融合主题竞争关系的短文本分类方法
2022-09-28潘智勇
潘智勇,赵 港
(北华大学 计算机科学技术学院,吉林 吉林 132013)
0 引 言
随着网络信息数据量的快速增长,以微博、Twitter和博客等为代表的网络短文本已成为重要的数据资源。与此同时,对这些网络短文本的信息处理也得到了更为广泛的关注,而数据表达特征的有效性,将直接决定着分类的准确率。由于文本中含有大量的同义词和多义词,传统基于词频统计的文本处理方法将会受到一定影响,限制模型应用。以隐狄利克雷分配(Latent Dirichlet Allocation,LDA)模型为代表的主题模型基于词汇与主题的共现关系,以主题作为底层特征和上层语义之间的中层特征,有效地克服了同义词和多义词的影响。针对短文本数据,Zhang等人结合词汇及隐主题作为新的词汇来学习短文本的向量表达,提高了文档的表达能力。刘爱琴等人利用LDA模型分析短文本,提取主题词,并以主题与词汇的共现矩阵对短文本进行分类。Yan等人提出词汇对主题模型(biterm topic model,BTM),该模型基于短文本数据中词与词共现关系,提取“词汇对”作为文档的基本特征,从而建立语料级的词汇共现关系,克服忽略词汇关系的不足。BTM通过“词汇对”与主题的共现关系提取主题特征,在短文本数据分类问题上得到了较好的应用。Yang等人利用词汇共现关系和类别词汇的相似性,提出种子词汇对主题模型(Seeded Biterm Topic Model,SBTM),并且利用附加用户信息,提出种子推特词汇对主题模型(Seeded Twitter Biterm Topic Model,STBTM)。但是,上述模型均基于主题独立性假设,利用词汇或词汇对与主题的共现关系提取主题特征,忽略了主题之间的关系,影响了主题特征的表达准确性。
以 卷 积 神 经 网 络(Convolutional Neural Networks,CNN)模型为代表的深度学习算法,在自然语言处理和图像处理领域均取得了较好的应用。CNN通过多层神经网络提取表达局部特征的神经元,在全连接层(fully-connected layer)建立各层神经元之间的全局关系,从而提高特征表达能力。作为中层特征的主题为隐变量,在表达文档的过程中存在冗余的问题。Chen等人提出Kate模型,将竞争关系引入到神经元的主题获取过程,使神经元的主题更具有区分度,同时降低全连接层模型参数,提高了主题学习效率。但上述模型以词汇作为局部特征,易受到同义词和多义词的影响。
本文融合BTM词汇对表达和面向文本的竞争自 编 码(competitive autoencoder for text,Kate)主题竞争关系,并利用全连接层构建起文档中主题之间的全局关系,提出竞争全连接主题网络模型(competitive fully-connected topic network,KFTN)。KFTN以“词汇对”表达文档数据,降低了短文本对主题表达的影响,引入了主题竞争关系,增强主题特征的表达能力,建立起语料级的词汇关系和主题间的全局关系,从而提高短文本分类的准确率。
1 相关模型背景
1.1 词汇对主题模型
由于短文本文档词汇数量较少,词汇特征过于稀疏,同时隐狄利克雷分配(LDA)模型基于词汇独立性假设,限制了LDA模型提取主题特征的准确性。词汇对主题模型(BTM)基于文档中共现的词汇构建无向词汇对,利用词汇对与主题的后验概率,对文档中主题特征进行采样。BTM构建的词汇对融入了词汇的共现关系,解决了短文档的稀疏性问题。LDA与BTM模型的概率图模型如图1所示。

图1 LDA和BTM的概率图模型Fig.1 Graphical models of LDA and BTM
从图1中可以看出,LDA中相互独立的主题产生相互独立的词汇,而BTM以相互独立的主题产生词汇对(w和w)。因此,与LDA主题采样不同,BTM的主题采样过程为:


1.2 面向文本的K竞争自编码模型
面向文本的竞争自编码(competitive autoencoder for text,Kate)模型在隐层编码过程中,以前个权重绝对值较大的神经元作为关键主题,并将其它神经元的权重分别转移到正负权重较大的神经元后置0,进一步增大关键主题权重。经过引入竞争关系,使重点主题更加突出,增强主题特征稀疏性,降低其它主题的影响。
Kate模型K竞争层结构如图2所示。图2中,竞争层和分别为正负权重最大神经元,其它神经元按正负权重分别相加后,以超参为系数增加和权重。
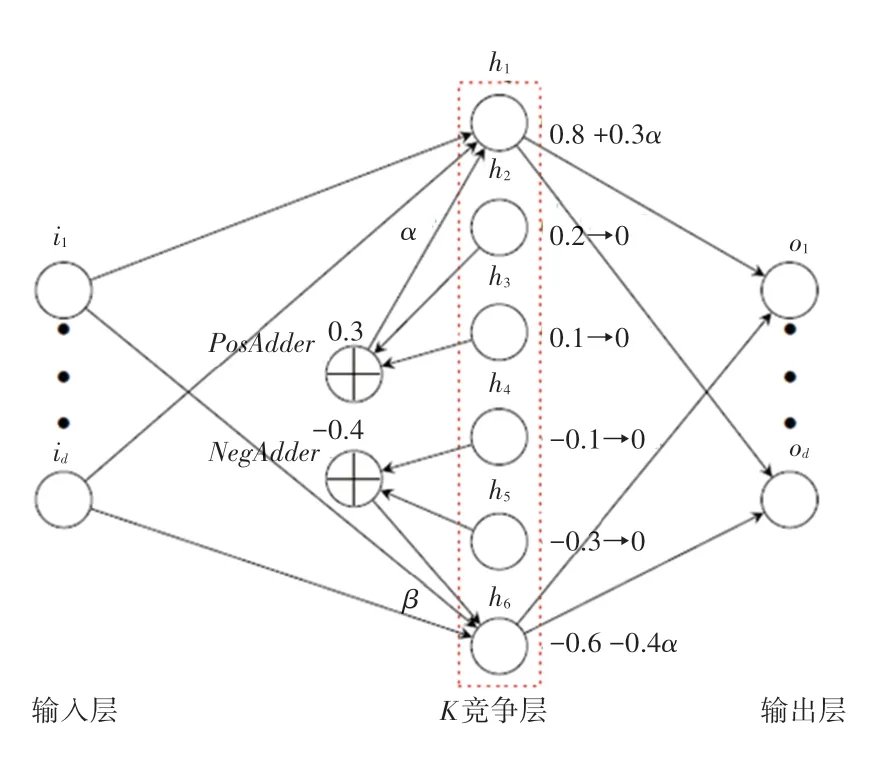
图2 Kate模型K竞争层结构图Fig.2 The architecture of K-competitive layer
2 K竞争全连接主题网络模型
本文结合BTM“词汇对”表达和Kate主题竞争关系,提出竞争全连接主题网络模型(KFTN)。该模型以融合词汇共现关系的“词汇对”表达短文本,提取主题作为初始主题特征。将初始主题特征引入竞争关系,增强主题特征稀疏性,突出关键主题作用,并以全连接结构建立主题间全局关系,提高主题特征表达的准确性。KFTN文档处理主要结构如图3所示。这里对KFTN主要部分拟展开阐释分述如下。
(1)主题初始采样。KFTN利用词汇共现关系提取无向“词汇对”表达文档(参见图3中同一颜色表示一组词汇对),建立起主语料级的词汇共现关系,从而使文档由词汇表达转为“词汇对”表达。利用式(1)采样计算后验概率,提取具有一定中层语义的主题,作为初始主题特征。

图3 KFTN文档处理主要结构图Fig.3 The main architecture of KFTN for documents processing
(2)竞争层。经主题初始采样,KFTN以主题特征表达文档。但所提取的主题基于独立性假设,忽略了主题之间关系,同时主题特征中还存在一定的噪声。因此,研究中为突出重点主题,增强主题特征稀疏性,降低噪声主题的影响,竞争层引入竞争机制,对主题特征进行重新编码/解码,保留具有代表性的项主题(正负权重各2项),其它主题权重置0。由图3可见,、分别表示非代表性主题的正负权重和,则正权重代表性主题权重由w重编码为w+mα,负权重代表性主题权重由w重编码为w+nα。其中,为权重系数。
(3)全连接层。全连接层以主题全连接结构建立竞争层提取的项代表性主题,从而构建主题之间全局关系,更准确表达数据。增加全连接层的层数可以提高模型的拟合,但会严重增加模型参数规模。各全连接层主题以线性关系连接:
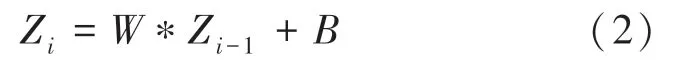
其中,Z为各层主题特征;为权值参数:为偏置参数。
3 实验分析
本文实验数据来源于20newsgroup和Reuters-21578两个标准新闻短文本数据集。其中,20newsgroup由18 846篇新闻组成,涉及政治、宗教、计算机科学、体育等20类新闻,每篇文档属于一类。Reuters-21578由路透社新闻报道组成,用以完成信息检索和机器学习等基于语料库的研究。实验根据文档中主题标签,以植物、金融和贸易等68类主题词的11 305篇文档为数据集,每篇文档包含一至多个主题词。
实验过程中,选取具有代表性的4组主题数(100、200、500和1 000),以文档主题分布作为liblinearSVM和分类器特征,对比不同主题数的情况下,KFTN与LDA和BTM的短文本分类实验准确率。
3.1 20newsgroup短文本分类实验
为获得更为公平的对比结果,在20newsgroup短文本分类中,以3次交叉验证的平均分类准确率,对比和评价不同模型。不同模型在20newsgroup数据集短文本分类的对比结果如图4所示。
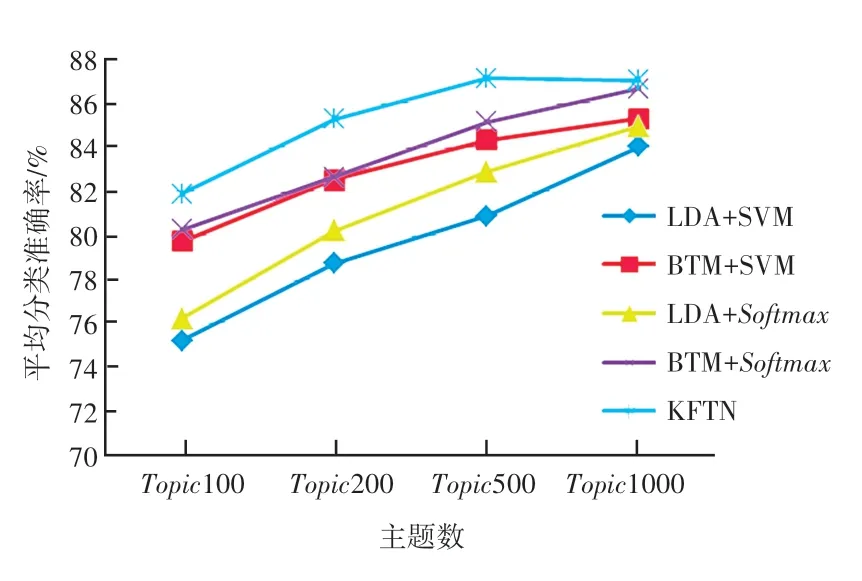
图4 20newsgroup短文本分类对比结果Fig.4 The comparison results of short-text classification on 20newsgroup
图4中,BTM模型通过“词汇对”建立词汇间的共现关系,克服了词汇特征过于稀疏和忽略词汇关系的不足,其分类准确率高于LDA模型。对于相同主题特征,与线性SVM准确率相近,但更关注标签与得分的相似度,其准确率略高于线性SVM。KFTN以“词汇对”建立底层特征,竞争关系突出重点主题,同时建立主题全局关系,更有效地表达短文本数据,其分类准确率高于其它模型。
20newsgroup数据集由20类新闻组成,主题作为文档的中层特征,并不能直接表示新闻类别。同时随着主题数的增加,主题特征的表达能力也得到增强,分类准确率得到提高。但过高维度的主题特征会造成特征过于稀疏,增加模型参数规模,影响模型学习的效率和应用。因此,当主题数达到500时,KFTN分类准确率趋于稳定。
3.2 Reuters-21578短文本分类实验
Reuters-21578数据集中文档为多标签文档,因此本文通过3次交叉验证方法,以_和_对比和评价不同模型。表1为不同模型在Reuters-21578数据集短文本分类的实验对比结果。
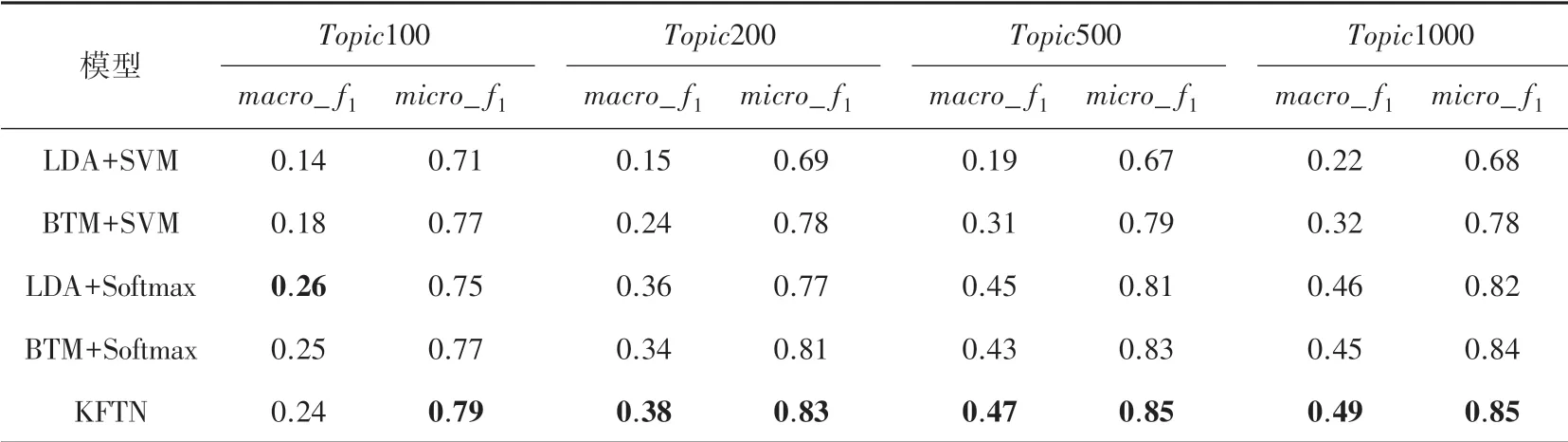
表1 Reuters-21578短文本分类对比结果Tab.1 The comparison results of short-text classification on Reuters-21578
采用分类器交叉熵作为损失函数,衡量标签与得分的相似度,更有利于多标签分类,因此其分类准确率略高于线性SVM分类器准确率。基于“词汇对”表达方法的BTM模型对于短文本的表达能力优于基于词频的LDA模型,在各个主题数下,分类准确率都高于LDA模型。由于_易受到识别性高的类别影响,LDA主题特征基于主题独立性假设,更易提取识别性高的类别特征。因此,在分类过程,LDA模型的_值略高于BTM模型。但LDA和BTM均忽略了词汇关系和主题关系,影响了主题特征表达。KFTN模型融合词汇关系和主题全局竞争关系,提取的主题特征更为准确有效,因此分类准确率高于LDA和BTM模型。
4 结束语
针对主题模型等算法处理短文本数据的不足,从短文本数据特点展开研究,本文提出竞争全连接主题网络模型(KFTN)。通过构建“词汇对”表达和引入主题权重竞争,建立词汇语料级关系和主题全局关系,突出重点主题的特征表达,降低了噪声对主题特征的影响。KFTN克服了主题模型忽略词汇关系和主题关系的不足,增强了主题特征的表达能力,提高了短文本分类的准确性。
