基于改进的ResNet与IMU位姿图像特征描述子
2022-09-28陈守刚张伟伟
陈守刚,张伟伟,赵 波
(上海工程技术大学 机械与汽车工程学院,上海 201620)
0 引 言
寻找图像局部特征稳定且高效的对应关系,是计算机视觉任务的基本组成部分。例如,基于多视图几何三维重建(Structure from motion,SFM)和同步 定 位 与 建 图(Simultaneous Localization and Mapping,SLAM)都需要稳定且区分度高的特征描述子。目前,基于深度学习的图像特征描述子(如:SuperPoint、LF-Net),展现出比人工设计的特征描述子具有更好的性能。然而,一些研究表明,当把SuperPoint等特征描述子应用于有遮挡的现实世界时,存在泛化能力弱的问题。存在这种局限性的一个重要原因,就是无法获取图像对之间特征点真实的对应关系。之前,许多方法都采用SFM数据集作为替代方案,但这些数据集提供的匹配特征点并不是真实的对应关系。
针对上述问题,本文方法不要求特征点之间具有严格的对应关系,仅从图像对之间的相对相机位姿中学习特征描述子,就可以通过各种基于非视觉的传感器,例如惯性测量单元(Inertial Measurement Unit,IMU)获得相机姿态;通过减少特征点之间严格匹配的要求,可以在多样化的数据集上学习更好的特征描述子,解决了特征点学习获取训练数据的困难。
然而,由于不能基于相机姿势来构造损失函数,现有的深度学习方法不能直接利用相机位姿作为约束。本文的主要贡献:提出了一种新的框架,将图像对之间的IMU位姿转换为对匹配点之间的像素位置的对极约束作为监督约束条件(如图1所示);匹配点的位置相对于用于训练的特征描述子是可区分的;为了进一步降低计算成本并加快训练速度,使用了从粗到精的匹配方案,以较低的分辨率计算对应关系,以更精细的比例进行局部优化。

图1 位姿一和位姿二图像匹配对之间的查询点和预测点之间的对应关系Fig.1 Correspondence between query points and prediction points between pose-1 and pose-2 image matching pairs
1 IMU器件测量与运动学模型
1.1 陀螺仪与加速度计的测量模型
陀螺仪的测量模型为:
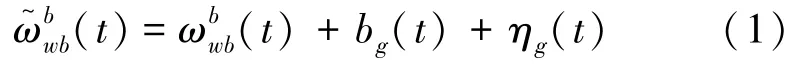
其中,b是随时间缓慢变化的偏差,η是白噪声。模型利用了静态世界假设,即重力加速度不发生变化。
加速度计的测量模型为:
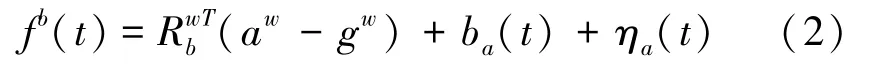
其中,b是随着时间缓慢变化的偏差,η是白噪声。
1.2 陀螺仪与加速度计的运动模型
运动模型的微分方程形式为:

使用欧拉积分、即三角积分可以得到运动方程的离散形式:

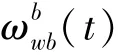
1.3 测量与运动混合模型
为了使符号简明,对符号进行重新定义为:
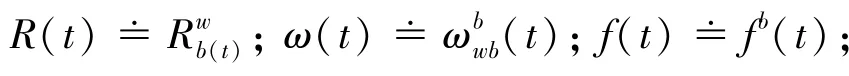
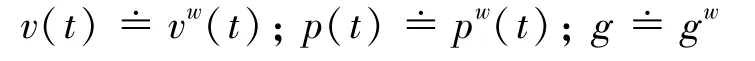
将测量模型代入运动方程:
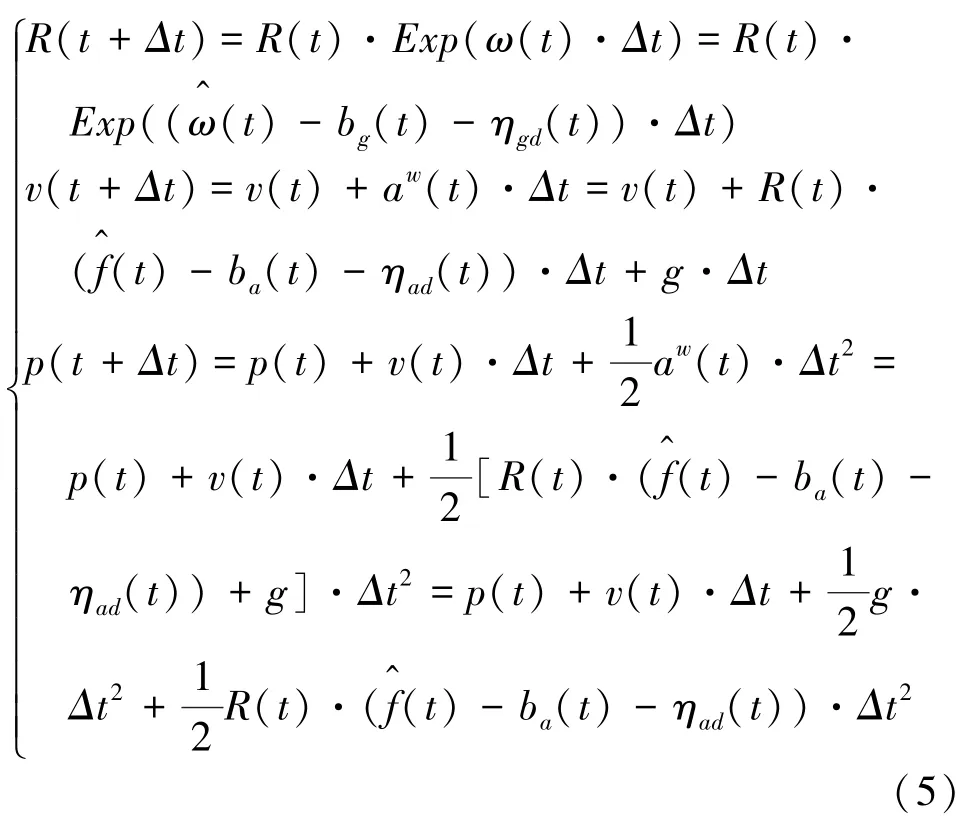
其中,噪声项采用η和η(表示discrete),故与连续噪声项η和η是不同的。离散噪声与连续噪声的协方差有如下关系:

进一步假设恒定、即采样频率不变,每个离散时刻由0,1,2,…表示,上述的3个离散运动方程可进一步简化为:

2 ResNet简介
2.1 ResNet架构
随着网络的加深,神经网络梯度消失,出现了训练集准确率下降的现象。为了解决上述问题,He等人在2016年提出ResNet深度学习模型,该模型的最大特性就是网络层深度可以无限叠加,而不会出现梯度消失的问题。该网络的提出,说明网络的深度对许多计算机视觉识别任务至关重要,在ImageNet数据集上的错误率仅为3.57%,获得ILSVRC 2015中图像分类任务的第一名。ResNet在COCO目标检测数据集上获得了28%的相对改进。
ResNet的残差模型如图2所示。图2中,表示输入的feature mapping,()为残差,()表示下一层网络的输入,该网络特征可以有效确保梯度不会消失。
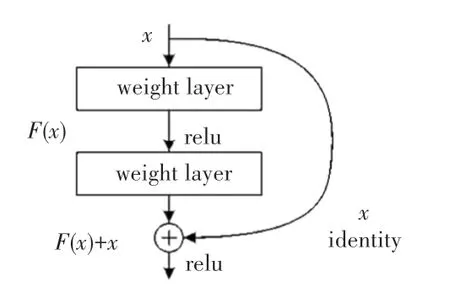
图2 ResNet的残差模型Fig.2 Residual model of ResNet
虽然ResNet网络的层数可以无限叠加,但是更深的网络会导致训练的复杂度变大。综合现有研究结果可知,ResNet采用18、34、50、101、152这5种深度的网络结构较为普遍。本文所提出的方法就是基于ResNet50网络结构,如图3所示。

图3 ResNet50的残差模型Fig.3 Residual model of ResNet50
2.2 ResNet50的改进
由于ResNet可以重复叠加深度网络,因此可以提取更多的网络特征。本文提出的方法只采用ResNet50网络模型中的第3个block单元块之前的网络架构作为主干网络,第3个block单元块输出的feature mapping大小为40×30×1 024。本文网络架构详见表1。

表1 本文方法网络架构Tab.1 The network architecture of the method proposed in this paper
由表1可见,第3个Block单元块之后,在输出40×30×1 024的feature mapping的基础上,依次进行1×1的卷积、上采样3×3卷积、3×3卷积、上采样3×3卷积、3×3卷积、1×1卷积等操作,从而获得不同粒度的特征图。
通过附加的卷积层,获得了粗糙级特征图。精细级特征图是通过进一步的卷积层以及上采样和跳过连接获得的。粗略特征图和精细特征图的大小分别是原始图像的1/16和1/4,且都具有128维的向量。精细级别的局部窗口的大小是精细级别特征图大小的1/8。
3 基于相机位姿的方法
如果只给出具有相机位姿的图像对,则不适用于标准深度度量学习方法。因此,本文设计了一种利用IMU数据进行特征描述子的学习方法。该方法中将相对相机位姿转换成图像对之间的对极约束,确保预测的匹配关系服从对极约束。考虑到该约束是实施在像素坐标上的,因此必须使对应的坐标相对于特征描述符是可微的,为了实现该目的,本文提出了可区分的匹配层方法。
3.1 损失函数
本文训练数据由含有位姿信息的图像对组成。为了利用这些数据训练特征描述子的关联匹配,使用2个互补的损失函数项:对极损失项和循环一致损失项。
图1中,是查询点、是预测的对应关系;对极损失函数L是和真实对极线之间的距离;循环一致性损失L是与其前后对应点(绿色)之间的距离。
给定一对图像和的相对位姿和相机内参,就可以计算基本矩阵。极线约束指出,如果和是真实匹配,则0成立,其中0可以解释为对应于中的对极线。本文将视为查询点,然后根据预测的对应位置与真实的对极线之间的距离,将此约束重新化为对极损失:

其中,()是中点在中的预测对应关系,而(·,·)是点与线之间的距离。
单独的对极损失函数,预测的匹配点位于对极线上,而不是真实的对应匹配关系(该位置在该线上的未知位置)。为了提供额外的约束,本文还引入了循环一致性损失,确保该点在空间上接近其自身:
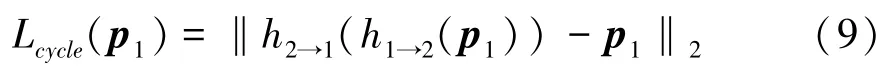
对于每个图像对,总目标是对极损失函数项和循环一致性损失项的加权总和,共计个采样查询点,可以表示为:
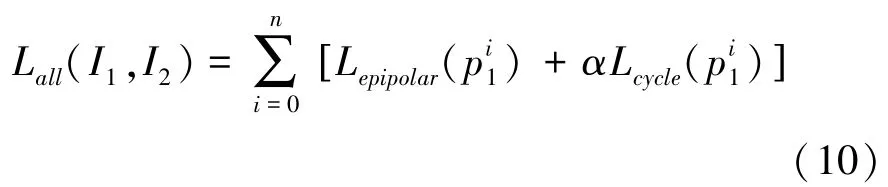

对极约束实际上为特征描述子学习提供了足够的监督。其关键原因是,对极约束抑制了许多不正确的对应关系。而且,在满足对极约束的所有有效预测中,鉴于其局部外观相似性,真正的对应关系最有可能具有相似的特征编码。因此,通过在所有训练数据上聚合这样的几何约束,使网络学会对真实对应之间的相似性进行编码,从而产生有效的特征描述子。
尽管本文的重点是仅从相机的位姿中学习,但当有真实匹配关系可用时,也可以使用真实的对应关系进行训练。在这种情况下,可以将损失函数替换为预测和真实对应关系的像素位置之间的距离。通过真实匹配关系训练的方法,比通过照相机姿势训练的方法会获得更好的性能,两者均优于先前的完全监督方法。
3.2 可区分的匹配层
损失函数是预测对应像素位置的函数,但若使用梯度下降法,则像素位置相对于网络参数是可区分的。传统方法是通过识别最近邻匹配来建立对应关系,但这是一种不可微分的操作。
针对上述问题,本文提出了可区分的匹配层方法。对于给定的图像对,首先使用卷积神经网络提取特征描述子、,为了计算中查询点的对应关系,将处的特征描述子(用()表示)与相关联。接下来进行2D softmax操作,可以得到在中的二维概率分布(,,):

其中,变量表示在的像素坐标上变化。
计算单个2D匹配作为此分布的期望:
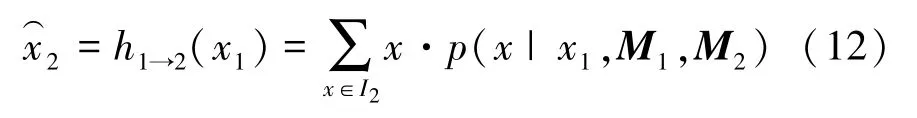
使用可区分的匹配层,使整个网络系统可以进行端到端训练。由于对应位置是根据特征描述子之间相关性计算的,因此将有助于特征描述子的训练学习。
4 实验结果分析
4.1 数据集
本文提出的方法使用MegaDepth数据集对网络进行训练。该数据集由196个不同场景组成。其中130个场景用于训练,其余场景用于验证和测试。数据集提供了数百万个具有已知相机位姿的图像训练匹配对,在此仅使用所提供的相机位姿和相机内参在这些图像匹配对上进行训练。
4.2 训练过程
本文使用Adam训练网络,其基本学习率为1×10,循环一致性项的权重设置为0.1。由于内存所限,在每个训练图像对中使用400个查询点。这些查询点由80%SIFT关键点和20%随机点组成。
训练所使用的设备为:RTX3060 GPU,Ubuntu 18.04操作系统与Intel i7第十代CPU。
4.3 实验结果
本文在MegaDepth数据集上对POSE特征描述子进行测试。给定一对图像后,在2个图像中提取关键点,并使用特征描述子进行描述。对每个图像匹配对之间的匹配数进行统计(仅考虑最近邻匹配),并将SIFT、LF-Net与POSE测试结果进行对比。
去除异常点之后的匹配结果如图4~图6所示。其中,图4的SIFT特征描述子代表传统人工设计方法;图5代表LF-Net深度学习方法;图6为采用本文提出的方法。根据对比的结果可以看出,本文方法得到的结果使精度得到了提高。

图4 SIFT描述子Fig.4 SIFT descriptor

图5 LF-Net描述子Fig.5 LF-Net descriptor

图6 POSE描述子Fig.6 POSE descriptor
实验不仅给出可视化的结果,并对几种方法进行了量化处理。3种特征描述子对比结果见表2。

表2 POSE特征描述子与其它模型的对比Tab.2 Comparison of POSE feature descriptor with other models
从表2中可以看出,POSE特征描述子不仅可以从图像中提取到更多的特征点,同时也提高了特征描述子的匹配度。
5 结束语
文中提出了一种新颖的特征描述子学习框架,该框架仅使用IMU获取的相机位姿监督进行训练,利用对极几何约束构造损失函数。实验表明,在不使用任何特征点对应匹配关系进行训练的情况下,其性能优于受到完全监督的其它算法。接下来的工作中,将进一步研究如何提高学习到的特征描述子对图像旋转的不变性、基于位姿监督的方法和传统度量学习方法是否有相互补充的可能性,以及相应的组合是否可以带来更好的性能。
