基于混合域注意力机制的服装关键点定位及属性预测算法
2022-09-19雷冬冬王俊英董方敏臧兆祥聂雄锋
雷冬冬,王俊英,董方敏,臧兆祥,聂雄锋
(三峡大学 a.水电工程智能视觉监测湖北省重点实验室;b.湖北省建筑质量检测装备工程技术研究中心,湖北 宜昌 443002)
近年来服装视觉的应用日益广泛,如模拟试衣间、同款搜图、换装游戏等,具有较大的潜在应用价值。实际应用中服装视觉算法面临各种挑战,如由模特姿势引起的服装变形和服装遮挡,服装款式、材质和剪裁上的差异,以及同款服装在“买家秀”和“卖家秀”中的差异等。神经网络作为解决视觉分析领域问题的重要方法之一,得到了广大研究人员的青睐。
神经网络在诞生之初吸收了生物学的原理本质,并在后续发展中脱离了生物细节,使用更加讲究效率的数理工科思维,从而取得成功。研究者们基于神经网络所做的服装视觉分析工作[1-7]也取得了显著成效,主要体现在服装关键点检测、服装检索和服装的属性预测等方面。基于姿态估计的方法[8-9]通过对服装姿态进行估计消除了服装姿态对服装关键点检测的影响。基于约束的方法[3,10-11]在算法模型中加入语义约束,利用布局约束或空间关系等语义约束提高服装关键点检测的性能。基于注意力机制的方法[12-15]识别图像的不同成分,使神经网络能够在解决如服装检测、检索、姿态估计等特定问题时应更多关注图像中的哪些特征。
考虑到服装的非刚性变形较大,不同模特姿态和服装风格下服装的关键点存在较大的空间差异,本文提出一种基于混合域注意力(mixted domain attention, MDA)机制的服装关键点定位及属性预测算法,利用循环十字交叉注意力(recurrent criss-cross attention,RCCA)[16]模块获取服装关键点之间潜在的空间关系,通过高效通道注意力(effective channel attention,ECA)[17]模块获得通道之间的交互信息,以期优化算法模型的性能,提高服装关键点定位、服装分类以及属性预测效果。
1 服装关键点定位及属性预测算法
基于混合域注意力机制的服装关键点定位及属性预测算法(MDA-DFA)是在Deep Fashion Analysis(DFA)[7]算法的基础上,引入RCCA算法和ECA算法来融合空间域和通道域注意力机制,以便更好地提取服装特征,最终提高服装关键点定位和属性预测效果。
1.1 DFA算法
DFA算法[7]主要是基于VGG-16网络,如图1所示。该算法将原始图像的大小调整为224像素×224像素,采取与VGG-16网络相同的初始卷积操作,在Conv4_3层后利用连续的卷积和转置卷积操作生成关键点热图进行定位。关键点热图特征和Conv4_3卷积特征共同组合成新的注意力映射,使得DFA网络可根据局部关键点和全局特征更灵活地聚焦服装的重要功能部分。
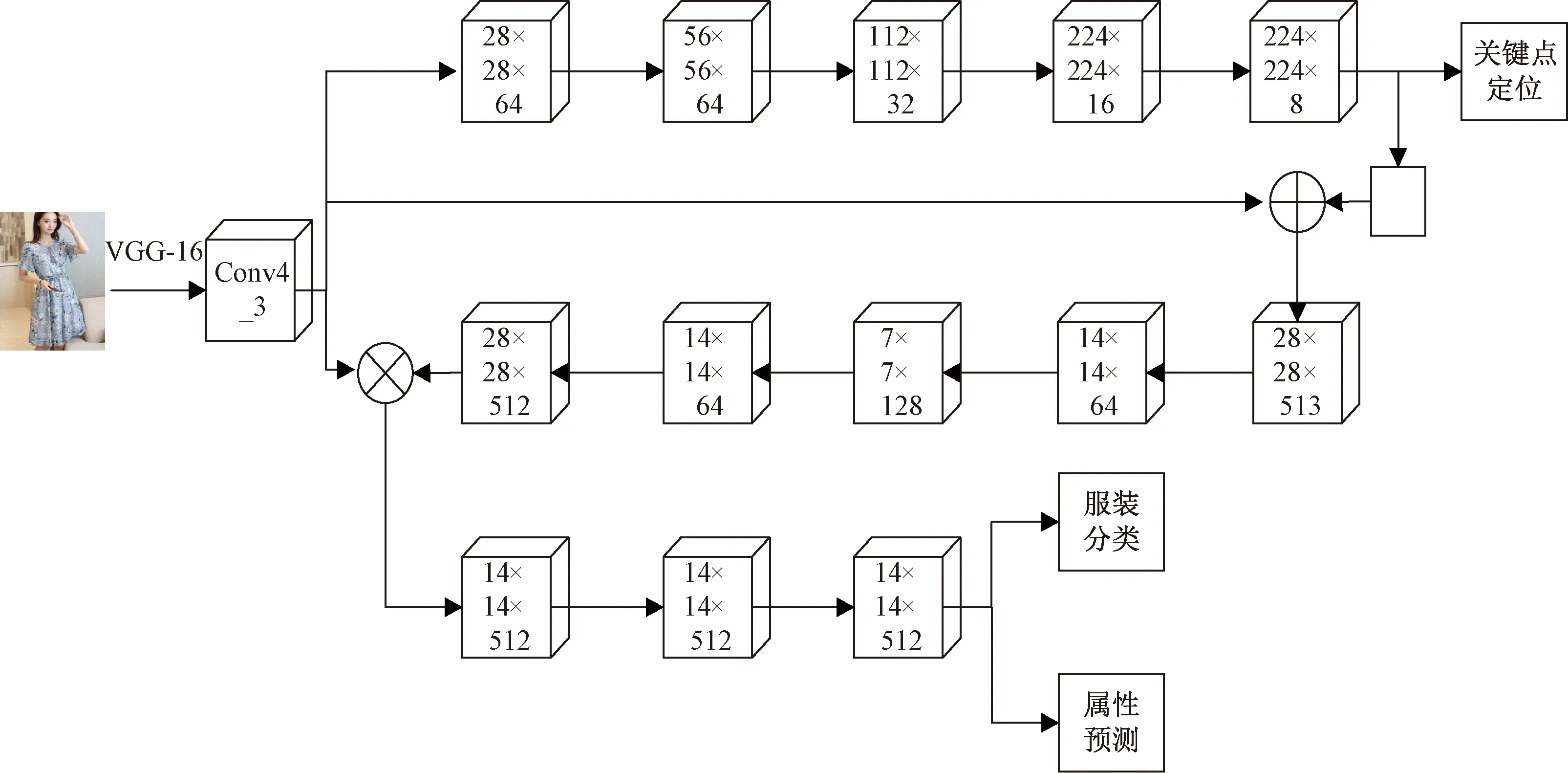
图1 DFA网络架构Fig.1 Network architecture of the DFA
DFA算法利用转置卷积对特征图进行上采样,获得的关键点热图在具有高分辨率的同时未丢失信息,与输入的服装图像具有相同的尺寸,可提高服装关键点定位的准确性。其以关键点热图为基础产生统一的空间注意力机制,使网络具有足够的信息去增强或减弱特征,避免了特征选择中的硬确定性约束,可取得较好的分类和属性预测效果。
1.2 全局信息模块
因服装关键点之间存在潜在的空间联系,为获得服装图像的全局特征,利用非局部空间连接算法中的RCCA算法获取特征的全局联系,从而捕获关键点之间的空间关系。RCCA算法是将Criss-Cross Attention(CCA)重复操作R次,通过计算任意两个位置间的交互直接捕捉远程的上下文信息,而不局限于相邻的点,相当于构造了1个和图像尺寸相同的卷积核,因此可以获得全局信息。
CCA[16]的运算过程如图2所示。给定局部特征映射F∈C×W×H,对F分别应用1个带有1×1滤波器的卷积层后,得到两个特征映射Q和K,其中{Q,K}∈C′×W×H,C′为降维后的通道数。

图2 CCA算法的细节Fig.2 The details of the CCA algorithm
得到Q和K后,通过Affinity运算和归一化处理进一步生成注意力映射图A∈(H+W-1)×(W×H)。在Q的空间维度的每个位置u都可以得到一个向量Qu∈C′。通过从与位置u在同一行或同一列的K中提取特征向量获得集合Ωu∈(H+W-1)×C′。Ωi,u∈是Ωu的第i个元素。Affinity运算的定义如式(1)所示。
(1)
式中:di,u为特征Qu和Ωi,u的关联度,di,u∈D,i的取值范围为1到H+W-1的整数,D∈(H+W-1)×(W×H)。在D的通道维度上应用Softmax层计算注意力映射图A。
在F上应用另一个带有1×1的滤波器的卷积层生成V∈C×W×H用于特征自适应[16]。在V的空间维度的每个位置u,都能得到1个向量Vu∈C和1个集合Φu∈(H+W-1)×C。集合Φu是V中与位置u同行或同列的特征向量的集合。上下文信息由式(2)定义的Aggregation运算收集。
(2)
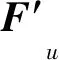
RCCA算法模块首先将局部特征映射F输入到CCA模块中,聚集十字交叉路径中的每个像素的上下文信息生成1个新的特征映射F′,则特征映射F′同时包含水平和垂直方向上的上下文信息。为获得更丰富、密集的上下文信息,将特征映射F′再次输入到CCA模块中,并输出特征映射F″。特征映射F″中的每个位置实际上收集了服装图像上所有像素的信息,捕获了长依赖关系。前后两个CCA模块可共享相同的参数,避免增加额外的成本。
1.3 通道注意力模块
DFA算法采取均分权重的方法处理通道域中的图像特征信息,然而,各通道域中的图像特征信息对分类和属性预测的影响是各不相同的。因此,在提出的MDA-DFA算法中引入通道域注意力机制。通道域注意力机制的原理为通过建立不同通道之间的相关性,基于网络学习的方式自动获取每个特征通道的重要程度,据此赋予每个通道不同的权重系数,从而强化重要的特征并抑制不重要的特征。具体操作:在RCCA算法和关键点注意操作后,网络的通道注意模块根据通道对服装分类和属性预测任务贡献的程度为512个通道分配权重,然后将其与原始特征映射相乘,得到加权的服装特征映射。
现有的通道注意力方法多致力于开发复杂的网络模块以实现更好的性能,因此不可避免地增加了模型的复杂性。而ECA网络在全局平均池化操作后,利用大小为k的一维卷积考量各通道及其k个邻居,从而在不降维的情况下捕获局部跨通道交互信息,克服了网络模型的性能与复杂性之间的矛盾。给定不降维的聚合特征y∈C,通过式(3)学习通道注意力。
ω=σ(Wy)
(3)
式中:W为一个C×C的参数矩阵,使用带状矩阵即式(4)学习通道注意力。
(4)
对式(4)来说,计算yi的权重时只需考虑yi和它的k个邻居之间的相互作用,如式(5)所示。
(5)
式中:Ωi,k为yi的k个相邻的通道的集合。
为了进一步提高性能,利用式(6)所示的方法使所有通道共享相同的学习参数。
(6)
这种让所有通道共享相同学习参数的方法可以通过式(7)实现。
ω=σ(C1Dk(y))
(7)
式中:C1Dk表示卷积核大小为k的一维卷积。使用这种跨通道交互的方法只涉及k个参数,在模型复杂度较低的情况下保证了ECA模块的效率和性能。
给定通道数C,根据式(8)确定内核大小k。
(8)
式中:|t|odd表示最接近t的奇数。将通道数代入式(8)计算得到k=5。
鉴于空间域注意力机制和通道域注意力机制在图像特征提取方面的优势,提出混合域注意力机制模型以充分利用两个注意力的信息,从而获得更好的服装关键点定位和属性预测效果。
1.4 算法结构
MDA-DFA算法的整体架构主要分为5个阶段,如图3所示。
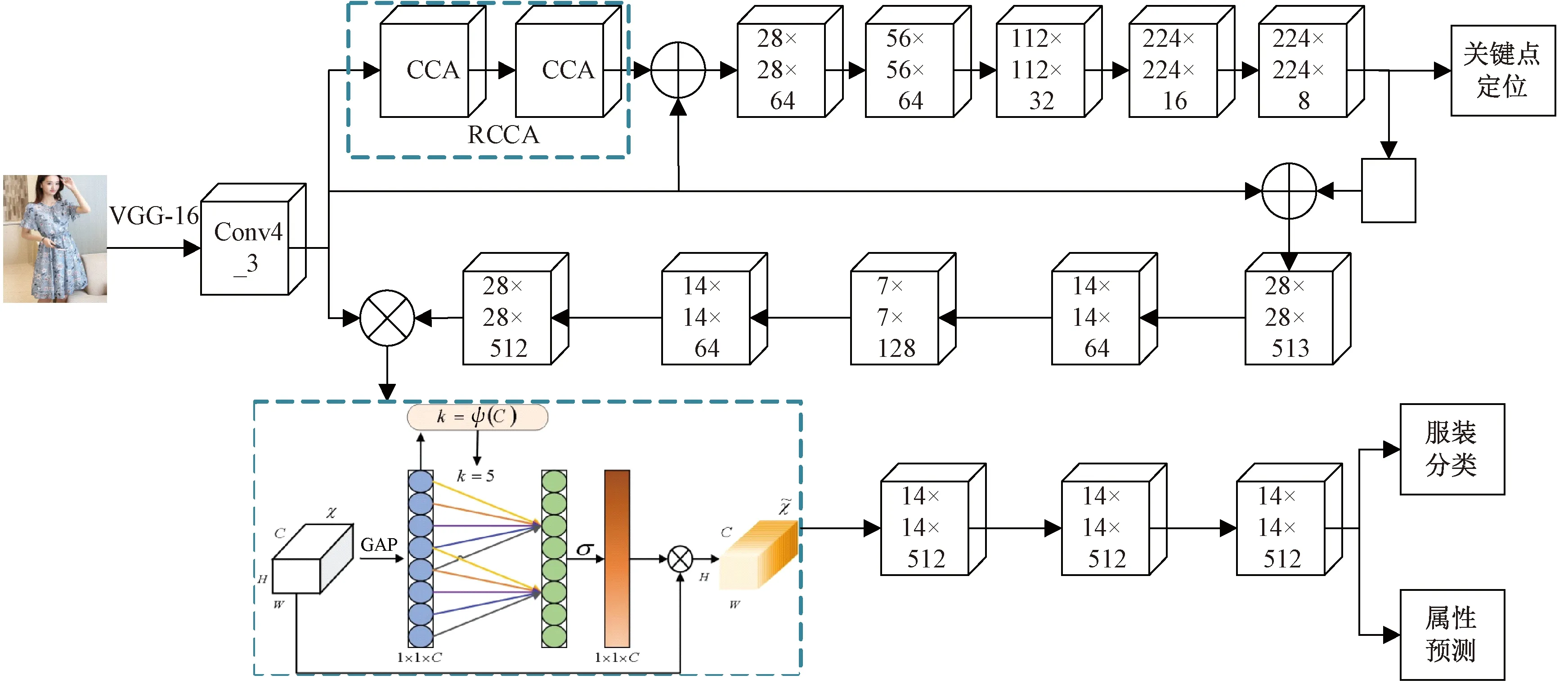
图3 MDA-DFA算法的网络架构Fig.3 The network architecture of MDA-DFA algorithm
阶段1:利用VGG-16的前4层网络提取原始服装图像的特征映射。
阶段2:将阶段1的输出,通过RCCA模块建立特征的全局联系,预测服装的关键点位置。
阶段3:基于阶段2的特征生成服装关键点热图,将阶段1得到的特征映射与热图进行通道拼接,再输入到空间注意力网络,得到加强服装关键点信息后的特征映射。
阶段4:将阶段3得到的特征映射与初始特征进行融合,再通过ECA网络建模卷积特征各通道之间的作用关系,从而改善网络模型的表达能力,更好地获取服装特征。
阶段5:将阶段4获得的特征送入VGG-16第5层及之后的网络,再分别对服装图像进行分类和属性预测,得到相应的结果。
2 试验设计与结果分析
2.1 试验平台和数据集
试验采用的平台配置为Inter i7 CPU,GTX1080GPU,16 GB内存;软件为Ubuntu操作系统,Python 3.6语言在Pytorch框架下实现。
试验采用的数据集为当下权威的服装评测数据集之一,香港中文大学多媒体实验室开源的大型服装数据集Deep Fashion[6]。该数据集含有非常丰富的标注信息,包括服装主体bounding box、服装类别、1 000种属性(细节特征)、8个服装关键点;数据中有正常、中等、严重等不同程度的变形图片;服装图片的视角按照人体穿着分为上半身、下半身、全身,其服装关键点个数分别为6、4、8。
2.2 试验设计及步骤
给定一个服装图像I,目标是预测服装关键点的位置L(见式(9))、服装类别B以及服装属性向量A。在DeepFashion数据集中,所有服装被分为50类,类别标签满足0≤B≤49。服装分类预测可视为一个1-of-k(哑编码)的分类问题,如“14”表示斗篷(Poncho),属于上身衣服,“25”表示牛仔裤(Jeans),属于下身衣服,“40”表示连衣裙(Dress),属于全身衣服;属性预测为多标签分类问题,标签向量A=(a1,a2,…,an),其中n为属性总数,ai∈{0,1},ai=1表示服装图像具有第i个属性,反之则不具有。
L={(x1,y1),(x2,y2),…,(xnl,ynl)}
(9)
式中:xi和yi是每个关键点的坐标,nl为关键点的总数。试验采用的数据集标注是8个关键点,故nl=8。
设计5组对比试验以改进服装关键点定位、分类与属性预测效果。
试验1:基于DFA网络架构,在第1次卷积和转置卷积阶段后加入RCCA网络模块,以克服多次卷积对图像像素之间上下文信息提取不足的局限性。
试验2:优化网络结构,将RCCA网络模块移至所有的卷积和转置卷积操作之前,以保留更多的原始全局信息。
试验3:基于DFA算法,利用试验2的设计获取图像像素之间的上下文信息,将关键点之间的内在联系用于服装分类与属性预测。
试验4:在试验3的基础上,在空间注意力网络之后加入ECA网络模块,让网络学习通道之间的交互信息。
试验5:MDA-DFA算法。将试验3和4的设计结合起来,在网络架构引入RCCA和ECA模块,融合空间域和通道域注意力机制,以更好地提取服装特征。
试验步骤:
(1)读取数据集及初始设置。读取数据集的路径、图像标注等相关信息;设置批次、批大小、学习率等初始参数。初始学习率设置为0.000 1,并以0.9的线性衰减率衰减。整个模型训练10个回合,训练的批处理大小为16。
(2)创建info.csv文件。将数据集中所有的标注信息整合到文件info.csv中,以满足机器学习的要求。其中每一行代表一张图片,包含图片ID、类别、关键点位置、属性、bounding box等信息。
(3)数据集预处理。定义服装图片的增广函数,进行翻转、随机裁剪、中心裁剪、随机翻转等多种预处理操作,增强数据的稳健性,处理后图片的尺寸为224像素×224像素。
(4)搭建基础网络架构。首先定义整个VGG-16的网络架构,然后定义高斯核函数和损失函数。
(5)搭建关键点定位的网络。首先定义关键点上采样函数,然后定义关键点提取函数和训练网络。
(6)搭建RCCA网络。定义实现RCCA的函数。
(7)搭建ECA网络。定义实现ECA的函数。
(8)提取初始特征。通过在ImageNet数据集上加载了VGG-16的预训练模型对本文的模型参数进行初始化。
(9)训练数据。设置相关的参数进行训练,每10个step显示一次计算出的损失值。
(10)预测关键点。训练结束后,根据训练好的模型对测试集进行预测。将关键点的热图记为M′∈R224×224×8,添加高斯滤波器,对关键点热图进行可视化处理。关键点定位采用均方误差(MSE)的损失函数,如式(10)所示。
(10)
式中:N为数组元素的总数,i,j∈(0,224)。
(11)预测类别与属性。训练结束后,根据训练好的模型对测试集进行预测。分别使用两个全连接层预测服装图像的类别和属性,它们的损失函数都是标准的交叉熵损失,如式(11)所示。
(11)
式中:X[true]为样本真实标签的得分;X[j]为第j个类别的得分。
(12)观察模型损失。利用TensorBoard可视化工具实时观察和记录损失值和预测的结果。
2.3 试验结果与分析
采用常用指标归一化误差(Enormalized)衡量图像关键点定位算法的性能,计算方法如式(12)所示。
(12)
采用准确率(Raccuracy)和召回率(Rrecall)两种标准试验评测指标客观分析算法模型在服装数据集上的表现。准确率是指预测正确的结果占总样本的百分比,如式(13)所示。召回率又叫查全率,是指在实际为正的样本中被预测为正样本的概率,如式(14)所示。
(13)
(14)
式中:Ntp为模型预测正确的正样本数量;Ntn为模型预测正确的负样本数量;Nfp为模型预测错误的正样本数量;Nfn为模型预测错误的负样本数量。
将试验1和试验2的关键点定位归一化误差与在相同数据集下的其他方法(如Fashion Net[6]、Deep Alignment[2]、DLAN[3]、DFA[7]和文献[15])的试验结果进行对比,如表1所示。
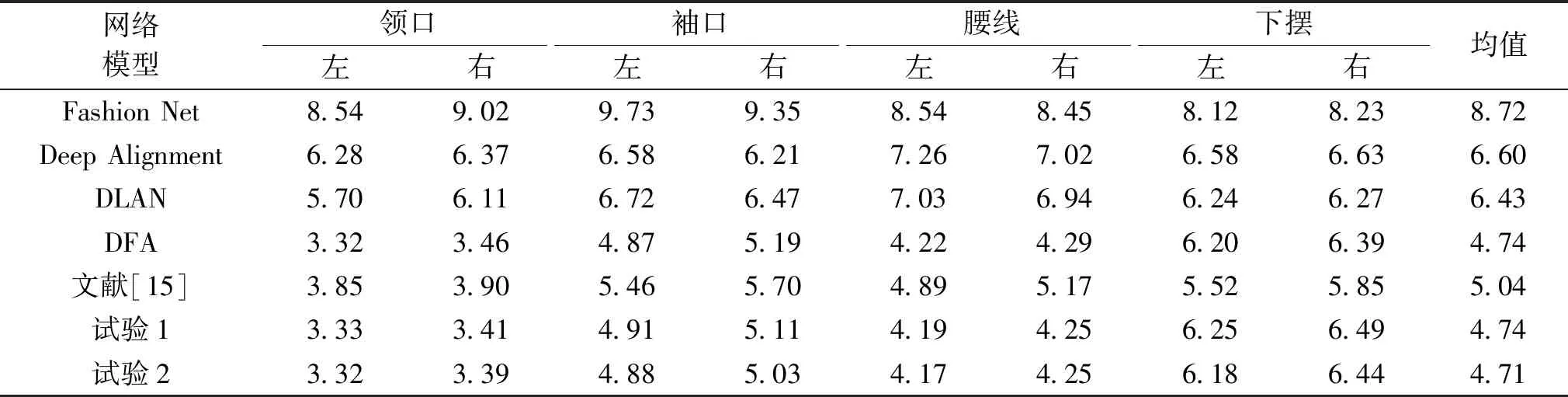
表1 不同算法的关键点定位归一化误差Table 1 Normalized location error of key point of different algorithms %
由表1可知,试验1除了左袖口和下摆处的关键点定位误差略大于DFA算法,下摆处的定位误差略大于文献[15]以外,其他关键点定位误差均小于所有对比方法的试验数据,体现了本文算法的有效性及其优势。将改进后试验2的结果与DFA算法进行对比可知,试验2中算法的定位误差在右领口处减少0.07个百分点,右袖口处减少0.16个百分点,左腰线处减少0.05个百分点,右腰线处减少0.04个百分点,左下摆处减少0.02个百分点。说明试验2体现出更佳的性能。
试验5的服装属性预测、服装分类以及关键点定位的损失曲线如图4所示。
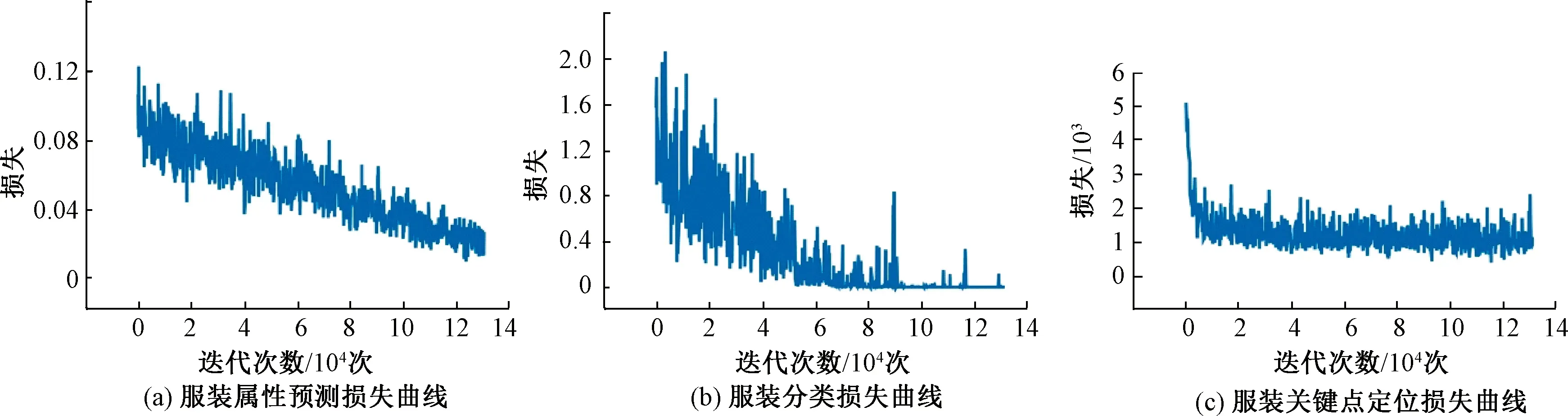
图4 服装属性预测、分类和关键点定位的损失曲线Fig.4 Loss curves for apparel attribute prediction, classification and key point location
由图4可知,在训练之初,模型的效果并不好,损失值较大。随着迭代次数的增加,网络所得误差值通过反向传播求解梯度,并通过梯度下降的方式更新模型参数,训练的误差值才逐渐降低。当误差值降到一定阈值时,模型收敛,则训练停止。
图5为服装的关键点定位可视化结果。

图5 原图和相应的关键点热图Fig.5 Original drawing and corresponding key point heat map
将试验3~5的试验结果与在相同数据集下其他方法,如WTBI[18]、DARN[19]、Fashion Net[6]、Weakly[20]、文献[11]、DFA[7]和文献[15]的试验数据进行对比,如表2所示。
由表2可知,MDA-DFA算法优于试验3和4的试验结果,在top-3的分类结果中,同时融合空间联系RCCA和高效通道注意力ECA的MDA-DFA网络得到的准确率最高,为91.36%,相比改进前的DFA网络提高了0.2个百分点。在属性预测的结果中,MDA-DFA算法的召回率也更高,总体上表现更佳,其中top-5面料预测的召回率比DFA网络提高了0.59个百分点。由此可见,将RCCA和ECA结合起来使用时网络的性能更优。
因此,提出的基于混合域注意力机制的服装关键点定位与属性预测算法能有效提高对服装袖口和腰线处关键点定位的精度,对困难关键点的定位有比较明显的改进作用,并在一定程度上提高了服装的分类与属性预测效果。
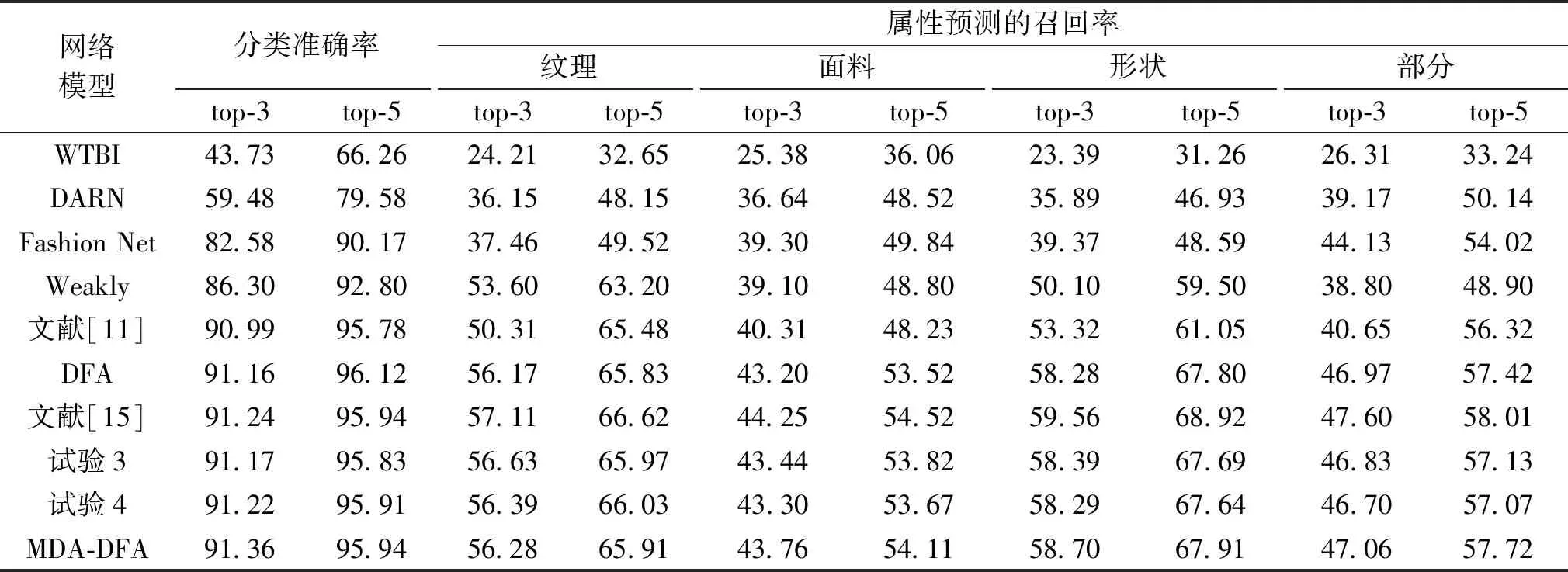
表2 不同算法的服装分类准确率与属性预测的召回率Table 2 Clothing classification accuracy and attribute prediction recall rate of different algorithms %
3 结 语
提出一个基于混合域注意力机制的服装关键点定位及属性预测的算法,利用RCCA模块获取服装图像像素的上下文信息,从而捕获关键点之间的空间联系,利用局部跨通道交互策略生成通道注意力捕获卷积通道间的交互信息,并将两种注意力分支网络得到的特征融合后再进行分类和属性预测。结果表明该算法取得了不错的效果。但相比人类对于服装的理解,人工智能还差得很远。在今后的研究中,可尝试将神经进化算法等生物学策略应用到相关领域,以促进其在计算机视觉中的应用。
