基于查询频率的混合事务分析处理数据同步优化
2022-09-26唐永金孙家博
唐永金,孙家博,蔡 鹏
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
随着互联网技术的快速发展,无论是互联网企业还是传统金融机构,业务积累的数据量都在快速增长.为了充分挖掘数据潜能,人们需要对数据进行实时分析处理.但是数据分析要消耗大量系统资源,在处理OLTP (Online Transaction Processing) 和OLAP (Online Analytical Processing) 请求时需要做好资源隔离,否则,OLAP 处理会严重影响OLTP 的性能以及应用端的用户体验.因此,现有的混合事务分析处理 (Hybrid Transactional Analytical Processing,HTAP) 系统大多采用解耦存储设计[1],即将OLTP 和OLAP 的数据分布在不同的副本.在解耦存储的 HTAP 系统中,OLTP 负责处理读写事务请求,将产生的日志发送给OLAP,OLAP 将收到的日志进行回放并更新到本地,为数据分析提供数据.
解耦存储后虽然做到了资源隔离,但是也产生了数据新鲜度问题[2],即OLAP 端的数据相较OLTP 存在延迟.对于一些实时分析场景,例如,系统监控、在线购物、无人驾驶等,数据新鲜度对分析结果有着非常重要的影响.在这些实时分析场景下,分析预测结果的准确性主要依赖于OLTP 端中所产生的最新数据[3-5].OLAP 端数据新鲜度的主要影响因素包含日志发送速度和日志回放速度.HTAP 系统在实际应用中,事务处理和查询分析负载通常来自不同的应用,实时分析应用往往只需要访问OLTP 端所产生的最新事务数据的小部分.基于表分组的日志并行回放方法[6]设计了针对表日志量的回放资源分配优化.但是这种算法从本质上,对每个表的日志都是一视同仁的,没有根据HTAP 工作负载的特点专门设计.
本文工作的目标是为HTAP 系统提供一种更高效的并且侧重提高OLAP 数据新鲜度的数据同步方法.本文在基于表分组的日志并行回放方法基础上,引入针对HTAP 工作负载特点的专门优化.根据 OLAP 端查询频率将表分为高频查询表和低频查询表.在保障数据一致性的前提下,OLTP 端实现了高频查询表优先的日志发送方法.同时,本文所使用的日志并行回放方法也针对高频查询表做了优化.引入优先级的日志发送方法,会导致不同表的日志回放队列可能存在较大的负载压力差距,进而产生数据倾斜问题.为保证回放效率,设计了基于负载压力的动态资源分配方法.解决了高频查询表日志优先发送导致的乱序日志冲突.通过版本号解决行的写写冲突,同时设计事务提交日志队列组,实现主节点和副本节点相同表的事务提交顺序一致.
综上所述,本文的主要结果为:
(1) 提出了由OLAP 端表查询频率驱动的优先级数据同步方法;
(2) 基于动态分配思想解决了高频查询表的数据倾斜问题;
(3) 设计了针对优先级数据同步的乱序日志冲突解决方案;
(4) 通过原型系统TPLR (Table-ID Based Parallel Log Replay)验证了本文方案的有效性.
1 相关工作
为了有效保证OLTP 端和OLAP 端数据的隔离性,在解耦存储的HTAP 系统中,分别为OLTP端和OLAP 端构建一个独立的数据库实例.
通过ETL (Extract Transform Load) 更新数据仓库的传统方法能够提供较好的性能隔离,但是由于其更新周期较长,OLAP 端在分析查询时无法保证数据的新鲜度.BatchDB[7]为了保证 OLTP 端和OLAP 端的隔离性,使用副本在不同的机器上或者在同一个机器不同的NUMA (Non-Uniform Memory Access) 节点上,并采用周期性同步和 OLAP 端主动请求同步两种同步方式来保证数据新鲜度.Oracle 提出双重格式[8],在内存中针对OLTP 端以行格式存储数据、OLAP 端以列格式存储数据,在执行查询时,会结合OLTP 端的日志返回最新的数据来保证数据的新鲜度.Micorsoft SQL Server[9]也是维护了两份副本,其通过避免同步OLTP 端被频繁修改热数据的方式来减小数据同步开销.F1 Lightning[10]将HTAP 作为一种服务,用来连接相互独立的 OLTP 端和 OLAP 端.这种解耦合的HTAP 设计能减少OLAP 对OLTP 端的影响.F1 Lightning 要求在每次执行查询操作时,OLAP 端都默认使用最大的安全查询时间戳,这种设计给数据新鲜度带来负面影响.TiDB[11]为 OLTP 端和OLAP 端使用独立的数据存储,基于Raft 协议保证数据的一致性和高可用性.在执行查询操作时,OLAP 端会发起校对和更新请求,在确保数据包含读取请求时间戳之后才会返回数据.
传统的串行日志回放方式,无法发挥机器多核优势,导致在负载压力较大的情况下,副本节点的数据版本远远落后于主节点数据版本.并行日志回放技术的核心问题是确定性 (数据一致性的保证)和并发性 (多核架构上的性能需求) 之间的矛盾.MySQL (My Structure Quest Language) 在5.7 版本提出组提交技术,MySQL 在主节点对事务分组,按组进行提交,同一个组内事务不冲突.在日志里添加组提交信息,副本节点回放时根据组提交信息,对同一小组的事务并行回放.这种方法的并行度依赖主节点的事务并行度,因此,在主节点事务冲突严重的情况下,日志回放的并行度会很低.KuaFu[12]保证并行回放的方式是在回放前通过分析日志生成一个写写依赖图,让无依赖关系的事务可以并行回放.但是,分析和建立事务依赖图的性能开销较大,并且依赖图以事务粒度的解决冲突仍然对并行度有所限制.Taurus[13]针对内存数据库的单流日志方案提出了一种并行日志回放方案.该方案兼容数据日志和命令日志,使用多个日志流提高主节点日志回放速度.Taurus[13]引入一种叫做日志序列向量的轻量级依赖跟踪机制,基于该向量捕获事务之间的依赖关系,确保在日志记录恢复中正确执行依赖关系.日志序列向量在日志数据量较大的情况下,记录和跟踪事务依赖关系会产生较大的开销.
针对多版本数据库的日志并行回放也存在一定的技术挑战.由于数据是多版本的,并发回放使得用户在读取数据时,所需的版本可能还不存在,即使存在也无法确定是否为正确的版本.为了解决这个问题,可以将主节点记录的所有可能的版本也传送给副本节点,使得副本节点可以根据事务的顺序推断出所要读取的正确版本,保证回放可以并发执行.
在传统的并行日志回放方法中,为了判断事务间是否存在冲突,需要检查并判断事务间的依赖关系,这个过程将会对系统产生较大的性能影响.学术界也提出了一种基于Session ID 的日志调度回放方法[14],将日志按Session ID 分组,高效分发给日志并行回放器,比起传统基于Transaction ID 的方法减少了并行回放线程之间不必要的冲突.这种方法在日志并行回放产生冲突时,依然以事务为粒度进行阻塞等待.
在现有工作中,有将日志根据表分组并行优化的方法[6],每个表拥有自己独立的回放队列,并且回放队列的线程资源是根据所对应表的日志总量动态调整的.这种方法对于不同表之间仍然是平等的,比较适合主备负载拥有相同数据特征的场景,没有对于HTAP 这种主备负载差别明显的场景进行优化.
2 系统架构
本文设计了实现多版本的内存数据库原型TPLR,图1 展示了TPLR 系统架构.TPLR 主要基于MySQL 中日志生成和回放模块进行修改实现.TPLR 系统架构由OLTP 主节点和OLAP 副本节点构成,并通过网络互连.TPLR 中主节点接收事务处理请求,副本节点负责查询分析请求.主节点定时同步副本节点的查询统计数据,分析统计数据,将表分为高频查询表和低频查询表.在日志发送阶段,经过日志发送模块的预处理,在保证数据一致性前提下,提升高频查询表的发送优先级.日志传送到副本节点后,由日志调度模块负责解析日志,并根据解析得到的Table-ID 等信息对日志进行分发调度.日志回放模块负责对日志并行回放,同时根据任务队列的负载压力,动态调整回放线程资源,事务所对应的日志记录完成回放并提交后,相应的数据记录才对查询操作可见.副本节点面对客户端的查询请求,需要检查当前数据是否满足数据新鲜度要求,如果目前数据状态无法满足,请求就需要等待日志回放与数据更新.
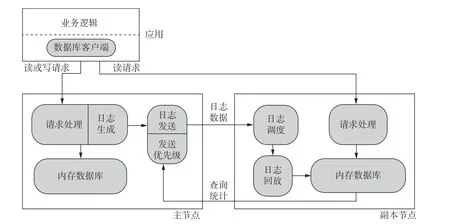
图1 TPLR 系统架构Fig.1 TPLR system architecture
TPLR 的数据记录格式主要特点是通过一个版本链来连接不同的版本,每条所记录的元数据除了包含主键和值外,还包含事务号、时间戳和行版本号.事务号表示主节点中事务的提交顺序,时间戳表示事务在主节点提交的物理时间,行版本号表示该条记录被实际修改的次数,在副本节点中可以用于解决写写冲突.TPLR 在日志生成阶段和常规日志相比添加了行版本号,事务DML (Data Manipulation Language) 操作数以及事务处理表数,主要是为了帮助解决副本节点中的数据一致性问题.
3 数据同步方法
3.1 日志格式
本文数据同步所使用的日志格式为行级日志,该日志记录数据库表结构变更以及每一行记录被修改的形式.行级日志不会记录类似select 和show 这些对数据本身无影响的操作,因此,只读操作不会影响数据同步.常规行级日志相关字段包括日志类型、事务号、操作类型、主键和值等.本文为保证数据一致性额外添加了一些新字段.
在日志处理过程中,需要根据日志类型信息将数据操纵语言日志和事务提交日志分开处理.其中DML 日志包含主节点插入、删除、更新操作,记录表结构和表数据的变化.事务提交日志记录事务提交时的相关信息,一般作为事务完成的标志.
本文实现原型使用了多版本并发控制技术.这种技术使得对行记录的修改不会覆盖旧数据,而是创建一个新版本记录,因此,需要在DML 日志中添加行版本号信息来保证在并行回放时,对数据行的更新顺序.
在事务提交日志中,所添加的事务DML 操作数 (Transaction DML Numbers,TDN) 主要记录每个事务中DML 记录数.在日志并行回放过程中,事务提交日志与DML 日志并行被处理,事务提交日志需要先根据DML 操作数确定是否所有DML 日志都回放完毕,再确定是否进行事务提交.
事务提交日志还增加事务处理表数 (Number of Tables in the Transaction,NTT),记录每个事务中涉及DML 操作的表的个数.NTT 主要是区分事务是否涉及多个表.如果事务涉及多个表,则需要按照串行顺序发送,否则将其视为单表事务,根据查询频率分类,对发送顺序进行调整,例如,将高频查询表事务日志优先传送.
3.2 日志发送方法
TPLR 基于查询频率的日志发送方法的基本思想是在能保证数据一致性的前提下,优先发送高频查询表,即通过OLAP 端的查询频率来决定日志发送优先级.图2 为日志发送预处理的流程.首先,将待发送日志数据解析后存到发送缓冲区;然后,在缓冲区中将日志根据NTT 分为单表事务和多表事务;最后,当缓冲区填满时,对日志进行预处理,目的是提升高频查询表的传送优先级.不过这里对于多表事务不能进行预处理,因为无法根据表查询频率判断多表事务的提交顺序.
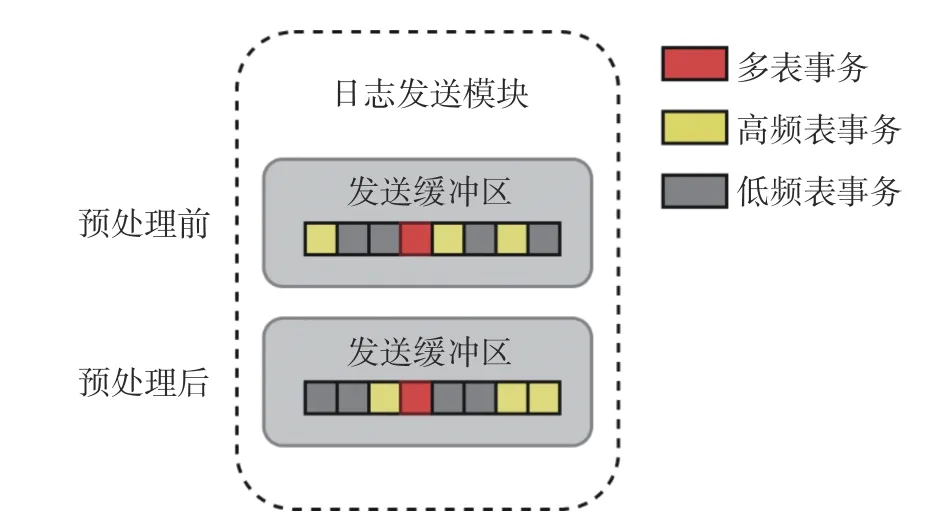
图2 日志发送预处理Fig.2 Log sending preprocessing
3.3 日志回放方法
TPLR 日志并行回放的基本思想是多线程并行处理DML 日志,同时解决多线程处理的数据一致性问题.在回放过程中重点优化回放速度,尽可能减少不必要的冲突,最小化系统的可见性延迟.图3展示了日志调度和日志回放.

图3 日志调度和日志回放Fig.3 Log scheduling and log replay
日志调度流程主要分为以下3 步.
(1) 副本节点的日志调度器收到主节点发送的日志数据后,将会对日志数据进行初步解析和切分成独立的日志记录.
(2) 日志调度器根据日志记录的类型和表名,对日志记录进行分组.日志记录的类型是 DML 操作日志,将会根据表名被分配到该表所对应的 DML 日志队列.日志的类型是事务提交日志,则根据TNN 判断日志相对应的事务是否为单表事务,对单表事务只需要将日志放入相对应事务提交队列,对多表事务则将日志复制多份,添加到每个表所对应的日志提交队列.
(3) 日志调度器完成对日志记录的分配后,副本节点中每个表所对应的回放线程将会同时回放所负责的日志记录.图3 中每个日志队列后分配的回放线程数不同,体现了资源分配的动态性.当事务所对应的日志记录回放完成且该事务的提交日志记录位于事务提交日志队列的队头时,该事务可提交.当事务完成提交后,该事务所对应的数据记录对查询操作可见.
在并行日志回放过程中,必须保证查询操作在副本节点中所查询到的数据与在主节点中所查询到的数据是一致的,即日志记录必须保证在副本节点中可见顺序与主节点中提交顺序是一致的.为了保证数据一致性,TPLR 中为每个表维护唯一的事务提交日志队列,并通过串行回放事务提交日志队列来保证副本节点与主节点中的每个表的事务提交顺序一致.
日志并行回放具体可以分为回放和提交两个阶段.第一阶段,回放线程并行回放所有的日志记录,并更新到副本节点中,但此时数据对查询操作不可见.第二阶段,事务提交日志满足提交条件时完成提交,即实现数据记录对查询操作可见.
第一阶段,具体流程可以分为以下3 步.
(1) 回放线程从所对应的日志记录队列中弹出日志记录并完成解析.
(2) 回放线程根据日志记录解析出的信息,在副本节点中查找该日志记录所修改的数据记录.
(3) 如果在 (2) 中查找为空,就将日志解析出的数据记录作为新纪录创建并插入,直接更新到数据表中.如果在 (2) 中查找不为空,说明数据记录不是第一次创建,需要将其与旧版本数据记录的行版本号进行比较.如果行版本号是连续的,则可以将新数据记录更新到所对应的版本链中;如果行版本号不连续,则需要等待行版本号更早的日志回放.
第二阶段执行过程展示在算法1 中.首先,回放线程会从事务提交日志队列队头中获取事务提交日志记录,解析日志获取事务号和提交时间戳.执行完第一阶段,事务DML 操作数d为0 时,说明日志回放完成,达成了提交条件,可以将该提交日志从队列中弹出,并对事务的NTT 值执行减1 操作.当事务处理表数n为0 时,更新当前表中已提交的事务最大提交时间戳.此时,该事务完成提交,其所对应的数据记录对副本节点中的查询操作可见.

3.4 回放资源分配
当数据表在OLAP 端和OLTP 端都被标识为高频时,回放算法会因为优先传送机制产生严重的数据倾斜问题.解决这一问题的主要思路是,在并行日志回放过程中,对每个表所对应的回放线程资源随着负载变化进行动态调整.特别需要说明的是,不能简单根据高频查询表分类,提前确定线程资源分配比例,因为高频查询表不一定是OLTP 端的高频更新表,提前确定线程资源分配比例容易造成线程资源浪费.
本文将回放队列的回放线程数量与其所对应表待处理日志记录数据总量设置为正相关.当主节点中的工作负载发生变化时,每个表的更新情况也可能发生变化,积压的待处理日志记录数据量也会变化,在副本节点中也需要重新组织分配每个表的线程资源.因此,为了更合理地为每个表分配回放线程资源,通过以下公式来计算负责每个表所对应的日志记录的回放线程数.

上式中:li(或lj)为表i(或j) 所对应的日志记录待处理数据总量,ti(或tj)为表i(或j)所对应的回放线程数量,st表示回放线程总数.式 (1) 表示任意两个表的日志记录数据总量与其所对应的回放线程数量的比值是相等的,即每个回放线程负责回放的日志记录数据量是相同的.
4 冲突检测与处理
在引入优先级日志发送后,日志本身可能不再是顺序的,为了保证查询服务的正确性,需要设计新机制,保证副本节点中行记录更新次序和事务提交顺序与主节点一致.
传统以事务为粒度的并行回放算法的冲突检测,一般要先分析和建立事务之间的依赖关系,只有不存在依赖关系的事务才能并行执行.这种处理方式主要存在两个问题: ①事务依赖关系的分析需要消耗额外系统资源;② 整体并行度较低,因为事务冲突的本质原因是不同的事务修改了同一条数据记录,然而事务中的其他日志记录可能并不存在冲突,理论上是可以并行回放的.
本文将日志并行过程的冲突问题转化为序列化问题.在回放过程中,如果发现待修改的行记录的版本号与当前日志记录中的行版本号不连续,必然存在其他线程正在回放行记录的早期版本,因此,需要等待其他线程完成回放,以保证行记录更新的有序性.图4 为并行日志回放冲突示例.
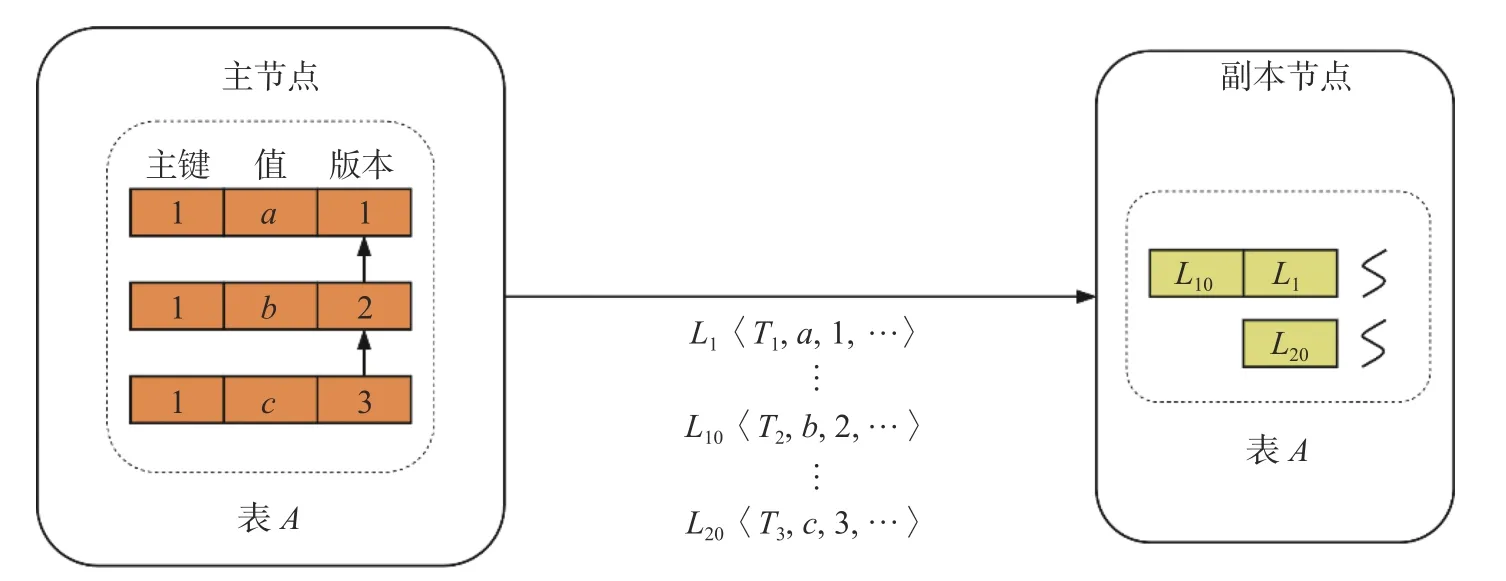
图4 并行日志回放冲突示例Fig.4 Parallel log replay conflicts
主节点中的模拟行记录经历3 个事务处理产生了3 个版本,并通过版本号标识更新顺序.主节点中记录值最初为a,顺序更新为b和c后分别产生了两个新版本.对应产生一条插入日志L1和两条更新日志L10,L20.在图4 中将传输的日志记录表示为日志名〈事务号,记录值,行版本号,日志其他信息〉,可以看到已经传输了L1,L10,L20共3 条日志.副本节点通过日志调度器将日志分配到所对应的日志队列中进行回放.在回放L1日志时发现行版本号为1,即初始版本号,因此,不需要进行行版本号判断,可以立即执行.对于L10,L20,假设L20日志先解析完毕,被调度线程进行回放.回放线程发现L20所对应的行版本号是3,此时副本节点中该数据记录的最新行版本号是1,两个行版本号不连续,这说明行版本号为 2 的日志记录还未完成回放,此时日志记录L20需要等待日志记录L10回放完成后,才能继续回放.综上所述,通过将行更新操作序列化,解决了并行更新行产生的写写冲突,日志回放的粒度也能从事务级别细化到行级别.
5 实 验
5.1 实验环境及测试负载
硬件环境: 本系统部署在单个物理节点上,该节点含有1 个CPU (Central Processing Unit),型号为Intel Xeon Processor (Cascadelake) @2.9 GHz 32 核;内存为128 GB;操作系统为64 位CentOS Linux release 8.2.
测试负载: 本文使用OLTP-Bench 工作负载生成工具生成TPC-C 负载来模拟现实业务场景,并以MySQL 为OLTP 端生成行级日志.TPC-C 包含 New-Order、Payment、Delivery 3 种读写事务.在具体的实验中,为了模拟不同工作负载的变化,在实验中设置了4 种不同事务比例的工作负载.工作负载TPCC−1,事务New-Order、Payment 和 Delivery 的比例是 1∶1∶1,此时DML 操作涉及8 个表.工作负载 TPCC−2 中只有事务 New-Order 和Deliery 的比例为1∶1,DML 操作涉及6 个表.工作负载 TPCC−3 中只有事务 New-Order 和Payment 的比例为1∶1,DML 操作涉及8 个表.工作负载TPCC−4 中只有事务 Delivery 和Payment 的比例为1∶1,DML 操作涉及7 个表.同时实验选择ORDER-LINE 表作为高频查询表,因为,该表在所有测试工作负载中都有涉及,并且总DML 日志数也是所有表中最多的.
本文共设计4 种不同的日志回放方法,互为对照.方法1 用TPLR 表示,使用本文设计的TPLR方法进行测试.方法2 用MLR (MySQL Log Replay)表示,使用MySQL 原生的日志并行回放方法进行测试.方法3 用TPLR_avg 表示,设计为在TPLR 方法的基础上将所有表设为同等的优先级.方法4用TPLR_Nodynamic 表示,设计为在TPLR 方法的基础上将线程分配固定为平均值.
5.2 日志回放性能分析
第一组的实验目的是通过对比MLR、TPLR_avg、TPLR_Nodynamic 和TPLR 4 种方法在回放相同工作负载生成的高频查询表日志所需的时间,分析在不同方法中,高频查询表的数据同步效率.首先,通过OLTP 端执行事务并生成所对应的日志记录;然后,统计4 个实验组对日志回放所需的时间.4 种工作负载TPCC-1 (图5(a))、TPCC-2 (图5(b))、TPCC-3 (图5(c))、TPCC-4 (图5(d))在不同方法上测试得到的回放时间.
通过观察图5 中的对比实验可以发现,在不同的工作负载下,随着日志记录数据量的增长,TPLR 方法均能比MLR 和TPLR_avg 方法更快回放完高频查询表的日志.同时要特别说明,与TPLR 相比,其他两种回放算法在高频查询表日志记录位于日志末尾时,需要回放所有日志数据.
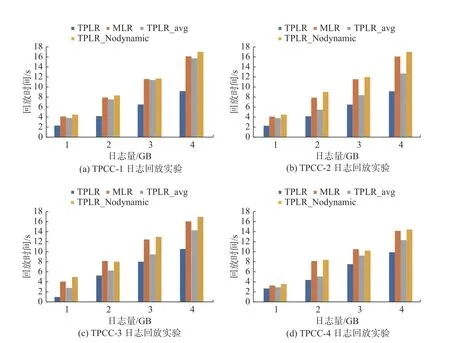
图5 回放时间对比Fig.5 Comparison of replay time
从MLR 和TPLR_avg 的实验结果能看出,在4 种工作负载下TPLR_avg 日志回放时间都比MLR更短,即使没有针对性回放,基于Table-ID 分组的日志并行回放方法的性能仍然是比较有竞争力的.主要原因是基于Table-ID 对日志分组回放冲突概率较低,并行度较高,能发挥多核架构性能优势.
与TPLR 方法相比,TPLR_Nodynamic 的回放时间较长,因为每个表待回放日志数量不同,平均分配线程后,每个表所对应工作线程回放完成时间也不同,导致部分回放线程闲置.与平均分配线程的方法不同,动态分配方法对于日志记录数据量较多的表,将分配更多的回放线程资源,日志记录数据量较少的表则分配较少的回放线程资源,避免因为等待日志记录较多的表,而影响事务的提交.
5.3 数据新鲜度分析
对于实时性要求比较高的查询分析操作,数据新鲜度对实时查询分析操作的结果以及响应时延有着非常重要的影响.本文对HTAP 系统的数据同步过程进行优化的一个重要目的就是提高副本节点中的数据新鲜度,因此,本节将通过相关实验比较不同方法下副本节点中的数据新鲜度.在相同时间下,副本节点中的数据版本越高,说明副本节点中的数据新鲜度越高.在具体实验中,为了有效判断副本节点中的数据新鲜度,先通过每隔一段时间获取一次已提交事务数量的方式来判断副本节点中的数据新鲜度,再通过相同时间下事务提交的数量比较不同方法下副本节点中的数据新鲜度.这里特别说明,通过事务提交数判断数据版本的前提是,回放日志已经将不修改数据的事务过滤掉了,不会出现提交事务之后数据本身并未发生改变这种干扰统计准确性的情况.
图6 展示了TPLR 方法和MLR 方法所对应的数据新鲜度变化.从图6 中可以发现,与MLR 方法相比,TPLR 方法能够持续保证高频查询表拥有更高的数据新鲜度.TPLR 和MLR 的高频查询表的数据新鲜度差距随着时间推移不断增大.从实验结果可以看出,TPLR 方法比MLR 方法多出的预处理操作耗时对回放效率影响不大.同时,因为并行回放而引入的事务提交队列,在实验过程中并不是一个瓶颈,只要DML 日志记录之间没有产生冲突,事务的提交就不会影响到日志的回放速度.

图6 数据新鲜度对比Fig.6 Comparison of data freshness
6 结 语
在HTAP 解耦存储架构下,OLAP 端需要更有针对性、更高效的方法来同步OLTP 端数据,以保证数据新鲜度能达到实时数据分析的要求.本文根据OLAP 端的查询统计数据,将表分为高频查询表和低频查询表.基于统计好的查询频率,在OLTP 端传送日志数据时,TPLR 会调整日志发送的优先级,提升高频查询表的发送速度.同时,在OLAP 端,TPLR 使用基于表分组的日志并行回放方法,对回放队列针对性倾斜线程资源.最后,通过实验证明,与传统的基于日志的数据同步方法相比,本文所提出的数据同步方法针对HTAP 负载特点进行优化,保证了更高的数据新鲜度.
