复杂背景下多种树形果树树冠的检测与识别方法研究
2022-09-14王文静高冠东
肖 珂,王文静,高冠东,么 炜
(1.河北农业大学 信息科学与技术学院,河北 保定 071001;2.河北省农业大数据重点实验室,河北保定 071001;3.中央司法警官学院 信息管理系,河北 保定 071000)
果树在种植过程中不可避免地受到病虫害的侵扰,而目前的传统喷药方法不仅造成了农药的浪费,而且喷药效果也不理想。随着“精准农业”的提出,机器视觉技术在喷施过程中得到越来越广泛的应用[1-2]。然而,在利用机器视觉提升喷施效率的同时,存在复杂背景下果树树冠难以检测与识别的问题。另外,不同的树形也十分影响喷施效果,因此,需要对复杂背景下不同树形果树的检测识别进行研究。近些年,针对在精准喷施中果树的识别问题,一些学者借助传统的机器视觉技术进行了研究。2016 年,丁为民等[3]在利用机器视觉提取树冠图像时,将图像的分割问题与图的最小分割相联系,通过非完全标记的方式,取代了传统分割算法中的前景与背景灰度直方图,提高了算法的运行速度与分割准确性。2021 年,Cheng 等[4]提出了1 种基于马哈拉诺比斯距离和条件随机场的分割模型用于识别樱桃树,所提出的方法比传统的K-means 与GrabCut 具有更高的准确率。随着深度学习的发展,深度学习被用于识别苹果果实[5]、草莓果实[6]、苹果花[7]、梨花[8]、苹果树枝[9]、枣[10],等。近些年逐渐将深度学习应用到树冠识别的研究当中。2019 年,Lin 等[11]应用全卷积网络(Fully convolutional neural networks,FCN)进行番石榴果实和树枝的分割,并实现了水果和树枝的IoU分别为0.806 和0.473,对424×512 像素的图像进行分割的时间成本为0.165 s。2021 年,王辉等[12]针对复杂果园背景中识别分割单株果树树冠困难的问题,研究了1 种基于Mask R-CNN[13]单株柑橘树冠识别与分割方法,参与建模的果园中单株柑橘树冠的分割准确率达到97%。以上的研究表明,传统图像处理方法一般对背景简单的果树环境处理效果较好,对于背景复杂、光线多变的果园环境中的果树处理效果不理想,而深度学习对背景复杂的环境有较好的处理效果,准确率与鲁棒性也较高。
进行精准喷施时,不仅需要将复杂环境下的果树树冠与背景分离,还需要考虑果树树形对施药过程的影响,国内外部分学者研究了树形对喷施过程的影响。牛萌萌等[14]的研究中介绍到树冠形状使喷头与目标物之间距离发生变化,影响了喷雾的分布与农药雾滴到达目标时的重叠量的大小,表明树冠形状对喷施有显著影响。另外,Wandkar 等[15]在论文中指出,树木结构的不同对喷雾沉积有很大的影响,不考虑树木结构易造成喷洒过量或者喷洒不足。由此可见,树形的不同对于喷施过程中施药策略、施药量等方面产生了非常大的影响。
近年来,有部分学者研究了果树树形的识别,2017 年, AKERBLOM 等[16]提出了1 种利用地面激光扫描数据进行全自动树种分类的方法,研究中基于定量结构的树模型从地面激光扫描数据中识别树种信息。2021 年,YAN 等[17]借助卷积神经网络对高分辨率的卫星遥感图像中的森林树种进行识别,识别的效果优于随机森林与支持向量机。以上研究能够识别出不同的树形,但无法将树冠的检测与树形的识别相结合,本文使用深度学习的方法将树冠的检测与树形的识别相结合,能够在精准喷施中提供喷施区域,并提供果树树形以供喷施系统调整喷施策略。
在精准喷施中果树识别方面的研究对复杂背景讨论较少,另外在识别果树时主要针对某一种树形果树或某一种品种果树进行研究。然而,目前我国果园大多处于非标准化的经营状态,不同的果园修剪的树形不尽相同,并且喷施过程中果树背景复杂,因此需要1 种方法能够对复杂背景下的果树进行检测与树形的识别。
针对上述问题,本文在Mask R-CNN 模型的基础上进行改进,提出1 种检测模型B-Mask R-CNN,本算法在采样时引入IoU 平衡采样(IoU-balanced sampling)用于平衡难易样本数;在边界框损失函数中引入平衡L1 损失(BalancedL1 loss)用于平衡多分类的损失。另外,修改了锚框(Anchor)比例提高模型准确率。本文所提出的B-Mask R-CNN 能够对搜集的复杂背景下矮化密植形、小冠疏层形、自然开心形、自然圆头形以及Y 形5 种常见修剪树形的果树进行检测识别,检测精度高,鲁棒性好。这将为复杂环境下果树树冠检测与树形识别提供有效的检测方法,为后续精准喷施中喷施模式和控制参数的分析研究奠定基础。
1 材料与方法
1.1 图像采集与数据集的构建
目前,大部分精准喷施中树冠检测的研究对复杂背景与果树树形的讨论较少,本文为了提高模型检测的泛化能力与鲁棒性,通过互联网平台搜集复杂环境下5 种常见的修剪树形的果树制作数据集,数据集的内容如表1 所示。

表1 数据采集情况Table 1 Data acquisition situation
为了增强算法鲁棒性,通过搜索引擎搜集了在不同场景、不同背景复杂度、不同亮度、不同尺寸、不同品种、不同树形、不同分辨率的果树图像共1 280 张。针对Y 形果树在侧面拍摄角度下,树形不易识别的问题,制作数据集时对图像进行了筛选,选取能够体现树形特征的图像进行试验。为了保证数据的平衡,每种树形各选取50 张,共250 张图片,本文对选取的250 张图片进行手工标注,标注的工具为麻省理工计算机科学与人工智能实验室研发的图像标注工具Labelme,标注图如图1 所示。标注完成后将数据集按照COCO2017 的格式进行转换。为了扩充数据集,对标注完的数据进行数据增强。数据增强的方式为:

图1 果树原图与标签图Fig.1 Original picture and label of fruit trees
(1) 水平镜面翻转,每张图片被翻转的概率为0.5;
(2)高斯扰动,扰动的概率为0.5,标准差的值为0 ~1.0;
(3)亮度变化,变化的概率为0.5,参数值的范围为0.5 ~1.5。
经过数据增强后获得数据集共1 500 张,每种树形各300 张。将数据集按照8∶1∶1 的比例划分为训练集、验证集与测试集。
1.2 B-Mask R-CNN 模型建立
B-Mask R-CNN 基于Mask R-CNN 提出,本算法能够同时实现树冠的检测与树形的识别。本文在进行特征提取时使用包含残差结构的ResNet 网络[18],残差结构能够在不增加模型参数的情况下有效缓解梯度消失与训练退化的问题。另外,引入特征金字塔网络(Feature pyramid networks,FPN)[19],实现了多尺度检测的目的。在提取特征框时,本文选用区域推荐网络(Region proposal network,RPN)结构, RPN 基于全卷积网络,能够与网络共享图像的卷积特征,极大地提升了检测速度。
B-Mask R-CNN 模型为了解决正负样本不均衡的问题引入了IoU-balanced sampling;在边界框损失函数中引入BalancedL1 loss 损失函数,解决了边界框损失与多分类损失不易收敛、准确率动荡明显的问题;除此之外,不同数据识别目标的尺寸大小不同,为了生成合适的目标候选框,调整了RPN 中的Anchor 比例。调整后的模型训练过程图如图2 所示。
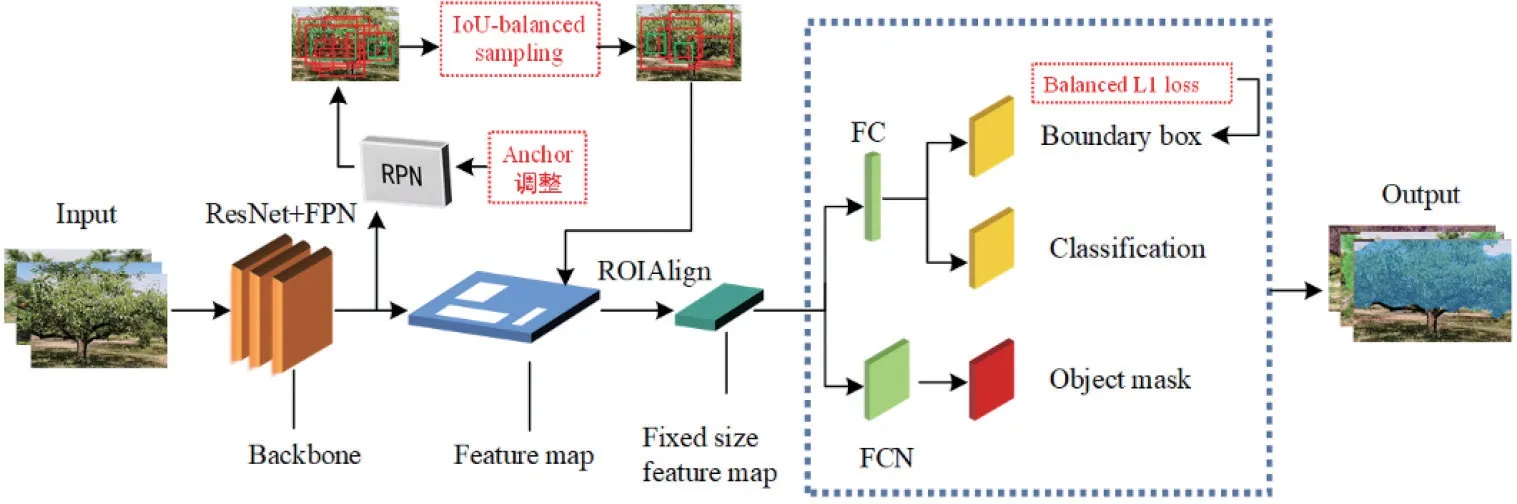
图 2 模型训练过程图Fig.2 The process diagram of model training
1.2.1 IoU-balanced sampling 的引入 本文提出的模型B-Mask R-CNN 在采样时引入了IoU-balanced sampling。研究发现[20],样本的分布在IoU 上并不是均匀分布,60%的困难样本分布在大于0.05 的地方,随机采样只提供了30%,这导致出现了大量的负样本,不利于训练。IoU-balanced sampling 通过在IoU 上均匀采样,实现了难样本在IoU 上的均匀分布,平衡了难易样本的分布。
IoU-balanced sampling 的采样公式如(1)所示。
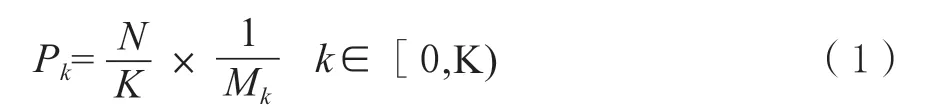
式中Pk为每个区间采样的概率,N为采样个数,Mk为候选采样数,K为划分区间数,k为区间定位。上述公式(1)中每个区间采样的概率指的是从Mk个候选采样数中选取N个负样本的概率,取值范围为[0,1]。
1.2.2 BalancedL1 loss 的引入 本文提出的模型B-Mask R-CNN 的多分类损失(L)由三部分组成:分类损失、边界框损失(Lbbox)与分割损失。当分类与分割效果较好时,Lbbox的大小十分影响损失与训练过程。直接提升Lbbox的损失权重会使得模型对困难样本更加敏感,产生过大梯度,而简单样本只占30%的梯度。本文为了平衡梯度,引入BalancedL1 loss 损失函数,使Lbbox与L更好地收敛。
使用Lb来表示本损失函数,如(2)所示。

公式(2)中,x为预测框与标签之间的差异值。α 为常数,用于控制在不影响困难样本梯度的情况下,对简单样本进行提升,试验中设置为0.5。γ 为常数,可以调整梯度的上界,当损失非常大时,能够帮助目标函数更好地平衡所涉及的各个任务,在试验中设置为1.5。b 为常数,用于保证公式(2)在Lb(x=1)时函数的连续性,α、γ、b 满足αlan(b+1)=γ,在本研究中b=e3-1。C 为任意的常数值。为推导函数过程中损失函数求积分所得。
1.2.3 Anchor 缩放比例调整 在模型训练过程中,Anchor 的面积和宽高比的设置是根据先验知识确定,先验知识对于减少网络的数据量非常重要,因此,选取合适的Anchor 能够有效地较少数据的运算量。
Anchor 的大小由面积与宽高比共同决定。为了保证设置的Anchor 能够覆盖原图的所有区域,本研究根据FPN 产生的5个不同尺度的特征图,将Anchor 设置为5个不同的面积,选取的面积如表2所示。
Anchor 框的大小计算公式为(3)与(4)所示。

式中,R为Anchor 的宽高比,h为Anchor 的高,w为Anchor 的宽,base_size为Anchor 面积的边长。最终每个区域中心生成的15 个Anchor 框的大小如表2 所示。

表2 锚框大小Table 2 The Size of Anchor
2 试验过程
2.1 运行环境
本文所有试验在实验室的服务器上完成,服务器的操作系统为Ubuntu18.04.1,CPU 的型号为Intel Core i7-9700CPU @3.00GHz8,GPU 的型号为NVIDIA GeForce RTX 2080,运行内存为32G。在此基础上使用Pytorch 的深度学习框架,使用Python3.7进行编程。
2.2 模型的训练
超参数的选择对模型的训练至关重要,本试验所涉及的超参数主要有学习率lr与训练轮数epochs。Mask R-CNN 在显卡数量为8 的情况下lr=0.02,本试验所使用的显卡数量为1,参考服务器的显卡数量,令lr=0.02/8,即lr=2.5e-3,并按照指数标尺扩大10 倍学习率与缩小10 倍学习率分别选取lr=0.025、lr=2.5e-3、lr=2.5e-4 进行试验,最终试验结果表明2.5e-3 的学习率为最佳。另外,本试验以常用的训练轮数6 为基准,缩小2 倍训练轮数与扩大2 倍训练轮数分别选取epochs=3、epochs=6、epochs=12 进行试验,试验表明epochs=6 时效果最好。
Mask R-CNN 所用的数据集为COCO 数据集,本文针对矮化密植形、小冠疏层形、自然开心形、自然圆头形以及Y 形5 种常见的修剪树形进行检测与识别,对网络模型进行微调,将网络模型中边界框检测头、掩膜检测头以及数据集的类别数修改为5。
本试验为了加快模型的训练速度以及改善训练效果,使用了迁移学习的方法。加载了ImageNet 预训练模型,并对预训练模型进行微调以适应自己的数据集。
2.3 评估指标
为了检验模型对果树检测与分割的效果,选取的评估指标有平均精度AP、均值平均精度mAP、准确率Acc以及平均准确率mAcc。
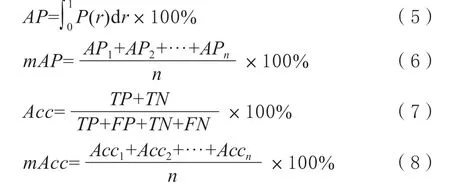
上述表达式(5)中P为精准率,r为召回率;表达式(6)中AP1为第一类的检测精度,AP2为第二类的检测精度,APn是第n类的检测精度,n代表类别数。表达式(7)中TP是正样本且被检测为正样本的数,FP是负样本但被检测为正样本的数,TN是负样本且被预测为负样本的数,FN是正样本但被检测为负样本的数;表达式(8)中Acc1为第一类的准确率,Acc2为第二类的准确率,Accn为第n类的准确率,n代表类别数。
3 结果与分析
3.1 B-Mask R-CNN 模型效果
(1)IoU-balanced sampling 提升效果
在进行采样时,本文引入了IoU-balanced sampling,此采样策略可以平衡模型在学习过程中的难易样本比例,优化学习模型,提升模型准确率。本文将B-Mask R-CNN 与Mask R-CNN 模型的检测效果进行了对比,对比时从目标检测框(bbox)与语义分割(segm)两方面进行对比。
表3 为bbox 对应的矮化密植形、小冠疏层形、自然开心形、自然圆头形以及Y 形5 种树形的AP值与mAP值的对比,表4 为segm 对应的5 种树形的AP值与mAP值的对比。

表3 bbox 检测精度对比Table 3 Comparison of bbox detection accuracy

表4 segm 分割精度对比Table 4 Comparison of segmentation accuracy
表3 与表4 中的AP1、AP2、AP3、AP4、AP5分别表示上述5 种树形的AP值。在表3 与表4 中IoU=0.50指IoU阈值为0.50 的mAP值,使用的范围更广泛,IoU=0.50∶0.95 时的mAP值取的是从0.50 到0.95之间,每隔0.05 所取的平均值,这个评价指标可以更好地表示模型检测与识别的效果。
从表3 与表4 的数值进行对比分析得知,本研究所提模型B-Mask R-CNN 比Mask R-CNN 在目标检测框与语义分割两方面都得到了显著地提升。本试验中表3 与表4 中的AP4为自然圆头形柑橘树的识别结果,由于试验中树冠部分与背景的边缘部分标注更加细致,数据集考虑了光照、角度、尺度等因素,并且识别的树形更多,导致检测结果与文献[12]中单一柑橘树的准确率相比较低,但本算法鲁棒性和实用性更强。
(2)BalancedL1 loss 提升效果
BalancedL1 loss 损失函数的引入有效地降低了Lbbox与L,使得模型更好地收敛与学习。图3 为改进算法前后Lbbox的对比效果。
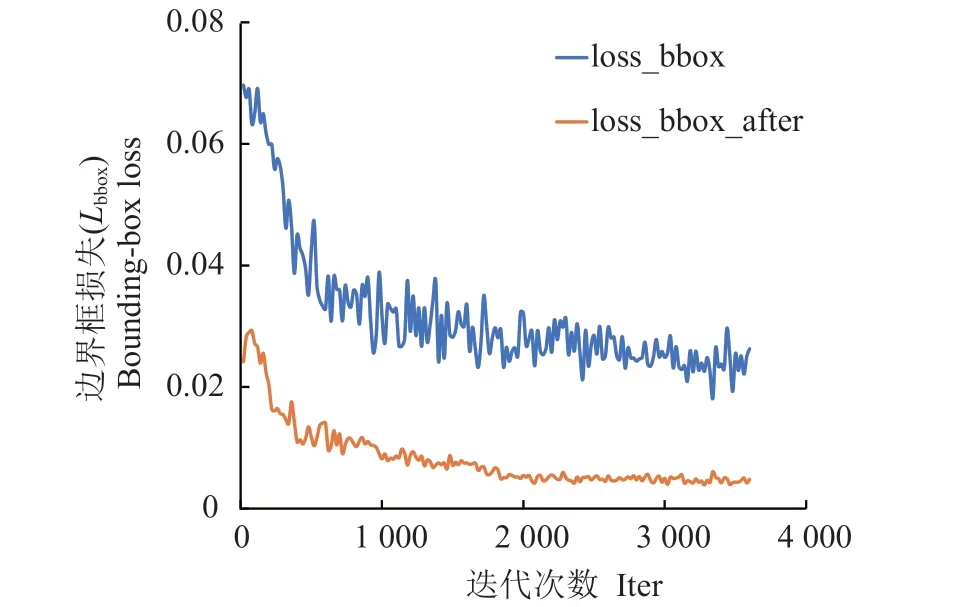
图3 改进前后Lbbox 对比Fig.3 Comparison of Lbbox before and after improvement
结果表明改进后的Lbbox起始的位置更低,训练过程中也更加平稳,损失值也更加的低。图4 为改进前后L的对比效果,结果表明改进后损失收敛更快,损失值更小,说明了BalancedL1 loss 损失函数的有效性。

图 4 改进前后L 对比Fig.4 Comparison of L before and after improvement
(3)Anchor 比例调整提升效果
Anchor 比例调整后,图5 的效果显示出,改进后的Acc得到了提高,并且起始的准确率也更高,震荡幅度小,易收敛。

图 5 改进前后Acc 对比Fig.5 Comparison of accuracy before and after improvement
3.2 ResNet50/101 对比
随着ResNet 深度的加深,特征提取的效果会相应提升,但同时也会增加网络模型训练的负担,增加训练时长。为了确定是否选用深度更深的ResNet101网络用于特征提取,本文将B-Mask R-CNN 模型中的Backbone 换为ResNet50 与ResNet101 进行对比。(表5)

表5 ResNet50 与ResNet101 对比Table 5 Comparison of ResNet50 and ResNet101
使用测试集中150 张图片对B-Mask R-CNN 模型进行测试,表5 中训练速度的单位s/iter 指的是每迭代1 次所用的秒数。由表5 结果分析,使用ResNet101 能够提升一点精度,但训练速度也大大降低,为了实现实时的树冠检测与识别,本研究最终将ResNet50 作为特征提取网络进行训练。
3.3 自然场景检测试验
3.3.1 不同复杂背景下检测效果对比 为了检验本文提出的B-Mask R-CNN 模型在不同复杂背景情况下树冠检测效果的优越性,从测试集中挑选图片进行对比试验。测试集由矮化密植形、小冠疏层形、自然开心形、自然圆头形、Y 形5 种树形组成,每种树形各30 张,从中选取5 种复杂背景情况。5 种复杂情况分别为树冠间距小、树冠背景近处有其他树、树冠背景远处有其他树、树冠旁有相近颜色物体与树冠未处于图像中央 。
将B-Mask R-CNN、Mask R-CNN、目标检测网络Faster R-CNN[21]、语义分割网络U-Net[22]以及传统分割算法K-means 分别对5 种树形进行检测与识别,以上5 种算法的检测结果与原图、标签图的对比结果如图6 所示。

图 6 复杂背景下各算法检测效果对比Fig.6 Comparison of detection effects of various algorithms in complex background
图6 进行结果展示时, Mask R-CNN 检测时易出现多个检测框,并且易将相近颜色物体与背景树识别为树冠区域。Faster R-CNN 得到了树冠的目标检测框与树形的类别,但不能实现树冠区域的分割,在检测树冠间距小的树冠时,易将旁边树冠识别在内,并且易出现识别不全的问题。U-Net 算法在进行树冠检测时仅得到了树冠区域的二值图像,在对复杂背景的树冠进行分割时,易将与树冠颜色相近的物体识别为树冠区域。K-means 也仅得到了树冠区域的二值图像,分割结果中显示将大量的背景区域分割到了树冠区域中。本文所提出的B-Mask R-CNN 算法能够得到树冠的目标检测框、分割得到的树冠喷施区域以及树形的类别。本算法对树冠间距小、树冠背景近处有其他树、树冠背景远处有其他树、树冠旁有相近颜色物体与树冠未处于图像中央 5 种复杂背景情况下的果树进行检测识别时,分割出的轮廓更加清晰,不易将旁边的树、背景树、旁边绿色物体以及道路误识别。
为了进一步验证所提算法的有效性,使用矮化密植形、小冠疏层形、自然开心形、自然圆头形以及Y 形5 种树形各30 张,总共使用150 张测试集的图片进行测试,使用平均准确率mAcc作为评价标准。将本文提出的B-Mask R-CNN 与Mask R-CNN、Faster R-CNN、U-Net 以及K-means 算法对比平均准确率,结果如表6 所示。表6 的结果可以显示出本文所提出的B-Mask R-CNN 算法的优越性。

表 6 5 类算法的平均准确率mAccTable 6 Average accuracy of five algorithms
综上所述,相比较Mask R-CNN、Faster R-CNN、U-Net 以及K-means 算法,本文所提出的B-Mask R-CNN 算法能够实现更好的检测与识别效果。
3.3.2 不同光照条件对比 传统的分割算法往往对光线条件比较敏感,而本文所提出B-Mask R-CNN模型对不同光照条件下的果树检测与识别有很好的鲁棒性,图7 以小冠疏层形的果树为例,展示了本算法在不同光照条件下的检测效果。本文挑选弱光、正常光、强光3 种不同光照条件下的图像进行对比,本算法均能够将树冠从复杂的背景中分割出来,证明了本算法对不同光照条件下复杂背景果树检测分割的有效性。

图 7 不同光照条件下检测效果对比Fig.7 Comparison of different brightness detection effects
3.3.3 不同树形对喷施效果的影响 本试验采集的5 种树形对喷头喷施范围有不同的影响,图8 利用红色框标注出喷施范围。当树冠同时位于图像中央时,大部分情况下,Dwarf 形图像的上下边界为0,左右边界有空余;Layered 形与Yshape 形图像的上下左右边界为0;Openheart 形与Roundhead 形图像左右边界为0,下边界留有较大距离。
另外,从图8 的喷施范围中也能够观察到,不同树形的喷施区域中树冠分布区域也不相同,树冠分布区域将影响到进行精准喷施时喷头是否打开,因此树形也会影响到喷头施药时的开闭情况。

图 8 树形对喷施的影响Fig.8 Effect of tree shapes on spraying
4 结论
(1)本文基于Mask R-CNN 进行改进,提出了B-Mask R-CNN 模型,本模型引入了采样策略IoUbalanced sampling 提升了算法的精度,边界框损失函数Lbbox引入BalancedL1 loss 使得损失更好地收敛,调整先验知识Anchor 比例,提升了算法的准确率。改进后算法在bbox 与segm 两方面的mAP值均达到了98.7%,检测速度为3.356e-1 s/iter,能够达到实时检测的标准。
(2)本文所提的B-Mask R-CNN 算法相较其他的算法实现了更精准地检测与识别,对5 种不同复杂背景下的树冠都能够进行较好地检测与识别,对不同光线下的树冠检测也具有很好的鲁棒性。其次,本文讨论了树形对施药过程的影响。本研究最终实现了复杂背景下树冠的检测与树形的识别,能够为后续的精准喷施研究提供树形信息,并为构建最优喷施控制模型奠定研究基础。
(3)本文在研究多种树形时,只讨论了5 种树形,今后可以增加更多的树形进行试验,进一步提高模型的泛化能力。另外,本文在讨论树形对精准喷施中施药过程的影响时,只针对本文在互联网上采集的数据集进行了讨论,未考虑到距离、角度等因素,下一步可以在实际场景下设定合适的控制变量,进一步研究树形对果园精准喷施中施药过程的影响。
