融合黑客论坛文本主题和情感的DDoS预测模型
2022-10-09王志英葛世伦
王志英, 戴 瑶, 葛世伦
(江苏科技大学 经济管理学院,镇江 212100)
分布式拒绝服务(distributed denial-of-service,DDoS)攻击是指黑客通过傀儡主机,消耗攻击目标的计算资源,阻止为合法用户提供服务[1].近年来,DDoS攻击事件层出不穷,严重威胁网络安全的稳定,因此,针对DDoS攻击的防御显得尤为重要[2].目前对于DDoS攻击的防御研究主要集中在DDoS攻击的事后检测.然而,恶意流量在DDoS攻击开始后才发生,这种事后检测对减少攻击造成的损失有限.在实践中,工业界通过部署更多的动态防御系统以提高对DDoS攻击的防范弹性,但成本也会随之增加[3].如何将DDoS事后检测转换为事前预测防御得到了学者们的关注,现有研究指出黑客发表在Twitter等社交媒体上的文本信息对于预测DDoS攻击事件具有较高的参考价值[4],但这些研究主要以Twitter等社交媒体上的文本情感作为预测依据,而融合主题和情感的预测准确率更高[5].作为黑客社交媒体主要平台之一的黑客论坛中存在着黑暗行为的一面[6],因为一部分黑客通过黑客论坛帖子交流分享黑客工具,并传授网络攻击教程,文献[7]提出将注意力转向黑帽黑客,因此,融合Twitter等之外的黑客论坛文本的主题和情感来预测DDoS攻击趋势是防御DDoS威胁的新颖且有意义的方式之一[8].因此,文中通过挖掘黑客论坛帖子文本的主题和情感,建立DDoS攻击的多元自回归移动平均预测模型,为DDoS预测研究提供一种新思路,并为信息安全管理提供未来一段时间DDoS攻击可能性趋势,进而有针对性地制定DDoS攻击的防御管理策略.
1 融合主题分类和情感分析的DDoS攻击预测模型的构建
1.1 预测模型框架
文中提出一种基于黑客论坛帖子文本的DDoS攻击预测模型,融合黑客论坛帖子的主题和情感分析,以提高现有研究仅基于情感预测的准确率,实现预测攻击趋势的有效性和准确性,模型框架如图1.
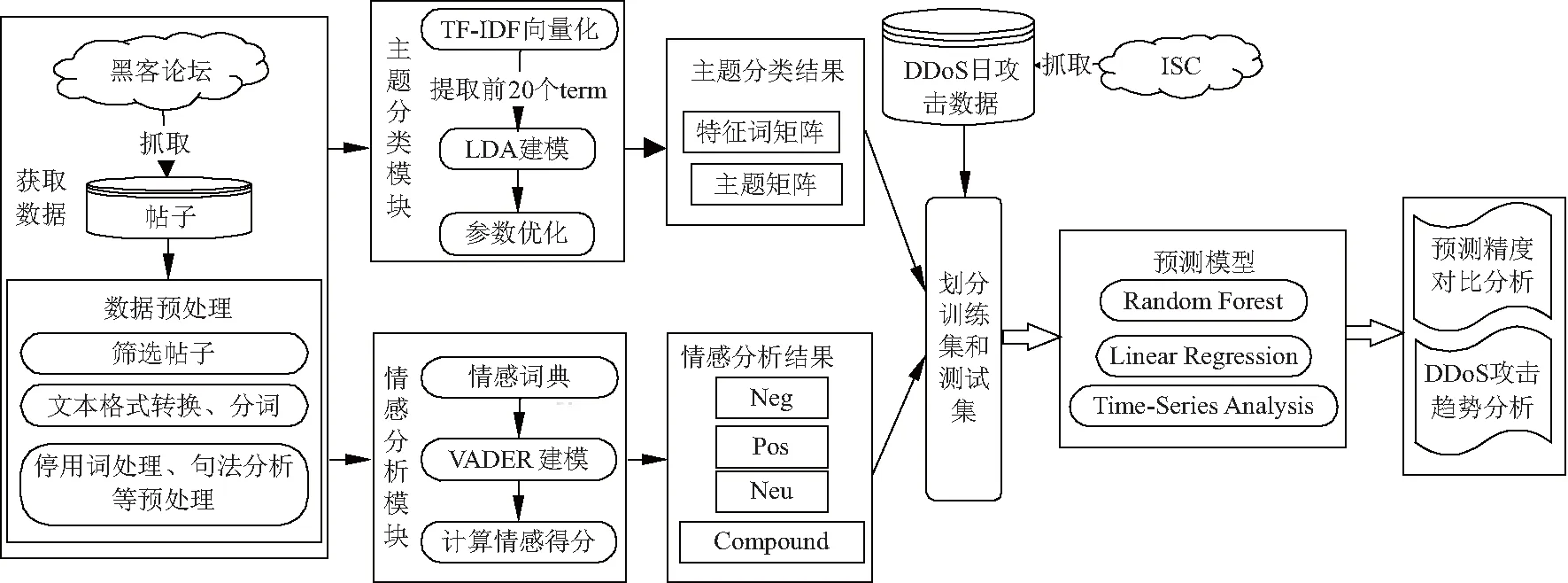
图1 模型框架
图1构建的模型框架的具体步骤如下:
(1) 帖子数据获取.文中的数据集主要包括两部分:黑客论坛的帖子数据和DDoS日攻击数据,首先利用后羿采集器获取Hack Forums论坛中Hacking Tools and Programs子版块下帖子的信息,接着登录审计网络安全(sysAdmin andit network security,SANS)研究所的互联网风暴中心(internet storm center,ISC)获取有关DDoS日攻击数据.
(2) 数据预处理.预处理主要包括文本格式转换、停用词及去除无用字符、表情等,为后续主题分类和情感分析做好基础.
(3) 主题分类和情感分析.利用LDA主题模型对收集得到的帖子文本数据进行主题分类,识别不同类型的黑客工具的主题及其时序变化;利用情感词典计算论坛帖子的情感得分,并得到不同情感类型的时序变化.
(4) DDoS攻击预测模型建立与分析.将上一步主题分类结果和情感分析结果作为特征变量带入,并进行模型参数设置、时间窗口设置、训练数据集等处理,提高预测模型的准确性.
(5) 预测精度对比分析与DDoS攻击趋势分析.通过与不同预测模型和特征选取的对比分析,验证所提预测模型的准确性.
1.2 黑客论坛文本主题分类模型构建
文中建立了基于黑客论坛文本的LDA主题分类模型.LDA算法是一个变参数的三层贝叶斯模型,用一个服从Dirichlet分布的K维(K个主题数)隐含随机变量表示文档的主题概率分布,模拟文档的生成过程[9].设第m个帖子中DDoS攻击主题多项式分布θm、第k个DDoS攻击主题的词语多项式分布φk均服从Dirichlet分布,分布函数为:
(1)
由LDA模型的生成过程可知,模型很难直接获得两个Dirichlet分布θm和φk,一般采用间接推理算法来估算模型的参数值.文中利用Python的sklearn库中的在线变分推断期望最大(expectation-maximization,EM)算法,在其基础上为了避免帖子内容过多而实现了分步训练,即一次训练一小批帖子,逐步更新模型,最终得到所有黑客论坛帖子文本的LDA模型.
1.3 黑客论坛文本情感分析模型构建
由于黑客论坛中的帖子具有简短和口语化的特点,且部分网络词语具有很强的情感色彩,利用基于词典和规则的情感分析(valence aware dictionary for sentiment reasoning,VADER)模型用于判定论坛帖子的情感倾向和计算论坛帖子的情感得分.对于一个基于情感词典的模型来讲,VADER的核心由两部分组成,一是情感词典的构造;二是语法规则的生成.相较于单纯的词典查找,VADER包含了5条可通用的语法规则:
(1) 标点符号.在文中一些标点符号能够显著影响句子的情感倾向,如感叹号.
(2) 全部字母大写的单词.全部字母大写的单词相对于小写字母单词来说在不改变句子情感极性的基础上具有较强的情感倾向.
(3) 程度修饰词.程度修饰词能够显著影响句子的情感倾向,如:“extremely”.
(4) 转折词.如转折词“but”通常意味着情感极性的转变,其后的情感词是主要的情感极性.
(5) 检查情感词之前的3个词是否为否定词.
基于以上语法规则,VADER的得分范围从-1.0(最积极)~1.0(最消极).因为不需要大量的训练数据,VADER被广泛应用到解码和量化文本、音频或视频等社交媒体中的情感得分[10].
1.4 融合黑客论坛文本主题分类和情感分析的DDoS攻击预测模型
融合黑客论坛文本主题分类和情感分析的DDoS攻击预测模型,采用多元自回归移动平均(multivariate auto regressive integrated moving average model-X,ARIMAX)模型作为参考.ARIMAX 模型为经典的时间序列分析模型,该模型改进了移动平均自回归(auto regressive integrated moving average,ARIMA)模型无法考虑影响变量而造成的模型不完整和不能准确表达多个时间序列之间的变化规律等问题,因此被广泛应用到有关时间序列的预测中.
ARIMAX模型假设响应序列(即DDoS日攻击量){yt}和输入序列xt包括两部分,xt=(x1t,x2t)T,即每日黑客论坛文本的主题分类结果{x1t}和每日黑客论坛文本的情感得分{x2t}均平稳,构建响应序列和输入变量序列的回归模型为:
(2)
式中:Θi(B)为第i个输入变量的移动平均系数多项式;Φi(B)第i个输入变量的自回归系数多项式;li为第i个输入变量的延迟阶数;{εt}为DDoS日攻击量的回归残差序列;Θ(B)为DDoS日攻击量的残差序列移动平均系数多项式;Φ(B)为DDoS日攻击量的残差序列自回归系数多项式;at为零均值白噪声序列.
利用基于R Squared和对称平均绝对百分比误差(symmetric mean absolute percentage error,SMAPE)作为模型预测评级指标,计算公式为:
(3)
(4)
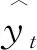
SMAPE的范围是[0,2],若其越靠近0则表示模型预测性能越好;反之,越差.RSquared的范围是[0,1],当RSquared=1时,即DDoS攻击量预测值和真实值之间的误差最小;RSquared值越大则表示模型预测性能越好;反之,越差.
2 数据获取及预处理
2.1 数据源
文中数据集包括两部分:黑客论坛帖子文本以及DDoS日攻击数据.其中,帖子信息来源为HackForums论坛的Hacking Tools and Programs子版块,利用后羿采集器获取一段时间的论坛帖子的信息.采集的论坛帖子的时间范围为2018年4月23日—2020年7月20日,爬取的帖子总数为38 530条.
2.2 预处理
通过后羿采集器爬取的帖子数据内容混杂,如表情、字符、其他对文本分析无意义的符号等,故需对帖子进行筛选以提高后续预测的精度.首先,从互联网上获得大量与DDoS攻击相关的文章,比如有关DDoS攻击所涉及的技术和工具;然后,去掉常见的停顿词,如the、is、at、on以及类似的其他停顿词,并对得到的关键词按频率排列;接着,将帖子分成两组,分别为候选组和无关组,其中,候选组帖子数16 869,筛选出的讨论DDoS的帖子6 615,无关组帖子数21 661,筛选出的讨论DDoS的帖子数为4 356.根据以上步骤逐步筛选,最终得到10 971条讨论DDoS攻击的帖子.
DDoS日攻击数据信息来源为SANS研究所的互联网风暴中心(Internet Storm Center,ISC)数据库.DDoS日攻击数据具体如图2.
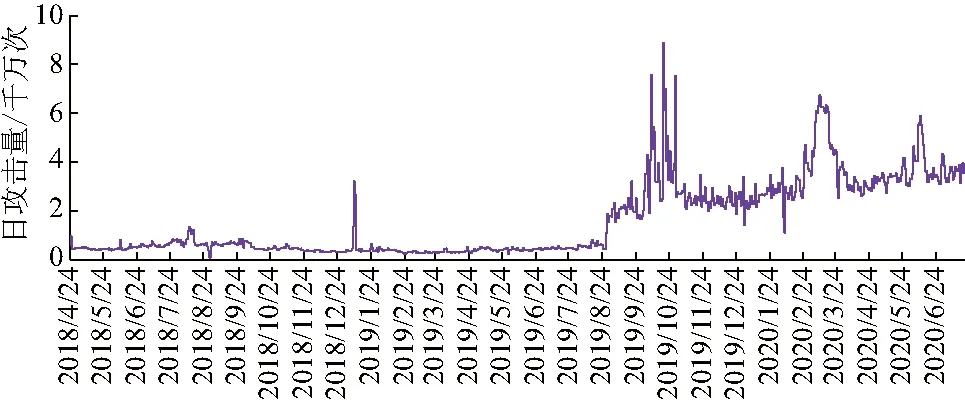
图2 DDoS日攻击量
由图2可知,2018年整体攻击量趋势保持平稳,直至年末,DDoS日攻击量达到全年最大值.据报道2018年12月份各大国内外银行都遭受不同程度的DDoS攻击,因此攻击量较年初显著增大.2019年下半年,DDoS日攻击量持续攀升,且规模比2018年显著增大.相较于2018年,近几年DDoS的攻击量大幅度攀升,尤其是2020年10月出现了该年攻击量的峰值.
3 预测结果分析
3.1 主题分类结果
文中选用机器学习、情感词典分别对采集到的帖子文本进行主题、情感的分析,利用Python的sklearn库建立LDA主题模型训练得到主题分类结果,参考以往的主题研究模型,最终拟定主题个数为5,得到的主题-关键词分布如表1.

表1 主题-关键词分布
每日各主题的帖子变化情况如图3.
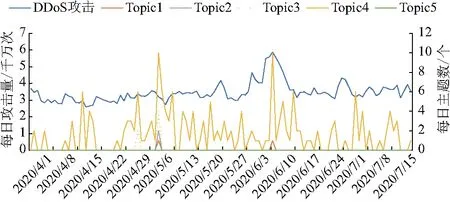
图3 主题分类结果
由表1和图3可知,Topic4在所有帖子的主题中占比最大,且每日的主题变化较大,Topic5的占比最小.其中,当黑客论坛的讨论主题(如Topic5)中包含skype、github等新关键词时,其后续讨论对DDoS的攻击量并没有太大影响;而当黑客论坛的讨论主题(如Topic4)中包含source、tool、code等关键词时,黑客的后续讨论对可能会对DDoS的攻击量造成影响.
3.2 情感分析结果
利用Python的VADER Sentiment Analysis包计算得到论坛帖子的每日情感得分,结果如图4.

图4 情感得分结果
由图4可知,积极和中性的情感得分较消极的情感得分波动幅度较大,而消极的情感得分主要集中在0~0.2.
3.3 预测模型建立与效果对比
鉴于DDoS攻击量的时序化特征,建立融合论坛帖子主题和情感的ARIMAX模型预测DDoS攻击.为了验证建立模型的预测准确性,选取其他预测模型与其模型进行对比,包括:随机森林(random forest,RF)、线性回归(linear regression,LR)和ARIMA.现有的DDoS攻击预测方法,基于机器学习的预测模型具有较大的优越性,其中,随机森林由于其较好的泛化性能且不易过拟合等优点被广泛应用到预测模型中[11].因此,文中采用随机森林进行DDoS攻击预测研究,参考文献[12],建立基于黑客论坛文本情感的随机森林预测模型与之对比.同时,参考了不考虑其他特征的ARIMA时序模型[13].预测结果如表2.ARIMAX模型和LR模型预测的效果整体优于RF模型和ARIMA模型,RSquared值较高,且SMAPE值较低;通过特征选择的纵向对比,融合主题分类和情感分析的各模型预测效果优于仅基于主题或情感的各模型.通过不同预测模型和不同特征选择的预测结果对比,即RSquared值和SMAPE值的对比,建立的融合主题分类和情感得分的ARIMAX预测模型RSquared值最接近1,且SMAPE值最小,即预测值与真实值之间的离散程度较小,预测更精确、有效.

表2 预测结果对比
将融合主题分类和情感分析两种特征的不同DDoS攻击各模型预测结果如图5,其中,随机森林模型(Model_RF)表示融合主题分类和情感分析的随机森林预测模型,线性回归模型(Model_LR)表示融合主题分类和情感分析的线性回归预测模型.
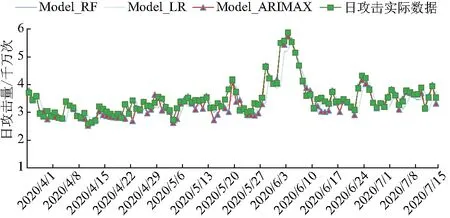
图5 融合主题和情感各模型的预测结果
在图5所有在带入主题分类和情感分析的预测模型中,相较于单纯基于主题分类或情感分析的DDoS攻击预测,两者融合的各模型预测值和实际值的拟合度都很高.其中,ARIMAX预测模型相较于其他模型与实际DDoS攻击量拟合效果最为接近,结合表2的结果也可知,该模型预测误差值最小,具有较好的预测效果.相较于ARIMA模型和单纯只选取其中一项输入变量的预测模型相比,融合主题和情感作为输入变量的预测效果上有显著提升.因此,认为针对黑客论坛的帖子文本,主题和情感两者能够提供更完整的特征信息,对实际的DDoS攻击预测也具有更高的参考价值.
4 预测模型的应用
根据不同模型和不同特征选择的预测结果对比,最终采用融合主题分类和情感分析的ARIMAX预测模型进行DDoS攻击预测.文中模型的测试集是2020年4月1日—2020年7月20日,应用该模型预测2020年下半年的DDoS攻击,结果如图6.
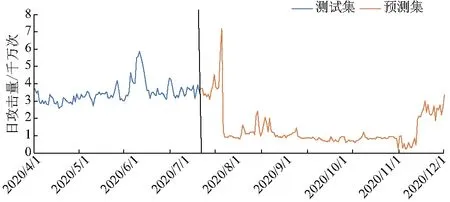
图6 DDoS攻击预测结果
根据图6的预测结果显示,2020年下半年DDoS的攻击量会小幅度减少,直至年末出现上升趋势.因此,建议信息安全管理人员在年底前采用更动态、成本更高的网络威胁检测配置;而在此之前,即大规模的DDoS攻击可能性不大时,可以降低防御级别,以达到成本效益最大化.
5 结论
利用数据挖掘和机器学习方法,基于黑客论坛帖子文本的主题和情感进行分析,并建立DDoS攻击的ARIMAX模型,研究结论如下:
(1) 融合主题分类和情感分析的DDoS预测更具有参考价值.从文本挖掘的角度出发,针对帖子的文本主题、文本情感以及两者结合分别构建了DDoS预测模型,从预测结果的精度指标来说,建立的ARIMAX模型在融合主题和情感的特征选择上具有更好的预测效果.对实际的DDoS攻击预测也具有更高的参考价值.
(2) 主题的后续讨论对DDoS的攻击有较大影响.针对筛选出的帖子是黑客工具模块下每日有关DDoS攻击的讨论帖,在LDA主题建模中,主题中若包含write、rat、use、net、free、source、tool、code、port、ip和dns等频次较高的关键词,其后续的讨论往往会增加DDoS的攻击量.若主题中包含skype等新关键词,其后续讨论则会减少DDoS的攻击量,这也验证了有学者提出的黑客论坛中用户的讨论可能隐藏着不同程度的安全隐患.
针对黑客论坛文本情感分析,文中仅采用情感词典这一种方式进行研究,将来可采用深度学习的方法提高文本情感识别的准确性.
