基于logistic回归的二分类结局临床预测模型的Stata实现方法*
2022-09-14张宇铮吕海永贾志芳
郑 敏 张宇铮,2 吕海永 贾志芳 姜 晶,2△
【提 要】 目的 结合早期胃癌患者淋巴结转移临床预测模型的实例,探讨通过Stata软件建立、评价和验证二分类结局的临床预测模型的实现方法。方法 选取2010年至2018年收集的早期胃癌患者淋巴结转移数据为实例数据集,并以2017年7月1日作为患者入组分界点,将数据分为建模集和验证集,通过实例介绍利用Stata/SE 15.0建立、评价和验证二分类结局临床预测模型的方法。结果 实例中建模集746例胃癌患者中144例(19.3%)发生淋巴结转移。预测模型最终纳入T分期、肿瘤最大径、分化程度和脉管浸润4个变量。模型的区分度评价指标C指数为0.864,模型校准度Hosmer-Lemeshow检验P=0.983,临床决策曲线显示临床适用度较好。在验证集中,模型的C指数为0.911,校准度Hosmer-Lemeshow检验的P值为0.631。结论 利用Stata软件可以简单、快捷地实现临床预测模型的建立、评价和验证过程,尤其在列线图的绘制方面存在优势。
在临床应用中,研究者关注的结局往往不是连续变化的,而是某个特定事件是否发生,如是否罹患疾病、有无并发症等二分类结局事件。二分类结局事件的发生率分布于0~1之间,不服从正态分布,无法采用线性回归模型描述观察指标对结局的作用大小及方向。此时,logistic回归模型可用于该结局事件发生概率的预测。
临床预测模型可以通过数学公式估计特定个体当前患有某病或将来发生某种结局的概率。对于二分类结局事件,常通过建立logistic回归模型,预测特定个体发生结局的概率。但是,目前对于此类模型在Stata软件中如何实现的介绍较少。本文拟利用2010年至2018年收集的早期胃癌(early gastric cancer,EGC)患者淋巴结转移数据作为实例[1],介绍此类模型的建立、评价和验证的指标体系及在Stata/SE 15.0软件中的实现方法,以期为相关研究者提供借鉴。
基于logistic回归的临床预测模型的原理与评价方法
1.临床预测模型的建立
(1)模型的变量筛选方法
建立临床预测模型,首先从研究目的出发,参考既往文献提出的该结局事件的影响因素,结合专业知识,初步选定欲探究的预测变量。再利用统计模型筛选、综合评估备选预测变量与结局事件发生与否的关系,最终确定纳入预测模型的变量。
(2)logistic回归模型的基本形式
logistic回归模型是一种预测、判断结局发生概率的概率型非线性回归模型[2]。其预测变量可以是任意类型的数据,包括连续型、等级型、无序多分类型或二分类型等,结局变量可以是二分类、有序变量或无序多分类变量。在实际应用中,以二分类结局变量多见。
logistic回归模型的基本形式为:
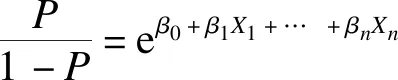
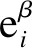
2.模型的评价
临床预测模型评价常包括区分度(discrimination)、校准度(calibration)、临床实用性(clinical usefulness)三个维度。
(1)区分度评价
预测模型的区分度是指该模型区分发生事件的高风险人群和较低风险人群的能力。区分度越高,模型的辨别能力越强[3]。常用指标包括C指数(C-index)、净重新分类指数(net reclassification index,NRI)和综合判别改善指数(integrated discrimination index,IDI)。
C指数是评价模型区分度的最常用指标。在logistic回归模型中,C指数等于根据构建的模型绘制出受试者工作特征(receiver operating characteristic,ROC)曲线下面积(area under curve,AUC)。logistic回归模型的C指数和AUC取值范围在0~1之间,取值越大,代表模型的区分度越高。
(2)校准度评价
校准度反映模型预测的绝对风险与实际观察风险的一致程度,也称一致性。校准度的评价方法包括拟合优度检验(Hosmer-Lemeshow goodness of fit test)和校准图。校准曲线是常用的一种校准图,是一条由个体发生结局事件的预测风险和实际风险的散点拟合而成的曲线,该曲线与斜率为1的参考线越接近、曲线拟合度越高,模型的校准度就越高。
(3)临床实用性评价——决策曲线分析
决策曲线分析法(decision curve analysis,DCA)用于解决临床效用问题。以实例数据为例,假设胃癌患者已发生淋巴结转移的概率为Pt,此时界定为淋巴结转移和(或)应当采取干预措施;无论Pt取何值,都会有个体因接受了干预而受益,也有个体因干预遭受伤害或未干预产生健康损失,由此计算淋巴结转移概率Pt下所有患者的净受益。决策曲线分析的意义在于探索如何令所有观察对象的净受益最大化。
3.模型的验证
建立预测模型后,还应当对模型进行验证,评价模型的可重复性和外推性。验证有内部验证和外部验证两种策略[4]。内部验证常在建立模型的数据集中进行,可采用留N法或K-折交叉验证、随机验证或bootstrap重抽样法。外部验证是指于不同的时间和(或)不同的研究现场收集独立的数据集,进而加以验证,此独立的数据集称为外部验证数据集。
4.模型的展示
临床预测模型常用的展示方式包括公式法、评分系统、列线图(nomogram)、网页计算器等。其中,列线图能够直观易懂地实现模型展示,适用于预测变量数不多的模型。
列线图按照纳入模型的预测变量的偏回归系数进行评分。实际应用中,根据某个体的预测变量的实际取值,计算所有变量的得分之和,查阅列线图中该总分对应的风险概率。
实例应用及结果解释
临床预测模型的构建与验证过程在常用的统计软件中皆可实现,如Stata、R、SAS等。本文案例以早期胃癌淋巴结转移(lymph node metastasis,LNM)预测模型的建立为例,展示使用Stata 15.0软件进行模型的构建、评价和验证的方法。案例中,研究者共招募872例早期胃癌患者,早于2017年7月入组的患者组成建模集(dataset1),共746例,之后的126例患者构成验证集(dataset2)。
1.预测变量筛选与模型构建
本案例数据集共有1个结局变量和9个备选预测变量,相应的变量名及含义见表1。
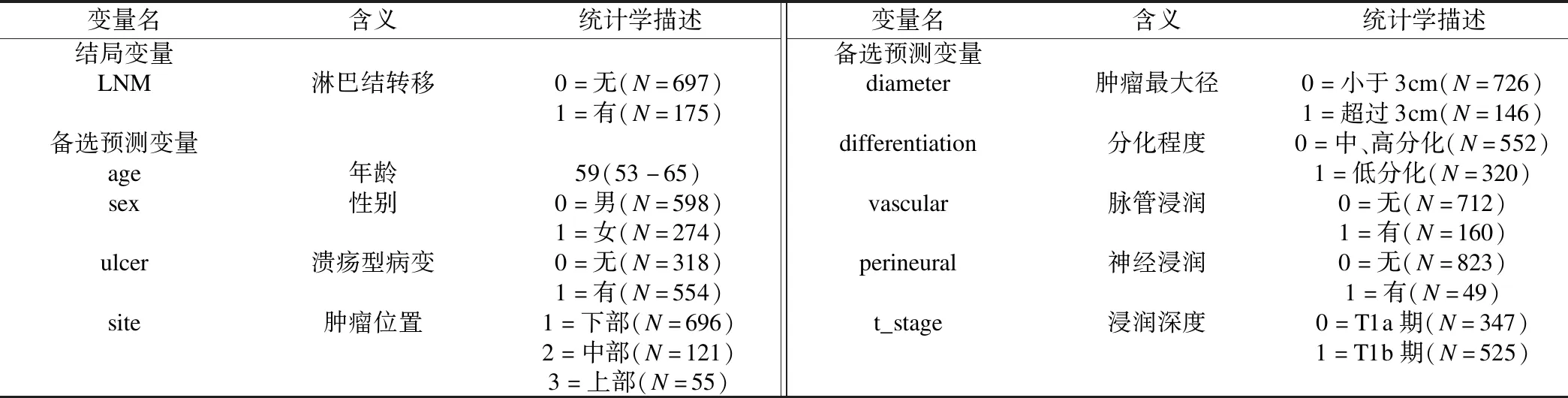
表1 变量命名、赋值及统计学描述
首先在建模集中进行结局变量LNM与上述9个备选预测变量关系的单因素分析,初步探究预测变量与结局变量是否相关,形成下一步变量筛选的变量池。单因素分析结果显示,共有7个备选预测变量(P<0.1)。
将单因素分析P<0.1的变量纳入多因素logistic回归分析,采用向前筛选的方法,筛选可能与结局变量LNM独立相关的因素。考虑T分期是早期胃癌治疗方法选择的重要依据,将其强制纳入模型(β=1.49,P=0.065)。除此之外,进入模型的变量还包括脉管浸润(有vs无,β=3.38,P<0.001)、分化程度(低分化vs中高分化,β=0.68;P=0.015)和肿瘤直径(>3.0 cm vs ≤3cm,β=0.59;P=0.045)。模型建立使用的Stata程序命令见表2。

表2 早期胃癌LNM预测模型构建的命令及说明
2.模型评价与验证
区分度评价结果显示,LNM预测模型的AUC为0.864(95%CI:0.827~0.901,图1a),区分度较好。采用Bootstrap法进行500次自助抽样进行内部验证,AUC为0.861(95%CI:0.851~0.864);在126名研究对象构成的外部验证集中,AUC为0.911(95%CI:0.848~0.974,图1b)。上述结果表明模型的区分度良好。
校准度Hosmer-Lemeshow检验显示,建模集中的P值为0.983(χ2=2.40),验证集中的P值为0.631(χ2=3.49)。校准曲线显示,建模集(图1c)和验证集(图1d)的实际观察值散点相对集中于斜率为1的参考线附近,表示模型预测值与实际观察值拟合度良好。
临床实用性评价结果显示,当LNM的概率阈值(Pt)的取值在10%~70%时,在该预测模型下观察对象的净受益较高。综上,该模型适合用于评价接受内窥镜治疗的EGC患者是否需要清扫淋巴结。
最终模型显示,LNM预测模型的预测变量包括脉管浸润、组织分化程度、肿瘤最大径和浸润深度(T分期),基于上述变量构建列线图(图2)。以上过程使用的Stata程序见表3。

表3 早期胃癌LNM预测模型验证的命令及说明
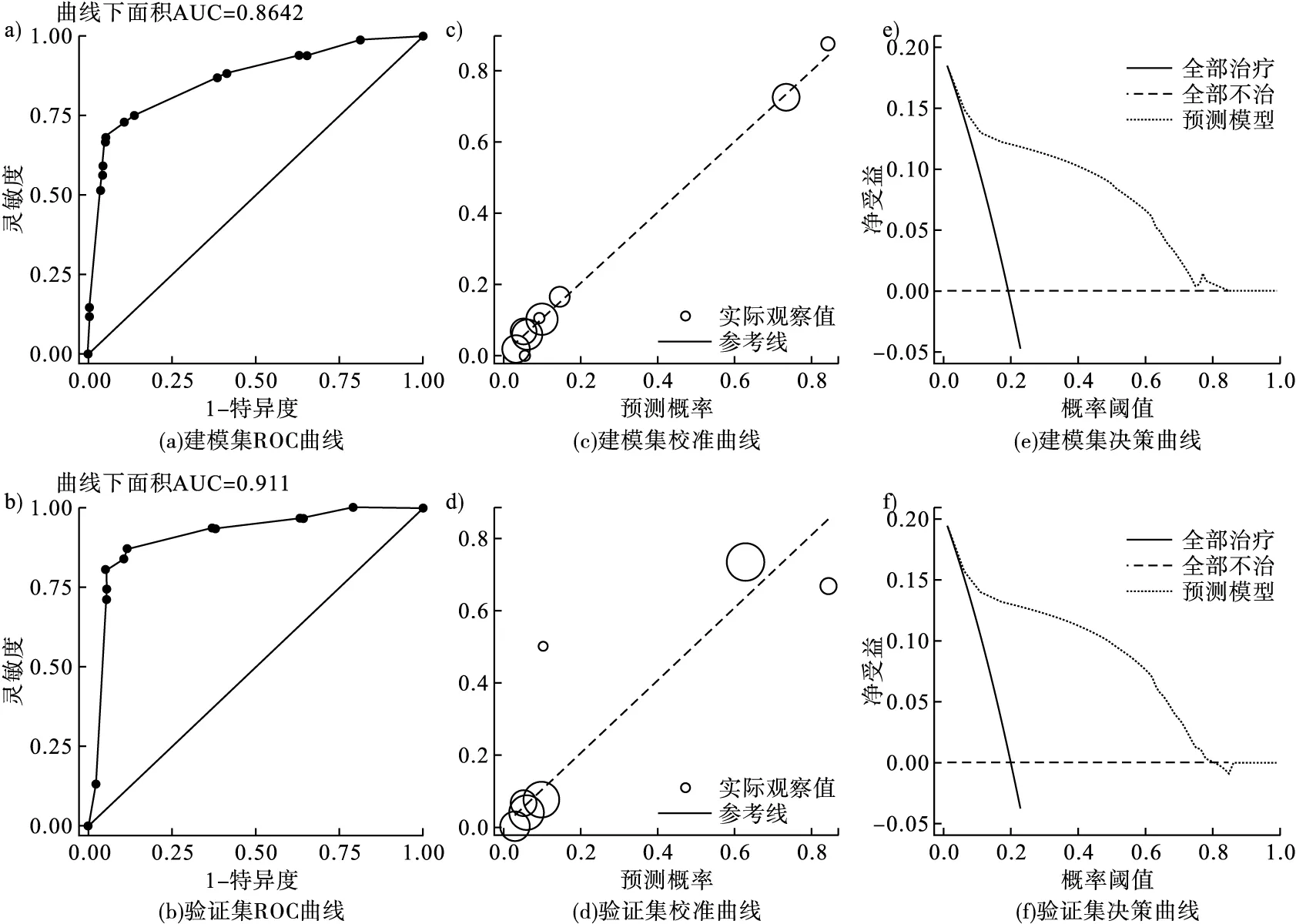
图1 早期胃癌LNM预测模型的区分度和校准度分析
讨 论
临床预测模型,作为直观的风险与获益评估的工具,可为医生、患者和卫生政策制定者提供简便易懂的资料[5]。模型的建立是个系统工程,不仅需要保证预测变量和参数计算方面准确易得,在模型的评价、验证和可视化方面也应当易于实现。Stata软件作为公认的统计分析软件之一,在临床预测模型的建立过程中有独特优势。其语句简单易懂,输出图形可直接用于发表,同时软件提供了详细的帮助和命令书写说明,大大降低了相关研究的学习门槛。研究者可以快捷地实现相应临床预测模型建立的整个过程。
本研究实例建立的淋巴结转移风险预测模型的列线图显示,早期胃癌患者如果有脉管浸润,此变量对应的风险评分记为10分,对应的胃癌淋巴结转移风险升高50%,脉管浸润是发生淋巴结转移的重要预测因素。该发现与第5版日本《胃癌治疗指南》中引用的eCura评分系统(OR=3.99,95%CI:2.43~6.55)[6-7],以及Jeung等构建的RSS评分系统(OR=25.448;95%CI:9.58~67.61)[8]等结论一致。值得一提的是,Stata软件仅需借助“nomolog”这一命令,即可输出列线图,而且图片质量较高。
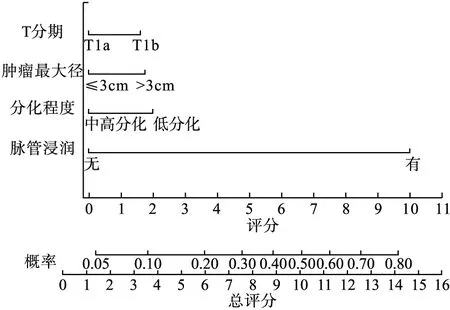
图2 早期胃癌淋巴结转移风险预测模型的列线图
总之,Stata软件在临床预测模型,尤其是基于logistic回归的预测模型的建立上,结果可靠,操作简便,是值得推荐的工具。
