罐式批次成品汽油调和配方集成建模方法
2022-10-13李炜阮成龙王晓明李亚洁梁成龙
李炜,阮成龙,王晓明,李亚洁,梁成龙
(1 兰州理工大学电气工程与信息工程学院,甘肃 兰州 730050;2 甘肃省工业过程先进控制重点实验室,甘肃兰州 730050;3 兰州理工大学电气与控制工程国家级实验教学示范中心,甘肃 兰州 730050;4 中国石化兰州石化分公司油品储运厂,甘肃 兰州 730060)
随着绿色环保理念的日益推进,我国汽柴油质量标准升级速度不断加快,这就需要炼油企业的油品调和技术不断升级跟进。然而实际中受研发能力和技术升级费用的限制,一些炼油企业目前仍采用在线罐式调和方式。在该生产模式下,成品汽油生产多是依据单一线性模型的配方进行罐式批次调和,其组分添加的流量为配方指导下的比值闭环控制,但产品质量指标由于无法在线分析,则为开环控制。因此,建立精准的调和配方模型就成为确保产品质量指标且接近卡边生产、提高企业生产效益的重要保障。尽管对于不同产地原油加工中经典池化问题(pooling problem)提出的多种优良解决方案助力了企业效益的提升,但是作为油品调和生产的优质配方依然是企业提质增效的基础保障。在罐式在线调和过程中,罐底通常会留有约占调和罐1/6的余油,且调和组分受不同产地原油影响,即使企业前端生产尽可能保证主料加氢汽油性质相似,但实际加氢汽油品质仍有差异,进而导致调和过程呈现批次现象。虽有部分学者提出从分子特征层面认识石油加工过程,通过准确预测产品性质优化工艺和加工流程,以提升每个分子对产品的使用价值,然而对在线罐式调和方式下罐底余油的影响仍缺乏细节的考虑。因此,综合考虑罐底余油以及批次效应,建立更加精准优质的配方模型,无疑对提高一次成功调和率、减少产品质量过剩、降低企业生产成本都起着决定性的作用。对于多批次引起工况的变化,传统的单一配方模型很难准确预测不同批次各个调和组分比例。而对于这类多工况问题,基于多模型集成的建模方法则能显著提高模型精度和泛化能力已成为主流的解决方案。
近年来,多模型研究在不同的应用领域已有了丰硕的成果。而对于罐式批次成品油调和而言,核心问题是如何科学合理地对罐底余油按组分批次聚类,并建立与之对应的高质量子模型及有效融合。针对实际工业中的批次问题,聚类不失为一种行之有效的方法。聚类算法通常可分为硬性和柔性两种,对于复杂工况问题,硬性划分和柔性划分的效果各有优缺点。由于罐底油划分并非是非此即彼的关系,因此柔性划分更为契合,而柔性划分最经典的是模糊-mean 聚类算法,但其仍存在对初始聚类中心敏感、无法处理非球状数据、易于陷入局部最优解等缺陷。针对上述问题,不同学者从多方面进行改进,如通过引入智能优化算法对聚类初始信息进行优化、提出各种准则确定聚类个数等。在距离度量上,文献[18]采用一种对离群点有抑制作用的非欧距离度量,但大多数通过引入核函数进行度量矩阵重构,且已证明引入核函数可使其聚类效果具有鲁棒性。但当应用中涉及多模态和不平衡特征问题时,由于多个核较单一核在核的选择和数据表示上具有更大的灵活性,可以有效解决此类问题,学者们又引入多核映射方法。Huang等提出了一种多核模糊均值(multikernel fuzzy-means,MKFCM)算法,首先将每个属性特征映射到单个核空间,然后将这些核与最优权值进行线性组合和构造复合核函数。文献[21]采用MKFCM 在机器学习库(UCI)数据集上进行实验,印证了该聚类算法具有更好的性能,但此方法更多考虑的是样本间差异,对于调和油生产多组分配方形成的特征差异仍有改进空间。
从已有的多模型研究来看,采用传统机器学习方法进行子模型建立仍占多数,亦取得了良好的应用效果,如最小二乘支持向量机、高斯过程、神经网络等经典方法,近年来新型机器学习应用也初见端倪。极端梯度提升树(extreme gradient boosting,XGBoost)是陈天奇等开发的一个开源机器学习项目,高效地实现了梯度提升树(gradient boosting decision tree,GBDT)算法,并从GBDT延伸出基于其他机器学习的集成算法,且可以使用任意自定义的二阶可导目标函数。考虑XGBoost在各种机器学习算法大赛及实际应用中均表现出较传统机器学习更优的性能,因此将其用于调和油各批次的子模型建立不失为一种优选方法。
鉴于此,考虑罐式批次成品油调和过程中罐底余油与批次类型对成品油质量指标的影响,提出了一种基于改进MKFCM 与XGBoost 结合的多模型集成建模方法。该方法首先将改进的MKFCM用于罐底油聚类分析及对数据分类,其次基于上述分类数据建立各个子配方的XGBoost模型,最后在配方生成过程中,根据当前罐底余油得出动态融合权值,对各个子模型进行输出融合,以期对不同调和批次生成更精准和更具鲁棒性的通用配方,为企业生产提质增效助力。
1 改进MKFCM-XGBoost 集成配方建模方案的提出
1.1 存在问题分析
就生产企业而言,在成品汽油罐式批次调和过程中,大多采用单一线性配方模型进行各组分比例的计算,而这种调和过程因无质量闭环的精准调控,往往呈现出配方与油品质量失配问题。究其原因,一是企业使用的单一配方模型无法应对调和过程中多工况、多批次问题;二是配方模型未考虑罐底余油及其所属批次类型对成品油质量的影响;三是线性调和配方难以适应由于各组分混合发生化学反应带来的非线性影响。而正是由于调和配方的不精细,使得企业只能以牺牲油品质量过剩为代价尽可能满足油品一次调和成功,从而影响了企业的生产效益。
1.2 集成建模思想的提出
就配方建模方法而言,要解决罐式批次调和工艺下的配方精准建模问题,多模型集成融合无疑是一种好的选择。在多模型集成建模中有两个关键要素。一是如何确定罐底油批次类型数及当前罐底批次类型,这是确定子模型个数和多模型融合权值的前提。考虑MKFCM在聚类算法领域具有优异的性能,而结合调和组分特征仍有提升空间,故拟对其进行改进,并用于罐底油批次个数和批次类型隶属度的确定。二是子模型的精准建立,这是建立优质集成模型的基础。由于XGBoost是一类结构风险最小的算法,具有复杂度低、泛化能力和灵活性强等特点,因而拟基于XGBoost建立各批次子模型。由此便形成了基于改进MKFCM-XGBoost 算法的多模型集成建模思路。
1.3 建模方案与流程
针对前述油品调和存在的实际问题以及工艺需求,结合上述建模思想,基于罐底油批次的多模型集成配方建模过程可分为3 个阶段,具体过程如图1所示。

图1 集成配方建模过程
第一阶段,罐底余油批次类别的确定。首先将历史上罐底余油组分[包括加氢汽油、醚化汽油、甲基叔丁基醚(MTBE)、车用异辛烷、汽油重芳烃、生成油、乙苯、甲苯以及二甲苯9种]添加比例,通过聚类算法确定出批次类型数及各个批次类型隶属度矩阵。
第二阶段,各批次子配方模型建立。根据第一阶段分类数据,采用XGBoost方法,分别建立各调和批次的子配方模型,其输入为成品汽油各项质量指标、罐底油组分添加比例,输出为上述9种组分油的添加比。
第三阶段,在线融合配方生成。根据当前罐底余油,利用第一阶段罐底余油历史数据聚类得到的批次类别进行类型归属计算,求取各子配方模型的融合权值,进而对其融合生成最终的配方。
2 MKFCM方法的改进
2.1 MKFCM算法

式中,x为第个样本;x为第个样本的第个特征;c为第个聚类中心;u为第个样本对第个聚类中心的隶属度;指数为控制样本模糊度的平滑因子;φ为第个特征在希尔伯特空间的映射;为特征映射的个数及核函数的个数;ω为第个核函数的权重值。同时根据每个样本的隶属度最大值进行类别划分,如式(3)。

应用拉格朗日乘子法对目标函数式(1)进行求解,由此可得到隶属度矩阵以及距离矩阵中各元素计算见式(4)、式(5)。


多核模糊均值聚类算法尽管可以较好地处理异构数据源以及数据特征不明显等问题,但具体实现中,仍存在选用不同核函数其聚类效果的差异问题。随着研究者们对核方法研究的深入,极大丰富了核函数的种类,但构造的核函数过于复杂,难以应用于实际,且参数优化整定存在困难。
2.2 MKFCM方法改进
MKFCM 算法中核函数选择与构造是决定其聚类效果的核心问题,结合工程的实用性,考虑高斯核函数相较其他核函数仅需确定一个参数,凭借简单高效的特性被广泛用于核函数构造,故本文仍采用其作为核函数,形式如式(11)所示。

由MKFCM 原理可知子高斯核参数的选取,反映着特征数据映射在希尔伯特空间的位置,从而对聚类效果存在一定影响。虽然Zhou 等提出一种核参数设定公式=,较好地实现了分类,但主要考虑的是样本之间的差异性。
对于调和油的罐底余油而言,样本由9种组分的添加比例组成,数据不仅是样本差异,而是一种样本矢量的差异。考虑罐底油各组分间可能服从不同的核概率分布,受文献[38]的启发,为使核参数的确定简单便利,又能体现各组分的差异,首先设定一个整体核参数,再计算出各个组分距离的最大值,最后算出该组分高斯核函数的参数值,从而使其具有自动适应选取各个罐底组分特征核参数σ的能力。具体各组分核参数的计算如式(12)所示。

基于标准MKFCM 算法,结合前述提出的一种各组分自适应核参数计算方法[式(12)],改进多核模糊-means聚类算法步骤如表1所示。

表1 改进MKFCM算法步骤
改进MKFCM 超参数主要包括聚类个数以及平滑因子等,本文将采用常用判别方法,如肘部法、间隙统计法(gap statistics,Gap)以及轮廓系数等,对上述参数综合分析以确定。
3 基于改进MKFCM-XGBoost 集成建模步骤与流程
3.1 XGBoost算法
XGBoost 是基于梯度提升树的集成算法,梯度提升树的工作原理可用式(13)表示。

式中,为一棵树上的节点数;w为这颗数上的第个叶子节点上的样本权重;g和h分别为损失函数的一阶导数和二阶导数;为L2 正则化的参数;为控制树复杂度的惩罚因子。
式(13)表明梯度提升树可以将无法正确预测或分类的样本,通过构建新的树,再通过梯度下降方式使其预测模型精度不断提升,降低目标函数值。从式(14)可知,XGBoost 为结构风险最小,其在目标函数中加入正则项对模型的复杂度进行约束,使学习出来的模型更为简单,减少过拟合;其次,XGBoost 支持用户自定义目标函数和评估函数,只需定义出的目标函数二阶可导即可。
3.2 改进MKFCM-XGBoost 的集成建模流程与步骤
综前所述,基于改进MKFCM-XGBoost 方法,罐式批次成品汽油调和配方集成建模的具体流程如图2所示。需要强调的是,最终配方生成时,需基于改进MKFCM算法求得当前罐底余油的隶属度向量,并以此作为XGBoost子配方模型的融合权重系数,依据融合式(16),以多模型集成的方式获得罐式批次成品汽油调和的最终配方。
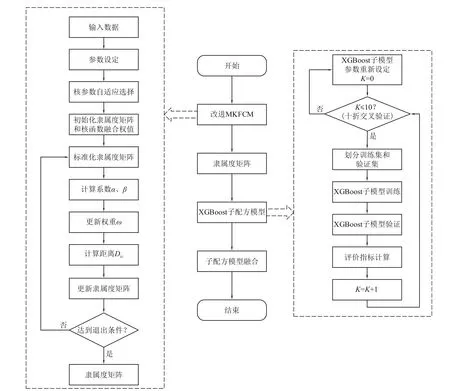
图2 基于改进MKFCM-XGBoost多模型集成建模的配方生成流程

具体步骤可归结如下。
步骤1:改进MKFCM参数设定,主要包括核函数的整体核参数、聚类个数、平滑因子、聚类的迭代结束条件等,再根据式(12)自适应计算各组分高斯核函数的核参数;
步骤2:参数初始化,在聚类之前需要初始化隶属度矩阵以及各个核函数的融合权值;
步骤3:根据表1算法步骤对历史罐底余油的各组分添加比例进行聚类,得到隶属度矩阵;
步骤4:根据式(3)由得到的隶属度矩阵对历史罐底余油数据进行批次类别划分;
步骤5: XGBoost 模型的参数设定,主要包括XGBoost 的集成中弱评估器的数量n_estimators、随机抽样的特征比例(每次生成树采样比例colsample_bytree、每次生成树的一层采样比例colsample_bylevel、每次生成一个叶子节点采样比例colsample_bynode)、集成中的学习率、L1/2正则化参数alpha/lambda、复杂度的惩罚项gamma、树的最大深度max_depth等;
步骤6:用各批次历史数据集训练XGBoost子配方模型,并进行折交叉验证,记录此参数下的模型指标;
步骤7:重新设定XGBoost模型的参数,再次返回步骤6;
步骤8:从若干组参数下选择出较好的子配方模型参数;
步骤9:计算出当前罐底余油的隶属度向量={,,…,};
步骤10:将当前罐底余油的配方比例以及欲达到的成品汽油各项质量指标,作为各个子配方模型输入进行预测,再基于步骤9得出的隶属度向量作为权重系数,利用式(16)进行融合;
步骤11:采用评价指标对模型评价,如果达到预期效果进入步骤12结束此过程,否则返回步骤1;
步骤12:结束。
4 基于改进MKFCM-XGBoost 的成品汽油调和配方建模实验
4.1 数据准备
实验所用数据为某大型炼油厂2017—2020 年真实脱敏数据,通过筛选后数据集共包含:8个油品质量指标特征(其余质量指标特征通过深度解读工艺、方差过滤、检验等方式删除)以及9种罐底油组分添加比例特征,9 种组分添加比例标签。需要进一步说明的是8个油品质量指标特征确定问题,该企业原始生产数据共有质量指标25 个,具体筛选方式包括:与企业资深专家沟通下对工艺的深度解读,确定了最为重要的研究法辛烷值、抗爆指数、芳烃、烯烃、苯含量5个指标,并删除了非数值及数据不全的10 个指标;再通过方差过滤方式,删除了一些数值方差为0的未洗胶质含量、溶剂洗胶质等5个指标;采用检验方式,依据指标特征与添加组分的相关度,筛选出氧含量、密度、硫含量3个指标,删除了相关度弱的饱和蒸汽压和电导率。样本筛选方式包括但不限于删除不符合工业实际工艺、调和失败以及不满足3原则的数据,最终挑选出8个指标特征的1192个样本。从中随机选取80%样本作为训练集,余下20%作为测试集。
4.2 模型性能评价指标
为了对文中方法建立的成品汽油调和配方模型性能进行客观评价,采用常见的评价指标均方误差(mean-square error,MSE)、决定系数()、泛化误差(genelization error,GE),并定义预测配方比例和(predicted blending ratios,PBR)评价指标。
(1)常用评价指标[式(17)~式(19)]

GE = bias()+ var()+≈bias()+ var() (19)
式中,为样本个数;ŷ为模型第个样本第种组分预测值;y为第个样本第种组分真实值;ˉ为第种组分真实值的平均值;SSE为第种组分的残差平方和;SST为第种组分的总离差平方和;bias()为偏差,由模型在训练集上的拟合程度决定;var()为方差,由模型的稳定性决定;为噪声,属于不可控因素,故本文未考虑。
(2)预测配方比例和 由于本文建立的是以9种调和组分添加比例为输出的配方模型,考虑模型的准确性,因此采用各组分的添加比例和作为评价指标,定义如下。
如果某批次成品油的混合质量为(吨),则调和中种组分的添加质量和应为(吨),如式(20)所示。

4.3 实验研究
4.3.1 参数选择
模型参数的选取对模型预测的性能至关重要。为了更为客观地评价本文中建模方法的性能,在实验中作了如下考虑:其一所有对比实验均采用网格搜索以及折交叉验证的方法选取最优的模型参数;其二是保证数据的一致性,将多模型各个子模型的训练集、测试集,共同作为单模型的训练集、测试集。需要采用网格搜索的参数主要包括:改进和未改进MKFCM以及XGBoost的相关参数。
(1)改进MKFCM参数选择 由于罐底油主料成分实际批次未知,因此需通过改进MKFCM确定及相应判别方法辅助完成。本文采用2.2节中提到的3种常用于聚类个数判断的间隙、手肘和轮廓等方法,聚类个数从2~10变化,分别计算间隙值、组内平方误差以及轮廓系数,具体结果如图3所示。

图3 判别方法的结果
间隙统计法是指从满足Gap 值局部最大且Gap 值差值大于参考分布1 个标准差的类别数中,选取最小类别视为最佳聚类个数。图3(a)中实线表示当前类别的Gap值与其相邻之间的差值,星形线表示参考分布在不同类别数上的标准差,三角形线表示不同类别数上的Gap值。可以看出类别数为3、4、6、9、10时,均同时满足前述的两个条件,故最佳聚类数为3。手肘法主要寻求类别数中组内平方误差的拐点,即关注变化率,图3(b)中黑实线表示组内平方误差在前后类别数的差值,虚线表示组内平方误差在不同类别数的值。综合可知,当类别数为3、4 时拐点相对明显,故最佳聚类数为3~4。轮廓系数法则是通过计算轮廓系数值,选取其中最大轮廓系数值所属的类别,其聚类效果更好,图3(c)表示不同类别下轮廓系数的值,显然聚类个数为2~3类时,轮廓系数值更大,故认为2~3类为最佳聚类个数。
综合图3的结果分析,可以得出聚类个数应为2~4 类,结合3 种判别结果,采用投票法可得批次个数应是3 个,这恰与企业的生产实际情况相符,故确定最佳聚类个数为3类,其余改进MKFCM的参数设置见表2。未改进MKFCM算法采用文献[38]的参数设置。

表2 改进MKFCM的参数设置
(2) XGBoost 参数选择 表3 给出了建立XGBoost各批次子配方模型或单一配方模型的部分参数设置,具体见3.2节步骤5中的参数说明。
4.3.2 罐底油成分聚类分析对集成模型的影响
通过4.3.1 节中分析可知,罐底油明显存在批次问题,尽管文献[38]与下文改进的MKFCM 分类算法均可将罐底油数据进行分类,但在集成配方生成时,当前罐底余油所属类别的隶属度对最终生成配方精度却有着重要的影响。针对MKFCM 算法,选出部分样本分别采用MKFCM 算法及改进MKFCM算法进行计算隶属度,结果见表4。
从表4 中可以看出,同样的样本采用MKFCM算法,得到了对各个批次隶属度均近似相等的结果,而采用改进的MKFCM 则隶属度出现了差异。尤其是第6 个样本,采用MKFCM 算法的隶属度均为0.333 左右,而通过改进MKFCM 算法求取隶属度,分别为0.36035、0.54604和0.09359,属于3类的概率出现了明显差异。这说明由于本文考虑了组分特征的差异,自适应选取各核的参数,使得改进后的MKFCM 算法可以更精细地将数据进行分类,从而建立更精准的批次子配方模型,而且在配方在线生成时,由于此隶属度反映了最终配方生成的融合系数,因而会进一步影响最终的模型性能。

表4 部分样本聚类隶属度
4.3.3 批次子配方模型建立与分析
根据上述聚类得出的各批次数据,采用表3中各子模型的参数设置,建立各个批次的子配方模型。为说明基于XGBoost建模的优越性,本文首先对比了11 种常用机器学习算法(多元线性回归、岭回归、lasso 回归、弹性网络、最近邻算法、偏最小二乘算法、决策树、支持向量机回归、随机森林、RBF 神经网络、广义RBF 神经网络)建立子配方模型,并从中挑选出性能较优的最近邻(nearest neighbor,KNN)模型,与XGBoost 建立的子配方模型进行对比;同时为说明本文考虑生产批次建立的多模型集成方法优于单模型方法,这里还通过单一XGBoost 配方模型(模型1)与XGBoost建立的子配方模型进行对比,使用MSE 以及性能指标评价分析,具体性能对比见表5。

表3 XGBoost部分参数的不同设置
从表5 中可以看出,基于XGBoost 建立的子配方模型性能均优于KNN的,说明XGBoost算法用于油品调和子配方模型建立更为优越。对比模型1可知,批次子配方XGBoost的预测精度均优于未考虑批次的XGBoost 单一配方模型(模型1);再以表5中的成品汽油调和主料加氢汽油为例进行更为细致的分析,发现均方误差前者均比后者低约0.1,决定系数亦提升了约0.03,且KNN 批次子配方模型也具有类似的优势。由此说明,同时考虑罐底余油及批次属性建立的子配方模型,对于批次属类预测而言更为精准。

表5 各批次子配方模型性能比较
4.3.4 基于改进MKFCM-XGBoost 集成配方模型建立与分析
为显现本文改进MKFCM-XGBoost 多模型集成配方的优势,分别与模型1、模型2(未考虑罐底油的XGBoost单一配方模型)、模型3(同时考虑罐底油及批次的MKFCM-XGBoost 集成配方模型)的预测结果对比。其中,图4为基于不同模型的加氢汽油预测结果(其余组分预测结果类似,限于篇幅,不再呈现),图5 为几种模型的MSE、直方图对比,表6 及表7 分别给出了几种模型下GE、PBR及MSE、等性能的定量比较。
表6 是对9 种组分预测配方模型的整体评价,分别为泛化误差GE 和预测配方比例和PBR 指标。其中GE 值越小越好,而PBR 越接近100%效果越好。亦可看出,文中提出的集成模型性能最佳,其次为集成模型3,而单一模型2最差。图4是130个加氢汽油真实值样本与几种模型预测结果的比较,可以直观看出,基于本文改进MKFCM-XGBoost 集成模型的加氢汽油预测值以及未改进MKFCMXGBoost 的集成模型3,仅有个别样本与真实样本未重合,其重合度最高;而未考虑罐底余油的单一模型2,与真实样本则出现了多个未重合,重合度最低(其他8 种组分也表现出类似结果)。由此可知,本文考虑批次及罐底余油的集成配方模型,明显优于未考虑批次的单一配方模型。这充分揭示出对于罐式批次调和工艺,考虑批次影响能有效提高配方模型精度;同时改进MKFCM的批次分类与所属批次的隶属度计算,更能体现各种组分特征之间的差异性,从而对数据集划分更为精准,进而据此融合又可进一步提高集成配方模型的预测性能。

表6 几种模型整体性能比较

图4 基于不同模型的加氢汽油预测结果
图5 及表7 是4 种配方模型对于不同组分添加比例的预测性能评估。从图5直方图可以直观看出,4种配方模型对各种组分预测的MSE、对应的数值大小不同,总体来说,MSE以加氢汽油最高,生成油最低,以醚化汽油最高,汽油重芳烃最低。从表7定量精细分析可知,相较于其他方法,本文方法预测各个组分的MSE数值均最小,而均最接近1,说明文中方法具有更精准的预测效果和泛化能力。因此,对于罐式批次成品汽油调和工艺,采用本文方法更适合于各组分添加比例的配方预测。

表7 几种模型配方的性能比较

图5 几种模型配方的性能对比
5 结论
根据某炼油企业成品汽油调和的实际工艺,考虑调和过程中罐底余油及其主料成分存在多批次等影响产品质量指标的因素,提出了一种基于改进MKFCM-XGBoost 的多模型集成建模方法,并将其用于罐式批次成品汽油调和配方的预测,经使用该企业历史生产数据进行实验对比研究,得到了如下结论。
(1)考虑罐底余油组分特征间存在的差异性,提出了基于组分特征的核参数自适应计算法,并用于改进MKFCM 方法,实验结果表明,较传统MKFCM 算法,改进算法能更好地对罐底余油进行分类和融合系数计算,从而为建模分类源头和融合生成配方提供了更精准的依据。
(2)考虑XGBoost算法具有预测精度高、复杂度低及泛化能力强等优势,文中采用XGBoost算法建立了各批次子配方模型,与11 种常见机器学习算法中实验结果性能最优的KNN 比较,对于罐式批次成品汽油调和的子配方模型建立,XGBoost 算法更适合。
(3)考虑罐式调和过程中存在罐底余油及批次问题,本文提出的多模型集成通用配方,无论对MKFCM 算法是否进行改进,与未考虑批次建立的单一配方模型相比,其预测精度、泛化能力及配方比例和均更具优势。
因此,基于本文改进MKFCM-XGBoost 集成建模方法生成的通用配方,可作为罐式批次成品汽油调和工艺生产的依据,有望提高企业生产效益。
