数据驱动的开源软件供应链可维护性风险分析方法
2022-09-26梁冠宇武延军田春岐
孙 晴 ,梁冠宇 ,武延军 ,武 斌 ,田春岐 ,王 伟
(1.中科南京软件技术研究院,南京 210000;2.同济大学 电子与信息工程学院,上海 201804;3.中国科学院软件研究所,北京 100190;4.华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
软件系统往往由自主研发、开源获取、外包开发、商业购买等多种来源的部件组合而成,为了满足快速开发的需求,软件供应链中第三方来源的 (如开源、外包、商业等) 成分软件的占比会增大,从而引入更多“不可控”成分,提高了软件安全评估的难度.大型软件的供应链环节非常复杂、流程和链条很长,暴露给攻击者的攻击面越来越大,攻击者利用供应链环节的薄弱点作为攻击窗口,供应链的各个环节都有可能成为攻击者的攻击入口.近几年来,供应链相关安全事件更是频繁发生,造成了不可估量的影响.综上所述,对软件供应链进行全链路的安全监控防护,针对薄弱环节进行安全预防是保障软件质量的必要手段[1].软件维护作为软件生命周期中最耗费时间和成本的阶段,评估软件可维护性能够发现目前系统中存在的问题以进行更改或重构,从而提高软件系统的可维护性,降低系统维护成本.
与传统软件相比,开源软件供应链具有生产线上化、供应全球化、仓储集中化和用户多样化等特点.目前针对开源软件供应链的可维护性研究往往缺少有效的理论验证,其合理性及有效性有必要进行更深入的分析和讨论.
基于此,本文首先,介绍了开源软件供应链维护性风险的研究现状,并指出当前工作的不足;其次,根据开源软件供应链的特点,提出了多维度的分析视角;最后,给出了一个开源供应链软件维护性风险度量方法和评估方法,并通过实验验证了模型的有效性.
1 开源软件供应链研究回顾
1.1 开源软件供应链概述
传统供应链可以理解为将原材料加工成中间组件,然后将中间组件形成最终产品并传送到消费者手中的过程.软件供应链的概念由传统供应链扩展而来,在软件供应链中,原始组件是原材料,集成组件是中间组件,软件产品是传送消费者手中的商品.软件的开发过程包括设计、编码、发布和运营4 个阶段,是一套持续交付的流水线.软件供应链和传统供应链的共性在于攻击者可以攻击供应链中的薄弱环节,污染上游组件,从而影响下游产品.由于开源软件源代码开放、通过互联网来传输等特性,导致供应链攻击可能发生在软件生命周期中的任何阶段,攻击面也更广.
1.2 国内外研究现状
开源软件的可维护性风险是指软件及其开源软件供应链因无法持久满足用户需求而产生的风险.开源软件维护性风险目前的研究主要依赖于统计软件开发者上次提交活动的时间,并以此将软件分为未维护或者类似的状态.比如,Khondhu 等[2]将一年作为评判标准对SourceForge 上的软件进行分类.然而使用特定的阈值并不是一个较好的方法.首先,在Khondhu 等[2]的研究方法中,这个决定是主观设置的,并没有经过实验验证.其次,对未维护软件的定义并不是要求在给定时期内完全没有提交,即使在某个时间间隔内发生很少的提交,软件也被认为是未维护的.换句话说,未维护的软件不一定需要被终止、弃用或存档.最后,开源软件的可维护性评分并不应该只是维护和非维护这种二元取值,而应该给出一个定量的分析.Coelho 等[3]提出了一个机器学习模型来识别无人维护的 GitHub 项目,使用 GitHub 提供的标准指标作为特征,比如,提交、克隆、建立问题和提出请求的数量.但该方法的准确率完全依赖于训练集的情况.本文旨在给出一个简单有效的指标来提醒用户依赖特定软件的风险,并较为全面地考虑开源软件生命周期中的多个特征.
2 开源软件供应链的可维护性质量模型
2.1 开源软件供应链的可维护性度量方法
随着软件质量研究的发展,不同学者已经提出了不同的软件质量模型,用不同的质量指标来量化软件的可维护性.以软件质量模型ISO/IEC 25010:2011 为例,传统软件可维护性评价指标主要从易分析性、易修改性、模块性和易测试性等软件属性出发.
原有的软件质量评估模型都比较早出现,而当前开源软件的发展随着相关平台级技术的迅猛发展,导致这些模型的评估体系、评分体系和权重设计都无法高效达到评估要求[4].本文所提出的评估体系主要针对企业场景而非研究用途,该评估体系能够高效、精准、低成本对开源软件供应链进行评估.目前对于易分析性、易修改性、稳定性等指标的评估方法,大多停留在学术研究层面,无法适应工程化和商业化对于评估本身的高效、低成本和实效性的要求.本框架结合开源软件供应链规模化、社交化的发展特点,主要从以下几个指标进行探讨.
(1) 团队健康
个人的精力和能力是有限的,大型软件的开发和维护需要不同角色的人参与,一定数量的差异化的开发人员保证了一个开源软件可以得到长足的发展.较大的团队规模也具有更高的抗风险能力,即使部分核心贡献者离去,也会有其他贡献者继续维护软件和做出贡献,不会导致软件完全失去维护.
(2) 软件活跃度
活跃度是指在某一段时间内该软件进行开发、维护、讨论等行为的活跃程度.活跃度高不意味着软件是成熟的,可能只是因为刚启动;而一个看似偃旗息鼓的软件不一定是一个烂尾楼,也可能是已经趋于稳定.在技术革新层出不穷的今天,一个再完美的软件如果止步不前,它的生命力终究就是有限的.其中活跃度又可以从以下3 个方面着手分析.
社区活跃度.社区活跃度反应了用户及开发者对软件的关注度,用户的持续关注和对软件做出贡献关系着软件的生存和发展.积极活跃的用户基础将有效促进软件的持续健康发展,提高软件的竞争力;社区活跃度下降意味着粘性用户的流失,从而导致软件失去生命力.社区活跃度从侧面上也反映了软件的质量水平,有影响力且运营良好的软件才能吸引更多用户和贡献者.
依赖平均更新时间.显然,使用老旧版本的开源软件会增大开源软件运维风险.依赖平均更新时间越低,一个软件的维护性就越好.
发布频率.在软件某一个版本规划中,要预先确定该版本所需包含的特性集合,当该集合内的所有特性全部开发完成,并且达到相应的发布质量标准后,才能发布该版本.这种软件开发模式更符合安全生产习惯,即不能够把未完成的功能添加到即将发布的版本中,以免增大缺陷风险.每个新版本的发布都是一个里程碑,预示着开源软件又向前迈进了一大步,因此,软件版本的发布频率也能体现软件的活跃程度.
(3) 依赖影响力
依赖影响力是指在一个开源软件供应链中,有多少软件直接或者间接依赖当前软件.依赖影响力对维护性风险的影响体现在两方面.一方面,一个软件的依赖影响力越大,其出现各种风险和漏洞时对整个供应链造成的影响就越大.开源软件供应链的上游软件具有蝴蝶效应,由于这个软件被许多软件直接或者间接依赖,一旦这个软件出现问题,将会给整个供应链造成滚雪球式的危害.相反,如果一个未被其他软件依赖的下游软件出现问题,就只会影响到使用这个软件的少部分用户.另一方面,一个软件被其他软件依赖至少意味着这个软件能够被这部分用户良好运行和使用,经受住了他们的考验,满足了他们的需求,在被依赖和使用的过程中可以获得更多的反馈从而推动软件持续改进.因此,一个软件的依赖影响力越大,它出现可维护性风险的概率越小.
(4) 测试完整度
测试不仅能保证代码的基本功能是正确的,也表明开发人员认真负责的开发态度.如果测试很少、没有测试或者测试失败,可能就会导致财产损失、人员伤亡等后果.一个漏洞越长时间不被发现,它所带来的隐患也许会越大.
(5) 外部依赖度
与依赖影响力相反,外部依赖度表征的是一个软件对外部模块依赖的程度.通过复用代码,依赖项中的所有漏洞和缺陷通过依赖关系转嫁给软件自身,因为,软件完全依赖于这些依赖项.一个没有任何依赖项的软件外部依赖度为0,这样的软件比有外部依赖项的软件更好维护,因为,维护者只需要关注程序自身逻辑的实现,而不需要考虑依赖项可能带来的外部风险.一般来说,一个软件的依赖项越多,该软件的风险越大,对依赖项进行维护的成本也越高.
(6) 可理解性
易理解性描述了通过相关文档来了解系统功能及其运行的难易程度.文档是软件开发使用和维护过程中的必备资料,它能提高软件开发的效率,保证软件的质量,在软件的使用过程中有指导、帮助、解惑的作用,对文档的分析一般从针对性、精确性、完整性、清晰性等方面出发.由于这些属性难以量化且没有一个统一的打分标准,本文仅从两方面来评价: ①软件是否有文档;②该文档是否清晰.
(7) 问题处理能力
许多软件通过漏洞追踪中心收集用户的反馈,GitHub 通过问题来实现同样的功能.问题被用来追踪各种想法、增强功能、任务和软件漏洞等.如果问题没有被适当处理,软件项目中就会同时包含大量的漏洞问题或模糊不明的产品需求.软件维护者会被大量工作所困扰,新的贡献者也不清楚软件当前的工作重点是什么.所以对问题的处理能力也对软件的发展和维护起着至关重要的作用.
(8) 软件生态
软件生态是一个复杂的社会-技术系统,软件生态的环境可以是软件公司或研究组织,也可以是一个虚拟的开源或开放开发社区.开源软件基金通常会以多种方式支持开源软件,比如,推广宣传开源软件,提供开源指导,为软件的发展和其他活动提供补助等.商业支持同样保证了软件有持续可靠的资金流来进行各种活动,这些支持或赞助都有助于软件的持续性发展.
(9) 发布形式
大部分的开源许可证都有免责条款,这意味着这些软件一旦出现问题,没有人提供保障.虽然开源社区可能愿意向用户提供帮助,但是这种帮助只是出于自愿而非义务.解决这一问题的有效方法是购买软件支持服务,也称为“订阅”.用户在订阅之后通常还能得到增强的功能,比如: Linux 操作系统就有Redhat、Novell 等公司提供各自的发行版并出售订阅服务;OpenLogic 提供了与开源软件相关的全方位的服务,几乎涵盖了使用开源软件的整个生命周期;Bluck Duck、Palamida 和ProteCode 等公司则专注于帮助用户防范开源的法律和安全等方面的风险.
2.2 开源软件供应链可维护性的评估方法
软件的可维护性度量是指软件在可维护评估中某一具体考察对象的实际情况.对属性的评估将反映出软件在这一评估点上表现的好坏,对所有属性的综合考虑将会得出该软件可维护性的评价.
实行可维护性属性的分级定义、分级计算,每一级有自己的权重体系.软件维护性特征的第一级软件质量要素对应可维护评估属性类,第二级软件质量要素对应具体的可维护评估属性.属性和属性类都有自己的权重定义,属性的权重定义更加细致,这样可以充分反应属性的差别.属性的权重取值为0 (不考虑),1 (不重要),2 (一般),3 (重要),4 (非常重要).属性类的权重取值为1 (不重要),2 (较为重要),4 (重要).属性和属性类的权重定义如表1 所示.

表1 模型属性和属性类的权重定义Tab.1 Weight definitions for model attributes and attribute classes
将每个属性类评分和其相关的权重代入公式,计算结果取平均值.属性类评分值的计算公式为

上式中:G表示当前属性类评分值,Mi为属性类中第i个属性的评分值,wi为该属性在这一属性类中的权重,n表示这一属性类中属性的个数.
由于不同属性的取值范围差别很大,比如,测试覆盖率的取值范围为 [0,1],而活跃度的取值范围为 [0,107] .在根据属性及其权重计算属性类的得分结果时,不使用属性的真实计算结果,而使用绝对值限制为[0,5]的属性评分值.根据属性的真实计算结果得到属性评分值的方法见3.2 节.
软件的可维护性评分由前面计算的属性类评分值乘以相应权重相加得出,计算公式为

上式中:M表示软件的可维护性评分,Gj表示第j个评估属性类的计算得分,Wj表示第j个质量属性类在整个评估体系中所占权重.
可维护性评分总分为100 分,可以根据可维护性评分将可维护性风险划分为3 个等级: 高风险(得分为 [0,33)),中风险 (得分为 [33,66)),低风险 (得分为 [66,100]).
2.3 部分属性的定义与计算方法
(1) 团队健康
团队健康这一项指标的计算参考了Gitee 网站中Gitee 指数的定义方法.成员数量定义为所有贡献超过1 次的用户总数;关键成员定义为所有贡献超过3 次的用户总数.
(2) 软件活跃度
社区活跃度的计算方法基于X-lab 开放实验室所提出的软件活跃度计算方法,该方法较为全面地考虑了在开发过程中所产生的多种行为数据,并且计算方法简单,保证了在实际使用中具有较高的计算效率[5].
依赖平均更新时间等于开发者将软件实际使用的依赖项版本更新到依赖项当前最新版本的平均时间.
发布频率基于 GitHub 或 npm 子生态发布事件进行统计,在数值上等于一个软件在一年内发布事件的次数.
(3) 依赖影响力
软件之间的依赖关系可以看作是一个有向图,PageRank 算法是图的链接分析的典型算法,在子生态的依赖关系上执行PageRank 算法即可求得软件的依赖影响力.
(4) 测试完整度
如果软件有测试用例,包含测试属性实际计算结果就为1;如果软件没有测试用例,包含测试属性实际计算结果就为0.测试覆盖率评分为从GitHub 上所采集到的该软件的测试覆盖率数据.
(5) 外部依赖度
外部依赖度表征了一个软件拥有外部依赖项的多少,取决于一个软件直接和间接依赖项的数量.
(6) 可理解性
如果软件包含说明文档,包含文档属性实际计算结果就为1;如果软件不包含说明文档,包含文档属性实际计算结果就为0.
(7) 问题处理能力
未关闭的问题占所有问题的比例等于一段时间内,建立但未关闭的问题数量占这段时间内建立问题数量的百分比.
问题平均关闭时间属于软件的统计特征,代表一个软件中所有问题从建立到关闭所花费的平均时间.
问题首次响应平均时间等于一个软件中所有问题从被创建到第一次被回应的时间的平均值.
(8) 软件生态
如果该软件有商业支持,存在商业支持属性实际计算结果就为1;如果该软件没有商业支持,存在商业支持属性实际计算结果就为0.如果该软件有基金会支持,存在基金会支持属性实际计算结果就为1;如果该软件没有基金会支持,存在基金会支持属性实际计算结果就为0.
(9) 发布形式
如果该软件存在商业版,存在商业版属性实际计算结果就为1;如果该软件不存在商业版,存在商业版属性实际计算结果就为0.
3 实例验证
3.1 数据收集
在模型中计算各个指标所需要的数据,包括软件间的依赖关系、开发者的人员组成等.总体而言分成两类数据: 第一类数据是来自软件间的依赖关系;第二类数据是软件在开发过程所产生的行为数据.第一类数据可以从包管理器中获取,第二类数据一般从代码托管平台采集.本文基于2021 年GitHub 全域公开数据集npm (Node.js 标准的软件包管理器),composer (PHP 软件包管理器) 和pip(Python 软件包管理器) 3 个包管理器的数据,所得数据集统计情况如表2 所示.

表2 数据集统计情况Tab.2 Data-set statistics
3.2 根据属性计算结果获取最终评分
模型中的指标可以分为两类: 第一类是取值范围有限的指标,比如,测试覆盖率 (取值范围为 [0,1]),是否有文档 (取值为0 或1,0 表示有,1 表示没有) 和是否有商业支持 (取值为0 或1,0 表示有,1 表示没有) 等;第二类是取值范围很大的指标,比如活跃度、成员个数、发布频率等.对第一类指标进行评分只需要乘一个系数即可保证取值范围是 [0,5],对于第二类指标需要给出具体的评分方法,对属性进行评分的思路是: 将属性计算结果根据其分布规律映射成线性,然后划分等级.
以软件活跃度为例,通过对GitHub 全域软件进行活跃度分析,得到软件的活跃度 (记为A) 与活跃软件数量 (记为N) 双对数分布情况如图1 所示.可以看到软件的活跃度与活跃软件数量的双对数图符合幂律分布.

图1 软件活跃度与活跃软件数量双对数分布图Fig.1 Software activities and the number of active software double logarithmic distribution
使用同样的绘图方法,得出全域软件上的成员数量 (记为Cc) 和活跃软件数量 (记为N) 双对数分布情况如图2 所示,软件的成员数量与活跃软件数量的双对数图也满足典型幂律分布.
图3 展示了关键成员数量 (记为Ccc) 和活跃软件数量 (记为N) 的双对数分布规律.图3 纵坐标取值范围和图2 相近,说明部分软件项目中大多数用户的贡献次数都大于等于3.同时,与图2 相比,图3 的横坐标取值范围更小,说明有一部分软件项目中不存在贡献次数超过2 的用户.这一现象也符合客观规律.
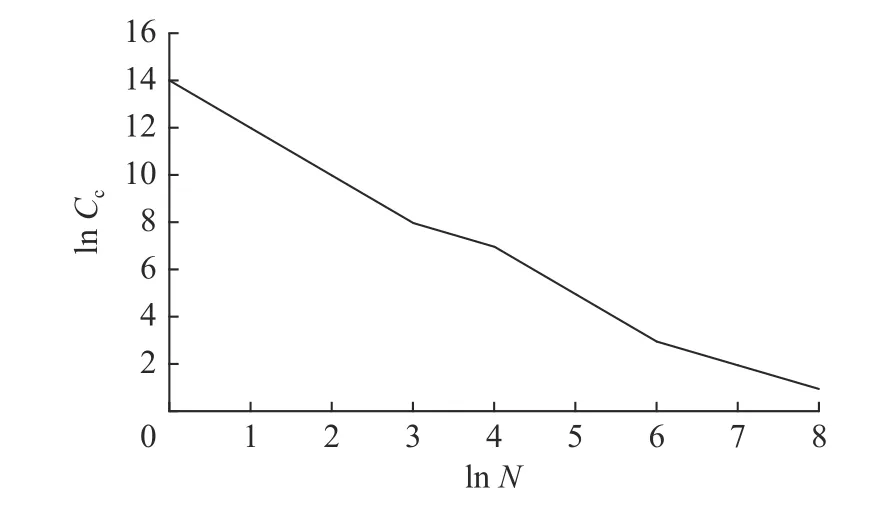
图2 成员数量与活跃软件数量双对数分布图Fig.2 The number of members and active software double logarithmic distribution
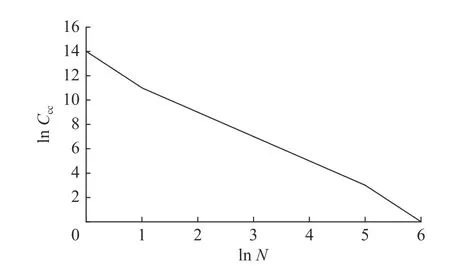
图3 关键成员数量与活跃软件数量双对数分布图Fig.3 The number of core members and active software double logarithmic distribution
以软件活跃度为例,为了能够根据软件活跃度的实际计算结果得到最终取值范围是 [0,5] 的活跃度评分,可以将图1 中的分布拟合成一条直线,拟合结果如图4 所示,先将 lnN的范围均匀地分成5 等份,得到每等份取值为2.由于软件活跃度越高,评分越好.所以,当评分为5 时,lnA=15,对应图4 中直线横坐标为0 的情况;当评分为4 时,lnA的取值对应图4 中直线横坐标为2 时曲线所对应的纵坐标,即12;当评分为3 时,lnA的取值对应图4 中直线横坐标为4 时曲线所对应的纵坐标,即9;以此类推,当评分为2 时,lnA=6;当评分为1 时,lnA=3;当评分为0 时,l nA=0 .

图4 软件活跃度与活跃软件数量双对数分布拟合直线图Fig.4 Dual logarithmic distribution of software activities and the number of active software fits a straight line chart
根据同样的方法,可以得出成员数量、关键成员数量计算结果和评分对照结果,如表3 所示.

表3 软件活跃度、成员数量、关键成员数量计算结果和评分对照表Tab.3 Comparison of software activity,contributor,and core contributor calculation results and score
为了提高计算结果的区分性,每个属性的评分保留小数点后两位.根据上述分析,软件活跃度评分的计算公式为

上式中:Macc为根据软件活跃度计算出来的软件活跃度评分,A为软件活跃度.
软件的成员数量评分计算公式为

上式中:Mc为根据软件成员数量计算出来的软件成员数量评分,Cc为软件成员数量.
软件的关键成员数量评分计算公式为

上式中:Mcc为根据软件关键成员数量计算出来的软件关键成员数量评分,Ccc为这个软件关键成员数量.
使用同样的方法,可以得到其他指标实际计算结果和最终评分之间的关系.
3.3 不同软件可维护性评分对比
以npm 子生态软件webpack (https://github.com/webpack/webpack) 和babel (https://github.com/babel/babel) 为例,webpack 直接或间接依赖了92 个外部软件,babel 直接或间接依赖了80 个外部软件.webpack 和babel 的依赖树深度都为4,这种“宽深”的依赖树结构往往可能招致比较广泛的供应链攻击[6].两者各项评分如表4 所示.

表4 webpack 和babel 评分明细Tab.4 Webpack and babel scoring details

续表4
babel 软件的可维护性评分远高于webpack 软件,且babel 软件属于低风险软件,webpack 为中风险软件.但webpack 软件的依赖影响力高于babel 软件的依赖影响力,因此,一旦webpack 软件出现维护性风险时,对整个生态造成的影响大于babel 软件.综上所述,webpack 软件更有可能为npm 子生态带来可维护性风险.
4 结 语
开源已经成了软件的主流开发模式,软件供应链的开源化影响了整个软件生态的安全性.本文建立了一个开源软件供应链可维护性质量模型,从多个维度对开源软件的可维护性进行了评估,并采集了2021 年的GitHub 行为数据和npm 生态数据进行验证计算.当前工作仍有需要进一步研究的地方,包括: 虽然目前的可维护性度量指标对开源软件属性进行了较为全面的衡量,但是还存在一些需要被补充的属性.比如,源码层面的分析 (包括程序的易分析性、易修改性及稳定性等),以达到对可维护性更加精准评估.本文仅提出了一个探究开源软件可维护性风险的框架,后续在收集到更多的数据后,会进行更加全面的定量分析,进一步证明模型的有效性.本文着眼于开源软件系统的各个部分,即对单个开源软件进行研究.将开源软件供应链作为一个整体进行可维护性度量,从而评价整个供应链的可维护性风险,同样是必要且有意义的,后续会进一步收集相应数据展开研究.
