对抗训练驱动的恶意代码检测增强方法
2022-10-09刘延华李嘉琪欧振贵高晓玲刘西蒙MENGWeizhi刘宝旭
刘延华,李嘉琪,欧振贵,高晓玲,刘西蒙,MENG Weizhi,刘宝旭
(1.福州大学计算机与大数据学院,福建 福州 350108;2.福建省网络计算与智能信息处理重点实验室,福建 福州 350108;3.丹麦科技大学应用数学和计算机系,哥本哈根 2800;4.中国科学院信息工程研究所,北京 100093)
0 引言
根据我国互联网网络安全监测数据分析报告,在2021 年上半年,我国境内感染计算机恶意程序的主机约有446 万台,同比增长46.8%,发现新增移动互联网恶意程序86.6 万余个。随着恶意代码及其变种数量的增加,恶意代码检测面临着巨大的挑战[1]。基于特征码的检测技术无法应对新型恶意代码,以人工分析为主要方式的检测技术存在检测效率低等明显问题,无法适应当前的网络安全环境,自动化和智能化的恶意代码检测具有一定的必要性。
在智能化恶意代码检测中,相关特征(如任务、意图、应用编程接口调用、系统调用以及字节特征等)被提前提取并用于恶意代码检测器的训练,取得了较好的结果[2-3]。然而,机器学习本身存在一些安全性问题[4]。机器学习模型的有效性取决于训练数据和测试数据遵循相同分布的假设,这种假设很可能遭到攻击者的破坏,损害模型的安全性。攻击者在输入样本上施加微小的扰动便能迫使分类模型输出错误的预测,这种方式称为对抗样本攻击[5]。在恶意代码领域,攻击者利用模型的不足,生成恶意代码样本,达到绕过恶意代码检测器的目的[6-7]。
随着恶意代码反检测能力的提高,增强恶意代码检测器识别对抗样本的能力,提高检测器的稳健性,是现阶段提升恶意代码检测水平的关键。防御蒸馏[8]、对抗训练[9]和对抗样本拒绝[10]等是常见的对抗样本防御措施。其中,对抗训练被认为是抵抗对抗攻击的最佳解决方案,它利用训练好的模型来生成对抗样本,然后将它们添加到训练集中以重新训练模型,从根本上增强目标分类器的稳健性[11]。Wang 和Liu 等[12]通过对抗训练方法提升面向恶意软件C2 流量的检测能力。Wang 和Zhang 等[13]提出了一个用于生成对抗样本进行对抗训练的框架,通过重训练提高分类器在安卓恶意软件检测和家庭分类中的有效性。这些研究证明了对抗训练增强恶意代码检测器的可行性。
在恶意代码检测器对抗训练的过程中,对抗样本的生成是一个重要环节。如何利用对抗样本知识,以较小攻击成本和较高攻击成功率生成具有现实意义的恶意代码对抗样本是恶意代码领域的一个重要问题。Goodfellow 等[14]提出的生成对抗网络(GAN,generative adversarial network)在样本生成上具有一定的优势。GAN 由生成器和判别器构成,通过生成器和判别器之间的博弈,生成器将学习到数据的潜在规律并生成新的数据。Kim 等[15]利用GAN 生成基于灰度图像的恶意代码样本。之后,Kim 等[16]在文献[15]的基础上利用深度卷积GAN 模型生成恶意代码样本,并基于图像结构相似性模拟零日恶意代码的生成。文献[17]利用辅助分类生成对抗网络生成恶意代码灰度图像,但没有考虑生成器生成的恶意代码质量。由于恶意代码的相邻字节之间存在结构上的相互依赖关系,对于恶意代码文件的任何更改都可能破坏可执行文件的功能,影响恶意代码的恶意功能[18]。恶意代码对抗样本与对抗性图像不同,即使成功地欺骗了检测模型,这些对抗样本在现实世界中也是不可行的。
在恶意代码的执行性问题上,Hu 等[19]提出了一种基于GAN 的恶意软件生成算法,通过引入一个替代检测器,对恶意代码检测器实现黑盒攻击,并通过在导入表中添加扰动应用程序接口(API,application programming interface)实现恶意代码对抗样本的生成。但是,基于原始GAN 模型的恶意代码生成,容易面临梯度消失以及训练不稳定等问题[20]。而且该研究在对抗生成的过程中并未考虑到攻击成本的问题。唐川等[21]提出了一种基于最小修改成本的对抗样本生成算法,利用深度卷积GAN 模型生成良性扰动,通过修改反编译文件并对安卓应用程序包(APK,Android application package)进行重打包,生成可执行的恶意软件对抗样本,成功绕过目标检测器的检测。但是该方法只考虑到了恶意代码特征的修改成本,未考虑到对抗样本生成过程中恶意代码检测器的查询次数。由于检测器的多次重复查询,容易引起安全人员的察觉,攻击者在对检测器进行攻击时,需要考虑到目标检测器查询效率问题。
针对上述问题,本文提出了一种对抗训练驱动的恶意代码检测增强方法。首先,基于沃瑟斯坦生成对抗网络[22](WGAN,Wasserstein generative adversarial network)和扰动删减方法,生成低扰动数量、高查询效率的恶意代码对抗样本。然后,利用生成的对抗样本对目标检测器进行再训练,增强恶意代码检测器性能。本文的主要研究工作包含以下几个方面。
1) 提出一种基于WGAN 的良性样本生成算法,构建面向API 调用的良性样本库。利用WGAN在一定程度上解决原始GAN 训练不稳定的问题。通过生成器和判别器之间的博弈训练,模拟良性样本的分布,构建良性样本库,进而为恶意代码对抗提供更加丰富的扰动组合。
2) 提出一种基于对数回溯法的扰动删减算法,构造恶意代码对抗样本。将生成的良性样本以扰动的形式添加到恶意代码,利用对数回溯法对添加的扰动进行删减,以较少的扰动数量和目标检测器查询次数绕过恶意代码检测器。
3) 基于对抗训练对目标检测器进行增强。利用生成的恶意代码对抗样本对恶意代码检测器进行重训练,提高恶意代码检测器对于对抗样本的检测率。最后,选取不同的恶意代码检测器进行实验,验证了本文方法的有效性和通用性。
1 相关理论
1.1 WGAN
WGAN 是GAN 的一种变体,不同于GAN 使用具有突变性的詹森香农散度作为生成数据与真实数据间的距离衡量标准,WGAN 引入沃瑟斯坦距离作为损失函数,能够对GAN 模型梯度消失以及训练不稳定问题进行优化。沃瑟斯坦距离更加平滑,即使2 个分布互不重叠,也能够很好地反映二者的远近。沃瑟斯坦距离的计算方法如式(1)所示。

其中,Pr和Pg分别表示真实样本的分布和生成器生成样本的分布,K表示利普希茨常数。||f||L≤K等价于若f的定义域为实数集合,则||f||L≤K表示f的导函数绝对值不超过K。
将判别器表示为函数f,设定一个固定常数c(c〉0),以c的绝对值截断判别器的参数ω,限制判别器的最大局部变动幅度,使其满足在判别器和生成器双方的博弈中,判别器的目标是尽可能正确地区分真实样本与生成器生成的假样本,即最大化沃瑟斯坦距离。相反地,生成器的目标是最小化沃瑟斯坦距离,尽可能输出与真实样本相似的样本以欺骗判别器。判别器的损失函数、生成器的损失函数以及WGAN 的目标函数分别如式(2)~式(4)所示。
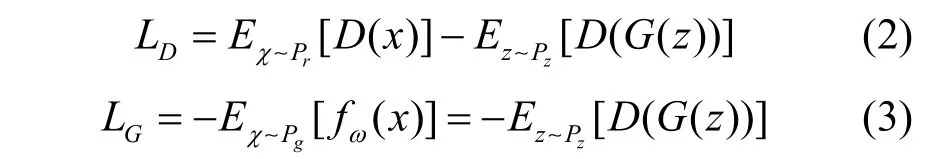
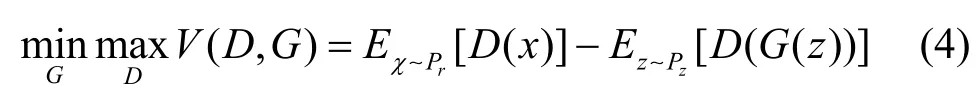
其中,G和D分别表示生成模型和判别模型,θ表示生成器的参数,ω表示判别器的参数。Pr、Pg和Pz分别表示真实样本分布、生成器生成样本分布和随机噪声分布。
WGAN 的训练是一个零和博弈的过程,生成器和判别器通过交替迭代训练,最终达到纳什均衡。训练判别器时,固定生成器的参数,将生成器生成的样本和真实样本作为判别器的输入,根据损失函数LD,更新判别器的参数并将梯度反向传播给生成器。每次判别器参数ω更新后将其按固定常数c的绝对值截断,将判别器的参数限制在固定范围内,即ω∈[-c,c]。训练生成器时,固定判别器的参数,输入一批随机噪声向量,然后输出虚拟数据,由判别器对生成的虚拟数据进行评估,根据损失函数LG更新参数和反传梯度。
1.2 API 调用特征表示
本文主要研究面向API 调用的恶意代码检测,通过获取应用程序的API 调用特征判断应用程序是否具有盗取隐私信息、恶意删除文件等恶意行为。定义一个应用程序API 特征集合S={s1,s2,…,sn}。将应用程序的API 调用特征映射为一个二值特征向量,若该应用程序包含API 调用si,则对应位置的特征向量元素值为1;若该应用程序未调用sj,则对应位置的特征向量元素值为0。
2 模型构建
为了增强恶意代码检测模型的稳健性和对抗样本识别能力,本文提出了对抗训练驱动的恶意代码检测增强方法。模型框架如图1 所示,主要由数据预处理、良性样本库构建、对抗样本生成和对抗训练组成。
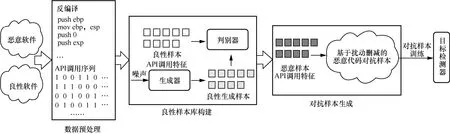
图1 对抗训练驱动的恶意代码检测增强模型框架
2.1 数据预处理
首先,使用反汇编工具对应用程序进行反编译,获取应用程序的API 调用特征。由于总体API数量较多,使用从恶意样本数据中提取的API 调用构建特征。同时,参考安卓开发者官网提供的API包索引名对提取的API 调用特征进行过滤。最后,采用卡方检验法降低特征维度,为每一个应用程序样本生成二值特征向量。
2.2 良性样本库的构建
WGAN 模型在一定程度上能够解决GAN 训练不稳定和模式崩溃导致生成数据多样性不足的问题。在构建良性样本库的过程中,基于WGAN 模型学习真实良性样本的特征分布,在满足真实样本分布的前提下,实现在真实良性样本基础上细微的变化,在一定程度上模拟良性样本的变种生成,进而提供更加丰富的扰动组合。
为了区分不同模块生成的样本,本文定义了不同的样本名称,具体描述如表1 所示。

表1 各模块生成样本的详细描述
在模型的结构设计方面,使用多层全连接网络构建WGAN 生成模型和判别模型,网络结构分别如图2 和图3 所示。

图2 生成模型的网络结构
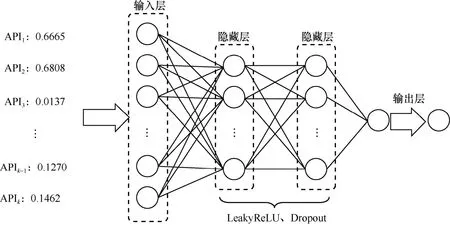
图3 判别模型的网络结构
生成模型由一个输入层、2 个隐藏层和一个输出层组成。输入层的输入向量为服从标准正态分布的随机噪声向量。隐藏层使用非线性函数ReLU 作为激活函数,能够减少计算量和降低过拟合。输出层使用的激活函数为Sigmoid。
判别模型由一个输入层、2 个隐藏层和一个输出层组成。输入层的输入来自真实样本。不同于生成模型使用的激活函数为ReLU,判别模型的隐藏层使用的激活函数为LeakyReLU。并且,在每个隐藏层后各添加一个Dropout 层,防止模型过拟合。
2.3 对抗样本生成和对抗训练
本文采用模拟对抗样本攻击的方式,通过对恶意代码添加扰动生成对抗样本,达到绕过目标检测器检测的目的。其中,攻击者的能力设定为攻击者掌握了目标检测器所使用的算法和特征集合,但是无法获取检测器的训练数据;攻击者通过增加API调用的方式修改恶意软件;攻击者只能查询目标检测器预测的类别。
由于恶意代码的特殊性,直接从原始恶意代码中删除一个特征可能会导致恶意功能消失,甚至程序崩溃。为了保留恶意代码的原始功能,只对原始样本添加API 调用,不删除或修改原本存在的特征。对抗样本的生成流程如图4 所示。
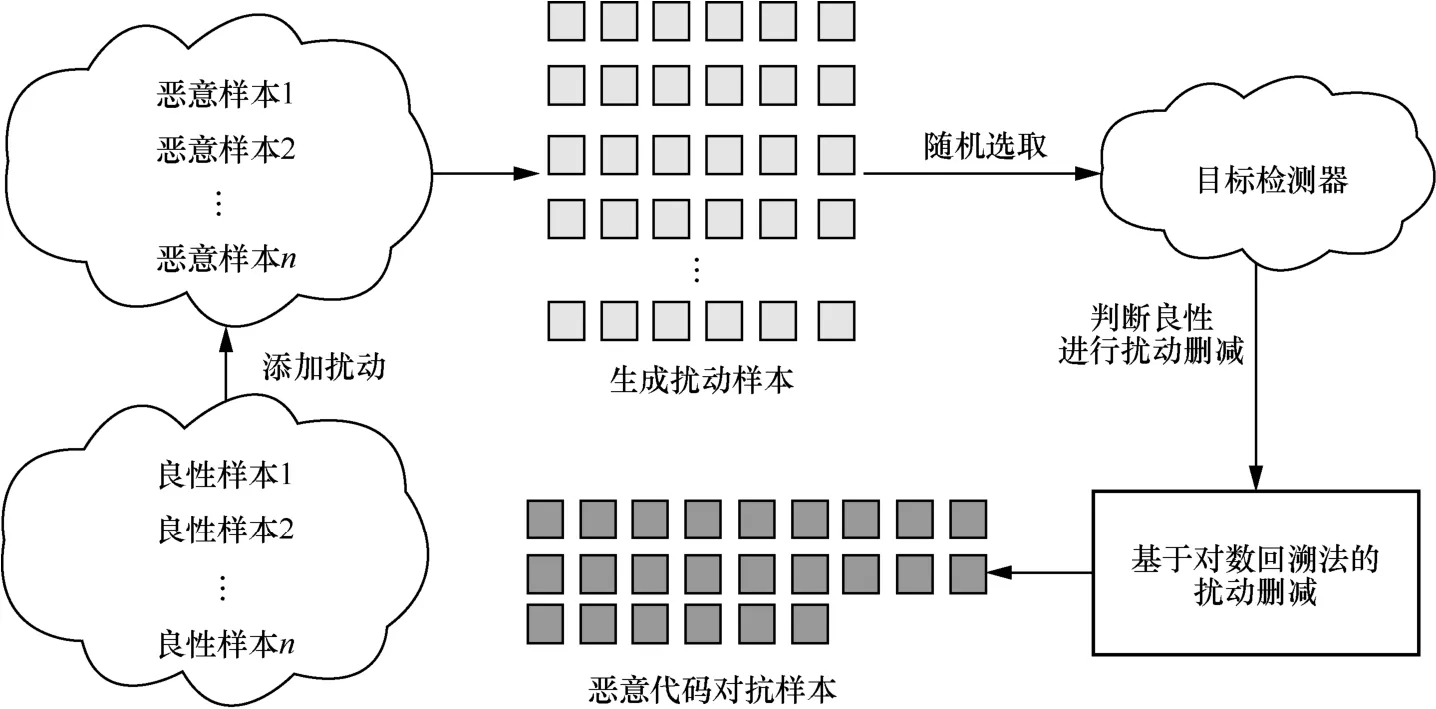
图4 恶意代码对抗样本生成流程
首先,将良性样本库中的样本以扰动的形式添加进恶意样本中,以躲避恶意代码检测器的检测。扰动方式如式(5)所示。
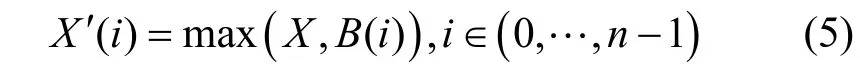
其中,X为原始恶意样本,B(i)为良性样本库中的第i个样本,X'(i) 为对应的添加扰动后的扰动样本,n为良性样本库的规模。max(·) 代表2 个特征向量间逐元素的或运算,若X的某一元素值为1,则X'(i)对应位置的元素值也为1,即保留恶意样本中的原始API 调用;若X的某一元素值为0,而B(i)对应位置的元素值为1,则X'(i) 对应位置的元素值也为1,即添加良性扰动。
其次,为了更加真实地模拟恶意代码制作者的攻击思路,本文从攻击者的角度出发,使用对数回溯法进行扰动删减,实现以较少的查询次数和较少的扰动数量生成恶意代码对抗样本。
最后,通过将生成的恶意代码对抗样本标注为恶意,扩充恶意代码检测器训练数据,完成检测器再训练,达到增强恶意代码检测器的目的。
3 基于WGAN 的良性样本生成算法
本文提出基于WGAN 的良性样本生成算法,WGAN 模型通过生成器和判别器之间的博弈训练,生成近似真实良性样本的数据。良性样本生成过程如算法1 所示。


首先,通过选择生成器生成的数据和真实样本来训练判别器,更新判别器的参数。然后,利用生成器生成的数据欺骗判别器,将判别器的判断结果反馈给生成器,并更新生成器的参数。通过生成器和判别器之间的博弈训练,生成器可以生成更真实的样本。
总之,在以后的工作中,辅导员老师不仅要加强对学生的心理关注,安全意识的灌输与教育,更要加强对重大事件危机应对措施的正确引导,使学生能够正确处理好自己的极端情绪,提升自身理性思考能力和调试能力,客观、正确地面对困难,解决困难!
由于样本数据是由0 和1 构成的二进制特征向量,而生成样本的数值介于0~1,需要对生成器的输出进行二值化处理。二值化处理如式(6)所示。

其中,oi为生成网络的输出向量的第i个特征值,bi为对应特征二值化结果。算法2 展示了二值化处理的过程。

运用算法1 和算法2,能够生成近似良性样本的生成样本,构建良性样本库,为恶意样本提供良性扰动。
4 基于对数回溯法的扰动删减算法
由于攻击者在攻击的过程中需要对检测器的结果进行查询,以判断攻击的有效性。减少查询目标检测器的次数可以防止被目标检测器发现其攻击行为而拒绝提供服务。攻击者在制作对抗样本时倾向于降低攻击成本、减少扰动数量和提高查询效率。为了从攻击者的角度模拟对抗样本的生成,提出基于对数回溯法的扰动删减算法,实现以较少的查询次数和较少的扰动数量生成恶意代码对抗样本。基于对数回溯法的扰动删减算法如算法3 所示。


对数回溯法是一种与二分查找思路相似的方法。二分查找法假定原始数据是一个有序的状态,通过数据的中间值与目标值的对比选取执行方向。而在本文中,对数回溯法面向的数据是API 调用列表,是一种无序的数据。本文模仿二分查找的思路,在迭代过程中,将原始数据随机减少一半。
首先,选取可以躲避恶意代码检测器的扰动样本,计算扰动集。然后,随机减少一半的扰动,加入恶意样本进行查询,并记录当前删除的扰动集。如果查询结果为良性,则重复进行此过程,直至检测器结果为恶意,交换删除数据和当前保留数据,重复上述迭代过程。若交换数据后查询结果仍为恶意,则恢复移除数据的一半数据进行查询,重复迭代,直至检测器结果为良性。当前数据集为删减后所得API。
5 实验
5.1 数据集
实验使用了2 个数据集,一个是安卓平台应用程序的数据集(后文简称为安卓数据集),一个是Windows 可执行应用程序的数据集(后文简称为Windows 数据集)。
安卓平台应用程序的数据集包含2 932 个恶意样本和2 165 个良性样本。其中,恶意样本来自开源恶意程序样本库VirusShare。良性样本来自小米应用商店,并且所有的良性样本都经过VirusTotal 平台的检测。VirusTotal 是一个在线检测平台,它通过将文件分发给多种反病毒引擎进行扫描,扫描结果准确率优于单一产品扫描,具有较高的可靠性。
Windows可执行应用程序的数据集为天池阿里云安全恶意程序检测比赛数据,包含8 909 个恶意样本和4 978 个良性样本。数据来自文件(Windows可执行程序)经过沙箱程序模拟运行后的经过脱敏处理的API 指令序列。
5.2 实验设置
实验选取随机森林(RF,random forest)、逻辑回归(LR,logistic regression)、决策树(DT,decision tree)、支持向量机(SVM,support vector machine)和多层感知器(MLP,multilayer perceptron)作为目标检测器,验证本文提出的对抗训练驱动的恶意代码检测增强方法的有效性。首先通过对良性样本和对抗样本进行评估,验证对抗样本生成方法的有效性;然后通过对抗训练前后的检测器对比,验证对抗训练的有效性。
在生成对抗网络模型的构建中,生成模型的节点数设置为100-128-128-196,判别模型的节点数设置为196-128-128-1。WGAN 模型的实验参数如表2 所示。

表2 WGAN 实验参数
5.3 评价指标
5.3.1 生成模型的有效性评估
对于生成模型的有效性评估,使用模型生成样本的良性样本检测率作为评估指标,即生成样本被检测器判断为良性的概率,记作GEN_TPR,定义如式(7)所示。

其中,num(·) 为样本的数量,f(·) 为目标检测器对样本的预测结果。G为WGAN 的生成器,z为从标准正态分布的随机噪声向量。
5.3.2 对抗样本的有效性
对抗样本的评估包含攻击成功率和攻击成本这2 个方面。
攻击成功率也称为绕过率,即对抗样本成功躲避目标恶意代码检测器检测,被检测器识别为良性的概率,记作ASR,计算方法如式(8)所示。

其中,num(·) 为样本的数量,f(·) 为目标检测器对样本的预测结果;x为恶意样本,x' 为x经过扰动后的样本。
对于攻击成本,本文综合考虑了添加的扰动数量和检测器查询次数,计算方法如式(9)所示。

其中,cost 为攻击成本;p为扰动数量,即添加的API 调用数量;q为恶意代码检测器的查询次数,α和β分别为p和q的权重,本文设定扰动数量与查询次数占相等权重,即α=β=0.5。
5.3.3 对抗训练的有效性
恶意代码检测器性能的评估,采用模型准确率来衡量检测器的检测率,通过对抗训练前后的准确率对比,验证对抗训练的有效性。准确率的计算方法如式(10)所示。

其中,TP 表示正确检测的恶意样本数量,TN 表示正确检测的良性样本数量,FN 表示被判断为良性的恶意样本数量,FP 表示被判断为恶意的良性样本数量。
5.4 生成模型的有效性评估
在训练WGAN 模型的过程中,将生成器的输出样本进行二值化处理后,作为目标检测器的输入,计算良性样本检测率。
在安卓数据集中,实验选取5.2 节中的5 种目标检测器,计算不同训练次数下的良性样本检测率,实验结果如图5 所示。

图5 安卓数据集下WGAN 生成样本的良性检测率
在Windows 数据集中,实验选取DT、MLP 和LR 这3 种目标检测器,计算不同训练次数下的良性样本检测率,实验结果如图6 所示。
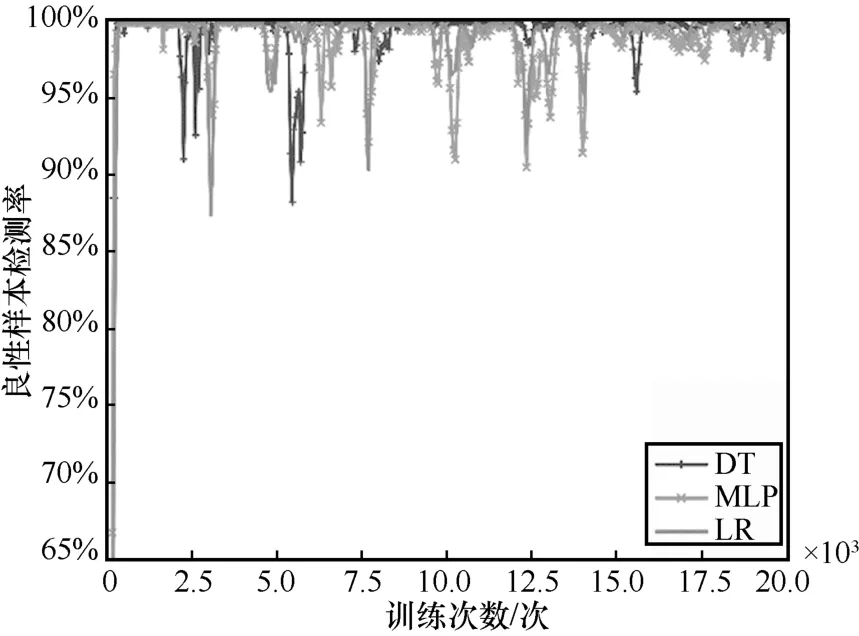
图6 Windows 数据集下WGAN 生成样本的良性检测率
由于WGAN 的训练过程是生成器和判别器的博弈过程,在迭代初始阶段,生成器还没有学习真实样本的分布,良性样本检测率较低,且存在较大波动,当生成器和判别器进行了多次博弈后,生成器模型生成更加满足真实样本分布的数据。
从图5 和图6 可以看出,安卓数据集在经过约12 500 次训练后,在不同的目标检测器下,良性样本检测率均在趋近100%处保持稳定。Windows 数据集在经过16 000 次训练后,生成样本的良性检测率维持在97%以上。基于WGAN 的生成样本较好地学习了真实良性样本的分布特征,在构建良性样本库上具有一定的有效性。
5.5 对抗样本生成结果评估
5.5.1 攻击成功率评估
在攻击成功率评估的实验中,对2 个数据集选取与5.4 节中相同的目标检测器进行实验。实验设置不同的良性样本库规模,评估恶意代码对抗样本的攻击成功率。图7 和图8 分别为面向安卓数据集和Windows 数据集的攻击成功率结果。其中,横坐标表示良性样本库的规模,纵坐标为恶意代码对抗样本攻击成功率。

图7 安卓数据集下不同良性样本库规模的攻击成功率
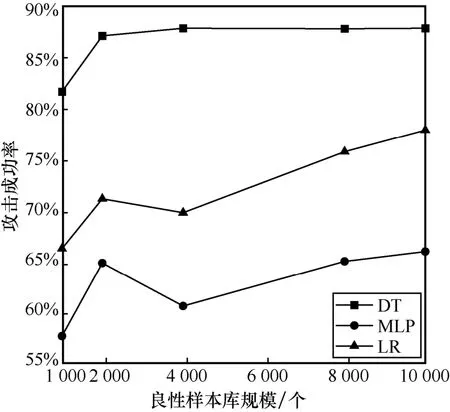
图8 Windows 数据集下不同良性样本库规模的攻击成功率
在安卓数据集中,当良性样本库规模大于2 000 个时,攻击成功率维持在一个相对稳定的状态,对抗样本具有较高攻击成功率。
在Windows 数据集中,MLP 的攻击成功率较低,但在良性样本库规模大于2 000 个时,仍达到60%以上的攻击成功率。在4 000~10 000 个的良性样本库规模中,攻击成功率呈现出一定的增长趋势。当良性样本库规模达到10 000 时,攻击成功率取得了较好的结果。
实验结果发现,当良性样本库规模为1 000 个时,2 个数据集下不同的目标检测器的攻击成功率均最低,过少的良性样本会影响当前对抗样本攻击方法的效果。当目标检测器为DT 时,2 种数据集都具有最高攻击成功率。决策树算法通过对训练数据进行分析,对特征生成规则,利用规则对新数据进行判断。本文的攻击方法通过向恶意样本添加扰动,容易对基于生成规则的决策产生干扰,达到攻击效果。
5.5.2 攻击成本评估
为了验证基于对数回溯法的扰动删减在扰动成本和查询效率上的有效性,本文对安卓数据集进行3 组实验,即实验1、实验2 和实验3,分别计算安卓数据集恶意代码对抗样本在不同良性样本库规模的攻击成本。实验1 按照扰动数量从小到大的顺序选取扰动样本,进行检测器查询,直到样本成功躲避恶意代码检测器的检测。实验2 按照扰动数量从小到大的顺序选取扰动样本,进行检测器查询,并对成功躲避恶意代码检测器的样本进行扰动删减。实验3 随机选取扰动样本,对成功躲避恶意代码检测器的样本执行基于对数回溯法的扰动删减。3 组实验统一使用RF 算法作为恶意代码目标检测器,评估在不同规模的良性样本库下,对抗样本生成的攻击成本,采用箱型图展示攻击成本结果,如图9~图11 所示,其中,▲表示数据平均值,●表示数据异常值。

图9 不同良性样本库规模的扰动数量
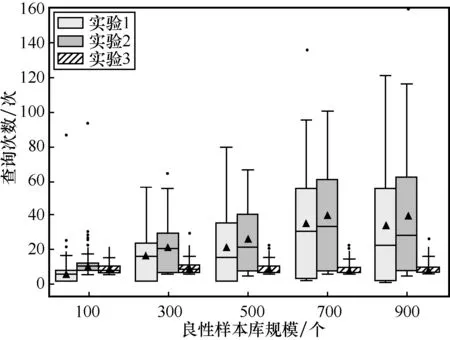
图10 不同良性样本库规模的查询次数

图11 不同良性样本库规模的攻击成本
在扰动数量上,3 组实验均受良性样本库规模的大小影响不大。实验1 是在文献[21]的对抗样本生成算法的基础上增加扰动样本的排序操作,扰动数量与文献[21]一致。实验2 在实验1 的基础上进行扰动删减,扰动数量最少。实验3 采取随机选取扰动样本的方式,扰动数量不稳定,跨度较大。从整体扰动数量的平均值看,3 组实验的扰动数量差距在5 个以内。
在目标检测器查询次数上,实验3 的查询次数最少。实验1 和实验2 的查询次数随着良性样本库规模的增加而增加,实验3 的扰动数量受良性样本库规模影响不大,始终保持较低查询次数。
本文通过理论分析,计算基于对数回溯法的扰动删减方法的查询次数。在进行扰动删减时,基于对数回溯法从最大的扰动集开始,不断从扰动样本中删除一半添加的扰动,直到样本被目标检测器错误分类,实现在尽可能少的查询次数内减少扰动数,当删减到只剩一个扰动且删减过程中每次迭代都需要交换保留集和删除集时,所需查询次数最多,设原扰动数为p,特征维度为k,则查询次数为2logp≤2logk。而在文献[21]的对抗样本生成算法中,对抗样本生成只关注扰动数量,并不关注查询次数,检测器查询次数等于良性样本库规模大小。
为了综合考虑扰动数量和恶意代码检测器查询次数,采用式(9)的攻击成本计算方法,实验结果如图11 所示。从图11 中可知,当良性样本库规模为100 个时,由于良性样本库规模较小,实验3 在查询次数上的优势并没有得到体现。并且,由于实验3 在选择扰动样本时具备一定的随机性,扰动数量存在一定的浮动,在良性样本库规模为100 个时,攻击成本的平均值略大于实验1 和实验2。在其他良性样本库规模中,实验3 的攻击成本最小,且实验3 的攻击成本不受良性样本库规模的影响。
在安卓数据集中,当良性样本库规模大于2 000时,攻击成功率维持在一个相对稳定的状态,对抗样本具有较高攻击成功率。为了验证本文方法对于不同分类器具有通用性,选取5.2 节中的目标检测器进行实验,在良性样本库规模为2 000 个的条件下,计算对抗样本生成的扰动数量与查询次数,结果如图12 和图13 所示。
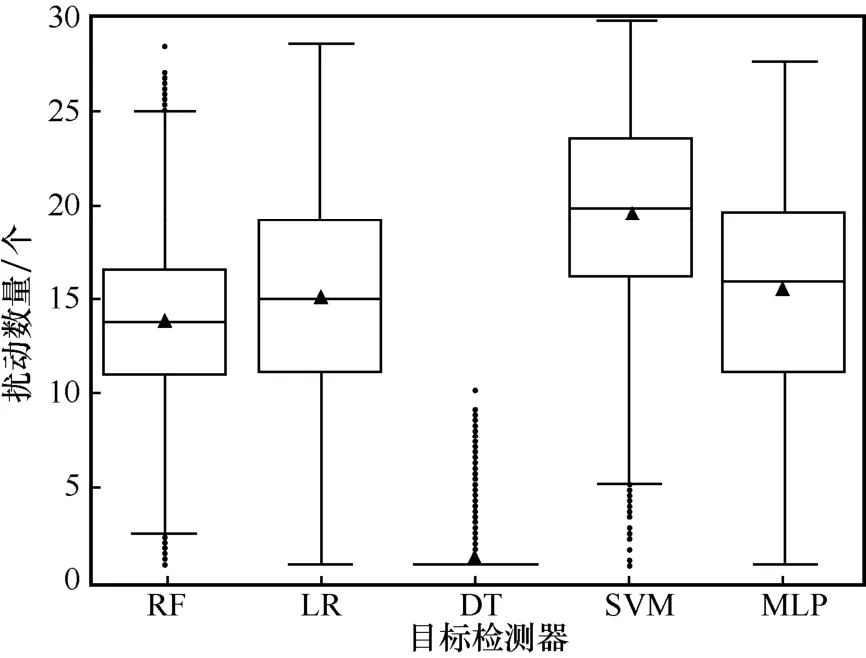
图12 不同目标检测器的扰动数量
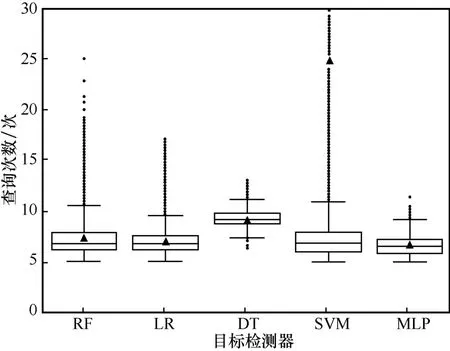
图13 不同目标检测器的查询次数
实验结果表明,本文提出的基于对数回溯法的扰动删减算法能够以较小的扰动数量和查询次数,躲避多种恶意代码检测器的检测,对不同的恶意代码检测器具有一定的通用性。
结合图7 和图12 中安卓数据集不同目标检测器的攻击成功率和扰动数量实验结果可以发现,具有最高攻击成功率的DT 检测器对应的平均扰动数量最少,而具有最低攻击成功率的SVM 检测器对应的平均扰动数量最多。检测器的对抗攻击难度与对抗样本扰动数量具有一定的正相关性。
在查询次数方面,各目标检测器模型没有体现出明显的差距,攻击过程中的检测器查询次数集中在5~10 次,具有较高的查询效率。
5.5.3 对抗样本的有效性评估
对于安卓应用程序,本文通过在反汇编文件中文件中插入扰动API,并利用工具对文件进行重打包和重签名。
以恶意 APK“VirusShare_ffb376be1e8d8311d 320f7a107caee9a”为例,利用本文提出的对抗样本生成算法,得到扰动API,在反汇编文件中添加扰动API 调用代码,并进行重打包和重签名。最后,利用VirusTotal 对扰动生成的APK 进行检测,实验结果表明,与原始恶意样本相比,将扰动生成的对抗样本识别为恶意文件的反病毒引擎数量减少了10 个,验证了本文所提出的对抗样本生成的有效性。
5.6 对抗训练结果评估
为了验证对抗训练对恶意代码检测器的增强作用,本文对2 组数据集分别进行4 组实验。首先,计算原始目标检测器的准确率,并对目标检测器进行对抗攻击。然后,将生成的对抗样本加入恶意代码检测器进行对抗训练。最后,再次攻击对抗训练后的检测器。
2 个数据集对抗训练前后检测器的准确率如表3 和表4 所示。其中,D 为初始检测器,DAT为对抗训练后的检测器。对D 和DAT检测器进行对抗样本攻击模型分别表示为AE1和AE2。表5 和表6为对D 和DAT检测器进行对抗攻击的攻击成功率,即AE1和AE2的攻击成功率。

表3 对抗训练前后检测器的准确率(安卓数据集)

表4 对抗训练前后检测器的准确率(Windows 数据集)

表5 对抗训练前后对抗攻击成功率(安卓数据集)

表6 对抗训练前后对抗攻击成功率(Windows 数据集)
从表3 和表4 可知,对于不同的目标检测器,在经过对抗训练后,检测器的准确率大都得到了一定的提升。结果表明,通过加入生成的恶意代码对抗样本进行对抗训练,提升了目标检测器的恶意代码识别能力。
从表5 和表6 可知,对抗训练后的恶意代码检测其攻击成功率明显低于原始恶意代码检测器。结果表明,通过对抗训练,恶意代码检测器识别对抗样本的能力有明显提高,提高了模型的抗干扰能力,增强了模型的稳健性。
6 结束语
针对机器学习模型的脆弱性问题,对恶意代码检测模型的增强方法展开了研究,提出了对抗训练驱动的恶意代码检测增强方法。首先,基于WGAN构建面向API 调用的良性样本库,以扰动的形式添加进恶意样本。然后,基于对数回溯法进行扰动删减以降低攻击成本。最后,基于主动防御思想将生成的对抗样本用于恶意代码检测器的重训练,提高恶意代码检测器防御对抗性攻击的能力。实验表明,本文提出的恶意代码对抗样本生成方法能够以较低的扰动成本和较少的查询次数生成具有较高躲避率的恶意代码对抗样本。通过生成的恶意代码对抗样本来丰富恶意样本库,重训练恶意代码检测模型,能够达到增强模型稳健性和提高模型检测率的效果。
在未来研究工作中,将进一步对本文方法进行改进和完善。一方面,针对对抗样本生成攻击成本最小化问题进行优化,考虑多个因素对攻击成本的影响并赋予合适的权重。另一方面,进一步探索基于代码混淆技术和躲避动态恶意代码检测模型的对抗样本生成方法。
