基于自动选择编码及动态选词策略的文本隐写方法
2022-10-09李晖金家立金纾羽马卫娇
李晖,金家立,金纾羽,马卫娇
(1.沈阳工业大学信息科学与工程学院,辽宁 沈阳 110870;2.北京猿力未来科技有限公司,北京 100102;3.广东东软学院计算机学院,广东 佛山 528225)
0 引言
大数据时代下的信息安全已成为当今社会的研究热点之一。信息隐藏(也称为隐写术)作为信息安全领域的关键技术能够将秘密信息嵌入公开载体中。图像[1-2]、视频[3-4]、音频[5-6]、文本[7-8]等数字多媒体信号是信息隐藏的常用载体。其中,文本是人们日常生活使用最广泛的传输媒介,为信息隐藏架起一座特殊的“隐蔽桥梁”。文本的低冗余性和高度信息编码特性使文本隐写方法具有重大的研究价值和现实意义。
文本隐写方法主要分为基于修改式和基于生成式两大类。第一类方法通过修改载体文本的格式或内容来实现信息隐藏[9-12]。例如,改变文本间距[9]、更改字符属性[10]、同义词替换[11]、句法转换[12]等。这类方法最大的缺陷在于安全性低,易被隐写分析手段检出。第二类方法则不需要事先准备载体文本,而是在秘密信息的控制下,通过使用生成算法自动生成隐写文本[7-8,13-20],算法不同,生成的文本内容也不同。该方法具有更强的抗隐写分析能力和更高的隐藏容量(ER,embedding rate),成为近年来文本隐写领域的前沿方向。
目前,基于生成式文本隐写方法的实现过程可归纳如下。首先,使用大规模语料库训练文本生成模型,使其能够很好地捕获自然语言的统计分布特征;其次,根据语言模型及构建规则确定每一时刻的候选词并计算相应的条件概率;之后,采用不同的编码方式对条件概率进行编码,以确定候选词与码字之间的映射关系;最后,根据秘密信息比特流确定每一时刻的输出,在文本生成的过程中实现信息隐藏。虽然这种方法具有较高的隐藏容量,但也存在以下问题。第一,目前主流的隐写模型大多采用循环神经网络(RNN,recurrent neural network)或长短时记忆(LSTM,long short-term memory)网络,生成的隐写文本长度有限并缺乏语义相关性。第二,在对候选词进行编码时,未能综合考虑每种编码方式各自的特点,缺乏编码灵活性。第三,随着候选词的增加,生成的隐写文本质量逐渐下降,会出现语法错误、语义模糊等问题,大大降低了隐写系统的安全性。
针对语义不相关、编码灵活性低以及候选词增加导致的隐写文本生成质量下降等问题,本文提出了一种基于自动选择编码及动态选词策略的文本隐写方法。该方法在机器翻译的背景下完成信息隐藏。通过使用Transformer 模型捕获文本的高维语义特征,使源语句和隐写文本之间具有语义相关性。在翻译的过程中,使用定长编码和哈夫曼编码建立候选词与码字之间的映射关系,通过引入评分比较机制实现编码方式的自动选择。此外,本文还引入了一种自适应选词策略,当候选词逐渐增加时,能够最大限度地减小隐写文本与正常文本之间的差异。
本文的创新主要包括以下3 个方面。
1) 隐写模型采用Transformer 模型。相比于RNN、LSTM 等时间序列预测模型,Transformer完全使用自注意力机制建立单词之间的全局依赖关系。因此,能够更好地捕获语义信息,提升模型提取长距离依赖特征的能力,从而生成语义清晰、逻辑相关的隐写文本。
2) 综合考虑了定长编码和哈夫曼编码各自的特点。候选词与码字之间的映射关系建立之后,通过引入评分比较机制实现编码方式的自动选择。
3) 为了缓解候选词的增加对隐写文本质量的影响,设计了一种基于概率差异百分比的自适应选词策略。通过设置概率差异阈值动态地选取迭代过程中的词元。
1 相关工作
基于生成式的文本隐写方法具有较高的安全性和实用性。早期的方法主要基于语法规则或句子模板[21-22]。这类方法没有考虑到语义,生成的隐写文本质量低。针对这一问题,基于统计语言模型的文本隐写方法应运而生。在统计语言模型中[23],生成第i个词语的条件概率与前i-1 个词语有关,当序列长度逐渐增加时,模型的参数空间愈发复杂,数据稀疏现象较为严重,因此引入马尔可夫假设来约束相关词语的个数。对于序列其概率可以表示为

其中,ωi为序列中的第i个词语,在每次的迭代过程中,可用极大似然估计来计算条件概率分布,即

马尔可夫模型是一种经典的统计语言模型,适合于自然文本的建模,因此出现了一些基于马尔可夫模型的文本隐写方法[13-15]。该模型具有一定的局限性,生成的隐写文本质量较低,易受到隐写分析技术的检测[24-25]。
随着神经网络在自然语言处理领域的广泛应用,基于神经网络的文本隐写方法相继被提出。例如,Fang 等[16]使用RNN 进行文本生成,将候选词划分成不同分组并进行定长编码,根据秘密信息匹配相应的编码域并输出分组中条件概率最大的单词。Yang等[7]使用LSTM学习自然文本的统计特征,在生成的过程中根据候选词的概率分布对其进行定长编码或哈夫曼编码,隐藏容量和隐写文本质量均达到最优性能。Ziegler 等[8]使用GPT-2(generative pre-training 2.0)预训练模型进行文本生成,在生成阶段采用算术编码策略,提高了隐写文本中单词的条件概率分布与正常文本之间的相似度。为了能够生成具有特定语义信息的隐写文本,Luo 等[17]使用基于RNN的编码器-解码器来生成高质量的隐写诗歌。Tong 等[18]同样使用该模型在生成中文流行音乐歌词的过程中隐藏秘密信息。Yang 等[19]将知识图谱融入文本生成的过程中,通过对图中路径进行哈夫曼编码,实现对语义趋势的控制,生成高质量且语义可控的隐写文本。Yang 等[20]使用基于RNN 的编码器-解码器和强化学习在实时交互式的问答中隐藏信息,在答复的过程中基于满二叉树对候选词进行定长编码,根据输入语句自动生成语义关联、语法正确的隐写对话。
机器翻译保证了源语句与目标语句之间的语义一致性,先后出现了一些基于机器翻译的文本隐写方法[26-28]。例如,Grothoff 等[26]使用统计机器翻译模型传递秘密信息。该方法首先对同一源语句使用不同的翻译系统获取候选译文集合;其次,根据候选译文的分配概率进行哈夫曼编码;最后,根据待嵌入的秘密信息在集合中选取相应的译文,实现在翻译的背景下完成信息隐藏。为了提高隐写系统的安全性,Stutsman 等[27]只将翻译之后的结果发送给接收者,避免了攻击者对源语句的分析。该方法首先使用文献[26]提出的方式来获取不同的翻译结果;其次,基于共享密钥及哈希函数计算每个翻译结果的哈希值;最后,根据秘密信息以及哈希值中的最低有效位匹配到相应的隐写译文,接收者只需根据获得的隐写译文计算其哈希值即可成功提取出秘密信息。与前2 种方法相比,Meng 等[28]使用一个统计机器翻译模型来获得候选语句,提高了候选译文的相似度,具有更强的稳健性和更大的隐藏容量。
上述基于机器翻译的文本隐写方法均使用统计机器翻译模型,生成的隐写译文质量较低。神经网络的发展掀起了新一轮机器翻译领域的热潮,在英-德、英-法等多个机器翻译任务上均取得了优越的性能[29-30]。神经机器翻译模型由编码器-解码器组成,编码器将源语句编码成固定维数的向量,解码器根据该向量逐步生成目标词汇。RNN、LSTM或Transformer 均可作为编码器和解码器。由于Transformer 具有强大的表征能力且可以并行化计算,因此本文使用基于Transformer 的编码器-解码器来生成语义相关的隐写译文,以此提高翻译准确性。在信息嵌入阶段,使用集束搜索(Beam Search)算法构建每一时刻的候选词,并对其进行定长编码及哈夫曼编码。通过比较2 种隐写译文的评分大小,动态选择翻译语句的编码方式,生成流畅度高、可读性强的隐写译文。通过比较概率差异百分比和阈值的大小,自适应选取每一时刻的输出,以此降低候选词的增加对隐写译文生成质量的影响。
2 模型原理及架构
2.1 模型原理
Transformer 是由Google 在2017 年提出的一种堆叠的编码器-解码器结构模型[31]。编码器由多头注意力(multi-head attention)机制和前馈网络(FFN,feed forward network)两大子层组成,解码器由掩码多头注意力(masked multi-head attention)机制、多头注意力机制及FFN 三大子层组成,每个子层后面使用残差连接和层标准化等方法。
Transformer 不包含循环结构的递归、卷积操作,而是使用自注意力机制捕获词语的语义特征,因而缺乏位置信息的感知功能。通过使用频率变化的正弦波引入位置编码,使模型能够对每个词语的位置及其之间的距离进行有效建模,计算过程为


为了提取更丰富的数据特征,Transformer 使用多头注意力机制将Q、K、V线性映射到多个子空间中,并独立地计算每个子空间的注意力权重。最终使用输出权重矩阵将各个结果进行拼接。计算过程为
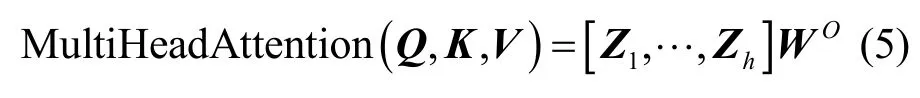
其中,h为子空间的数量,dv为V的维度,Zi表示某一个子空间的计算结果,其可用式(6)进行计算。
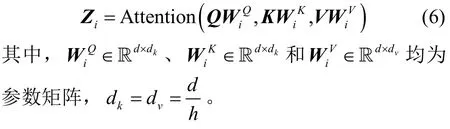
经过多头注意力机制后,模型可获取不同角度的语义信息,再将输出经FFN 做进一步处理,即

解码器的结构与编码器大致相同,其不同之处主要体现在掩码多头注意力机制上。该机制能够阻止未来时刻的输出所产生的影响。解码器中还包含编码器-解码器交互子模块,其中的K、V来自编码器,而Q来自解码器,使模型在解码的过程中能够找到与源语句相关性强的词语。
解码器的解码方式包括基于搜索式和基于采样式两大类。前者中的Beam Search 是一种基于图的启发式搜索算法,广泛应用于机器翻译、知识问答、语音识别等领域。其基本思想是在每一步深度扩展的过程中,只选取条件概率最大的前B个解,B为集束大小(BS,beam size),其余输出则进行截断,从而减小了内存消耗,提高了搜索效率。具体流程如下。假设在t-1 时刻,模型得到B个候选序列在t时刻,集束搜索根据已有的B个候选序列Y[t]1-分别与词表v中的每个词进行组合,即最终从生成的序列中保留B个条件概率最高的序列作为即,计算过程为

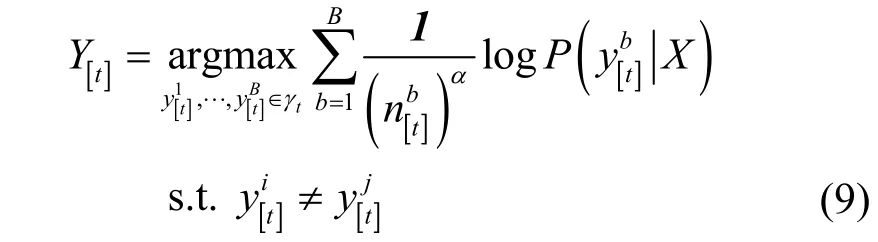
2.2 整体架构
本文提出的文本隐写方法包括信息隐藏和信息提取两大部分,隐写模型整体架构如图1 所示。在信息隐藏阶段,首先使用Transformer 编码器获得源语句对应的语义向量,解码器根据该向量逐步生成目标词元;其次,使用Beam Search 算法在译文生成的过程中构建候选词,选择相应的隐写编码方法对候选词进行编码;之后,在秘密信息的控制下,选取候选词中与之对应的词元,通过动态选词策略确定实际的输出词元,直至遇到结束标识符<EOS〉或到达序列的最大长度;最后,将输出的BPE(byte pair encoding)序列[32]分别进行解码,经评分比较机制实现编码方式的自动选择,发送方将最终生成的隐写译文和相关介质在公开信道上发送给接收方。秘密信息的提取过程与嵌入过程相反,接收方需使用相同参数的Transformer 模型,并采用相同的方法进行解码,以便正确提取出秘密信息。

图1 隐写模型整体架构
2.3 自动选择编码策略
基于满二叉树的定长编码(FLC,fixed-length coding)和基于哈夫曼树的变长编码(VLC,variable-length coding)是2 种常见的编码方式,已被广泛应用于生成式文本隐写术中[7,16,19]。在FLC 中,每个内部节点包含2 个子节点,并且所有叶子节点具有相同的深度。在VLC 中,各符号出现的概率对应不同长度的码字,使概率较大的符号具有较短的码字,因此VLC 是一种最优前缀码。在编码之前,本文使用Beam Search 算法选取前BS 个词元组成候选词CP,即在 FLC 中,需满足,嵌入率bpw 为每词元可嵌入秘密信息的比特数。而在VLC 中,只需根据候选词的条件概率构造一棵哈夫曼树,并对叶子节点进行哈夫曼编码即可 。因 此,在bpwBS=2的条件 下,,而VLC 充分考虑了每次迭代过程中候选词的条件概率分布,生成的隐写文本质量更加优越。由此可见,若注重嵌入率,FLC 更有效;若注重生成的隐写文本质量,则VLC 更有效。本文旨在通过自动选择编码策略实现FLC 和VLC 的自动选择,以同时具备2 种编码方式各自的优点。
编码完成后,根据秘密信息输出每一时刻候选词中与之对应的词元,直至遇到结束条件或到达序列的最大长度。随后依次组合全部输出,将BPE 序列解码后获得2 种隐写译文,并通过评分比较机制实现编码方式的自动选择。该机制如图2 所示。
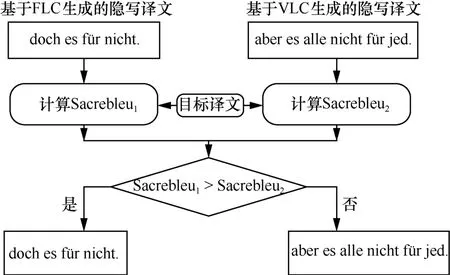
图2 评分比较机制
BLEU(bilingual evaluation understudy)是机器翻译领域常用的评估指标之一[33],用来衡量模型的翻译结果与实际目标语句之间的相似度。BLEU 越大,生成的文本质量越优越。计算过程为

其中,BP 为惩罚因子,可用式(11)进行计算。
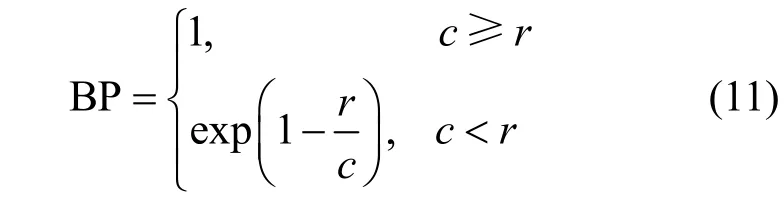
其中,c为模型翻译的预测句长度,r为参考句的有效长度,N为预测句与参考句在匹配时的n-gram 最大窗口大小为标准化权重。pn为生成的预测句与参考句的匹配精度,即
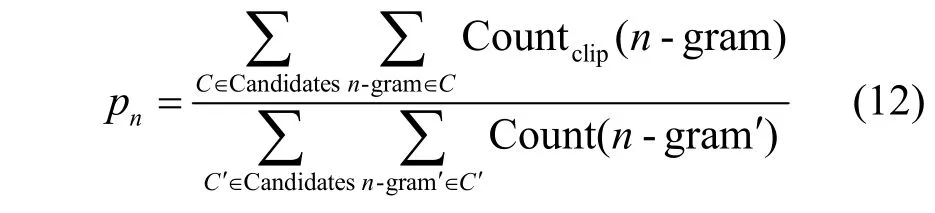
其中,Candidates 表示候选译文集合;n-gram 为n元文法,表示语句中连续n个词所组成的序列;Countdip表示某一个n-gram 的截断计数。
BLEU 是一种参数化度量,参数的变化也会导致该值发生变化,从而缺乏可比较性。文献[34]提出了一种度量内部标记化和规范化的方案Sacrebleu,其内部具有一套标准的处理体系,能够生成可比较的BLEU。本文将Sacrebleu 作为编码方式的选择依据,分别计算生成的2 种隐写译文Sacrebleu 并比较两者大小,选取较大者对应的编码方式作为当前翻译语句的实际编码方式,若两者相等,则选取VLC。上述方法能够实现编码方式的自动选择,自动选择编码过程如图3 所示。

图3 自动选择编码过程
2.4 动态选词策略
集束搜索需要将上一时刻的B个候选序列与词库进行组合,从中输出B个条件概率最大的扩展并组成序列。在每次迭代的过程中,将生成的词元后缀作为候选词,秘密信息的嵌入会造成已有候选序列与生成词元前后相关性弱的问题,大大降低生成的隐写译文质量。为此,本文引入动态选词策略,如图4 所示。

图4 动态选词策略

3w;反之,则选取输入前缀w1。依次类推,直至序列生成结束。
序列生成结束后,对其进行反向搜索,最大限度地保证前后词元的依赖关系。例如,当t=3 时,输出隐写词元w1,其对应的输入前缀为w4,而t=2时的隐写词元为w2,因此也需根据式(13)计算ph。若则t=2 时仍然输出w2;反之,则输出w4。经过前向和反向搜索,实现了词元的动态选择,有效减小了秘密信息的嵌入对生成隐写译文质量的影响。
在进行前向和反向搜索时,候选词中会出现词元相同而条件概率不同的情况,假定为t时刻隐写词元对应输入前缀的条件概率,为时刻隐写词元的条件概率。当时,,也需计算两者的概率差异百分比,以解决“同词不同值”的问题。
2.5 嵌入与提取算法
本文使用Beam Search 算法构建每一时刻的候选词,并对其中的词元进行编码以完成秘密信息的嵌入。图5 所示为BS=4 时,在生成第2 个词元的过程中嵌入秘密信息的示意。源语句经编码器映射为相应的语义向量,对其进行复制扩展并传送到解码器中。假设t=2 时的候选序列集合为经过Linear+Softmax 层之后,每个序列分别与词表v进行组合,获得4 种概率分布空间,最终根据式(9)选取条件概率最大的前4 个序列组成Y[3],即其中表示将单词作为序列的后缀进行拼接。本文对生成的4 个后缀进行编码,根据秘密信息输出与之对应的词元,实现了在译文生成的过程中嵌入秘密信息。
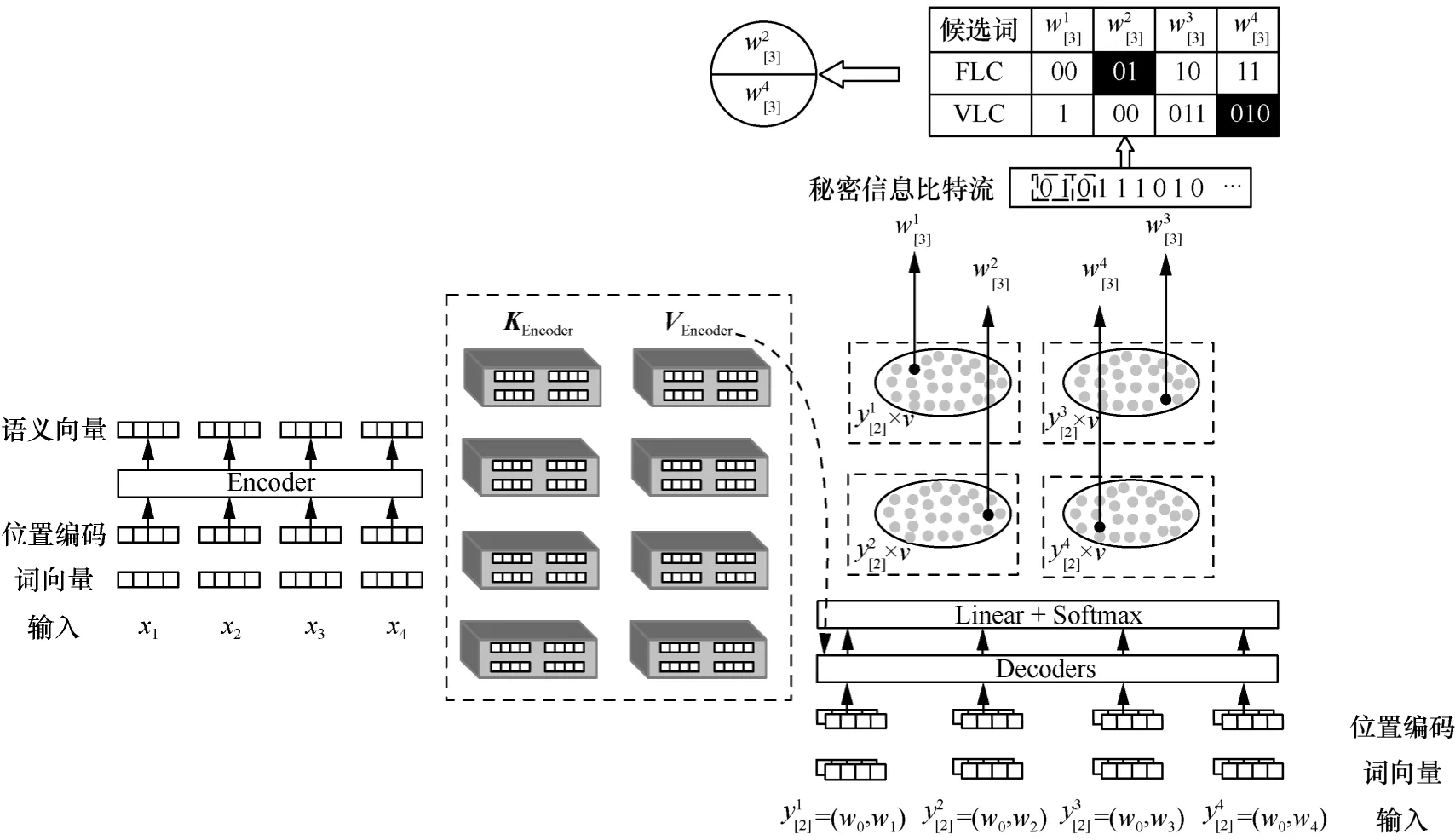
图5 在生成第2 个词元的过程中嵌入秘密信息的示意(BS=4)



信息提取与嵌入过程相反。发送者需要使用相同参数的模型,使接收者能够对源语句进行正确翻译。在翻译的过程中,需采用相同的Beam Search算法构建候选词。为了能够正确提取出秘密信息,接收者还需共享pi,其主要目的如下。第一,在机器学习的多分类任务中,常用Softmax 函数将模型的输出结果映射到(0,1)范围内,为了防止数据下溢,本文采用Beam Search 算法将条件概率转换成对数形式,使其取值范围变为(-∞,0) 。因此,接收者可以根据条件概率的2 种表示形式判断某句隐写译文实际采用的编码方式。例如,编码方式若采用FLC,则将pi以对数形式返回给接收者,若采用VLC,则将pi以非对数形式返回给接收者,上述过程实现了编码方式的自动选择。第二,候选词中会出现相同的词元,接收者可以根据pi找到真正携带秘密信息词元,通过读取其对应的二进制编码即发送者嵌入的秘密信息。第三,动态选词策略导致某一时刻未能正确嵌入秘密信息,因此接收者可根据ip查找该时刻正确嵌入的秘密信息。第四,接收者可根据pi判断某一时刻与之对应的词元是否在候选词中,以此来判定当前时刻是否携带秘密信息。具体提取算法如算法2 所示。


3 实验与结果分析
3.1 实验设置
本文选取WMT 2014 英德翻译任务中所有可用的并行数据作为训练集,其中包含Europarl v7数据集(约192 万个句子对)、Common Crawl 数据集(约240 万个句子对)以及News Commentary v9 数据集(约20 万个句子对),并按照以下标准过滤训练集。
1) 源语句和目标语句及其BPE 编码的有效长度控制分别控制在(1,80)和(3,150)范围内。
2) 目标语句BPE 编码长度与源语句BPE 编码长度的比值在(0.5,2)范围内。
3) 去掉空白语句。
按照上述标准过滤后,训练集大约包含423 万个句子对,每条英文语句与德文语句的平均分词长度分别为23 和21。验证集选择newstest 2013,测试集选择newstest 2014,将2 个数据集的有效长度控制在(1,80)范围内。随后使用Moses 脚本对过滤之后的训练集、验证集和测试集做进一步处理,包括Normalize punctuation、Truecase 等操作。数据集使用BPE 编码分割成子词符号,其中包含37 000 个共享源-目标词汇。将BPE 编码长度相同的句子对组合在一起,每个训练批次平均包含大约10 万个目标词元。
本文使用Pytorch 1.6.0 仿真平台,编程语言为Python 3.6.5,基于NVIDIA Tesla V100 32 GB x1 和CUDA 10.1 加快训练Transformer 模型,对其共训练16 万步,累计12 步更新一次梯度。在训练的过程中,学习率的变化为文献[31]的2 倍,其余的参数配置与文献[31]相同,本文通过平均最后5 个检查点得到最终的翻译模型。
3.2 自动选择编码策略对隐写算法性能影响
隐写算法性能的评价指标主要体现在不可感知性和隐藏容量两大方面。不可感知性主要取决于生成的隐写文本质量,隐藏容量主要取决于在文本中嵌入的秘密信息量。本文使用Sacrebleu 评估模型的翻译准确性,该值越大,隐写文本质量就越高。隐藏容量定义为实际嵌入的比特数除以计算机中所有生成文本所占的比特数,该值越大,模型的嵌入能力就越强。
3.2.1 自动选择编码策略对不可感知性影响
嵌入秘密信息前,本文讨论了BS 的取值和可调参数α对测试集目标语句Sacrebleu 的影响,结果如表1 所示。嵌入秘密信息后,每一时刻输出特定的隐写词元,α不再影响生成的隐写译文质量,bpw 和Sacrebleu 的变化情况如表2 所示。其中,FVLC(fixed-and variable-length coding)是在FLC和VLC 的共同作用下将秘密信息嵌入目标词元中,自动选择编码策略对实验结果的影响可以直接体现在FVLC上。由于本文提出的编码方式包含VLC,导致bpw 不确定,因此本文计算了生成的每个词元所嵌入的平均比特数。

表1 嵌入秘密信息前生成目标语句的Sacrebleu

表2 嵌入秘密信息后生成隐写译文的bpw 和Sacrebleu
基于以上结果,可以得出如下结论。嵌入秘密信息前,适当增加波束和α可以提高翻译质量,Sacrebleu 的最大值为27.41。嵌入秘密信息后,采用3 种方式生成隐写译文的Sacrebleu 均随着BS 的增加而减小,且无论BS 大小如何,采用FVLC 生成隐写译文的Sacrebleu 最大。原因是每个词元可嵌入的比特数随着BS 的增加而增加,bpw 逐渐增大。在每次迭代的过程中,输出对象受秘密信息的控制程度逐渐加大,增加了隐写译文与实际译文之间的差异。FVLC 综合考虑了FLC 和VLC 各自的编码特性,且以Sacrebleu 的大小作为编码方式的选择依据,因此生成的隐写译文质量更加优越。
为了进一步验证自动选择编码策略对不可感知性的影响,本文与文献[35]进行了对比分析,结果如表3 所示。
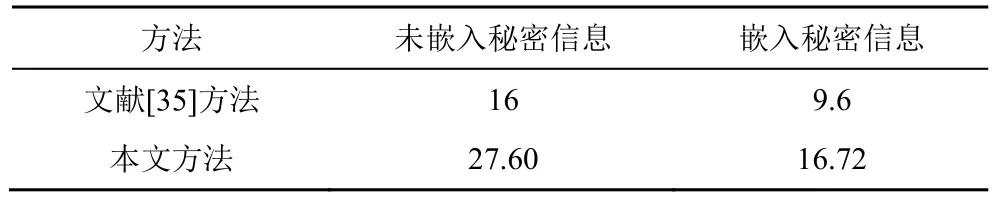
表3 不同方法BLEU 对比
从表3 可以看出,在未嵌入秘密信息的前提下,Transformer 模型可以生成更高质量的译文。嵌入秘密信息后,虽然2 种方法的BLEU 均有不同程度的下降,但本文方法仍具有较高的BLEU。
3.2.2 自动选择编码策略对隐藏容量影响
隐藏容量是评估隐写算法性能的重要指标,其描述了在文本中嵌入的秘密信息量。本文将ER 定义为实际嵌入的比特数除以计算机中所有生成文本所占的比特数,即

其中,M为生成的语句总数,Li为第i个语句长度,k为每词元可嵌入的比特数为第i个语句在计算机中实际占用的比特位数。每个英文字母在计算机中实际占8 位,因此表示第i个语句中的第j个单词所包含的字母总数。由于秘密信息的嵌入对象为每一时刻的词元,因此L1为生成序列的平均词元数。分别为生成隐写译文的平均长度和其中每个词元所包含的平均字符数。不同方法生成隐写译文的bpw 和ER 如表4 所示。
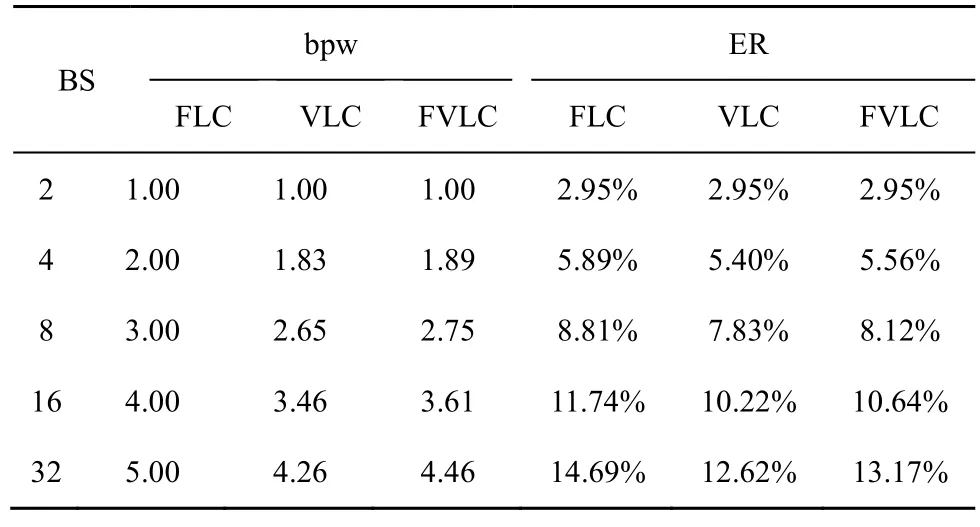
表4 不同方法生成隐写译文的bpw 和ER
从表4 可知,ER 均随着BS 的增加而增加,且当BS 取值为4、8、16 和32 时,采用FLC 生成隐写译文的ER 最大,次之是FVLC,最小则是VLC。结合之前的实验结果可以得出,在保证隐藏容量的同时,采用FVLC 可以生成更高质量的隐写译文。
为了进一步验证自动选择编码策略对隐藏容量的影响,本文对比了不同方法下的隐藏容量,结果如表5 所示。

表5 不同方法下的隐藏容量对比结果
由表4 和表5 可知,当BS=2 时,自动选择编码策略对隐藏容量的影响较小,且本文方法的隐藏容量均大于对比方法。当BS=4 时,虽然隐藏容量处在FLC 和VLC 之间,但也均大于对比方法。
3.3 概率差异阈值hthreshold 对隐写算法性能的影响
不同的翻译语句势必会影响隐写系统的性能。BS=4 时,不同hthreshold的条件下采用FVLC 生成的隐写译文如表6 所示。

表6 不同hthreshold 时采用FVLC 生成的隐写译文(BS=4)
从表6 中可以看出,同一源语句在不同阈值下能够生成流畅度高、可读性强且具有语义相似性的隐写译文。本文在BS=4 的条件下进行实验,进一步讨论了阈值的选取对隐写译文质量、bpw 和隐藏容量的影响,结果分别如图6~图8 所示。

图6 不同hthreshold 对模型Sacrebleu 的影响
从图6 中可以看出,随着hthreshold的增加,Sacrebleu 均在减小。原因是hthreshold的增加减小了隐写词元与其输入前缀的依赖程度,使每一时刻的输出越来越受到秘密信息的影响,从而选取条件概率较低的词元,降低了隐写文本质量。由于自动选择编码策略以Sacrebleu 作为编码方式的选择依据,因此FVLC 的Sacrebleu 高于FLC 和VLC。
在讨论hthreshold对bpw 的影响时,本文将bpw定义为正确携带秘密信息的词元所嵌入的平均比特数。从图7 中可以看出,FVLC 和VLC 的bpw均随着hthreshold的增加逐渐增加。原因是hthreshold的增加减小了正常词元对隐写输出的限制,使正确携带秘密信息的词元数增多。在FLC 中, BS=2bpw始终成立,因此当BS=4 时,FLC 的bpw 始终不变。

图7 不同hthreshold 对模型bpw 的影响
本文的动态选词策略不改变秘密信息的嵌入对象,导致某一时刻未能正确嵌入秘密信息。在讨论hthreshold对ER 的影响时,将ER 定义为正确嵌入的秘密信息比特数除以计算机中所有生成文本所占的比特数。从图8 中可以看出,ER 值会随着hthreshold的增加而增加。原因是hthreshold的增加提高了每一时刻输出隐写词元的概率,在翻译的过程中增多了正确嵌入的秘密信息比特数,隐藏容量逐渐增加。表7 列出了在不同hthreshold、嵌入方式以及BS 的情况下,bpw、Sacrebleu 和ER 的实验结果。

图8 不同hthreshold 对模型ER 的影响
根据表7 可以得出以下结论。1) 当BS 取值分别为4、8、16、32 时,FVLC 和VLC 的bpw,以及不同嵌入方式的ER 均随着的增加逐渐增加,Sacrebleu 逐渐减小,而FLC 的bpw 保持不变。原因在于差异阈值的提高增加了隐写词元的可选择性,使生成的隐写译文包含更多的隐写词元,因此隐写文本质量逐渐降低,正确嵌入秘密信息的比特数逐渐增多。2) 相比于FLC 和VLC,FVLC的bpw 介于两者之间,并且评分比较机制的引入使FVLC 具有较大的Sacrebleu,生成的隐写译文质量更高,在一定程度上提高了系统的不可感知性。3) 在讨论对ER 的影响时,实际正确嵌入秘密信息的比特数及计算机中所有生成文本所占的总比特数均会影响ER 的大小。从实验结果中可以计算出,当BS=8 时,FVLC 和VLC 的ER 平均相差0.032,与FLC 的ER 平均相差0.12,Sacrebleu 分别平均提高了2.442 和3.598。由此可见,FVLC 虽然牺牲了较低的隐藏容量,但却大幅提升了隐写文本质量。综上所述,随着BS 的增加,通过采用自动选择编码策略以及设置合理的概率差异阈值仍能生成高质量的隐写译文,在一定程度上提升了隐写算法的性能。
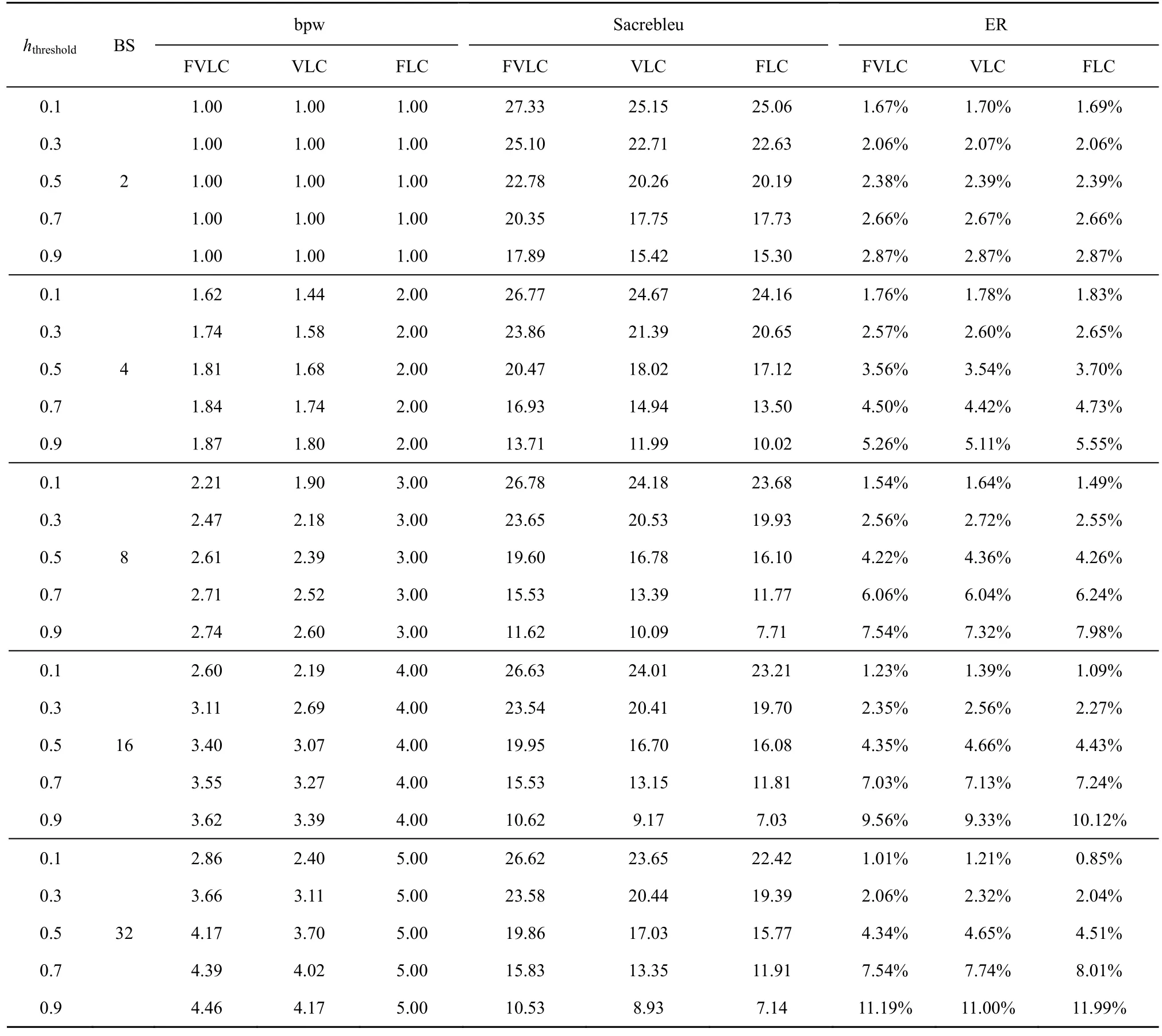
表7 不同hthreshold、嵌入方式以及BS 对bpw、Sacrebleu 和ER 的影响
4 结束语
本文提出了一种基于自动选择编码及动态选词策略的文本隐写方法,该方法在机器翻译的背景下使用Transformer 模型传递秘密信息。在翻译的过程中,通过比较2 种隐写译文与实际译文的Sacrebleu 大小实现FLC 和VLC 的自动选择,通过计算隐写词元与正常词元的概率差异百分比,实现在译文生成的过程中根据概率差异阈值自适应选词。实验结果表明,评分比较机制的引入能够生成流畅度高、可读性强的隐写译文,差异阈值的引入能够缓解候选词增加导致的隐写文本生成质量较低的问题。
