查询优化器连接顺序评估
2022-09-26项兆坤徐金凯
陈 婷,项兆坤,徐金凯,张 蓉
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
分析型数据库管理系统主要用于完成联机分析处理 (Online Analytical Processing,OLAP) 任务,这类系统被广泛应用于数智供应链与物流科技、金融分析、销售业务分析等数据管理领域,为这些领域提供复杂的分析处理服务.在OLAP 负载中,查询往往会涉及多个关系,即多表连接.数据库查询优化器在处理多表连接查询时,会面对一个复杂的连接顺序选择 (Join Order Selection,JOS) 问题,也称为连接顺序优化问题,即从连接顺序搜索空间中选出性能最优的连接顺序.不同的连接顺序在语义上等价(即能获得相同的结果集),但是查询效率有着显著差异,在执行时间上可能呈现几个数量级的差异.因此,连接顺序的选择是一个十分关键的查询优化问题[1].由于连接操作的交换性和结合性,随着连接表数量的增加,搜索空间的大小会呈指数级增长,如考虑左深树、右深树和浓密树时,N个表连接的搜索空间高达,无法在多项式时间内解决.Ibaraki 等[2]证明了连接顺序选择是一个NP-hard 问题.
在研究连接顺序优化问题时,通常会以查询中的表和连接关系作为结点和边构建连接图,以图的形式展现查询中各表如何连接.在很大程度上,找到最优连接顺序的复杂度与连接图的连接形状有关[3].不同的连接形状具有不同的优化特性,对应着不同的优化策略及优化难度,这为优化器连接顺序的选择带来很大的挑战.
如果计算得到最优连接顺序,那么优化算法本身将会耗费大量时间,反而会降低查询效率.因此,如何在优化时间与优化效果之间进行权衡是连接顺序优化算法需要考虑的核心问题.传统的连接顺序优化算法会对连接顺序的搜索空间进行剪枝,如基于动态规划的方法[4-5]和基于启发式算法的方法[6-8].随着机器学习的发展,目前深度学习[9]和强化学习[10-13]也被运用于处理连接顺序优化问题.因为,连接顺序的选择,在很大程度上决定了数据库分析处理的性能,所以,连接顺序选择问题备受相关领域研究者的关注.然而,面对众多连接顺序选择策略,如何评估它们的优劣还是一个难点问题.评估连接顺序选择策略就是计算优化器所选连接顺序的执行时间与最优连接顺序执行时间的相对差距.文献[14]对已有基于学习的基数预估算法进行评估,分析现有基于学习的方法是否适用于基数预估问题.现有工作没有一整套通用的评估连接顺序选择策略的方法,无法有效评估各种连接顺序选择策略的优劣.同时,目前已有的评测基准和评测工具的数据大多缺乏真实应用数据特征 (如多样的倾斜度),且负载中往往只涉及链式、星型、树型等简单连接形状,不能覆盖所有连接形状,无法针对不同连接形状进行有效评测.
为了有效评测优化器在连接顺序选择上的优化效果,本文设计了面向不同连接形状的连接顺序选择策略评测工具.本文提出了基于主键的确定性数据生成方法、适用于不同连接形状的连接模板生成算法、基于结果导向的参数实例化与过滤谓词生成方法,实现对优化器查询处理性能的评估.
1 相关工作
常见的评测基准,比如,Star Schema Benchmark[15]、TPC-H[16]、TPC-DS[17]主要用于数据库查询执行的整体性能评测,其数据分布为均匀分布,而真实应用场景中的数据往往为非均匀分布,有较大的数据倾斜度,并且其负载仅涉及链式、树型以及星型的简单连接形状.因此,这些评测基准无法对查询优化器的连接顺序选择进行针对性评测.
基于网络电影数据集(Internet Movie Data Base,IMDB)的Join Order Benchmark (JOB)[18]可用于评测基数预估、连接顺序选择,但是其数据集不可扩展,数据倾斜度固定.同时,虽然它提供了相对复杂的连接,单个查询最大连接数为16 (平均值为8),但连接形状均为含环型,因此,无法针对某一特定连接形状进行专项评测,且缺乏连接顺序选择的评测指标.JOB 共有33 个查询模板,每个模板只有2~ 5 个查询,若要评测深度学习和强化学习的连接顺序优化方法,JOB 作为训练数据来说不够充足.许多工作[19-21]会使用JOB 的子集JOB-LIGHT 进行基数预估的评测,它基于简化的IMDB 数据集,仅包含70 个查询,且均为连接数小于或等于5 的星型负载.针对基数预估的评测基准有STATSCEB[22]和IMDB-CEB[23],分别采用真实的数据集STATS 和IMDB,人工构建查询负载.它们缺乏随机可控的连接数目和丰富的连接形状.
目前有许多工作基于现有评测基准的数据集与负载设计针对查询优化器的评测工具,它们大致分为两类.第一类是面向查询优化器的某个特定部分的评测.Gu 等[24]针对查询优化器的代价模型设计了评测工具TAQO,对优化器候选执行计划列表的预估代价排名和真实代价排名进行比较,得到优化器所选执行计划的排名指标,以计算优化器代价模型的准确性.TAQO 只提出了评测方法与评测指标,没有设计数据集与负载,在实验时使用TPC-H 作为测试负载.Qin 等[25]计算代价模型中磁盘代价估计的准确性,实现细粒度的评测方法.
第二类是面向查询优化器整体的评测.Li 等[26]提出了评测查询优化器的工具OptMark,他们利用TPC-DS 的数据与负载,设计了基于质量与效率的评价指标,用以评测整体优化器的端到端性能.OptMark 关注优化器选择的最终物理执行计划的有效性.对于一个查询,在其可遍历的执行计划搜索空间中,优化器所选出的默认执行计划比其他执行计划耗时短,则称该查询为有效查询.有效性是指有效查询在所有查询中所占的比例.由于不同物理执行计划可能拥有相同的连接顺序,该有效性指标不能直观反映连接顺序的优劣.TiDB 参考OptMark 的有效性指标,使用TPC-H 和JOB 的数据集和负载,实现了Horoscope 工具,以评估TiDB 的查询优化器性能.
综上所述,现有的评测基准与评测工具有3 点不足: ①数据缺乏真实应用数据特征,如多样的倾斜度;② 负载缺乏随机可控的连接数目和丰富的连接形状;③缺乏有效的连接顺序评测指标.因此,它们无法充分评测优化器的连接顺序选择问题,无法得到可靠的评测结果.
2 连接形状
连接图是以表为结点,连接关系为边的无向图,展示查询中各表之间的连接关系.示例1 中查询包含4 张表(表A、表B、表C、表D)和4 个连接谓词,该查询的连接图 (图1),具有4 个顶点和4 条边.

图1 示例1 的连接图Fig.1 Join graph of example 1
示例1SELECT COUNT(*) FROM A,B,C,D WHERE A.pk=B.fk1AND A.pk=C.fk1AND C.pk=B.fk2AND D.pk=B.fk3AND A.col1> 100 AND B.col2<=2000 AND C.col1+C.col2> 300 AND D.col1=400;
连接图根据连接形状的不同,可以分为7 类 (图2),分别为链式、星型、树型、环型、含环型、网格型和集团型.
图2(a)是简单的链式连接形状,查询中的表按顺序连接,在实际应用中很常见,同时也较容易优化.图2(b)星型连接常见于数据仓库应用中,此类查询中的表分为一张事实表和多张维度表.事实表是数据仓库中的中央表,存储有事实记录的表,如交易记录、销售明细、系统日志等;维度表用于保存维度的属性值,即事实表中属性的相关详细信息,如日期维度表、产品维度表、用户维度表等.星型可以看成将多张维度表连接到中央事实表.图2(c)树型可以看成是链式和星型的混合类型,连接形式更加随机,会产生更大的连接顺序搜索空间.图2(d)环型中的所有表通过依赖关系连接形成一条环路,处理环路的复杂度高,给某些连接顺序选择策略带来极大挑战.图2(e)含环型的连接图中至少存在一条环路,即可能存在多条环路,增大搜索空间以及延长优化时间.示例1 的连接形状即含环型.图2(f)网格型的连接图呈现网格形状,每张表至少与另外两张表存在依赖关系.网格型由于存在大量的环而难以优化.图2(g)集团型查询中的任意两张表之间都存在一个连接谓词,是连接顺序优化的最坏情况.

图2 连接图的不同形状Fig.2 Shapes of join graphs
连接形状越复杂,对其优化的时间复杂度和空间复杂度就越高.同时,由于不同连接形状的特性,适合一种连接形状的连接顺序优化算法可能不适合另一种连接形状,健壮的优化器需针对不同的连接形状采用不同的优化策略.
3 评测系统整体架构
评测系统整体架构如图3 所示,分为两个部分: 测试场景生成器和连接顺序评估器.测试场景生成器由模式生成、数据生成和负载生成3 个部分组成,连接顺序评估器由查询计划解析、连接顺序枚举、连接顺序评估3 个部分组成.

图3 系统整体架构Fig.3 System architecture
首先,系统读入用户定义的配置文件,配置文件的内容包括: 数据库配置、模式配置 (如生成表数量及规模、各表的属性列数目、各表的属性列数据分布、参与连接的表数量、查询连接图形状等)、输出文件保存路径、其他自定义配置.测试场景生成器根据配置文件中的定义模式进行模式生成,生成每张表的规模、每张表的属性列数目及数据类型、属性列的数据倾斜度、每张表的参照关系等.
然后,数据生成模块采用基于主键的确定性数据生成机制生成各属性数据.负载生成模块包括连接图生成和过滤谓词生成两部分,该模块先基于各表的参照关系采样生成具有不同连接形式的负载模版,再通过结果导向的参数实例化方法生成过滤谓词.
最后,测试场景生成器将所生成的数据和负载通过Java 数据库连接 (Java Database Connectivity,JDBC) 接口导入数据库,将数据库查询优化器所选择的查询计划 (通过“EXPLAIN”关键字得到) 返回给连接顺序评估器.由连接顺序评估器对查询计划进行解析以获得优化器选择的连接顺序,再将该连接顺序与评估器采样的连接顺序共同放入评估池,对评估池中所有连接顺序的性能进行对比,最终输出连接顺序评估结果.
4 测试场景生成器
4.1 数据生成
本文采用基于主键的确定性数据生成方式[27-28]进行数据生成.数据生成器为每个属性列指定生成函数,属性列的值以主键为自变量通过生成函数映射得到.数据生成器规定生成函数必须为满射函数,若满射函数F:X →Y,则Y中的所有元素在X中都能找到原像.假设某张表的主键x∈[0,n],其属性列c的生成函数为F(x) ,则主键x对应属性列c的值为y=F(x) ,其中y∈{y|y=F(x),x ∈[0,n]}.需要注意的是,非数字类型的数据类型 (如Varchar) 需要进行类型转化.通过定义符合分布的生成函数即可保证属性列数据的分布,如高斯分布和ZipFian 分布.
基于主键的数据映射 (生成) 实现了数据感知的参数实例化.在生成过滤谓词时,通过求解各属性与主键的关联关系的满足性约束,即可感知可供采样的数据范围,故而保证查询结果不为空,生成有效的查询.
4.2 负载生成
为了实现对查询优化器连接顺序选择的质量评测,负载需要拥有不同的连接形状、丰富的连接数量以及多样的谓词基数.无论是现有的评测基准负载,还是某现实应用负载都不能包含所有负载特征,代表所有负载.本文的可配置负载生成能够根据配置文件,生成满足特定需求的负载,对负载的覆盖面更广,能更好地评估优化器的优化能力.
负载生成阶段按照给定配置文件从模式中选取规定数量的表以及各表之间的主外键参照关系,进行连接图的生成,接着通过结果导向的参数实例化生成基数不同 (且不为零) 的过滤谓词.
4.2.1 连接图生成
连接图生成器生成连接图G=(V,E) ,其中V是参与连接的表的集合,E是边的集合,E中的每一条边是连接两张表的连接谓词,表的连接关系由主外键参照关系决定.G的初始状态为空集 (G=∅),连接图生成器依次对G进行加点操作 (定义1) 或加边操作 (定义2),直至得到符合配置要求的连接图.
定义1(加点操作) 向连接图G=(V,E)中添加一个结点v,v要满足以下条件:
(1)vV;
(2)存在连接谓词使得v与集合中的某一结点u相连,即存在e=(u,v) ;
(3)若连接形状为树型,则u∈V;若连接形状为链式或环型,则u∈V且u的度为1;若连接形状为星型,则u∈V且u为中央事实表.
定义2(加边操作) 向连接图G=(V,E)中添加一条边e=(u,v),u,v为两个结点,e满足以下条件:
2.2 治疗前后两组MAP、HR、SVV水平对比 治疗后观察组HR水平明显高于对照组,而MAP、SVV水平均明显低于对照组,差异有统计学意义(均P<0.05)。见表2。
(1)eE;
(2)u∈V且v∈V.
适用于不同连接形状的连接模板生成算法的基本思路是: 分别通过加点操作和加边操作为连接图添加新表和新的连接关系 (边) 以生成高质量的多表连接模板,使模板中的连接均为有效的主外键连接,且连接形状与连接数目符合要求,如算法1 所示.

首先,初始化连接图G和度为1 的结点集合D为空集 (行1—2).接着加入第一张表,若生成星型连接,则选择规模最大的表作为中央事实表加入连接图G;若生成其他类型,则从所有表中随机选择一张表加入连接图G(行3—7).然后,根据目标连接形状不断向G中添加结点和边直至结点数量满足规定表数量为止 (行9—23).第9 行|V|表示集合V中元素的个数,即当前G中的结点数量.树型连接的生成,规定每次向连接图G中添加一个结点v与一条边e,即进行一次加点操作和一次加边操作(行10—12).链式连接同样进行一次加点操作和一次加边操作,且边e需要连接结点v和度为1 的结点u.在链式连接生成过程中 (从加入第二张表起),需要同步更新度为1 的结点集合D,确保始终存在两个度为1 的结点,即首尾结点 (行15—19).环型与链式相比,相同的是所有表都处于一条链上,不同的是环型的首尾两张表间存在一条边.最后,环型的生成需要进行一次额外加边操作 (行24—27).星型连接生成将模式中规模最大的表作为中央事实表,随机选择其余表作为维度表.在选择维度表时,每次对连接图进行一次加点操作和一次加边操作,且要求新加入的结点v与事实表存在依赖关系,新加入的边e需要连接维度表v和事实表 (行21).当参与连接的表数量为N时,则算法循环N次,每次向连接图中加入一张表,时间复杂度为O(N) .观察常用的OLAP 评测基准如TPC-H、TPC-DS、SSB、JOB 等,它们单个查询的最大连接数为18,因此,N通常不是很大.
4.2.2 过滤谓词生成
基数预估的结果影响代价模型,从而决定连接顺序的选择.而基数预估分为对基表过滤算子的预估和对连接算子的预估,4.2.1 节已由连接图确定参与连接的关系以及连接条件,本节将在连接图的基础上生成基于单个表的标准过滤谓词.
参数实例化是过滤谓词生成过程中不可或缺的部分,它控制算子的中间结果集大小,从而使得查询优化器选择代价不同的查询执行计划,直接影响查询性能.本文采用基于结果导向的参数实例化算法[28],实现有效的查询参数实例化.谓词参数的取值范围可由主键到属性列的映射函数以及连接条件确定性得到,该算法根据取值范围选择合理的参数,确保经过参数实例化的过滤谓词与连接谓词有效,即无空值返回.
5 连接顺序评估器
首先,连接顺序评估器通过“EXPLAIN”关键字获得查询优化器选择的执行计划,从中提取出选定连接顺序;其次,枚举适当数量的连接顺序 (称为枚举空间),将优化器选择的连接顺序与枚举的连接顺序共同放入同个评估池;再次,强制数据库依次按照评估池中的连接顺序执行,得到各自的执行时间;最后,利用两个评估指标对优化器连接顺序的选择进行评估.
5.1 枚举空间

表1 连接顺序的搜索空间Tab.1 Search space of join order
执行搜索空间中所有连接顺序是十分耗时的,本节采用式 (1),以一定误差和置信水平下的最小样本数量作为枚举空间大小[29].

式(1)中:n是所需要枚举空间大小;Z是置信水平的Z统计量,如95%置信水平的Z统计量为1.96;p是总体的估计差异性,该值一般未知,设定为0.5;e是相对误差.
在实验中设定置信水平为95%,相对误差为10%,即Z=1.96,e=0.1,根据式 (1) 得到枚举空间大小约为97 个 (向上取整).
5.2 评估指标
为了评价查询优化器的连接顺序优劣,本节引入两个评估指标: MRR (Mean Reciprocal Rank)和偏差.MRR 着重于查询优化器所选连接顺序的排名,偏差对比查询优化器所选连接顺序的执行时间与枚举空间中所有连接顺序的执行时间最小值,计算它们之间的相对偏离程度.同时,为了分析基数预估对连接顺序选择的影响,本文使用Q-error 计算基数预估的误差.
(1) MRR
MRR 值常用于检索系统中评估系统的性能,表示正确检索结果在全体检索结果中的排名.其公式为,其中Q代表查询的个数,ri是对于第i个查询,将查询优化器选择的连接顺序和枚举的连接顺序的执行时间从小到大排序,查询优化器选择的连接顺序的执行时间的排名.
若有3 个查询,查询优化器选择的连接顺序排名分别为1、3、5,则可得
(2) 偏差
偏差计算优化器所选连接顺序的执行时间与最优 (最短) 执行时间之间的偏差.其公式为,其中D表示偏差,t表示优化器所选连接顺序的执行时间,tb表示枚举的连接顺序搜索空间中最优 (最短) 的执行时间.
通过MRR 值的排名情况可以判断连接顺序的优劣,但有时虽然优化器选择的连接顺序排名较低,其与最优连接顺序的执行时间却相差不大.因此,MRR 值低并不一定表明连接顺序选择效果差;MRR 值低且执行时间偏差大则说明连接顺序选择较差.本文通过结合MRR 与偏差,对连接顺序选择性能进行有效评估.
(3) Q-error
Q-error 计算优化器的预估基数与真实基数的误差,用以评估基数预估的准确性.其公式为,其中e表示优化器预估的基数,a表示真实的基数,Qe=1 表示预估准确.
6 实验分析
6.1 实验环境和测试场景
本文在OceanBase (v3.1.2)和PostgreSQL (v14)上进行实验,其中OceanBase 为单机版本.数据库分别部署在两台8 核CPU、32 GB 内存的机器上,本文的评测工具部署在一台4 核CPU、16 GB 内存的机器上.
为生成尽可能丰富多变的多表连接负载,测试场景生成器生成20 张不同的表,规模最小为千行(约245 kB)、最大为千万行 (约3.6 GB).每张表拥有数量不等的属性列与外键约束.实验负载包含3~ 9张表的多表连接查询,连接形状包括链式、星型、树型和环型.
6.2 实验结果
本节评估OceanBase 和PostgreSQL 在4 种连接形状 (链式、星型、树型和环型) 下选定连接顺序的性能.测试场景生成器为每种连接形状随机生成50 个查询.连接顺序评估器为每个查询枚举除优化器选择的连接顺序之外的97 个不同的连接顺序,共98 个连接顺序构成评估池,强制待测试数据库以评估池中的规定连接顺序运行查询,从而得到执行时间.具体地,OceanBase 通过“HINT LEADING”关键字实现规定连接顺序,PostgreSQL 通过“SET join_collapse_limit=1” 语句实现规定连接顺序.OceanBase 和PostgreSQL 的评估池是相同的,即二者的评估池包含98 个相同的连接顺序.为了消除执行计划缓存对实验的影响,实验设置关闭数据库的执行计划缓存.注意实验设置3 张表参与连接时只产生链式和环型.
表2 展示了OceanBase 和PostgreSQL 执行4 种连接形状的多表连接查询时的MRR 结果.如表2 所示,对于链式、树型和环型的多表连接,PostgreSQL 的MRR 值均高于OceanBase,表明PostgreSQL 的连接顺序排名整体优于OceanBase,而两者对星型的排名无明显差异.先由MRR 值观察到两数据库的整体连接顺序排名情况,下文结合偏差分布对评估结果进行分析.

表2 OceanBase 和PostgreSQL 执行4 种连接形状的多表连接查询时的MRR 结果Tab.2 MRR results for OceanBase and PostgreSQL when processing multi-table-join queries with four join shapes
图4—6 为箱型图,展示了目标数据的最小值、上四分位数、中位数、下四分位数与最大值,是常用的表示目标数据分布的一种统计图.图4 展示了OceanBase 执行4 种连接形状的多表连接查询时的偏差分布情况,横坐标表示参与连接的表数量,纵坐标表示优化器所选择的连接顺序的执行时间与最优执行时间的偏差.图4(a)展示了OceanBase 处理链式的多表连接的结果分布,当参与连接表的数量为3 时,偏差的中位数为1.3%,偏差的均值为8.9%,位于数据序列25% (下四分位) 至75% (上四分位) 位置的偏差的范围为0~ 11.5%,3 个偏差分布中的异常值 (离群点) 分别为37.7%、39.1%和40.7%.IQR (Inter-Quartile Range) 为内距,又称为四分位差,1.5IQR 的上边缘表示偏离上四分位数1.5 倍距离内的最大极值点,如图4(a)中表数量为5 时的1.5IQR 上边缘为49.7%;1.5IQR 的下边缘表示偏离下四分位数1.5 倍距离的最小极值点,如图4(a)中表数量为5 时的1.5IQR 下边缘为0.当参与连接表的数量小于或等于5 时,偏差大部分低于20%.当参与连接的表数量从3 增长到6 时,偏差整体呈现增长趋势,这表明随着参与连接的表数量的增大,OceanBase 选择的连接顺序与最优连接顺序之间的执行时间偏差越来越大.优化器从连接顺序搜索空间中选择出最优连接顺序的效果降低.图4(b)展示了OceanBase 在处理星型连接时的平均偏差均低于10%,除了当参与连接的表数量为9 时,有一偏差的异常值为73%外,其余偏差的异常值均低于20%,该结果表明OceanBase 对星型连接的处理效果较好,且优化性能稳定.然而经统计,OceanBase 对星型连接的平均执行时间为27 s,而PostgreSQL处理相同查询的平均执行时间只需1.5 s,因此,OceanBase 仍需提升对大数据量负载的优化能力.将图4(c)和图4(a)对比可知,OceanBase 处理树型连接的偏差均值全都高于链式,尤其当表数量为8 和9 时,树型的偏差明显比链式的偏差大,这说明随着连接形状复杂度的增大,优化器的连接顺序优化效果降低.图4(d)的结果展示了OceanBase 处理环型连接的偏差分布变化趋势与处理链式连接的偏差分布变化趋势相似,不同的是其处理链式连接时,图4(a)中异常值的偏差都低于80%,而处理环型时存在偏差高于100%的异常值,这说明存在多表连接负载的实际执行时间比最优执行时间长2 倍以上.观察图4(d)上偏差的最大异常值,OceanBase 选择的连接顺序执行时间为5 484 ms,最优执行时间为2 442 ms,两者相差约3 s,这在实际应用中难以接受.OceanBase 在处理链式与环型连接时,在偏差的异常值上的差异表明存在环路复杂连接会对优化器带来挑战.

图4 OceanBase 执行4 种连接形状的多表连接查询时的偏差分布情况Fig.4 Distribution of deviation on OceanBase when processing multi-table-join queries with four join shapes
为了进一步分析优化器何时错误选择的连接顺序,本节通过查看异常值查询的执行计划,发现此类查询的算子预估基数与真实基数相差较大.异常值查询的单表过滤算子的基数预估Qe的平均值为2.9,连接算子的基数预估Qe的平均值为51.6.OceanBase 通过最值统计、distinct 值统计等统计信息进行基数预估,3.2 版本以上增加直方图统计.在联合谓词和连接谓词的基数预估时,OceanBase 假设数据均匀分布和谓词相互独立,这些假设会导致基数预估存在误差.随着谓词之间的相互交叉增多以及连接层次的深入,基数预估的误差会越来越大.错误的基数估计使得优化器代价模型在计算算子代价时会产生较大误差,最终令优化器选择了性能较差的连接顺序.由此可见,连接顺序选择效果受到错误预估基数的影响较大.
图4(a)中当表数量增加到7 时,偏差整体呈现下降趋势.这是因为本实验设置置信水平为95%、相对误差为10%的枚举空间大小为97 个,该枚举空间与庞大的多表连接搜索空间对比相对较小.连接顺序评估器很可能没有随机选到最优的连接顺序.图5 以OceanBase 为例展示了枚举空间大小对评估结果的影响.当式 (1) 中置信水平为95%、相对误差为10%时,枚举空间大小为385 个.图5 对比了枚举空间为97 个和385 个时,OceanBase 执行链式、星型、树型和环型负载时选择的连接顺序执行时间与最优执行时间的偏差结果,实验设置参与连接的表数量为5.图5 的横坐标分别为4 种类型的枚举空间大小,纵坐标为优化器选择的连接顺序的执行时间与最优执行时间的偏差.从图5 中可以看出,当枚举空间增大时,4 种形状的偏差整体呈现增长趋势,枚举空间为385 个的中位线和均值比枚举空间为97 个的中位线与均值分别平均增长了26.7%和27.1%.结果表明,图4(a)的下降趋势与枚举空间的大小有关.尽管相对较小的枚举空间会影响最终的评估结果,但本文的工具依旧能够发现优化器的不足,如图4 所示,当参与连接的表数量越多,偏差的异常值的数目越多,而偏差的异常值意味着优化器对某些多表连接负载的优化效果很差,使其执行时间明显长于最优时间 (偏差高于50%).
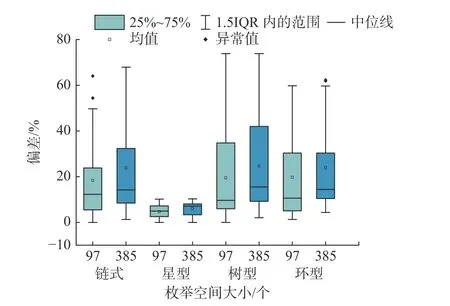
图5 枚举空间大小对评估结果的影响Fig.5 Influence of enumeration space on evaluation results
图6 展示了PostgreSQL 执行4 种连接形状的多表连接查询时的偏差分布情况,横坐标表示参与连接的表数量,纵坐标表示优化器选择的连接顺序的执行时间与最优执行时间的偏差.图6(a)—(d)4 种连接形状平均偏差大部分都低于15%,且4 种连接形状的执行性能没有明显差异,这表明PostgreSQL 优化器的连接顺序选择策略较健壮.但图6(b)展示星型负载的偏差均值皆高于图5(b),且存在更多的偏差异常值,这表明PostgreSQL 对星型连接的连接顺序选择策略有待改进.计算图6 中偏差异常值对应的执行计划的算子基数预估准确度,得到单表过滤算子的Qe平均值为4.6,连接算子的Qe平均值为180.1,与OceanBase 不同的是,PostgreSQL 在大多数情况下低估了算子的基数.PostgreSQL 通过直方图、最频值和distinct 值等统计信息进行基数估计.PostgreSQL 的基数预估基于3 条假设: ①均匀性,所有值 (除了频率最高的项) 都是均匀分布的;②独立性,所有谓词都是相互独立的;③包含原则,连接键的值域有重合.基于以上假设,PostgreSQL 对联合谓词和连接谓词的基数预估同样会存在较大误差.由此可见,PostgreSQL 的连接顺序选择策略也会受糟糕基数预估的影响而产生巨大偏差.由于枚举空间的影响,多表连接的评估池中包含更优连接顺序的概率较低,因此,图6 中当参与连接的表数量为8 和9 时,链式、树型、环型的偏差较低,并且表2 中当参与连接的表数量为8 和9 时,PostgreSQL 运行这3 类形状的负载时MRR 值较高.

图6 PostgreSQL 执行4 种连接形状的多表连接查询时的偏差分布情况Fig.6 Distribution of deviation on PostgreSQL when processing multi-table-join queries with four join shapes
以上实验表明,PostgreSQL 在处理链式、树型、环型连接时的整体连接顺序选择效果优于OceanBase,但在星型连接上的优化效果不如OceanBase.PostgreSQL 在处理4 种连接形状时性能较稳定;OceanBase 除对星型有稳定的优化效果外,在处理其余类型时,随着表数量的增大,优化效果降低,并且受连接形状复杂度的影响,其在处理树型和环型连接时的优化效果劣于链式.
7 结论和未来工作
针对优化器的连接顺序选择问题,本文实现了一个通用的评估工具,有效评测优化器在连接顺序选择上的优化效果.本文使用基于主键的确定性数据生成方法生成测试场景数据;使用适用于不同连接形状的连接模板生成算法以及基于结果导向的参数实例化方法生成测试场景负载;使用连接顺序评估器实现执行计划的解析与连接顺序的枚举,实现对优化器连接顺序优劣的评估.经过对OceanBase 和PostgreSQL 的评估,发现了两者在连接顺序选择效果上的差异与各自的不足之处.
目前,本文评估工具只支持内连接,不支持外连接;支持主键-外键连接、外键-外键连接,不支持非主外键连接.在未来工作中,将扩展本文工具生成负载的连接模式,使其覆盖更全面的负载类型.
