基于多模态深度学习的音乐情感分类算法
2022-09-28周萍
周 萍
(南昌职业大学 信息技术学院,南昌 330500)
0 引 言
众所皆知,音乐艺术家通常使用动态节奏、发音来传达音乐中的情感。随着互联网和流视频技术的发展,“音乐+视频”逐渐成为流行的可视化表现形式。对于音乐视频,用户在关注其名称、收录专辑和艺术家的同时,还会关注诸如流派、情感和视频质量等属性。因此,结合视频内容对音乐的情感等属性进行分类是一个重要的研究课题,亦能切合线上音乐网站、音乐视频网站和内容共享网络等场景的应用需求。现有的研究主要集中于分别面向音频和视频单模态信息来进行分类等任务,但是针对音乐视频进行情感分析仍然是一个亟待解决的热点问题。情感可以通过情感词汇以口头方式表达,也可以通过非语言线索(如语调、面部表情和手势)表达。音乐视频中的情感不仅包括了视频、文字、面部表情等情感属性,还涵盖了通过音乐旋律、器乐节奏和作曲家突出场景表达的附加情感。本文将采用深度学习算法对音乐视频的情感进行分类,提出以音频梅尔谱图为输入的音频神经网络以学习音频特征,剖析了视频神经网络学习视频数据的时空特征,用于捕获整个视频信息。本文使用多模态融合,将音频特征和视频特征结合进行情感分类。由于缺乏已标记音乐视频数据集,本文构建了具有多样性的音乐视频数据集,并基于该数据集进行实验评估,用来验证提出的算法的有效性。
1 音频和视频神经网络设计
1.1 音频神经网络设计
卷积神经网络(Convolutional Neural Network,CNN)的有效性在于能够从端到端管道中的原始数据中学习特征以应对特定任务。由于处理诸如音频这一类信号需要二维CNN,因此本文设计了二维音频网络来提取音频特征。许多现有的音频网络使用音乐的梅尔谱图的幅度表示作为输入,忽略了梅尔谱图的相位信息。音频网络使用梅尔谱图的原始波形作为输入可以同时保留信号幅度和相位信息,因此本文提出的二维音频网络需要使用原始波形作为输入进行音乐情感分析。本文提出的音频网络结构如图1所示。由图1中的二维音频网络可知,卷积层(32)是指在池化大小为2的通道上执行32个步长为2卷积操作,卷积核的大小为3×1,再采用最大池化操作来降低信号的维数,同时保留卷积信号中的必要统计信息。本文提出的二维音频网络使用指数线 性 单 元()作 为 激 活 函 数,使 用(01)缓 解 过 拟 合 的 副 作 用,其 中(01)是指概率为01的操作。本文提出的二维音频网络将来自4个卷积层和4个最大池化层的输出拼接为一个328的二维输出矩阵。

图1 二维音频网络Fig.1 Two-dimension audio network
1.2 视频神经网络设计
本文采用三维卷积网络(3D Convolutional Networks,C3D)和 膨 胀 卷 积 网 络(Inflated 3D ConvNet,I3D)对视频特征进行提取。二维音频网络和C3D视频网络融合流程如图2所示。由图2

图2 二维音频网络和C3D视频网络融合Fig.2 The fusion between two-dimension audio network and C3D video network
可见,在进行C3D预处理后,本文将原始C3D网络的末端2个全连接层替换为维度分别为1 024和512的全连接层,以降低维度,并应用概率为0.2的层来缓解音乐视频数据微调中的过度拟合问题。使用随机梯度下降(SGD)作为优化器,学习率设置为0.000 01。此外,研究还给出了二维音频网络和I3D网络视频融合流程如图3所示。图3中,对于I3D网络,对最后的inception块的输出进行三维全局平均池化,使用音乐视频数据对整个网络进行微调,并使用学习率为0.000 1的Adam优化器。
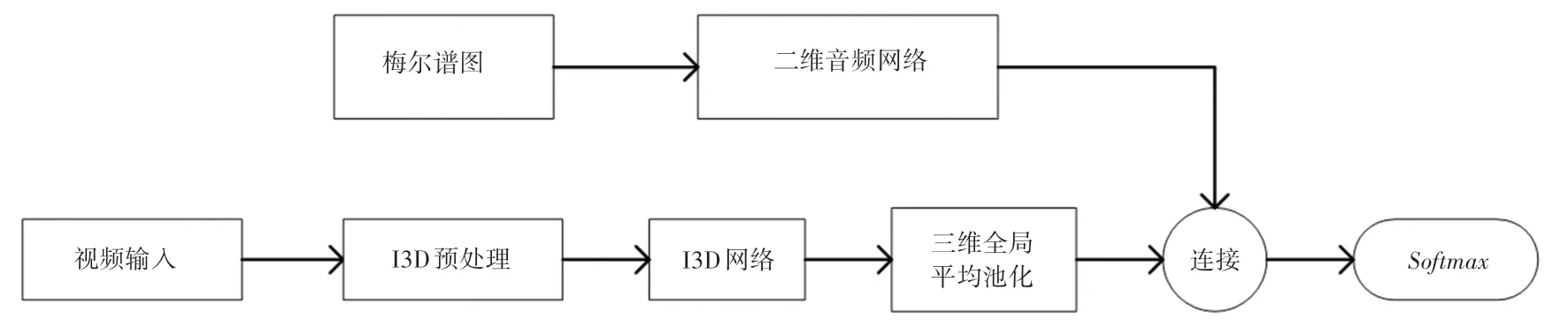
图3 二维音频网络和I3D网络视频融合Fig.3 The fusion between two-dimension audio network and I3D video network
2 分类算法设计
2.1 输入预处理
在使用多模态深度学习算法进行训练前,需要对输入的视频数据进行预处理。图2、图3中的C3D预处理和I3D预处理过程即如图4所示。使用C3D和I3D视频网络进行视觉情感分类之前,所有的视频帧被调整到合适的大小、数量和通道。C3D和I3D网络使用具有红色、绿色和蓝色通道的32帧视频进行训练。对于视频帧,以统一的时间间隔进行提取以捕获整个视频信息内容。图4中,卷积层1包含64个卷积操作,卷积层2包含256个卷积操作,卷积层3包含512个卷积操作,卷积层4包含一个大小为7×7×7、步长为2的卷积核,卷积层5包含一个大小为1×1×1的卷积核,卷积层6包含一个大小为3×3×3的卷积核。对于音频数据,本文对音频数据进行零填充得到全长音频波形,随后对30 s的音乐信号以16 kHz的频率进行采样。音频输入是CNN音乐网络的480 000维输入向量。经过预训练的2D音乐CNN也需要使用零填充生成全长音频,以生成固定大小的梅尔谱图。梅尔谱图是通过获取短时傅里叶变换(short-time Fourier Transform,STFT)的绝对值发现的频率内容随时间的二维表示。
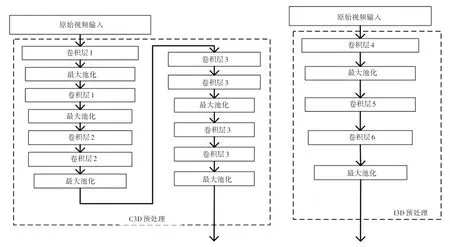
图4 输入预处理Fig.4 Input preprocessing
2.2 多模态分类
将音频和视频信息融合为多模态,分别将C3D和I3D视频网络的决策级特征与一维音乐CNN(OneDMCNN)和二维音乐CNN(TwoDMCNN)的决策级特征融合,产生了4种多模态架构,即C3D+OneDMCNN、I3D+OneDMCNN、C3D+TwoDMCNN和I3D+TwoDMCNN。音频和视频的每个单模态情感分类器首先分别使用数据集进行微调,去除每个单模态的分类器后,将输出的结果用于多模态特征融合。
为了克服数据匮乏的问题,结合迁移学习来进行音乐视频分类。首先加载预训练的权重,并微调源神经网络,使其适应音乐视频数据集。然后,提取每个单模态情感分类的学习特征,用于多模态决策。使用sport-1 M数据集训练C3D以及使用RGB ImageNet和kinetic数据集训练I3D。采用歌曲数据集训练的预训练二维音乐CNN作为音乐情感分类器,并微调该音频网络,以对网络分类音乐情感进行泛化。
多模态融合是一个整合来自多个来源信息的过程,目前有3种信息融合方法,包括早期融合、晚期融合和混合融合。应用了后期融合,将最高级别的预训练特征组合起来,由层做出最终分类决策。将每个单模态网络所学习的特征连接起来,用于单独的音乐和视频情感决策,也由层做出最终决策。
3 实验评估
3.1 数据集构建
现有的情感分类算法应用机器学习技术来训练分类器,将情感划分为离散的类别。这些算法通过训练预测输入数据的情感类别,从而将输入表示为情感空间中的一个点。
音乐视频情感分析的主要挑战在于情感边界的模糊性和标记训练数据的稀缺性。现有的音乐视频数据集仍无法用于情感分类算法的有效训练,而数据集的稀缺问题对研究人员来说是一个巨大的挑战,算法需要足够的数据样本才能做出更准确的决策。对此,首先通过整合现有的数据集和其他从互联网上收集的数据样本,构建了一个用于音乐视频情感分析的小型数据集。将多种人类情感划分为6个类别作为基本情感类别,即兴奋、恐惧、中性、放松、悲伤和紧张。上述属于6个情感类别的样本如图5所示,每个音乐视频样本的长度约为30 s。

图5 数据集情感实例Fig.5 Emotion examples of the dataset
在本音乐视频数据集中,大多数音乐视频是从互联网上收集的,这使得数据集在区域、语言、文化和乐器方面存在巨大差异。每个数据样本都有其不同的特征,包括频率、音高、过零率、运动强度、节奏规律和分辨率等。本文所考虑的6种情感类别的边界是模糊的,部分情感之间存在重叠。选择了一致且易于确定情感的音乐视频来构建数据集,并用对应于6种基本类别的情感对数据集进行标注。其中,兴奋的情绪通常是指人们高兴或受某种刺激而精神激奋,视觉内容一般包括舞蹈或派对等高强度肢体动作、群体活动和丰富多变的环境。这类音乐一般采用快节奏、大调、和声、流畅或多变的节奏。恐惧情绪源于对危险或恐怖的感知,视觉信息包括一些不自然的事件或随时间突然变化的人物,音乐创作时通常会用到快节奏、高响度和不规则的节奏。放松是一种低张力状态或恢复平衡状态。这一类的视觉信息一般包括自然场景和乐器,此类别的音乐通常具有缓慢的节奏与和声。悲伤是人类心理的一种不愉快的感觉,悲伤的音乐通常具有缓慢的节奏和轻微的音调。紧张类别包括引发负面情绪的暴力场景,带有紧张情绪的音乐一般包括高响度、快节奏和碰撞的和声。
3.2 实验设置和结果分析
在实验部分,分别使用音频和视频神经网络来测试提出的音乐视频数据集。使用迁移学习并对预训练的CNN进行微调,以将其应用于提出的音乐视频数据集。实验中使用的性能评估指标主要有:准确率、分数和受试者操作特征曲线下的面积()。其中,准确率是指正确分类的数据样本占总样本的百分比,分数是精度和召回率之间的调和平均值。受试者操作特征曲线是显示分类算法在所有分类阈值下的性能以及真假阳性率的图表,而是曲线下方的整个二维区域,表示了对所有可能分类阈值的性能的聚合度量。针对不同的神经网络,实验选择了2种优化器。优化器的作用是用于调整神经网络的参数,使神经网络更快、更好地收敛。表1展示了各种单模态分类网络的评估结果以及优化器对各种学习因素的影响。由结果可知,一维音乐CNN和I3D使用Adam优化器时能获得最好的性能,二维音乐CNN和C3D使用SGD优化器时能获得最好的性能。学习率设置为0.001。
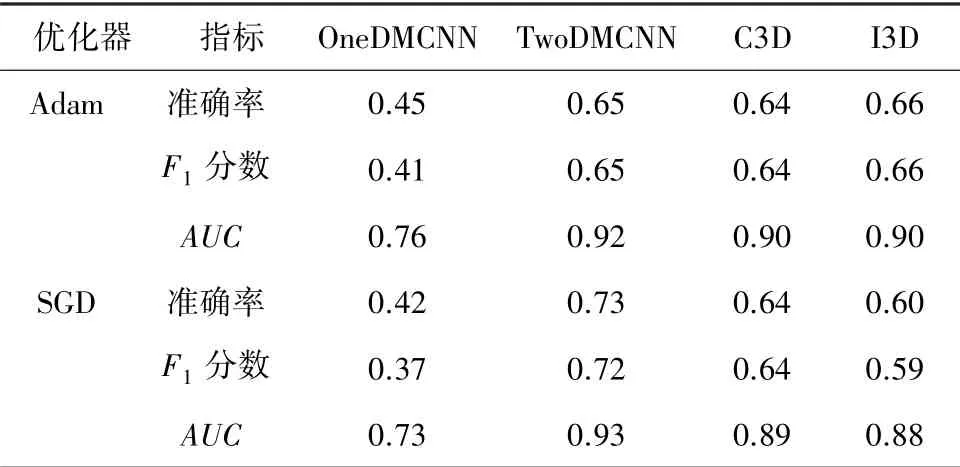
表1 不同优化器下单模态分类网络的评估结果Tab.1 Evaluation results of single-modality classification networks under different optimizers
随后将音频和视频的单模态结果融合为最终的多模态结构。C3D使用Adam和SGD优化器的性能较为接近,本文仅选择SGD优化器进行多模态集成。二维音乐CNN在歌曲数据集上进行预训练,因此其性能优于一维音乐CNN。虽然一维音乐CNN包含了音频流的相位和幅度,但由于端到端训练的数据样本非常有限,一维音乐CNN的性能也无法超过二维音乐CNN。
将表现最好的单模态分类器中学习到的特征整合到各种优化器上,用于音乐视频情感预测。音乐网络在决策级别与视频网络集成,并使用分类器对级联特征进行分类。分类是通过六重交叉验证完成的。表2展示了各种多模态组合的结果。决策级特征融合的结果表明,当所有的音视频特征都用决策算子结合时,能获得最好的性能。为了更好地了解提出算法的性能,实验统计了所有多模态分类器及集成多模态的。由表2结果可知,集成多模态在决策级别融合了多模态的所有学习特征,因此拥有最好的性能。集成多模态的混淆矩阵见表3。由表3结果可知,与其他情绪相比,放松和悲伤情绪更容易被混淆。与其他无声情绪相比,兴奋和紧张情绪之间能够得到更好的区分。

表2 单模态组合和集成多模态的评估结果Tab.2 Evaluation results of single-modality combination and integrated multi-modality

表3 集成多模态的混淆矩阵Tab.3 Confusion matrix for integrated multi-modality
4 结束语
借助迁移学习和后期决策级融合,提出了基于多模态深度学习的音乐视频情感分类算法。构建了一个小型音乐视频数据集,将音乐和视频部分分开,以便用于其他音频和视频CNN的预训练。实验评估的结果表明,多模态融合能有效提高分类性能。该结果表明,在已标记数据样本不足的情况下,提出的算法可以学习到音乐视频的多模态特征,实现准确、高效的情绪分类。
