基于差分隐私的深度伪造指纹检测模型版权保护算法
2022-10-09袁程胜郭强付章杰
袁程胜,郭强,付章杰
(1.南京信息工程大学计算机学院、软件学院、网络空间安全学院,江苏 南京 210044;2.南京信息工程大学数字取证教育部工程研究中心,江苏 南京 210044)
0 引言
随着大数据技术和数字经济的蓬勃发展,互联网每天都会产生海量的数据,部分数据不仅关系到个人隐私权益,还会涉及国家安全和社会公共利益。为了避免敏感隐私数据外泄,对其进行安全访问至关重要。生物识别技术(借用人体生理或行为特性)作为一种新颖的身份识别模式,逐渐替代传统的密码验证。在现有的生物特征中,指纹因具有唯一性、稳定性和长久不变性的特性,应用更普及。截至2021 年,指纹识别占据全球生物识别的大部分市场份额[1]。但是,该技术存在严重的安全隐患,借助硅胶、树脂、明胶等材料伪造的指纹能够成功欺骗指纹识别系统。因此,伪造指纹[2]检测技术被提出。
近些年,随着机器学习尤其是深度学习的迅速发展,人工智能技术被广泛应用在无人驾驶[3-4]、计算机视觉[5-6]、自然语言处理[7-8]等领域,基于深度学习的深度伪造指纹检测方法[9]也相继被提出。但是,训练一个鉴别指纹真假的模型除依赖超强的算力和专业的领域知识外,还需要海量优质指纹数据的加持,并且一旦模型滥用势必会导致用户隐私的泄露和知识产权侵犯风险,对训练好的深度伪造指纹检测模型进行版权保护迫在眉睫。
深度伪造指纹检测(后文简称为深伪检测)模型在确保指纹识别系统完整和隐私数据安全访问方面的作用是无法替代的[10-12],尤其是对具有较高隐私的深伪检测模型的保护极为重要。现有的知识产权保护对象更多是新媒体内容,鲜有对深伪检测模型版权保护的研究,并且无法直接将现有方法用于深伪检测模型的版权保护任务中。文献[13]提出一种构造零比特水印的版权保护方法,当模型所有者对知识产权和经济利益产生纠纷时,可调用远程应用程序接口(API,application programming interface)来获得模型的访问权限,并通过远程操作从神经网络模型中提取嵌入的水印实现版权验证,通过对抗训练操作生成触发集以调整分类决策边界,并依据触发集输出的特定标签对模型版权归属进行验证。该方法在MNIST 数据集上表现出较好的性能,而对指纹数据集保护的效果如何有待考究。文献[14]提出一种抗伪造攻击的神经网络水印协议,通过引入单向哈希函数,确保所有权的触发样本形成单向链,且触发样本的标签也被赋值,其认为攻击者无法拥有训练权限,因此该协议能够抵挡伪造攻击。但是现实中,攻击者通过非法手段能够获得模型的训练权限,该方法将不适用。文献[15]提出一种深度模型的分发机制,能够为用户提供分等级的服务,但是当用户与攻击者发动合谋攻击后,该模型将会被攻击者窃取和非法使用。
针对神经网络模型知识产权侵权问题,本文提出了一种基于差分隐私的深度伪造指纹检测模型版权保护算法。首先,通过构建的触发集微调模型的分类决策边界以建立后门,实现模型版权的被动验证。然后,为了最小化原始任务在非触发集中的误差,在深伪检测模型中设计一个噪声层模块,充分利用差分隐私算法的期望稳定性进行分类决策,让模型在训练时降低对噪声的敏感度。当模型授权给用户后,攻击者与用户发动合谋攻击,以非法获得使用权,此时仅需通过给模型嵌入的后门来验证模型版权。即使攻击者伪造一批与触发集样本同分布的数据来混淆模型版权,所有者依然可通过给触发集加盖时间戳的方式,抵抗混淆版权的恶意攻击。本文的主要贡献如下。
1) 提出一种主动保护和被动验证相结合的深度伪造指纹检测模型版权保护框架。主动保护通过设计一组访问权限,利用概率选择策略将冻结的关键性神经元进行不同程度的解冻,以实现对该模型的授权分发和用户的身份管理。即使攻击者与用户发动合谋攻击,所有者依然可以通过后门映射关系来进行版权的被动验证。
2) 改进了传统的决策边界微调算法。通过给深度伪造指纹检测模型引入随机性,借助差分隐私算法的期望稳定性进行分类决策,以降低模型对噪声的敏感度,从而让模型的分类决策边界更加稳定。确保在后门嵌入时,决策边界不会发生大幅变化而影响原始任务。
3) 在3 个公开的指纹数据集上进行了性能测试,实验结果表明,主动保护并不会影响后门验证,对于不同模型任务后门依然有效,嵌入的后门对模型修改同样具有稳健性。此外,所提算法能够抵挡攻击者发起的合谋攻击,也能够抵挡模型修改带来的微调、压缩等常见攻击。
1 模型版权保护算法分类
通过对现有模型版权算法进行归纳发现[16],主要分为三类,即白盒水印算法、黑盒水印算法和无盒水印算法。白盒水印算法实现流程如图1 所示,利用白盒水印进行版权验证时,所有者能够访问模型的结构和参数,通过修改神经网络模型的权值实现水印的嵌入和提取。黑盒水印算法实现流程如图2所示,在无法获悉神经网络模型的结构和参数时,通过生成的触发集让模型输出预期的分类结果,以实现水印的提取和对比。无盒水印算法实现流程如图3所示,利用生成式模型让输出的图像中含有水印。在版权验证时,利用提取网络完成水印的提取和版权归属验证。

图1 白盒水印算法实现流程

图2 黑盒水印算法实现流程
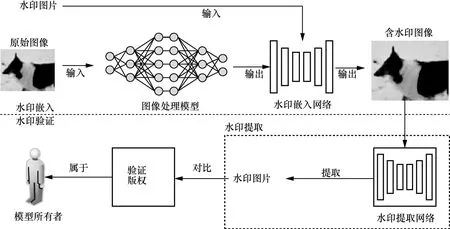
图3 无盒水印算法实现流程
1.1 白盒水印算法
Uchida 等[11]在2017 年首次提出模型水印的概念。在训练过程中,利用构造的投影矩阵将水印植入模型权重中,通过提取网络实现水印信息的提取和版权验证。具体实现过程如下,首先,随机选择某一卷积层进行平均操作,并将其转化成一维向量;然后,将投影矩阵与一维向量的乘积输入激活函数中,构造一个二值比特流;最后,将水印转化成二进制向量,利用交叉熵损失函数最小化水印信息和激活后的二值比特流,以实现模型水印信息的植入。水印验证是将投影矩阵与权重执行乘法操作,利用阶跃函数进行水印提取,通过与嵌入的二值水印信息进行对比实现模型版权的归属确权。若权重变化幅度较大,便能检测到水印的存在。因此,Kuribayashi 等[17]提出了一种基于全连接层权重的量化水印嵌入方法,该方法通过在训练过程改变模型参数,量化水印对模型的影响,从而确保植入的水印引起的参数变化很小。
Rouhani 等[18]提出一种通用水印版权保护方案,将其命名为DeepSigns。DeepSigns 能够生成一个受保护的神经网络模型,模型所有者设计一个水印签名,将其植入不同激活图的概率密度函数中,并使用密钥记录嵌入位置。当版权验证时,首先通过密钥获取水印的位置信息;然后提取水印签名;最后比较所提取水印与真实签名之间的误差,若小于阈值,则提取成功。Feng 等[19]提出一种带有补偿机制的水印嵌入方案,为了让嵌入的水印位置更隐蔽,抵抗覆写攻击,选取随机权重;然后将权重进行正交变换,并通过二值化操作向系数中嵌入水印,再通过逆正交变换得到新的含水印的权重;最后使用其他权重作为补偿来微调模型,以消除二值化对性能的影响。
Fan 等[20]指出,现有的水印算法易受到伪造攻击。为此,他们提出一种基于护照的水印策略,即让预先训练好的模型在正确的护照下保持任务性能。当面对伪造或修改的护照,原始任务性能会大幅下降。该方法在不同卷积层后添加了一个护照层,类似于归一化层,区别在于护照层的权重和偏置由特殊的护照决定,而归一化层的权重和偏置是为了保证中间层的变化幅度不能过大而抵消部分归一化操作对模型的影响。因为模型训练过程与护照紧密耦合在一起,所以模型的性能受到护照的控制。若攻击者通过逆向工程伪造一个新的护照来盗取模型,则必须从头训练模型。因此,该方法能够有效抵挡混淆攻击。文献[20]仅适用于一些特殊的归一化层,为了让归一化层都植入水印,Zhang 等[21]在原始任务中引入了一个护照感知分支,通过设计一个秘密护照让护照感知分支与原始模型联合训练。仅当验证模型版权的归属时才提供护照和护照感知分支,而其他时候只将原始模型提供给用户使用。在验证过程中,正确的护照能使模型正常工作,伪造护照则不能。
针对模型版权归属确权问题,目前的白盒水印算法虽然能够很好地解决,但是模型内部结构信息需要公开,攻击者能够轻易地训练一个模型。因此,模型所有者更期望将持有的模型封装成黑盒,通过提供API 完成指定任务。
1.2 黑盒水印算法
Zhang 等[22]提出一种新颖的模型版权认证方法,即黑盒水印算法,并分别给出3 种黑盒水印算法:第一种算法将特定的文本信息嵌入图像中作为水印;第二种算法将无意义的噪声嵌入图像作为水印;第三种算法将不相关图像分配错误标签后作为水印。上述方法均能通过植入后门映射关系实现模型的版权归属认证。Adi 等[23]通过后门植入法研究版权的归属问题。首先,从原始数据中选定部分样本作为触发集,并进行标记;然后,通过训练让模型拟合触发样本的特性。在版权验证时,所有者将触发样本输入API 中,通过观察预测结果是否为预设的标签。为了降低误报率,Guo 等[24-25]提出一种基于进化算法的水印生成和黑盒水印优化算法,将版权所有者的签名植入数据集中,使用含签名信息的数据集来训练一个神经网络模型。当嵌入签名的数据被输入时,预设的临时模式将会运行,以此验证模型的版权。Jia 等[26]发现现有的水印嵌入方法大多与主任务无关,可通过模型微调和压缩来盗取版权,为此提出纠缠水印的概念,即将水印嵌入和原始任务紧密耦合。此外,在后门植入时,触发集输出错误的标签会导致决策边界发生变化,影响原始任务的性能。Zhong 等[27]设计一种全新的黑盒水印算法,在后门嵌入过程中,决策边界并不会发生变化。Quan 等[28]设计一种用于保护图像处理模型的黑盒触发式水印,通过微调操作使模型改变特定域内的预测结果,为了让微调后的模型输出图像和事先预定义的图像接近,将触发图像和初始验证图像一并输入模型中训练,用触发图像的预测结果来更新验证图像。在验证水印时,当所有者把触发图像输入模型后,如果输出结果与验证图像相同则验证成功。Ong 等[29]提出一种用于保护生成对抗网络的水印方法,核心是当输入一个触发图像时,模型会生成一个包含水印的图像来验证版权。
由于深度模型易遭受数据中毒和后门攻击的威胁,确保神经网络模型在部署后的完整性对黑盒模型极其重要。Zhu 等[30]提出一种基于黑盒的脆弱水印方法来检测恶意微调,水印处理分为以下3 个步骤:用户首先用一个特定的密钥来构造一组触发集;然后,用交替训练的方式对训练集和触发集进行分类;最后,对训练好的DNN 模型进行微调。
黑盒水印算法是目前主流的模型版权保护方法。所有者仅需通过API 访问远程模型便能完成版权验证,不需要像白盒水印算法那样将内部结构公开给第三方。虽然黑盒水印算法提升了模型的安全,但是攻击者依然可通过伪造触发集的方式混淆版权。
1.3 无盒水印算法
无盒水印算法是一种新颖的、不需要人模交互、不需要获悉模型细节和不需要构建特定触发集的生成式版权保护方法,核心操作是在模型训练损失函数中引入一个水印损失项,使输出样本中包含水印信息,最终通过水印提取和比对实现模型版权的归属确权。Zhang 等[31]通过在模型后引入一个与原始任务无关的水印模块,提出一种端到端的水印信息嵌入算法。具体地,在原始任务后设计一个水印嵌入模块,通过迭代优化将水印信息嵌入图像中。为了从水印图像中提取水印,便于后续水印比对和版权归属认证,同时训练一个由密钥控制的水印提取子网。当攻击者利用该框架训练的模型进行代理模型攻击时,表征归属的水印信息将被嵌入该代理模型中。此外,还通过对抗训练提升模型的稳健性,以提高水印防御代理模型攻击的性能。Wu 等[32]提出一种全新数字水印框架,设计一个水印损失组合损失函数来训练模型,使输出的图像中包含一个定制化的水印信息,后续神经网络模型版权需要归属确权时,只要通过检测输出图像中的水印,便能够判断图像是否来自该神经网络模型。实验结果显示,该方法在面对各种图像处理操作时,如图像着色、超分、编辑及语义分割等,均表现出良好的稳健性。
无盒水印的版权验证算法是通过在输出图像中植入定制化数字水印信息来保护模型版权的,为深伪检测模型的版权保护研究提供了新思路。
2 本文算法
2.1 融合主动保护和被动验证的版权保护框架
本文提出的融合主动保护和被动验证的深伪检测模型版权保护框架如图4 所示。其包含以下3 个功能:第一,可以防止未授权用户使用深伪检测模型,仅授权用户能使用该模型,而未授权者将会得到一个与任务无关的输出;第二,能够对深伪检测模型进行分级保护,越忠诚的用户获得的访问等级越高;第三,当攻击者策反授权用户发起合谋攻击时,模型所有者可通过后门映射关系对该模型进行版权归属确权。

图4 融合主动保护和被动验证的深伪检测模型版权保护框架
首先,模型所有者将预训练好的深伪检测模型使用后门嵌入模块来微调决策边界,让模型获得后门映射关系。然后,通过概率选择模块筛选模型中的关键性神经元,以确保选定的神经元不影响后门触发。接着,冻结模块将筛选出的关键性神经元进行冻结,以降低模型的可用性,让未授权用户无法使用该任务模型。最后,分发模块对冻结模块中的神经元授予不同等级,依据授权等级从冻结模块中解冻不同数量的神经元,以执行相应的功能,该操作能够确保最忠诚的用户解冻全部的神经元。在上述操作过程中,模型所有者仅需执行一次后门嵌入模块、概率选择模块和冻结模块的调用操作,当用户需要使用模型时可以多次调用分发模块。被动验证是当用户被攻击者策反后,导致模型被非法使用时所采取的事后验证操作。综上,本文所提的版权保护框架能够为深度伪造指纹检测模型提供一个系统完整和版权归属确权的解决方案。
2.2 决策边界的构建
本文使用FGSM(fast gradient sign method)[33]生成对抗性指纹集,并在原始任务模型上进行白盒测试,当模型输出标签发生错误时,则定义为成功对手。由于FGSM 通过逐批添加扰动的方式来生成对抗性指纹,因此那些测试错误的对抗指纹被视为失败对手。选择失败对手作为触发集的目的是限制决策边界[13],让成功对手返回原先正确分类的类别时变化更少。此外,失败对手还具有表征模型边界形状的作用,从而提升模型的稳健性。决策边界微调的前后对比如图5 所示,标签T 和标签F分别表示类别为True 和Fake 的成功对手,而分别表示类别为True 和Fake 的失败对手。
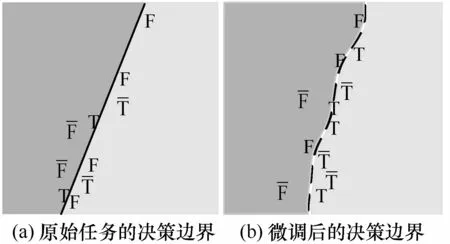
图5 决策边界微调的前后对比
为了实现深伪检测模型的版权保护,使用对抗性指纹的原始标签作为后门映射关系进行被动验证。具体地,利用决策边界微调算法让深度伪造指纹检测模型的决策边界发生轻微改变,以实现模型的水印植入。由于触发集是由对抗性指纹构成的集合,当进行决策边界微调时,深伪检测模型能够学习到触发集图像中对抗指纹的特殊特征,使原始任务输出错误结果。为了解决上述问题,受差分隐私和对抗样本防御具有一定联系[34]的启发,让深伪检测模型的决策边界更加稳定,不易受触发集的对抗性扰动影响,本文通过在原始任务中添加噪声层,从而在前向传播过程中引入随机性,使模型能够利用差分隐私算法的期望稳定性进行最终的决策,并能够有效降低深伪检测模型对噪声的敏感性。此外,还能够确保在用触发集进行后门嵌入的过程中,决策边界不会因为扰动对模型的影响而大幅变化。
2.3 噪声层的构建
差分隐私[35]是避免个人数据隐私泄露的一种防御方法,通过给数据添加噪声以引入随机性,使在数据集上的任何增加或删除操作记录都能被隐藏,用户无法通过查询的结果反推出隐私信息。设D为随机算法,输入域为X,输出域为R,任意2 个相邻数据集x,x′∈X,输出集合满足S⊆R。若x和x′在算法D下满足式(1),则称算法D满足(ε,)δ-差分隐私。

其中,ε和δ均为控制差分隐私保护强度的超参数,ε为隐私预算,δ为隐私被泄露的概率,P(·) 为算法D的输出概率。
度量标准ρ用来表示敏感性,以记录2 个查询之间的不同数目。在标准的差分隐私中,通常用汉明距离作为度量标准,以使数据库中单一数据的改变不会大幅修改输出的分布。而差分隐私也适用于对抗样本的范数度量。本文将深伪检测模型的输入图像构成的样本视为数据库,将图像中的像素视为记录,以建立起差分隐私与深度伪造指纹检测模型之间的联系。具体地,本文触发集的构建是使用FGSM 来生成对抗性指纹的,通过微调建立后门映射,利用映射关系来验证版权归属。
本文利用了差分隐私的2 个属性:1) 后处理性,即差分隐私算法之后模型的输出结果仍具有差分隐私的特性;2) 期望稳定性,即差分隐私算法之后模型的输出期望对输入的扰动变化不敏感。上述属性能够使差分隐私与模型的稳健性建立明确的联系。通过差分隐私的期望稳定性来进行决策,以降低分类决策边界的敏感性。在执行后门嵌入时,微小扰动对原始任务性能并不会产生太大影响。差分隐私的期望稳定性为

其中,α表示添加的扰动,D(x) 表示随机算法的输出,且D(x) ∈[ 0,1]。为了验证差分隐私的属性2),对其进行如下推理。连续性随机变量的输出期望为
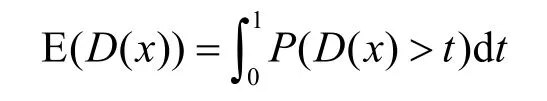
将式(1)两边同时积分得
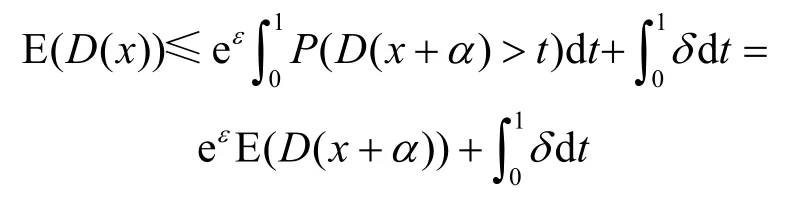
其中,δ是常数,可得

因此,E(D(x)) ≤eεE(D(x+α))+δ得证。
深度伪造指纹检测模型的稳健性是指模型输入的轻微改变并不会影响原始任务的性能,在基于标签输出概率的深度伪造指纹检测模型中,稳健性应该满足

其中,y为模型分类结果,f和n为标签类别。
本文将检测模型SoftMax 层的决策转化为随机的D(x),利用噪声的输出期望E(D(x)) 作为决策概率,以挑选最大的概率标签,如式(4)所示。
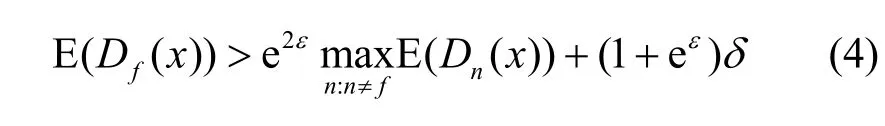
式(4)为稳健性条件,若满足条件,则输出期望E(D(x)) 对微小扰动是稳健的。证明如下。
证明根据式(2)可得
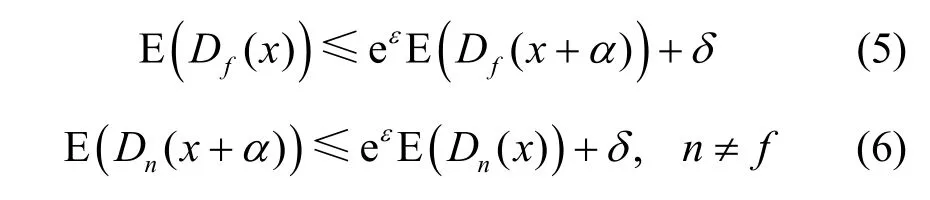
式(5)给出了 E(Dn(x+α))的下界,式(6)给出了maxn≠fE(D f(x+α))的上界。式(4)中标签n的期望值下限严格高于其他标签的期望值上限。满足式(3)的稳健性条件,从而建立差分隐私与模型稳健性联系,实现模型输出的稳健性。当满足式(4)时,可得稳健性为
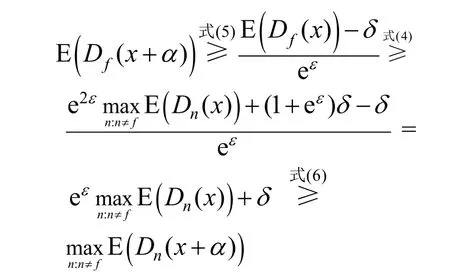
则深度伪造指纹检测模型稳健性结论为
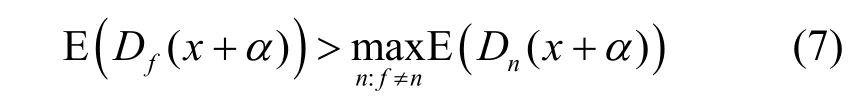
深度伪造指纹检测模型的实现流程如图6 所示。在进行模型训练时,通过添加噪声层以引入高斯噪声,使深度伪造指纹检测模型的分类决策获得随机性。添加噪声后的训练相对复杂,无法直接计算该输出的期望。因此,本文采用蒙特卡罗估计来近似原有的期望值。具体地,在原始任务中添加决策层,反复调用预测来计算噪声对SoftMax 层输出结果并取平均操作得到期望的估计值。利用差分隐私算法的期望稳定性进行最终决策以降低该模型对噪声的敏感度。如式(7)所示,对于添加噪声后的指纹图像,该模型的输出期望依然比较稳定。

图6 深度伪造指纹检测模型的实现流程
2.4 主动保护框架
对于训练好的深度伪造指纹检测模型,训练的参数中一部分神经元对任务的决策至关重要,若剔除则会影响任务的输出,被视为关键性神经元;而有些神经元有无与否对任务并无影响,被视为普通神经元。本文提出的主动保护框架通过冻结模型中关键性神经元,以禁止未授权用户的使用。由于大部分神经元位于卷积层,仅冻结卷积层中的关键性神经元。首先,通过概率选择策略筛选出关键性神经元以便于后续的冻结操作。概率选择是通过观察丢弃某个神经元后,对模型性能的变化程度,若明显,则相应的神经元极为重要。另外,输入样本不同,对神经元产生的刺激也不同。假设输入样本为x n(n=1,…,N),训练的参数中必然存在一些关键性神经元构成集合剔除则会使性能陡然下降。由于会随着xn的变化而变化。因此,每输入一批样本,模型就会产生一批不同的集合为了消除不同输入产生的随机性,当所有样本输入后,统计每个神经元入选集合的次数,并用pθ表示被选定的概率。若神经元总在中,则为关键性神经元,并赋值1。本文将概率选择操作转化为式(8)所示的优化问题,通过优化操作筛选出关键性神经元,在不影响后门验证的同时,还能确保选取的关键性神经元尽可能少。

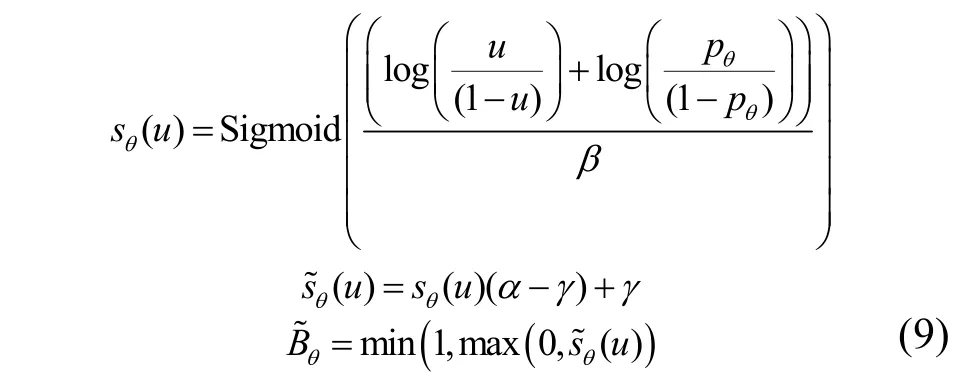
其中,β用来衡量与Bθ的逼近程度,u符合均匀分布U(01),,α>0 和γ>0 为的可调整参数。由于Bθ在式(7)中已被放宽,且中零元素相对较少。采用文献[37]中的累加分布函数,即


通过式(9)和式(11)将式(8)放宽,并将式(8)的优化问题转化为
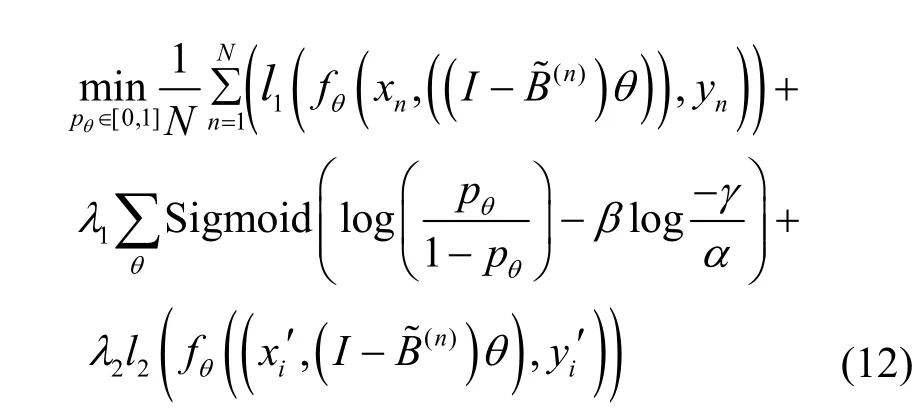
利用式(12)对模型进行优化,以完成关键性神经元的筛选和保障后门的验证;利用概率选择操作将关键性神经元进行冻结,并限制未授权用户的使用;将冻结的神经元划分不同子集,让每个子集均包含不同数量的神经元,图4 中的分发模块通过选择不同的子集来控制深度伪造指纹检测模型的性能,而冻结模块和解冻模块分别用来进行关键性神经元的冻结和解冻操作。
2.5 时间戳
任意数据经过哈希运算[38]后均生成一个定长的输出。该运算是单向的,即无法依据哈希值反推出原始数据。因此,使用时间戳对电子数据产生的时间进行签名认证,以证明其在某个伪造签名之前就已存在。时间戳的生成操作如下。
1) 使用时间戳服务中心(TSSC,time stamp service center)提供的时间戳软件,将电子数据加盖时间戳并输出哈希值A。
2) 将生成的哈希值A发送给TSSC,由TSSC记录下生成的时间点,并将哈希值A与时间点拼接组成的新数据输入哈希函数,构建新的哈希值B。
3) TSSC 利用私钥将哈希值B进行加密操作以防止B的泄露,将加密后的哈希值与时间点绑定封装来生成时间戳,并返还给申请者保管。
时间戳的验证步骤如下。
1) 将原有电子数据作为输入,使用时间戳软件求得哈希值A。
2) 把哈希值A与时间点作为输入,得到哈希值B。
3) 利用TSSC 提供的公钥将使用者保管的加密内容进行解密,得到哈希值B′。
4) 通过对比哈希值B和哈希值B′,来判断原有数据的时间点是否一致。
3 具体实施
3.1 数据集介绍
为了验证本文所提算法的性能,使用的数据集分别来自2015 年、2017 年和2019 年的指纹活性检测竞赛,公开发布3 个指纹集LivDet2015、LivDet2017 和LivDet2019。其中,LivDet2015 指纹数据集中的图像使用4 种不同的光学传感器GreenBit、Biometrika、DigitalPersona 和Crossmatch 采集构建而成,每类传感器采集的指纹数量约为4 000 张。LivDet2017、LivDet2019 数据集中的图像则是由 GreenBit、DigitalPersona、Orcanthus 这3 种不同光学设备所采集,LivDet2017 和LivDet2019 中每类光学传感器采集的指纹约为6 000 张和4 000 张。
3.2 性能评价指标
本文采用的深度伪造指纹检测模型版权保护算法的性能指标如下[13]。
1) 保真度。在神经网络模型中植入水印后,不能影响原始检测模型的性能。
2) 高效性。植入的神经网络水印应避免模型版权验证时响应时间过长。
3) 有效性。神经网络水印必须长期有效,对每个用户保持独一无二性。
4) 稳健性。神经网络水印遭受常见的恶意攻击后,依然存在且能用于后续的模型版权归属确权。
5) 安全性。用于模型版权验证的水印不易被伪造、访问和读取。
3.3 后门的嵌入和提取
黑盒水印主要是通过构造触发集来为模型嵌入后门的。当模型版权归属发生纠纷时,拥有者通过触发集的特定输出实现模型版权认定,而伪造者无法提供该证明。触发集的生成如式(13)所示。
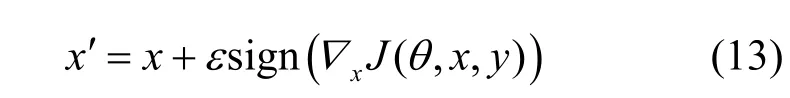
其中,θ为检测模型的相关参数,J(θ,x,y)为训练该模型的损失函数,∇为梯度,sign(·) 为符号函数,ε为添加的扰动大小。通过逐渐添加扰动的方式使构造的触发集位于决策边界附近。成功对手和失败对手的对抗性指纹示例如图7 所示,当触发集中样本数量为4 时,图7(a)为越过边界的成功对手,图7(b)为保持原有分类的失败对手。
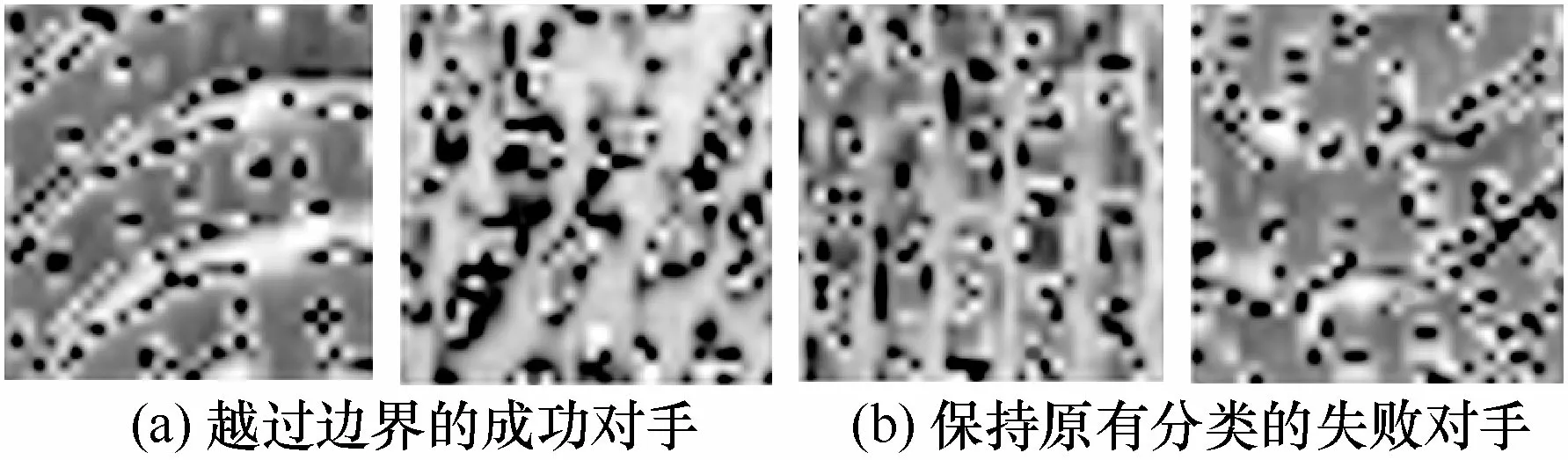
图7 成功对手和失败对手的对抗性指纹示例
后门的提取通过输入触发集样本使成功对手和失败对手都能被深度伪造指纹检测模型正确分类,最理想的状态是所有触发样本的标签与模型预测结果之间的距离为零。但是,由于深度伪造指纹检测模型存在被攻击和嵌入时触发精度对原始任务的影响,导致误报,因此,通过设计阈值θ对水印提取的性能进行评估。为了将错误率控制在0.05以内,嵌入成功和失败的概率均为0.5,触发样本服从二项分布即

其中,T为触发集样本的个数,为了使水印验证有效,只需误报数小于阈值,便认为成功提取水印。如当T=50 时,阈值为19,只要触发集的标签与预测标签最大误差小于19,则表明水印提取成功。
3.4 实验结果
本文在不同数据集下进行了算法性能测试,在LivDet2017 中的Orcanthus 对不同卷积层模型分类精度进行了分析,不同卷积层数下的分类精度如图8 所示。卷积层数为3 时,深伪检测任务的性能最佳,因此在后续的实验中,均采用4 个卷积层和3 个全连接层结构,利用期望值进行最终决策,且差分隐私算法的强度分别设为ε=1.0,δ=0.05。目前,基于深层的伪造指纹检测虽然已取得极高的性能,但是本文还是使用一个轻量级的模型进行版权保护:一方面,本文主要研究的是深伪检测模型的版权保护任务,有别于传统的深伪检测任务,因而选用的是参数较少、层数较浅的模型;另一方面,鉴于移动终端的有限算力,本文期望设计的轻量化深伪指纹检测模型能够应用在小型化的设备提供服务,如手机、平板等移动终端。
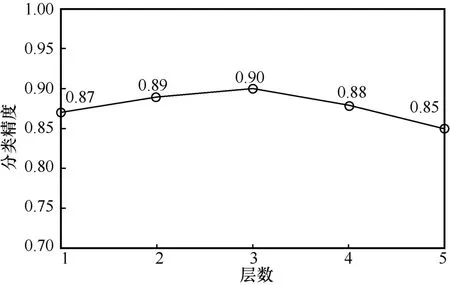
图8 不同卷积层数下的分类精度
本文将LivDet2015 中的真假指纹图像进行再整合,用于真伪检测模型的构建,差分隐私对深度伪造指纹检测模型分类精度的保护效果如图9(a)所示,原始任务检测模型分类精度为92%。当使用触发集微调决策边界时,原始任务的分类精度下降了22%。虽然能够鉴别模型版权归属,但此时的性能下降较明显,不满足版权保护算法中的保真度。通过引入噪声层的方式重新构造决策边界,在完成版权归属确权同时,能够减弱对任务性能的影响,仅下降3%。此外,本文还测试了LivDet2017 和LivDet2019中在不同传感器下的保护效果,如图9(b)所示。结果表明嵌入的后门不仅能够被成功触发,并且优化后的决策边界微调算法还能对原始任务起到较好的保护作用。为了进一步验证所提框架的有效性,本文测试了不同用户等级下的模型分类精度,如图10 所示,结果表明所提算法依旧有效。
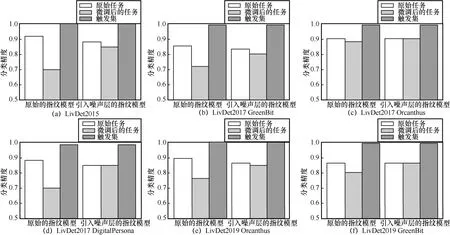
图9 差分隐私对深度伪造指纹检测模型分类精度的保护效果

图10 不同用户等级下的模型分类精度
若未授权用户尝试访问深度伪造指纹模型,将拒绝提供服务,即使提供输入数据,输出的结果也将无任何参考价值。真伪指纹鉴别是一个二分类问题,性能最低为50%,相当于随机采样的概率。为了验证本文采用的概率选择策略能够降低模型分类精度,采用了以下4 种不同的策略对神经元进行冻结。1) 随机,随机性地冻结神经元。2) 均值,围绕总体神经元的均值冻结。3) 升序,按照神经元的值从小到大冻结。4) 降序,按照神经元的值从大到小冻结。将第2 个卷积层中的神经元进行不同程度的冻结,模型的性能如图11 所示,可观察到本文采用的概率选择策略仅需冻结4%左右的神经元就能快速降低模型的分类精度,而其他4 种策略则需要冻结20%左右的神经元。

图11 不同冻结神经元比例下的模型分类精度
3.5 模型稳健性验证
为了验证深度伪造指纹检测模型修改后是否具有稳健性,本文还在LivDet2015 数据集下进行了稳健性实验。通过对参数进行修剪,将绝对值最小的权重剔除来模拟压缩攻击,结果表明构造的触发后门能够抵挡模型压缩攻击。对模型压缩的稳健性如表1 所示,深度伪造指纹检测模型能抵挡50%左右的压缩攻击。

表1 对模型压缩的稳健性
通过构造大小不同的伪造触发集来微调训练好的深度伪造检测模型,对模型微调的稳健性如表2所示。原有的触发集能够对检测模型进行版权归属认证,表明本文提出的触发后门具有稳健性,与对抗样本难以防御的特性[39]相一致。

表2 对模型微调的稳健性
除了上述2 种攻击,攻击者还可能对冻结的关键性神经元进行再训练,尝试重现原始任务。由于攻击者事先无法获悉检测模型是在哪层执行关键性神经元冻结,只能通过固定其他层的神经元对该层进行重训练。对于未授权用户来讲,该尝试等同于重新训练一个原始任务模型。而攻击者是因为计算资源有限,为了降低模型的训练成本,才会盗取合法用户的知识产权。因此,攻击者不会花费更多训练代价来获取模型的使用权,使主动保护方案具有稳健性。即使使用者被策反,模型拥有者依然可借助时间戳进行模型版权归属确权,本文所提的框架依然具有稳健性。
3.6 水印验证框架
深度伪造指纹检测模型在抵抗模型微调攻击的同时,也会存在多个水印共存问题,间接发生水印的混淆。攻击者对模型进行微调攻击后,尽管模型性能会下降,但是攻击者宁愿牺牲检测模型的准确率。为了保障安全,本文设计了一种新的水印验证框架,当发生水印混淆时,由权威第三方提供时间戳的生成和认证服务,模型所有者仅需向权威第三方提供触发集,使用SHA-256 哈希运算来为触发集生成时间戳。当需要版权确权时,再次向权威第三方提供触发集,借助时间戳认证服务,通过时间先后来对混淆后的版权进行认证。模型所有者把争议模型以及触发集提供给权威第三方,权威第三方通过SHA-256 哈希函数给触发集加盖时间戳,把生成的哈希值交还给模型所有者,形成证据。当发生水印混淆的时候,模型所有者和攻击者都需要把哈希值和触发集提交给权威第三方进行认证。最后权威第三方通过时间戳的哈希值,来判断时间节点的先后顺序,生成时间戳靠前的版权验证者为模型的真正所有者。
3.7 方法的通用性
除了在3 个公开的指纹数据集上进行了版权归属验证,本文还在Cifar10 数据集上进行了通用性测试,本文算法同样表现出较好性能,如表3 所示。通过与现有的5 种算法[22-23,25]对比可知,当模型嵌入黑盒水印后,原始任务分类精度都会退化,相比较而言,本文算法分类精度降幅更小,基本上可忽略,对原始任务影响较小。

表3 算法的通用性性能
4 结束语
在保密通信过程中,指纹识别是应用最广的身份识别技术,对保障隐私安全和查验用户身份的合法与否至关重要。近年来,研究者发现其易遭受伪造指纹的欺骗攻击,伪造指纹检测技术应运而生。但是训练一个鉴别真假指纹的深层模型需要海量的数据和超强的算力,高敏感型的指纹被收集后存在泄露风险,而深度伪造指纹检测模型的滥用势必会导致个人隐私的泄露和知识产权侵权风险,对深伪检测模型进行版权保护迫在眉睫。针对传统黑盒版权保护算法存在削弱原始任务性能且适用于模型事后确权的问题。本文提出一种基于差分隐私的深度伪造指纹检测模型版权保护算法,在实现版权的主动保护和被动验证的同时,能够兼顾原始任务分类精度。为解决传统的决策边界微调算法造成的原始任务分类精度下降问题,本文在检测模型中引入了噪声层模块,旨在特征提取过程中引入随机性,并利用差分隐私算法的期望稳健性进行最终的决策,以训练一个对噪声不敏感的深度伪造指纹检测模型。通过对抗训练来微调该模型的决策边界为其嵌入后门,使嵌入后门后的决策边界只发生轻微变化。采用概率选择策略对深度伪造指纹检测模型的神经元进行选择性冻结,让忠诚的用户可解冻更多数量的神经元,以实现对该模型的主动保护。此外,还设计了一种水印验证框架,攻击者通过伪造触发集来为模型植入后门水印,致使模型版权发生了混淆。当模型面对混淆攻击时,所有者可通过时间戳的顺序,对该模型版权进行验证。实验结果表明,本文设计的版权保护算法对多种不同攻击具有一定的稳健性。
由于模型版权保护研究还处于起步阶段,尤其是基于生物特征的神经网络模型,目前还没有统一的性能评价指标,如何为不同模型和不同的版权保护方法设计统一的指标是接下来需要研究的内容。
