基于模拟退火与强化学习机制的任务分析方法
2022-10-14彭鹏菲郑雅莲
彭鹏菲,龚 雪,郑雅莲,姜 俊
(1.海军工程大学 电子工程学院, 武汉 430033; 2.武汉大学 水资源与水电工程科学国家重点实验室, 武汉 430072; 3.海军工程大学 作战运筹与规划系, 武汉 430033)
1 引言
任务分析是开展任务规划的重要前提,针对任务分析中多方条件限制的任务序列重组问题,众多学者已开展深入研究,总体来说,作战任务分析方法可分为三类,一是数学解析模型、二是遗传进化方法、三是智能规划方法。如在传统任务分析算法研究中,董涛和王志亮等人通过耦合任务集来进行任务解耦,从而达到任务序列重构的目的;李翠明等从任务间内在机理的角度定量分析任务间的联系,采用遗传算法求解任务最优分配方案。在深度强化学习基础上,将任务放置神经网络中分析处理。赵晓晓等建立基于多层神经网络的任务规划智能分析模型,并开展模型的合理性分析。在强化学习的基础上,动态建立任务间信息交互的环境,实现特定环境下的任务分析。马悦等针对现代战争快节奏、高强度和高复杂性的特点,通过强化学习和智能技术提高了决策自动化和自主化水平。上述研究成果,均从任务细粒度出发,并通过对任务协同关系定量分析得出任务执行序列。上述算法在一定程度上能解决任务分析与规划问题,但仍存在许多缺陷,如针对数学解析模型算法,该模型由于难以考虑多方面的任务交互信息,因而易陷入局部最优;遗传算法存在依赖于初始解、参数复杂、迭代时间长、底层存储机能和收敛过早等问题;深度强化学习算法虽可有效解决参数复杂及初始解依赖问题,但算法的数据需求量大,存在实时完备性较差、时间延迟等问题。
通过模拟退火(simulated annealing,SA)算法中的降温迭代,结合基于模拟退火选择策略的强化学习来改进算法的当前状态,并研究退火因子的动态变化。该算法有较好的推广应用前景。
2 基于模拟退火选择策略的强化学习算法改进
该算法基于强化学习的策略选择机制,引入状态因子,逐步实现对最优状态的选择。
SA是基于Monte迭代求解策略的一种随机寻优算法,基于物理退火过程与组合优化之间的相似性,SA由某一较高温度开始,利用具有概率突跳特性的Montropolis抽样策略在解空间中进行随机搜索,伴随温度的不断下降重复抽样过程,最终得到全局最优解。
强化学习Q算法是基于value-based,在某一时刻的状态下(∈),采取动作(∈)能够获得收益的期望,环境会根据agent的动作反馈相应的奖励,因此Q算法将状态与动作构建成一张Q表来存储值,然后根据值来选取能够获得最大收益的动作。
2.1 基于强化学习的动作选择策略
基于模拟退火思想,引入状态因子,令=(,)-(,) (式中,为当前温度下的状态,为当前状态下的随机动作,为当前状态下最大的动作值),通过寻找最优状态的最适应状态因子,Q表随着状态因子适应度的改变而不断更新,最终收敛至最优值。同时,根据智能体(agent)的运动时耗及其运动状态反馈,更新奖励矩阵。agent依据奖励矩阵做出动作选择,同时,奖励矩阵随着agent的选择不断更新,直至收敛至最优状态,获得最优的Q表集合。
在上述行为选择策略中,可设计自适应动态探索因子,以提高早期发现任务状态多样性的概率,避免陷入局部最优。另外,该算法通过模拟退火降温的过程来降低折扣因子,从而提高算法的收敛速度,模型选择策略流程如图1所示,图1中表示在当前温度下agent在该状态下的随机动作,表示当前温度下agent在该状态下的最大动作。

图1 基于模拟退火选择策略的强化学习改进算法选择策略流程框图Fig.1 Improved algorithm selection strategy for reinforcement learning based on simulated annealing selection strategy
该策略的具体执行步骤如下:
1) 当STATE=时,随机初始化ACTION=,此时设置agent的最高奖励值的动作ACTION=;
2) 判断学习得到的当前状态下(为该状态下动作选择的扰动值)与=e(±((,)-(,)))(为该状态下动作选择的扰动界定值)之间的大小关系,若<,则采取随机动作为当前动作且计算两任务之间的时耗,若是在[0,5],则给予agent奖励,并继续更新寻找任务新解的过程。否则,采取最优动作为当前动作。
3) 判断当前状态是否为最终状态,若“是”则结束寻找过程,若“否”继续寻找。针对任务分析中任务动态执行序列以及任务分解的难点,将任务分析模型引入,对于基于模拟退火选择策略的强化学习改进算法,其设计目标包括:动态设计最终agent的状态;依据奖励机制进行最优任务序列搜寻;引入任务空间-时效评判机制对agent进行奖励或惩罚。
基于模拟退火选择策略的强化学习改进算法,以模拟退火算法为基础,引入基于任务分析的学习机制,在设置最大的回合数的基础上,动态实现退火过程,在agent不断学习的过程中不断更新Q表,最终产生任务序列执行图,解决任务分析的任务重构问题,算法流程如图2所示,奖励机制流程如图3所示;图2中Episode表示agent学习的回合数,Steps表示agent探索的最大步数,表示两任务间的信息交互逻辑空间距离,表示两任务间的时耗,表示状态因子,表示当前温度下的agent的状态;图3中表示当前状态下agent获得的奖励值。
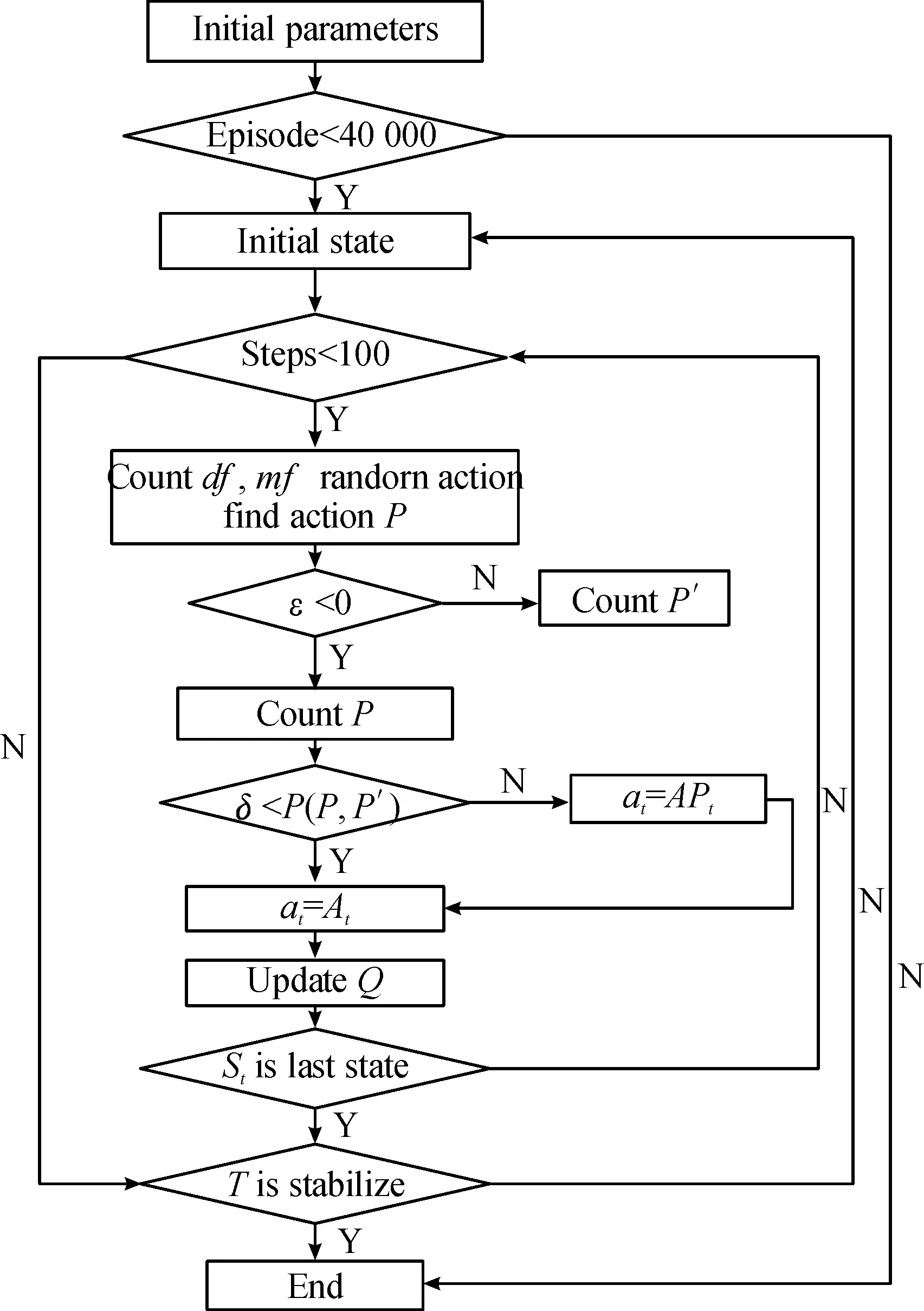
图2 基于模拟退火选择策略的强化学习改进算法流程框图Fig.2 Flow chart of reinforcement learning improvement algorithm based on simulated annealing selection strategy
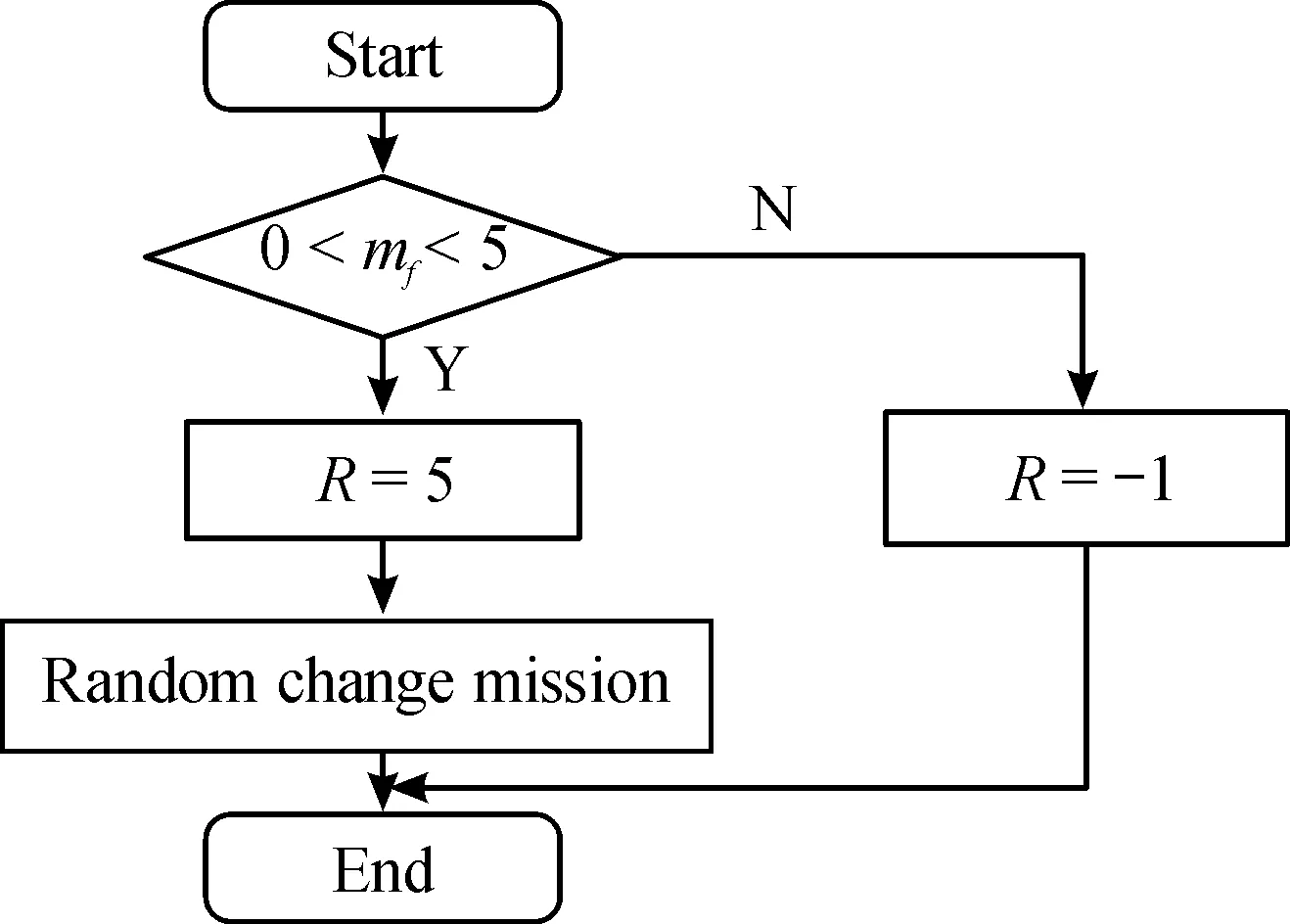
图3 奖励机制流程框图Fig.3 Flow chart of the reward mechanism
2.2 基于模拟退火选择策略的强化学习改进算法运行环境设计
强化学习的定义是:在与环境交互中,agent通过“试错法”获得奖励指导,最终最大化agent的学习过程。
强化学习环境(强化学习系统)提供的信号通常是一个标量信号,能评估动作执行效果,通过奖励反馈实现最大化agent的目标。
因环境提供的信息有限,agent无法很快定位到目标任务,所以,当agent移动到任务,会对下一个任务+1进行可移动性判别,若不可移动,则对agent进行惩罚,回到起点并开始下一个回合;若可移动,则对agent进行奖励,移动并判别;直至达目标任务,进行下一回合。
基于模拟退火选择策略的强化学习改进算法学习机制如图4所示。
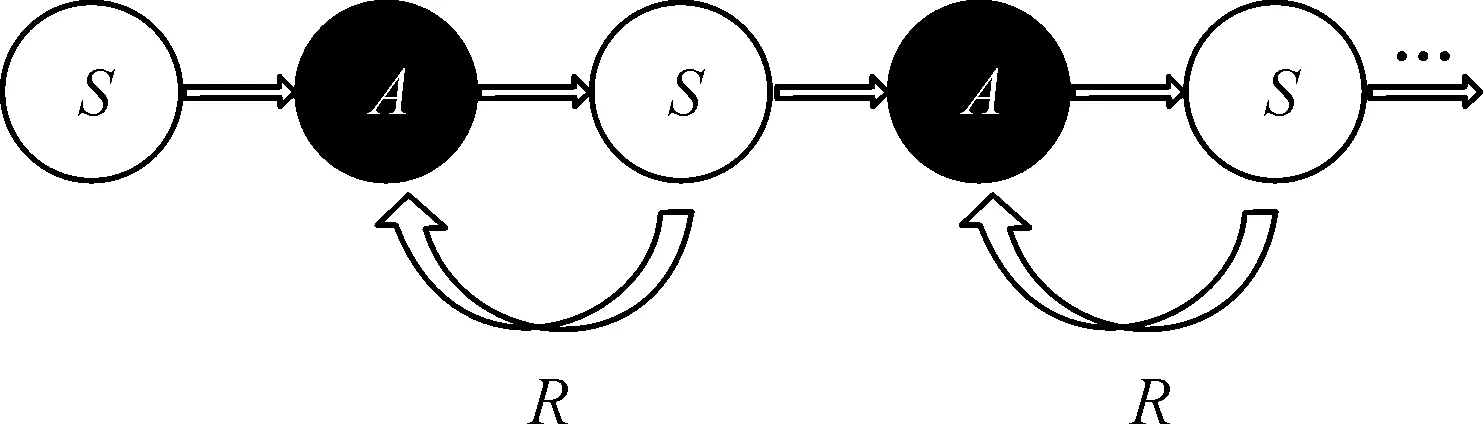
图4 基于模拟退火选择策略的强化学习改进算法学习机制示意图Fig.4 Learning mechanism diagram for reinforcement learning improvement algorithm based on simulated annealing selection strategy
该机制原理如下:若agent的某一行为策略使其从环境中获得奖励,则会增加采用该策略的倾向。假设环境是一个状态有限的离散马尔可夫过程,agent在每个时刻能从有限操作集中选择一个操作。在环境接受此操作后,将其转移到下一个状态并对上一个状态进行评估,基于模拟退火选择策略的强化学习改进算法学习更新Q表的奖励机制如图5所示。

图5 基于模拟退火选择策略的强化学习改进算法学习奖励机制示意图Fig.5 Learning reward mechanism for reinforcement learning improvement algorithm based on simulated annealing selection strategy figure
因此,在设计基于模拟退火选择策略的强化学习改进算法运行环境时,假设agent需要对个任务进行处理,且最终的目标任务已知。在初始化时,agent对任务进行判别,若任务与任务+1有信息交互,则记为智能体,此时,智能体可由任务到达任务+1或由任务+1到达任务,即针对任务间的信息交互,智能体采用策略选择机制寻得最优的任务序列图。若是任务与任务+1间没有信息交互,则记为智能体无法从任务到达任务+1。另外,设计环境奖励矩阵的依据为:通过专家评价,若任务+1完全依赖于任务的信息输出,则计(state,action)=1;若任务+1不完全依赖于任务的信息输出,则计(state,action)处于(0,1)的区间;若任务+1完全不依赖于任务的信息输出,则计(state,action)为-1;若是以某个任务为目标任务,则计(state,action)处于(100,150)的区间。
3 基于强化学习改进的任务序列重构及任务图生成
在强化学习Q算法的开始阶段,温度较高,智能体(agent)以较高的概率进行动作选择。随着学习次数的增加,根据模拟退火规则,温度会逐渐下降直至稳定。探索因子根据退火规则下降,智能体以更高的概率选择最佳的动作。使其能够跳出局部最优解的同时能够随着退火的进行不断收敛到一个最优的Q表集合,从而得到最佳任务执行图。
3.1 基于模拟退火选择策略的强化学习改进算法任务分析模型的构建
本文将奖励矩阵的概念引入模型,并对基于矩阵的作战任务建模及重组问题进行了解决与应用拓展。具体模型优势如下:
1) 通过分析任务间的信息交互,将策略选择机制和奖励方法结合;
2) 通过反馈的奖励值,不断更新agent的运动方向。
假设每单一任务都是一个独立的方向,并且每一个任务都相互独立。按如下状态,智能体获得不同的奖励矩阵反馈值:若2个任务之间没有信息交互,则记奖励矩阵对应的(状态,动作)值为负;若是2个任务之间有单方面的信息交互,则记奖励矩阵对应的(状态,动作)值为正值且在[0,1]之间;若是双方都有信息交互,则记奖励矩阵的对应(状态,动作)值为正值且大于1。
在每一种状态下,智能体根据策略选择机制的反馈值采取相应的动作,随着学习周期增加,不断丰富agent的学习经验,最终获得最优Q表。
任务分析方法的实现过程,主要分为2个部分:第1个部分是Q学习模拟退火模型的构建,此部分将模拟退火思想中的退火因子与Q学习机制相结合,进行任务序列重组;第2个部分是迭代学习模型的求解,此部分通过学习迭代生成任务序列图。具体基于模拟退火选择策略的强化学习改进算法任务分析模型的结构如图6所示。

图6 基于模拟退火选择策略的强化学习改进算法任务分析模型结构框图Fig.6 Structural diagram of the task analysis model of a reinforcement learning improvement algorithm based on a simulated annealing selection strategy
第1步,将任务时间矩阵、任务间信息交互矩阵输入Q学习模拟退火模型,可得学习后的Q表、串行任务执行序列和任务奖励评价矩阵。在迭代求解任务序列的过程,任务奖励评价矩阵反作用于Q模拟退火算法生成最优的Q表集合。第2步,在进行学习迭代的过程中,将收敛的Q表和串行任务序列相结合,以生成任务序列图。
3.2 任务序列重组
首先,根据1.1节的策略选择机制,编制任务序列重组算法,通过任务信息交互矩阵形成初始任务空间解。其次,在初始空间解中,根据任务间的信息交互进行定量分析,生成任务关系矩阵。最后,运用策略选择机制更新任务关系矩阵,并反馈对应任务的奖励矩阵。
智能体在学习时将不断更新任务空间矩阵和任务奖励矩阵,且更新的这2个值又能对智能体进行进一步反馈,直到其达到最佳状态及最佳温度,最终生成串行任务执行序列,即完成任务序列重组。任务序列重组结构如图7所示。
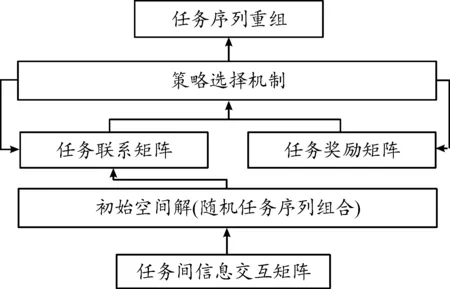
图7 任务序列重组结构框图Fig.7 Structure of the task sequence reorganisation
3.3 任务序列图生成
根据上述动作选择策略,将改进的基于模拟退火选择策略的强化学习改进算法引入任务分析算法中,执行过程如图8所示。
图8 基于模拟退火选择策略的强化学习改进算法执行流程框图Fig.8 Execution flow of reinforcement learning improvement algorithm based on simulated annealing selection strategy
具体执行步骤如下:
Step 1:初始化任务时间矩阵、任务间信息交互矩阵。
Step 2:运用基于模拟退火选择策略的强化学习改进算法重构任务序列。
① 随机产生初始解状态,即随机解空间,设置最大回合数Episode=40 000,设置最大探索步数steps=100,初始化最初状态值。
② 在当前状态下,随机初始化一个动作值、未来需要执行的动作集合和未来Q表集合。随后,计算任意两任务间的信息交互逻辑空间距离、两任务间的时耗。智能体通过不断选择任务序列,反馈逻辑空间距离,持续更新奖励矩阵,从而推算出最优的任务执行序列。
引入状态因子,=(,)-(,),若<0,则计算=e(,)-(,);若>0,则计算=e-(,)-(,)。
判断和,若<,则取当前状态下的随机动作为当前动作,且若在[0,5],令表示任务和任务+1间的时耗,若<0,则agent不能从任务到任务+1,若是>5,则时耗太长,效率低下,则给予agent奖励,并寻找任务新解;若>,取当前状态下的随机动作为当前动作,同样地,若在[0,5],则给予agent奖励,并寻找任务新解。
判断step是否小于100,若“是”,重新执行②,若“否”,执行③
③ 运用贪婪算法更新Q表,并判别是否到达最终状态(实现最大目标),若“是”,返回①;判断是否达到降温标准,若“是”,结束,若“否”,开始下一回合。
Step 3:生成任务执行序列及任务执行图。
4 实验分析
以15枚TBM来袭事件为例开展实验分析,将反TBM作战任务抽象为15个任务,采用任务序列重组及任务图重构算法。
仿真实验平台为LAPTOP-QEHE6SH7处理器是11th Gen Intel(R) Core(TM) i5-1155G7 @2.50 GHz,64位操作系统,基于x64处理器的联想小新笔记本。编程工具为Pycharm,应用了Conda环境。
4.1 基于模拟退火选择策略的强化学习改进算法参数设置
根据多次实验,可得基于模拟退火选择策略强化学习改进算法的模型参数,具体如表1所示。

表1 模型参数Table 1 Model parameter
4.2 基于模拟退火选择策略的强化学习改进算法有效性仿真分析
与Q算法和SA算法相比,基于模拟退火的Q学习任务分析算法有如下优势:
反TBM作战任务包含预警探测、目标截获、跟踪识别、火力拦截、杀伤效果评估等方面。
图9展示了反TBM作战任务基于优先级任务序列的排列,且任何一个作战资源平台都无法单独承担全部作战任务,因此需进行基于多因素的作战任务分析。
图12所示,基于模拟退火选择策略的强化学习改进算法与SA算法在空间逻辑距离收敛上均具有良好的效果,当达到第1 500回合左右,基于模拟退火选择策略的强化学习改进算法已收敛,而SA已陷入局部最小值。
1) 运用任务时间矩阵考虑多因素对任务序列的影响,能更加全面地考虑多复杂因素对任务信息交互的影响,因而能轻松应对各种复杂因素的变化;
2) Q学习任务分析算法能考虑多样化输入,不只是对任务信息交互矩阵进行分析和处理。
通过基于模拟退火选择策略的强化学习改进算法,经任务序列重组,能获得最优的串行执行任务序列,如图9所示。

图9 任务序列重组后的串行执行任务序列图Fig.9 Diagram of serial execution of tasks after task sequence reorganisation
基于模拟退火选择策略的强化学习改进算法,其基于Q算法,经迭代学习后得到最优执行任务序列并行图,当基于模拟退火选择策略的强化学习改进算法最大回合数为 40 000、贪婪值为0.4时,如图10所示。
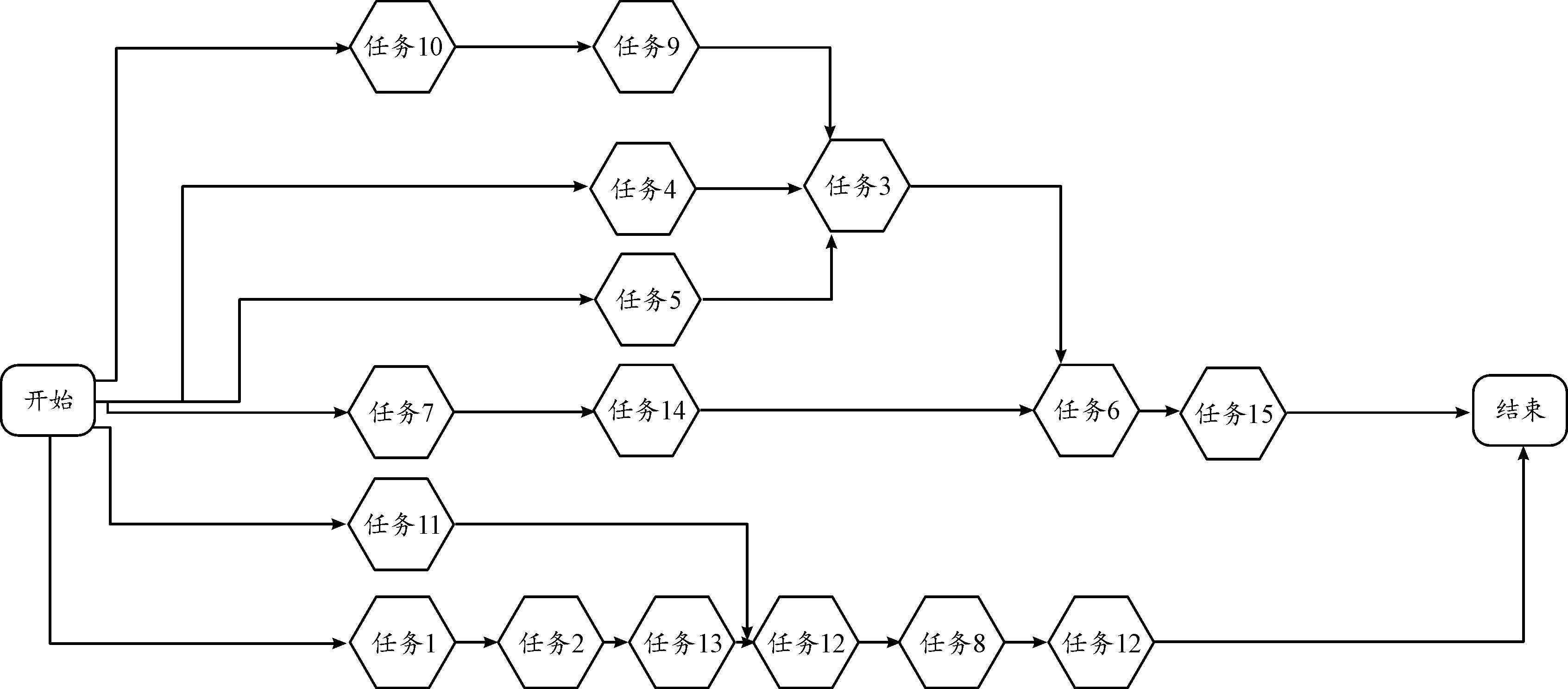
图10 40 000步收敛后的并行执行任务序列图Fig.10 Task diagram after 40 000 steps of convergence
当贪婪值为0.2时,结果如图11所示,最大奖励值无法收敛,因此不可取。当贪婪值为0.8时,达到最大奖励值后,结果有向下的趋势,因此同样不可取。
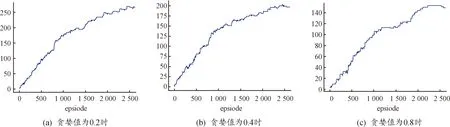
图11 不同贪婪值的最大奖励收敛效果曲线Fig.11 Comparison of the maximum reward convergence effect for different greedy values
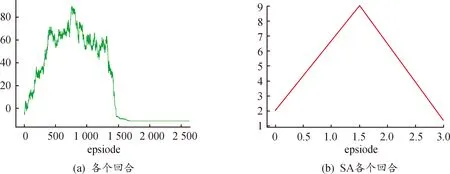
图12 基于模拟退火选择策略的强化学习改进算法和SA算法各个回合逻辑空间距离df曲线Fig.12 Comparison of the reinforcement learning improvement algorithm based on simulated annealing selection strategy and the SA algorithm for each round of logical space distance df
4.3 基于模拟退火选择策略的强化学习改进算法运行效率分析
从性能来看,基于模拟退火选择策略的强化学习改进算法随着回合数的不断增大、退火因子不断减小,退火因子对任务奖励机制的影响越来越小。
最终,当算法达到最优时,退火因子达到稳定状态,基于模拟退火的Q学习任务分析算法收敛至最优回合数。对于SA而言,随着退火的进行,算法陷入局部最优,因而性能较差。对于传统Q算法而言,无法自行决策,难以收敛到最优状态,且迭代速度慢、时效性较差。
为了验证基于模拟退火选择策略的强化学习改进算法任务分析算法在任务序列重构的优越性,设置相同任务时间矩阵、任务间信息交互矩阵,将传统SA算法、传统Q算法和基于模拟退火选择策略的强化学习改进算法在收敛回合数上进行比较,结果如表2所示。与SA和Q算法相比,在额外加入一个任务时效矩阵输入的情况下,基于模拟退火选择策略的强化学习改进算法在第2 629回合达到收敛,跳出设定回合制,Q算法无法收敛,SA算法收敛步数过短,可能已陷入局部最优。因此,相比之下,基于模拟退火选择策略的强化学习改进算法在收敛效果上更具优越性。

表2 收敛回合数Table 2 Convergence table for the number of algorithm episode
最后,基于模拟退火选择策略的强化学习改进算法在第2 629回合收敛,其比传统的Q学习算法节省了时间,且得出了任务的最优串行执行序列以及不同初始状态下最优的并行任务执行图。与SA算法相比,基于模拟退火选择策略的强化学习改进算法更容易跳出局部循环且能迅速地找到不同场景下的任务执行图。
5 结论
本文提出的基于模拟退火选择策略的强化学习改进算法,通过不断的降温迭代和最大回合数的经验学习,产生针对各个回合的Q表,获取算法至退火收敛时的最优Q表,进而实现基于模拟退火Q学习的回合迭代,产生符合不同情景的任务分析图。仿真实验结果表明,该算法比传统Q学习算法更具操作性,且比传统的模拟退火算法更能跳出局部最优值,快速在一个相对较好的回合数收敛,并产生较好的任务分析图,具备解决任务分析问题的人工智能算法性能。
将Q强化学习和模拟退火算法结合,一定程度上解决任务分析问题。但算法也存在缺点,如Q学习算法难以处理连续问题。因此,可考虑将强化学习的sarsa和粒子群算法结合,开展研究进一步的任务规划处理。
