甲醇制芳烃K-means-PSO-SVR局部建模及优化
2022-10-13刘鹏龙许雄飞张玮许鑫张侃王俊文
刘鹏龙,许雄飞,张玮,许鑫,张侃,王俊文
(1 太原理工大学化学化工学院,山西 太原 030024;2 中国科学院山西煤炭化学研究所,山西 太原 030001)
芳烃是重要的有机化工原料,我国对芳烃的需求巨大,但是现阶段国内芳烃供应量存在较大缺口,对外依存度高达50%以上。为了解决国内芳烃产能不足的问题,从我国“富煤、贫油、少气”的能源禀赋出发,研究煤基转化制取芳烃具有重大的战略意义。煤基转化制芳烃主要指的是煤经甲醇制芳烃(MTA),MTA按照反应工艺技术可分为固定床一段法、固定床两段法和流化床法。固定床两段法MTA 工艺相对于固定床一段法具有芳烃总收率和总选择性高的优势,相对于流化床法具有结构简单、造价低廉的优势,因此研究固定床两段法MTA 具有切实的应用前景。建立高精度的固定床两段法MTA 反应产物预估模型,对于提高固定床两段法MTA 反应过程的总体性能、降低生产能耗、提高产物的产率产量及原料的转化率将起到至关重要的作用。
化工过程建模主要包括机理建模和数据驱动建模。其中,机理建模是利用已知的物理定理、经验公式和化学反应先验知识对化工过程进行建模。徐亚荣等在消除内外扩散作用对反应的影响下建立了MTA 五集总动力学模型,并通过实验证明模型相对可靠。施丽丽等在等温固定床反应器中对甲醇制芳烃的反应动力学进行了研究,考察了反应温度和空速对MTA 反应的影响,建立了五集总的动力学模型,并拟合得到动力学模型参数,最后经统计检验验证了所建模型的可靠性。MTA 反应过程涉及众多的物理过程和化学反应,反应网络相当复杂,副反应众多,上述文献中建立的集总型动力学模型建立在等温平推流的理想条件之下,并且经过若干简化。除此之外,MTA 各个工艺参数和产品之间严重耦合,所以建立一个精确的MTA 机理模型非常困难。而数据驱动建模是一种将系统看作一个黑箱,不依赖其内部机理,只通过输入输出数据直接进行建模的方法,这种方法特别适用于机理复杂的化工过程软测量建模。许雄飞等建立了用于固定床两段法甲醇制芳烃产物预测的多元非线性回归模型,测试结果表明:该模型相对于传统的动力学模型,具有产物预测精度高、计算量小以及泛化性强的优点。熊伟丽等提出了一种混沌最小二乘支持向量机的建模方法并将其应用于青霉素发酵过程的参数检测,实验仿真结果表明了该方法对青霉素发酵过程建模的适用性。Serrano等利用人工神经网络来预测实验室规模的鼓泡流化床气化过程中的焦油生成,预测结果具有良好的准确性,从而表明人工神经网络这种数据驱动的模型是预测气化过程中焦油生成的有效工具。
固定床两段法MTA 反应网络复杂,副反应众多,具有复杂化工系统的共性——“强非线性”;动态稳定控制(DCS)系统储存了固定床两段法MTA 大量的过程数据,这些数据大部分都是相似数据,即固定床两段法MTA 过程数据具有“样本趋同”的特点,这导致了可用于数据驱动建模的有效数据少,对固定床两段法MTA 过程的建模属于小样本建模;固定床两段法MTA 实验过程中需控制大量的参数,比如“反应压力”“甲醇空速”“一二段反应器的温度”“预热器的温度”“冷却循环泵的温度”等,这些众多需要控制的参数导致了MTA 过程数据“高维度”的特性;固定床两段法MTA 温度和压力之间存在耦合现象,对任意一方进行控制都会导致另一方发生变动,因此MTA过程数据具有“强耦合”的特性;固定床两段法MTA各工况的可调节范围广,在大工况范围内的不同工况区间MTA 的反应形式和程度都不同,因此说固定床两段法MTA“局部间差异大”。由于大工况、多扰动会导致单一全局模型精度低、泛化能力差,所以单一全局模型不适用于具有样本趋同、高维度、非线性、强耦合、局部差异大特点的固定床两段法MTA 建模。多模型融合建模可以解决上述问题,从而提高建模的精度。仲蔚等提出了一种基于模糊均值聚类的多模型建模方法,该方法先根据模糊聚类后子集中所含样本数的多少来选择局部建模算法,再用模糊聚类后产生的隶属度对各个子模型的输出加权求和得到最终结果,将该方法用于分馏塔柴油倾点软测量建模,结果表明其具有良好的泛化性和预测精度。李修亮等提出了一种基于在线聚类和-支持向量回归的多模型软测量建模方法,并成功运用于加氢裂化分馏塔装置的轻石脑油终馏点在线预测。李丽娟等提出了基于仿射传播聚类的支持向量机多模型建模方法,并将其成功运用于机理复杂的花生四烯酸发酵过程建模。
为了适应固定床两段法MTA 这种复杂工艺原始数据的自身特性,本文结合聚类算法-means、粒子群优化算法(PSO)和支持向量回归算法(SVR)提出了-means-PSO-SVR 局部建模方法,并基于该模型用PSO 算法对固定床两段法MTA 的关键工艺参数进行了优化,从而对工业生产提供指导。
1 甲醇制芳烃K-means-PSO-SVR 局部建模
数据驱动的MTA 模型不依赖于MTA 复杂的内部反应机理,只是由MTA 反应的实验数据建立的一个输入输出之间的隐性映射关系。构建MTA 数据驱动模型的关键在于数据的获取以及建模算法的设计。
1.1 数据来源
为了得到构建固定床两段法MTA 模型所需要的数据,首先参考有关MTA 工艺的文献再结合单因素实验,对影响两段式固定床MTA 反应的工艺参数进行了筛选。固定床两段法MTA 实验中需要控制众多参数,比如预热器温度、一二段反应器温度、反应压力、甲醇体积空速和冷却循环泵的温度。在预实验阶段对上述参数进行了单因素实验,并进行方差分析,最终选定了一段反应温度、二段反应温度、甲醇体积空速和反应压力4个对MTA反应产物影响最显著的因素。然后,参考相关文献并咨询中国科学院山西煤炭化学研究所相关专家,最终确定了表1所示的4个工艺参数的变动范围。
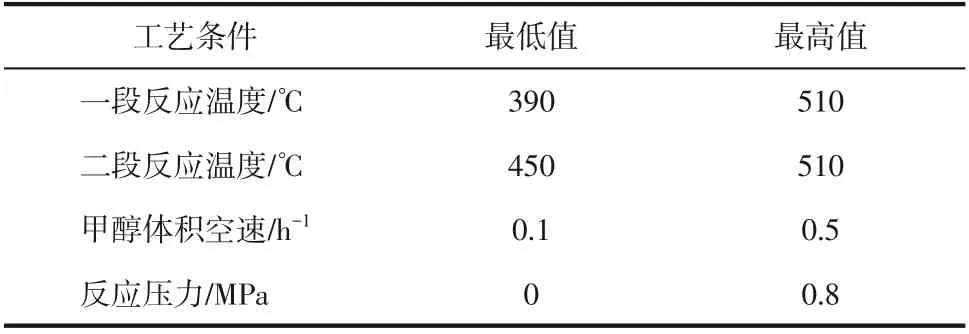
表1 固定床两段法MTA工艺条件的变动范围
对于上述4个影响因素,理论上进行全面试验取得的信息量最大,但是全面试验的经济成本和时间成本都很高,试验设计的目的就是用最少的试验次数取得最理想的实验结果,因此需设计一个尽可能代表样本空间全局特征的试验方案。基于以上原则,以上述4个影响因素为输入,以苯、甲苯和二甲苯(BTX)总收率为输出,用Design-expert软件中的响应面方法自定义设计了四因素五水平的69组试验方案,试验设计的因素水平表见表2。最后,依据已有的两段式固定床MTA 装置进行了实验,实验的工艺流程如图1所示。

表2 试验设计因素水平表

图1 固定床两段法MTA工艺流程
平流泵将原料罐中的甲醇按照设定的流速泵入预热器,预热器中的甲醇在活性氧化铝催化剂的作用下发生脱水反应生成二甲醚。然后,二甲醚和未反应的甲醇进入第一段固定床管式反应器,一段反应器中的甲醇和二甲醚在HZSM-5分子筛催化剂的作用下主要发生MTO 反应生成乙烯、丙烯等低碳烯烃。一段反应器的主要产物低碳烯烃进入第二段固定床管式反应器后,在Zn改性的ZSM-5催化剂的作用下发生脱氢、环化和氢转移等反应生成芳烃和烷烃。随后,高温气相混合产物经换热器冷却后在气液分离罐里进行气液分离,用湿式流量计计量气体产物的体积并用气体取样袋对气相产物进行取样以便进行成分分析。最终,在反应持续一段时间后取出产品罐里累积的液相产物并对其分液、称量记录和成分检测。经检测和计算得到的部分实验数据见表3。
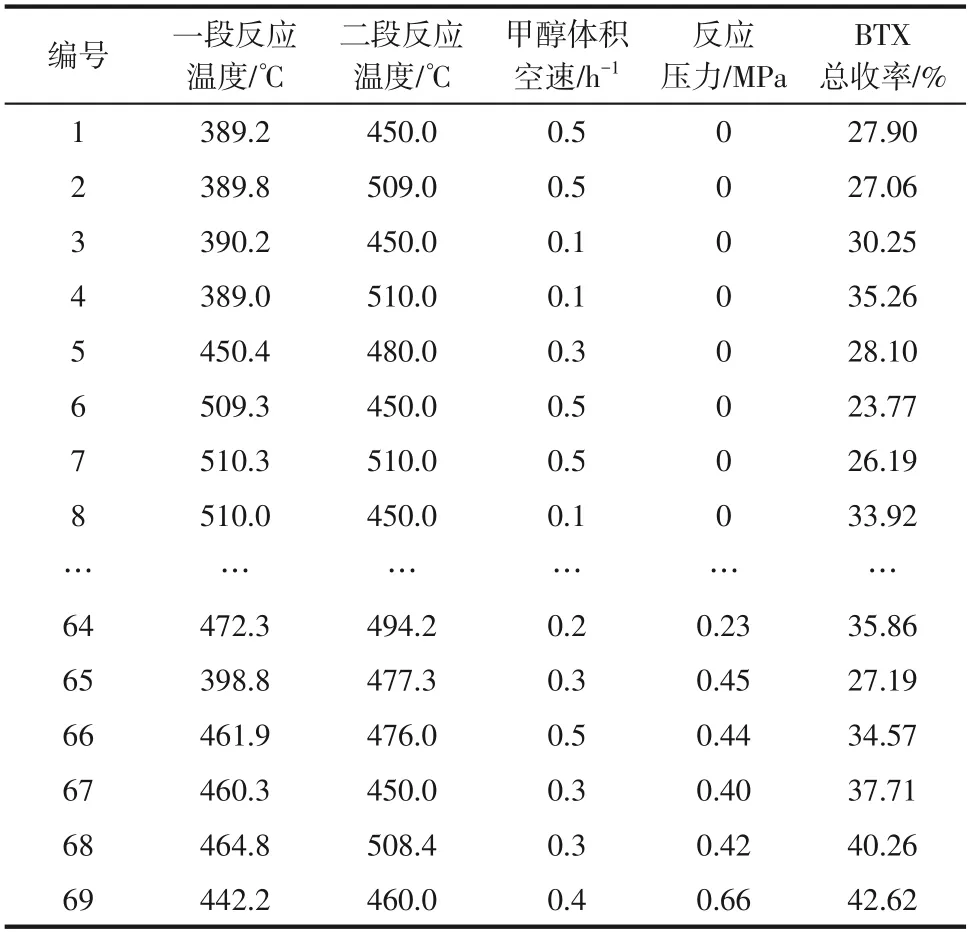
表3 部分实验数据
1.2 模型构建方法
1.2.1-means
-means 算法是一种样本集合划分的聚类算法,基于损失函数最小化的策略将样本集合划分为个类或簇,并且划分之后每个样本到其所属类的中心的距离总是小于其到其他类的中心的距离。简言之就是让簇内的样本点尽量紧密地连在一起,而让簇间的距离尽可能大。
假设给定个样本的集合{…,x},并且每个样本由一个维的向量表示,-means聚类的目标就是将这个样本划分到个不同的类中。means 聚类采用欧氏距离来度量样本之间的距离,样本x和x之间的距离(x,x)定义如式(1)所示。
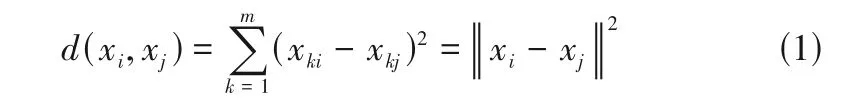
定义样本到其所属类中心间的距离的总和为损失函数,再假设样本划分为(,,…,C),则损失函数的计算公式如式(2)所示。

式中,μ为簇C的均值向量,也称为类的中心,其计算公式如式(3)所示。

-means 聚类实质上就是求解使得损失函数最小化的最优化问题,这是一个组合优化问题。将个样本分成个类,所有可能的分法如式(4)所示。

这个数字是指数级的,这说明-means聚类损失函数的最优化求解是一个NP 难问题,在实际应用中,常用迭代的方法求解。-means 聚类算法的迭代过程包括两个步骤:①随机选择个样本作为初始类中心,然后将样本逐个划分到距其最近的类中心所属的类中,这样就得到一个样本划分结果;②对上次迭代划分的每个类中的样本求均值得到新的类中心。重复以上的步骤直到问题收敛或者达到设定的迭代次数为止。
1.2.2 支持向量回归(SVR)
支持向量回归(SVR)是在支持向量机(SVM)的基础上引入不敏感损失函数来解决非线性系统回归估计的一种算法。SVR和SVM的基本思想相同:通过核函数将原始输入空间线性不可回归的样本点非线性映射到高维甚至无穷维的特征空间,在特征空间中样本点可以回归到一个线性超平面。
假设给定个样本的集合{(x,y),=1,2,3,…,},其中x∈R为输入值,y∈R 为目标值,为样本维度。不敏感损失函数的定义如式(5)所示。
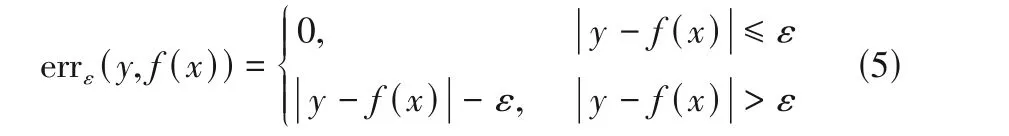
式中,为对应的目标值;()为所求的回归估计函数;>0为误差容忍度。
由于样本线性可回归是样本线性不可回归的特例,所以为了不失一般性假设样本集合{(x,y),=1,2,3,…,}为线性不可回归。在非线性情况下,用一个非线性映射(·)将样本数据映射到高维的线性特征空间,此时估计函数()的形式如式(6)所示。

式中,、分别代表的是高维特征空间中线性超平面的法向量和截距向量。引入松弛变量ξ、

理论上取回归边界上的任意一个标准支持向量便可根据KKT条件定理求得的值,但是出于稳定性考虑,一般取标准支持向量的平均值,则的计算公式如式(10)所示。

式中,为标准支持向量的数量;SV为所有的支持向量集合。
尽管理论上满足Merce条件的函数都可以选作核函数,但是对于特定的问题,选用不同的核函数得到的SVR 回归估计也可能会有很大不同,因此核函数的选择对于SVR模型至关重要。常见的核函数有线性核函数、多项式核函数、高斯径向基核函数、Sigmoid核函数等。
1.2.3-means-PSO-SVR局部建模
固定床两段法MTA 过程数据具有样本趋同、维度高、非线性、强耦合、大工况范围内局部间差异大的特点,为了适应这种复杂工艺原始数据的自身特性从而建立相对较好的数据驱动模型,本文在进行固定床两段法MTA 实验并得到原始数据的基础上,提出了一种-means-PSO-SVR 的局部建模方法,依据该方法建立的模型的二维示意图如图2所示。该方法首先采用“分而治之”的策略用means算法对样本空间的数据进行聚类,实现对样本空间个区域的划分,这样能一定程度上解决MTA 数据非线性和局部差异大的特性。再由于基于VC维理论和结构风险最小化的SVR方法恰好适用于小样本、高维度建模,因此在个局部建模上使用经PSO 算法优化过超参数的SVR 算法。最后,将建立在个不同区域的相互独立的局部模型集成起来组成覆盖整个样本空间的集成模型。
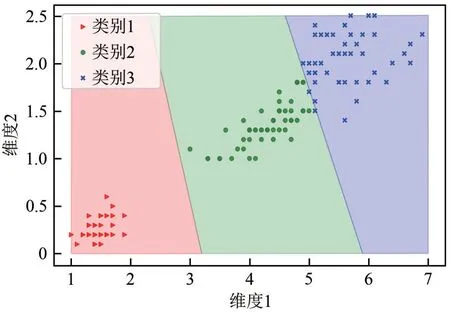
图2 K-means-PSO-SVR模型二维示意图
将实验得到的69 组原始数据采用留一法进行交叉验证,即:每次训练使用68 组数据充当训练集,剩余1组数据充当测试集,这样重复进行69次训练使得每组数据都充当过一次测试集,这样做可以避免由于训练集和测试集样本划分不同而产生的误差。在对-means-PSO-SVR 模型的参数进行调节测试时,发现在选择值为3 即将样本空间划分为三部分并且SVR 选择高斯径向基核函数时建模效果最佳。样本空间划分好之后,在各个样本子空间上基于交叉验证的思想运用PSO 算法对SVR 算法的惩罚参数和核函数带宽进行寻优。然后在3 个样本子空间上用各自最优的和进行SVR 建模。在对测试集的样本进行预测时,首先分别计算该测试样本到3个类中心的欧氏距离,然后将其归于距其欧氏距离最小的类中心所属的类,最后用其所属类的SVR模型进行预测。
1.3 模型评价指标
以测试样本集上的拟合优度()和均方误差(MSE)来衡量所建立模型的精度。拟合优度和均方误差的计算分别如式(11)和式(12)所示。

式中,y和f分别表示第个样本的目标值和预测值。
2 结果与讨论
为了验证提出的-means-PSO-SVR 局部建模方法对固定床两段法MTA 工艺的适用性,除了means-PSO-SVR 外,还用单一全局SVR、BP 神经网络和线性回归这3 种建模方法对固定床两段法MTA 工艺进行了数据建模,并将这些MTA 模型进行比较分析。在不添加噪声时,4 种建模方法对BTX总收率的预测结果如图3所示,从中可以看出线性回归的建模效果最差,BP 神经网络的建模效果相对线性回归有所提升,单一全局SVR 又优于BP 神经网络,-means-PSO-SVR 建模效果最佳,测试集可以达到0.88。这表明:由于MTA 过程数据高度非线性,线性回归这种线性模型并不能对数据进行较好的拟合;由于MTA 过程数据具有小样本、高维度的特性,基于结构风险最小化的单一全局SVR 的建模效果优于基于经验风险最小化的BP 神经网络的建模效果;由于MTA 过程数据在大工况范围内局部间差异大,-means-PSO-SVR 方法的建模效果优于单一全局SVR 的建模效果。综上所述,-means-PSO-SVR 建模方法可以有效解决固定床两段法MTA过程数据样本趋同、维度高、非线性、强耦合、大工况范围内局部间差异大的问题。

图3 4种建模方法对BTX总收率的预测值和真实值对比
在对原始数据加入了不同水平的、服从高斯分布的噪声之后,再用上述提及的4种建模方法分别进行建模,以此来比较所建立的不同模型的鲁棒性。表4对不同噪声水平下的各建模方法的预测精度进行了量化比较。分析表4 可知,4 种建模方法对BTX 总收率的预测性能都随着噪声水平的升高而逐渐下降;在相同水平的噪声下,-means-PSO-SVR建模方法的性能明显优于其他3种建模方法,并且在噪声水平为20%时仍能达到0.72,这表明-means-PSO-SVR 局部建模方法对噪声具有很强的鲁棒性。除此之外,分析表4 还可以发现:不论在何种程度的噪声水平下,这4种建模方法的建模效果都符合原始数据无噪声情况下的规律,这也是对上文分析结果的一个有力佐证。以上的比较和分析进一步验证了本文提出的-means-PSO-SVR 局部建模方法对固定床两段法MTA 这种强非线性系统的适用性。

表4 不同噪声水平下4种建模方法预测精度比较
3 MTA工艺参数优化
在用-means-PSO-SVR 局部建模方法建立了数据模型之后,以此为基础运用粒子群优化(PSO)算法对两段式固定床MTA 工艺的关键工艺参数进行了优化。PSO算法的基本思想是通过群体中个体之间的协作和信息共享来寻找最优解,其优势在于原理简单、容易实现并且无需调节众多参数。
PSO算法的算法流程如图4所示,该算法首先在可行解空间中初始化一群粒子,每个粒子都代表极值优化问题的一个潜在最优解,用位置、速度和适应度值3项指标来表示粒子特征。粒子在解空间中运动,并且在每一次迭代过程中粒子都通过个体极值和群体极值来更新自身的速度和位置,粒子速度和位置的更新分别如式(13)和式(14)所示。

图4 粒子群优化算法的算法流程

粒子每更新一次位置就计算一次适应度值,并且将粒子的适应度值与个体极值、群体极值进行比较从而更新个体极值和群体极值的位置。随着计算的推移,通过探索和利用搜索空间中已知的有利位置,最终粒子围绕一个或多个最优点聚集,使得优化问题收敛。
将每个粒子的速度和位置分别用1个四维向量来表示,向量的4 个维度分别代表两段式固定床MTA工艺的4个关键工艺参数:一段反应温度、二段反应温度、甲醇体积空速和反应压力。每个粒子的适应度值是将自身的位置信息代入建立的means-PSO-SVR 模型计算得出的,其物理意义是BTX总收率的倒数,粒子群优化的目标就是寻找适应度值的全局最小值。将50 个初始种群粒子初始化后迭代100次,迭代寻优过程如图5所示。由图5可知,在迭代19 次以后群体极值已不再减小,这说明此时寻优的解已经收敛到全局最优值即BTX总收率最高值处。优化结果预测的最高BTX 总收率为44.30%,对应的工艺参数为:一段反应温度446.2℃、二段反应温度467.3℃、甲醇体积空速0.4h、反应压力0.64MPa。

图5 粒子群优化算法迭代寻优过程
为了验证优化结果和实际反应的一致性,在两段式固定床实验装置上严格按照PSO 算法寻出的MTA最佳工艺参数进行了5次独立重复实验,对产品进行检验计算后得到如表5 所示的实验结果。5次重复实验平均BTX总收率为44.02%,与预测值44.30%的误差在1%以内,因此认为PSO算法的寻优结果是可靠的。
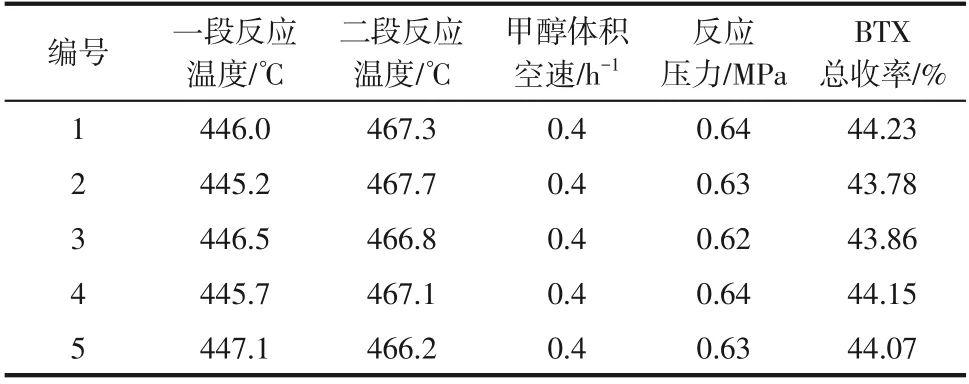
表5 最优工况下5组独立重复实验结果
4 结论
针对固定床两段法MTA 过程数据样本趋同、维度高、非线性、强耦合、大工况范围内局部间差异大、单一全局模型对目标产物BTX 总收率的预测效果不佳的问题,提出了-means-PSO-SVR 局部建模方法。在3 种噪声水平下对-means-PSOSVR、单一全局SVR、BP神经网络和线性回归4种算法的建模效果进行了比较,结果表明不论在何种程度的噪声水平下,建模效果的优劣情况皆为means-PSO-SVR>单一全局SVR>BP 神经网络>线性回归,并且-means-PSO-SVR 对噪声具有很强的鲁棒性。分析原因可能为:①MTA 反应过程是一个强非线性系统,因此线性回归这种线性算法的拟合程度最差;②基于结构风险最小化的SVR 算法相比BP 神经网络算法更适用于小样本和高维度建模,因此对于具有小样本、高维度特性的固定床两段法MTA 过程数据,单一全局SVR 的建模效果要优于BP 神经网络,这也是建立局部模型时使用SVR 算法的原因;③在大工况范围内的不同工况点,MTA 实际反应过程差别巨大,单一全局模型并不能准确描述样本空间内局部间的差异性,因此建立的-means-PSO-SVR 局部模型性能要优于单一全局SVR 模型。综上所述,本文提出的means-PSO-SVR 局部建模方法适用于固定床两段法MTA 建模,所建立的模型准确度高、泛化性和鲁棒性强。
在所建立的-means-PSO-SVR 数据模型基础上运用PSO算法对固定床两段法MTA的4个关键工艺参数进行了优化,得到的最高BTX 总收率为44.30%,对应的最优工艺参数为:一段反应温度446.2℃,二段反应温度467.3℃,甲醇空速0.4h,压力0.64MPa。按照优化所得的最优工况进行了5次独立重复实验,实验结果验证了优化结果的可靠性。
符号说明

—— 惯性权重
—— 误差容忍度
μ—— 第类的均值向量
ξ,ξ* —— 第个松弛变量
,+1 —— 分别为第、+1次迭代
g—— 群体极值的第维分量
—— 第个粒子的第维分量
