基于决策树和BN的自动驾驶车辆行为决策方法
2022-10-10刘延钊黄志球沈国华王金永
刘延钊,黄志球,沈国华,王金永,徐 恒
(1.南京航空航天大学计算机科学与技术学院,江苏 南京 211106;2.南京航空航天大学高安全系统的软件开发与验证技术工业和信息化部重点实验室,江苏 南京 211106;3.软件新技术与产业化协同创新中心,江苏 南京 210093)
0 引 言
自动驾驶车辆是包含感知、决策和控制三大功能模块的智能体系统[1]。其中,行为决策模块的功能是进行自动驾驶车辆驾驶行为决策,其决策结果关乎自动驾驶车辆的行驶安全。因此,提高行为决策模块的智能化水平是自动驾驶领域的研究热点和难点。21世纪初,美国成功举办自动驾驶车辆公开赛,掀起了全球自动驾驶技术研究的热潮。近些年,我国自动驾驶产业蓬勃发展,随着科研技术的突破和成果的产出,自动驾驶技术逐渐地改变了现代人类的生活方式。然而,随着近些年自动驾驶车辆事故的发生,在社会上也引起了民众对于车辆安全方面的普遍担忧。
城市交通中存在的不确定性因素给自动驾驶车辆识别和判断交通情况并做出合理驾驶行为造成极大的困难。这些不确定性主要体现在交通参与者行为难以预测。因此,在城市中进行自动驾驶是一个突出的挑战,特别是在许多激进的、高速的交通参与者面前[2]。麻省理工学院的自动驾驶车辆技术(Massachusetts Institute of Technologyautonomous vehicles technology,MIT-AVT)研究结论表明:由于人类行为在不同层面的差异,自动驾驶系统在实际应用过程中面临巨大挑战,这些挑战来自于人与环境交互过程中的不确定性[3]。主要包括以下几类:①人类在参与交通过程中的行为具有不确定性,主要包含与其他车辆、行人等交通参与者之间信息交互时的不确定性。②人工驾驶员风格、经验和其他有助理解、判断人工驾驶行为等因素的不确定性。③人类对驾驶环境的判断和驾驶方式的差异性。④人类驾驶员驾驶车辆熟练度的差异性。⑤车辆发生故障时,人类驾驶员故障排除能力的差异性。
自动驾驶技术融入城市交通中,能够改善交通环境,提高出行的安全性,减少交通事故的发生频率。然而,距离自动驾驶完全进入现代交通流还要几十年时间。在此期间,自动驾驶车辆不可避免地要与其他车辆以及车辆内部和外部的人进行交互[4],因此人类驾驶员仍是最关键的决策者[5]。
当前,由于对驾驶行为分类的研究并不完善,自动驾驶领域内并没有形成共识以供参考来准确地判断不同的驾驶行为类别。现有研究对于分类标准的定义给出了不同的方式。例如Augustynowicz[6]考虑将驾驶行为规范为[-1,1]的离散值。Constantinescu等[7]采用主成分分析(principal component analysis,PCA)法筛选出5类驾驶行为。Miyajima等[8]利用高斯混合模型(Gaussian mixture model,GMM)来分类驾驶员的行为。Yurtsever等[9]使用词袋(bag of words,BOW)和K均值聚类算法分类驾驶行为。Sama等[10]使用一个自编码网络来获取基于道路类型的驾驶特征。Liu等[11]利用三通道RGB(red green blue)来描述不同的驾驶行为,并利用深度稀疏自编码器分类不同的驾驶行为。
这些方法虽然在一定程度上对驾驶风格进行了定义,但目前的研究尚未形成共识,主要原因在于这些方法对人工驾驶车辆行为相关知识获取和表达的研究都限定在某个具体的交通场景中,且预测模型大多为黑盒模型,可解释性差,若通过丰富场景进行知识获取,经济成本和时间消耗巨大,因此在应对复杂多变的城市交通环境时存在明显的局限性。在知识的获取和表达方面,目前主要的研究方法有模糊理论、人工神经网络、专家系统。这些方法能够对知识进行简单有效地表达,但缺点是无法对知识进行自动获取,而且实时性和推理速度方面存在缺陷。人工神经网络虽然能解决知识获取的问题,但在模型拟合上容易存在“过学习”和“欠学习”的问题,且模型灵活性较差,学习收敛速度慢[12]。
决策树算法是支持决策过程可视化的白盒模型,在知识自动获取和准确表达方面具有明显优势,便于引入专家经验理解人工驾驶车辆行为和交通场景中多源异构信息的关系,极大地降低了研究影响人工驾驶行为因素的时间和成本。另外,通过决策树剪枝可以有效避免过拟合问题,因此在应对驾驶行为的分类问题上具有明显优势。
自动驾驶车辆行为决策方法按照实现逻辑可以分为以下两类:
(1)基于规则的行为决策方法:常用方法为有限状态机。该方法的逻辑为根据驾驶经验和交通法规等约束,提前建立规则匹配机制,在车辆驾驶过程中根据实际情况匹配具体的驾驶行为[13]。代表性的应用包括国防科技大学的红旗CA7460无人车[14]、美国福特集团与卡内基梅隆大学合作的BOSS无人车[15]、麻省理工大学的Talos无人车[16]、斯坦福大学与德国大众公司合作的Junior无人车[17]等。基于规则的行为决策方法逻辑性强,规划推理能力强,但规则设计复杂、成本高,对实际场景覆盖率低,推理准确率低。
(2)基于学习算法的行为决策方法:此类方法的逻辑为利用大量数据进行模型训练来模拟真实的驾驶环境,通过模型完成驾驶行为选择[18]。基于学习算法的行为决策中常用的方法为:部分可观测马尔可夫决策过程[19](partially observable Markov decision process,POMDP)、卷积神经网络[20]、贝叶斯网络(Bayesian network,BN)等。Ulbrich等[21]通过提出基于非线性动态BN的场景建模方法,提高了自动驾驶车辆换道的可靠性。Brechtel[22]在POMDP模型的基础上嵌入BN,减小了行为决策过程中由于环境感知不确定带来的风险。Liu等[23]利用深度强化学习算法解决高速公路上的水平决策问题,无碰撞地完成了导航任务。代表应用有智能先锋II号无人车[24]、英伟达端到端卷积神经网络决策系统[25]等。与基于规则的行为决策方法相比,基于学习算法的行为决策方法具有更高的推理准确率和真实场景覆盖率。同时,也存在一些大数据领域的普遍问题,即数据依赖性强、模型可解释性差[26]等问题。
针对当前自动驾驶车辆行为决策研究中存在的缺乏人工驾驶车辆行为相关知识的获取与表达、对交通场景中不确定性因素考虑不充分等问题,本文提出利用决策树算法进行人工驾驶行为分类,并结合BN概率推理的自动驾驶车辆行为决策模型。
1 人工驾驶车辆行为分类模型
1.1 决策树的概念
决策树是依据决策建立起来的、用来分类和决策的树结构。概括地说,决策树算法的逻辑可以描述为if-then,根据样本的特征属性按照“某种顺序”排列成树形结构,将样本的属性取值按照if-then逻辑逐个自顶向下分类,最后归结到某一个确定的类中。“某种顺序”是指决策树的属性选择方法。以二叉决策树为例,树形结构由结点和边组成,决策树的结点代表分类问题中样本的某个属性,边的含义为是与否两种情况,即样本属性取值是否符合当前分类依据。
1.1.1 决策树的属性选择方法
决策树学习的关键在于选择划分属性。属性的选择流程可简略表述为:首先,计算训练样本中每个属性的“贡献度”,选择贡献最高的属性作为根结点。根结点下扩展的分支将依据根结点所代表属性的取值决定(例如根结点代表的属性为性别,则分支为男和女)。然后,将已经被选择为结点的属性从候选属性集中剔除,接着不断重复进行候选属性集合中剩余属性的“贡献度”的计算和选择,直至达到预设的模型训练阈值(例如达到决策树最大深度)。最后,得到一棵能较好地拟合训练样本分布的决策树模型。
根据属性选择方法的不同,可以把决策树的生成算法分为以下3种:
(1)ID3(iterative dichotomiser 3)算法:信息增益大的属性优先。首先,计算所有候选属性的信息增益,选择其中信息增益最大的属性作为根结点。然后,按照根结点所代表属性的取值决定分支情况。其次,将已选择属性从候选集中删除,并计算剩余属性的信息增益。最后,选择信息增益最大的结点作为子结点,直至所有属性都已选择。信息熵是用来衡量样本纯度指标的,是计算信息增益的前提,定义为
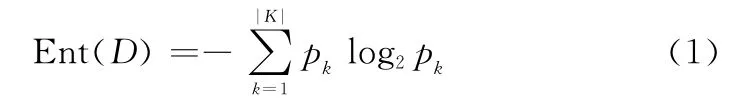
式中:D为样本集合;p k为D中第k类样本所占的比例,其计算方式为

式中:Ck表示集合D中属于第k类样本的样本子集。
假设D中某个具有V个取值的属性为A,取值分别为{a1,a2,…,a V}。根据不同的取值将D中的样本划分为V个子集。其中,取值为av的样本属于第v个子集,记作D v。
根据式(1)可以计算出样本D v的信息熵。通过增加各分支权重|D v|/|D|使样本数量多的结点具有更大的“影响”[27]。首先,计算属性A对于数据集D的条件熵Ent(D|A):
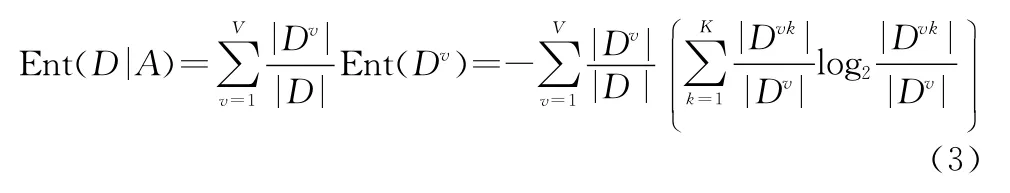
然后,计算用属性a对样本集合D进行划分所得的信息增益=信息熵-条件熵:
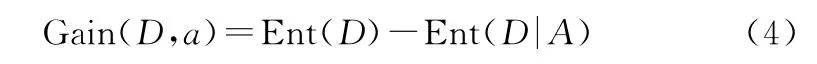
通过对所有属性的信息增益进行计算,选择信息增益最大的属性作为结点添加入树,重复进行属性的信息增益计算和选择过程,最终构建出一棵分类决策树。
(2)C4.5算法:信息增益率大于平均值的属性优先。信息增益率即为各属性信息增益所占比例。因此,属性取值的个数越少,信息增益率反而越高,这就导致信息增益率准则更偏向于取值个数少的属性。因此,在ID3算法中各属性信息增益计算的基础上,C4.5算法运用了一个启发式原则:首先,计算每个属性的信息增益率,进而计算所有属性的平均信息增益率。然后,按照信息增益率与平均信息增益率的大小关系,将属性分为两类。最后,选择信息增益率大于平均值,且数值最大的属性。信息增益率的计算方式为
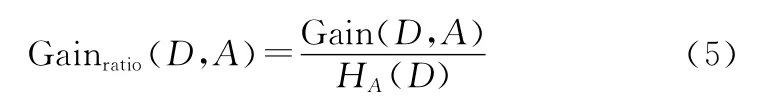
式中:H A(D)是与属性A有关的定值。通常,取值为样本集合D的信息熵:

(3)分类与决策树(classification and regression tree,CART)算法:基尼指数小的属性优先。CART不再以信息增益为基础进行属性的选择,而是采用一种代表样本不纯度的指标对属性进行度量,这种不纯度指标叫做基尼指数。基尼指数越小代表样本的纯度越高。基尼指数的定义为
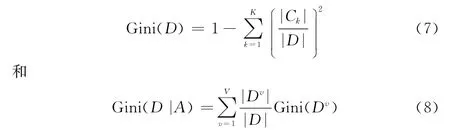
1.1.2 决策树算法选择
决策树依靠不同的属性选择方法生成树结构,但如果不加干预地任其生长,可能导致生成的决策树规模太过庞大,对训练数据学习的“过分好”,这类问题被称为过拟合。剪枝策略常被用于减少过拟合风险。剪枝是指对决策树的分支进行修剪,防止决策树规模过大的一类方法。按照对分支修剪时间的不同,可分成“预剪枝”和“后剪枝”策略。其中,预剪枝策略是指在未确定划分结点前,判断决策树是否进一步生长的。例如,该结点划分并不能提高分类准确率,则拒绝使用该结点进行划分。后剪枝是指在已经生成决策树的基础上加以调整,得到更精简的后剪枝决策树的策略。但实际上修剪树是为了缩小决策树的规模,如果修剪过度,则会导致学习结果过于“简单”,从而导致欠拟合问题。
ID3算法以信息增益为标准选择属性,缺点为:①没有剪枝策略,容易导致过拟和问题。②属性取值个数越多,信息增益越大。③只能用于处理离散分布的属性。④没有考虑缺失值。
对于ID3算法存在的缺点,C4.5算法有了一定的改进。C4.5通过剪枝策略可以有效降低过拟合风险。以信息增益率为标准,克服了ID3对取值个数多的属性的倾向问题。通过选择相邻样本平均数作为划分点,来处理连续属性。用没有缺失值的样本子集来填充,解决数据缺失的问题。但C4.5算法同样存在一些不足:①剪枝策略可以再优化。②C4.5使用多叉树,效率不如二叉树高。③C4.5只用于分类,不能用于回归任务。④C4.5基于熵运算,设计大量对数运算,耗时较长。
CART算法在C4.5的基础上进行了改进。CART算法基于“代价复杂度”,剪枝效率更高。CART是二叉树结构,运算效率高,且既可以用于分类,也可以用来回归。CART算法通过计算基尼指数进行结点划分,避免了费时的对数运算。
基于以上不同算法的对比,并结合实际应用中自动驾驶车辆数据集庞大,对运算速度要求高,需要对缺失值处理等原因,本文采用性能最好的CART算法作为构建决策树模型的方法。
1.2 预测模型
人工驾驶行为预测模型如图1所示。
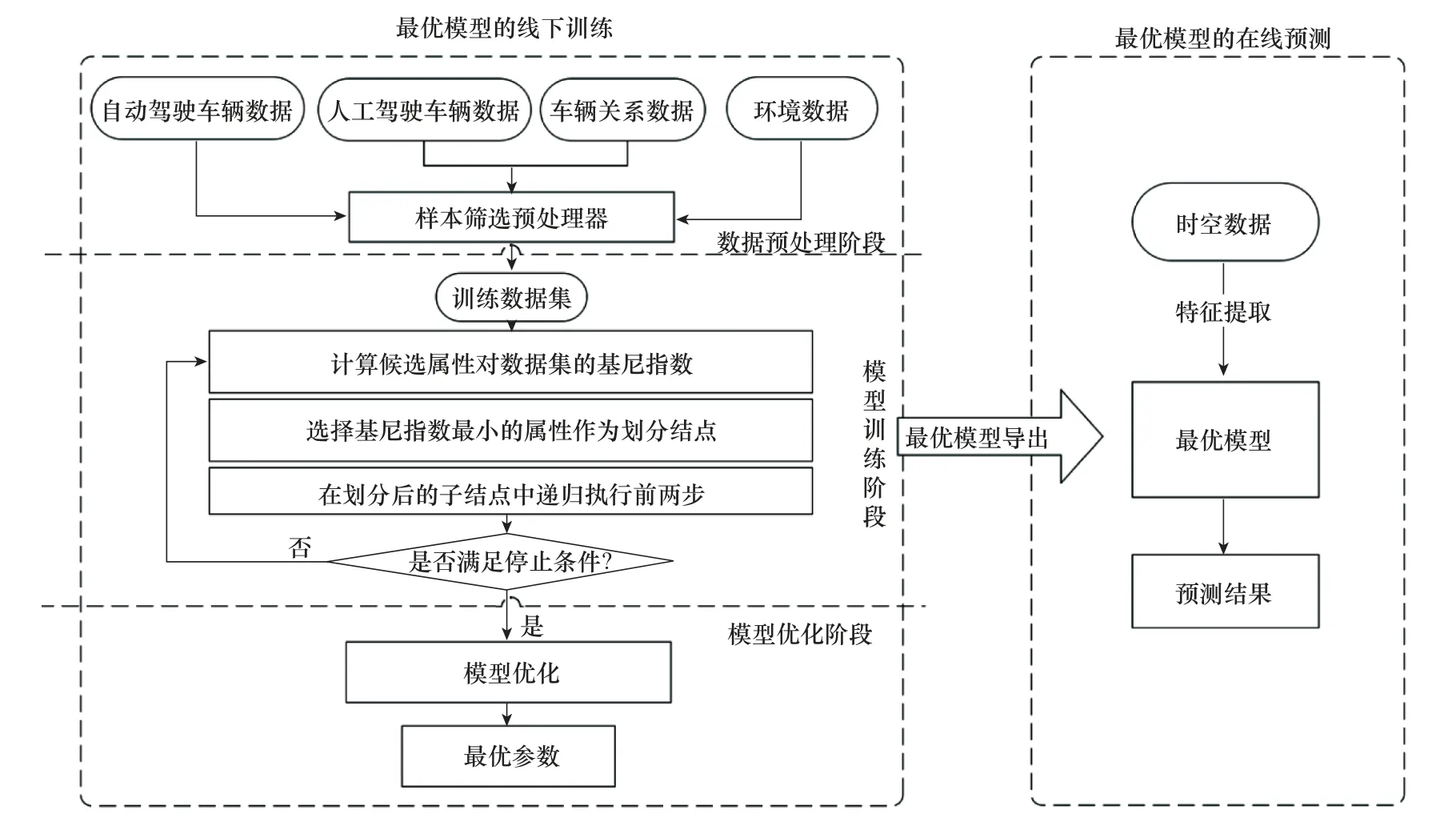
图1 人工驾驶行为预测模型Fig.1 Prediction model of human-driving behaviors
1.2.1 线下训练
人工驾驶行为预测流程分为模型的构建和行为预测两部分。模型的构建部分就是线下训练获得最优模型并导出的过程,该流程主要分为3个阶段:
(1)数据预处理阶段:该阶段的目的是采集数据并提取数据特征形成训练模型的数据集。首先,利用辅助驾驶软件PreScan搭建仿真场景并采集数据,通过PCA降低数据的相关性,获得了人工驾驶车辆速度、与人工驾驶车辆相对距离、刹车次数等数据主属性。然后,计算得到与人工驾驶车辆相对速度等属性具有一定相关性,且对分析人工驾驶行为具有重要意义的属性。最后,对数据进行筛选并进入模型训练阶段。
(2)模型训练阶段:该阶段的目的是根据训练数据对决策树模型进行学习。首先,计算每个属性对于数据集的基尼指数。基尼指数代表了有放回抽样实验中,从一个样本空间中选择的两个样本不相同的概率。然后,选择基尼指数最小的属性作为划分结点,并产生分支。其中,每个分支代表的子树部分的数据纯度比父结点划分前数据纯度高,以此来代表对样本进行了进一步的分类。最后,递归地执行属性的基尼指数计算。随着结点的划分,每个结点中的样本纯度逐渐增大,即更倾向于同一类别。为了防止决策树的过拟合问题,在模型训练时可以预先设置训练阈值(如决策树最大深度等)。当结点的分裂过程中参数达到了训练阈值,就结束决策树的生成过程,并通过后剪枝策略将生成的决策树中那些对样本分类“贡献”低的分枝剪掉。剪枝策略能够缩小决策树的规模,有效地防止过拟合问题,从而提升训练模型的泛化能力。
(3)模型优化阶段:该阶段的目的是对模型的最优参数进行选择。由于搜索过程是一个遍历模型候选参数的过程,若模型参数的取值过多,则遍历过程复杂且耗时。因此,采用网格搜索的模型参数选择方法。首先,通过设置每个参数的取值范围和增量大小,降低遍历过程的复杂度,从而获得最优模型参数。然后,导出最优模型训练参数和模型文件,用于最优模型的线下预测阶段。
1.2.2 在线预测
人工驾驶行为预测模型的在线预测部分的功能是将自动驾驶车辆传感器获得的时空数据输入到最优模型中,进行人工驾驶行为在线预测。最优模型的分类精度与行为预测结果将组合成标签 概率对,作为自动驾驶行为决策模型的一个输入。
1.3 分类模型评价指标
二分类问题中通常包括两类结果,即正类和反类,根据分类模型对属于不同类别的数据预测结果的不同,可以将结果分为以下4种情况:
(1)真正类TP:实际与预测结果均为正类。
(2)真反类TN:实际与预测结果均为反类。
(3)假反类FN:实际为正类,预测结果为反类。
(4)假正类FP:实际为反类,预测结果为正类。
根据以上4种分类结果,定义查准率P和查全率R分别为

在实际的分类模型评价标准中,最常用的是F1度量,它是查准率P和查全率R的调和平均。

由于人工驾驶行为分类模型的训练是一个多分类任务,考虑F1度量的两种计算方式,微观F1(micro-F1)和宏观F1(macro-F1),两者的区别在于micro-F1是通过计算所有类别总的P和R,然后计算F1的值,而macro-F1是通过计算每个类别的P和R,然后计算F1,最后将每个类别的F1取平均得到。
由于本文人工驾驶行为分类模型训练所用数据较平衡,故采用macro-F1作为分类模型的评价指标。
2 基于BN的行为决策模型
2.1 BN的相关概念
BN是一种以贝叶斯公式为基础的概率图模型,BN的结构是一个有向无环图(directed acyclic graph,DAG),图中结点被称为BN结点,若结点之间存在依赖关系,则由一条有向边连接,方向为被依赖结点指向依赖结点[28]。BN的参数由结点的概率值和结点间的条件概率表(conditional probability table,CPT)组成,CPT用来描述属性的联合概率分布。具体来说,一个BN由结构G和参数θ两部分构成,即BN=〈G,θ〉,网络结构G是一个DAG,每个结点对应一个属性,若两个属性有直接依赖关系,则二者由一条有向边连接起来,由父结点指向子结点;参数θ定量描述这种依赖关系,假设属性x i在G中的父结点集合为πi,则θ包含了每个属性的条件概率表
BN结构表达属性之间的条件独立性,给定父结点集,BN假设每个属性与其非后裔属性独立,即属性x1,x2,…,x d的联合概率分布定义为

2.2 BN的学习与推断
2.2.1 BN学习
BN通过有向边将网络中各个结点连接起来,当其中的某个结点状态发生变化时,与其直接或间接相连的结点也会随之更新,这个过程称为贝叶斯推理。推理的前提是构建出符合问题需求的BN模型,为了充分利用BN概率推理的能力,学习得到一个好的DAG和CPT十分重要。
BN学习分为结构学习和参数学习两部分[29]。
结构学习是指构建出符合问题需求的DAG结构,常用方法为基于采样的马尔可夫链蒙特卡罗(Markov chain Monte Carlo,MCMC)方法,该方法是基于马尔可夫链实现的参数估计方法。通过构造先验分布,来模拟待估计参数可能的分布情况。随着状态的变化,马尔可夫链逐渐收敛,从收敛后的马尔可夫链中按照一定的采样标准进行样本采样,用采样的样本逼近待估计参数的后验分布。
假设,存在连续型变量x∈X,变量x的概率密度为p(x),根据连续性变量的概率定义可知,变量x在其定义域X内的期望为

如果存在另外的函数f,满足f(x)在定义域X内均有定义,那么f(x)在定义域X上的期望为
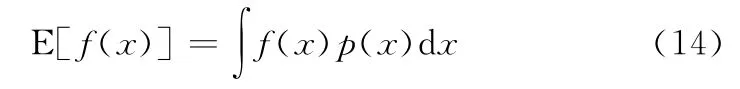
则式(14)的无偏估计为
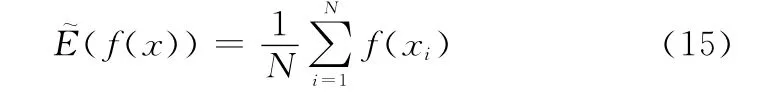
式中:x1,x2,…,x n是独立同分布的随机变量。
如果连续变量x的概率密度p(x)比较复杂,那么式(14)中的积分运算将无法进行。而MCMC方法通过采样样本来逼近真实分布的方式避免了困难的积分运算问题。其中,采样的样本是有限个数的,并且服从真实分布情况的。
将马尔可夫链状态转移的概率概率记作T(x′|x),t时刻的状态分布记作p(x t)。如果满足如下条件:
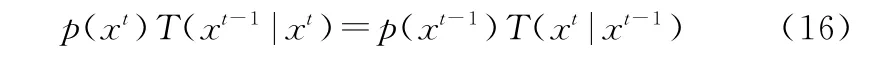
那么,称p(x)为马尔可夫链的平稳分布。式(16)被称为马尔可夫链的细致平稳条件。
MCMC的采样方式中,具有代表性的算法为Metropolis-Hastings(MH)算法。通过“拒绝采样”来近似得到平稳分布,M H算法流程如下所示。

参数学习是指在已知贝叶斯网络结构的情况下,构建当前结构各结点代表的属性之间的CPT。目前最常用的参数学习方法为最大似然估计[30](maximum likelihood estimation,MLE),通过采样数据进行参数估计。假设数据集D c包含训练集D中所有属于类别c的样本,并且这些样本满足独立同分布性质,那么,便可得到参数θc对于数据集D c的似然为
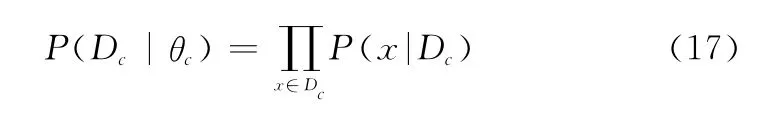
P(D c|θc)取最大值时的参数值便是θc进行最大似然估计。求解过程如下:
由于似然函数为连乘形式,且概率P满足P>0,所以对似然函数等号两边同时取对数得到对数似然(log-likelihood,LL):
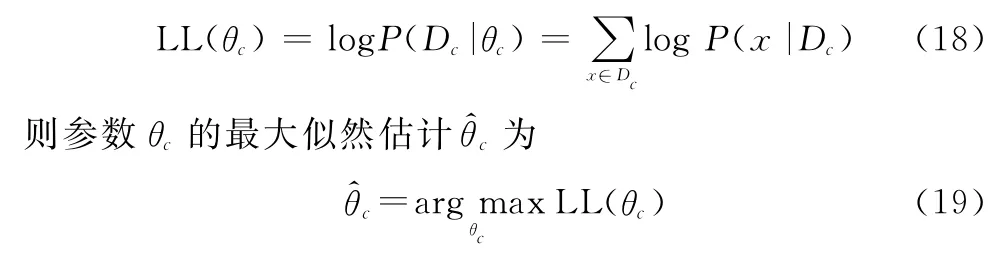
2.2.2 贝叶斯推断
BN训练好(即结构和条件概率表确定)后,便可以用来进行“查询”即概率推理[31-32],通过一些属性变量的观测值来推测其他属性变量的取值,这个过程被称为贝叶斯推断,属性变量观测值称为“证据”。
贝叶斯推断的过程就是贝叶斯公式计算的过程。贝叶斯公式为

式中:H表示待推断假设;E表示证据;P(H)称为先验概率,即证据E未被观测前对于H基于现有知识的认知;P(E)称为归一化常数,或边缘似然率,是一个定值;P(H|E)称为后验概率,是推断的结果;P(E|H)称为似然,指在给定假设下,证据与假设的相容程度,是E的函数。
贝叶斯推断的具体步骤如下:
步骤1确定BN结构和CPT,并基于先验知识,构建初始的BN。
步骤2观测到证据后,根据证据更新网络。若证据是根结点,则沿着边缘正向传播,若为子结点,则沿着边缘反向传播。即根据贝叶斯规则,计算新的先验条件概率。
步骤3根据计算出的先验条件概率,沿着边缘逐个更新各结点的后验概率。
步骤4当有新的证据被观测到时,执行步骤2和步骤3更新所有结点的后验概率。
2.3 BN决策结果的选择依据
BN实际是由一些结点以条件概率的形式,直接或间接连接起来的,直观上看,结点与结点之间靠有向边连接,但实际是以概率的形式互相影响的,所以BN支持从原因到结果的正向推断,也支持从结果到原因的反向推断。同时BN支持流式数据的更新,观测到证据后BN得到更新,而当新数据到来时,前期更新得到的后验概率又作为新证据的先验概率参与BN更新,不要求这些证据同时出现,符合实际交通场景中不同行为的非同时性,这个过程叫做贝叶斯更新。最终的更新结果为各结点的后验概率,因此本文以后验概率最大为选择依据。
2.4 BN决策模型
利用BN构建自动驾驶车辆行为决策模型。决策额框架如图2所示。该框架分为BN学习阶段和BN驾驶行为决策阶段。首先,根据驾驶场景信息进行BN学习,结合先验知识进行最优结构筛选。然后,将学习到的BN模型导出。最后,将传感器实时数据和人工驾驶行为预测结果输入到模型中,进行BN概率推理,获得最优驾驶动作。
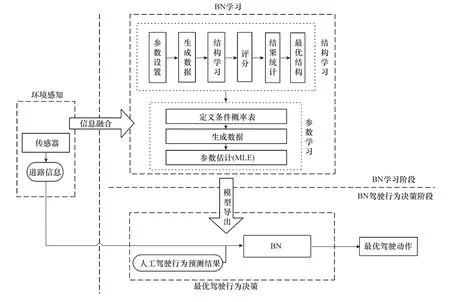
图2 自动驾驶车辆行为决策框架Fig.2 Framework of behavioral decision-making of autonomous vehicles
3 案例分析
3.1 驾驶场景分析
在复杂且充满不确定性的城市交通环境中,自动驾驶车辆的行为决策系统能否充分考虑复杂的路况以及不确定性因素,直接影响着自动驾驶车辆行驶的安全性。现阶段,自动驾驶车辆的研究已经取得了一些成果,但短时间内完全取代人工驾驶车辆仍无法实现,所以人工驾驶车辆与自动驾驶车辆共存的交通环境仍是研究的主要方向。对于人工驾驶车辆来说,驾驶员的操作尤其重要,然而真实世界中,绝大部分的交通事故都是由于人类驾驶员的错误操作引起的。2016年2月,谷歌自动驾驶车辆与加州的一辆公交车相撞,据谷歌官方说法,当时自动驾驶车辆正在山景城菲利斯大道上向北行驶,一辆在国王大道上向西行驶的公交突然闯红灯,最终导致两车相撞。事故调查结果显示,当时谷歌自动驾驶车辆试图并道时与一辆行驶的公交车相撞,汽车中的工作人员表示自己当时认为公交车会放慢车速让汽车通过,因此并未采取任何应对措施,但实际上公交车非但没减速,反而加速转弯,这就是导致事故发生的主要原因。由此次事故可见,人工驾驶车辆的行为的确会影响自动驾驶车辆的安全,在某些情况下,忽略这一因素甚至会导致严重的交通事故。另外,在城市交通中,不遵守交通规则的行为时有发生,例如行人无视红绿灯横穿马路、车辆争抢路口强行超车等行为。另外在车辆众多、识别难度大的场景,例如停车场等,自动驾驶车辆要能给出合理、高效的驾驶行为也显得尤为重要。
根据以上情形设置驾驶场景,并针对各场景进行行为决策分析以及仿真实验验证,重点针对场景一进行详细分析,其他场景的分析结果将在仿真实验中展示。
场景1还原谷歌2016年事故场景。在十字路口处,自动驾驶车辆处在同向两车道右侧由南向北行驶,初速度为6 m/s,车道中心线为虚线(即允许在安全的情况下进行换道操作),路口附近有一向西行驶的人工驾驶车辆企图进入右侧车道继续向北行驶,到达路口时速度为10 m/s,加速度为2 m/s2。
场景2在城市中一个双向四车道前方有人行道的路况下,自动驾驶车辆由西向东在最右侧车道以10 m/s的速度行驶,左前方、左后方、前方同车道各有一辆人工驾驶车辆,人行道处有行人横穿马路。
场景3存在多车辆的停车场,自动驾驶车辆欲安全稳步提速驶离停车场,加速度为3 m/s2。
3.2 决策模型构建
3.2.1 人工驾驶行为分类模型
在自动驾驶车辆行驶的过程中,将传感器获得的自动驾驶车辆周围车辆的信息(如速度,是否正常使用转向灯等),与周围车辆关系信息(如相对距离,相对速度等)以及环境信息(如交通灯,人行道等)输入训练好人工驾驶行为分类模型进行在线预测获得驾驶行为类别,并将该类别以及分类准确率作为BN行为决策模型的一个输入。
3.2.2 BN行为决策模型
BN的结点代表了交通环境中参与决策的要素,结点间的有向边表示结点间的因果关系。结点中包含结点名称、属性,结点间通过条件概率相互关联。
以场景1为例,行为决策模型中所应用的BN结点的名称及含义如表1所示。
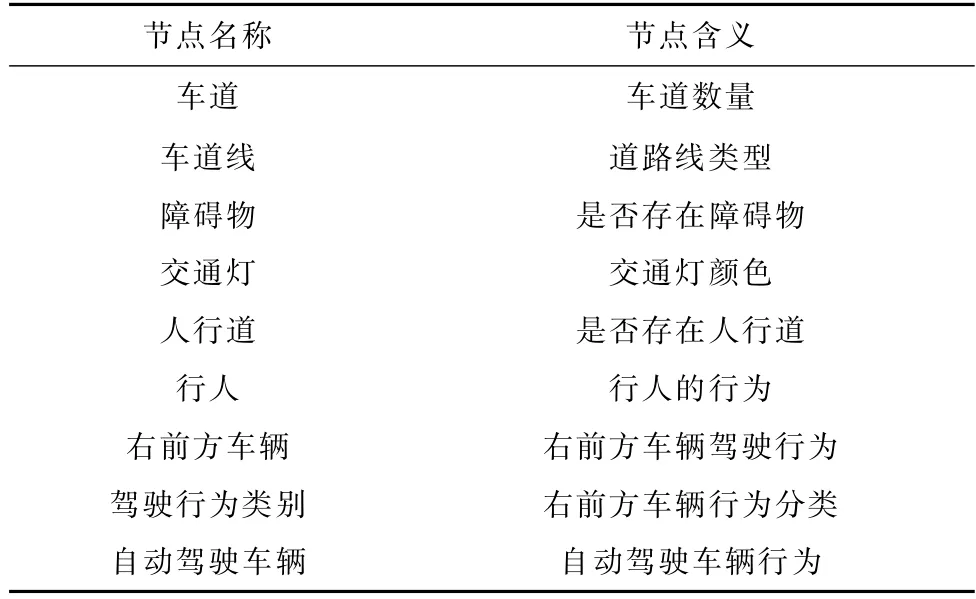
表1 BN结点及其含义Table 1 Name and meaning of BN nodes
表1中仅列举了场景1中涉及到参与决策的结点,本文利用BN工具Netica实现BN结构的创建,训练和概率推理,以最大后验概率准则为依据选择自动驾驶车辆最优驾驶行为。场景1的初始BN如图3所示。
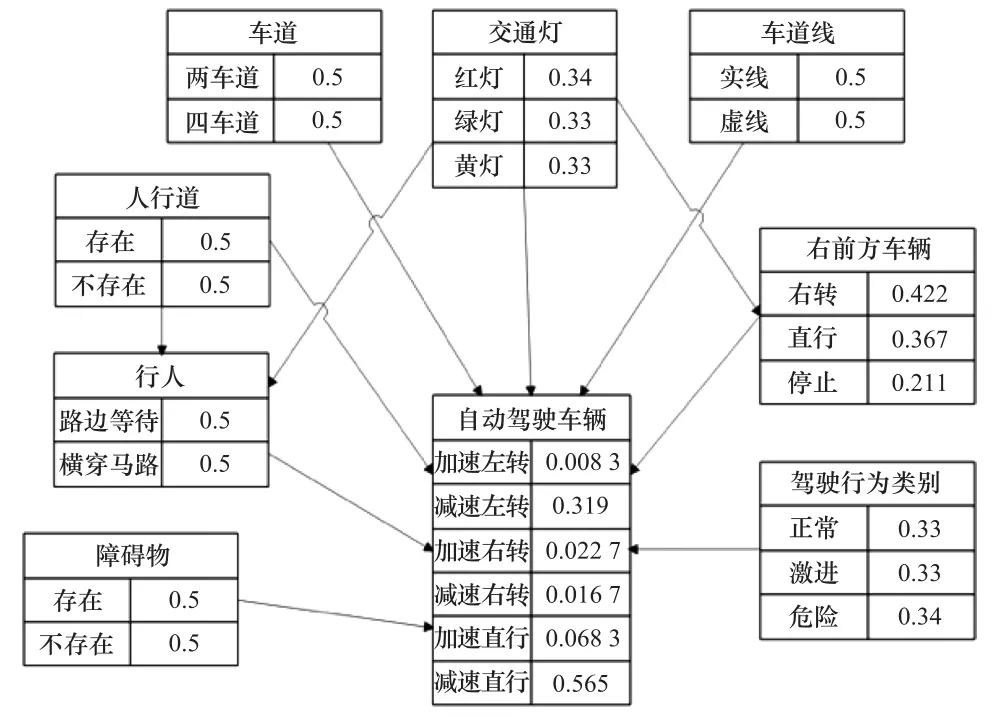
图3 场景1的初始BNFig.3 Initial BN of scenario 1
图3中描述了3类信息:
(1)道路信息(车道,车道线,交通灯,人行道,障碍物):用于自动驾驶车辆识别周围交通道路情况,以确定可能采取的驾驶行为,如车道线为虚线,则表示允许换道操作。
(2)其他交通参与者信息(行人,右前方车辆,驾驶行为类别):这类信息是自动驾驶车辆需要及时应对的交通环境中的不确定性因素,要想做出安全可靠的驾驶行为,需要对这些交通参与者的行为做出及时的应对,如行人横穿马路,车辆需减速避让。
(3)自动驾驶车辆信息(自动驾驶车辆):根据道路信息确定的自动驾驶车辆可能的驾驶行为。
3.3 驾驶行为决策
驾驶行为决策过程即BN概率推理过程,在训练好的BN基础上,当“证据”被观测到(即传感器获取了当前道路信息和其他交通参与者信息)时,将BN中对应结点的概率值依次更新,进而依次更新其他各结点的后验概率,得到场景1更新后的BN如图4所示。
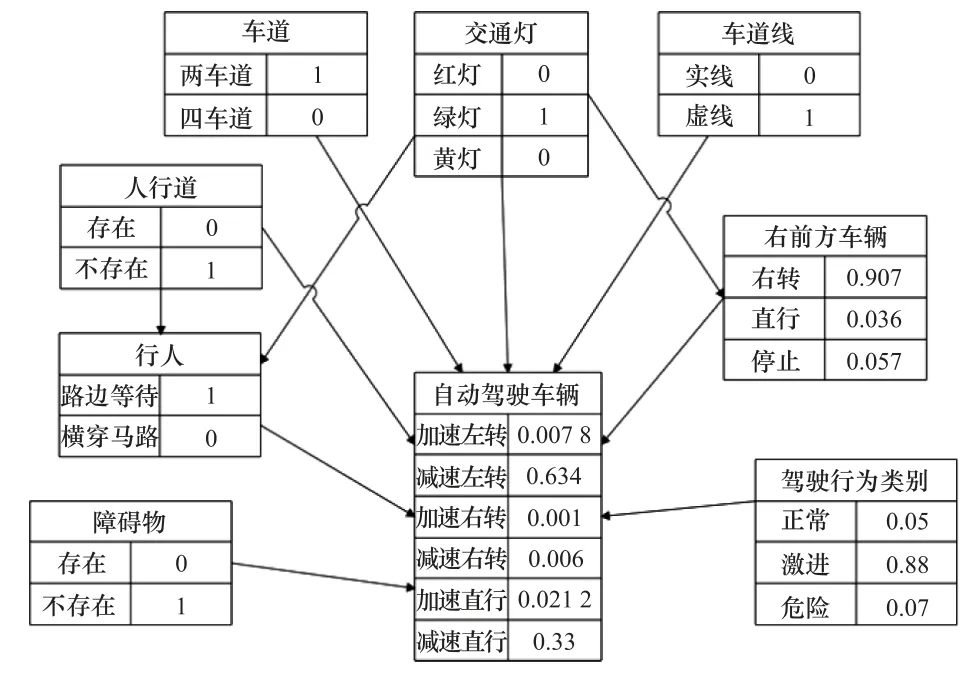
图4 场景1更新后的BNFig.4 Updated BN of scenario 1
图4中除驾驶行为类别和自动驾驶车辆结点外,其余结点的概率值均通过车辆传感器实时获取,其中驾驶行为类别结点的概率值由人工驾驶行为分类模型获得,根据场景1仿真实验过程中监测数据,经人工驾驶行为分类模型预测的结果为aggressive,模型分类精度为88%,以标签-概率对(aggressive,0.88)作为BN中驾驶行为类别结点的“证据”。BN行为决策的结果在自动驾驶车辆结点中显示,根据图4中BN概率推理的结果,基于最大后验概率准则,自动驾驶车辆行为决策的结果为减速左转,即减速向左做出避让行为。
3.4 对比实验
谷歌自动驾驶车辆事故的主要原因是由于自动驾驶车辆错误预估了公交车的行为,本文通过构造场景1情况下无人工驾驶行为分类模型的自动驾驶车辆行为决策模型(以下称为单一决策模型)来验证本文模型。
场景1中单一决策模型的初始BN如图5所示。
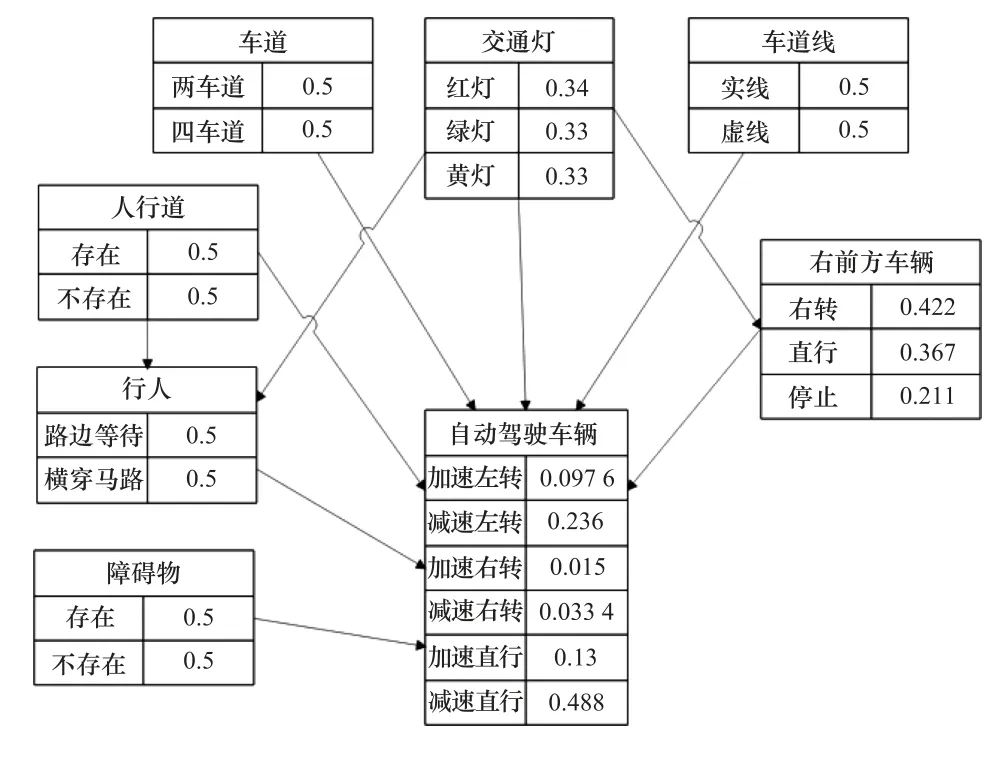
图5 单一决策模型的BNFig.5 BN of single decision-making model
依次更新各结点后验概率,得到更新后单一决策模型BN如图6所示。
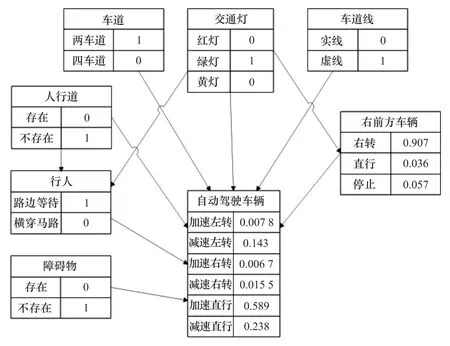
图6 单一决策模型的更新后BNFig.6 Updated BN of single decision-making model
根据最大后验概率准则,单一决策模型的决策结果为加速直行,与自动驾驶车辆行为决策模型的结果不同,将在第4节仿真实验中验证行为决策结果的正确性。
4 仿真实验
4.1 仿真工具介绍
PreScan是一款西门子公司旗下的汽车驾驶仿真软件,支持全球定位系统(global positioning system,GPS)、雷达等多种功能的开发应用。该工具主要功能[33]分为4部分:驾驶场景建模、车载传感器配置、车辆控制系统搭建和运行结果可视化。PreScan能够便捷地搭建交通场景,支持与Matlab/Simulink、CarSim等软件进行联合仿真,场景模型搭建操作方便。同时,支持真实地图导入,能够较好地吻合真实场景,适用于自动驾驶、辅助驾驶等系统的开发与验证。智能驾驶系统在PreScan中的仿真实现过程如图7所示。
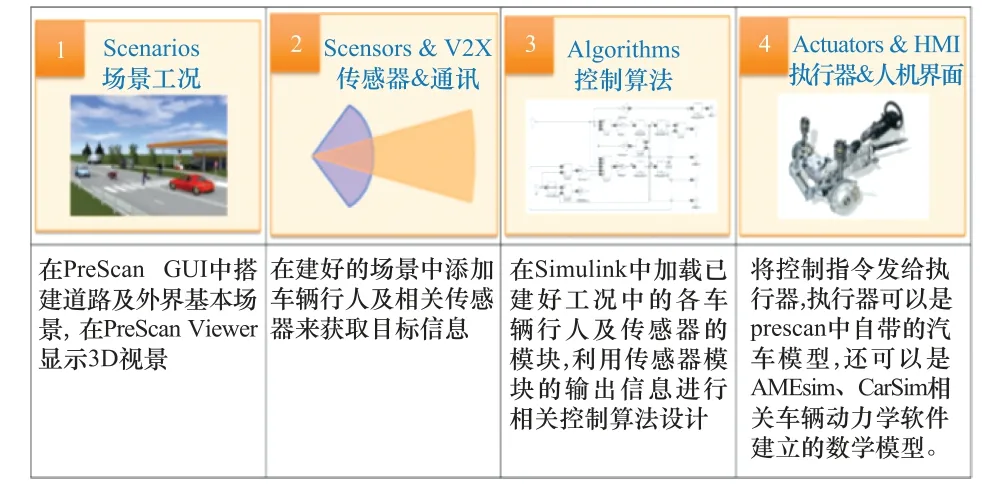
图7 PreScan仿真过程Fig.7 Simulation process of PreScan
4.2 场景与控制算法搭建
PreScan支持简易界面操作和编程操作两种方式进行场景搭建,并且可以通过拖拽方式添加车辆、行人等交通参与者,同时提供多种传感器设备可以实时收集车辆运行数据和环境数据。根据驾驶场景1建模,其三维建模结果如图8所示,其中黑色车辆代表自动驾驶车辆,白色车辆代表人工驾驶车辆。

图8 场景1的三维模型Fig.8 Three dimensional model of scenario 1
驾驶场景2的三维模型建模结果如图9所示。其中,黑色车辆代表自动驾驶车辆,其他颜色车辆代表人工驾驶车辆。
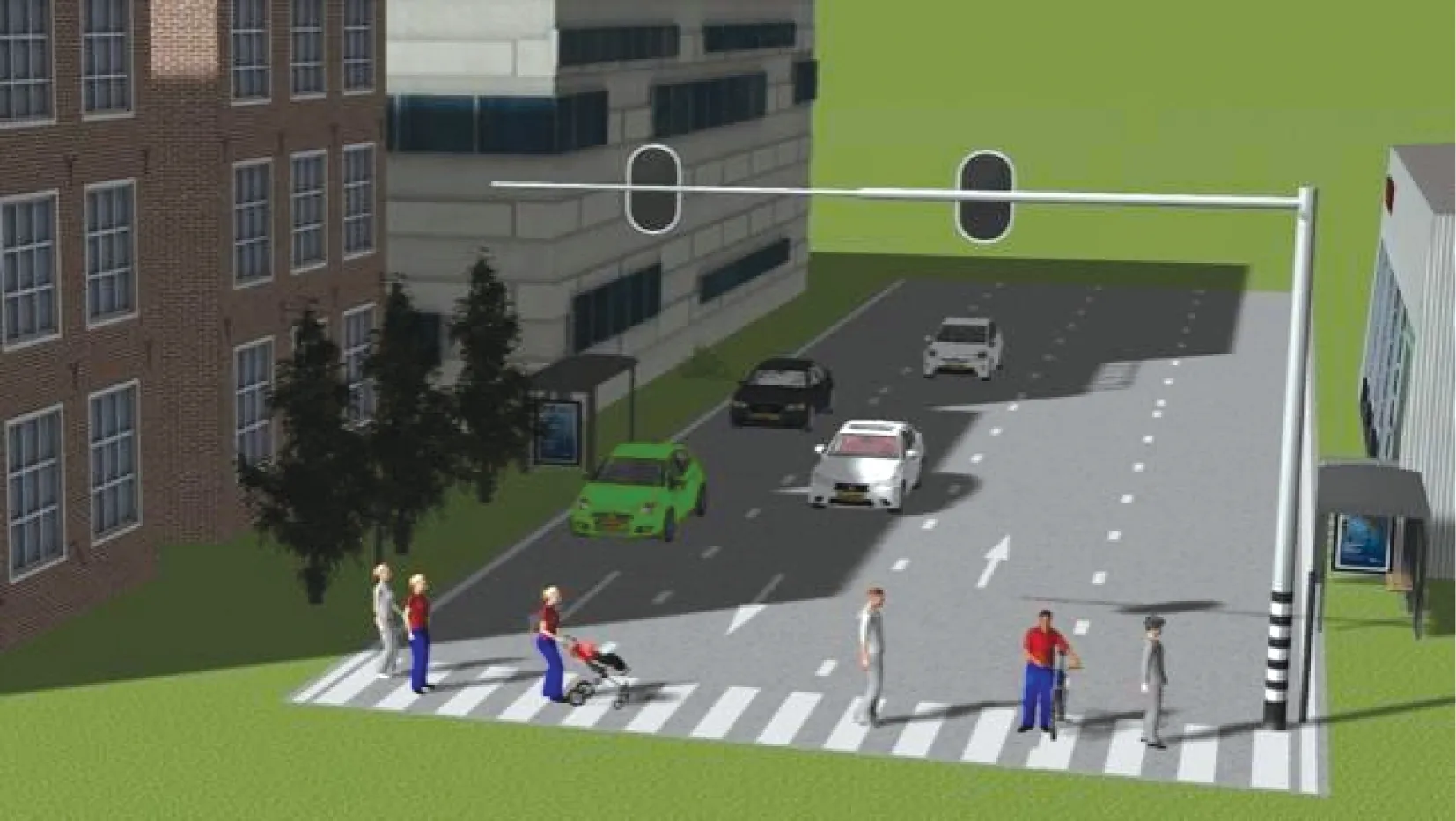
图9 场景2的三维模型Fig.9 Three dimensional model of scenario 2
驾驶场景3的三维模型建模结果如图10所示。其中,位于道路中间的黑色车辆代表自动驾驶车辆,其他车辆表示在停车位中的人工驾驶车辆。

图10 场景3的三维模型Fig.12 Three dimensional model of scenario 3
设置好驾驶场景和交通参与者后,通过PreScan中提供的Simulink模块接口,设置车辆的动力学模型和行为决策控制算法,从而完成对车辆的运动控制。以场景1为例,车辆的动力学模型如图11所示。
图11 场景1中的车辆动力学模型Fig.11 Dynamic model of autonomous vehicle in scenario 1
在simulink中搭建行为决策算法,其结果如图12所示。
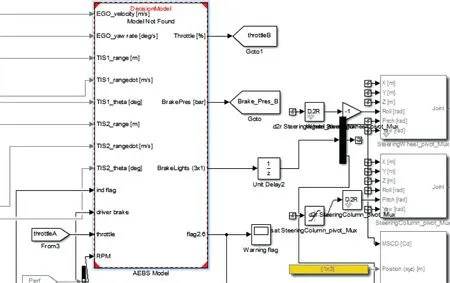
图12 Simulink中搭建的行为决策算法Fig.12 Algorithm of behavioral decision-making in Simulink
4.3 实验分析
将场景1中车辆行驶数据导出,如图13所示,其中图13(a)为速度随时间变化情况,图13(b)为加速度随时间变化情况。
图13(a)的第3 s时右前方车辆开始加速准备通过路口,这一信息被自动驾驶车辆传感器获取,自动驾驶车辆速度降低,5 s后速度逐渐恢复至6 m/s,图13(b)的加速度变化情况也符合这一情况。通过PreScan中的三维Viewer模块可视化仿真过程,路口处车辆行为如图14所示。
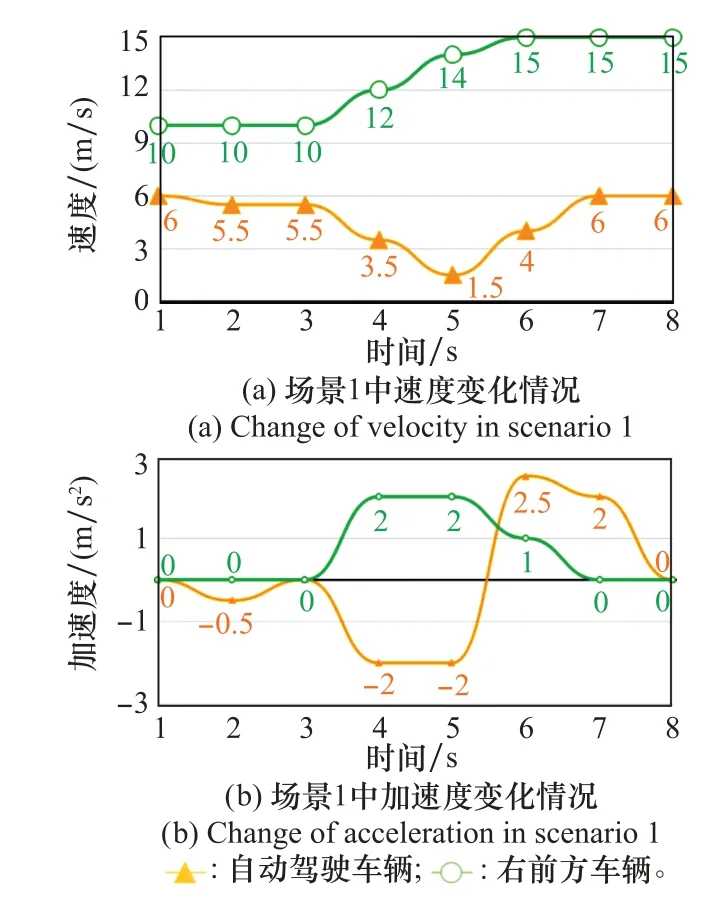
图13 场景1中车辆行驶数据Fig.13 Data of driving vehicles in scenario 1

图14 路口处车辆行为Fig.14 Behavior of vehicle in intersection
由以上结果可知,自动驾驶车辆做出了减速避让的驾驶行为,成功地避免了类似谷歌自动驾驶车辆事故的发生。然而单一决策模型的决策结果为减速直行,将会导致与人工驾驶车辆发生碰撞。
将场景2中的车辆行驶数据导出,如图15所示。

图15 场景2中车辆行驶数据Fig.15 Data of driving vehicles in scenario 2
由图15(a)和图15(b)可知,自动驾驶车辆在行驶临近人行道时,行人横穿马路引得周围车辆减速,自动驾驶车辆的行为决策结果为逐渐减速避让。
场景3中自动驾驶车辆行驶路线如图16所示。
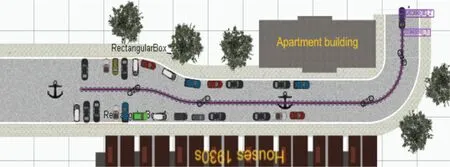
图16 场景3中自动驾驶车辆行驶路线Fig.16 Route of autonomous vehicle in scenario 3
由行驶路线可知,自动驾驶车辆成功驶离车辆众多的停车场。
5 结束语
本文针对自动驾驶车辆行为决策研究中缺乏人工驾驶车辆行为相关知识的获取与表达、对交通场景中不确定性因素考虑不充分等问题进行了深入研究,提出了以人工驾驶行为分类为基础,利用BN建模驾驶场景并进行最优驾驶动作推理的自动驾驶车辆行为决策方法。
本文的研究内容如下:
(1)基于决策树算法建立人工驾驶车辆行为分类模型,解决了影响自动驾驶车辆行为决策的因素相关知识的获取与表达方面的问题,设置对比实验验证了该模型的必要性,提高了行为决策模型在应对交通环境中交通参与者行为复杂难以预测方面的鲁棒性。
(2)基于BN算法建立自动驾驶车辆行为决策模型,解决了交通场景中不确定性因素考虑不充分的问题。利用BN建模驾驶场景并进行最优驾驶动作推理,提高了自动驾驶车辆在城市交通环境中行为决策的安全性。
(3)基于自动驾驶仿真工具PreScan设置驾驶场景仿真环境,并设置车辆控制算法等要素,以仿真方式验证了本文提出的自动驾驶车辆行为决策方法的可靠性。
本文研究中仍存在不足之处,需要未来继续深入研究:
(1)本文中人工驾驶行为分类模型的构建基于仿真实验获得的数据集,未来应在更丰富的数据集上进行训练。对于人工驾驶车辆行为分类所依赖的属性以及类别的划分仍需根据实际情况进行调整,未来可根据更多的领域经验进行改进。
(2)本文中只考虑了行为决策的安全性,而实际生活中还有更多需要考虑的因素,如舒适性、效率等。未来可在决策模型中增加效用结点以扩展驾驶动作的选择标准,使决策模型给出更安全,舒适的驾驶动作。
(3)本文行为决策的目标行为设计粒度较粗,未来可考虑基于横纵向解耦的方法对决策行为进一步细化,以达到更精准的行为决策结果。
