引入类别关键词的朴素贝叶斯林业文本分类
2022-09-16郭肇毅
郭肇毅
(乐山师范学院 电子信息与人工智能学院,四川 乐山 614000)
0 引言
移动互联网的飞速发展,使得现在网络上的文本数量越来越多,对这些文本进行有效的分类,有助于用户快速挖掘出自己所需要的信息,而且,文本分类可以用于垃圾邮件过滤[1]、情感分析[2]、网络舆情监测[3]等自然语言处理的常见任务中,是目前的一个研究热点之一。
我国林业在信息化的发展过程当中,出现了很多涉及林业的网站、信息系统等,涌现出了各类的林业文本信息,对这些文本的分类,如果仅仅依靠人工,是一件十分低效的事情。因此,在建设各类涉及林业的网站、信息系统时,引入人工智能的模型,不仅能够节约大量的人工,而且也能极大地加快林业信息化的进程。
1 研究现状
文本分类的方法主要分为两类:一类是基于知识工程的方法,一类是基于机器学习的各种模型的方法。使用机器学习的各种模型的方法是目前的主流方法,在这方面已经有很多学者对此进行了研究。
有研究者提出在文本分类任务中引入朴素贝叶斯的方法[4]。近年来,有学者提出了一种基于Bert 和知识图谱融合的模型的方法来解决文本分类的任务[5]。2019 年,又有研究人员提出了一种XLNet 模型的方来进行文本分类,该方法通过对输入的文本序列进行重新的排列、以及组合的方式,使得模型可以进行上下文的两个方向上的学习,并且,又避免了Bert 中的两个阶段的学习数据分布不统一的问题[6]。此外,又有科研人员提出了ALBERT 模型,来对Bert 模型进行改进,提升其性能[7]。随着LSTM 模型的提出,有研究人员采取LSTM-TextCNN 相结合的方式进行文本分类[8]。
对于特定的行业领域,例如,林业文本的分类,目前的专门的研究还较少,但也有研究人员提出用通过使用LM 优化模糊神经网络模型的方法来进行文本分类[9]。但是,总的说来,这方面的研究还不太成熟。
纵观这些机器学习的模型,若是比较复杂的神经网络类的模型,分类效果确实不错,但是其耗费的时间、硬件资源等都十分巨大,对于某些单位而言,很多时候不需要那么精准的分类,看重的是综合的成本,使用朴素贝叶斯模型来进行分类,既能获得较高的分类精准度,所花费的成本也不高,是一个比较合适的选择。而在原始的朴素贝叶斯模型基础上,根据特定的领域的分类任务,例如,林业文本,引入每种林业文本类别中的高频关键词的因素,可以在不额外增加成本的基础上,进一步提高文本分类的精准程度,是十分有意义的。
具体地,例如,对于一个林业文本,如果其中出现得有“旅游”“自驾”等字样,那么,可以认为这个林业文本很可能属于一篇关于林业旅游方面的文本。因此,在用原始的朴素贝叶斯对文本进行分类的基础上,在考虑这些关键词的因素,能够使得分类的效果更精准,而且也没有额外增加成本,是一个不错的选择。
2 相关工作
文本分类的流程大体上可以分为文本的预处理、文本的特征表示和分类器的构建。具体过程如图1 所示:
2.1 文本的预处理
因为中文不像英文,单词与单词都有天然的空格进行分隔,所以在文本的预处理阶段,需要对中文文本进行分词。目前市面上已经有很成熟的分词工具可供使用,例如,斯坦福的分词工具,中科院的分词工具等。这里采用的是中科院的分词工具。同时,中文中存在很多没有实在意义的“的”“了”等助词,这类词叫做停用词,去掉这类词,对于文本本身的意思没有任何影响,目前市面上也有很多不同版本的停用词库,这里采用的是百度的停用词库。
2.2 文本的特征表示
一篇文本是无法真正意义上被计算机理解的,就需要用文本的某些特征来表征这篇文本。这里采用的是用文本中的具有区分度的高频词来表征一篇文本。所用到的算法是tf-idf 算法[10]。tf-idf 算法的公式如式(1)(2)所示:

简单而言,tf-idf 选出的是具有区分度的高频词,例如,假如一篇文本出现了很多次“桂花”“买卖”这两个词,但若语料库中的其他文档中也出现了很多次“买卖”这个词,但是这些其他文档中极少出现“桂花”这个词,那么,对于那篇文本而言,“桂花”才是一个具有文本区分度的高频词,而“买卖”不是。所以,tf-idf选出的就是诸如“桂花”这类具有文档区分度的高频词,而不是随便一个高频词就选出来。
2.3 构建分类器
采用的是用朴素贝叶斯的算法思想,通过训练语料构建分类器,然后随后进行分类效果的测评。贝叶斯的公式如式(3)所示:
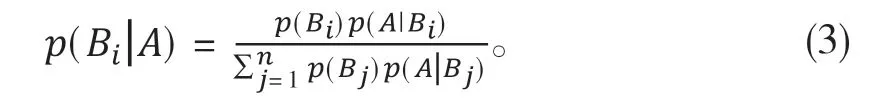
当贝叶斯公式用于文本分类时的原理大体如下:


3 引入类别关键词的朴素贝叶斯
文章主要在原始的朴素贝叶斯算法的基础上,引入类别关键词的因素,从而提高分类的精准度。
对于一篇林业文本,在用朴素贝叶斯进行相应计算的基础上,引入类别关键词的因素,从而提高分类的精准度。例如,对于一个林业文本,如果其中有某方面文本的标志性字样,那么,可以认为这个林业文本很可能属于一篇那个特定方面的文本。因此,在用原始的朴素贝叶斯对文本进行分类的基础上,在考虑这些关键词的因素,能够使得分类的效果更精准,而且也没有额外增加成本,是一个不错的选择。
具体而言,如式(16)所示:

上式中,是要进行类别判定时的最终概率值,是原始朴素贝叶斯计算出的概率值,是根据经验给类别关键词设定的一个概率值,和是权重值,二者的和为1,且要比大。
为解决数据稀疏性问题,平滑技术采用加1平滑。
4 具体实验
4.1 实验数据
实验采用的文本数据来源于网络,有4 个类别,分别是“花木商情”“林业科技”“林业旅游”和“林业资源管理”。训练语料有1016 篇,4 个类别分别占的数目为96、374、84 和462。测试语料共有255 篇,4 个类别分别占的数目为24、94、21 和116。
每篇文本用tf-idf 提取出5 个具有区分度的高频词作为文本特征词。
根据4 个类别的特点,根据经验准备4 个类别关键词列表,例如“林业旅游”关键词列表中就有“旅游”“风景区”等和旅游高度相关的词。
4.2 实验过程
实验的具体过程如图2 所示:

图2 实验流程图
也就是,最初,对文本进行预处理,对比停用词表去除停用词,通过tf-idf 找出每篇文档的5 个特征词,根据贝叶斯公式进行判定概率的计算。同时,将分词后的文本中的所有词汇与类别关键词列表进行比对,根据比对结果计算出另一个判定概率,然后,根据公式(16)计算出最终的判定概率,比较4 个最终的判定概率,最后判定文档属于哪个类别。
4.3 性能指标
性能指标采用自然语言处理常用的准确率和召回率,以及二者的综合评价值F 值作为评价指标。
对于文本分类任务,precision和recall的计算公式如下所示:

4.4 实验结果
根据(16)式中的公式,根据2-8 准则,选取和分别取80%和20%,以F 值为评价标准,得到的实验结果分别如下图所示。其中,图3 是考虑平滑的情况,图4 是没有考虑平滑的情况。

图3 考虑平滑实验结果图

图4 不考虑平滑实验结果图
考虑了平滑的具体的每种文档的判定结果数如表1 所示:

表1 考虑平滑每类文档的判定结果数
从上述的图表可以看出,引入了类别关键词因素的朴素贝叶斯的方法在综合性能上要优于原始的朴素贝叶斯方法,这说明了在用朴素贝叶斯进行文本分类时,引入类别关键词的方法,是有意义的尝试。特别是不考虑的平滑的情况下,引入了类别关键词因素的方法的优势更加明显,说明在不考虑平滑的这种比较简单粗暴的情况下,引入一些细节性的因素,效果更好。
而没有考虑平滑的具体的每种文档的判定结果数如表2 所示:

表2 不考虑平滑每类文档的判定结果数
5 结论和展望
从实验可以看出,引入了类别关键词因素的朴素贝叶斯方法,相比原始的朴素贝叶斯的方法,效果更好。特别是对于不考虑平滑的这种简单粗暴的情况,引入了类别关键词因素这些较为细节的因素,实验结果更好。
从工程应用的角度来看,朴素贝叶斯这类简单有效的方法已经能够运用于很多工程实际问题了,对于分类精准度要求不那么高的很多实际工程应用,朴素贝叶斯类的方法已经够用了,在实际问题中,如果对经济成本、硬件资源等要求较为苛刻的情况,完全没有必要使用神经网络类的模型。
