基于YOLOv3的SAR舰船图像目标识别技术
2022-09-19张官荣张海珠
张官荣, 赵 玉, 李 波, 陈 相, 张海珠
(1.空军工程大学航空工程学院,西安 710000; 2.中国人民解放军95949部队,河北 沧州 061000)
0 引言
水上交通运载是海域战争中双方进行激烈较量的重要方面,而舰船是世界各国海上运输的主流交通工具,对于海域情况的精确探测具有重要作用。合成孔径雷达(Synthetic Aperture Radar,SAR)技术通过脉冲压缩,同时利用合成孔径提高雷达距离向和方位向的分辨率,进而获取全天候、全天时的SAR图像[1]。基于SAR图像的自动目标识别(Automatic Target Recognition,ATR)技术,是通过传统的SAR方法自动估计目标的状态,并形成了固定的信息处理流程,即对目标的检测、鉴别和分类[2],其核心是提高算法的解译效率和准确率。目前,SAR ATR技术已广泛应用于无人机、卫星等搭载平台,通过对海港、海洋表面舰船的实时监测和观察来获取重要的海域军事情报。
近年来,深度学习技术,尤其是以卷积神经网络(Convolutional Neural Network,CNN)为基础的算法突飞猛进,避免了繁琐的人工设计特征算法,同时,在各类下游任务中被证明具备优秀的精度和较强的鲁棒性,在SAR图像检测识别的领域,基于卷积神经网络的算法也具有强大的性能,因此被广泛研究。研究人员基于深度学习技术设计了针对图像任务的多样化卷积神经网络模型,例如AlexNet[3],VGG[4],Googlenet[5],ResNet[6],DenseNet[7]等。而图像目标检测任务则基于以上基础模型进行特征提取,之后根据是否需要提取目标候选框分为两种研究方式:第一种是需要目标候选框的两阶段检测算法,以R-CNN[8]检测算法为代表;另外一种则不需要额外的区域候选网络,因此被称为单阶段检测算法,以YOLO[9-10]系列检测算法为代表。相比于传统的SAR图像目标检测的研究成果,基于深度学习的SAR图像检测技术既确保了时效性,又提升了模型精度。因此,本文以YOLOv3为基础网络,对SAR ATR技术开展研究工作,同时采用了Faster R-CNN作为对比网络,保证了实验的完整性。
1 YOLOv3网络
1.1 Darknet-53主干网络结构
在基本图像特征提取方面,YOLO3采用了Darknet-53网络结构,包含53个卷积层,由一系列1×1和3×3的卷积层组成。其网络结构如图1所示。
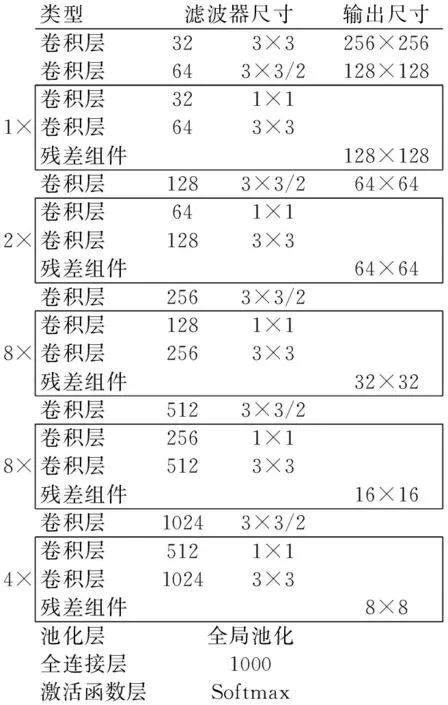
图1 Darknet-53网络结构Fig.1 Darknet-53 network structure
Darknet-53网络在一些卷积层之间设计了残差组件用于解决网络变深带来的性能退化问题,如图2所示。其中,x表示残差的上层特征输入,F(x)表示学习到的残差,F(x)+x则表示残差组件的输出。

图2 残差组件结构图Fig.2 Structure diagram of residual component
1.2 YOLOv3网络
YOLOv3使用Darknet-53作为网络的分类主干部分,通过调节卷积层的步长控制输出特征图的尺寸。同时,YOLOv3借鉴特征金字塔网络(Feature Pyramid Networks,FPN)的思想,采用上采样和特征融合的方法输出3个尺寸的特征图,用于不同尺寸目标的检测。第1个特征图下采样32倍,适用于较大目标的检测;第2个特征图下采样16倍,适用于中型目标的检测;第3个特征图下采样8倍,适用于小型目标的检测。YOLOv3网络结构如图3所示,其中,5L表示共5层。
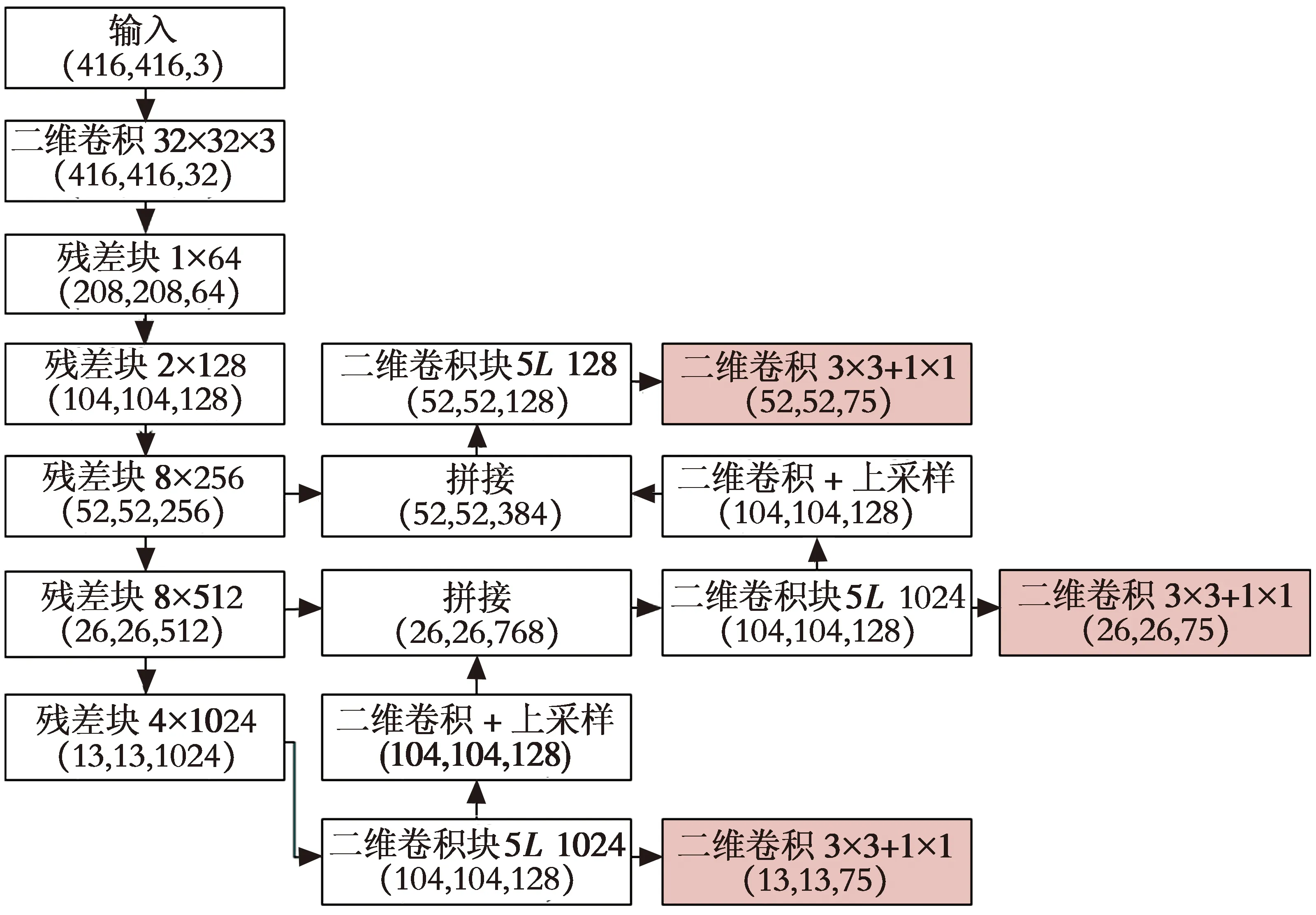
图3 YOLOv3网络结构图Fig.3 Structure diagram of YOLOv3 network
1.3 多尺度先验框
YOLOv3网络结构通过K-means聚类获取不同尺寸的先验框,分别聚类为373像素×326像素,156像素×198像素,116像素×90像素,59像素×119像素,62像素×45像素,30像素×61像素,33像素×23像素,16像素×30像素和10像素×13像素9种大小,分别为3种不同的下采样尺度提供3种大小的先验框。先验框的尺寸根据目标的大小分配,如图4所示,图4(a)表示较大的目标分配前3个较大的先验框,特征图大小为13像素×13像素;图4(b)表示中等的目标分配中间3个尺寸的先验框,特征图大小为26像素×26像素;图4(c)表示尺寸较小的目标分配后3个较小的先验框,特征图大小为52像素×52像素。
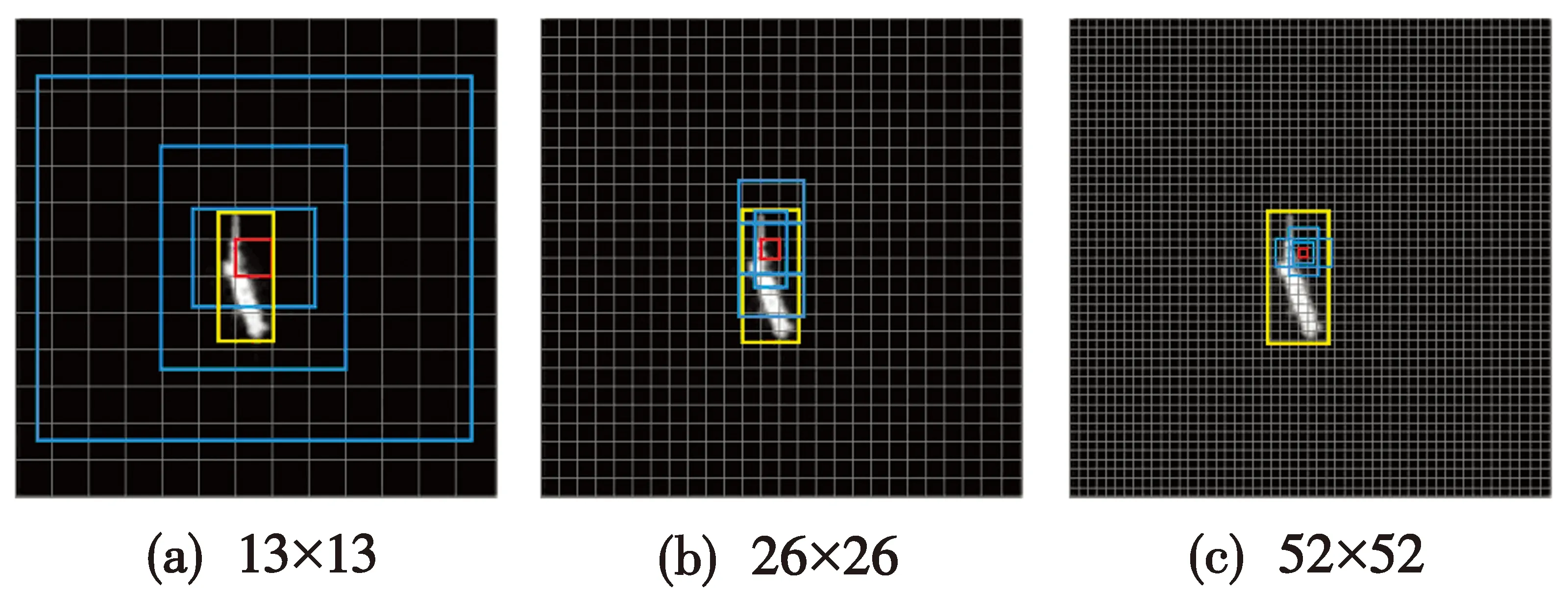
图4 目标不同尺度的像素级先验框和特征图Fig.4 Pixel-wise prior boxes and feature map for different scales of object
若目标的中心如图5所示,当被测目标中心点落入某网格时,则由该网格进行预测。YOLOv3通过目标中心与对应网格的偏移量进行预测回归。
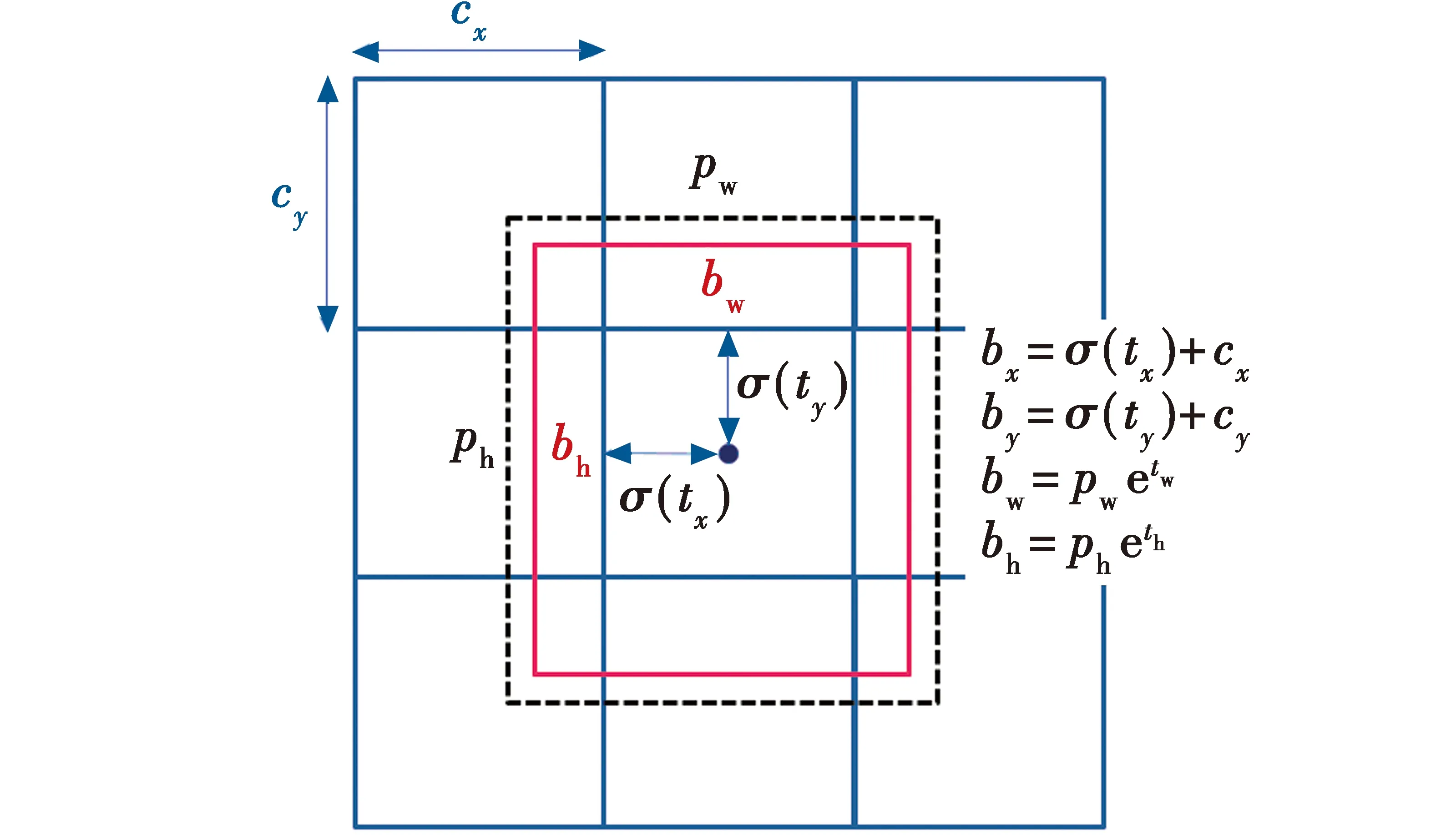
图5 边框预测Fig.5 Bounding box prediction
其中:(cx,cy)表示进行预测网格的左上角像素位置;tx,ty表示被检测物体的中心像素位置与左上角像素位置的偏移距离;pw,ph分别表示特征值置信图内的宽和高;(bx,by)表示预测锚框中心点的位置;bw,bh分别表示预测锚框相对于特征图的宽和高;通过Sigmoid函数σ(·)将偏移距离tx,ty压缩至[0,1]内,保证被测物体中心能落入进行预测的网格中;tw,th分别表示特征图宽和高的尺度缩放因子。
1.4 损失函数
对于给定图像,将其分为S×S个网络,每个网络将产生B个box。YOLO系列模型使用均方误差作为损失函数,其由置信误差lobj、分类误差lcls,以及预测位置误差lbox组成,即
l=lbox+lcls+lobj
(1)
式中,
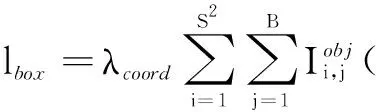
(2)
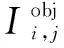
(3)
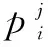
(4)
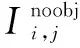
2 实验过程及结果
2.1 数据集介绍
本实验采用公开的SAR图像船舶检测数据集[11],其主要源于Sentinel-1 SAR数据和国产高分三号SAR数据,涵盖了不同模式下、非同源的43 819幅SAR舰船图像切片和对应标签,可用于目标检测任务,部分可视化表达如图6所示。

图6 部分可视化SAR舰船图像数据Fig.6 Partial SAR ship image data
2.2 模型训练
本文训练和测试的环境基于Ubuntu16.04系统,Pytorch1.7.1框架,CUDA10.1,GPU使用GTX2080,优化器选取经典的随机梯度下降算法,权重衰减为0.000 5,学习率为0.001,训练批次为50 000,损失函数变化曲线如图7所示。整个模型通过有监督的训练方式,设计损失函数回归和优化SAR舰船图像目标识别模型。
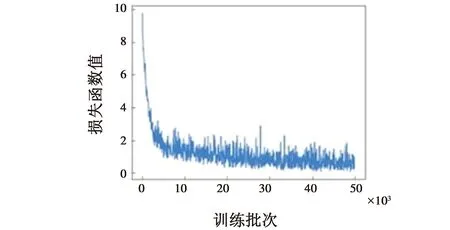
图7 网络训练损失曲线Fig.7 Network training loss curve
2.3 实验结果
本实验采用的评价指标为主流的mAP指标,该指标是所有检测目标类别准确率AP的平均值,衡量模型在各类别上识别效果的平均水平。同时,本实验采用在目标检测领域较为成熟的Faster R-CNN作为对比算法,测试结果如表1所示,表1中FPS (Frames Per Second)表示算法的每秒检测帧数,反映其检测速度。
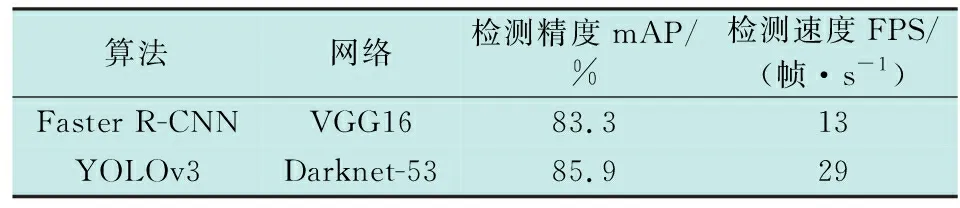
表1 测试结果对比Table 1 Comparison of test results
由表1可见,YOLOv3网络的检测性能在检测精度与检测速度上均优于Faster R-CNN,尤其对于检测速度的提升,且由于SAR舰船图像相对于海域目标较小,YOLOv3网络中的特征金字塔网络(FPN)提升了小目标的检测精度,因此,YOLOv3相比Faster R-CNN的性能在检测精度和检测速度方面均有所提升。YOLOv3检测结果如图8所示,其中,场景1~6仅为部分结果展示,无具体指代。

图8 SAR舰船检测结果Fig.8 SAR ship detection results
3 总结
本文针对SAR图像自动目标识别面临的关键问题展开了深入研究,设计了一种基于YOLOv3网络的SAR舰船图像小目标检测模型,该模型基于Darknet-53主干网络提取图像的浅层特征,以多尺度先验框对目标物体进行检测。实验结果表明,基于YOLOv3的网络对小目标的检测算法在SAR舰船检测的任务上取得了很好的效果。
