基于深度学习的双目立体匹配方法综述
2022-10-16尹晨阳职恒辉李慧斌
尹晨阳,职恒辉,李慧斌
(西安交通大学 数学与统计学院,西安 710049)
0 概述
双目立体视觉是机器视觉的一种重要形式,其基于视差原理来获取被测物体的三维几何信息,在自动驾驶[1]、机器人[2]、工业检测[3]、遥感[4]以及三维重建[5]等诸多方面得到广泛应用,是计算机视觉领域的研究热点之一。立体匹配作为双目立体视觉的关键步骤[6],其匹配精度和匹配效率直接影响整个双目立体视觉系统的性能。
立体匹配是指从图像对中寻找具有同名特征的像素间对应关系的过程,通常可分为稀疏匹配和稠密匹配,本文主要关注稠密匹配。传统立体匹配方法通常包含匹配代价计算、代价聚合、视差计算和视差优化4 个步骤(或其中部分步骤的组合)[7]。传统立体匹配方法依据是否含有代价聚合步骤可分为局部匹配方法[8-9]、全局匹配方法[10-11]以及介于两者之间的半全局匹配方法[12-13]。
局部匹配方法也称为基于滑动窗口的匹配方法,通常包含立体匹配方法中的所有步骤。在代价计算步骤中,局部匹配方法采用像素灰度差绝对值AD(Absolute intensity Differences)、CT(Census Transform)[14]和归一化互相关(Normalized Cross-Correlation,NCC)[15]等度量函数计算匹配代价。在代价聚合步骤中,局部匹配方法采用的具体方法通常是:对于左右视图中的2 个像素,分别以这2 个像素为中心取相同大小的窗口(称为聚合窗口),逐个计算2 个窗口内同位置的像素之间的匹配代价并将其累加作为最终的聚合匹配代价。对于视差计算步骤,局部匹配方法常采用赢家通吃算法(Winner Takes All,WTA)直接进行视差搜索。对于视差优化步骤,一般采用左右一致性检查(Left-Right Check)算法剔除错误视差,并用中值滤波或双边滤波等平滑算法对初始视差图进行平滑,从而提高视差精度。
与局部匹配方法不同,全局匹配方法不包含代价聚合步骤,其认为视差图在全局范围内是平滑的,对于相邻像素视差值相差较大的情况需要加以惩罚,据此构造全局能量函数来代替局部匹配方法中的代价聚合步骤。在全局匹配方法中,整个图像的所有像素同时进行视差值求解,其能量函数通常包含数据约束项和平滑约束项。
半全局立体匹配方法(Semi-Global Matching,SGM)[12]也采用最小化能量函数的思想,但与全局匹配方法不同,SGM 将二维图像的优化问题转化为多条路径的一维优化(即扫描线优化)问题,聚合来自多个方向的路径代价,并利用WTA 算法计算视差,在匹配精度和计算开销之间取得了较好的平衡。
近年来,随着深度学习技术的发展,传统立体匹配方法中的代价计算、代价聚合、视差计算和视差优化等步骤均可被整合至深度神经网络框架中,并表现出了更优的性能。立体匹配技术的研究趋势逐渐从传统方法转向深度学习方法,并产生了一系列颇具代表性的研究成果。通常可将基于深度学习的立体匹配方法分为非端到端和端到端两类,其中,非端到端方法的共同特点是尝试利用深度神经网络取代传统立体匹配方法中的某一步骤,而端到端方法则以左右视图作为输入,直接输出视差图,利用深度神经网络直接学习原始数据到期望输出的映射。本文总结近年来所出现的基于深度学习的立体匹配方法,将其归纳为非端到端立体匹配方法和端到端立体匹配方法,对不同类方法的性能和特点进行比较与分析,归纳立体匹配方法当前所面临的挑战,并展望该领域未来的发展方向。
1 基于深度学习的非端到端立体匹配方法
早期基于深度学习的立体匹配方法较关注对传统匹配方法4 个步骤中的某一个或某几个单独进行设计优化。对于代价计算,非端到端立体匹配方法采用学习的特征替换手工设计的特征,然后使用相似性度量(如L1损失函数、L2损失函数,或通过神经网络学习得到的度量函数)得到代价体。对于代价聚合,非端到端方法通常采用学习的方式优化SGM[12]代价聚合步骤中人工设计的惩罚项,从而提升聚合效果。对于视差优化,基于深度学习的非端到端方法一般采用多阶段策略或引入残差信息来优化视差计算步骤得到的初始视差图。本文将分别从以上3 个角度介绍基于深度学习的非端到端立体匹配方法。
1.1 基于代价计算网络的非端到端方法
寻找可靠且稳健的代价计算函数是保证匹配正确率的首要步骤,因此,对于匹配代价计算步骤,基于深度学习的非端到端方法试图通过设计不同结构的卷积网络来学习更有效的特征和度量函数,将其用于代价计算从而提高立体匹配方法的精度。
文献[16]提出的MC-CNN 首次尝试将深度学习引入立体匹配任务。考虑到人工设计的代价函数鲁棒性不高,在反光、弱纹理等病态区域表现不佳,该文设计MC-CNN-acrt和MC-CNN-fst这2种网络结构,如图1所示,主要思想是通过深度神经网络学习图像块特征的相似性度量。在MC-CNN 网络的训练过程中,该文构建一个二分类数据集(相似的图像块对和不相似的图像块对),以有监督的方式进行训练。在MC-CNNacrt框架中,利用孪生网络(Siamese Network)对图像块进行特征提取,然后经过数个全连接层来计算输入的2 张图像块中心像素的相似性分数,以网络学习的隐式度量代替手工设计的显式度量函数。MC-CNN-fst 架构则采用显式的相似性度量(以向量内积取代MC-CNNacrt的全连接层),从而降低时间成本,但是其匹配精度略有下降。
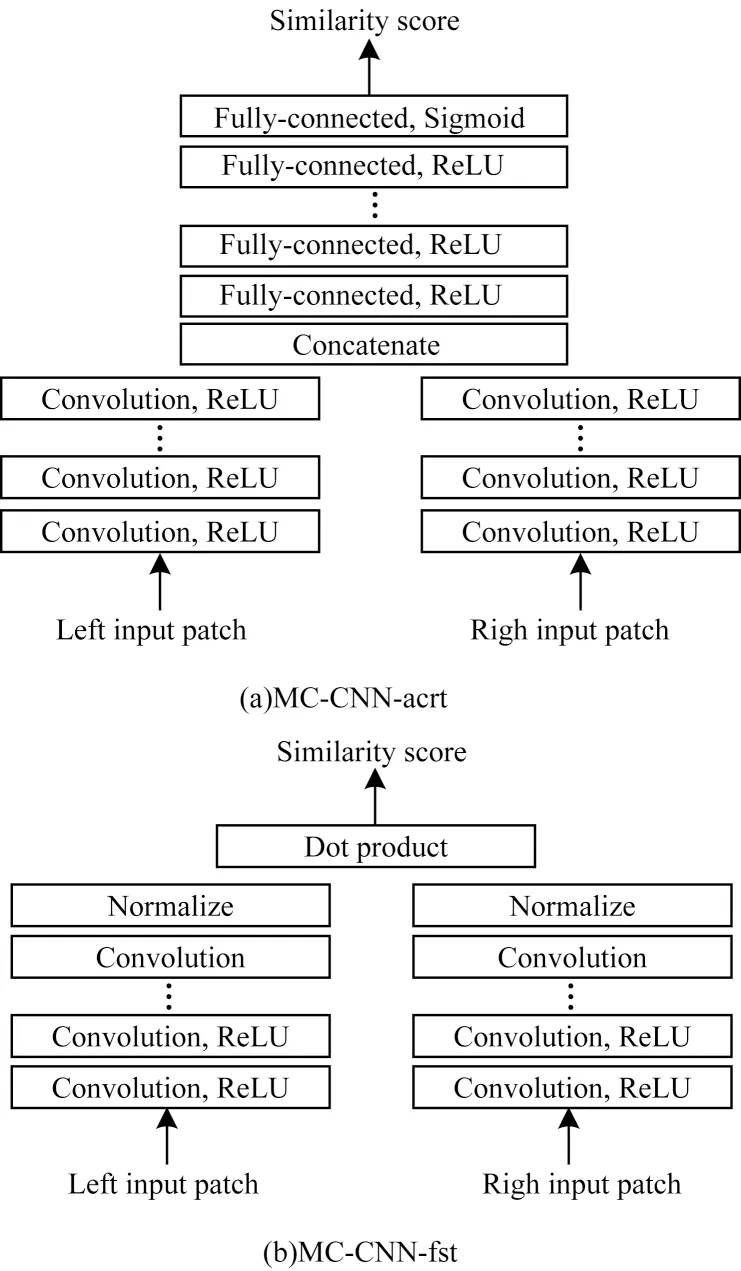
图1 MC-CNN 网络架构Fig.1 The network architecture of MC-CNN
在MC-CNN 之后,很多研究人员延续了其孪生网络基本架构,并专注于改进特征提取方式从而提高匹配精度。文献[17]提出的MatchNet 采用更多的卷积层来提取特征,并引入池化层以减小特征尺寸。文献[18]提出的Deep Embedding 通过在2 个并行的子网络中使用不同大小的卷积核进行多尺度特征提取,然后融合不同尺度特征并由匹配代价决策层处理得到匹配代价。文献[19]提出的Content CNN 不再采用MC-CNN[16]中的二分类训练方式,而是将立体匹配看作以视差作为类别的多分类问题,从而训练网络。文献[20]在最终的匹配代价决策层之前插入4P(Per-Pixel Pyramid Pooling)层,使用4 个不同窗口大小的池化操作将输出相连接以创建新特征,由于其生成的特征包含从粗到细的信息,使得网络在扩大感受野的同时不会丢失图像细节。文献[21]指出文献[20]中的金字塔池化层需要重新计算每个可能的视差,为此引入多尺度且步长为1 的池化模块,并将其位置由全连接层末端移至全连接层之前,在保证匹配精度的同时提高了计算效率。文献[22]提出的SDC(Stacked Dilated Convolution)模块利用4 个不同扩张率的并行空洞卷积来增加网络感受野,从而提取到更加有效的特征。文献[23]引入一致性和独特性2 个原则改进特征提取效果。文献[24]提出的合并双向匹配代价体(Coalesced Bidirectional Matching Volume,CBMV)网络架构,在训练时使用随机森林分类器将由神经网络学习的隐式代价函数与手工设计的显式代价函数相结合,使学习到的匹配代价函数在跨域迁移时泛化性更强。
上述基于代价计算网络的非端到端方法,其匹配效果表现证明了基于CNN 提取的特征相较手工特征更加准确有效,且用于特征提取的网络越复杂或训练数据集越大,提取的特征在匹配时性能表现越优。此类方法(如MC-CNN 等)尽管在KITTI等数据集上取得了远超传统方法的精度,但是由于它们大都采用孪生网络结构,然后通过数个全连接层(DNN)对提取的特征进行串联和进一步计算以获得最终的匹配代价,因此此类方法普遍存在时耗较高的问题。例如,假定图像大小为M×N,最大视差预设为D,孪生网络一次前向传播的时间为T,则代价体的构建就需耗时M×N×(D+1)×T。如果T值较大,此类方法将具有较低的时间效率,以MC-CNN 为例,其生成单张KITTI 数据集中的图像(1 226×370 像素)视差图就需耗时67 s,因此,此类方法大多因为时间复杂度较高而无法满足实际需求。
1.2 基于代价聚合网络的非端到端方法
代价聚合步骤的输入是由代价计算步骤得到的初始代价体,输出是优化后的代价体。在代价聚合步骤中,像素在不同视差下的匹配代价值会根据其邻域像素的代价值来重新计算,以此邻接像素间的联系,从而降低异常点的影响,提高信噪比。目前,传统方法中采用最广泛的代价聚合方法是由SGM[12]提出的基于扫描线优化的代价聚合方法,但SGM[12]中代价聚合的依据准则较为依赖先验知识,例如平滑项中不同惩罚参数的设置。SGM-Net[25]等基于深度学习的非端到端方法试图利用置信度学习和左右一致性原则来设计代价聚合网络以解决此问题。
文献[26]指出SGM 的代价聚合步骤中并非所有的像素都应具有相同的惩罚项,为此根据左右一致性原则用CNN 处理初始左右视差图,以得到每个像素的置信度,并在之后的代价聚合步骤中减小对高置信度像素的惩罚。在文献[26]工作的基础上,文献[25]针对SGM 需要人工调整惩罚参数的问题,提出SGM-Net,利用CNN 自动学习惩罚参数。如图2 所示,SGM-Net 的输入是小图像块和其归一化的位置参数,输出对3D 物体结构的惩罚项。在SGM-Net 的训练过程中,作者设计了一个包含路径代价和邻域代价的损失函数:路径代价考虑扫描线上的像素点视差与实际视差之间的路径成本,邻域代价则关注相邻像素视差之间的过渡成本。除此之外,SGM-Net 根据物体之间不同的遮挡关系,将沿扫描线的视差过渡分为正视差过渡和负视差过渡,保证其在病态区域也能有较好的视差预测效果。然而,由于SGM 中惩罚项无法被准确标记,因此网络必须在训练过程中设计包含3 个步骤的策略以生成惩罚项的弱标签,这就使得整个方法在训练过程中变得复杂且耗时。
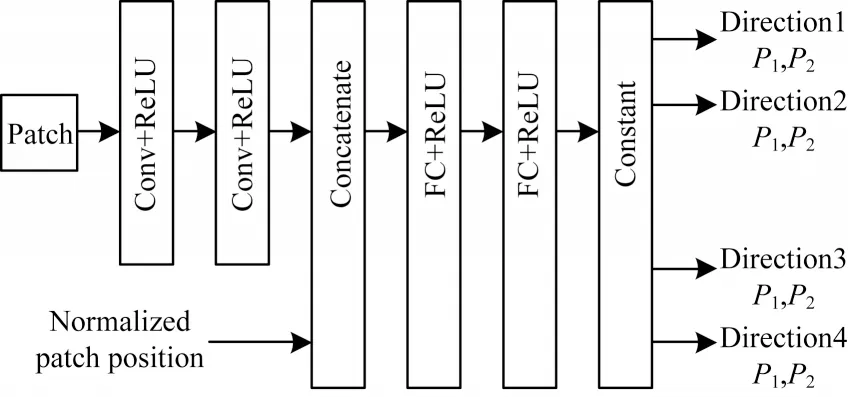
图2 SGM-Net 网络架构Fig.2 The network architecture of SGM-Net
文献[27]指出SGM[12]采取的扫描线优化方法会导致视差图出现条纹现象,其提出基于置信度的智能聚合策略,使用相应的置信度得分对每个独立路径计算的匹配成本进行加权求和。与此类似,文献[28]提出的SGM-Forest 也不再使用SGM[12]中原始的聚合方式来简单组合来自多个一维扫描线的匹配成本,而是训练随机森林分类器来融合多个方向的一维扫描线优化成本,针对图像中的每个位置都选择效果最优的扫描线路径。
1.3 基于视差优化网络的非端到端方法
视差优化是传统立体匹配方法流程中的最后一步,目的是剔除初始视差图中的错误视差,并得到优化后高质量的视差图。在深度学习兴起后,LRCR等[29]尝试利用基于置信度学习、逐步调优以及残差校正等思想设计深度神经网络,从而进行视差优化。
文献[30]提出名为λ-ResMatch 的多阶段框架,该框架利用深度残差网络学习匹配代价的度量,并采用SGM[12]中的代价聚合步骤处理代价体,再利用全局视差网络(Global Disparity Network,GDN)取代赢家通吃(WTA)算法计算得到视差图和置信度,而后利用置信度得分修正视差图,完成视差优化。文献[31]将视差优化分解为3 个子步骤:检测不正确的视差;用新视差替换不正确的视差;利用残差校正的思想对输出视差进行改善。该文将上述3 个子步骤嵌入在一个统一的卷积网络框架中,称为DRR(Detect、Replace、Refine)。由于DRR的输入是初始视差图,因此允许多次使用DRR反复优化视差图,使匹配精度进一步提升。然而,在用新视差替代不可靠视差时会造成计算资源浪费,增加了计算负担。文献[21]将视差优化分解为4 个子步骤:利用卷积网络对初始最优视差图和次优视差图进行融合;将融合后的视差图和原始图像作为输入,依次进行错误视差检测、并行视差替换和残差优化,与文献[31]不同,在并行视差替换的步骤中,并行的2 个沙漏状结构的子网络分别用来处理图像中的平滑区域和细节区域,进一步提高了视差预测的准确性。受残差网络思想的影响,文献[32]提出递归残差网络RecResNet(Recurrent Residual CNN),通过估计在多个分辨率下计算的残差组合来纠正不同类型的视差错误,最终生成优化后的视差图。该网络可用于优化由未知黑盒算法生成的视差图,并能周期性地应用于其自身的输出以进行进一步改进。与上述完全基于CNN 的视差优化方法不同,文献[29]按照RNN 模式搭建左右比较递归模型LRCR(Left-Right Comparative Recurrent),该模型可以同步执行视差估计与左右一致性检测,在每次重复的步骤中,模型会为左右视图同时生成视差图并进行左右一致性检测,以识别可能出现视差错误的区域。此外,LRCR 框架中引入了柔性注意力机制,用学习到的误差图引导模型在下个重复步骤中有选择性地关注不可靠区域的视差,从而逐步改善视差图的质量。值得注意的是,所有这些基于视差优化网络的非端到端方法都能取得出色的匹配精度,但是它们会受到高计算负担的影响,以最具代表性的LRCR[29]为例,其在当时的KITTI 数据榜单上取得了最好的结果,但处理一张图片的时间高达49.2 s。
2 基于深度学习的端到端立体匹配方法
上述基于深度学习的非端到端立体匹配方法本质上并未脱离传统方法的框架,一般仍需添加手工设计的正则化函数或视差后处理步骤,这意味着非端到端立体匹配方法具有计算量大和时间效率低的缺点,同时也未解决传统立体匹配方法中感受野有限、图像上下文信息缺乏的问题。随着MAYER等[33]首次成功地将端到端网络结构引入立体匹配任务并取得良好效果,设计更有效的端到端立体匹配网络逐渐成为立体匹配的研究趋势。从各立体匹配数据集的公开排行榜上可以发现,端到端方法在立体匹配任务中已然占据了主导地位。
如图3 所示,当前基于深度学习的端到端立体匹配网络以左右视图作为输入,经参数共享的卷积模块提取特征后按相关性操作(Correlation)或拼接操作(Concat)构建代价体,最后根据代价体的维度进行不同的卷积操作以回归出视差图。根据代价体维度的不同,端到端立体匹配网络可分为基于3D 代价体和基于4D 代价体的2 种方法,而具有级联视差优化效果的2D 编码器-解码器和由3D 卷积组成的正则化模块是当下分别用来处理3D 和4D 代价体的2 种结构。2D 编码器-解码器由一系列堆叠的2D CNN 组成,并带有跳跃连接,加入残差信息以提高视差预测效果。而3D 正则化模块的关键点则是在构建代价体时将提取的左右图特征沿视差维度进行拼接以得到一个4D 的代价体,而后使用3D CNN 处理4D 代价体,以充分利用视差维度信息。

图3 用于端到端立体匹配的2 种主流架构Fig.3 Two mainstream architectures for end-to-end stereo matching
2.1 基于3D 代价体的端到端立体匹配网络
基于3D 代价体的端到端立体匹配网络接近于传统密集回归问题(如语义分割、光流估计等)的神经网络模型。如图3(a)所示,受U-Net[34]模型的启发,该类型端到端网络的设计中部署了编码器-解码器结构,以减少内存需求并增加网络的感受野,从而更好地利用图像的上下文信息。具体而言,一些研究为提升网络的视差预测精度,采用多阶段学习和多网络框架或多任务学习的思想设计立体匹配网络,而另外一些研究则着眼于减少网络计算负担,采用从粗到精的策略设计更高效的结构。
文献[33]首次引入端到端视差回归网络Disp-Net,其包含快速框架Disp-NetS 和精确框架Disp-NetC。Disp-NetS 借鉴U-Net[34]的框架设计一种用于视差回归的编码器-解码器结构。Disp-NetC 则类似于光流估计中的FlowNetCorr[35]网络结构(如图4 所示),首先利用孪生网络提取输入的左右视图特征,然后对提取的左右特征块进行1D 的相关性(Correlation)操作,得到3D 代价体(尺寸与特征图大小相同,通道数为Dmax,Dmax是预设的最大视差值)。Disp-NetC 网络的后续部分则利用2D 编码器-解码器处理3D 代价体并回归出最终的视差图。与非端到端方法特征提取模块常采用孪生网络相比,由于Disp-Net 将整个图像作为输入,因此其具有更高的时间效率,处理KITTI 数据集中一张图片仅需0.06 s,时间效率是MC-CNN 的1 000 倍,但在图像的病态区域,如遮挡、重复或无纹理区域,Disp-Net 仍然较难找到正确的对应关系。

图4 FlowNetCorr 网络架构Fig.4 The network architecture of FlowNetCorr
考虑到Disp-Net[33]网络结构配置的确定过程经过了多次手工设计和调整,而且无法确认是否为最佳配置,为此,文献[36]引入自动机器学习(AutoML)的思路。该文利用基于梯度的神经架构搜索和贝叶斯优化来进行超参数搜索,寻找Disp-Net的最佳配置,并提出AutoDispNet-CSS 网络结构。文献[37]为了解决Disp-Net[33]网络对遮挡区域预测效果不佳的问题,提出DispNet-CSS 框架,其包含多个基于FlowNet[35]的编码器-解码器结构和基于FlowNet 2.0[38]的堆栈结构,通过反复估计遮挡区域和运动边界来改善视差估计效果。
秉承多阶段网络的思想,文献[39]提出二级级联残差学习网络CRL(Cascade Residual Learning)。如图5 所示,CRL 的第一阶段结构DispFulNet 由Disp-NetC 网络添加额外的反卷积模块得到,能生成包含细纹理的初始视差图;第二阶段结构DispResNet利用多尺度残差信号修正初始视差图,采用残差学习的思想实现更有效的视差精细化。CRL 在所有立体匹配方法中达到了当时最高的匹配精度,但复杂的结构意味着较高的计算负担,因此,其时间效率比Disp-Net 慢80%。

图5 CRL 多阶段网络架构Fig.5 Multi-stage network architecture of CRL
文献[40]认为CRL 网络的第二阶段中采用光度误差(即色彩空间层次的重构误差)对视差进行调优,鲁棒性不足。为此,该文提出iResNet 网络,在特征空间层面计算重构误差,组合特征空间中的重构误差与特征相关(feature correlation)作为特征恒量,并在最后的视差优化模块输入级联的特征恒量和左图特征,从而输出调优残差。这种网络设计允许反复使用视差优化模块对视差图进行调优,以网络的匹配速度换取匹配精度。事实上,iResNet 和CRL 具有类似的思想,但iResNet 在提升匹配精度的同时也实现了更好的时间效率,其匹配效率相较CRL 提升了4 倍。从网络不同阶段间的信息交互情况来看,CRL[39]方法只有第一阶段网络结构预测的视差信息会传递到第二阶段网络结构,而iResNet则在网络的前后两阶段结构间共享更多的信息,这也是CRL[39]采用更复杂的网络架构但预测效果仍不如iResNet 的主要原因。
尽管采用多阶段的网络设计策略在很大程度上提高了匹配精度,但更复杂的网络意味着更高的计算负担。因此,文献[41]采用从粗到精的金字塔策略,提出首个无监督的实时域自适应立体匹配网络MADNet。为了提升在线自适应效率,MADNet在反向传播时不对网络的全部参数进行更新,而是采用启发式的奖励-惩罚机制来动态选择每次更新的参数。同样,为减少计算成本,文献[42]利用从粗到精的策略,提出分层离散分布分解立体匹配网络HD3(Hierarchical Discrete Distribution Decomposition),将立体匹配视为像素对应的概率问题,以考虑立体匹配中固有的不确定度估计。HD3将估计视差等价转化为估计离散匹配分布问题,并将图像分层分解为从粗到细的多个尺度,在利用网络预测出不同尺度上的离散匹配分布后,对由网络计算得到的不确定度进行加权组合,以得到图像整体的离散匹配分布。
弱纹理、反射、物体边缘等病态区域会严重影响立体匹配网络的匹配精度,通过融合不同模型的优点或采用多任务学习的方式能有效缓解此问题。文献[43]提出由CNN 和条件随机场(CRF)组成的混合模型,利用CNN 学习提取的特征,从而计算CRF 的一元和二元代价,并将CRF 公式化为最大余量马尔可夫网络,实现CNN+CRF 的联合训练。文献[44-45]提出一种由预测视差的主干网络和提取边缘的子网络共同组成的多任务学习网络EdgeStereo。如图6 所示,该模型在视差主网中共享子网提取的边缘特征,并在损失函数中加入具有边缘感知的平滑正则化项,从而将边缘信息整合到视差主干网络中,达成边缘检测与视差学习相互促进的目的。由于加入了边缘信息,EdgeStereo 在细薄结构区域以及物体边缘处表现较为优越,立体匹配方法固有的边缘肥大缺陷有所缓解,但其仍旧存在训练方式复杂以及对距离相机较远的物体结构匹配精度不高的问题。

图6 EdgeStereo 多任务网络框架Fig.6 Multi-tasking network framework of EdgeStereo
文献[46]构建的网络模型SegStereo 用语义信息来指导病态区域的视差学习,该模型包含视差主干网络和语义分支网络。SegStereo 在视差主干网络中融合来自语义分支的语义特征,并在网络训练的损失函数中引入语义损失项,利用语义信息指导视差估计,提高了反光、遮挡、重复纹理以及弱纹理等病态区域的匹配精度。与文献[46]中使用2 个独立的编码模块来分别提取语义和视差特征不同,文献[47]提出的DSNet 是一种轻量级网络架构,在特征提取时语义分割分支网络与视差估计共享相同的主干网络,此外,该文不再直接将语义分支网络的特征进行拼接,而是设计一种具有注意力机制的匹配模块提取融合特征从而进行视差估计。与加入边缘信息的EdgeStereo[44-45]相比,加入语义信息的SegStereo[46]和DSNet[47]在病态区域的匹配精度提升效果较为明显,但它们在细薄结构和物体边缘区域的匹配精度则显著低于EdgeStereo[44-45]。
2.2 基于4D 代价体的端到端立体匹配网络
与受传统神经网络模型启发的架构不同,基于4D代价体的端到端立体匹配网络架构是专门为立体匹配任务而设计的,这一架构下的网络不再对特征进行降维操作,从而使代价体能保留更多的图像几何和上下文信息,因此,基于4D 代价体的端到端立体匹配网络视差预测效果一般优于基于3D 代价体的端到端网络,但是这种精度上的提升需要消耗更多的计算时间和存储资源。从基于4D 代价体的端到端网络的初始设计理念(尽可能降低图像信息损失)出发,文献[48-53]致力于让网络在学习过程中考虑更多的图像上下文信息。而为了缓解该种网络架构普遍存在的高计算负担问题,文献[54-58]尝试从压缩4D 代价体大小、减少3D 卷积数量等不同角度提高网络效率。
文献[59]提出一种新型深度视差学习网络GCNet,其创造性地引入4D 代价体,并在正则化模块中首次利用3D 卷积来融合4D 代价体的上下文信息,开创了专门用于立体匹配的3D 网络结构。如图7所示,GC-Net 包含4 个步骤:

图7 GC-Net 网络框架Fig.7 Network framework of GC-Net
1)利用权值共享的2D 卷积层分别提取左、右图像的高维特征,并在此阶段进行下采样将原始分辨率减半以减少内存需求。
2)将左特征图和对应通道的右特征图沿视差维度逐像素错位串联得到4D 代价体,大小为,其中,H、W分别为图像的高和宽,Dmax为最大视差,C为特征通道数。
3)利用由多尺度的3D 卷积和反卷积组成的编码-解码模块对代价体进行正则化操作,得到大小为H×W×Dmax×1 的代价体张量。
4)对代价体应用可微的Soft ArgMax 操作回归得到视差图。
GC-Net 取得了当时KITTI 基准下最高的匹配精度,原因是其构建的代价体包含高度、宽度、视差和特征通道4 个维度,从而保留了图像更多的立体几何信息。但是值得注意的是,由于网络中大量使用3D 卷积,因此GC-Net 会存在计算时间方面的局限性,其处理一张分辨率为1 216×352 像素的图像需要0.9 s,耗时约为基于3D 代价体的端到端立体匹配网络DispNet 的15 倍。
与基于3D 代价体的端到端立体匹配网络类似,在基于4D 代价体的网络学习过程中加入更多的信息也能提升视差预测精度。文献[48]提出的金字塔立体匹配网络PSMNet,主要由空间金字塔池化(Spatial Pyramid Pooling,SPP)模块和堆叠的沙漏状3D CNN模块组成,其中,金字塔池化模块提取多尺度特征以充分利用全局环境信息,堆叠的沙漏状3D 编码器-解码器结构对4D 代价体进行正则化处理以提供视差预测。但是,由于SPP 模块中不同尺度的池化操作固有的信息损失,导致PSMNet 在如物体边缘等包含大量细节信息的图像区域的匹配精度较差。在PSMNet 的基础上,文献[49]将卷积空间传播网络(Convolutional Spatial Propagation Network,CSPN)模块扩展到3D 情形以处理4D 代价体,使3D 正则化模块可以从空间维度和视差维度上对4D 代价体进行信息聚合。文献[50]则针对PSMNet 网络前端的代价计算部分进行改进,提出多级上下文超聚合(Multi-level Context Ultra-Aggregation,MCUA)的二级特征描述方法,通过将层次内和层次间的特征组合(即将浅层、低级特征与深层、高级语义特征相结合),将所有卷积特征封装成更具区分性的表示形式,在没有显著增加网络参数量的前提下提升了网络的匹配性能。受半全局匹配(SGM)的启发,文献[51]引入指导代价聚合的显式代价聚合(Explicit Cost Aggregation Sub-Architecture,ECA)模块。ECA模块由双流束网络(two-stream network)组成:第一个流通过卷积操作沿着代价体的高度、宽度、视差3 个维度结合空间和深度信息,生成3 个潜在的代价聚合方式;第二个流评估潜在的聚合方式并选出其中最佳的一种,选择标准由轻量卷积网络获得的低阶结构信息所确定。GWC-Net[52]通过组相关策略保留基于3D 代价体的端到端网络中代价体构建方式(相关性操作)的优点,考虑不同特征通道的关联性从而得到更好的代价体表示,使网络能够推断出更准确的视差图。根据多任务学习的思想,DispSegNet[53]通过分割的方式利用语义信息指导深度估计,提高了网络在病态区域的匹配精度。
尽管上述基于4D 代价体的端到端网络取得了良好的匹配效果,但由于3D 卷积结构本身的计算复杂度,导致网络在存储资源和计算时间上成本高昂。以GCNet[59]为例,其处理分辨率为1 216×352 像素的图像对大约需要10.4 GB GPU 内存[54]。为了解决此问题,压缩代价体[54-55]、构建更低分辨率的代价体[56-57]或减少3D卷积层个数[58]等多种思路被提出。文献[55]设计的网络PDS(Practical Deep Stereo)引入一个瓶颈匹配模块,通过将来自左、右图像的级联特征压缩为更紧凑的匹配表示形式来压缩4D 代价体,从而减少内存占用量。文献[54]提出基于GC-Net[59]的稀疏代价体网络(Sparse Cost Volume Net,SCV-Net),在由左、右图像特征生成4D 代价体的步骤中引入步幅参数使代价体更紧凑,在不影响性能的情况下大幅减少了内存使用量。文献[56]采用从粗到细的策略,提出一个三阶段视差估计网络AnyNet:首先以低分辨率特征图作为输入,构建低分辨率4D 代价体;其次使用3D 卷积在较小的视差范围内进行搜索得到低分辨率视差图;最后对低分辨率视差图上采样得到高分辨率视差图。该方法是渐进式的,允许随时停止来获得较粗的视差图,以匹配精度换取匹配速度。文献[57]提出实时轻量立体匹配网络StereoNet,在得到低分辨率的视差图后通过2D 卷积网络进行上采样和视差优化,以降低网络的复杂性,但与采用高分辨率4D 代价体的方法相比,StereoNet在物体边缘区域的匹配精度有所下降。文献[58]设计GA-Net,其采用半全局聚合(Semi-Global Aggregation,SGA)层和局部引导聚合(Local Guided Aggregation,LGA)层替换正则化模块中的大量3D卷积层,其中:SGA是SGM中代价聚合方法的可微近似,并且惩罚系数不再由先验知识确定,而是由网络学习得到,因此,对于图像的不同区域具有较好的适应性和灵活性;局部引导聚合层LGA 则附加在网络末尾以聚合局部代价,旨在细化薄结构和物体边缘的视差。
如上所述,许多研究人员尝试从优化4D 代价体大小和减少3D 卷积个数等不同角度设计网络结构,使网络在时间效率上得到改进。但是,综合匹配精度和匹配效率可以看出,如何设计更加高效实用的网络结构仍需进一步探索。
3 方法性能比较
3.1 数据集
表1 给出了4 个常用数据集的介绍与比较。KITTI 2012[60]是用于立体匹配的第一个大型驾驶场景数据集,包括静态场景的室外图像,该数据集由389 个灰度图像对组成,分为194个训练图像对和195个测试图像对,数据集的GT(Ground Truth)由LIDIA 测量获得,GT 是半密集的,覆盖了图像约1/3 的像素点,并经过手工矫正后将其转换为视差。KITTI 2012 数据集提供了在线排行榜,可对全部区域像素和去除遮挡区域像素分别进行评估。KITTI 2015[1]数据集采集于动态场景,图像内容包含行驶中的汽车,该数据集共包含400 对彩色双目图像,训练集和测试集各200 对。KITTI 2015 数据集的数据采集方式与KITTI 2012 相似,评价指标也为误匹配率,分为前景(移动的目标)、背景和全部区域3 种情形。Middlebury 2014[61]数据集由33 个亚像素级别的室内静态场景组成,分为训练集(13 对)、附加集(10 对)和测试集(10 对),图像和GT 提供了全分辨率、半分辨率和1/4 分辨率3 种版本,该数据集视差范围在200~800 像素之间,与KITTI 数据集相比,Middlebury 2014最大的一个差异是图像分辨率非常高,达到了600万像素。Freiburg SceneFlow[33]数据集包含约39 000 对大小为540×960 像素的虚拟图像,根据场景类型又分为FlyingThings3D、Monkaa 和Driving 这3个子集。FlyingThings3D 数据完全由渲染生成,共包含22 872 个图像对,其中,4 370 个图像对作为验证集;Monkaa 数据从动画片中生成,共包含8 591 对双目图像;Driving的数据生成方式与Monkaa相同,提供驾驶场景的数据,共包含4 392 对图像。

表1 立体匹配任务常用数据集Table 1 Common datasets of stereo-matching tasks
综合近些年的研究结果来看,KITTI 数据集和Middlebury 数据集被广泛应用于训练和测试基于图像块的CNN 网络架构(如MC-CNN 等),这是因为单个训练图像对可以产生数千对不同的图像块。而在端到端架构中,由于其需要大量数据集进行有效训练,且这种情况下一个图像对仅对应一个样本,因此大多数端到端立体匹配网络在迁移到如KITTI 和Middlebury 等真实数据集前,通常选择在Freiburg SceneFlow 数据集上进行预训练。
3.2 评估指标
立体匹配方法的评估指标有匹配精度与时间复杂度。匹配精度的衡量标准有平均绝对误差、均方根误差与误匹配率,计算公式分别如下:
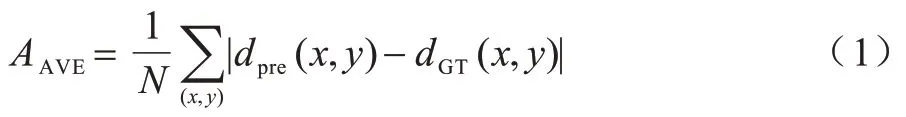
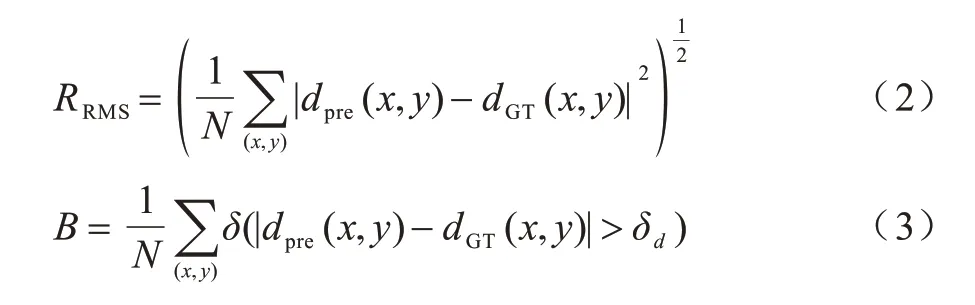
其中:dpre(x,y)与dGT(x,y)分别为预测视差和真实视差;δ为指示函数,当差值大于设置的阈值δd时其取值为1,否则为0;N为参与计算的像素点总数。
3.3 性能分析比较
本文从KITTI 2015 和Middlebury 2014 网站上选取部分方法的量化评价结果,以对基于深度学习的非端到端和端到端立体匹配方法进行定量比较。
表2 和表3 分别给出各立体匹配方法在所有区域(All pixels)和非遮挡区域(Non-occluded pixels)2 种情形下的误匹配率,并在表4 中给出不同种类立体匹配方法的定性分析结果。

表2 KITTI 2015 数据集上不同立体匹配方法的性能比较结果Table 2 Performance comparison results of different stereo-matching methods on KITTI 2015 dataset

表3 Middlebury 2014 数据集上不同立体匹配方法的性能比较结果Table 3 Performance comparison results of different stereo-matching methods on Middlebury 2014 dataset

表4 不同立体匹配方法的特点比较Table 4 Comparison of characteristics of different stereo-matching methods
在表2 中,误匹配率的误差阈值限定为3 个像素,且D1-bg、D1-fg、D1-all 分别代表背景区域、前景区域和所有区域。在表3 中,误差阈值限定为2 个像素,F、H、Q 分别代表全分辨率、半分辨率和1/4 分辨率,AVE 代表像素点的平均绝对误差。
从表2 和表3 可以看出:在KITTI 数据集中,相比于深度学习与传统方法相结合的非端到端方法,早期基于深度学习的端到端方法计算效率明显提高,但匹配效果并不理想,随着后期研究的深入,端到端方法(尤其是基于4D 代价体的端到端方法)的匹配精度要明显优于非端到端方法;在Middlebury 2014 数据集中,大部分基于3D 代价体的端到端方法的误匹配率高于非端到端方法,原因是端到端立体匹配网络的学习效果较为依赖训练集中图像场景的类型。端到端立体匹配网络通常在Freiburg SceneFlow数据集中进行预训练,而Middlebury 2014 数据集中的图像与Freiburg SceneFlow 中的图像在情景内容上差距较大,导致网络迁移到Middlebury 2014 数据集上时表现较差。而对于基于4D 代价体的端到端方法,除受到跨域迁移的影响之外,还因对于高分辨率图像处理能力不足,导致其不仅在Middlebury 2014 数据集排行榜中排名靠前的算法数量较少,而且匹配精度也低于基于3D 代价体的端到端立体匹配方法。
4 未来展望
基于深度学习的立体匹配方法已经取得了显著成果,然而,综合匹配精度和时间效率来看,目前的研究工作仍处于起步阶段。该领域未来的发展方向主要在以下几个方面:
1)鲁棒性。基于深度学习的立体匹配方法在精度上较传统方法有很大提升,但在弱纹理、重复纹理、遮挡、透明、镜面反射、光学失真等病态区域的误匹配率依旧很高,而这些场景在实际应用中真实存在且不可避免,因此,设计新的立体匹配方法以降低这些区域的误匹配率依然会是未来的研究重点。从文献[44-47,53]等研究结果来看,将高级视觉任务中的目标识别、场景理解与低级视觉特征学习相结合是解决该问题的一种有效途径。
2)实时性。大多数端到端方法在构建3D 或4D代价体后分别使用2D 和3D 卷积进行正则化处理,这导致它们普遍具有高昂的时间成本和计算资源开销,严重阻碍了此类方法在嵌入式设备中的实际应用。因此,开发精度与速度并存的轻量级端到端网络是未来的一个重要研究方向。
3)跨域迁移性。深度神经网络在很大程度上依赖于训练图像的可用性,其方法性能和泛化能力会受到训练集较大的影响,且容易出现模型对特定领域过拟合的风险。针对立体匹配问题,大多数端到端网络框架一般都会选择在合成数据集Freiburg SceneFlow 上进行预训练,而这导致了训练后的模型在迁移到真实数据集上时效果明显下降。因此,开发泛化性较强的立体匹配方法,使其在跨域迁移时能适应新的情景环境也是需要解决的一大难题。在其他视觉任务中,常通过设计特定的损失函数或使用领域自适应和迁移学习策略来缓解此问题,这2 种思路也是缓解立体匹配网络泛化性问题的潜在对策。
4)对高分辨率图像的处理能力。当前大多数基于深度学习的立体匹配方法不能很好地处理高分辨率输入图像,通常会生成低分辨率的深度图,导致这些方法无法有效重建如植被、细杆等细薄结构以及距离相机较远的结构。对于高分辨率图像,当下一种有效的思路是采用分层技术,即利用深层、低分辨率的特征信息生成低分辨率深度图,而后结合浅层、保留较多空间位置信息的特征生成高分辨率深度图。但在这种基于由粗到精的策略中,低分辨率深度图可以实时生成,而生成高分辨率深度图则需要较长时间。因此,对高分辨率图像实时生成精确的深度图仍是未来研究的一大趋势。
5)学习范式。对训练图像进行逐像素标签标注是一项耗时耗力的工作,已经有许多研究人员尝试采用无监督方法来缓解标注负担。而相比于监督学习方法,现有的无监督方法匹配精度较低,因此,设计效果优良的无监督训练算法也具有重要的研究意义。
6)网络架构搜索。目前基于深度学习的立体匹配方法研究大都集中在设计新的网络结构和训练方法,仅有较少的研究人员关注自动学习最佳架构问题,如AutoDispNet[36]。使用神经进化理论从数据中自动学习网络架构、激活函数,可以释放对人工网络设计的需求。因此,对自动学习复杂视差估计网络架构进行研究也具有较大的发展前景。
7)不同类型网络的应用。目前基于深度学习的立体匹配方法大都基于卷积神经网络,结合其他类型网络(如循环神经网络、生成对抗网络等)的优势来进一步提高立体匹配的效果,也是一个潜在的研究方向。
5 结束语
本文对基于深度学习的立体匹配方法进行分类和总结。基于深度学习的非端到端方法取得了优于传统方法的性能表现,并且相较端到端方法,非端到端方法对训练数据样本量的要求较低,同时具有较强的泛化性和跨域迁移性,但是该类方法存在计算时间长、感受野有限、缺乏上下文信息、匹配精度不高等问题。基于深度学习的端到端方法具有匹配精度高、网络结构易于设计、实时性高等优点,但是该类方法训练数据量较少、计算资源成本较高且跨域迁移性较弱。设计同时满足匹配精度、实时性、鲁棒性、跨域迁移性等要求的立体匹配方法,将是下一步的研究方向。
