的品种和产地进行区分的问题,进一步使用PLS-DA对样品数据进行分析。PLS-DA可以同时实现多元线性回归和主成分分析[10,19],相较于PCA模型,PLS-DA模型除了对数据进行降维处理,还能实现预测模型的构建,通过有监督的模式更好地明确样本组间关系。PLS-DA模型对红葡萄酒样品品种和产地的分类可视3D模型见图3。图3-a中可看出3个品种数据点各自形成清晰可见的聚集分布,分类效果较好,图3-b中4个产地分组间仍有较大部分的重叠。从正确率来看,模型对于样品的品种和产地的识别能力均为100%,但对于品种鉴别的预测能力为83.81%,对于产地溯源的预测能力为71.43%。
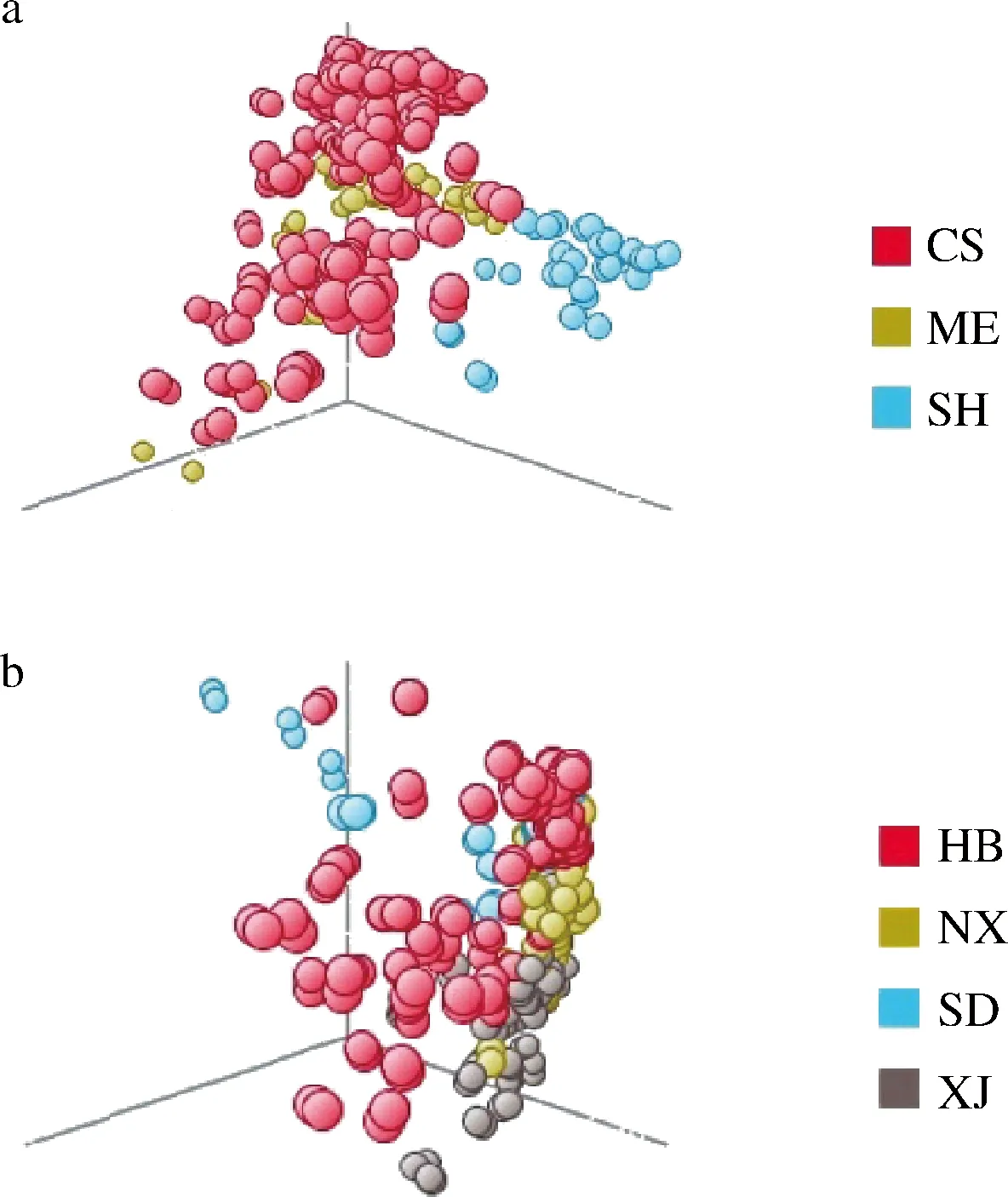
a-品种;b-产地图3 品种和产地的PLS-DA图Fig.3 PLS-DA of ariety and origin
在品种鉴别的交叉验证中赤霞珠、梅鹿辄和西拉的分类正确率分别为81.12%、80.95%和100.00%(表4);在产地溯源的交叉验证中河北、宁夏、山东和新疆的分类正确率分别为71.97%、78.57%、50.00%和80.00%(表5)。根据这种有监督的分析,可以注意到西拉与其他2个品种差异较大,品种预测中赤霞珠和梅鹿辄正确率相对较低,但仍明显呈现出聚类分布的趋势,表明3个品种酿酒葡萄所生产的葡萄酒中的化合物组成存在一定程度的差异。产地预测中正确率低于80%,模型预测结果中,各个样本组中被错误分类的样品散落在其他几个样本组之间,没有统一性,其葡萄酒数据间存在异常点,需要采用更为稳定与对异常点容忍度更大的模型进一步分析。
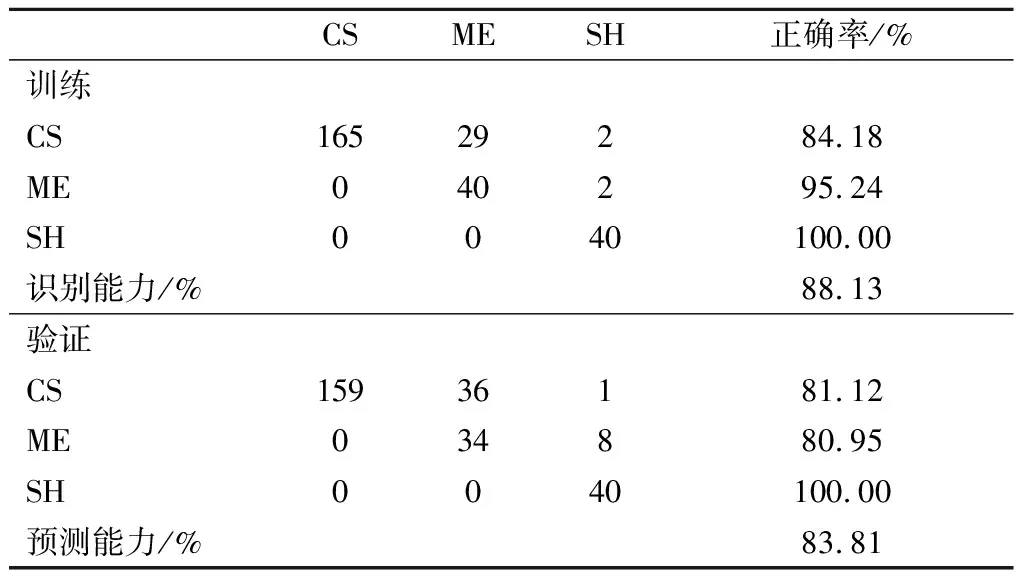
表4 PLS-DA模型的品种分类结果Table 4 The oeriew of ariety classification results obtained by PLS-DA model
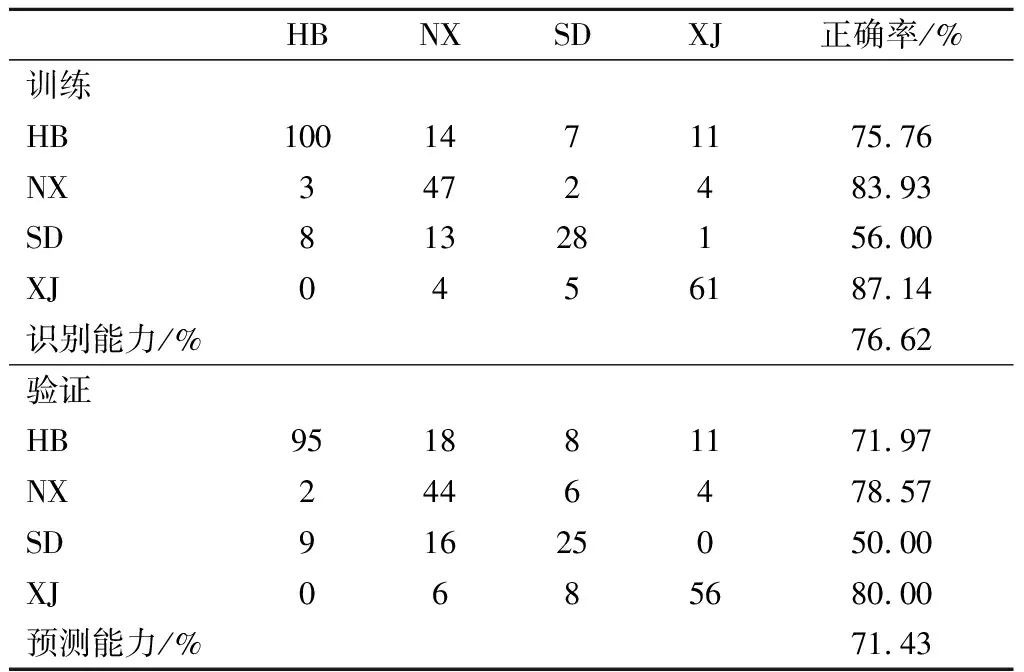
表5 PLS-DA模型的产地分类结果Table 5 The oeriew of origin classification results obtained by PLS-DA model
2.3.3 SM
SM模型作为一种常见的广义线性分类器,一般用于分类与回归问题的研究,对数据异常点的容忍度优于PLS-DA,适用于较小的数据集,不容易造成过拟合现象[13,20]。本次构建的SM模型采用线性核函数和留一法交叉验证,对于样品的品种和产地和识别能力均为100%,对于品种鉴别的预测能力为97.48%,对于产地溯源的预测能力为85.07%(表6、表7)。训练集和测试集的整体正确率较高,各个组别自身正确率除山东产地外均在80%以上,山东产地仅为64.00%(表7)。品种模型的训练和预测正确率十分优异,3种酿酒葡萄所酿造的葡萄酒之间的差异明显。但有13个山东产地的红葡萄酒样品被识别为了河北产地样品,导致产地预测正确率出现了较大的偏差,这可能是由于山东省与河北省葡萄的主要种植地均在沿海地区,其地理环境、土壤条件以及种植方式均有相似之处,使得2个产地葡萄酒在一定程度上具有相同的化合物信息,导致无法正确分类。尽管SM对于数据异常点的处理较为优异,但仍然会受到相似性较大的数据点的影响,且组间样本量差异较大,对模型分类预测结果造成影响。
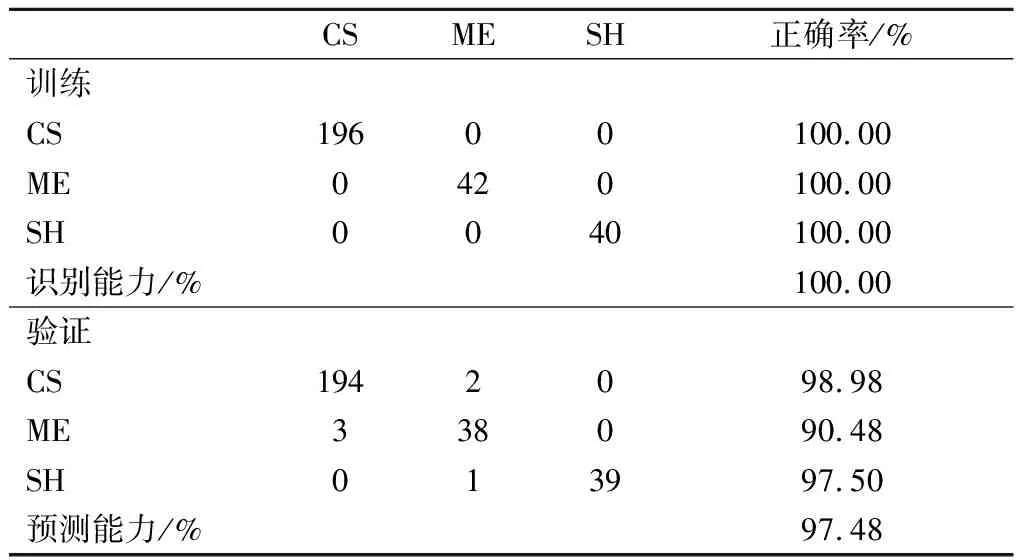
表6 SM模型的品种分类结果Table 6 The oeriew of ariety classification results obtained by SM model
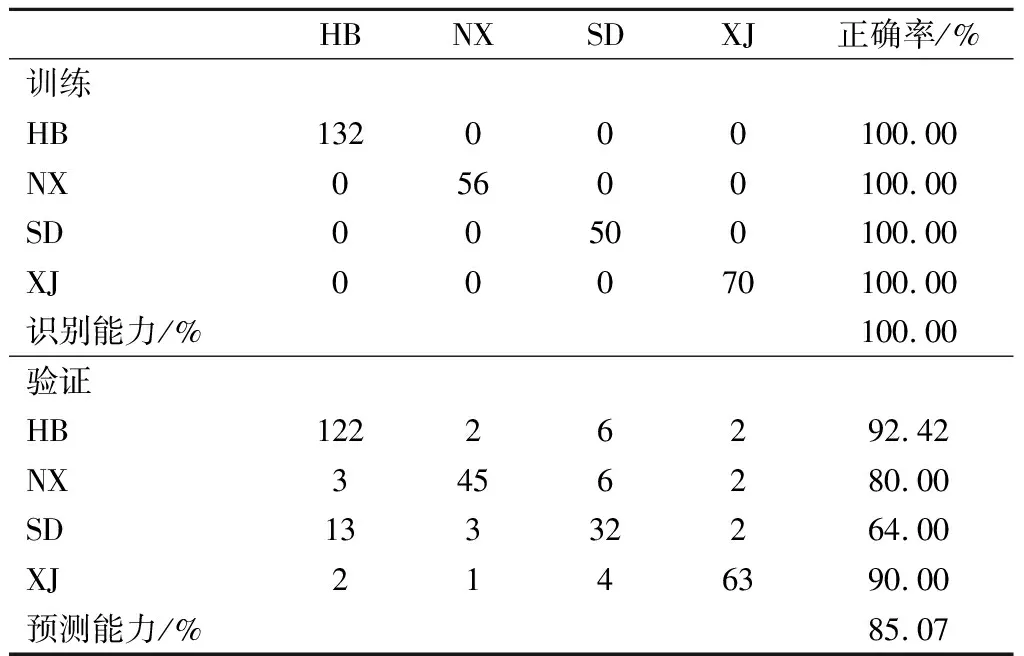
表7 SM模型的产地分类结果Table 5 The oeriew of origin classification results obtained by SM model
2.3.4 RF
为了进一步避免数据异常点对于模型的影响,使用对于异常点不敏感的RF,其作为一种非线性分类与回归方法[21],区别于SM需要对多项参数进行调整优化,更为简单直接,从原始样本中抽取多个样本单独进行决策树建模,通过对大量决策树的预测汇总,投票得出最终预测结果,提高了模型的预测精度,一定程度上避免了过拟合等问题的出现[22-23]。图4给出了决策树≤500时红葡萄酒样品品种和产地分类的袋外误差结果,在保证模型有效的基础上设置尽可能少的决策树个数以节省建模所需时间。品种鉴别中误差最低点为0.003 597 122,对应的最小决策树个数为257,产地溯源中误差最低点为0.012 987 013,对应的最小决策树个数为259。
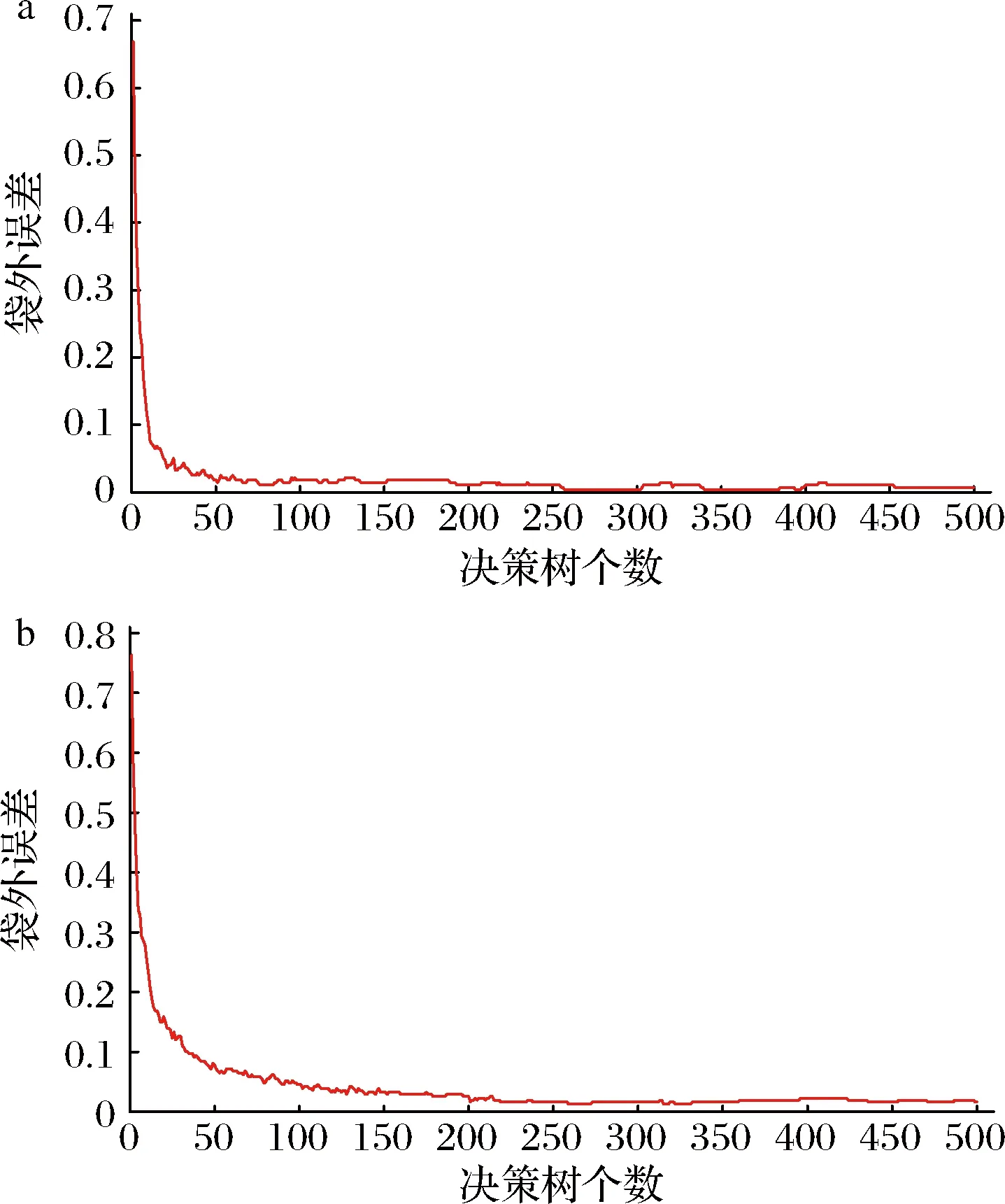
a-品种;b-产地图4 品种及产地溯源袋外误差Fig.4 Out-of-bag error of ariety identification and origin traceability
根据筛选出的最小决策树个数分别建立预测模型(见表8和表9)。2个模型在训练过程中没有出现错误分类,即识别能力均为100.00%,表明RF模型能够分别对红葡萄酒的品种和产地进行有效区分。整体品种分类的预测正确率为99.64%,赤霞珠、梅鹿辄和西拉的分类正确率分别为100.00%、97.62%和100.00%;整体产地分类的预测正确率为98.70%,河北、宁夏、山东和新疆的分类正确率分别为100.00%、98.21%、96.00%和98.57%。在针对2个模型的验证中,所有组别的正确率均高于96.00%,验证了RF模型的有效性。
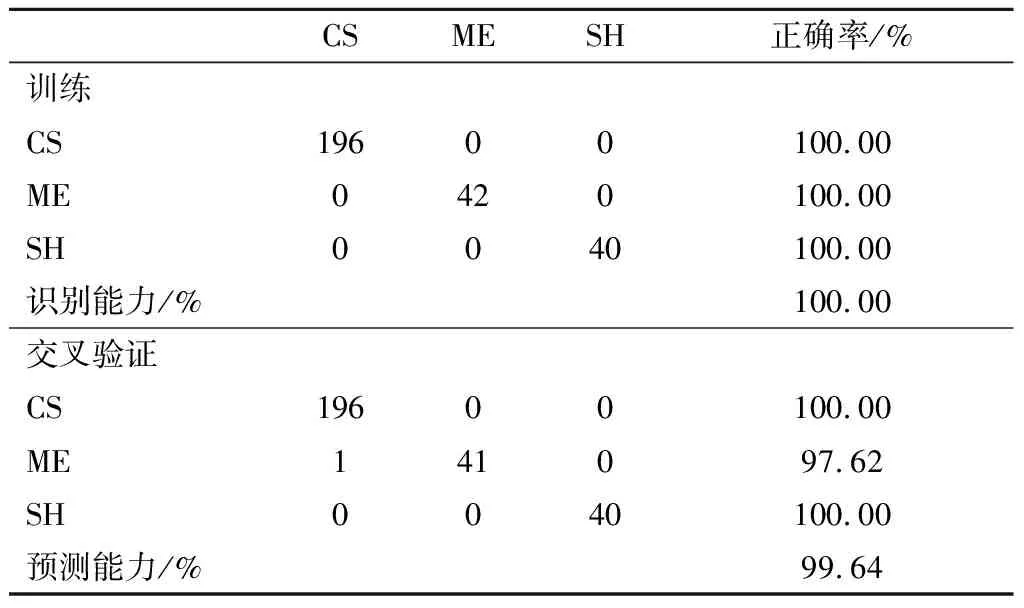
表8 RF模型的品种分类结果Table 8 The oeriew of ariety classification results obtained by RF model
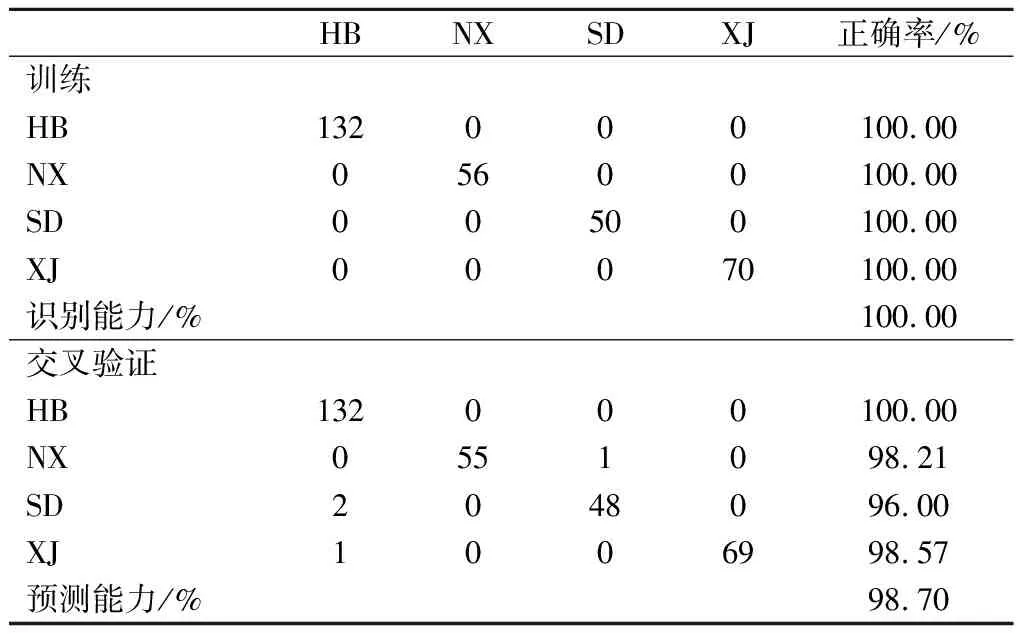
表9 RF模型的产地分类结果Table 9 The oeriew of origin classification results obtained by RF model
本实验选取的3个葡萄品种赤霞珠、梅鹿辄和西拉在色素、花青素和一些酚类物质的种类和含量存在显著差异[24],使得建立模型的干扰较少,较易得到准确率优异的品种预测模型。产地模型中克服了河北与山东产地样品数据间的相似性,仅有2个山东产地样品被识别为河北产地,有效避免了过拟合问题。同时,本研究在前期对数据进行了过滤以及特征化合物提取,筛选出的特征化合物在建立预测模型时更具有优势,相较于同类研究仅使用部分目标酚类化合物及部分代谢物建立的RF预测模型(正确率91.75%)[25],预测正确率更高,性能更好。
3 结果与讨论
使用UPLC-QTOF-MS在全扫描模式下对红葡萄酒进行了代谢指纹图谱分析,在获得丰富信息数据的基础上对红葡萄酒进行品种鉴别和产地溯源具备可行性。不同葡萄品种(赤霞珠、梅鹿辄和西拉)酿制的红葡萄酒除在PCA模型中无法实现聚类之外,在其他3种模型中均呈现出了较好的分类正确率,尽管各品种中包含了来自全国各地不同产地的信息,但其自身的差异性较小,识别率较高。而来自不同产地(河北、宁夏、山东和新疆)的红葡萄酒受到产地间相似地理环境、土壤条件和种植方式等因素的影响,存在较多异常点信息,PCA和PLS-DA模型均无法实现准确分类,而对于异常点容忍度优异,过拟合现象发生概率较小的SM和RF模型,成功实现了对于不同产地的准确分类。本研究通过多元化、多维度的非靶向数据源构建了系统的预测模型,鉴别不同品种和产地的葡萄酒,从而建立了我国葡萄酒真实性鉴别的有效方法。
但同时,本实验在样品设置上存在一些不足,由于中国酿酒葡萄的主要种植品种为赤霞珠,因此无论是品种样品设置还是产地样品设置中赤霞珠都占据了大多数。各个产地的主要酿酒葡萄种植品种存在差异,使得产地模型的建立存在较大的干扰。另外,由于时间对葡萄酒的影响较大,尽管本次样品中涵盖了不同的时间信息,但差距较小,在未来的研究中,可以对葡萄酒中组分随着时间产生的变化进行探究,进一步分析本研究中的2个模型是否具有长期的适用性,以及如何进行适度的更新调整,从而建立更加完善可靠的葡萄酒分析预测模型。
