基于信息熵的船舶主机性能监测方法
2022-09-28张焱飞
刘 兴,杨 越,张焱飞
(1.中远海运散货运输有限公司, 广东广州 510006;2. 上海外高桥造船海洋工程有限公司, 上海 200137;3. 上海船舶运输科学研究所有限公司, 上海 200135)
0 引言
随着智能船舶的快速发展,智能船舶系统在船舶设备维护、性能评估和监测中扮演着越来越重要的角色。基于大数据分析方法和传统设备监测方法对船舶设备进行监测可以帮助船舶管理者了解船舶设备运行状况,从而为船舶设备维护做出提前预判和规划[1]。
船舶主机作为船舶运行的关键设备,由众多设备组成。众多的设备可分为多个子系统,多个子系统按照设备功能和特点分为废气排气系统、冷却水系统、滑油系统等[2]。因此,对主机进行性能监测可充分分析主机下各子系统的运行状态,通过主机运行参数分析结果可以快速判断主机当前的运行状况,评估主机性能是否下降或者上升。
现阶段,要构建出符合主机运行的物理模型,需要完整的主机设备参数信号,但由于信号采集限制,研究者很难构建出准确的主机运行物理模型。构建物理模型需要精准的物理量,比如排气流速或者交换水温等,然而实际工程中,以上关键信号很难送出,因此缺少了部分关键物理量则很难构建物理模型。针对此类问题,绝大多数研究学者利用大数据分析方法来对船舶主机海量数据进行特征提取、状况识别、故障诊断、性能监测以及故障预测。
绝大多数的大数据识别方法集中在数据的聚类划分、深度学习上。船舶主机是复杂的系统,常用的大数据分析方法可以提升监测水平,但实际工程中,大数据分析方法依靠比较复杂的数据基础,若缺少数据学习样本,则会使数据分析结果陷入局部最优的情况。
因此,本文引入信息熵方法来监测船舶主机运行性能,根据信息熵方法计算的熵值结果对比2个满载航次的主机性能趋势,从而实现对满载航次下船舶主机运行性能的监测。
1 信息熵有关理论
“熵”是热力学中表示分子状态无序程度的物理量。在信息论中,通讯的随机性无法避免,因此通信系统具有统计的特征,信息源可作为多随机事件的集合,这类集合具有随机性。因此与热力学中分子状态无序性相似[3]。在20世纪40年代,香农提出了信息熵的概念,把信息中排除了冗余后的平均信息量成为“信息熵”,用于衡量不确定性,是离散随机事件出现的概率,及计算所有可能发生事件相关信息量的期望值[4],系统越复杂出现的类目越多,则信息熵越大。系统越简单,出现种类或者概率越小,则对应的信息熵较小[5]。信息熵具有3个特点[6]:1)单调性。事件在统计中发生的概率越高,则信息量越低,该特性也暗含了信息含量先验假设,默认某些条件下不含信息量,即表示一种概率分布,将默认情况的概率定为0。2)非负性。信息熵是一种广度量,是一种合理的必然情况。3)累加性。多种随机事件同时发生,并存在的不确定性的量度表示为不确定性的量度之和,
信息熵的计算公式为
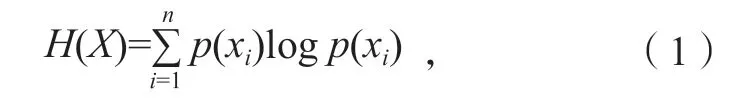
式中:n为系统X出现n个不同状态,p(xi)为xi(i=1,2,...,n)出现的概率。公式结果越高代表系统越混乱,若H(X)=0,表示系统较为稳定。
2 船舶主机气缸状态参数与数据选择
本文选择的某目标船是1艘30×104t级别的散货船,主要来往于巴西和中国。该船主机的最大输出功率为25200 kW,配有6个气缸,每个气缸可提供气缸废气排气出口温度、气缸缸盖冷却水出口温度、气缸活塞滑油出口温度,即对应主机废气排气系统、冷却水系统以及滑油系统。
在实际工程中,实船数据采集周期为1 s 1组数据,为了让数据可用于后续的计算,需要对实时秒级数据进行筛选处理,剔除异常值和空值,接着按1小时为数据处理周期,对每整小时内的数据进行平均计算,即计算3600个数据采集周期内的数据,最终得到主机气缸3个系统下每小时的平均值。
本次研究可以更加直观展示监测结果,本文选取目标船2个时间相邻的满载航次作为研究对象,2个满载航次转速相近,航路相近,航速相近。第一个满载航次的航行时间从2021-11-05到2021-12-23,航行时长49天,对原始采集数据进行筛选处理后总计得到1176条小时数据;第二个满载航次的航行时间从2022-04-13到2022-05-26,航行时长44天,筛选处理后得到总计1056条小时数据。以2个航次下主机废气排气系统为例,如图1所示(图1中#1~#6表示目标船主机的1号~6号气缸)。对比图1中2个航次的气缸废气排气温度数据,可知航次一的废气排气温度数据波动幅度较大,在第一航次运行到第850 h和1000 h附近有过异常的数据下降,后又恢复到原来时间附近,而航次二的数据展示可知长达44天的航行期间,主机废气排气系统温度均维持在稳定运行范围内,温度发生异常或温度变化幅度较大的现象较少。
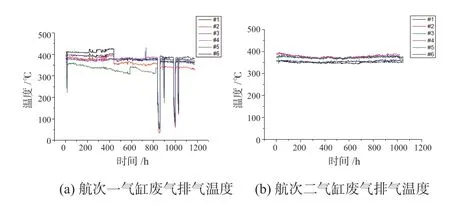
图1 2个满载航次主机气缸废气排气温度示意图
根据船期计划已知,在第一个满载航次和第二个满载航次之间,该目标船按计划进坞维修保养过船舶主机。
3 基于信息熵的主机性能监测方法
本文提出的基于信息熵主机性能监测方法主要利用主机气缸在3个系统下温度偏差值的波动进行熵值计算,得到主机气缸在3个系统下的熵值情况。按照此主要思路构建监测方法流程框架。
首先,计算目标船主机6个气缸3个系统温度的整体平均值,接着计算每个气缸3个系统温度和整体平均值之间的温度偏差,可以得到每个气缸的废气排气温度偏差、缸盖冷却水出口温度偏差以及气缸滑油出口温度偏差。根据各个系统温度特征和温度偏差特征确定各个系统下温度偏差间隔以作为分布统计对象。在本次研究中,废气排气系统最大温度是420℃左右,最低则降至30℃左右,温度偏差也从-60℃~50℃不等,因此对于废气排气系统以5℃作为分布统计对象,即定[-5,0)、[0,5)、[5,10)等范围为分布统计区间,对于冷却水系统和滑油系统,温度变化范围在100℃以下,且温度偏差变化最大未超过10℃。因此,冷却系统和滑油系统以1℃为分布统计对象,即定[-1,0)、[0,1)、[1,2)等范围为分布统计区间。
以整个航次为统计区间,计算参数模型的熵值,对传统计算公式进行改进,计算式为
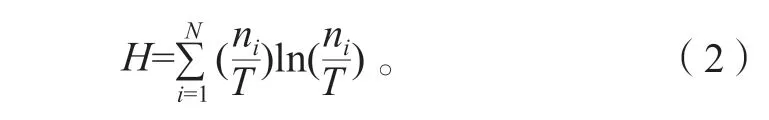
式中:H为满载航次的熵值,N为统计区间数据,ni为每个区间内的统计数目,T为以整个航次为统计区间的总数目,ni=0则不参与统计。
4 验证与分析
依据前面的监测方法,对目标船主机数据进行温度偏差计算,得到主机6个气缸3个系统下的温度偏差。以主机废气排气系统数据为例,如温度偏差结果,如图2所示(图2中#1~#6表示目标船主机的1号~6号气缸)。
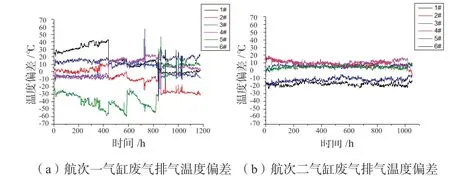
图2 2个满载航次主机气缸温度偏差示意图
每个系统统计区间利用信息熵方法进行计算,得到2个满载航次下6个气缸在各个系统的熵值,如图3所示。
对目标船主机在3个系统下的熵值进行平均计算,最终得到主机在2个航次的整体熵值结果,如表1所示。数据。
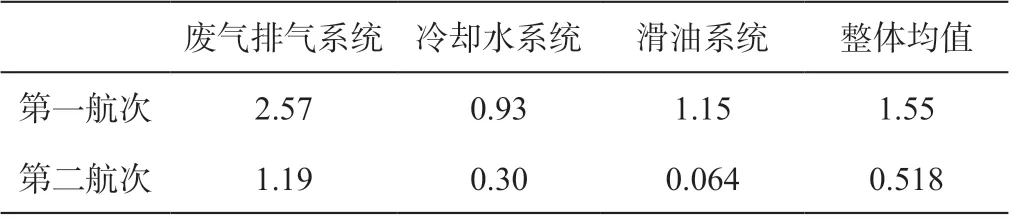
表1 两满载航次整体熵值结果
根据图2可知,相较于第二次满载航次,第一次满载航次各个系统的温度偏差波动范围较大。根据图3可知,第一次满载航次的所有气缸各个子系统下的温度偏差熵值均大于第二次满载航次的熵值,其中,第二航次下多个气缸在冷却水系统和滑油系统熵值为0,表明对应气缸在该系统下的温度偏差较为稳定。对2个满载航次下3个系统熵值进行平均计算,如表1所示,第二满载航次下3个系统熵值都要比第一满载航次熵值低很多,特别是滑油系统熵值,第一满载航次熵值为1.15,第二满载航次熵值为0.064,其中1号、2号、3号以及5号气缸熵值均为0,计算结果表明,以上4个气缸在第二满载航次的滑油出口温度偏差都稳定在固定区间,因此整体较为稳定,无异常较大范围波动。温度偏差结果与熵值计算结果也体现第二满载航次主机性能要比第一满载航次的主机性能要高一些。根据已知条件,该目标船在2022年1月份对主机进行过维修和保养。经过维护保养后的主机设备运行性能会比保养之前要好一些,因此,本文计算得到的熵值趋势情况符合主机运行情况。
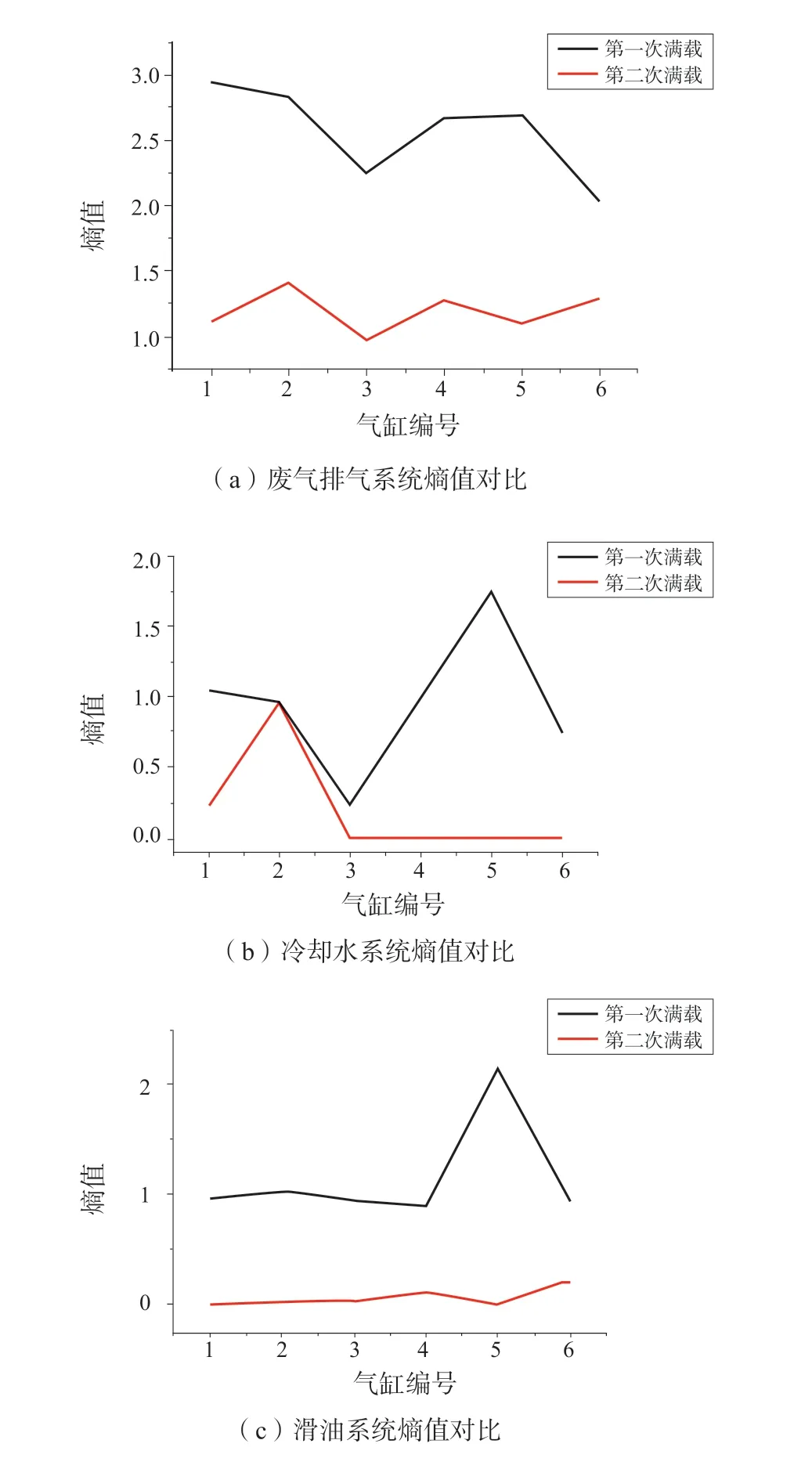
图3 2个满载航次下气缸熵值对比图
5 结语
本文提出一种基于信息熵的船舶主机性能监测方法,对比2个目标满载航次的主机气缸在各个系统下的熵值,主机维护保养后的第二满载航次各个气缸熵值均出现了下降,表明主机性能有所上升。因此,2个航次熵值结果表明,本文提出的方法可以初步监测主机性能状况和趋势。本文提出的方法侧重监测气缸温度偏差波动的稳定性,但是主机性能监测方法仍然需要考虑各个气缸的温度偏差值,若同一系统下某气缸温度偏差过大,但温度偏差波动较为稳定会导致主机监测过程中出现性能识别盲区。
