利用开源词向量扩充图情领域术语词
2022-09-16朱姝姍党亲亲
朱姝姍,党亲亲,蒋 玲
(乐山师范学院,a.图书馆;b.经济管理学院,四川 乐山 614000)
0 引言
随着自然语言技术的不断发展,特别是目前transformers 技术和预训练语言模型技术的突破[1],基于深度学习方法的各项自然语言任务的性能有了很大提高[2-3],这些技术提供的信息服务越来越广泛[4]。目前,在很多特定领域中,问答和检索系统被广泛应用,例如很多网站都提供针对该网站的检索和问答服务[5]。特别地,在大学图书馆的服务中,基于自然语言技术的问答和检索也是一个有价值的服务工具,被很多大学所采用[6]。
此类信息服务系统,面临一个关键难题是专业术语的收集和处理问题。通常,一个特定领域存在大量的专业术语词汇,这些词汇往往是构建该领域信息服务系统不可或缺的数据。但是,此类词汇的收集和应用都存在一定困难。首先,这类词语,对于通用语料来说,是低频词甚至是表外词,基于这些语料预训练的语言模型和词向量,无法有效处理此类词汇,给接下来利用语言模型和词向量构建该领域的服务系统带来了挑战。而为了能够有效处理该领域的信息,需要尽可能地收集这个领域的专业术语词,在进一步采用相关技术来提升信息系统处理此类词汇的性能。因此,低成本收集专业术语词是一个构建特定领域信息服务系统的一个关键环节。
首先,每个特定领域的术语词都有自己独特的涵义和使用方法,例如财务、法律、税务等领域。收集这些领域的术语词,往往需要专业知识,这给收集术语词带来了挑战。其次,专业术语词在通用领域中出现的频次相对不多,且给定的特定领域往往缺少足够的语料用于收集这些术语词,进一步导致了收集困难。最后,如果利用大量的该领域的专家来进行收集标注,不仅人工成本高,而且效率低下,且寻找合格的领域标注人员有很大困难。因此,直接通过人工的方法,给获得此类专业词的收集整理带来了很大挑战。为此,针对特定领域,开发高效低成本的专业词收集方法和工具,具有很大的应用价值。
可利用开源词向量来收集术语词。我们知道,语料中包含的词语数量随着语料的增多而增多,特别地,对于海量语料,往往包含了成百上千万个词语。对于这样的语料,一般来说包含一个特定领域的大量术语词。而目前的开源词向量是利用海量语料训练而来的,因此,借助这些开源词向量数据集,为收集特定领域的术语词提供的机会。我们研究发现,可以开源词向量来有效收集特定领域的术语词。
目前,利用海量语料训练的开源词向量,是研究和应用的一个热点。英文训练好的开源词向量数据集有word2vec[7],GloVe[8],中文词向量[9]。
利用给定的开源词向量数据集来收集术语词,可通过词向量技术和人工标注方法结合的方式来获取术语词。我们通过如下步骤来进行。
首先,收集一定数量的种子词。一般是利用这个领域里已有的术语词集,也可以通过专业人士标注利用已有的专业语料进行人工标注得到一定量的术语词,这一步是必不可少的,要求是在资源允许的条件下,尽量收集更多的专业词汇。
其次,利用开源词向量和词词相似算法,从词向量集合中查找和种子词相似的词汇,作为术语词的备选集合。由于术语词和种子词其使用环境接近,因此它们之间具有较大的相似度。这是通过词相似方法来收集术语的理论根据。这个环节是自动的,成本低,速度快。我们知道,如果一个词在训练语料中出现的次数较多,其对应的词向量有很好的表示。反之,很多专业词往往是低词频词,其对应的词向量的表示就没那么有效,因此利用词向量计算相似度,不是完全准确的。
最后,利用专业人员对基于词向量数据得到的备选词进行标注,从而获得准确的近义词。这一步需要一定资源和人工。首先,备选词集合中的词汇数量一般不是很多,人工成本不是太高。其次,由于选择的词语和种子词之间有较大的相似度,因此其中很大比例是术语词。这一步需要研究如何用更少的人力成本来收集可能多的专业词的近义词的方法。需要通过实验来分析基于词相似计算查找的近义词的情况,以及后续的人工标注的工作量进行评估,确定这个方法的有效性。另外,利用词相似来查找近义词算法中,有一些超参数需要确定,这些超参数对接下来的人工标注成本有影响。
针对图书馆信息服务领域,研究了如何用开源词向量来收集术语词的有效性。首先,选择了图书情报领域的一个术语词集合作为种子词集[10]。然后我们选择一个被广泛使用的开源词向量数据—腾讯词向量数据集[9]作为获取术语词的词向量集合。词向量相似度算法采用余弦相似度算法来召回种子词的相似词。利用人工方法,对召回的词语进行人工标注,获取准确的术语词。实验表明,设计的方法是一个高效的特定领域的近义词标注方法,实现了图书检索领域的近义词的收集整理工作,可为该领域的进一步信息服务提供了一个有价值的术语词集合。最后,进一步分析了召回算法中的超参数对实验结果的影响,进而找到了这些超参数设定的合适值,以降低这个工作人工标注工作量,提升这个方法的速度。
下面先介绍开源词向量有关概念和词相似计算方法,然后介绍利用开源词向量获取专业词语方法。
1 词向量和词相似介绍
训练词向量最常用的方法是采用浅层神经网来进行的。常用的模型有skipgram 模型和gloves 模型等。这些模型计算速度快,适合于用海量语料来训练。我们采用的开源词向量数据集采用的是skipgram 模型,是米科洛夫于2013 年设计的[7]。在skip-gram 语言模中,把语料看做词语构成的一个序列集合S=(w(1),w(2),,...,w(M)),对于词语w(t),用该词预测其周围的词语词语概率p(w(t+k) |w(t)),训练的目标是增大这个概率。得到下面的损失函数进行优化:

其中,Kfalse 表示窗口半径,通常取值为5。Skipgram 模型是浅层模型,只有输入层和输出层,因此计算速度快,可以采用大规模语料计算进行训练。该方法训练的词向量具有优越的性能,被广泛的研究和应用,目前依然是研究热点方法。从公式(1)可以发现,基于skipgram 语言模型训练的词向量,是用相邻的词语互相预测得到的,这样训练的词向量,其主要捕获的是词的上下文信息。这些上下文信息反映了这个词的用法。
从skipgram 语言模型的损失函数,可以发现,如果2 个词语出现的上下文越相似,则它们的词向量越相似。因此可用词向量分析词语的相似度。类似的,2 个词语,如果都是一个特定领域的术语词,则它们的用法,也就是上下文有很大可能有一定的相似性,因此二者之间的向量的相似度值也较大。因此可以利用这个特性来获得更多的一个给定领域的术语词。需要用到词向量的相似度,下面介绍基于词向量度量2 个词语的相似度方法。通常,基于词向量方法相似度采用余弦相似度。设2 个词 的对应的词向量,则这两个词的相似度可通过如下公式计算:
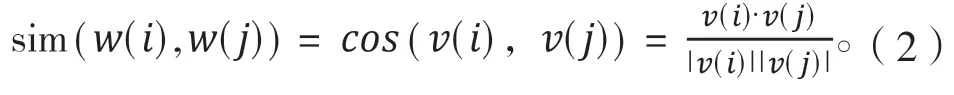
表示向量的内积,表示向量的模长。研究发现[7],余弦相似度可以有效度量2 个词语用法的相似或是相关程度。这给寻找用法相关的术语词提供了一个有效的算法。但实际情况有些复杂,对于给定的一个术语词,和其相似度较大的词语,只有一定概率是术语词,有些时候,尽管2 个词的相似度很高,但也不能保证该词就一定是和种子词一样是术语词。这就给基于相似度寻找术语词带来了麻烦,因此需要人工标注来进一步确认哪些词是术语词。
2 利用开源词向量获取专业词语方法
利用词向量的相似度来获得术语词,首先要有一定数量的种子词,然后利用词向量的相似度,找到和种子词相速度高的词语。通常有top-k 和top-p 两种方法来获得和种子词相似度高的词语,下面分别介绍。
(a)Top-k 方法。对种子词w,设词向量集合为V,令

topk(w,V)false 表示V 中和w 相似度最高的前k 个词。K 的大小对选择寻找术语词效率和数量有影响。在下面的实验中,我们会研究k 的影响。
(b)top-p 方法。对于种子词w,类似公式(3),我们定义集合
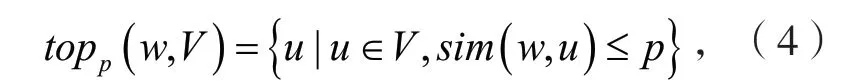
top p(w,V)表示V 中和w 相似度大于p 的全部词语。同样地,参数p 寻找w 的相似词有很大影响。我们通过实验来研究p 的影响。
通过Top-k 或者top-p 方法,获得了词w 的相似词集合 topk(w,V)或者top p(w,V),然后通过专业人士对这个集合中的词进行标注,进一步获得精确的术语词。这一步需要一定时间和人工成本。
3 实验设置
3.1 开源词向量
为了验证开源词向量是否有助于收集特定领域的术语词,采用了一个被广泛应用的词向量数据集:腾讯词向量数据集[9]。该词向量采用是skip-gram 模型的改进版——位置敏感的skipgram 模型,传统的skip-gram 语言模型是词袋模型,也就是没有位置信息,位置敏感的skipgram 采用的训练目标函数如下:

该方法在原有skipgram 方法上添加了位置编码信息zj,因而可以获得更词之间的相对位置关系,可以获得了更好的词表示。
腾讯词向量数采用的训练数据集是自大规模的多源数据,有来自腾讯新闻和天天快报的新闻语料,同时还补充了通过爬虫技术获得的互联网网页数据和来自在线小说语料等,讯词向量首先利用了现有的词典和维基百科和百度百科的词条,使用的分词算法中也考虑了Shi 等人于提出的语义算法[9]来发现语料中的新词。
3.2 参数设置
实验中有2 类参数:一个是top-k 算法中参数k,首先设k=5,10,15,20,25,30,然后根据实验结果的评估,最后k=10;另一类参数是top-p 中的p,设为p=0.5,0.6,0.7,0.8,0.9,0.95。实验评估结果设定为0.7。
3.3 图书情报领域种子词集合选择
针对图书馆信息服务领域,选择术语种子词是一个专业词汇数据集是<图情常规专业>[10],该数据集中包含了4846 个中英图书情报专业语词,剔除了英文词语,保留了其中的中文词。这个数据集有有1158 个术语词义项,每个义项包含了1 到4 个术语词,其中有86 个义项包含了多个术语词。很多词通过约定符号进行了合并和缩写表示,为了接下来的处理,我们对这些特殊表示进行了拆分补全处理:
a)原有语料中的含有小括号形式的专业“引(序)言”,把它们拆分为“引言”和“序言”。
b)代用中括号的表达,例如“重印[本]”,也做了进一步拆分,拆分结果为“重印”和“重印本”。
c)对于小括号中有多个专业的,例如“文件(宗卷”,“存档)号码”,做了拆分和补全,结果为“文件号码”“宗卷号码” “存档号码”。
4 实验结果
4.1 方法的有效性评估实验
首先利用实验评估方法的有效性。通过实验,可以回答利用开源词向量集合,是否可以有效地扩充专业词的近义词。为此,从数据集D 中选择了181 个图书情报专业术语词汇作为种子词。按词相似方法,按照top-k(k=50)方法,从词向量集合V 中抽取了和这些目标词相似度较高一些词语,然后再经过专家标注,选出和图书情报相关的术语词(见图1)。图1 中的横坐标是词语id,纵坐标是召回的术语词数量。按照种子词召回的术语词数量进行了递增排序。从图中可以看到,有超过一半的种子词召回了超过10 个术语词。平均每个种子词召回了25 个术语词。这表示通过词相似算法,从开源词向量中可以获得大量的特定领域的专业术语词。这个实验说明,利用开源词向量集合来获取图书情报特定领域的专业词汇,是一个有效的方法。

图1 所有种子词扩充的术语词分布
为了进一步评估近专业术语词扩充的情况,按召回数量划分了若干个区间,统计了每个区间包含的种子词数量,见表1。可以看到,有57 个种子词只获得了至多2 个术语词。而有77 个种子词获得了大于3 小于40 个术语词。有46 个种子词获得了超过40 个术语词。从这个表格中,可以看到,不同的种子词获得的术语词数量差异很大。有大量的种子词获得了很少的术语词,作为一个极端情况,有25 个术语词没有召回一个术语词(见表1 中最后一行)。出现这种情况,有2 个原因:首先,这个术语词可能是一个图书情报中用法很不常见的生僻词;还有一种情况是词向量语料集合本身带来的问题,例如训练词向量的语料中与某个种子词相关的图书情报术语词很少导致的。与之相反,有大量的种子词召回了很多术语词。要注意的是,这些数据是基于top-50 方法得到的,因此每个种子词至多召回50 个术语词。这显然是不充分的,实际上,针对召回多的种子词,可以进一步扩大top-k 中的k 值,会进一步召回更多的术语词。实验的目的是正面这个方法的有效性,因此只尝试了k=50 的情况。

表1 种子词在不同术语扩充数量区间的分布情况
4.2 参数k 的影响
在top-k 算法中,k 越大,召回的术语词数量可能越多。但是标注工作量也逐步增加。同时,随着k 变大,召回的词和目标词的相似度越低,这这个词是目标词的术语词的概率也变小。可见,k 对任务的性能和成本有着直接影响,选择合适的k 是非常关键的一个环节。我们实验了当k 的变化对召回专业词数量变化的影响。在这个实验中,设k=1,2,…,50,分布统计181 个种子词在第k 个位置(top-50)召回的术语词数量(见图2)。我们可以看到一个显著的趋势:随着k 增大,召回的术语词稳步下降,降幅从100 左右降到50 左右。这个现象说明,k 越大,该位置是术语词的概率越小。k=1 附近,概率大约为0.55,当k=50 的位置时候,概率大约为0.25 左右。
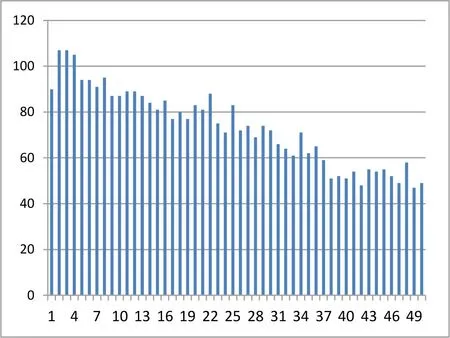
图2 top-50 中第k 个位置召回术语词的数量
4.3 top-p 实验
在top-p 方案中,p 越大,也就是相似度越大,则召回的词越少,获得的术语词也就越少。反之,可以获得更多术语词,但是p 变小,召回词的数量会急剧增多,会大大加重标注的代价。我们用实验来分析p 的大小对召回术语词数量的影响。为此,我们根据p 的取值范围和实验设定,设定了p 的5 个分布区间,基于181 个种子词召回的术语词,按其和种子词之间的相似度,统计了落在不同区间获得的术语词数量。实验结果如图3所示。
在图3 中,召回的术语词和种子词的相似度落在区间[0.6,0.7)中最多,其次是[0.5,0.6)区间。这是因为,在此区间内,按照top-p 算法,召回了和种子词相似的词数量更多,因此其中包含了更多数量的术语词。而相似度越大,召回词语的数量越少,基于标注得到的术语词也少,见图3 中最后2 个区间中术语词的数量。为了平衡标注工作和术语词召回数量2 个矛盾结果,取p=0.5,这样可以保证召回数量不是太多,同时可以获得一定数量的术语词。

图3 p 对术语词数量的影响
5 结语
文章介绍了利用开源词向量获得特定领域术语词的方法。整个方案包括2 个步骤;首先,利用词相似算法召回和种子词的最相似的词;然后,利用图书情报领域专家对这些词进行判别标注,以便获得精确的图书情报领域的术语词。采用了2种基于词相似算法进行召回,top-k 和top-p 算法,同时分析了参数k 和p 的获得术语词的数量和标注工作量影响。实验结果表明,利用开源词向量数据集可以有效扩充图书情报领域的术语词。
