结合残差BiLSTM 与句袋注意力的远程监督关系抽取
2022-10-16江旭钱雪忠宋威
江旭,钱雪忠,宋威
(江南大学人工智能与计算机学院,江苏无锡 214112)
0 概述
实体关系抽取作为信息抽取、自然语言理解、信息检索等领域的核心任务和重要环节,可从非结构化和程序化的文本中提取实体之间的语义关系,为用户提供更加精准全面的信息。实体关系抽取通常是在非结构化和程序化的文本中提取二元关系并组成关系三元组的形式,例如
在现有关系抽取方法中,监督关系抽取的准确率较高,但耗费大量人力资源。远程监督关系抽取方法通过数据自动对齐方式解决了大量无标签数据的自动标注问题,并且能够大幅减少标注成本,但存在知识库标注的句子有噪声、实体与关系之间表示不明确、无法准确表达句子与实体之间关系等问题。针对这些问题,研究人员提出了一系列解决方案。文献[1]提出图卷积网络,能够处理具有广义拓扑图结构的数据,并深入挖掘其实体和关系特征。文献[2]结合多实例与分段卷积神经网络(Piecewise Convolutional Neural Network,PCNN)进行远程监督关系抽取。文献[3]引入注意力机制,利用句子与关系来分配权重,通过对正确的句子与关系分配较高的权重,提升了关系抽取性能。随着深度学习技术的发展,神经网络[4-5]被广泛应用于远程监督关系提取。文献[6]提出分段卷积神经网络来建模句子表示,并选择准确的句子作为句袋表示。文献[7]使用多种神经网络作为句子编码器,并提出一种句袋内注意力机制,通过句袋中所有句子表示的加权和来计算句袋。文献[8]采用类似的注意力机制,并结合实体描述来计算权重。文献[9]提出一种软标签方法来降低噪声实例的影响。文献[10]采用双向长短时记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络来提取句子特征,使用注意力机制来识别噪声句子以及句袋。
上述远程监督关系抽取方法利用句子嵌入的加权和来表示句袋[11],以关系感知的方式计算句袋内的注意力权重,并在训练阶段使用相同的句袋表示来计算该句袋被分类到每个关系中的概率,然而这种采取先识别实体再预测关系的端到端抽取方式会导致前一个任务的错误传递到下一个任务,并且忽略了实体与各个关系之间的联系。为解决上述问题,本文提出基于残差BiLSTM(ResNet_BiLSTM)与句袋内和句袋间注意力机制的实体关系抽取模型。通过句子嵌入的加权和计算关系感知句袋,并结合句袋注意力模块,在模型训练过程中动态计算句袋注意力权重,以解决句袋噪声问题。
1 基于ResNet_BiLSTM 与句袋注意力的关系抽取
本文提出一种基于ResNet_BiLSTM 与句袋注意力的关系抽取模型,用于远程监督关系抽取。g={b1,b2,…,bn}表示一组远程监督给出的具有相同关系标签的句袋,n是句袋数量表示句子数为m的句袋,表示在第i个句袋中的第j个句子,jm表示第j个句子长度,模型框架如图1 所示,主要包括以下模块:

图1 基于ResNet_BiLSTM 与句袋注意力机制的关系抽取模型框架Fig.1 Framework of relationship extraction model based on ResNet_ BiLSTM and sentence bag attention mechanism
1)句子编码器。给定一个句子和句子中两个实体的位置[12],得到句子的输入表示。
2)ResNet_BiLSTM 特征提取器。由句子编码器得到的输入句子表示,通过输入ResNet_BiLSTM 得到句子特征[13]表示。
3)句袋内注意力机制。给定句袋bi中所有句子的句子表示和关系嵌入矩阵R、注意力机制权重向量和句袋表示来计算所有关系,其中k为关系索引。
4)句袋间注意力机制。给定一组句袋g,通过基于相似性的注意力机制来进一步计算权重矩阵β,得到句袋组的表示。
1.1 句子编码器
句子的特征编码由词和词的位置特征表示,在句子中每个词被映射成一个dw维度的词嵌入,句子的特征向量表示为,位置特征[14]是每个词到实体之间的距离,表示为,将位置特征映射成dp维的词嵌入,这3个向量的连接向量为dw+2dp维的向量,表示为
1.2 ResNet_BiLSTM 特征提取器

其中:F(x)为BiLSTM 输出门通过线性变换得到。F(x)计算如式(8)所示:

其中:Whf为随机初始化权重矩阵。
1.3 句袋内注意力机制
Si∈表示句袋bi中所有句子表示,表示关系嵌入矩阵,其中h是关系数量。与传统方法不同,传统方法推导了关系分类的统一句袋表示,本文方法在所有可能的关系条件下计算句袋bi的表示:

其中:rk是关系嵌入矩阵R2的第k行;T是训练样本集合。
最终句袋bi表示为矩阵,每行对应于此句袋中可能的关系类型。
1.4 句袋间注意力机制
为解决句袋带噪问题,设计一种基于相似性的句袋间注意力模块[16]来动态地降低带噪句袋的权重。如果两个句袋bi1和bi2都被标记为关系k,则和应该关系更接近,给定一组具有相同关系标签的句袋,将更高的权重分配给该组中与其他句袋接近的句袋,句袋组g可表述如下:

其中:g∈;βik组成注意力权重矩阵β∈Rn×k。βik计算如式(13)所示:

其中:γik表示用第k个关系标记句袋bi的置信度[17]。受到自注意力机制的启发[18],γik使用向量本身计算一组向量的注意力权重,根据它们自身表示计算句袋的权重。γik计算如式(14)所示:

函数相似性计算如式(15)所示:
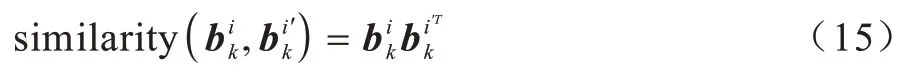

然后第k个关系得分ok通过句袋组g和关系嵌入rk计算得到,如式(17)所示:

其中:dk是偏置项。
最后使用Softmax 函数获得句袋组g被分类为第k个关系的概率,如式(18)所示:

需要注意的是,相同的关系嵌入矩阵R用于计算式(11)和式(16),类似的dropout损失率用于句袋表示Bi以防止过拟合。
1.5 模型实现过程
基于ResNet_BiLSTM 与句袋内和句袋间注意力机制的关系抽取模型实现过程具体如下:
1)数据处理。首先训练集中的所有句子包含相同的两个实体,将其累加到一个句袋,然后对于每n个共用的句袋,将相同的关系标签放入一个句袋中,需要注意的是,一个句袋组是一个训练样本。因此,该模型也可以在小批量模式下通过打包多个句袋组成一批句袋。
2)目标函数优化。优化公式如式(19)所示:

其中:θ是模型参数集,包括单词嵌入矩阵、位置特征嵌入矩阵、权重矩阵和关系嵌入矩阵;J(θ)通过mini-batch随机梯度下降法(Stochastic Gradient Descent,SGD)来优化模型[20]。
3)训练和测试。在训练阶段,将具有相同关系标签的n个句袋累积到1 个句袋组中,并计算句袋表示的加权和,以获得句袋组g的表示。由于每个句袋的标签在测试阶段是未知的,因此在处理测试组时,每个句袋被视为一个句袋组(即n=1)。此外,与文献[15]类似,仅对正样本应用句袋间注意力机制,其原因是表示无关系的句袋表示形式是多样的,难以计算权重。
4)预训练。在实验中采用预训练策略,首先对模型进行句袋内训练,直到收敛,然后添加句袋间注意力机制模块,进一步更新模型参数,直至再一次收敛。初步的实验结果表明,预训练策略相比于句袋间注意力机制能够获得更好的模型性能。
2 实验设置与结果分析
2.1 数据集和评价指标选取
实验采用NYT(New York Times)数据集。该数据集由文献[21]发布并得到广泛使用,基于远程监督关系提取研究,将Freebase 知识库中的三元组和NYT 数据集中的文本对齐生成,包含52 个实际关系和1 个特殊关系NA,其中NA 表明2 个实体之间没有关联性。
在计算机上使用NVIDIA GTX 1080 Ti 显卡运行程序,采用精确率-召回率(Precision-Recall,PR)、曲线下面积(Area Under the Curve,AUC)和精确率(Precision,P)@N(P@N)[22]来评估模型性能。P@N采用One、Two 和All 测试集,其中,One 表示对测试集中每个实体对随机选择一个句子,通过这一个句子对关系进行预测,Two 表示对测试集中每个实体对随机选择两个句子,通过这两个句子对关系进行预测,All 表示对测试集中每个实体对选择所有句子对关系进行预测,mean 表示对求得的结果取平均值。P@N使用了前N个实例的准确率,其中N取100、200、300。
2.2 训练细节和超参数设置
在实验中,使用的多数超参数遵循文献[23]中的设置,如表1 所示。在初始化时采用文献[19]发布的50 维单词嵌入。2 个不同批量大小Np和Nt分别用于预训练和训练,使用训练集进行网格搜索来确定n的最佳值,n∈{3,4,…,10},Nt∈{3,4,…,200},Np∈{10,20,50,100,200}。需要注意的是,增加句袋组数量n可能会增强句袋间注意力,导致训练样本减少,当n=1 时,句袋间注意力的影响将消失。使用mini-batch SGD 的初始学习率为0.1,学习率在每100 000 步后下降至之前的1/10,在实验中仅包含句袋内注意力的预训练模型,在300 000 步内收敛,包含句袋间注意力的训练模型的初始学习率设置为0.001。

表1 实验超参数设置Table 1 Setting of experimental superparameters
2.3 模型性能对比
选取文献[24]中的11 种模型与本文ResNet_BiLSTM+ATT_RA+BAG_ATT 模型进行性能对比,其中,CNN、PCNN 和ResNet_BiLSTM 分别表示不同句子编码方式,ATT_BL 表示基于句袋内注意力,ATT_RA 表示基于关系感知的句袋内注意力机制,BAG_ATT 表示基于句袋间注意力。在训练阶段,用于计算注意力权重的关系查询向量被固定为与每个句袋的远程监督标签相关联的嵌入向量[25-26]。在测试阶段,所有关系查询向量都被应用于分别计算关系的后验概率,选择概率高的结果作为分类结果,给出所有模型的AUC 值的平均值和标准差如表2所示。
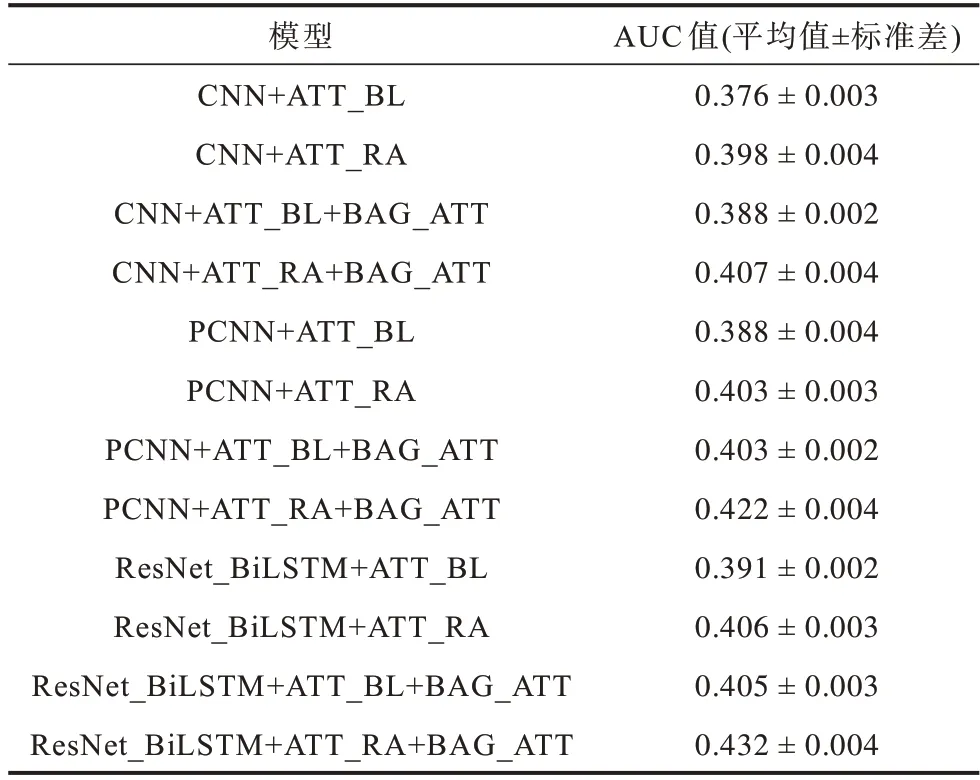
表2 不同模型的AUC 值比较Table 2 Comparison of AUC values of different models
为进行定量比较,还绘制了所有模型的PR 曲线图如图2~图4 所示。由图2~图4 可以看出:
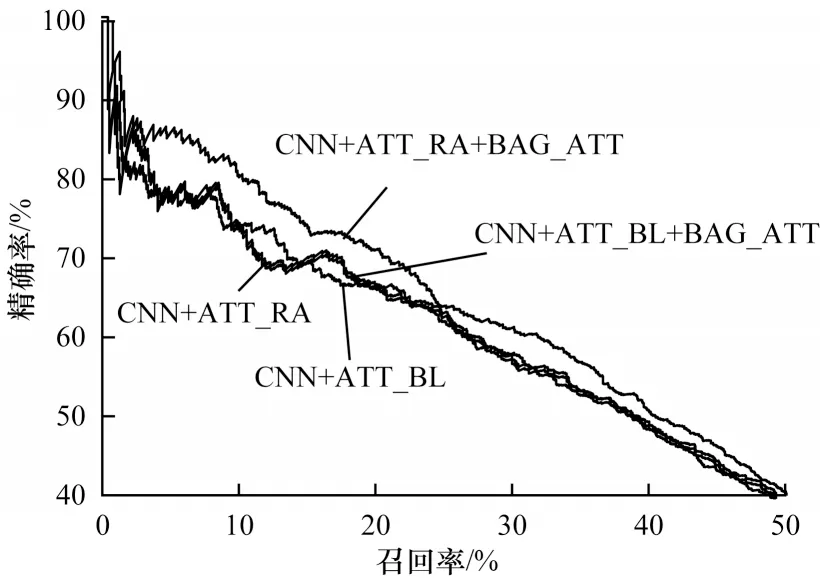
图2 CNN 句子编码的PR 曲线Fig.2 PR curves of CNN sentence coding

图3 PCNN 句子编码的PR 曲线Fig.3 PR curves of PCNN sentence coding

图4 ResNet_BiLSTM 句子编码的PR 曲线Fig.4 PR curves of ResNet_BiLSTM sentence coding
1)ResNet_BiLSTM 作为句子编码器相比于CNN、PCNN 表现更好。
2)使 用ResNet_BiLSTM、CNN 或PCNN作为句子编码器时,ATT_RA 优于ATT_BL,主要原因为ATT_BL 在训练时推导出句袋表示时仅考虑目标关系,而ATT_RA 以所有关系嵌入作为查询,计算出句袋内的注意力权重,提高了句袋表示的灵活性。
3)对于3 种句子编码器和2 种句袋内注意力机制,带有句袋注意力机制的模型相比于其他模型具有更好的性能,这一结果验证了句袋间注意力机制用于远程监督关系提取的有效性。
可见,将ResNet_BiLSTM 作为句子编码器并与句袋内和句袋间注意力机制相结合可获得最佳AUC性能。
2.4 句袋内注意力机制对模型性能的影响
通过实验验证句袋内注意力机制对模型性能的影响,随机选择实体对的1 句、2 句和所有句子进行测试并构造One、Two、All 这3 个测试集,实验结果如表3 所示。

表3 在3 种测试集上的模型P@N 比较Table 3 Comparison of P@N of models on three test sets %
由表3 可以看出,ResNet_BiLSTM+ATT_AL+BAG_ATT 具有较高的P@N值,无论采用ResNet_BiLSTM 还是BAG_ATT,ATT_RA 在所有实体对测试集上均优于ATT_BL。由于当一个句袋中只有一个句子时,ATT_BL 和ATT_RA 的解码程序是相同的,因此从ATT_BL 到ATT_RA 的改进可归因于ATT_RA 在训练阶段以关系感知的方式计算句袋内注意力权重。
2.5 句袋间注意力权重分布
将句袋中的句子数设置为5 进行句袋间注意力计算,每个句袋首先使用BAG_ATT 模型来计算句袋间注意力机制的权重,然后计算训练集各部分句袋间注意力权重的平均值和标准差,如表4 所示。由表4 可以看出,训练句子数量较少的句袋通常被分配较低的句袋间注意力权重,且训练句子数量较少的实体对更可能有不正确的关系标签。
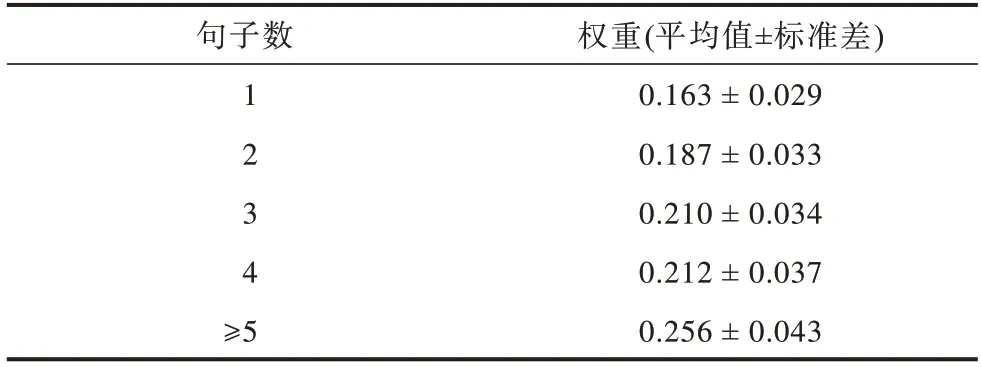
表4 不同句子数的句袋间注意力权重分布Table 4 Distribution of attention weight between inter-sentence bags with different number of sentences
3 结束语
本文提出基于ResNet_BiLSTM 与句袋内和句袋间注意力机制的实体关系抽取模型。引入残差连接采集句子特征信息,保留句子在前后传递过程中的特征信息。通过BiLSTM 进行句子特征信息识别与训练,解决了反向特征依赖问题。使用句袋内注意力机制,对正向实体与关系赋予更高权重,提高识别准确性。采用句袋间注意力机制,缓解了在提取句子中的关系时的噪声句袋问题。在NYT 数据集上的实验结果表明,该模型能够充分利用实体与关系特征,具有更好的关系抽取性能。下一步将使用实体关系与句子的分区过滤策略,并结合BERT 提取语义特征,进一步提高关系抽取的准确性和灵活性。
