基于Spark的配电网数据挖掘及处理研究
2022-09-21吕颖利李志强
吕颖利,李志强
(济源职业技术学院,河南 济源 459000)
0 引 言
配电网的线路故障分析、设备灵敏性计算、无功补偿、潮流计算、网络架构升级以及负荷线损预测等课题的探究都离不开电网负荷和线路拓扑等数据。配电网储存的线路拓扑数据大多为半结构和非结构化,具有波动频率太高、数据容易丢失、无序等缺点,这些都将直接或间接地对配电网负荷预测、无功补偿等技术的研究造成负面影响。同时,由于配电网数据需要消耗大量的计算时间和空间来完成格式转化、清洗筛选以及数据异常辨别等操作,因此需要从长远出发,考虑大数据技术的运用与计算效率的提升,帮助配电网大数据释放能量。本文以配电网非标数据为切入点展开研究,通过结合Spark等大数据技术完成了非标准数据的公用信息模型(Common Information Model,CIM)/可扩展标记语言(Extensible Markup Language,XML)统一格式转换。该方法依据弹性数据集的分布情况将弹性分布式数据集(Resilient Distributed Datasets,RDD)当成数据载体,同时和传统的MapReduce数据挖掘处理方式进行对比,极大地缩短了数据并行处理的时间。
1 CIM/SVG数据格式
CIM是一种关于如何描述电力行业设备数据及应用数据信息的国际化行业标准。在CIM中,CIM/XML作为一种国际化标准语言,旨在构建规范化的电力拓扑模型。可缩放矢量图形(Scalable Vector Graphics,SVG)是一种用于对图形界面进行设计和优化的标准语言,由万维网联盟(World Wide Web Consortium,W3C)研制开发。
如今,CIM模型与SVG语言已经在电网的生产精益化管理系统等系统中得到运用,电网的运维人员可以根据实时电网拓扑图监测设备的运行状态,从而迅速开展故障消缺等工作。可是当需要进行配电网的线路故障分析、设备灵敏性计算、无功补偿、潮流计算、网络架构升级以及负荷线损预测等研究工作时,由于在系统数据库下载的CIM、SVG等数据具有非标准化、非结构化的特征,因此不能采用[1]。传统的CIM/XML和SVG大都用文件对象模式(Document Object Mode,DOM)和XML的简单应用程序接口(Simple API for XML,SAX)等进行分析,得出电网拓扑数据的关联,但同时具有效率低下、面对重大损失无法挽救线路拓扑和平台相关应用、无法结构化拓扑数据等缺点。
针对以上缺点,本文采用Spark中的内存分布式计算引擎、分布式图形计算以及分布式数据分析等库,对来自于配电网系统的CIM、SVG等数据进行提炼聚合,从而获取到线路拓扑与地理位置的有效信息。同时,结合提炼的信息建立基于有向线性序列的配电网数据表,并对拓扑图中供电区域进行逐一划分,给无功补偿、潮流计算等研究奠定了基础。
2 地理位置与线路拓扑信息的提取
实际上,电网中的CIM模型和SVG语言能够实现数据规范化,主要归功于它们是包含统一标准字符数组的数据文件。本文根据规则表达式的模式,分析和提炼出CIM/XML、SVG中有效拓扑数据信息。
2.1 规则表达式
1951年,美国科学家Stephen Kleene首次阐述了规则表达式的概念。规则表达式亦可称为正则表达式,它是一种特殊工具,用于字符串数据的相关操作,实质上是一种关联规则,用来对字符串进行匹配。规则表达式具有很多优点,如便捷性,可以用于提取、调换及搜索各类繁杂的字符串,同时还具有效率高、错漏率低等优点,可以满足Web的提取功能、辨别功能、抽取功能以及自动查看功能等要求[2]。
2.2 地理位置信息提取
SVG拥有相关几何和地理数据用于配电线路拓扑存储。本文通过提取SVG中各类型设备的地理位置坐标来完成配电网网络架构的优化以及数据信息提取速度的提高。配电网中的设备由点型、线型以及复合直线型构成,点型设备的位置坐标由一个横坐标值和一个纵坐标值确定,而线型和复合直线型设备的位置坐标分别由两个横坐标和纵坐标组成。
在进行规则匹配时,需要采用不同的规则表达式来匹配不同类型的设备位置坐标。对配电网中SVG数据通过规则表达式匹配后得到电网设备的具体地理位置坐标信息。
2.3 线路拓扑信息提取
通过CIM/XML语言中的端点对象来描述配电网线路拓扑数据间的联系,电网设备可以依据端点的个数进行分类,主要包括单端点与双端点两种设备类型。汇流母线、营销电表等设备仅有一个端点,因此属于单端点设备,而隔离开关、电缆等设备有两个端点,属于双端点设备。结合CIM/XML语言对配电网线路拓扑关联度进行研究和分析,大致流程如图1所示。
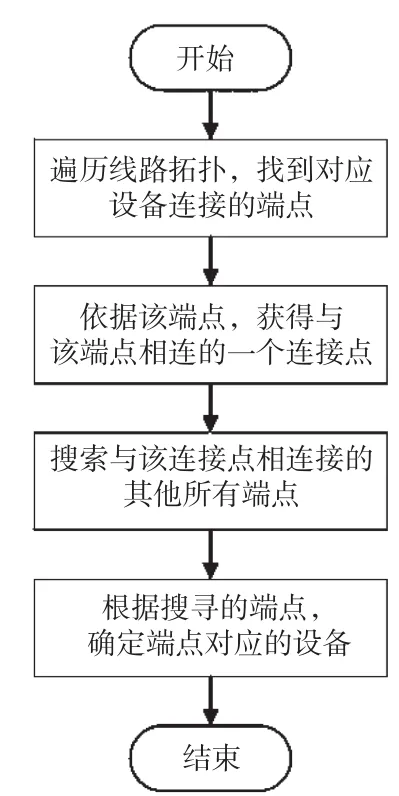
图1 基于CIM/XML线路拓扑关联度分析流程
配电网的线路故障分析、设备灵敏性计算、无功补偿、潮流计算、网络架构升级以及负荷线损预测等探究还要用到线路拓扑中设备的电压级别和开关状态等参数信息。由上述对设备具体参数的CIM/XML描述,可以通过设计规则表达式用于匹配与设备ID相关联的电压级别与开关状态[3]。
3 拓扑中结构化数据构建
3.1 拓扑设备的规约转换
通过建立规则表达式匹配获取设备的联络端点号、关联电压级别以及关联开关状态等信息,并以设备ID号为关联字段将这些数据信息筛选合并输出,完成线路拓扑所需数据的初始化工作。但是线路拓扑中设备种类繁杂,若直接将初始化的数据拿来使用,则会消耗大量时间,效率不高,因此本文设计了如下规则用以拓扑设备的规约转换操作。
(1)将双端点设备(隔离刀闸、电力电缆、绝缘导线等)由初始化的点型规约转换成线型设备,具体操作是在设备坐标同位置下复制生成一个新的坐标点。(2)将单端点设备(汇流母线、营销电表等)由初始化的线型/复合直线型规约转换成点型设备,具体操作是折中法,即拿设备线段中间位置的坐标替代。(3)将不影响拓扑构建和潮流计算的设备(电流互感器、避雷针等)直接删除。
拓扑设备的规约转换如表1所示,规约转换后的拓扑设备信息如表2所示,描述了拓扑设备的规约转换过程。
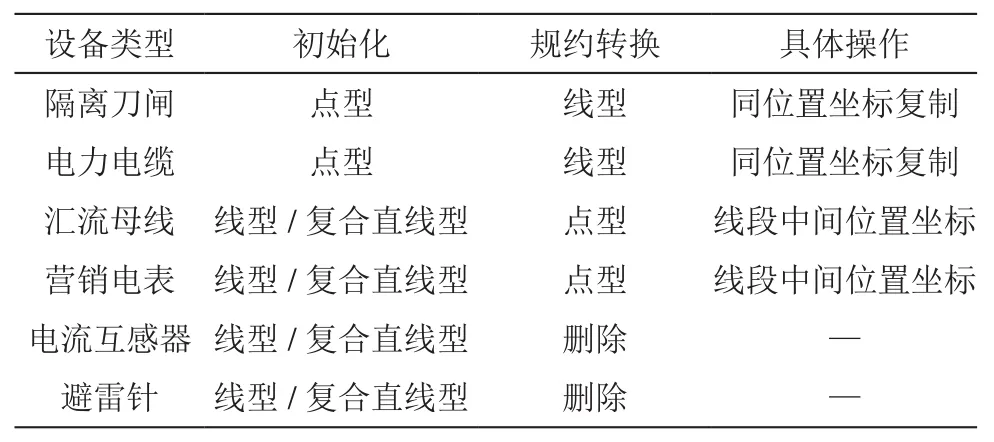
表1 拓扑设备的规约转换

表2 规约转换后的拓扑设备信息
3.2 配电网线路拓扑数据联络架构
上文完成了拓扑设备的规约转换,以此为基石,本文将设备对应端点作为关键字段,实现端点关联设备参数、不同种类设备规模以及端点定位的有效存储,完成配电网线路拓扑数据联络架构的构建[4]。配电网线路拓扑数据联络架构如图2所示。
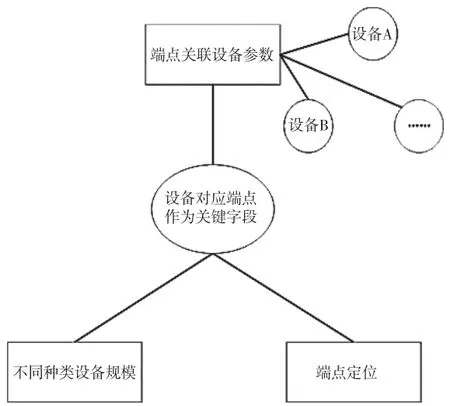
图2 配电网线路拓扑数据联络架构
由于配电网的线路故障分析、设备灵敏性计算、无功补偿、潮流计算、网络架构升级以及负荷线损预测等探究需要使用到配电网线路拓扑数据联络架构中的数据,继续以设备对应端点为关键字段,结合配电网线路拓扑数据联络架构中的数据建立端点坐标匹配表及线路拓扑数据匹配表[5]。
3.3 供电区域划分及线路归并
由于线路拓扑数据匹配表中的数据量巨大,不能直接用于线路故障分析、负荷线损预测等研究,本文根据拓扑的分布特征划分供电区域,进而建立有向的线路拓扑数据匹配表。将各类变电站中的汇流母线视为开始节点,把与汇流母线相连的配电房、环网柜等节点当成结束节点。首先遍历所有的开始节点,其次通过深度优先遍历生成拓扑路径,从而获得有向线型线路拓扑。
每个配电网的供电区域都包含着很多不同的线路,而这些线路也许不通过变压器、绝缘子等电力设备与其他线路直接相连接,这就需要缩小拓扑规模范围,其方法是将线路进行简化、整合,操作步骤如下。若原始线路中存在node1、node2、node3,而node1与node2、node2与node3分别通过类型相似的line1和line2相连,那么可以删除node2,直接将line1与line2的电阻、容抗等参数叠加整合输出成line3,通过line3直接连接node1和node2。线路进行简化、整合后,线路拓扑的数据数量得到有效缩减。
4 基于Spark的拓扑数据分析
前文对采集的配电网原始数据进行整合、简化和匹配等操作,最终获得具有统一标准格式的线路拓扑数据,但由于各个环节数据挖掘和处理的时间与空间复杂度不一致,同时后续无功补偿、潮流计算等研究需要高效率的拓扑数据分析,于是本文结合Spark中的内存分布式计算引擎、分布式图形计算以及分布式数据分析完成线路拓扑中非标数据格式的标准转化,实现过程如下。
(1)线路拓扑的CIM模型及SVG语言格式的数据实际上是由很多有规律性的字符数组构成的XML格式文本。基于Spark拓扑数据分析的关键一步便是把初始数据转化成RDD格式的抽象数据集,而后在node的内存里进行数据存储。图3是线路拓扑的RDD存储模式。
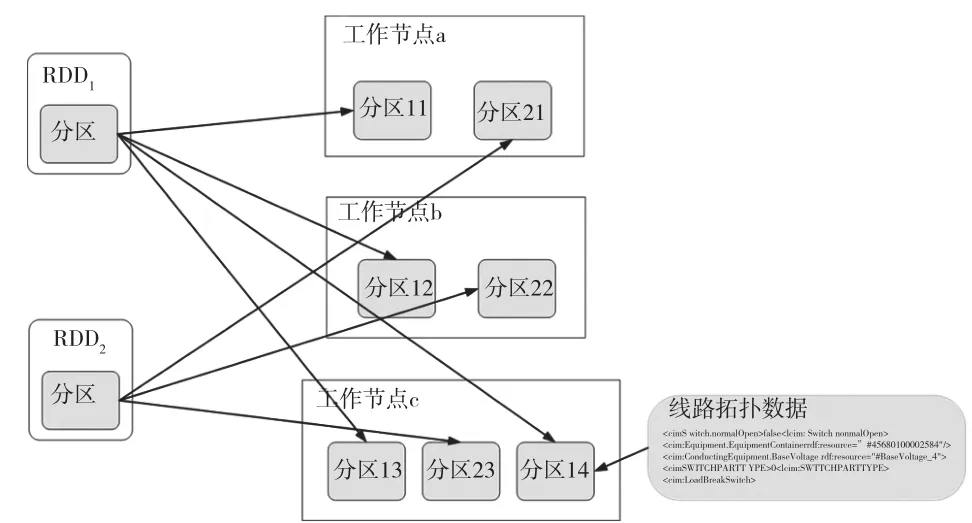
图3 线路拓扑的RDD存储模式
图3中,线路拓扑数据是按分区划分并在工作节点中实现存储。RDD1和RDD2的数据都是在工作节点a、工作节点b以及工作节点c上完成存储,而RDD1由分区11、分区12、分区13以及分区14组成,RDD2由分区21、分区22和分区23组成。
(2)使用Hive中的用户定义表生成函数,将RDD形式存储的线路拓扑数据转换成能被系统直接扫描并使用的数据,极大地缩短了获取线路拓扑数据信息的时间。本文以B供电公司的配电网数据为例,大约120种配电设备的总数量接近35万,通过以上方式提取线路拓扑数据信息,总计得到384 426条地理位置数据、756 597条设备ID关联端点号数据、304 541条电压级别数据以及70 343条开关状态数据。
(3)以设备对应端点为关键字段,结合配电网线路拓扑数据联络架构中的数据建立端点坐标匹配表及线路拓扑数据匹配表,表中包含215 643条端点坐标匹配数据和214 582条线路拓扑数据匹配数据。根据拓扑数据node与line的地理位置信息,绘制出B供电公司a区域的配电网线路拓扑结构图。
(4)由于经常出现很多条线路直接连接在一起的现象,因此在对线路归并整合时应该重复对提取的数据进行计算。就拓扑线路简化、整合流程图来说,使用并发编程框架将line1、line2和node1、node2、node3的数据转换成RDD格式,同时使用分布式图形计算模型将上述line和node转换成线与点,同时在内存中归并整合后存储数据。Spark技术的最大优点就在于它不需通过磁盘而直接在内存中读写,这有利于减少配电网拓扑数据处理的时间开销,从而提高运行效率。
5 基于粒子群优化算法的配电网数据挖掘分析
集成和处理后的配电网数据由于量大不免会存在一些离群数据文本,本文采用粒子群优化算法对配电网拓扑数据中的负荷聚类中心进行优化,并用K-means方法确定最佳聚类数。为了验证粒子群算法的可行性,对B供电公司3个区域的配电网馈线运行数据进行了仿真测试,包括配电变压器容量、配电变压器月平均负荷数据和配电变压器月最大负荷数据。根据不同的时间和区域进行混合、剔除处理,共有940个数据。
分别对样本的相关馈线数据进行归一化计算后,确定初始最优K值。根据粒子群算法对数据进行排序时,参考相关文献的参数设置,当聚类数K=3时,最大迭代次数设置为200。粒子群优化算法后的排序效果如图4所示。

图4 配电变压器参数的三维散点
从数据集来看,有3个聚类,聚类1有600多个数据向量,聚类2有200多个数据向量,每个数据向量有3个特征,其中聚类的每个特征根据不同的簇分布。3类数据的样本在一定程度上是交错的,由于它们的高度不同,因此无法清晰看到样本数量。特别是第一种数据点比较分散,但是其他种类的数据点比较集中。应清理平均月负荷的3个异常值,清理最大月负荷的9个异常值,即直线以上的12个点,从而完成配电变压器运行数据的预处理。离群样本诊断作为数据预处理中最为关键的一个环节,重点是找出和别的样本有显著差异的离群点。离群样本剔除对故障预测模型的构建影响不大,但有助于提高模型的预测精度,因此离群样本被视为噪声。
为了测试和验证聚类操作的可靠性,分析了从组中提取的拒绝最大负荷样本的异常值,这可能是由于数据采集终端故障,导致无法收集一些数据,从而同时产生几个月的异常数据,但这也表明异常值的诊断可靠。
6 结 论
本文重点研究了基于Spark的配电网线路拓扑数据挖掘和处理,实现了非标准数据的CIM/XML统一格式转换,同时利用Spark中的内存分布式计算引擎、分布式图形计算以及分布式数据分析等库,对来自于配电网系统的CIM、SVG等数据进行提炼聚合,并使用抽象数据集RDD作为数据载体,极大缩短了数据并行处理的时间。而后通过采用粒子群优化算法使得聚类效果有了很大提高,粒子群聚类算法能够有效、可靠地诊断和消除异常值,对研究配电网系统各类故障因素的影响具有重要意义。
