Autonomous maneuver decision-making for a UCAV in short-range aerial combat based on an MS-DDQN algorithm
2022-09-22YongfengLiJingpingShiWeiJingWeiguoZhngYongxiLyu
Yong-feng Li ,Jing-ping Shi ,b,*,Wei Jing ,Wei-guo Zhng ,b,Yong-xi Lyu ,b
a School of Automation,Northwestern Polytechnical University,Xi'an,710129,China
b Shaanxi Province Key Laboratory of Flight Control and Simulation Technology,Xi'an,710129,China
Keywords:Unmanned combat aerial vehicle Aerial combat decision Multi-step double deep Q-network Six-degree-of-freedom Aerial combat maneuver library
ABSTRACT To solve the problem of realizing autonomous aerial combat decision-making for unmanned combat aerial vehicles(UCAVs)rapidly and accurately in an uncertain environment,this paper proposes a decision-making method based on an improved deep reinforcement learning(DRL)algorithm:the multistep double deep Q-network(MS-DDQN)algorithm.First,a six-degree-of-freedom UCAV model based on an aircraft control system is established on a simulation platform,and the situation assessment functions of the UCAV and its target are established by considering their angles,altitudes,environments,missile attack performances,and UCAV performance.By controlling the flight path angle,roll angle,and flight velocity,27 common basic actions are designed.On this basis,aiming to overcome the defects of traditional DRL in terms of training speed and convergence speed,the improved MS-DDQN method is introduced to incorporate the final return value into the previous steps.Finally,the pre-training learning model is used as the starting point for the second learning model to simulate the UCAV aerial combat decision-making process based on the basic training method,which helps to shorten the training time and improve the learning efficiency.The improved DRL algorithm significantly accelerates the training speed and estimates the target value more accurately during training,and it can be applied to aerial combat decision-making.
1.Introduction
Air domination is becoming more and more important in modern warfare.Among recent developments in this area,unmanned combat aerial vehicles(UCAVs)have attracted worldwide attention.UCAVs have the advantages of high mobility,low cost,and zero risk of casualties among their operators.In the past,UCAVs have been used mainly for aerial reconnaissance,battlefield monitoring,attracting fire,and communication relay tasks[1].With developments in weaponry,computer intelligence,and communication technology,there has been continuous improvement in the performance of UCAVs[2,3],and they are likely to become a mainstay of military equipment,able to perform aerial combat,ground fire suppression,and acquisition of air dominance[4].
Despite this great improvement in performance,however,it is difficult for UCAVs to carry out all of their complex tasks independently in an increasingly complex combat environment,and most of these tasks cannot be separated completely from human intervention.With currently available technology,it is necessary for a ground controller to control a UCAV through a task control station.This control method suffers from delays and is prone to electromagnetic interference.An interference attack can interrupt communication between base station and UCAV[5].It is therefore essential for air forces to develop UCAVs with autonomous combat capability.
With the rapid development of artificial intelligence(AI),it has now reached a level where it has great potential for application to autonomous aerial combat.The development of the ALPHA intelligent aerial combat system in the United States[6]indicates the likelihood that future aerial combat will no longer be between human and human,but rather between human and machine or between machine and machine[7].UCAVs will evolve from simple remote control to intelligent and autonomous control,and equipped with intelligent combat decision systems,will graduallyreplace piloted aircraft,with consequent improvements in combat effectiveness and reductions in cost.In close combat,a UCAV will be able to select appropriate flight control commands according to the current combat situation,seize a favorable position,and find an opportunity to shoot down the enemy aircraft and protect itself.

Abbreviations 6-DOF Six-degree-of-freedom AI Artificial intelligence BP Back-propagation DDPG Deep deterministic policy gradient DRL Deep reinforcement learning GWO Grey wolf optimizer MS-DDQN Multi-step double deep Q-network PID Proportional—integral—derivative UCAV Unmanned combat aerial vehicle
In the increasingly complex aerial combat environment,an autonomous maneuver decision requires a UCAV to generate appropriate maneuver control commands automatically in different aerial combat situations.In the past few decades,aerial combat decision-making methods have become divided into two categories:traditional methods and those based on AI.The traditional methods for maneuver decisions include pursuit evasion games[8—11],differential game strategies[12—15],game theoretical methods[16],influence graph methods[17—20],and Bayesian theory[21—23].For example,the differential game method describes the dynamic decision-making process of aerial combat through a differential equation and thereby determines the optimal behavior of a UCAV relative to its target.This enables the UCAV to respond rapidly to changes in the combat environment,but,owing to the limitations of real-time calculation,it is difficult to apply this approach in complex environments[12].Game theory has been used to model UCAV aerial combat decisions in those situations that are common to all aerial combat environments,but the timesensitive nature of information in complex environments will have a deleterious effect on some decisions.Therefore,a constraint strategy game model for time-sensitive information in a complex aerial combat environment has been proposed[16].This model provides improved decision-making for a UCAV in both attack and defense.In another approach[21],aerial combat is regarded as a Markov process,and Bayesian reasoning is applied,with the weight of maneuver decision factors being adjusted adaptively to give an improved objective function and enhance the superiority of the UCAV.Although these decision algorithms can improve the efficiency,robustness,and optimization rate of decision-making to some extent,the frequent reasoning processes that they require increase the optimization time,leading to slow responses of the UCAV,which is not suitable for the modern battlefield environment.
Methods based on AI include expert system methods[24—26],genetic learning algorithms[27],neural network methods[28—30],and reinforcement learning algorithms[32—34].Expert system methods are widely used in AI,and the associated techniques are mature.In the context of UCAV control in a combat environment,these methods establish rule sets in the knowledge base by using if—then rules according to data provided by pilots.The situation and state of motion of both sides in the combat are predicted,and pseudo-random numbers are used to generate corresponding maneuver commands according to a certain probability.However,the disadvantage of this method is that the rule base is complex and has poor generality,and therefore it needs to be continually debugged.In Ref.[27],a decision model for aircraft maneuvering was designed based on a genetic learning system.By optimizing the maneuver process,the aerial combat decision-making problem in an unknown aerial combat environment can be solved.The corresponding tactical actions can then be generated in different aerial combat environments.However,the parameter design of this method is subjective and cannot be applied flexibly.A decisionmaking system using a neural network technique has been shown to have strong tracking accuracy for highly maneuverable targets[28].However,this neural network method needs a large number of UCAV aerial combat samples for its learning process,and a sufficient number of such samples are not available.To solve the uncertain factors of UCAVs in aerial combat,the method proposed in Ref.[31]forecasts the target state using the grey wolf optimizer(GWO)method and can be used for real-time optimization.
In contrast to other methods based on AI,reinforcement learning algorithms for UCAV control base their learning process on continuous trial-and-error interactions between the agent and the environment.According to feedback from the environment,these algorithms generate a strategy and then act according to this strategy to make the UCAV continuously interact with the environment and achieve the dominant position in aerial combat.Further feedback and consequent modifications of the strategy finally lead to an optimal strategy.Since the reinforcement learning process does not usually require training samples,it is able to optimize behavior through rewards obtained from environmental feedback alone[32].To improve the computational efficiency of reinforcement learning,in the approach proposed in Ref.[33],expert experience is used as a heuristic signal to guide the process of reinforcement learning and neural network training.In Ref.[34],an intelligent aerial combat learning system based on the learning mechanism of the brain was proposed,with the aim of training UCAVs by simulating human reasoning processes and carrying out autonomous learning.In Refs.[35—37],by combining neural networks with reinforcement learning,a deep reinforcement learning(DRL)algorithm was constructed to improve operational efficiency of UCAVs.The deep deterministic policy gradient(DDPG)method is another network-based DRL method.It can deal with the learning problem in a continuous action space.Using this method,a driver can be designed,and a maneuver strategy can be established to solve for the continuous action values[38—40].
However,the DRL algorithm has the problems of slow training speed and convergence speed.At the same time,under the conditions of aerial combat,the aircraft model itself is nonlinear and the flight trajectory of the target is uncertain,leading to difficulties in UCAV maneuver decision-making.To solve these problems,this paper adopts the following approach:
(1)The particle model of UCAV is used in most papers on air combat maneuver decision,in this paper,We constructed a six-degree-of-freedom(6-DOF)UCAV model.In the establishment of the 6-DOF UCAV situation assessment function,not only the angle,height,environment and missile attack performance of UCAV are considered,but also the performance of UCAV is fully considered to solve the problem of UCAV out of control.The 6-DOF model is more in line with the actual application needs,and has higher authenticity and practicability.
(2)The control law is designed to control the flight path angle,roll angle,and flight velocity,which makes the 7 classic maneuver actions are extended to 27 so that a UCAV can carry out maneuvers that cannot be completed by a typical action library.
(3)A multistep double deep Q-network(MS-DDQN)algorithm is proposed to improve the training speed and accuracy oftraditional DRL by introducing the final return value into the previous steps.
(4)A 6-DOF UCAV model is constructed in a MATLAB/Simulink environment,and the appropriate aerial combat action is selected as the UCAV maneuver output.An aerial combat superiority function is established,and a UCAV aerial combat maneuver decision model is designed.Finally,based on the basic training method,the pre trained learning model is used as the starting point of a second learning model.The simulation results show that the method is effective and feasible for UCAV maneuver decision-making.
2.Background
In this section,an introduction to the UCAV autonomous tactical decision system,UCAV motion model,and UCAV controller is presented,together with the relevant theoretical background,including the Q-learning algorithm and Q-based DQN algorithm.
2.1.UCAV autonomous tactical decision system
Research into UCAV autonomous tactical decision-making systems has aimed to improve the autonomy of UCAVs,allowing them to deal independently with emergencies,improve the efficiency with which they execute tasks,and improve their ability to adapt to the environment.As shown in Fig.1,the UCAV autonomous decision-making module comprehensively evaluates the situation information of the UCAV and its target.If the UCAV is in the aerial combat state,the combat situation information is input into the module,which obtains the relative advantage function and the maneuver command based on the maneuver action library,generates the corresponding maneuver action,and obtains the rudder deflection through the control law,to guide the aerial combat of the UCAV.If the UCAV is not in the aerial combat state,it will search the battlefield until the target is found.The module can also be switched automatically into manual mode.
2.2.UCAV motion model

Fig.2.The F-16 aircraft configuration.
Fig.2 shows the UCAV model used in this paper which is based on the General Dynamics F16 aircraft of the United States Air Force,and the flight envelope of the UCAV model is-20≤α≤90,-30≤β≤30,0˙1≤M≤0˙6.Because the focus of this study is on UCAV maneuver decision-making,the UCAV is regarded as an ideal rigid body with left-right symmetry when its motion is considered,and the influence of the Earth's rotation is ignored,as are the dynamic characteristics of the sensors.The velocity and three attitude angles of UCAVs are considered.Control of the UCAV relies mainly on the thrust of its engine and on its aerodynamic control surfaces.To take account of the nonlinear behavior of the UCAV and its maneuvering capabilities,a 6-DOF equation is adopted to describe its state of motion.The structural parameters of the UCAV are shown in Table 1,and the restrictions on each rudder surface are shown in Table 2.
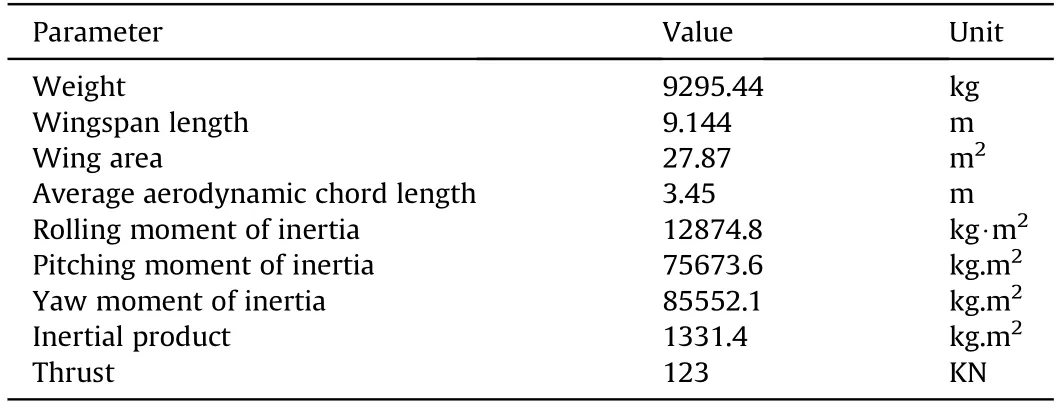
Table 1Structural parameters of the UCAV.
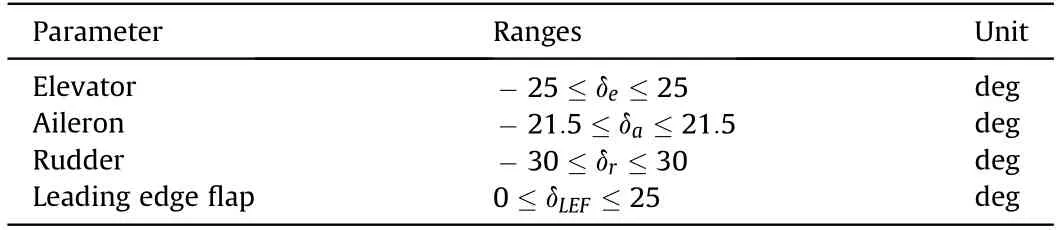
Table 2Limitations of each rudder surface.
The ground coordinate system is taken as the European coordinate system,and the nonlinear 6-DOF model of the UCAV in this system can be described as force equations,moment equations,motion equations,and navigation equations.The nonlinear relationship between aircraft state vector x=[V,α,β,p,q,r,φ,θ,ψ,x,y,z]and control input u=[δ,δ,δ,δ]can be obtained,where V,α,and β are the speed,angle of attack and sideslip angle,respectively,φ,θ,and ψ are the roll angle,pitch angleand yaw angle,respectively,p,q,and r are the angular rates along the three axes,x,y,and z are the position along the x-axis,y-axis and z-axis in the ground coordinate system,respectively,and δ,δ,δ,and δare the elevator deflection,aileron deflection,rudder deflection,and throttle lever displacement,respectively.
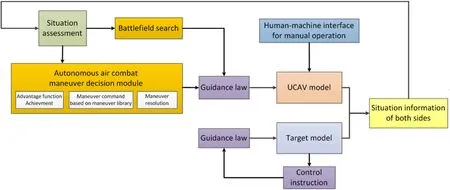
Fig.1.UCAV autonomous decision module.
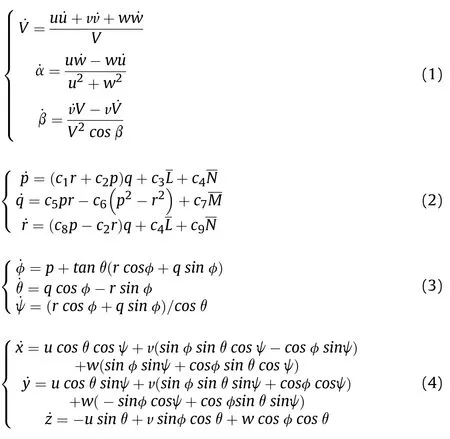
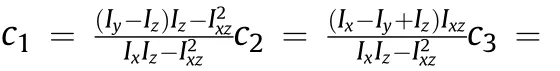
The above Eqs.(1)—(4)together constitute the 6-DOF motion equation of the UCAV.
2.3.UCAV controller
In this paper,using the above nonlinear UCAV model,and taking account of the influence of attitude on UCAV aerial combat decisions,a proportional—integral—derivative(PID)algorithm is used to set up the control law and construct the basic operation database.At the same time,a DRL algorithm is used to determine the UCAV maneuvers under autonomous decision-making,thus achieving complete and accurate control of the UCAV.
According to the information of flight path angle,it can directly control the normal of the aircraft,to change the elevator deviation.
Longitudinal control loop:
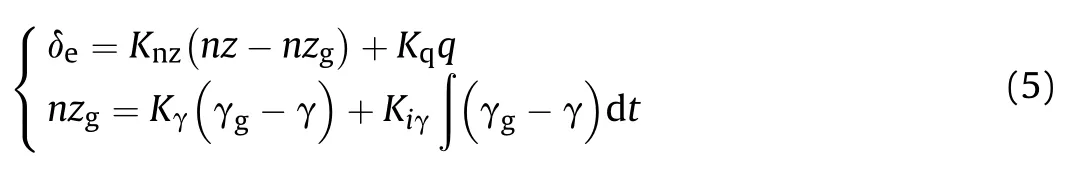
where nz is the normal overload,q is the pitch angular rate,γ is the flight path angle,nzand γare the given normal overload and flight path angle,K,Kand Kare the proportional coefficients,Kis the integral coefficient.
Velocity control loop:
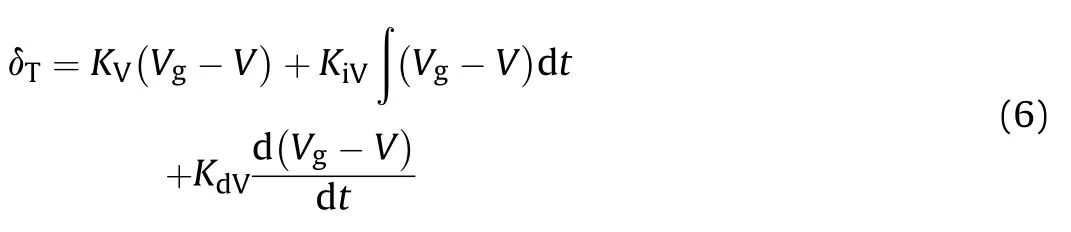
where Vis the given speed command,Kis the proportional coefficient,Kis the integral coefficient,Kis the differential coefficient.
The roll angle control loop is composed of a vertical gyroscope.By measuring the roll angle of the aircraft and adding the signal to the aileron channel,a roll stability loop is formed to keep the wing horizontal.The yaw rate is measured by the course gyroscope,and the signals of yaw rate and sideslip angle are added to the rudder track to form the course stability control loop and reduce the sideslip.
Lateral control loop:

where p is the roll angle rate,φ is the roll angle,r is the yaw angular rate,φis the given roll angle command.K,K,K,and Kare the proportional coefficients.
The specific values of control law parameters are listed in Table 3.
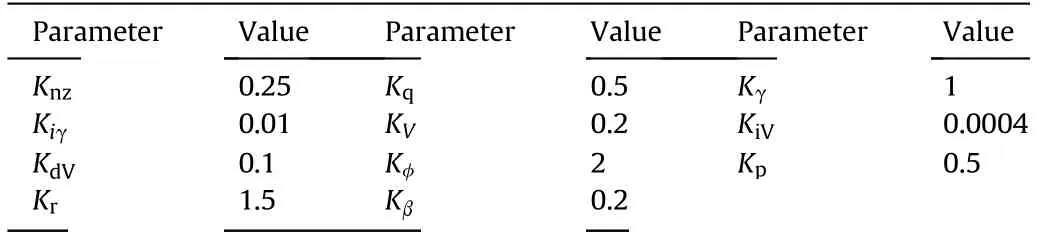
Table 3Control law parameters.
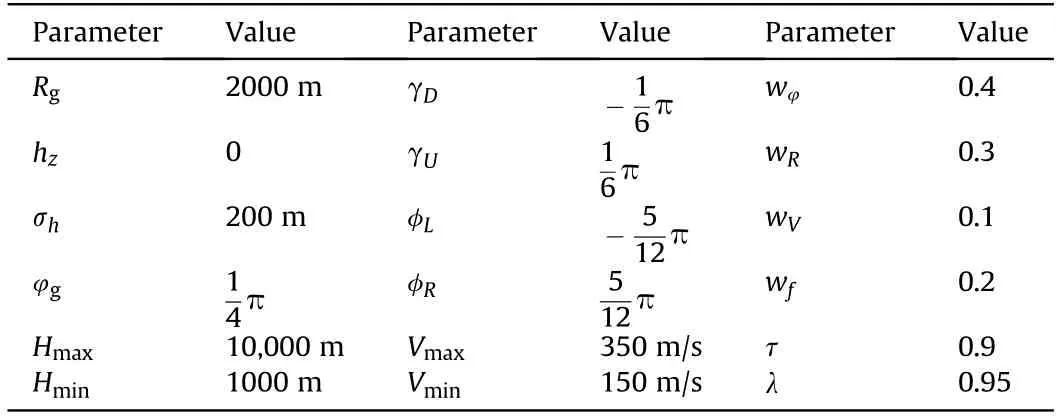
Table 4Parameters and their values.
On the basis of trim status H=3000 m,V=200 m/s,θ=1˙73,give flight path angle command γ=30,roll angle command φ=30,and velocity command V=250 m/s,respectively.
According to the digital simulation results shown in Figs.3-5,it can be seen that the flight path angle signal,velocity signal,and roll angle signal can accurately track the given step signal,which meets the requirements of control law design.
2.4.Deep reinforcement learning
The reinforcement learning algorithm consists of the following five principal parts:agent,environment,states,action A,andobservation R.At time t,the agent generates action and interacts with the environment.After the action has been executed,the state of the agent changes from sto sand gives a return value Rof the environment.In this way,agents always modify their data on their interaction with the environment,and the optimal solution is obtained after many operations.(see Fig.6).
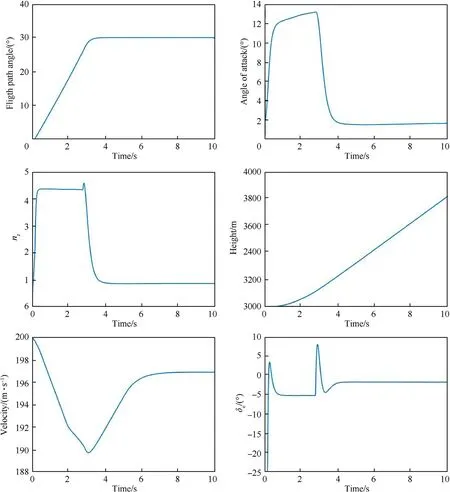
Fig.3.Simulation results of flight path angle control.
The calculation process in reinforcement learning is one of continuous exploration of the optimal strategy.Strategy here refers to the mapping from state to action.The following formula gives the probability of each action corresponding to each state s:

In a reinforcement learning algorithm,we want to maximize the value of the action corresponding to each state:

In traditional reinforcement learning,a tabular form is usually used to record the value function model.This method can give the value of the function in different states and actions in a stable manner.However,in the face of complex problems,the space of states and actions is large,and it takes a long time to retrieve the corresponding state values in the table,which is difficult to solve.Because deep learning integrates feature learning into the model,it has self-learning properties and is robust and can therefore be applied to nonlinear models.However,deep learning cannot estimate data rules without bias,and it requires a large amount of data and repetitive calculations to achieve high accuracy.It is thereforeappropriate to consider the construction of a DRL algorithm by combining deep learning with a reinforcement learning algorithm.
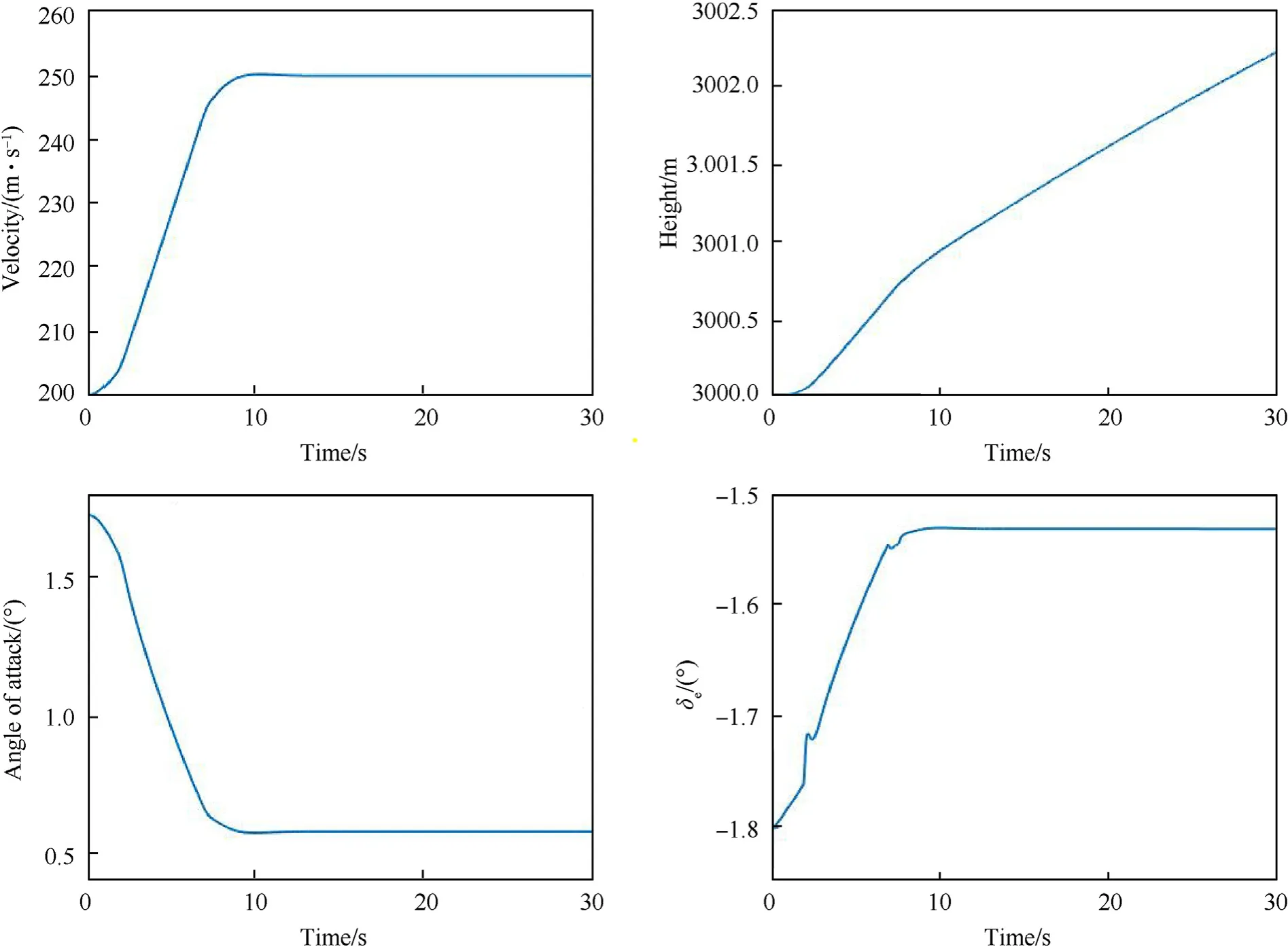
Fig.4.Simulation results of velocity control.
The deep Q-network(DQN)model consists mainly of a multilayer back-propagation(BP)network maneuver decision model and a decision model based on Q-learning.In the decision-making process for a UCAV involved in aerial combat,it is necessary to analyze its flight status and combat situation,as well as those of the enemy aircraft.The BP network is used to calculate the long-term discount expectation of each state-action pair,and the Q-function network is used as the basis of evaluation when traversing all maneuvers in different states.At the same time,to keep the learning data close to the independent distribution data,we need to establish a database to store the state,action,reward,and next state of the action in a given period of time.With this method,in each learning step,a small portion of the samples in the storage area〈s,a,r,s〉is used,and this disturbs the correlation of the original data and reduces the divergence compared with previous Q-learning approaches(see Figs.7 and 8).
To deal with uncertainty,the DQN algorithm also establishes a target net with the same structure to update the Q value.The target net has the same initial structure as the Q-function net,but the parameters are fixed.The parameters of the Q-function net are assigned to the target net at intervals to keep the Q value unchanged for a certain period of time.The optimal solution can be obtained by minimizing the following loss function with the gradient descent method:

where
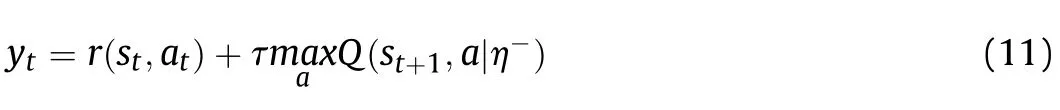
is the target parameter.
Because the DRL algorithm iterates the value Q(s,a)of the state—action pair,in the learning process,when action ais selected at time t,the update of the value function becomes
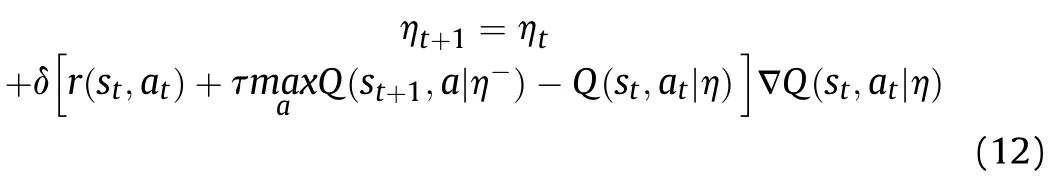
where δ is the learning rate,τ is the discount rate,r(s,a)is the comprehensive advantage function,η is the network parameter of the Q-function,and ηis the target network parameter.It can be seen from Eq.(12)that the reinforcement learning algorithm contains the comprehensive dominance function and the state value after the selected action,which means that the method tends to be infinitely stable in the long run.
3.Proposed method
This section describes in detail how to realize the autonomous maneuver decision of the UCAV when maneuvering to the target based on an improved DQN in an uncertain environment.It also gives the situation assessment function and maneuver actionlibrary,as well as describing the implementation of the corresponding algorithm.
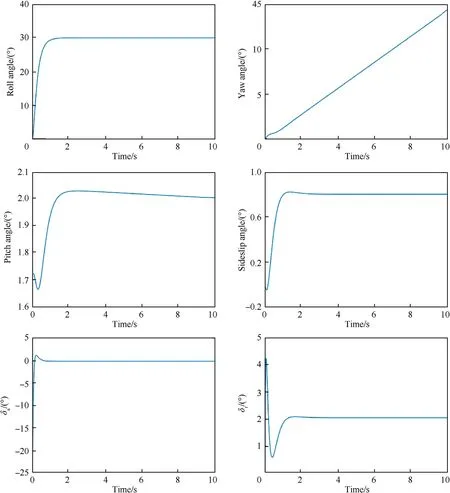
Fig.5.Simulation reslts of roll angle control.
3.1.DQN-based framework for UCAV control
3.1.1.Reward function
In aerial combat decision-making,taking the situation between the UCAV and its target in instantaneous time and space as a reward and punishment signal and constructing the corresponding aerial combat advantage function can make the decision-making system choose the appropriate maneuver and improve the UCAV's combat advantage over the enemy.Traditional environmental rewards generally include azimuth reward,speed reward,distance reward,and height reward,and the comprehensive aerial combat situation assessment value is obtained by weighting these components.However,this situation assessment does not consider the performance of the UCAV's weaponry and cannot adapt accurately to different weapons.Therefore,to solve this problem,in this paper,a superiority function for the attack mode of UCAV air-to-air missiles is designed[41].The typical air-to-air missile attack range is coneshaped,with a certain distance and angle in front of the attacking aircraft,as shown in Fig.9.In this figure,Vand Vare the velocity vectors of the UCAV and the target,respectively,R is the distance vector between the UCAV and the target,φand φare the angles between the distance vector and the velocity vectors of the UCAV and the target,respectively,and Rand φare the attack distanceand the attack angle,respectively,of the UCAV's missile.
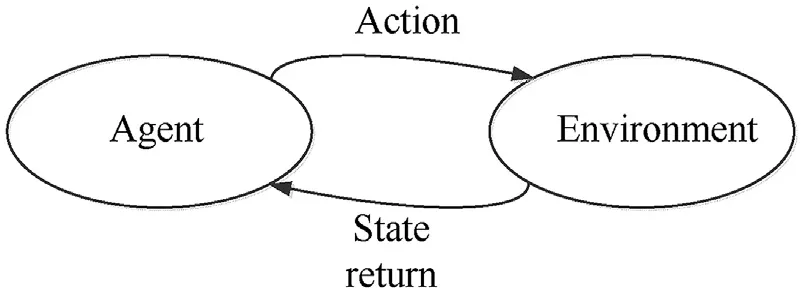
Fig.6.Basic framework of reinforcement learning.
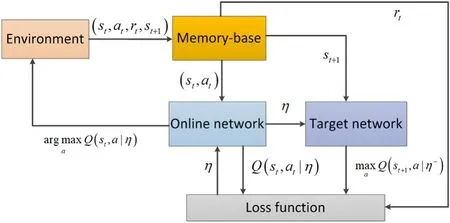
Fig.7.DQN model.
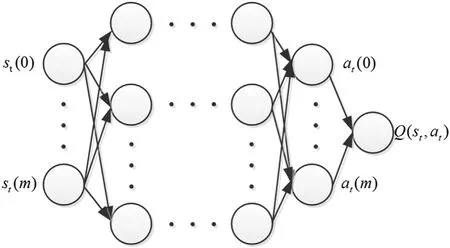
Fig.8.Neural network.
(1)Azimuth situation
In an aerial combat environment,the rear,chasing,aircraft is in the dominant state and the aircraft being chased is in a disadvantaged state,while the two aircraft are in an equilibrium state when they fly in the opposite or the same direction.In this paper,the angle advantage is calculated from the azimuth angle of the two aircraft.The azimuth advantage function is given by

When φ+φ=0,the UCAV is tailing the target,and the angle advantage function is greatest;when φ+φ=π,the UCAV and target are in the same situation;φ+φ=2π,the UCAV is tailed by the target and is in a disadvantaged state.
(2)Distance situation
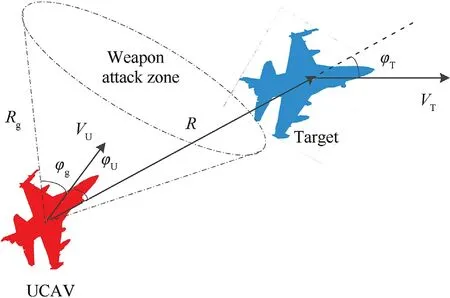
Fig.9.Aerial combat situation.
Nowadays,aerial combat weapons are generally air-to-air missiles.For most of these missiles,the hit rate is related mainly to distance.To make the distance parameter function insensitive to changes in distance,the UCAV decision-making must be robust.The distance advantage function is given by
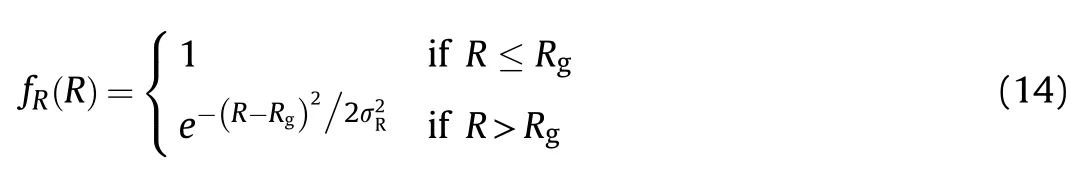
where R is the distance between the UCAV and the target,Ris the attack distance of the UCAV's missile,and σis the standard deviation.
(3)Speed situation
In an aerial combat environment,there is an optimal attack speed Vof the UCAV relative to its target,and the associated speed advantage function is given by

where V is the current speed of the UCAV,and the optimal attack speed relative to its target is given by
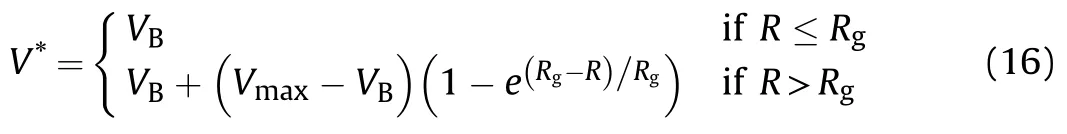
where Vis the speed of the target and Vis the maximum speed of the UCAV.
(4)High-level situation
In an aerial combat environment,there is an optimal attack height difference h.When the UCAV is higher than its target,it has a potential energy advantage,and the associated height advantage function is given by
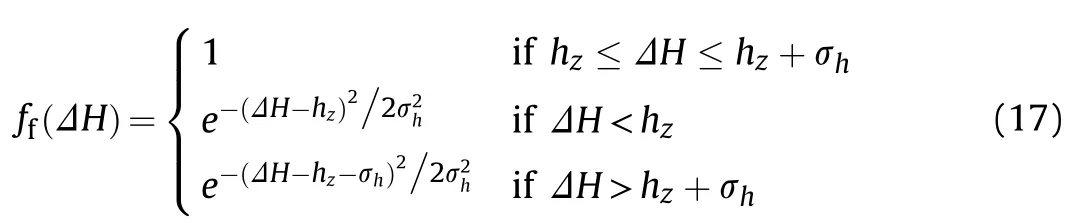
whereΔH is the current height difference between the UCAV and the target and σis the standard deviation of the optimal attack height of the UCAV.
(5)Attack situation
If the distance between the UCAV and the target is less than the attack distance of the missile,the angle between the UCAV speed vector and the distance vector is smaller than that of the UCAV missile,and the angle between the velocity vector and the distance vector of the target is less than 90,then the target is within the attack range of the UCAV and it can launch a missile and intercept the target.This ends the current simulation round,and the next round is entered.The reward value of the UCAV is given by
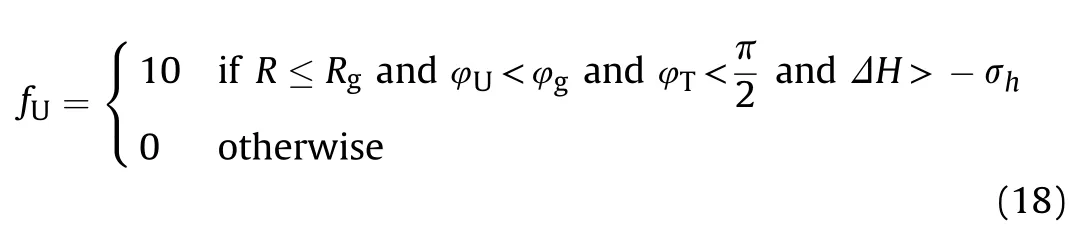
When the conditions in Eq.(18)are met,the UCAV receives a reward value.To train UCAVs to avoid attack by enemy aircraft,the target in the simulation also has attack weapons.When the target meets the same conditions,the UCAV is at a disadvantage and receives a negative reward value:

where
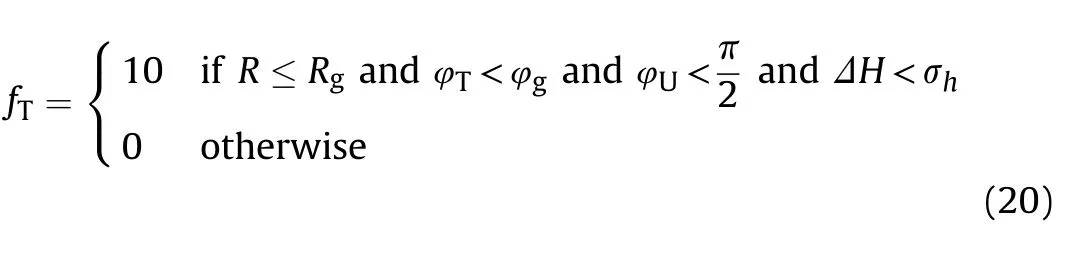
(6)Environmental situation
To avoid stalling,too low or too high a flight path,too great a distance from the target,or collision with the target,the speed of the UCAV must be limited to not less than 150 m/s,its height to not less than 1000 m,and its distance from the target to the range 1000—50,000 m.The associated reward value is:
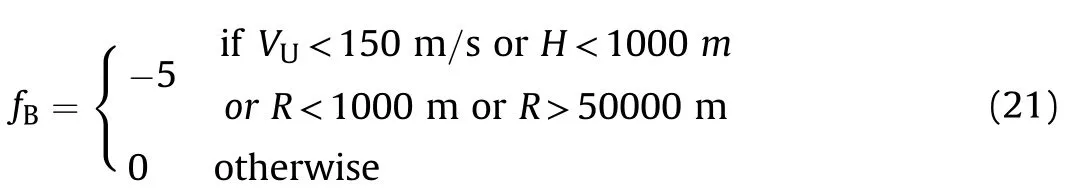
At the same time,because the UCAV model is a 6-DOF nonlinear model,the choice of maneuver action should consider not only the situations of the UCAV and the enemy,but also the state of the UCAV,so that the selected maneuver action can be fully executed without losing control of the UCAV.For fixed-wing aircraft,the magnitudes of the triaxial force and the triaxial moment are related to the angle of attack and the sideslip angle,and so the key to controlling the aircraft and its flight quality is the angle of airflow.When the aircraft is maneuvering,it is necessary to protect the airflow angle to avoid runaway of the aircraft due to inertia or disturbance beyond the flight envelope.To ensure that the decision mechanism avoids a choice of maneuver instructions that cause UCAV to lose control,the angle of attack of the UCAV should be limited to[-20,20]and the sideslip angle limited to[-30,30],with a negative reward value being given when these limits are exceeded.Thus,the reward value is given by:
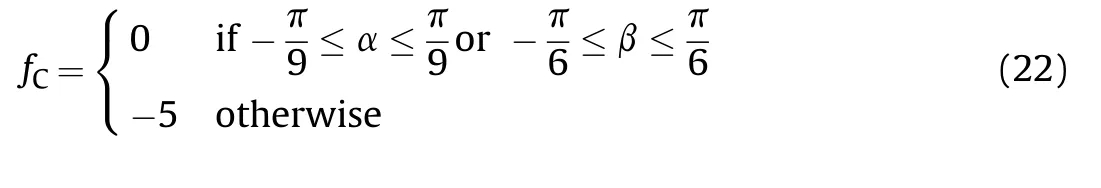
(7)Comprehensive advantage evaluation function
The advantage function is used to judge the maneuver strategy.The purpose of the maneuver is to seize a favorable position and attack the target.Therefore,decision-makers need to consider the influence of each advantage function on the UCAV's aerial combat and evaluate it comprehensively.Because each of the advantage functions has a different influence on the aerial combat situation,a comprehensive advantage function is taken as a weighted sum of each advantage function:
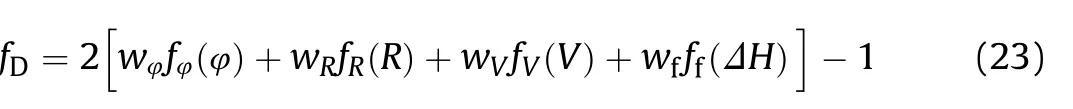
In this expression,the weight of each advantage function is determined by simulated aerial combat,and the calculated value is used as the feedback input of the environment.When this weighted sum of the advantage functions is large,the UCAV is in the dominant position.If this situation can be maintained for a certain time,the UCAV will have a greater chance to shoot down the target.However,when the weighted sum is small,the UCAV is in a disadvantageous position and has a greater probability of being attacked by the target.
At the same time,the attack situation and environmental situation based on the missile are added to the dominance function to give the following formula:

3.1.2.Action space
The control mode of the UCAV is divided into attitude control and track control.Attitude control is common in UCAV short-range aerial combat,which requires tracking and entanglement of targets.In the PID control law,the state and rate of change of the attitude angle are usually controlled to realize attitude change.Track control is common in UCAV oversight aerial combat,and long-distance targeting is achieved by controlling the position.
In the current aerial combat environment,there is intense combat is fierce and the tactical action switching time is fast.By constructing a mobile action database,it is possible to select appropriate maneuver actions according to the current battlefield situation,and the probability of winning an aerial combat can be increased.A UCAV aerial combat maneuver action library can be divided into two sub-libraries:a typical tactical action library and a basic maneuver action library.The typical tactical action library includes the Cobra maneuver,hammer maneuver,spiral climb,etc.,but each of these tactical actions is essentially composed of various basic actions.At present,special maneuver actions must be closely coordinated by humans and computers,otherwise the status of UCAV can exceed its normal envelope,leading to the risk of runaway.Therefore,in the design of the decision system,the basic maneuver action library[42,43]proposed by NASA is usually used as the selection range of the UCAV maneuver action library.
However,these seven maneuvers are the flight states of a UCAV under extreme control,and they do not reflect the actions encountered in aerial combat.Control of an aircraft according tospeed can be divided into constant flight,accelerated flight,and deceleration flight;control according to roll angle can be divided into straight plane flight,left turn,and right turn;and control according to altitude can be divided into plane flight,climb,and descent.The combination of speed,roll angle,and height gives 27 kinds of maneuvering actions,as shown in Fig.10.
For realization of the basic control action library,the movement calculation command in the maneuver action library consists of three commands:thrust,normal overload,and roll rate[T,nz,p].The maneuvering action command[V,γ,φ]in the European coordinate system is used to realize various maneuvers,and a candidate action library for autonomous combat decision is established,in which Vis the velocity command of the UCAV,γis the flight path angle command of the UCAV track,and φis the roll angle command of the UCAV.
The 27 maneuver actions are used as the output of the UCAV maneuver decision,and the flight of the UCAV is thereby controlled.Because the UCAV lacks the human ability to sense the aircraft state,it is necessary to limit the above maneuver actions.By limiting the track inclination angle,roll angle,and speed command of the track,constraints are imposed at the control output end to prevent the UCAV from losing control due to excessive or too small value of the attack angle,sideslip angle,and speed.The command range of the flight path angle at the control output is[γ,γ],that of the roll angle is[φ,φ],and that of the speed is[V,V].At the same time,if the UCAV azimuth is near the target,the roll angle is probably too large,and so a reverse rolling command should be received to correct this,to prevent the combat efficiency from being reduced.On the other hand,the importance of altitude is less than the azimuth and distance.It is easy to climb too high or fall too low in the learning process,and so certain restrictions need to be imposed.Therefore,for a variety of aerial combat situations,the maneuver action commands are as follows.In terms of height,when a fixed height command is received,

When a climb command is received,

When a descent command is received,

When a direction instruction in terms of angle is received,
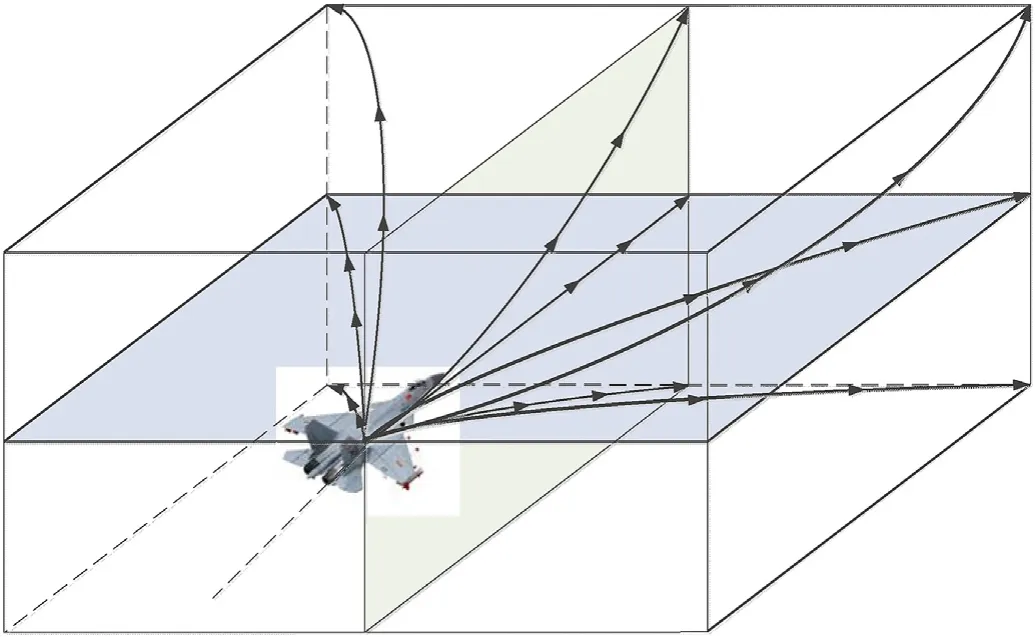
Fig.10.Maneuver library.

When a right-turn command is received,

When a left-turn command is received,

When a constant-speed command is received,

where Vis the current speed of the UCAV.When an acceleration command is received,

When a deceleration command is received,

3.1.3.State space
Since the aerial combat environment is a three-dimensional space,to fully represent the flight status and aerial combat situation of the two aircraft,the state space of the autonomous aerial combat maneuver decision module in Fig.1 contains 10 variables:
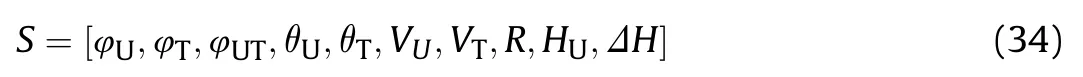
where φis the angle between the UCAV velocity vector and the target velocity vector,θand θare the pitch angles of the UCAV and the target,respectively,His the current flight altitude of the UCAV,andΔH=H-His the altitude difference between the UCAV and the target.It is necessary to normalize the state space and then input it into the neural network model.
3.2.UCAV aerial combat decision-making based on MS-DDQN
The DQN algorithm suffers from the problem of a cold start.It is difficult to get the model into a relatively ideal environment during the early stages of algorithm iteration,which leads to a large error in the estimation of the value function in the early learning stage.The slow learning rate will affect the later learning process,and it is difficult to find the optimal strategy.With a double Q-learning algorithm,the model can use different models when choosing the optimal action and calculating the target value,thereby reducing the overestimation of the value function.
At the same time,the aerial combat decision-making system needs to make many decisions throughout the entire aerial combat,and this is a continuous process.During training,some time is needed to skip the period of large fluctuations in the early stage and enter a stable period.Because the purpose of the decision-making is to ensure that the UCAV reaches a dominant position in a certain time and attack the enemy aircraft,the situation on the UCAV side at the end of aerial combat is particularly important.The final reward values for each aerial combat are returned to the value function of the state—action pair Q(s,a)with certain weights,with the aim of improving the speed and accuracy of training.
The target parameters are updated as follows:
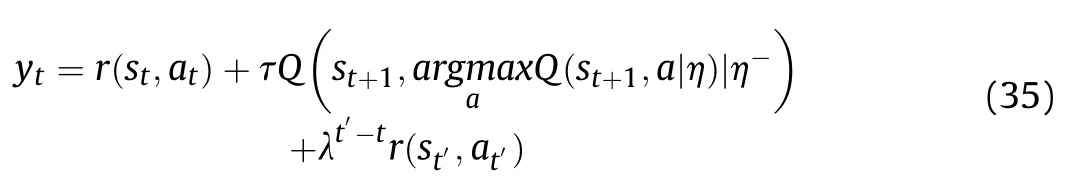
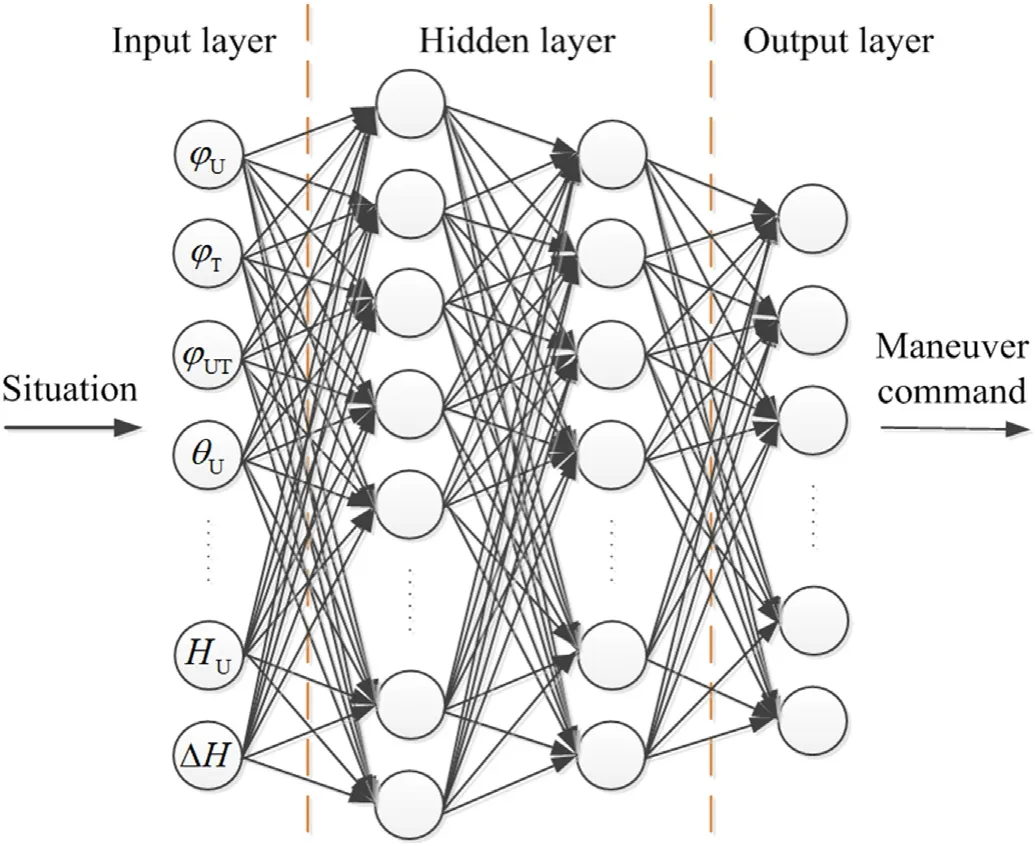
Fig.11.Neural network model.
When an action is selected at time t,the value function is updated as follows:
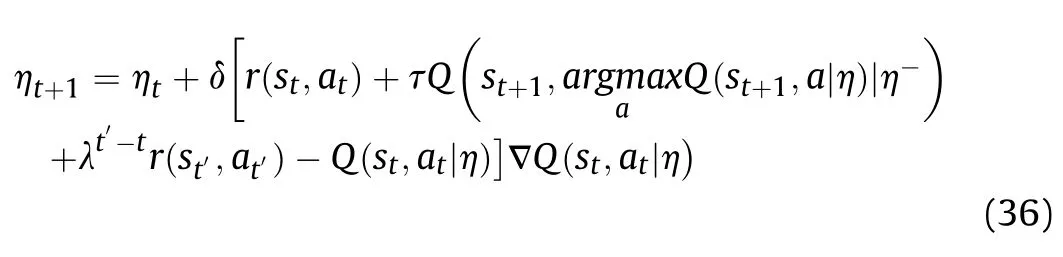
where t'is the time of single aerial combat decisions and r(s,a)is the final reward value of the aerial combat,the reward value r(s,a)is updated as follows:

A neural network approximation function is also used,in which the input layer includes the current situation information,and the output layer includes longitudinal maneuver decision-making instructions,lateral maneuver decision-making instructions,and speed control commands Fig.11.The situation information is input into the neural network,and the maneuver action value is output.At the same time,the optimal maneuver action is obtained by interaction with the environment,which allows the UCAV independently make operational decisions and improve its intelligence.
In its training for aerial combat decision-making,the UCAV makes maneuver decisions according to the DRL algorithm described above.The whole training process is composed of multiple aerial combat rounds.Whenever the UCAV decides that it has hit the enemy plane,is hit by the enemy plane,reaches the maximum round time,or is in the wrong position,it ends the aerial combat round,enters a new aerial combat round,and resets the simulation environment.In the process of training,an ε-greedy strategy is adopted.In the beginning,actions are randomly generated with 100% probability.As the simulation progresses,the probability is continuously reduced to 10%,at which point the strategic approach is optimal.At the same time,to reflect the effect of learning,the decision-making ability needs to be judged regularly during training,and the random probability needs to be reduced to 0 when a judgment is made,so that the decision-making model can directly output the largest Q-value action.Also,the final value of the dominance function value needs to be determined,to judge the learning efficiency compared with different periods.
The specific implementation steps of the MS-DDQN algorithm for UCAV short-range aerial combat maneuver decision-making are shown in Algorithm 1.

Algorithm 1.Specific implementation steps of the MS-DDQN algorithm.1 Initialize replay memory D to capacity N 2 Input UCAV model,aerial combat environment,and missile model 3 Initialize action-value function Q with random weights η and target action-value function Q′with weights η-=η 4 Initialize hyper-parameters:evaluation frequency M,mini-batch size N,random probability ε,learning rate δ,reward value ratio λ,maximum episode E,maximum step T,target networks update interval C 5 For each episode e=1,2,…,E,do 6 Observe initial states of UCAV models of both sides and the simulated aerial combat environment to obtain the current situation 7 If e% M==0,do 8 Make ε=0 to perform evaluation episode 9 End if 10 For each step t=1,2,…,T,do 11 Choose one action randomly from the 27 kinds of maneuvers in the maneuvering library with a probability ε;otherwise select at=argmax a Q(st,aη)12 Perform action at,get reward rt and new status st+1 13 Store transition(st,at,rt,st+1)in D 14 Judge whether the aerial combat round is over 15 end for 16 Get final reward Rt,stop time of aerial combat t'and store transition(st,at,rt,st+1,Rt,t′)in D 17 Sample random minibatch of transitions(si,ai,ri,si+1,Ri,i′)from D 18 Set yi=■■■■ ■■■ri for terminal si′,ri+τQsi+1,argmax a Q(si+1,a■η)■■■■η-+λi′-iRi′for nonterminal si′■■■■ ■■■19 Perform a gradient descent step[yt′-Q(st′,at′■η)]2 to the network parameters 20 Every C steps,reset the target network,and make η-=η 21 Gradually decrease the value of ε to 0.1 22 End for
4.Experiment and results of analysis
In this section,we discuss the simulation environment and the setting of various parameters and carry out experiments.On the basis of the experimental results,we prove the effectiveness and performance improvement provided by our proposed method.
4.1.Simulation environment settings
To verify the MS-DDQN algorithm proposed in this paper,the parameters are set and constrained during the experiment.According to the range of flight performance,acceleration,and altitude of the UCAV,a constrained flight control law is designed,i.e.,the limitations of the aircraft state are incorporated into the design of the controller,the control input is calculated,the actual rudder deflection angle of the UCAV is limited to the maximum allowable deflection angle in real time,and the flight parameters are maintained within safe boundaries without affecting normal flight control.This ensures flight and operational performance and safety,reduces the workload of the UCAV,and realizes control of the UCAV.The main constrained variables are the angle of attack,sideslip angle,overload,and airspeed.
Let the UCAV be designated as red and the enemy(the target)as blue.The simulation environments of the red and blue aircraft are limited in the same airspace.In the first task,a constant-velocity model is introduced for the target,in which the target moves in a straight line at a uniform speed,and its initial direction,velocity,and position are evenly distributed.In the second task,the target turns at a uniform speed,and its initial direction,velocity,and position are again evenly distributed.The parameters of the MSDDQN algorithm and their values are listed in Table 4.
The parameters of the neural network are set as follows.A twolayer fully connected feedforward neural network is used as the online Q-network,with 10 input states and 27 output values.The network has two hidden layers,with unit sizes of 1024 and 512,respectively.The TANH function is used as the activation function,and the PURELIN function is used to activate the last output layer.The buffer size of the memory playback unit D is set to 10.After 10,000 samples have been stored,the neural network starts training.The number of training samples extracted each time is 1000,and the target network is updated every 100 combat rounds,in which the learning rate is δ=0˙01 and the discount coefficient is τ=0˙9.
In the process of simulation,to complete the whole maneuver,the decision time of each step is 1 s,and the maximum time of each operation is 200 s.If the UCAV decides to track the enemy aircraft,be tracked by the enemy aircraft,reach the maximum turn time,or be in the wrong position,it ends the aerial combat round.Every 100 combat rounds,it evaluates the learning ability of the neural network and checks the reward value when it stops flying.The computer used in the simulation has an AMD Ryzen 7 3700X 8-core CPU and an NVIDIA GeForce GTX 1660 SUPER graphics card.
4.2.Analysis of simulation results
4.2.1.Algorithm training
The aircraft models of both sides are identical,as shown in section 2.2,in which the red machine is the UCAV,the blue machine is the target aircraft,and the initial state space is shown in Fig.12.We carry out the first training task as follows.The initial direction,speed,and position of the target are shown in training episode 1 inTable 5.The target moves in a straight line at a constant speed.The pre-training is carried out based on the basic training method.After pre-training of 200,000 combat rounds,the weight of the training network in subtask 1 is transferred to subtask 2 as the initial weight network of the current strategy,and then the training of 200,000 combat rounds is carried out.The initial state value of subtask 2 is shown in training episode 2 in Table 5,the initial position of the target is on a ring 20,000 m away from the UCAV.
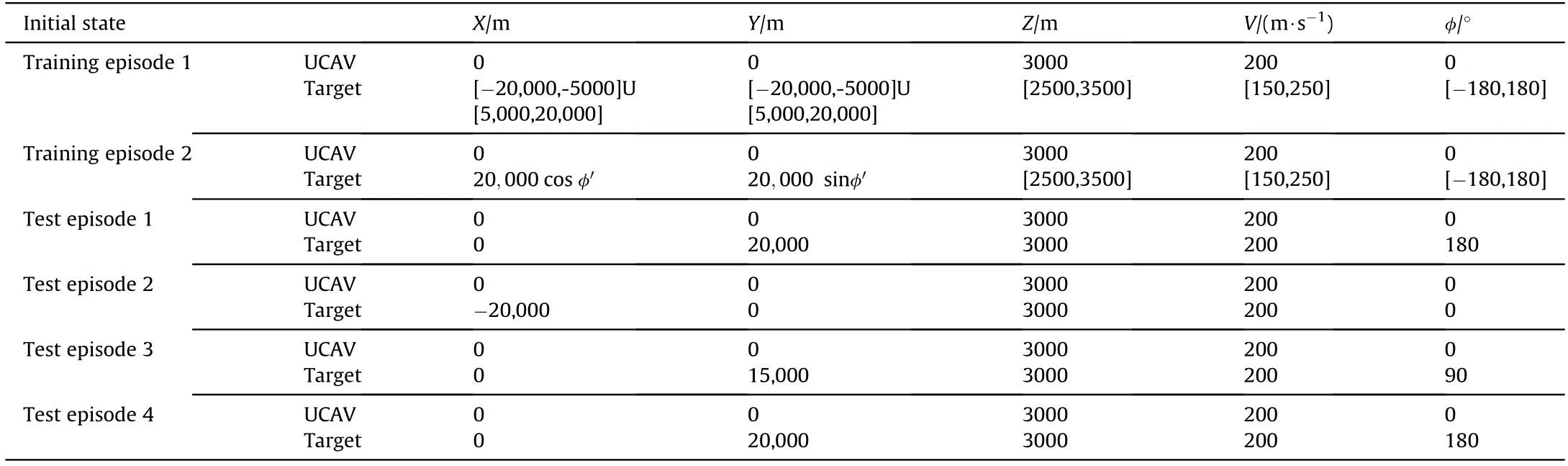
Table 5Initial state values.
Fig.12.Initial state space.
After training,the states of both sides are as shown in test episode 1 in Table 5,and the test is carried out.The whole combat trajectory can be seen in Fig.13,which shows the real-time position changes of both sides.The trajectories of the UCAV and target are green and gold,respectively.Fig.13(a)and(b)are a stereogram and a plan diagram,respectively,of aerial combat.It can be seen that the UCAV begins to roll to the right,accelerates to climb and turn to the right when it flies to 13 s,continuing to accelerate when it flies to 30 s.During the whole process,it chooses the appropriate maneuver and adjusts its speed and attitude so as to achieve the dominant position and attack the target.As can be seen from Fig.14(a),the distance between the UCAV and the target continually decreases until the attack distance is reached,and as shown in Fig.14(b),the UCAV is slightly higher than the target,which is convenient for attacking the latter.Fig.14(c)shows that the value of the UCAV's dominance function increases continuously and it finally succeeds in defeating the enemy.Fig.14(d)and(e),and 14(f)show the changes of pitch angle,roll angle,and velocity,respectively,of the UCAV during its tracking of the target tracking.It can be clearly seen that the UCAV continually adjusts its attitude and velocity in order to reach the attack position.Owing to the improvement of the maneuver library,the roll value selected by the UCAV as it flies toward the target will not be too large,avoiding the risk of overflight.
To verify the universality of the training,the states of both sides are shown in test episodes 2 and 3 in Table 5,and the corresponding combat trajectories are shown in Fig.15 and Fig.16.The target also moves in a straight line at a constant speed.
We can see that when facing the enemy aircraft from the rear,the UCAV will choose to accelerate,roll right,and climb to a certain altitude at the start,accelerate in forward flight when flying to 30 s,switch attitude when flying to 40 s,and roll right behind the target to attack.When facing the enemy aircraft from the right side,it will roll to the left and climb at the start.When flying to 28 s,it will accelerate to roll to the left and descend.It will also choose to attack behind the target.This shows that the UCAV trained by the algorithm can choose the appropriate maneuver and occupy a relatively dominant position in different situations.
After the environmental variables have been set,the second training is carried out,the training method is the same as the first training,and the target turns at a constant speed with a roll angle of 30.The initial direction,speed,and position values are shown in test episode 4 in Table 5.
Fig.17 shows the combat trajectory of the UCAV,and Fig.18(a)and(b),and 18(c)show its range,altitude,and speed and those of the target.It can be seen that the UCAV can still choose the appropriate maneuver in the complex situation of facing a turning moving target.
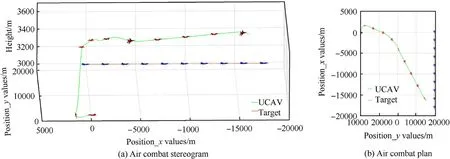
Fig.13.Position simulation 1 of a UCAV attacking a linearly moving target.
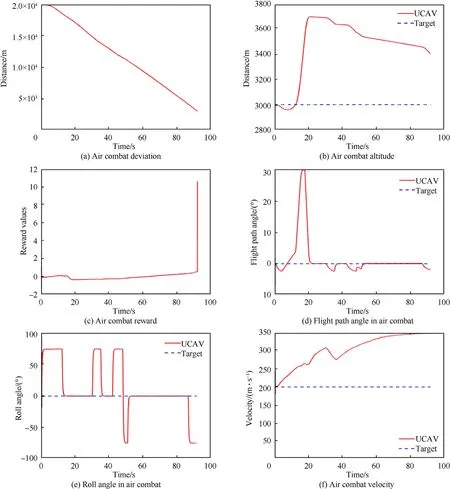
Fig.14.Simulation 1 of a UCAV attacking a linearly moving target.
4.2.2.Effectiveness of the algorithm
In the air combat maneuver decision-making process,the length of decision-making time affects the reaction speed of the UCAV.The decision-making time of the DRL method is about 1.5 ms,while the decision-making time of other air combat decision-making algorithms such as differential game method and game theory method is more than 3 ms.The response speed of UCAV is slow,and the decision-making time is not as good as the DRL algorithm.But the DQN algorithm has the problems of slow training and low efficiency,so this part aims to improve the learning efficiency of DRL through the MS-DDQN algorithm.
To verify the superiority of the MS-DDQN algorithm,an experiment is performed to compare its performance with those of MSDQN and traditional DQN strategy exploration methods.These three algorithms are implemented in the first training task and are then evaluated after a period of training.The initial positions of the enemy and the UCAV in the evaluation are as shown in training episode 2 in Table 4,and the average final dominance value is calculated.
Fig.19 shows the average final dominance value of the UCAV in each evaluation episode.The red,blue,and green results represent the dominance values of the MS-DDQN,MS-DQN,and DQN algorithms respectively.It can be seen that the training speeds of the MS-DDQN and MS-DQN algorithms are initially higher than that of the DQN algorithm and that the average dominance value of the MS-DDQN algorithm eventually becomes greater than that of the MS-DQN algorithm.
After the task training,we randomly select 1000 initial positions to test the algorithm.
Fig.20 shows the average final dominance value of the UCAVafter calculation for each test set.From Table 6,it can be seen that the success probability of the MS-DDQN algorithm test value is much higher than those of the MS-DQN and DQN algorithms.This means that the use of the DRL-based MS-DDQN algorithm enables the UCAV to explore effective maneuvers and succeed in targeting enemy aircraft.
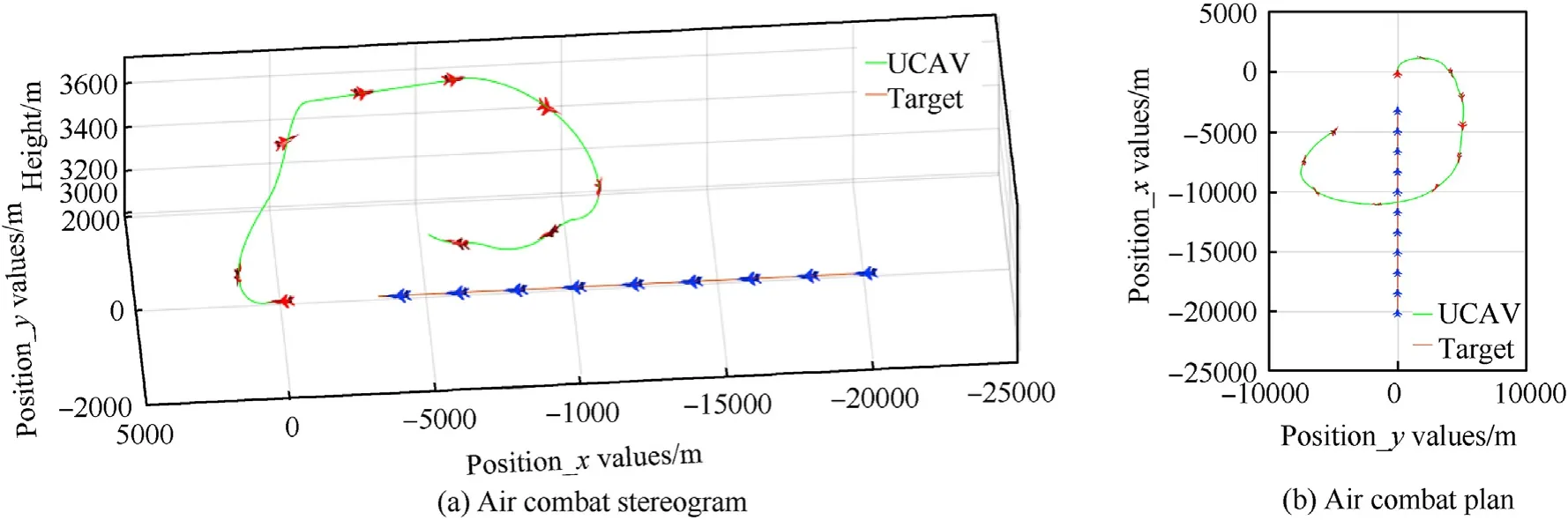
Fig.15.Position simulation 2 of a UCAV attacking a linearly moving target.
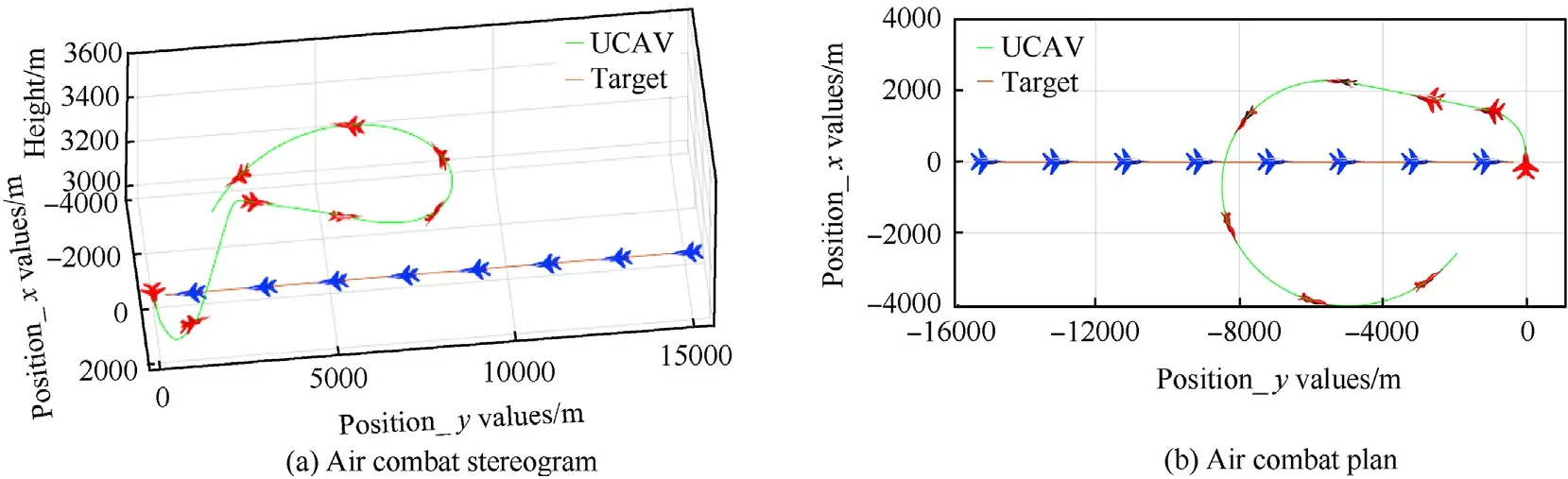
Fig.16.Position simulation 3 of a UCAV attacking a linearly moving target.
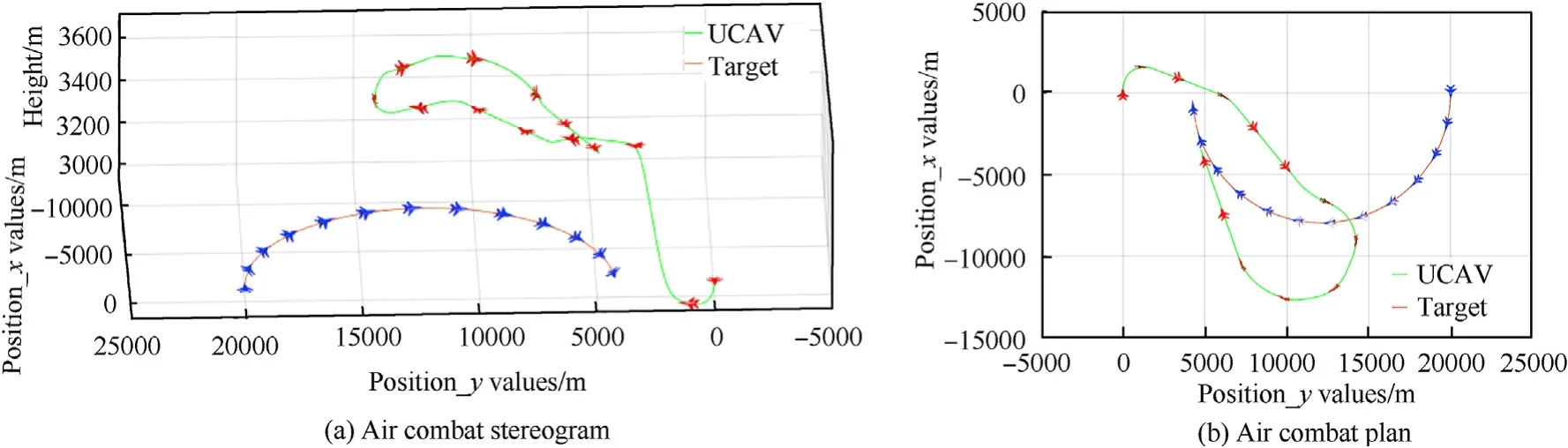
Fig.17.Position simulation 4 of a UCAV attacking a turning moving target.
4.2.3.Comparison of algorithms
Simulations of UCAV aerial combat are performed for training using the MS-DDQN and DQN algorithms,with the initial values of direction,speed,and position as given in Table 7.Among them,the UCAV adopts MS-DDQN algorithm for training and generates corresponding air combat maneuvers.The target adopts DQN algorithm for training,and the action space is the same as the UCAV.

Table 6Comparison of different algorithms.

Table 7Initial state values for aerial combat comparison.
Fig.21 shows the combat trajectory of the UCAV,and it can be seen that the flight path is scissor-shaped for both algorithms.Fig.22(a)and(b),and 22(c)show the altitude,roll angle,and speed of the UCAV.After a period of combat,the UCAV using the MSDDQN algorithm successfully shoots down its target.This comparison shows that the combat effectiveness of UCAVs can be effectively improved by using the MS-DDQN algorithm.
5.Conclusions
Traditional algorithms model UCAV decisions in attack and defense by describing the dynamic decision-making process of aerial combat.However,these decision models require frequent reasoning processes,which will waste a lot of time in seeking the optimal solution,and this is difficult to apply in real-time UCAV aerial combat.
In this paper,an MS-DDQN algorithm based on DRL has been used to construct an autonomous aerial combat maneuver decision system for UCAVs that takes account of the 6-DOF flight of a UCAV.The decision system is trained by the transfer method.Thesimulation results show that by improving the original DQN algorithm using DRL,the proposed algorithm can significantly speed up training and improve the effectiveness of combat.
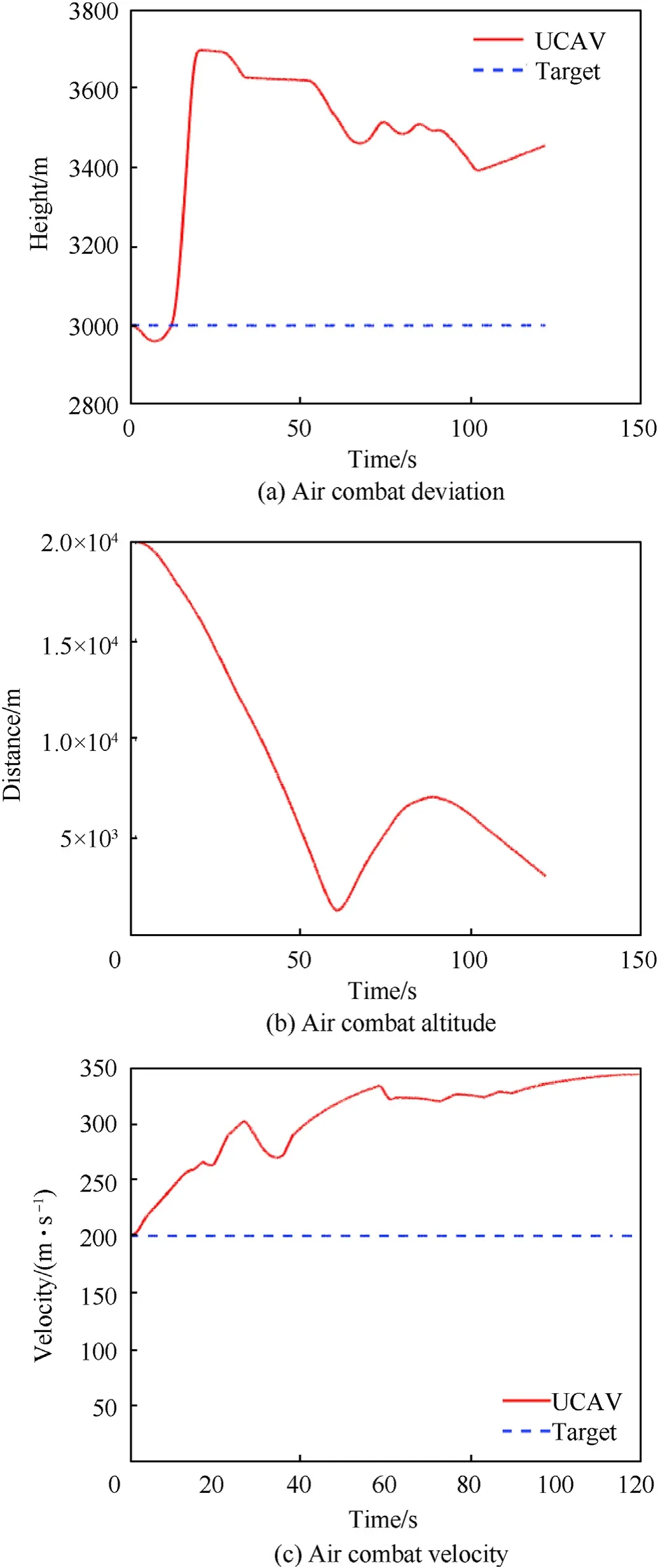
Fig.18.Simulation 4 of a UCAV attacking a turning moving target.
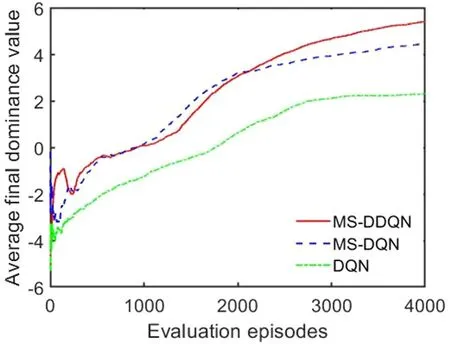
Fig.19.Average final dominance value of each evaluation episode.
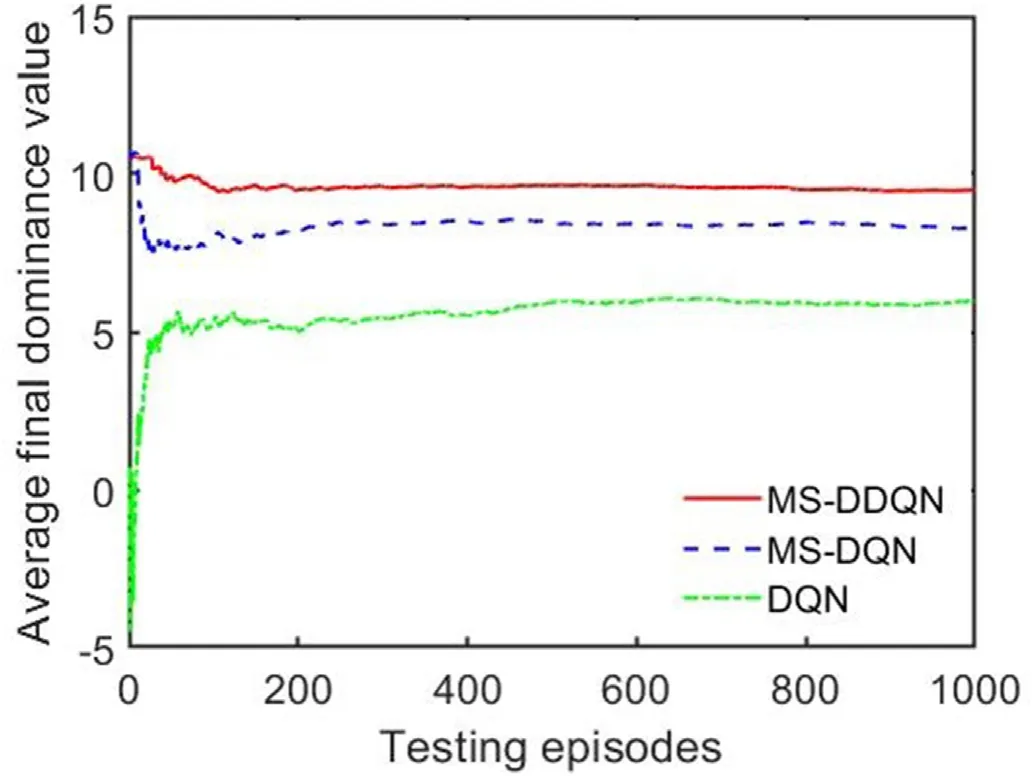
Fig.20.Average final dominance value of each testing episodes.
In the future,we intend to make the simulation scenarios more realistic by considering uncertain factors such as obstacles,wind field interference,and measurement errors,as well as moving on from virtual digital simulations of UCAVs to actual maneuver operations.
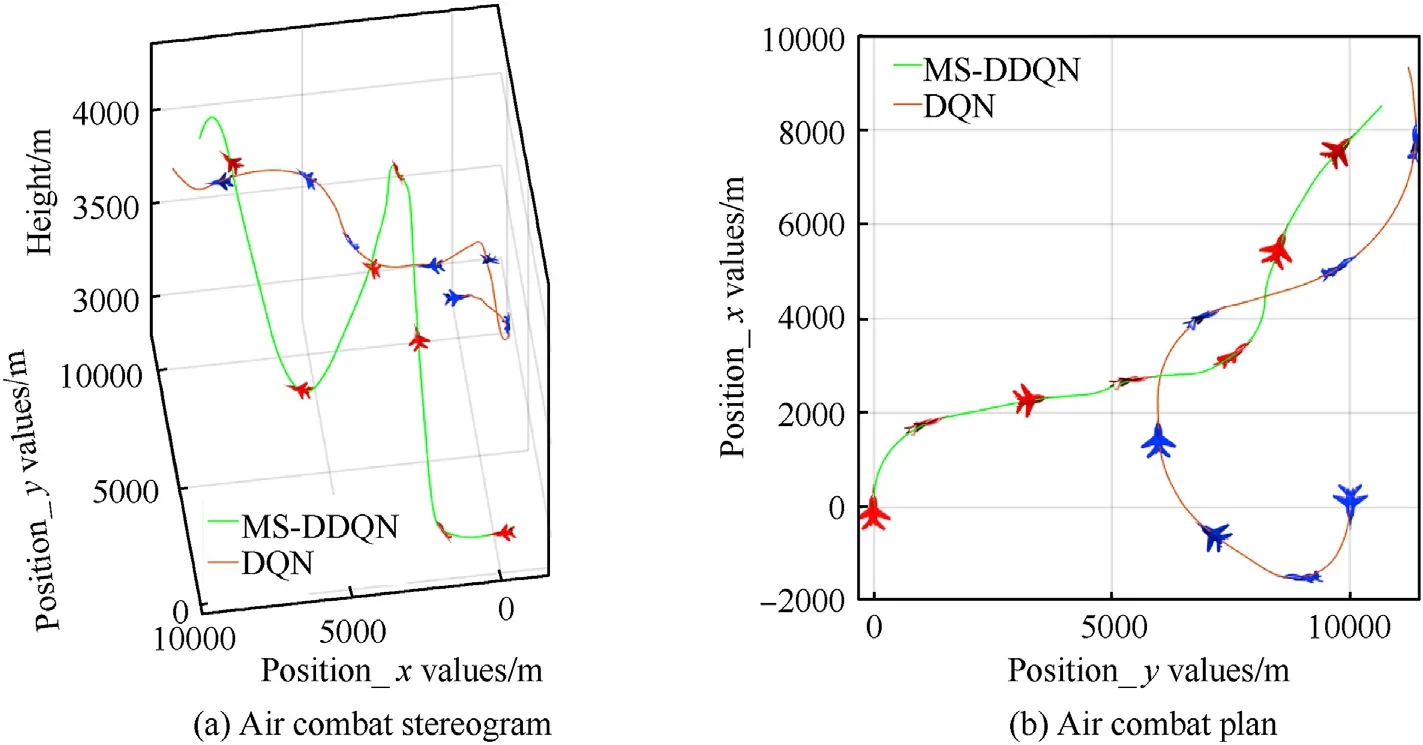
Fig.21.Comparison of MS-DDQN and DQN algorithms for position simulation 5 of a UCAV attacking a turning moving target.
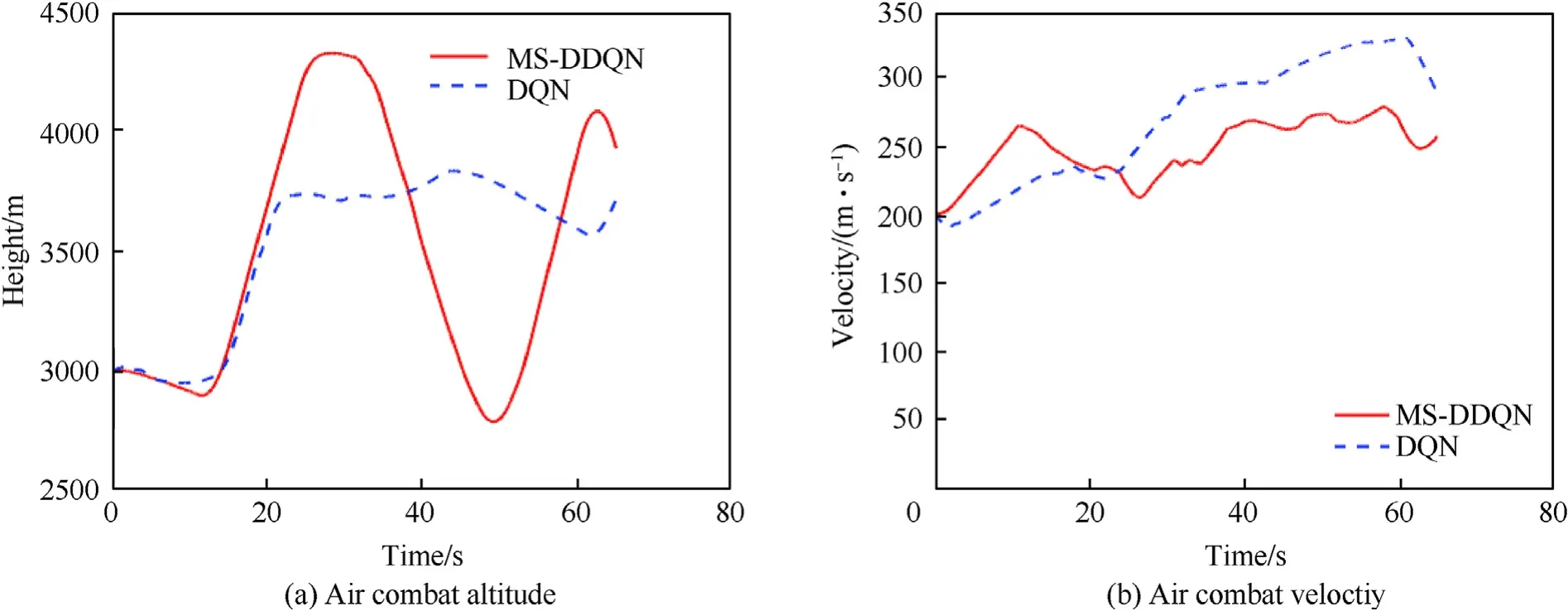
Fig.22.Comparison of MS-DDQN and DQN algorithms for position simulation 5 of a UCAV attacking a turning moving target.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This work is supported by the National Natural Science Foundation of China(No.61573286),the Aeronautical Science Foundation of China(No.20180753006),the Fundamental Research Funds for the Central Universities(3102019ZDHKY07),the Natural Science Foundation of Shaanxi Province(2019JM-163,2020JQ-218),and the Shaanxi Province Key Laboratory of Flight Control and Simulation Technology.
杂志排行

Defence Technology的其它文章
- 3D laser scanning strategy based on cascaded deep neural network
- Damage analysis of POZD coated square reinforced concrete slab under contact blast
- The properties of Sn—Zn—Al—La fusible alloy for mitigation devices of solid propellant rocket motors
- The surface activation of boron to improve ignition and combustion characteristic
- Numerical investigation on free air blast loads generated from centerinitiated cylindrical charges with varied aspect ratio in arbitrary orientation
- Natural convection effects on TNT solidification inside a shaped charge mold