基于BERT 模型的检验检测领域命名实体识别①
2022-09-28苏展鹏李洋张婷婷让冉张龙波蔡红珍邢林林
苏展鹏 李洋 张婷婷 让冉 张龙波 蔡红珍 邢林林③
(∗山东理工大学农业工程与食品科学学院 淄博255000)
(∗∗山东理工大学计算机科学与技术学院 淄博255000)
0 引言
命名实体识别作为自然语言处理中关键部分,是信息抽取的基础,其主要作用是在无序的文本中按不同的需求提取出特定有意义的命名实体。现广泛应用于智能回答、机器翻译、知识图谱等方面。同时命名实体识别技术是通用领域和特殊领域进行信息抽取加快信息化发展的基础。
目前命名实体识别在通用领域中已经得到了优良的效果[1],主要得益于通用领域的数据集的完善和模型方法的不断优化。起初主要是基于规则字典方法,这种方法耗时长、性能差、效果不佳,之后提出的基于统计的方法[2],像随机条件场模型(conditional random field,CRF)和隐马尔科夫模型(hidden Markov model,HMM),这类方法依靠通用领域精确的特征条件得到不错的训练结果[3-4]。但因为其需要人为参与操作多、成本高,逐渐被深度学习方法所取代。深度学习方法在降低人工成本的同时,也具有很强的领域适应性,可以在不同领域取得不错的训练效果。因此深度学习方法现已成为自然语言处理(natural language processing,NLP)领域的主流方法。Hammerton[5]将长短期记忆模型循环神经网络(long-short term memory,LSTM)模型应用在了命名实体识别任务中,取得了理想的实验结果。Huang等人[6]提出了双向长短期记忆模型循环神经网络(bi-directional gate recurrent unit,BILSTM)搭配CRF模型,同时还融合了其他语言学特征以提升模型性能。王洁等人[7]将字向量作为输入,利用双向门控循环单元(bi-directional gate recurrent unit,BIGRU)搭配CRF 模型提取会议名称的语料特征,发现与LSTM 相比GRU 的训练时间减少了15%。Ma 和Hovy[8]提出了一种基于IDCNN-LSTM-CRF 的模型在不需要数据预处理的情况下可以提取字向量和字符向量并在conll 2003 数据集中得到了91.21%的准确率。Yue 和Jie[9]提出lattice LSTM 模型将字符向量和字向量融合来解决一词多义问题,使模型更易识别实体边界。Radford 等人[10]提出OpenAI 生成式预训练(generative pre-training,GPT) 模型,用Transformer 编码代替LSTM 来捕捉长距离信息,但是因为是单向的,无法提取上下文语义特征。Devlin 等人[11]提出了能够更好获取字符、词语和句子级别关系特征的变压器双向编码器表示法(bidirectional encoder representation from transformers,BERT)预训练语言模型。通过BERT 利用Transformer 模型提升自身模型的抽取能力,能够更好地明确实体边界。
李妮等人[12]提出BERT-IDCNN-CRF 模型来解决BERT 微调过程中训练时间过长的问题并在MSRA 语料上F1 值能够达到94.41%。顾亦然等人[13]提出了BERT-BILSTM-CRF 模型来解决专业电机领域中出现的小规模样本特征信息不足和潜在语义特征表达不充分的问题。
检验检测行业作为近几年出现的一个新兴服务业,到目前为止检验检测领域还没有相关的公开数据集,进行检验检测领域的命名实体识别训练缺乏训练数据。同时由于检验检测领域的特殊性,使得检测文本识别过程中存在以下难点:(1)检验检测领域实体搭配规则不明确,检测项目冗杂繁多;(2)检测组织在检验检测文本中存在大量缩写和简称;(3)检测仪器实体中存在含有功能、结构等多种名词叠加的长实体,这类实体难以准确识别实体边界。根据以上问题本文提出了BERT-BIGRU-CRF 融合模型,在BIGRU-CRF 轻模型的基础上引入了BERT预训练模型,通过BERT 模型提前在大规模的中文语料库中进行训练,学习中文语义特征,以此来解决小规模数据集存在的语义特征不足的缺点,让模型可以在本文自行搭建的检验检测小数据集上取得更好的效果。同时BERT 的Transformer 模型可以提升模型的抽取信息能力,可以更好地识别检测实体边界,确定检测实体类型。而BIGRU-CRF 模型可以在不降低性能的前提下减少模型训练时间。实验结果表明本方法可以较好地解决检验检测领域识别的难点,准确识别出检验检测领域实体,同时缩短训练时长。
1 BGC 检验检测领域实体识别模型
1.1 BGC 模型框架
模型主要是由BERT 语言预训练层、BIGRU 编码层和CRF 推理层3 部分组成。首先将字符序列传入到BERT 预处理模型中。BERT 会依据字符的位置向量、字向量和文本向量3 部分加和得到最终的输入向量。经过编码获取到上下文语义信息,把融合后的向量输入给BIGRU 网络模型。经过BIGRU 的双向编码后,最终输出给CRF 选择出最合理的标签序列输出。BGC 模型结构如图1 所示。

图1 BGC 检验检测领域实体识别模型结构
1.2 BERT 预训练语言模型
BERT 作为一个预训练模型在处理特殊领域的命名实体识别任务时有着很好的语义表征效果,BERT 主要模型结构是由多组双向的Transformer 编码构成。其无监督的方法,使得BERT 可以通过预训练学习中文语义特点,通过迁移学习的方法转移到检验检测领域中来,以此来解决检验检测领域语料匮乏数据量少导致的文本特征信息不全面的问题。同时引用注意力机制对文本的上下文进行理解关联。因为其特殊的构造使得其可以使训练的结果更好反映出上下文语义关系,提取出检验检测领域特征信息,解决实体嵌套和冗杂的问题。同时双向的Transformer 结构要比传统LSTM 模型可以更好地处理长期依赖问题。其作为编码器拥有强大的语言表征能力和特征提取能力[14],其结构如图2 所示。

图2 Transformer 编码器结构
本文利用Transformer 本身引入的多头注意力机制,来多次计算学习不同的表示子空间,从而获取相关信息来提高模型在不同位置的专注度。经过BERT 预处理模型对句向量处理后,通过多头注意力机制使句子向量在向量映射的不同情况下出现权重得分对比,使实体边界更易被识别。同时为了弥补自注意力机制不能抽取时序特征的问题,对词语中的位置进行编码:

其中,pos表示词语在其句中位置;d是PE的维度;dk是输入向量的维度;Q、K、V都是自注意力机制(Self-Attention)计算出的字向量矩阵,QK的乘积表示了此中某个词在整个句子中的关注程度。为了计算出向量在每一个映射的注意力向量:
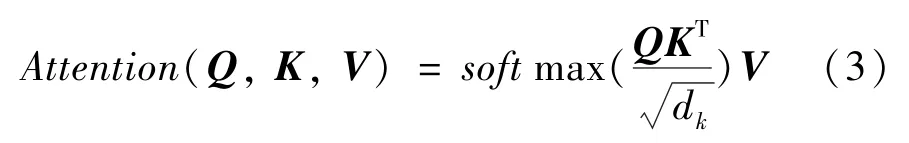
将Self-Attention 机制对之前的输出部分做一次残差连接和归一化处理将共享前馈神经网络在多个子空间中计算向量相似度:


最后为了使BERT 在NLP 任务中得到更好的表征效果,采用表征词语无监督方式的Masked 语言模型和下一句预测2 种任务方法[14]。Masked 语言模型采用随机屏蔽15%的信息,将被屏蔽的信息区分处理,把其中80%的信息替换成Masked,10%的被遮挡信息会被任意词替换,10%的遮挡信息保持不变,以此来保证训练过程中模型可以更加准确获得词间信息。下一句预测则是采用二分类方法把任务中的句子分成上下连贯句子和非连贯句子2 类。让模型预测判断两个句子间的关系,最后作出Is-Next 和NotNext 2 种判断结果并进行标记,以此来获得句子间的上下关系。因此BERT 模型可以在其他小数据领域中获得更好的全局表达效果,使得模型可以应用在检验检测这种语料匮乏的领域中。
1.3 BIGRU 网络层
GRU 和LSTM 模型可以解决循环神经网络(recurrent neural network,RNN)模型无法长期记忆和反向传播中的梯度消失问题。但GRU 作为LSTM 的变体模型,其在保留了LSTM 效果的基础上将遗忘门和输入门合并成了更新门,简化了模型参数。本文LSTM 引入了3 个函数来控制输入值记忆值和输出值,而GRU 则是通过重置门和更新门2 个门控制新的输入和记忆输入[15]。在BERT 后搭配BIGRU模型,来增强模型训练速度和泛化性能,表达公式如下:

式中,zt为更新门t时刻的输出,rt代表重置门t时刻的输出,σ为sigmoid 函数,和ht分别表示t时刻的记忆内容和隐藏状态。GRU 结构如图3 所示。

图3 GRU 单元结构
在单向的神经网络中,信息总是由前往后获取,只能采集到上游信息,为了让下游信息也能被获取,所以采用两条单向的GRU 组成的正反两层的BIGRU 模型,加强模型语义挖掘能力,能更好地理解前后文依存关系。
1.4 CRF层
虽然BIGRU 模型的输出也能够评分出最优标签,但是只能在标签内判别。所以会出现很多错误标记和无用标记的问题。为此需要在BIGRU 后加入一个CRF 层来考虑标记信息间的依存关系。增加约束来确保预测标签的合理性,减少非法序列出现的概率。
对于最开始的输入字符序列x进行预测标签分布得到的标签序列y;对于BIGRU 层的输出矩阵p,其大小由一个句子中的单词数n和标记种类k所决定,其中Pi,j、Ai,j分别为第i词在第j个标签的得分和转移矩阵中标签i到标签j的概率得分。最终序列y的得分如式(8)所示。

然后利用Softmax 归一化处理得到最大的输出概率为

最后利用Viterbi 算法[16]求得到所有序列上的预测中最优解作为检测实体结果,其公式为

2 实验分析
2.1 检验检测领域数据集
当前国内对检验检测领域的命名实体识别研究较少,缺少训练所需要的数据集。因此本实验通过网络爬虫的方法爬取了近10 年来检验检测领域机构的检测类文本。整合检测类文本的特点和常用关键词,将命名实体分成以下4 类,即检测项目、检测仪器、检测标准和检测组织。检验检测实体分类定义如表1 所示。

表1 检测实体识别类型及定义
根据其中68 家网址的检验检测相关文本,总共搜集出5.5 万条数据,为了搭建出本文命名实体识别所需要的数据集,经过了数据清洗和数据去重工作,得到有用数据条数10 812 条。将得到的数据条数以8 ∶1 ∶1 的比例分成训练集、测试集和验证集。同时本次实验采用的是BIO 方法,命名实体以B 为始端,I 为实体中间部分,O 为非实体部分。本文将实体分为了4 类,因此出现的标注类别有B-M、I-M、B-S、I-S、B-P、I-P、B-E、I-E、O 共9 种。数据中各实体类别数量在数据集中的比例如表2 所示。

表2 不同实体在各数据集中的数量统计
2.3 实验室环境和参数设置
实验室硬件设备为CPU 采用Intel(R) Xeon(R) Gold 6242R,GPU 采用NVIDIA Tesla T4,内存为425 GB。实验室虚拟环境采用Python3.6 的版本搭配Tensorflow 1.14.0 的版本对模型进行训练和测试。本次实验采用BERT-Base 模型,其含有12 个Transformer 层、768 个隐含层和12 个多头注意力机制。为了使得下梯度下降的方向更加明确,减少训练时间。将批尺寸参数数值设置为16,迭代轮次设置为30。同时为了保证模型不会过拟合,将删除比例参数的数值设置为0.5,学习率设置为1 ×10-5。
2.4 评价指标
本文采用准确率(precision,P)、召回率(recall,R)以及F1(F1-sorce,F1)值作为模型性能的评价指标,具体公式为


其中,TP表示模型预测为正确且识别正确的样本个数,FP表示模型预测为正确却未能识别的样本个数,FN表示预测为错误的样本个数。
3 结果分析
为了验证在检验检测领域中本实验模型实体识别能力,在相同的实验环境下,本次实验加入了3 个对照模型BILSTM-CRF、BILSTM、HMM。通过搭建好的检验检测数据集进行模型训练,采用P、R、F1测试结果进行评估,每个模型在不同检测实体的实验结果如表3 所示。

表3 不同训练模型的对比结果(%)
通过实验结果发现BGC 模型是所有实验模型里面得分最高的,相较于其他模型得分有了明显提升。其中在4 种实体中得分较高的实体是检测标准。其F1 值达到了85.67%的分数,这类实体构成相对简单,在本次实验中取得了不错的识别得分。而其他类实体得分略逊色于检测标准实体。而BILSTM-CRF 模型、BILSTM 模型、HMM 模型中BILSTM-CRF 模型的4 个实体F1 得分更高,其识别效果仅次于BGC 模型。
在加入BERT 预训练模型后,BERT-BIGRUCRF 和BERT-BILSTM-CRF 2 种模型进行对比实验,观察实验结果和训练时长(min)如表4 所示。
对比BERT-BIGRU-CRF 模型和BERT-BILSTMCRF 模型,发现除了检测组织F1 得分外,其余实体得分都略高于BERT-BILSTM-CRF 模型。而BGC 模型的训练时间缩短了6%,证明模型简化后的性能依旧可以得到保证。
对其中表现较好的BILSTM-CRF 模型和BGC模型的测试结果分析发现,BGC 模型的F1 得分高的原因,在于其可以准确识别以下3 种情况实体:(1)检测组织实体中存在的组织缩写如华测检测、岛泽测试等;(2)检测仪器实体中存在的长实体如电涡流式覆层厚度测量仪、溶体流动速率测定仪等;(3)检测项目中出现长实体如维卡软化温度检测、熔体流动速率测定等。而BILSTM-CRF 模型在测试时,在出现第1 种缩写问题时多次错误地将检测组织标注成检测项目。而在后2 种情况出现时,BILSTM-CRF 模型标注结果中出现实体标注不全的问题。对比发现BGC 模型在融合了BERT 预训练模型和BIGRU 轻模型后,通过分析学习上下文语义,结合学习的语料特征,使得模型可以结合上下文识别出检测组织的缩写,同时消除了歧义问题,明确实体边界使得检测项目和检测仪器实体中存在的一词多意和嵌套实体都被精准识别并区分出来。在本次小型检验检测数据集的训练情况下,BGC 模型得到了相对更好的训练结果。说明了本模型可以很好地解决检验检测领域中实体边界模糊和句式冗杂的问题。
同时发现,4 类实体中检测项目实体的F1 得分相对较差,而检测项目实体又在检验检测领域中举足轻重。通过对测试结果整理分析后发现其主要原因是检测项目复杂多变。模型对检测项目中出现的新词的识别还有待加强。针对此实体特点后续可以再扩充检验检测数据集。在数据集内实体更加丰富的情况下,对检测项目类实体进一步定义区分。可以从检测范围、检测方法和检测产品角度去定义,更细致地划分检测项目实体,改善检测项目实体目前识别得分较低的情况。
4 结论
本文从解决检验检测领域的命名实体识别问题出发,针对检验检测领域存在的语料匮乏、句式冗杂等问题提出了结合BERT 预训练模型和BIGRUCRF 轻模型的检验检测领域命名实体识别方法BGC。通过在BGC 模型中加入BERT 预训练模型后更好地识别出复杂实体的边界,对比未加入BERT 的模型,该方法在4 类实体中的P、R、F1 结果有了显著的提升。而BGC 模型使用BIGRU 轻量模型后使得BGC 模型比BERT-BILSTM-CRF 模型的训练时间缩减了6%,同时性能仍然优良。研究表明BIGRU 模型确实可以在性能保持不变的情况下提高训练速度,减少训练成本。两个实验证明了BGC模型在检验检测领域的可行性。在后续数据集进一步补充、优化检验检测领域实体分类和定义后,将针对检验检测领域数据中更复杂的问题进行进一步的研究。
