基于GAN的视频隐写算法
2022-09-30林洋平张明书陈培刘佳杨晓元
林洋平 , 张明书,2* , 陈培 , 刘佳 , 杨晓元,2
(1.武警工程大学密码工程学院, 西安 710086; 2.网络与信息安全武警部队重点实验室, 西安 710086)
隐写术是一种将秘密消息隐藏在载体信息中,使得攻击方无法知晓载体中是否含有秘密消息,从而达到隐蔽传输目的的秘密通信技术。它在公共服务、网络传输、军事通信等方面的应用非常广泛,相较于加密技术而言,因其具有的不可感知性,不易受到恶意攻击方的分析检测,是目前研究秘密通信领域的热门课题,在信息化条件下的军事通信拥有很高的应用价值[1]。
视频隐写术是应用于视频媒介的信息隐藏技术,视频中拥有比图像更多的冗余信息,它的嵌入容量和安全性有着更好的表现,随着5G高速网络的发展,大量视频媒介信息在互联网中迅速传播,载密视频很容易隐藏其中,因此视频隐写术在载体数量与传播安全性方面的优点日益突显。
原始载体在嵌入秘密消息后,会对载体原有的统计信息进行一定程度上的修改。因此在设计隐写算法时,通过某种修改策略使得嵌入后造成的失真减小,失真越小受到攻击者的恶意攻击概率越低[2]。
许多学者提出诸如预测模式[3]、DCT(discrete cosine transformation)系数[4]、运动矢量[5]等一系列基于压缩域的视频隐写算法。而人工构建最优修改策略在设计上是困难的,这需要对视频格式特点与统计信息进行详尽地分析,这也会加大隐写算法的设计难度。深度学习技术为隐写术的发展提供了一个新的思路,它无需人工对视频数据进行预先的特殊处理,只要合理地设计出网络的基本结构和相应损失函数,通过优化算法就可达到修改策略的最优化,理论上只要利用大量数据进行合理的训练便可达成此目标。基于卷积神经网络与生成式对抗网络的深度学习技术[6-7]的出现,为人们提供了一种新的方法。它在计算机视觉的传统领域诸如分类、超分、去模糊等的应用十分广泛,正是由于其优异表现,吸引许多研究学者的注意,通过结合目前已有隐写算法构架,将其作为隐写特征提取模块,减少隐写算法的人工设计难度。神经网络在图像与文本隐写领域中的应用十分广泛,已拥有许多重要的研究成果,但在视频隐写术中的应用目前还处于探索阶段,因而如何将神经网络与视频隐写术进行结合成为研究该领域的重要内容。
采用生成修改概率矩阵进行消息嵌入的方法,提出一种基于生成对抗网络的视频隐写算法。在视频生成对抗网络的基础上,设计一个隐写生成对抗网络,其包含一组隐写生成器与判别器,以生成最优修改概率矩阵。同时为了提高隐写生成器的性能,将视频生成网络生成的前景信息作为隐写生成器的输入,以便生成修改概率矩阵,而后将其传递给嵌入函数得到最优修改映射,进行秘密信息的嵌入。隐写判别器以载密与原始样本作为输入,将样本三个通道分别通过高通滤波器进行预处理,再利用三维卷积网络对载密和原始样本进行区分。经过隐写生成器与判别器之间的博弈对抗,以期于载密样本能误导判别器的正确判断。
1 隐写架构
1.1 隐写算法设计
在载体修改式隐写术的思想下,提出视频隐写算法(steganographic generative adversarial network, SGAN),其架构由两部分组成:视频生成对抗网络(SGAN-videonet, SGAN-VN)、隐写对抗网络(SGAN-stegonet, SGAN-SN),算法架构细节如图1所示。
隐藏算法的主要步骤如下:发送方在嵌入消息之前,将噪声Z作为视频生成对抗网络的输入,以生成载体视频G(z),载体视频由前景f(z)、后景b(z)

图1 隐写算法架构Fig.1 Steganographic structure of the proposed algorithm
与掩模m(z)组成。隐写对抗网络将前景作为输入,利用隐写生成器生成修改概率矩阵,通过最优二元嵌入函数自适应生成最优嵌入修改位置图,将秘密消息m嵌入到载体视频像素最低位中,得到含密视频。
接收方收到含密视频后,将视频发送方经过秘密信道传输的修改位置图作为提取参考,提取出载密视频中的秘密信息。
1.2 基于失真代价的隐写
基于修改载体的隐写算法中,设计架构的目标是使得隐写代价函数最小,以抵抗基于特征学习的隐写分析算法的攻击[8]。代价函数通常定义为
(1)
式(1)中:X=(xi,j)H×W与Y=(yL,j)H×W分别为原始载体样本与嵌入修改样本;ρi,j为修改i与j的所需代价。在这种思想的指导下,许多学者提出了相应的图像隐写算法,如S-UNIWARD(spatial universal wavelet relative distortion)[9]、HILL(high-pass, low-pass, low-pass)[10]等。针对将信息嵌入载体后会导致不同的样本属性改变,隐写算法通过设计的相应隐写代价函数,优化嵌入方式减少修改原始样本带来的隐性失真。然而,鉴于嵌入消息后带来的不同失真而设计相应代价函数难以实现,目前许多算法如ADSL-GAN(automatic steganographic distortion learning framework with GAN)[11]、UT-SCA-GAN(U-net, tanh-simulator, selection channel awareness, GAN)[12]等,利用CNN(convolutional neural networks)作为拟合代价函数的工具,引入基于神经网络的隐写分析算法,利用对抗模型中的博弈对抗策略,构成生成式对抗网络,通过二者之间博弈训练,使得嵌入消息带来的失真最小化。
1.3 双流视频生成模型
视频隐写术相对于图像隐写术来讲,直接将原始载体输入网络中,将会使得参数繁多并且数据复杂难以训练。因此在设计架构时,利用了双流生成视频模型能够生成视频运动信息的特点,本文提出通过将视频中的时空特征信息,作为隐写生成器的输入,以减轻生成器的训练成本。该视频生成模型不会直接生成伪样本,首先会利用噪声Z作为输入,生成代表视频信息中动态与静态的不同部分:前景f(z)、后景b(z),这两个部分分别对应现实世界中外界环境中的静止信息与动作信息,通过与掩模m(z)的组合控制来得到生成的伪视频,表达式为
G(z)=m(z)⊙f(z)+[1-m(z)]⊙b(z)
(2)
式(2)中:生成视频G(z)为利用噪声Z驱动合成的;m(z)为视频中的时空掩模,为不同的像素位置以及时间选择前景模型与后景模型进行匹配控制,⊙为Hadamard乘积。
而对于生成的视频任务,采用了基于DCGAN(deep convolutional generative adversarial net)的视频生成架构[13]。为了提高生成视频的清晰度与嵌入容量,将生成视频的分辨率从原始模型的64×64提高到128×128。
2 隐写对抗网络
2.1 生成器结构
本文设计的双生成对抗网络隐写架构中包含两个生成器:一个负责视频生成任务,基于DCGAN的视频生成网络;另一个负责嵌入修改概率矩阵的生成,称为隐写生成器。与图像隐写网络不同,视频信息流中主要包含两种类型的信息,除了空域信息以外,还包括时域信息。在图像空域隐写术中,较多采用分析单张载体图像的空域信息,进而生成修改概率进行隐写。视频信息往往是连续不断的序列信息,在静止空间与运动空间中都含有大量的冗余信息,可供进行信息的嵌入,但视频数据较图像而言,数据量更大且其特征提取网络更不易训练。
因此本文提出的架构中,直接将DCGAN所生成前景作为生成器的输入,利用卷积网络来提取前景的特征信息。在文献[12]中生成器的基础上,将二维卷积改为三维卷积网络,实现在时间维度中的采样,通过更深层的网络结构与大量对抗训练,得到一个针对视频时空冗余的概率修改矩阵。在这种架构中一共包含16层三维卷积层,前8层每一层包含一个1×5×5卷积核的三维卷积层,后接一个BN层,前8组采用的是LeakyReLU激活函数,后8组是ReLU激活函数与转置三维卷积层,最后一组的输出用sigmoid激活函数,使用sigmoid函数将卷积网络提取的特征映射,将其转换成数值在0~1的概率,为了防止修改概率过大而造成嵌入消息的安全性降低,对每个概率减去0.5,将区间控制在0~0.5。隐写生成器的具体结构,如表1所示。
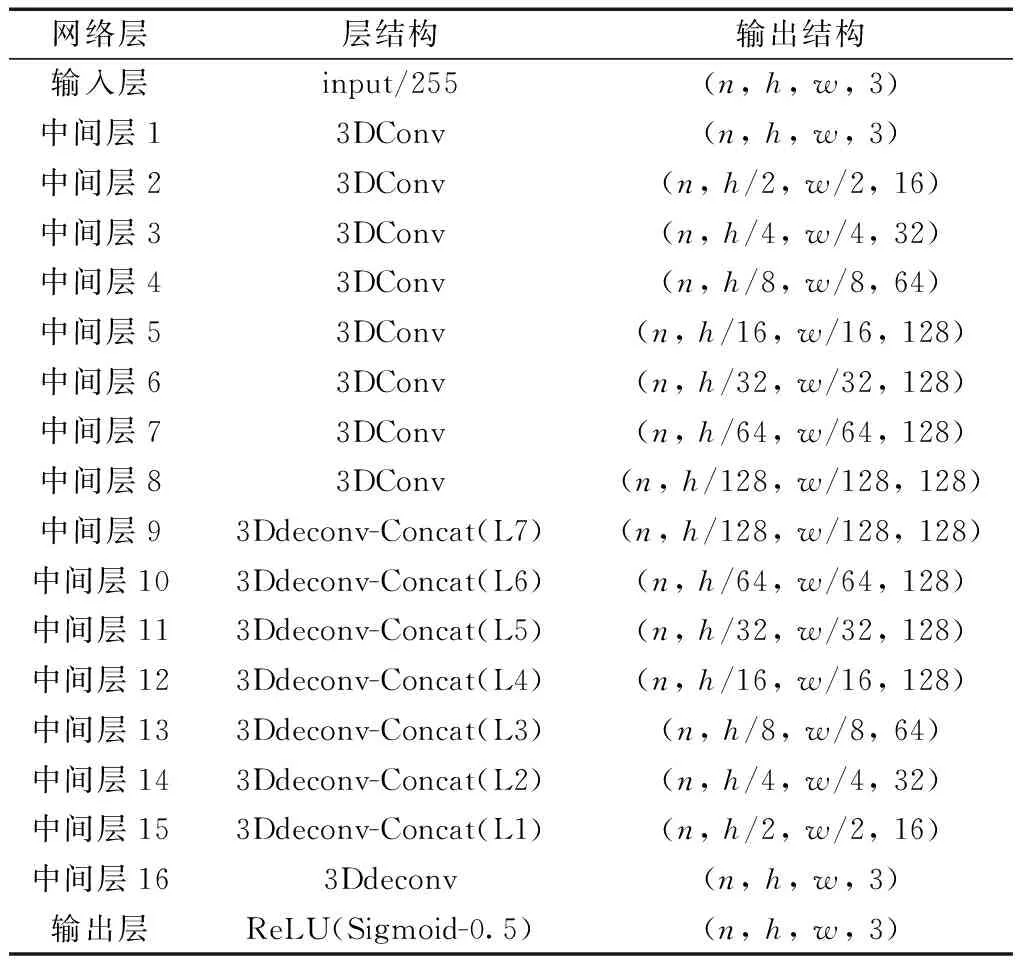
表1 隐写生成器结构Table 1 The structure of steganography generator
2.2 判别器结构
生成对抗网络中判别器主要用于判别生成样本的真假性,判别器的性能会直接影响到生成器所生成样本的质量,第一个GAN使用一个5层三维卷积网络,卷积核为3×3×3,步长为2,除了第五层卷积层后使用sidmiod函数以外,每一层卷积操作后都使用LeakyReLU作为激活函数。这样卷积层既可以学习视频背景中的统计信息,也可以学习物体运动的时空关系。第二个GAN中判别器是作为一个隐写分析器,经过博弈对抗训练过后,生成器生成的修改概率矩阵所对应的载密样本,强化抵抗隐写分析检测的能力。在Xu-Net的基础上,设计一个基于三维卷积的视频隐写分析器,将其作为视频隐写对抗网络的判别器。Xu-Net是文献[14]中提出的灰度图像隐写分析模型,考虑到视频信号的时空维度与通道数目,为了将其用于彩色三通道载密视频帧的分析检测,将高通滤波器在时间维度与通道维度中进行拓展,分别对每一帧的图像三个通道进行处理,最后合并为一个通道数目为18、时间维度为32的特征图,以便于处理连续的视频信号,而后将其所得残差特征输入一个6层三维卷积网络中分析其时空特征,根据激活函数把时空特征映射为识别概率值,通道间的处理过程如图2所示。
2.3 损失函数
在训练过程的两个阶段中分别训练两个对抗网络,二者的判别器在结构设计上存在着差异,但共同将网络输出的标签信息作为衡量判别器性能的
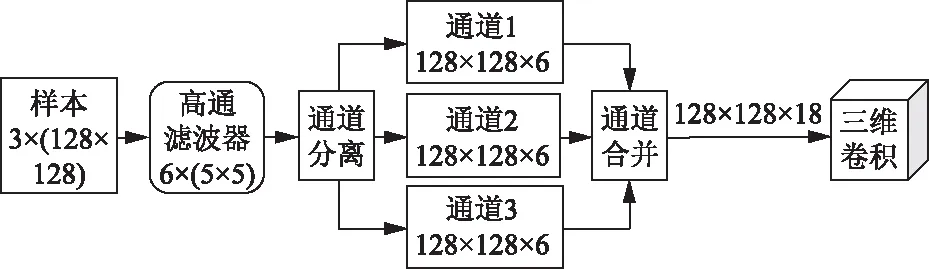
图2 通道的分离与合并Fig.2 Channels separation and merge
关键参考信息,对此将两个判别器的损失定义为
(3)
式(3)中:y′为判别器中激活函数输出;y′i则为判别器对载体样本与嵌密样本的分类标签。对于生成器的损失函数,将其定义为
lG=-αlD+β(C-3NHWQ)2
(4)
C=C1+C2+C3
(5)
式中:NHWQ为训练之前设定的期望载荷。在两个阶段的训练中,第一阶段将参数β设定为0,参数α设定为常数1;而在下一阶段中,会对实际训练需求进行参β的合理设定,以保证目标函数的最优化,本文中参数β设置为10-71。Ck为嵌密样本三个通道中的秘密消息载荷,将其定义为

(6)
(7)
(8)

2.4 最优嵌入函数
视频隐写算法在得到修改概率矩阵之后,需要得到相应的嵌入修改位置图来进行秘密消息的嵌入,而这里的嵌入修改位置图是通过式(9)所示最优嵌入模拟器生成的[15]:
(9)
式(9)中:pi,j为嵌入变化概率;ni,j为0~1均匀分布产生的随机数;mi,jmi,j为嵌入值。但该函数不能在实际训练中生成网络的梯度反向传播传递梯度,导致训练时间过长。为了解决上述嵌入函数不连续的问题,引入了一个基于tanh函数的最优嵌入激活函数[12],即
m′i,j=-0.5tanh[λ(pi,j-2ni,j)]+
0.5tanh{λ[pi,j-2(1-ni,j)]}
(10)
(11)
式中:λ为缩放因子,控制函数在阶梯状态中变化的坡度,不同缩放因子对应函数的变化,如图3所示。

图3 不同缩放因子下的嵌入函数Fig.3 Embedding functions with different scaling factors
3 实验结果与分析
3.1 数据集与实验设置
实验环境为window10操作系统下的tensorflow1.15深度学习构架,所用实验仪器的显卡型号为英伟达GTX TITAN XP,CPU型号为INTEL Xeon E5-1603,内存为16 GB。所有的实验都是在UCF101数据集上进行的,UCF101是一个现实动作视频的动作识别数据集,收集自YouTube,提供了来自101个动作类别的13 320个视频,其大小为320×240,在深度学习领域用于视频的动作识别数据集。从UCF101数据集中随机抽取500段视频,作为视频生成网络的训练视频。为了匹配实验所需的视频大小,利用基于python的skimage工具包将其转化为大小为128×128的视频。
实验中生成对抗网络的训练分为两个阶段,首先训练第一个生成网络使其可以生成符合自然语义的伪视频,经过3 000轮的迭代训练后,再训练第二个生成网络负责嵌入修改矩阵的生成,对其训练共800次。对于第一个网络中的训练采用的是,训练一次生成器后,进行一次判别器的训练。训练中使用学习率为0.000 2的Adam优化器来训练模型,对每个批次视频样本训练3 800次,共500次迭代。
3.2 实验结果
3.2.1 视频生成对抗网络性能
当经过3 000轮的训练后,视频生成网络的训练结束,参数在此时及以后不发生改变,进而进行下一部分的第二个生成网络的训练,使其生成最优嵌入修改矩阵。对第二个网络的训练采用的是,每训练两次生成器,训练一次隐写判别器的方式,两种模块的对抗性训练交替进行。
如图4所示,经过前一轮次的训练后,第一个生成网络已然可以生成拥有逼真效果的伪视频,相较于原始视频来说,其噪点较多,并且在纹理复杂的区域较为模糊。但是这些缺点正好为本文消息的嵌入,提供合理的冗余空间。因为在实际网络环境中充斥着大量因压缩算法或者传输带宽不足导致的视频缺失与模糊,因此在真实环境中这样的视频是存在的。

图4 生成视频帧Fig.4 Generate videos
双流视频生成网络的特点是能够同时生成视频的静止与运动信息:动态前景与静态后景,如图5所示。考虑到视频隐写术的关键是利用其中的时空冗余信息,因此在设计第二个网络中本文使用基于三维卷积的特征提取网络,并利用动态前景作为载体视频的时空特征信息,提高隐写生成器生成修改概率矩阵的能力,构成双生成对抗网络视频隐写算法。

图5 前景、后景与掩模Fig.5 Foreground, background and mask
3.2.2 抵抗彩色隐写分析器
通过对比实验来验证本文提出的隐写算法架构的抗隐写分析算法攻击的能力,实验选取了基于空域的S-UNIWARD算法进行对比,由于S-UNIWARD是灰度图像隐写算法,对其进行训练时,将一张数据集中的图像拆分为三张灰度图像,作为该算法的输入,训练后的隐写模型分别对三个彩色通道进行嵌密,为了进一步验证双生成对抗网络隐写算法的有效性,增加一组消融性实验作为对比,将载体视频作为隐写生成器的输入,基于时空信息与原始载体样本的两种隐写对抗网络在三个模块的结构、参数上相一致,不同点在于如何设置隐写网络的输入,分别用GAN与SGAN表示。为了检验二者的差异性,从以下隐写安全性方面进行评估。
目前针对序列视频信息的空域隐写分析算法较少,且无法应用于基于图像的S-UNIWARD算法,本文通过将算法所生成的视频随机抽取帧图像作为数据,引入彩色图像隐写分析算法SCRM[16]作为隐写分析工具,结合集成分类器[17]对其进行检测。
分别对通道嵌入率为0.05、0.1、0.2、0.3、0.4 bpc (bit per channel, bpc)的载密样本进行分析,共使用了10 500组样本作为数据集,其中9 000组样本为训练集,1 500组样本用于测试分类准确度,实验中得到的平均嵌入率分别为0.050、0.099、0.198、0.300、0.401 bpc。
从表2可以看出,本文提出的SGAN架构与S-UNIWARD算法相比,在嵌入率为0.05、0.1、0.3 bpc在SCRM检测中都取得了较好的表现,在检测错误率上分别有0.65%、1.33%、3.26%的提升,在0.1、0.2、0.3 bpc的嵌入率下GAN也要优于S-UNIWARD算法,检测错误率的变化曲线如图6所示。总体上SGAN架构与GAN架构之间,前者要综合上优于单纯地只对视频进行特征提取的后者,从实验中证明了前者的抗隐写分析能力要更强。在与S-UNIWARD算法比较时,其只在部分嵌入率下优于该算法,整体上并没有显著的提高,但本文算法的嵌入对象是时空冗余信息,因此基于空域的图像隐写分析算法的结果作为参考,抗隐写分析的能力在部分嵌入率下有所下降是正常的。
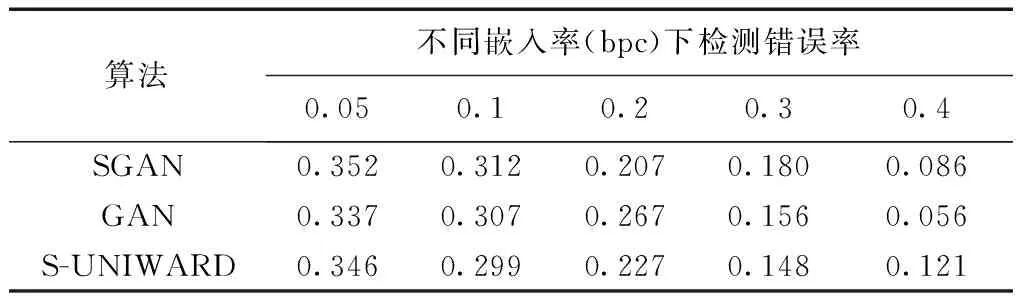
表2 SCRM检测错误率Table 2 Error rates of SCRM detection
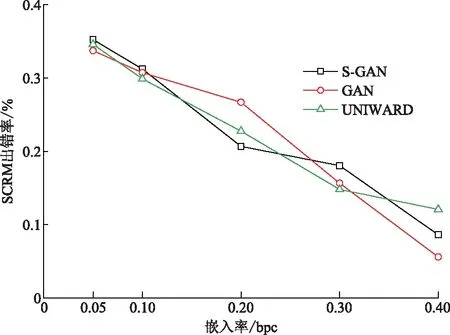
图6 SCRM检测错误率Fig.6 Error rates of SCRM detection
3.2.3 时空内容自适应性
图7为本文方案SGAN架构在五种通道嵌入率下在红色通道中修改位置图,可以看出嵌入位置的选择多在像素变化较为频繁的运动部分,这里时空冗余较多对于视频信息更为适合隐藏秘密消息,并且随着嵌入率的提高这部分选择的机率越来越高,这表明所提出的方案具有时空内容自适应性。

图7 各嵌入率下的修改位置图Fig.7 Modification maps under different embedding rates
4 总结与展望
为了提高视频隐写术在公共信道中的安全性,使得其能够抵抗来自隐写分析算法的攻击,提出了基于生成式对抗网络的视频隐写算法。该算法生成的视频在质量上满足真实视频中的语义信息,利用隐写生成器与判别器之间的博弈学习,优化生成器的性能,减小嵌入带来的失真,自适应嵌入秘密消息比特。从实验结果上来看,算法生成的载密视频在空域隐写分析算法SCRM的检测下,能在低嵌入率时较同类算法S-UNIWARD的抗检测率有一定提升。
